Recognition: unknown
When Errors Can Be Beneficial: A Categorization of Imperfect Rewards for Policy Gradient
Pith reviewed 2026-05-07 16:19 UTC · model grok-4.3
The pith
Imperfect proxy rewards can sometimes raise true performance in policy gradient training by steering away from mediocre outputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
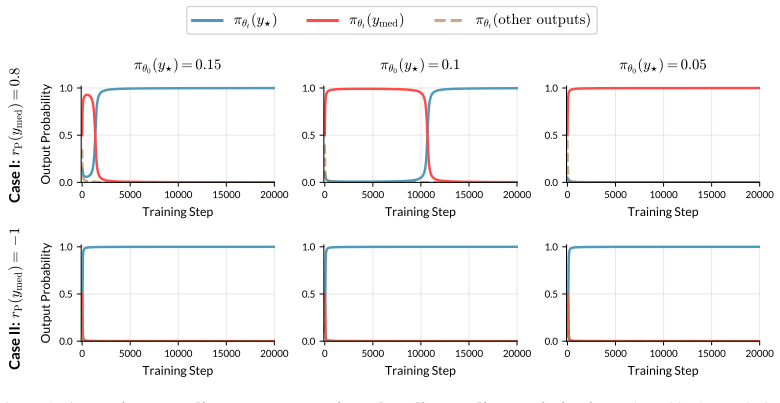
By examining which outputs attract probability during policy gradient optimization, reward errors can be categorized by their net effect on ground truth reward: some errors are harmful because they favor low-true-reward outputs, others are benign, and some are beneficial because they prevent the policy from stalling around outputs that have only mediocre ground truth reward. The effectiveness of any given proxy reward therefore depends on its interaction with the initial policy and the specific learning dynamics.
What carries the argument
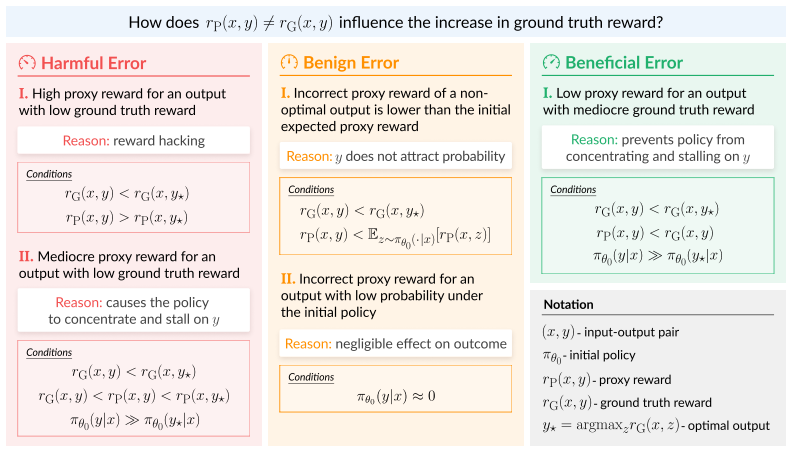
Categorization of reward errors into harmful, benign, and beneficial types, determined by whether the errors cause probability to shift toward outputs with higher ground truth reward during standard policy gradient updates.
If this is right
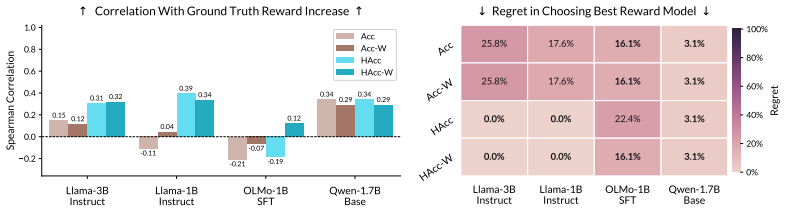
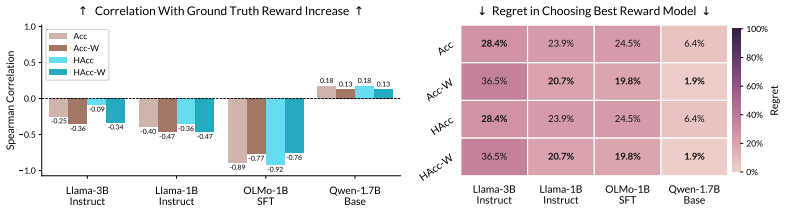
- Reward models for RLHF can be assessed with new metrics that account for error harmfulness, which often correlate more strongly with final language model performance after training.
