Recognition: unknown
Green Shielding: A User-Centric Approach Towards Trustworthy AI
Pith reviewed 2026-05-08 03:40 UTC · model grok-4.3
The pith
Routine variations in how users phrase medical queries shift LLM diagnostic outputs along clinically meaningful Pareto tradeoffs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
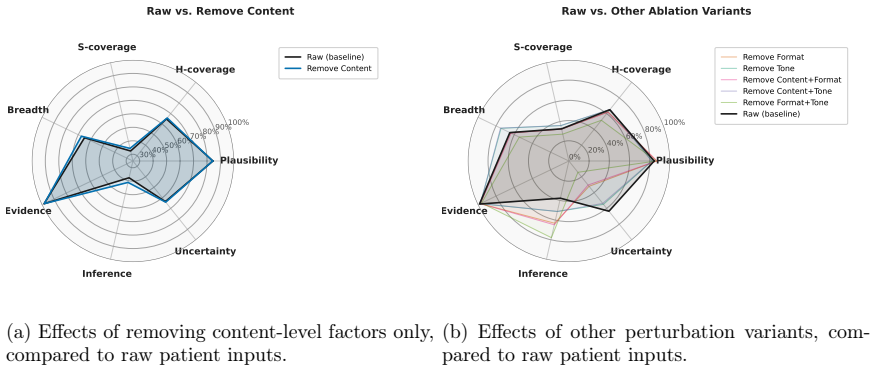
By applying the CUE criteria to create the HCM-Dx benchmark with patient-authored queries and physician-developed references, Green Shielding demonstrates that prompt-level factors induce shifts in frontier LLMs' differential diagnosis lists that form Pareto-like tradeoffs, where neutralization improves plausibility and clinician-likeness at the cost of reduced coverage of highly likely and safety-critical conditions.
What carries the argument
The neutralization perturbation regime, which removes common user-level factors from queries while preserving clinical content, as a mechanism to reveal tradeoffs in model outputs along dimensions of plausibility and coverage.
Load-bearing premise
That the chosen perturbations accurately reflect realistic user variations in how queries are phrased and that the physician-developed metrics and reference sets truly measure clinical utility and safety.
What would settle it
Observing that neutralization does not increase plausibility or reduce coverage of safety-critical conditions when tested on additional frontier LLMs with independent physician validation would undermine the claimed Pareto tradeoffs.
Figures






read the original abstract
Large language models (LLMs) are increasingly deployed, yet their outputs can be highly sensitive to routine, non-adversarial variation in how users phrase queries, a gap not well addressed by existing red-teaming efforts. We propose Green Shielding, a user-centric agenda for building evidence-backed deployment guidance by characterizing how benign input variation shifts model behavior. We operationalize this agenda through the CUE criteria: benchmarks with authentic Context, reference standards and metrics that capture true Utility, and perturbations that reflect realistic variations in the Elicitation of model behavior. Guided by the PCS framework and developed with practicing physicians, we instantiate Green Shielding in medical diagnosis through HealthCareMagic-Diagnosis (HCM-Dx), a benchmark of patient-authored queries, together with structured reference diagnosis sets and clinically grounded metrics for evaluating differential diagnosis lists. We also study perturbation regimes that capture routine input variation and show that prompt-level factors shift model behavior along clinically meaningful dimensions. Across multiple frontier LLMs, these shifts trace out Pareto-like tradeoffs. In particular, neutralization, which removes common user-level factors while preserving clinical content, increases plausibility and yields more concise, clinician-like differentials, but reduces coverage of highly likely and safety-critical conditions. Together, these results show that interaction choices can systematically shift task-relevant properties of model outputs and support user-facing guidance for safer deployment in high-stakes domains. Although instantiated here in medical diagnosis, the agenda extends naturally to other decision-support settings and agentic AI systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Green Shielding, a user-centric framework for trustworthy AI that characterizes how benign, non-adversarial variations in user query phrasing affect LLM behavior in high-stakes settings. It operationalizes this via the CUE criteria (authentic Context, Utility metrics, realistic Elicitation perturbations), introduces the physician-developed HCM-Dx benchmark of patient-authored medical queries with structured reference diagnosis sets, and reports that prompt-level perturbations (especially neutralization) produce Pareto-like tradeoffs across frontier LLMs: neutralization yields more plausible and concise, clinician-like differentials but reduces coverage of highly likely and safety-critical conditions.