- In domains with verifiable ground truth rewards, designers can deliberately include certain errors to keep the policy from settling on mediocre outputs.
- Proxy reward quality cannot be judged in isolation; it must be evaluated relative to the starting policy distribution and the update rule being used.
- The same categorization logic supplies a way to anticipate when a proxy will help versus hurt optimization progress.
Where Pith is reading between the lines
- The same probability-shift analysis could be applied to approximate rewards in non-language-model settings such as robotics or game playing to identify beneficial noise patterns.
- Reward model training procedures might be modified to favor the inclusion of controlled beneficial errors for tasks where early stalling is a known risk.
- This perspective suggests examining whether certain forms of reward hacking could be reframed as useful steering mechanisms rather than pure failures.
Load-bearing premise
The analysis assumes that probability shifts are driven purely by differences in the proxy reward values under standard policy gradient dynamics, without confounding effects from regularization, sampling variance, or other training components.
What would settle it
An experiment in which a reward error labeled beneficial produces lower final ground truth reward than the ground truth reward itself, or in which the new harmfulness-aware metrics correlate no better with post-training performance than standard ranking accuracy.
Figures




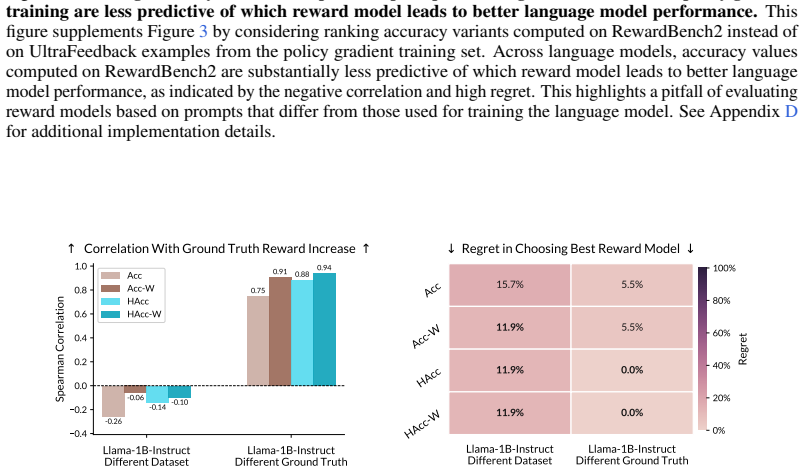
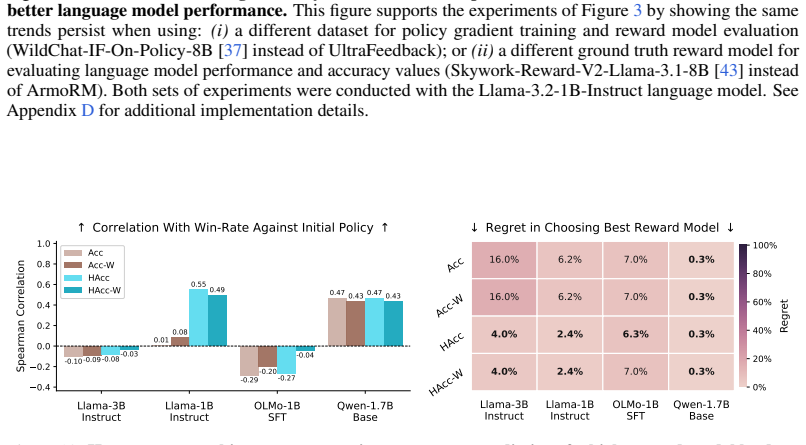



read the original abstract
Training language models via reinforcement learning often relies on imperfect proxy rewards, since ground truth rewards that precisely define the intended behavior are rarely available. Standard metrics for assessing the quality of proxy rewards, such as ranking accuracy, treat incorrect rewards as strictly harmful. In this work, however, we highlight that not all deviations from the ground truth are equal. By theoretically analyzing which outputs attract probability during policy gradient optimization, we categorize reward errors according to their effect on the increase in ground truth reward. The analysis establishes that reward errors, though conventionally viewed as harmful, can also be benign or even beneficial by preventing the policy from stalling around outputs with mediocre ground truth reward. We then present two practical implications of our theory. First, for reinforcement learning from human feedback (RLHF), we develop reward model evaluation metrics that account for the harmfulness of reward errors. Compared to standard ranking accuracy, these metrics typically correlate better with the performance of a language model after RLHF, yet gaps remain in robustly evaluating reward models. Second, we provide insights for reward design in settings with verifiable rewards. A key theme underlying our results is that the effectiveness of a proxy reward function depends heavily on its interaction with the initial policy and learning algorithm.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that imperfect proxy rewards in policy gradient optimization are not uniformly harmful. By analyzing which outputs increase in probability under policy gradients, it categorizes reward errors as harmful, benign, or beneficial, with beneficial errors preventing the policy from stalling at outputs that have only mediocre ground-truth reward. It applies this to RLHF by proposing new reward-model evaluation metrics that better correlate with post-RLHF language-model performance than standard ranking accuracy, and offers design insights for settings with verifiable rewards. The effectiveness of any proxy is shown to depend on its interaction with the initial policy and the learning algorithm.