Significance. If the central empirical patterns hold, the work provides concrete, evidence-based guidance on how routine user interaction choices systematically shift clinically relevant output properties, filling a gap between adversarial red-teaming and deployment practice. The physician-guided benchmark construction and focus on falsifiable tradeoffs represent a constructive extension of the PCS framework to real-world decision-support scenarios.
major comments (3)
- [Abstract / neutralization description] Abstract and the section describing neutralization: the central claim that neutralization 'removes common user-level factors while preserving clinical content' is load-bearing for interpreting the coverage drop as a genuine Pareto tradeoff rather than an artifact of query degradation. No quantitative validation of content preservation is reported (e.g., blinded physician comparison of information content, differential completeness, or retained clinical cues between original and neutralized queries).
- [Results / empirical evaluation] Results section reporting empirical patterns: the abstract states consistent shifts across models but provides no error bars, statistical tests, full methods details (data exclusion rules, exact perturbation implementations, or inter-rater reliability for reference sets), or sensitivity analyses. This leaves the magnitude, reliability, and clinical meaningfulness of the reported tradeoffs unverified.
- [HCM-Dx benchmark and metrics] Benchmark and metrics section: the claim that the chosen metrics and reference sets 'capture true Utility' and safety relevance rests on physician development, yet no explicit mapping or validation is given showing how the metrics distinguish information loss from model behavior change under neutralization.
minor comments (2)
- [Introduction] The CUE acronym expansion and its relation to the PCS framework could be stated more explicitly on first use to aid readers unfamiliar with the prior framework.
- [Results figures/tables] Figure or table captions describing the Pareto fronts should include the exact number of models, queries, and conditions evaluated to allow immediate assessment of scale.
Simulated Author's Rebuttal
We thank the referee for their constructive and insightful comments on our manuscript. Their feedback has prompted us to enhance the rigor and transparency of our presentation. Below, we provide point-by-point responses to the major comments, indicating revisions made to the manuscript.
read point-by-point responses
-
Referee: [Abstract / neutralization description] Abstract and the section describing neutralization: the central claim that neutralization 'removes common user-level factors while preserving clinical content' is load-bearing for interpreting the coverage drop as a genuine Pareto tradeoff rather than an artifact of query degradation. No quantitative validation of content preservation is reported (e.g., blinded physician comparison of information content, differential completeness, or retained clinical cues between original and neutralized queries).
Authors: We agree that quantitative validation of content preservation is important to rule out query degradation as an alternative explanation. Although not included in the original submission, we have conducted a post-hoc validation study involving two blinded physicians who independently rated 50 randomly sampled query pairs (original vs. neutralized) on scales for clinical content preservation, completeness of diagnostic information, and retention of key cues. The average scores were 4.3/5 for preservation, with inter-rater agreement (Cohen's kappa) of 0.82. These results support that neutralization preserves clinical content while removing user-level factors. We have added a dedicated subsection in the Methods and a summary in the Results, along with the full rating protocol in the appendix. revision: yes
-
Referee: [Results / empirical evaluation] Results section reporting empirical patterns: the abstract states consistent shifts across models but provides no error bars, statistical tests, full methods details (data exclusion rules, exact perturbation implementations, or inter-rater reliability for reference sets), or sensitivity analyses. This leaves the magnitude, reliability, and clinical meaningfulness of the reported tradeoffs unverified.
Authors: We acknowledge that the initial results presentation lacked sufficient statistical detail and methodological transparency. In the revised version, we have added error bars representing 95% bootstrap confidence intervals for all key metrics across models and perturbations. We now include statistical tests (paired Wilcoxon signed-rank tests with Bonferroni correction) to confirm the significance of observed differences, with p-values reported. The Methods section has been expanded to detail data exclusion rules (queries with incomplete reference sets or fewer than 50 tokens were excluded, affecting <5% of data), exact implementations of perturbations (including prompt templates and randomization seeds), and inter-rater reliability for reference diagnosis sets (Fleiss' kappa = 0.78). Additionally, we have included sensitivity analyses varying the neutralization intensity and perturbation types. These changes allow readers to better assess the reliability and clinical relevance of the Pareto tradeoffs. revision: yes
-
Referee: [HCM-Dx benchmark and metrics] Benchmark and metrics section: the claim that the chosen metrics and reference sets 'capture true Utility' and safety relevance rests on physician development, yet no explicit mapping or validation is given showing how the metrics distinguish information loss from model behavior change under neutralization.
Authors: We appreciate this point, as explicit validation strengthens the link between our metrics and clinical utility. We have added a new subsection 'Metric Validation and Clinical Mapping' that provides an explicit table mapping each metric (e.g., plausibility, coverage of safety-critical conditions) to specific physician-defined criteria, such as alignment with differential diagnosis guidelines from medical literature and risk stratification. Furthermore, using the content preservation validation from our response to the first comment, we demonstrate that the observed changes in coverage and plausibility under neutralization are attributable to model behavior rather than information loss, as the queries retain high clinical fidelity. Physician raters also confirmed that metric scores reflect genuine shifts in model output properties relevant to safety and utility. revision: yes
Circularity Check
No circularity: empirical measurements on independent benchmark and perturbations
full rationale
The paper is an empirical study that introduces a new benchmark (HCM-Dx) consisting of patient-authored queries, physician-developed reference diagnosis sets, and custom metrics. It applies defined perturbation regimes (including neutralization) to frontier LLMs and directly measures resulting shifts in output properties such as plausibility, conciseness, coverage, and safety-critical condition inclusion. These tradeoffs are reported as observed model behaviors on the held-out test queries, not as quantities fitted from the same data or derived by construction from the input definitions. The PCS framework is invoked only for high-level methodological guidance and does not supply any load-bearing theorem, uniqueness result, or ansatz that reduces the central empirical claims to self-citation. No equations, predictions, or self-definitional reductions appear in the reported results.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The CUE criteria (authentic Context, true Utility, realistic Elicitation) constitute a sufficient and appropriate lens for characterizing benign input variation.
- domain assumption Structured reference diagnosis sets and clinically grounded metrics developed with physicians accurately measure differential diagnosis quality and safety.
invented entities (3)
-
Green Shielding
no independent evidence
-
CUE criteria
no independent evidence
-
HealthCareMagic-Diagnosis (HCM-Dx)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review arXiv 2023
-
[2]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review arXiv 2023
-
[3]
The claude 3 model family: Opus, sonnet, haiku.Claude 3 Model Card,
Anthropic. The claude 3 model family: Opus, sonnet, haiku.Claude 3 Model Card,
-
[4]
URLhttps://www-cdn.anthropic.com/de8ba9b01c9ab7cbabf5c33b80b7bbc618857627/ Model_Card_Claude_3.pdf
-
[5]
Ziwei Xu, Sanjay Jain, and Mohan Kankanhalli. Hallucination is inevitable: An innate limitation of large language models.arXiv preprint arXiv:2401.11817, 2024
-
[6]
A survey on hallucination in large language models: Principles, taxonomy, challenges, andopenquestions.ACM Transactions on Information Systems, 43(2):1–55, 2025
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, et al. A survey on hallucination in large language models: Principles, taxonomy, challenges, andopenquestions.ACM Transactions on Information Systems, 43(2):1–55, 2025
2025
-
[7]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models.arXiv preprint arXiv:2203.11171, 2022
work page internal anchor Pith review arXiv 2022
-
[8]
Measuring Faithfulness in Chain-of-Thought Reasoning
Tamera Lanham, Anna Chen, Ansh Radhakrishnan, Benoit Steiner, Carson Denison, Danny Hernandez, Dustin Li, Esin Durmus, Evan Hubinger, Jackson Kernion, et al. Measuring faith- fulness in chain-of-thought reasoning.arXiv preprint arXiv:2307.13702, 2023
work page internal anchor Pith review arXiv 2023
-
[9]
Towards Understanding Sycophancy in Language Models
Mrinank Sharma, Meg Tong, Tomasz Korbak, David Duvenaud, Amanda Askell, Samuel R Bowman, Newton Cheng, Esin Durmus, Zac Hatfield-Dodds, Scott R Johnston, et al. Towards understanding sycophancy in language models.arXiv preprint arXiv:2310.13548, 2023
work page internal anchor Pith review arXiv 2023
-
[10]
Dan Hendrycks, Mantas Mazeika, and Thomas Woodside. An overview of catastrophic ai risks. arXiv preprint arXiv:2306.12001, 2023
- [11]
-
[12]
District Court for the Southern District of New York
U.S. District Court for the Southern District of New York. Mata v. avianca, inc., no. 1:2022cv01461, document 55, 2023. URLhttps://law.justia.com/cases/federal/ district-courts/new-york/nysdce/1:2022cv01461/575368/55/. Opinion and Order (Castel, J.), June 22, 2023
2023
-
[13]
The eu artificial intelligence act.European Union, 2024
EU Artificial Intelligence Act. The eu artificial intelligence act.European Union, 2024
2024
-
[14]
Demystifying the draft eu artificial intelligence act.arXiv preprint arXiv:2107.03721, 2021
Michael Veale and Frederik Zuiderveen Borgesius. Demystifying the draft eu artificial intelligence act.arXiv preprint arXiv:2107.03721, 2021
-
[15]
Artificial intelligence risk management framework (ai rmf 1.0).journal=URL: https://nvlpubs
Elham Tabassi. Artificial intelligence risk management framework (ai rmf 1.0).journal=URL: https://nvlpubs. nist. gov/nistpubs/ai/nist. ai,, 2023
2023
-
[16]
Mulligan
Deirdre K. Mulligan. If anyone builds it, everyone dies: Sociotechnical imaginaries of ai and our regulatory futures. Invited talk, 2026. 18
2026
-
[17]
Veridical data science.Proceedings of the National Academy of Sciences, 117(8):3920–3929, 2020
Bin Yu and Karl Kumbier. Veridical data science.Proceedings of the National Academy of Sciences, 117(8):3920–3929, 2020. doi: 10.1073/pnas.1901326117. URLhttps://www.pnas. org/doi/abs/10.1073/pnas.1901326117
-
[18]
What disease does this patient have? a large-scale open domain question answering dataset from medical exams.Applied Sciences, 11(14):6421, 2021
Di Jin, Eileen Pan, Nassim Oufattole, Wei-Hung Weng, Hanyi Fang, and Peter Szolovits. What disease does this patient have? a large-scale open domain question answering dataset from medical exams.Applied Sciences, 11(14):6421, 2021
2021
-
[19]
Yuxin Zuo, Shang Qu, Yifei Li, Zhangren Chen, Xuekai Zhu, Ermo Hua, Kaiyan Zhang, Ning Ding, and Bowen Zhou. Medxpertqa: Benchmarking expert-level medical reasoning and under- standing.arXiv preprint arXiv:2501.18362, 2025
-
[20]
Chatdoctor: A medical chat model fine-tuned on a large language model meta-ai (llama) using medical domain knowledge.Cureus, 15(6), 2023
Yunxiang Li, Zihan Li, Kai Zhang, Ruilong Dan, Steve Jiang, and You Zhang. Chatdoctor: A medical chat model fine-tuned on a large language model meta-ai (llama) using medical domain knowledge.Cureus, 15(6), 2023
2023
-
[21]
Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned
Deep Ganguli, Liane Lovitt, Jackson Kernion, Amanda Askell, Yuntao Bai, Saurav Kada- vath, Ben Mann, Ethan Perez, Nicholas Schiefer, Kamal Ndousse, et al. Red teaming lan- guage models to reduce harms: Methods, scaling behaviors, and lessons learned.arXiv preprint arXiv:2209.07858, 2022
work page internal anchor Pith review arXiv 2022
-
[22]
Harmbench: a stand- ardized evaluation framework for automated red teaming and robust refusal
Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, David Forsyth, and Dan Hendrycks. Harmbench: a stand- ardized evaluation framework for automated red teaming and robust refusal. InIn Proceedings of the International Conference on Machine Learning, 2024, ICML’24. JMLR.org, 2024
2024
-
[23]
In: Rogers, A., Boyd-Graber, J., Okazaki, N
Ethan Perez, Saffron Huang, Francis Song, Trevor Cai, Roman Ring, John Aslanides, Amelia Glaese, Nat McAleese, and Geoffrey Irving. Red teaming language models with language models. InYoavGoldberg, ZornitsaKozareva, andYueZhang, editors,Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 3419–3448, Abu Dhabi, Unit...
-
[24]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J Zico Kolter, and Matt Fredrikson. Universal and transferable adversarial attacks on aligned language models.arXiv preprint arXiv:2307.15043, 2023
work page internal anchor Pith review arXiv 2023
-
[25]
Jailbroken: how does llm safety training fail? InProceedings of the 37th International Conference on Neural Information Processing Systems, NIPS ’23, Red Hook, NY, USA, 2023
Alexander Wei, Nika Haghtalab, and Jacob Steinhardt. Jailbroken: how does llm safety training fail? InProceedings of the 37th International Conference on Neural Information Processing Systems, NIPS ’23, Red Hook, NY, USA, 2023. Curran Associates Inc
2023
-
[26]
do anything now
Xinyue Shen, Zeyuan Chen, Michael Backes, Yun Shen, and Yang Zhang. " do anything now": Characterizing and evaluating in-the-wild jailbreak prompts on large language models. InPro- ceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, pages 1671–1685, 2024
2024
-
[27]
Not what you’ve signed up for: Compromising real-world llm-integrated applications with indirect prompt injection
Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. Not what you’ve signed up for: Compromising real-world llm-integrated applications with indirect prompt injection. InProceedings of the 16th ACM workshop on artificial intelligence and security, pages 79–90, 2023
2023
-
[28]
Formalizing and benchmarking prompt injection attacks and defenses
Yupei Liu, Yuqi Jia, Runpeng Geng, Jinyuan Jia, and Neil Zhenqiang Gong. Formalizing and benchmarking prompt injection attacks and defenses. In33rd USENIX Security Symposium (USENIX Security 24), pages 1831–1847, Philadelphia, PA, August 2024. USENIX Association. ISBN 978-1-939133-44-1. URLhttps://www.usenix.org/conference/usenixsecurity24/ presentation/l...
2024
-
[29]
Certifying LLM Safety against Adversarial Prompting
Aounon Kumar, Chirag Agarwal, Suraj Srinivas, Aaron Jiaxun Li, Soheil Feizi, and Himabindu Lakkaraju. Certifying llm safety against adversarial prompting.arXiv preprint arXiv:2309.02705, 2023
-
[30]
In34th USENIX Security Symposium (USENIX Se- curity 25), pages 2383–2400, 2025
Sizhe Chen, Julien Piet, Chawin Sitawarin, and David Wagner.{StruQ}: Defending against prompt injection with structured queries. In34th USENIX Security Symposium (USENIX Se- curity 25), pages 2383–2400, 2025
2025
-
[31]
Dataset security for machine learning: Data poisoning, backdoor attacks, and defenses.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(2):1563–1580, 2022
Micah Goldblum, Dimitris Tsipras, Chulin Xie, Xinyun Chen, Avi Schwarzschild, Dawn Song, Aleksander Mądry, Bo Li, and Tom Goldstein. Dataset security for machine learning: Data poisoning, backdoor attacks, and defenses.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(2):1563–1580, 2022
2022
-
[32]
Wild patterns reloaded: Asurveyofmachinelearningsecurityagainsttrainingdatapoisoning.ACM Computing Surveys, 55(13s):1–39, 2023
Antonio Emanuele Cinà, Kathrin Grosse, Ambra Demontis, Sebastiano Vascon, Werner Zellinger, Bernhard A Moser, Alina Oprea, Battista Biggio, Marcello Pelillo, and Fabio Roli. Wild patterns reloaded: Asurveyofmachinelearningsecurityagainsttrainingdatapoisoning.ACM Computing Surveys, 55(13s):1–39, 2023
2023
-
[33]
InjecAgent: Benchmarking Indirect Prompt Injections in Tool-Integrated Large Language Model Agents
Qiusi Zhan, Zhixiang Liang, Zifan Ying, and Daniel Kang. Injecagent: Benchmarking in- direct prompt injections in tool-integrated large language model agents.arXiv preprint arXiv:2403.02691, 2024
work page internal anchor Pith review arXiv 2024
-
[34]
Trojanrag: Retrieval-augmented generation can be backdoor driver in large language models,
Pengzhou Cheng, Yidong Ding, Tianjie Ju, Zongru Wu, Wei Du, Ping Yi, Zhuosheng Zhang, and Gongshen Liu. Trojanrag: Retrieval-augmented generation can be backdoor driver in large language models.arXiv preprint arXiv:2405.13401, 2024
-
[35]
In34th USENIX Security Symposium (USENIX Security 25), pages 3827–3844, 2025
Wei Zou, Runpeng Geng, Binghui Wang, and Jinyuan Jia.{PoisonedRAG}: Knowledge corrup- tion attacks to{Retrieval-Augmented}generation of large language models. In34th USENIX Security Symposium (USENIX Security 25), pages 3827–3844, 2025
2025
-
[36]
Ai agents under threat: A survey of key security challenges and future pathways.ACM Computing Surveys, 57(7):1–36, 2025
Zehang Deng, Yongjian Guo, Changzhou Han, Wanlun Ma, Junwu Xiong, Sheng Wen, and Yang Xiang. Ai agents under threat: A survey of key security challenges and future pathways.ACM Computing Surveys, 57(7):1–36, 2025
2025
-
[37]
Jingming Zhuo, Songyang Zhang, Xinyu Fang, Haodong Duan, Dahua Lin, and Kai Chen. Prosa: Assessing and understanding the prompt sensitivity of llms.arXiv preprint arXiv:2410.12405, 2024
-
[38]
POSIX : A Prompt Sensitivity Index For Large Language Models
Anwoy Chatterjee, H S V N S Kowndinya Renduchintala, Sumit Bhatia, and Tanmoy Chakraborty. POSIX: A prompt sensitivity index for large language models. In Yaser Al- Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Findings of the Association for Compu- tational Linguistics: EMNLP 2024, pages 14550–14565, Miami, Florida, USA, November 2024. Association fo...
-
[39]
Benchmarking prompt sensitivity in large language models
Amirhossein Razavi, Mina Soltangheis, Negar Arabzadeh, Sara Salamat, Morteza Zihayat, and Ebrahim Bagheri. Benchmarking prompt sensitivity in large language models. InEuropean Conference on Information Retrieval, pages 303–313. Springer, 2025
2025
-
[40]
Quantifying language mod- els'sensitivity to spurious features in prompt design or: How i learned to start worrying about prompt formatting
Melanie Sclar, Yejin Choi, Yulia Tsvetkov, and Alane Suhr. Quantifying language mod- els'sensitivity to spurious features in prompt design or: How i learned to start worrying about prompt formatting. In B. Kim, Y. Yue, S. Chaudhuri, K. Fragkiadaki, M. Khan, and Y. Sun, editors,International Conference on Learning Representations, volume 2024, pages 25055–...
2024
-
[41]
Towards llms robustness to changes in prompt format styles.arXiv preprint arXiv:2504.06969, 2025
Lilian Ngweta, Kiran Kate, Jason Tsay, and Yara Rizk. Towards llms robustness to changes in prompt format styles.arXiv preprint arXiv:2504.06969, 2025. 20
-
[42]
Large language models sensitivity to the order of op- tions in multiple-choice questions
Pouya Pezeshkpour and Estevam Hruschka. Large language models sensitivity to the order of op- tions in multiple-choice questions. InFindings of the Association for Computational Linguistics: NAACL 2024, pages 2006–2017, 2024
2024
-
[43]
Bryan Guan, Tanya Roosta, Peyman Passban, and Mehdi Rezagholizadeh. The order effect: Investigating prompt sensitivity to input order in llms.arXiv preprint arXiv:2502.04134, 2025
-
[44]
Syceval: Evaluatingllmsycophancy
Aaron Fanous, Jacob Goldberg, Ank Agarwal, Joanna Lin, Anson Zhou, Sonnet Xu, Vasiliki Bikia, RoxanaDaneshjou, andSanmiKoyejo. Syceval: Evaluatingllmsycophancy. InProceedings of the AAAI/ACM Conference on AI, Ethics, and Society, volume 8, pages 893–900, 2025
2025
-
[45]
arXiv preprint arXiv:2505.23840 , year=
Jiseung Hong, Grace Byun, Seungone Kim, and Kai Shu. Measuring sycophancy of language models in multi-turn dialogues.arXiv preprint arXiv:2505.23840, 2025
-
[46]
Open (clinical) llms are sensitive to instruction phrasings
Alberto Mario Ceballos-Arroyo, Monica Munnangi, Jiuding Sun, Karen Zhang, Jered Mcinerney, Byron C Wallace, and Silvio Amir. Open (clinical) llms are sensitive to instruction phrasings. InProceedings of the 23rd Workshop on Biomedical Natural Language Processing, pages 50–71, 2024
2024
-
[47]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding.arXiv preprint arXiv:2009.03300, 2020
work page internal anchor Pith review arXiv 2009
-
[48]
Pubmedqa: A dataset for biomedical research question answering
Qiao Jin, Bhuwan Dhingra, Zhengping Liu, William Cohen, and Xinghua Lu. Pubmedqa: A dataset for biomedical research question answering. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP), pages 2567–2577, 2019
2019
-
[49]
Medmcqa: A large-scale multi-subject multi-choice dataset for medical domain question answering
Ankit Pal, Logesh Kumar Umapathi, and Malaikannan Sankarasubbu. Medmcqa: A large-scale multi-subject multi-choice dataset for medical domain question answering. InConference on health, inference, and learning, pages 248–260. PMLR, 2022
2022
-
[50]
Large language models encode clinical knowledge.Nature, 620(7972):172–180, 2023
KaranSinghal, ShekoofehAzizi, TaoTu, SSaraMahdavi, JasonWei, HyungWonChung, Nathan Scales, Ajay Tanwani, Heather Cole-Lewis, Stephen Pfohl, et al. Large language models encode clinical knowledge.Nature, 620(7972):172–180, 2023
2023
-
[51]
Towards conversational diagnostic arti- ficial intelligence.Nature, pages 1–9, 2025
Tao Tu, Mike Schaekermann, Anil Palepu, Khaled Saab, Jan Freyberg, Ryutaro Tanno, Amy Wang, Brenna Li, Mohamed Amin, Yong Cheng, et al. Towards conversational diagnostic arti- ficial intelligence.Nature, pages 1–9, 2025
2025
-
[52]
HealthBench: Evaluating Large Language Models Towards Improved Human Health
RahulKArora, JasonWei, RebeccaSoskinHicks, PrestonBowman, JoaquinQuiñonero-Candela, Foivos Tsimpourlas, Michael Sharman, Meghan Shah, Andrea Vallone, Alex Beutel, et al. Health- bench: Evaluating large language models towards improved human health.arXiv preprint arXiv:2505.08775, 2025
work page internal anchor Pith review arXiv 2025
-
[53]
G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. G-eval: Nlg evaluation using gpt-4 with better human alignment.arXiv preprint arXiv:2303.16634, 2023
work page internal anchor Pith review arXiv 2023
-
[54]
A survey on llm-as-a-judge.The Innovation, 2024
Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, et al. A survey on llm-as-a-judge.The Innovation, 2024
2024
-
[55]
Justice or prejudice? quantifying biases in llm-as-a-judge
Jiayi Ye, Yanbo Wang, Yue Huang, Dongping Chen, Qihui Zhang, Nuno Moniz, Tian Gao, Werner Geyer, Chao Huang, Pin-Yu Chen, et al. Justice or prejudice? quantifying biases in llm-as-a-judge.arXiv preprint arXiv:2410.02736, 2024
-
[56]
arXiv preprint arXiv:2410.21819 (2025)
Koki Wataoka, Tsubasa Takahashi, and Ryokan Ri. Self-preference bias in llm-as-a-judge.arXiv preprint arXiv:2410.21819, 2024. 21
-
[57]
Judging the judges: A systematic study of position bias in llm-as-a-judge
Lin Shi, Chiyu Ma, Wenhua Liang, Xingjian Diao, Weicheng Ma, and Soroush Vosoughi. Judging the judges: A systematic study of position bias in llm-as-a-judge. InProceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics, pages 292–...
2025
-
[58]
Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems, 36:46595–46623, 2023
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems, 36:46595–46623, 2023
2023
-
[59]
Chatbot arena: An open platform for evaluating llms by human preference
Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, Anastasios Nikolas Angelopoulos, Tianle Li, Dacheng Li, Banghua Zhu, Hao Zhang, Michael Jordan, Joseph E Gonzalez, et al. Chatbot arena: An open platform for evaluating llms by human preference. InForty-first International Conference on Machine Learning, 2024
2024
-
[60]
Tianle Li, Wei-Lin Chiang, Evan Frick, Lisa Dunlap, Tianhao Wu, Banghua Zhu, Joseph E Gonzalez, and Ion Stoica. From crowdsourced data to high-quality benchmarks: Arena-hard and benchbuilder pipeline.arXiv preprint arXiv:2406.11939, 2024
-
[61]
Judgebench: A benchmark for evaluating llm-based judges,
Sijun Tan, Siyuan Zhuang, Kyle Montgomery, William Y Tang, Alejandro Cuadron, Chenguang Wang, Raluca Ada Popa, and Ion Stoica. Judgebench: A benchmark for evaluating llm-based judges.arXiv preprint arXiv:2410.12784, 2024
-
[62]
Suhana Bedi, Hejie Cui, Miguel Fuentes, Alyssa Unell, Michael Wornow, Juan M Banda, Nikesh Kotecha, Timothy Keyes, Yifan Mai, Mert Oez, et al. Medhelm: Holistic evaluation of large language models for medical tasks.arXiv preprint arXiv:2505.23802, 2025
-
[63]
Landon Butler, Abhineet Agarwal, Justin Singh Kang, Yigit Efe Erginbas, Bin Yu, and Kannan Ramchandran. Proxyspex: Inference-efficient interpretability via sparse feature interactions in llms.arXiv preprint arXiv:2505.17495, 2025. 22 A Computation of Confidence Intervals We report point estimates and confidence intervals (CIs) for three pilot-study metric...
-
[64]
Ensure every clinical fact in neutralized_prompt appears in extracted_state (no new facts)
-
[65]
Ensure all clinically relevant facts in extracted_state are represented in neutralized_prompt (no omissions), except that stylistic rephrasing and summarization is allowed if facts are preserved
-
[66]
Allow rewording, tense changes, and order changes
-
[67]
Return STRICT JSON ONLY: { is_consistent: true/false, added_facts: [
If the neutralized prompt mentions a diagnosis, it must be explicitly present in extracted_state (e.g., in O). Return STRICT JSON ONLY: { is_consistent: true/false, added_facts: [ ... ], missing_facts: [ ... ], notes: short explanation } 29 HCM-Dx: Prompt Neutralization Module, Detector and Neutralizer You are a medical expert and a reliable annotator. Yo...
-
[68]
Maintain clinical accuracy; never invent clinical facts
-
[69]
Preserve all factual symptom descriptions, timelines, and any user-mentioned prior diagnoses
-
[70]
Rewrite the case in neutral, third-person clinical style
-
[71]
Remove unrelated emotional language, conversational fluff, or non-medical life details
-
[72]
Produce a concise diagnostic query
-
[73]
I’m really scared
Produce output exclusively as astrict JSON object. Return strict JSON with the following schema: { neutralized_prompt: a third-person, concise, neutral clinical case summary followed by a single question asking for the most likely diagnosis, factors: { mentions_specific: true/false, contains_irrelevant_details: true/false, missing_objective_data: true/fal...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.