Significance. If the categorization is valid, the work supplies a principled way to interpret reward-model errors in RLHF rather than treating all inaccuracies as detrimental. The new metrics and the emphasis on initial-policy dependence constitute concrete, usable contributions that could improve reward-model selection and reward design. The theoretical framing also highlights an under-appreciated interaction between reward misspecification and optimization dynamics.
major comments (1)
- [theoretical analysis and RLHF experiments] The central theoretical step (policy-gradient probability-flow analysis) derives the benign/beneficial classification under unmodified REINFORCE dynamics driven solely by the proxy reward. The manuscript later invokes PPO-based RLHF experiments that include clipping and KL penalties; these modifiers can reverse the sign of the effective gradient for the same error type, undermining the direct applicability of the categorization to the reported experiments. The paper notes the dependence on the learning algorithm but does not supply the required re-derivation or bounds under the clipped PPO objective.
minor comments (1)
- [abstract and introduction] The abstract and introduction would benefit from an explicit statement of the precise conditions (initial-policy distribution, absence of baselines or regularization) under which an error is classified as beneficial.
Simulated Author's Rebuttal
We thank the referee for highlighting the distinction between the theoretical setting and the experimental implementation. We respond to the major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [theoretical analysis and RLHF experiments] The central theoretical step (policy-gradient probability-flow analysis) derives the benign/beneficial classification under unmodified REINFORCE dynamics driven solely by the proxy reward. The manuscript later invokes PPO-based RLHF experiments that include clipping and KL penalties; these modifiers can reverse the sign of the effective gradient for the same error type, undermining the direct applicability of the categorization to the reported experiments. The paper notes the dependence on the learning algorithm but does not supply the required re-derivation or bounds under the clipped PPO objective.
Authors: We agree that the probability-flow analysis establishing the harmful/benign/beneficial categorization is performed under the standard REINFORCE update, which applies the proxy-reward gradient without clipping or KL regularization. PPO, as used in the RLHF experiments, modifies the objective via probability-ratio clipping and an explicit KL penalty; both can alter the sign or magnitude of the update for a given token and reward error. The manuscript already states that proxy effectiveness depends on the learning algorithm, yet we did not re-derive the categorization or supply transfer bounds for the clipped PPO loss. In the revision we will add a dedicated subsection that (i) identifies the regime in which the original classification remains approximately valid (small policy steps where clipping is inactive for most tokens and the KL term acts primarily as a regularizer rather than a sign-reversing force), (ii) reports additional diagnostic experiments confirming that the proposed reward-model metrics retain their improved correlation with post-RLHF performance even when PPO clipping is active, and (iii) explicitly flags the absence of a full PPO re-derivation as a limitation. A complete theoretical extension to arbitrary PPO hyperparameters lies outside the scope of the present work. revision: partial
- Complete re-derivation or quantitative bounds for the benign/beneficial classification under the full clipped PPO objective
Circularity Check
No circularity: categorization derives from first-principles policy gradient sign analysis without reduction to inputs or self-referential fits
full rationale
The paper's claimed derivation begins from the standard REINFORCE gradient form and examines the sign of (proxy reward difference) to determine whether probability mass increases for outputs with higher or lower ground-truth reward. This produces the harmful/benign/beneficial categorization as a direct mathematical consequence rather than an equivalence by construction, a fitted parameter renamed as prediction, or a load-bearing self-citation. No equations reduce to their own inputs; the analysis is explicitly conditioned on unmodified policy-gradient dynamics and the initial policy, with the paper noting dependence on the learning algorithm. Subsequent RLHF metric development and reward-design insights are presented as applications of the independent theoretical result, not as validations that close a loop. The derivation remains self-contained against external benchmarks of policy-gradient behavior.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions of policy gradient methods hold, including differentiable policies and updates that follow the expected gradient of the reward.
Reference graph
Works this paper leans on
-
[1]
On the theory of policy gradient methods: Optimality, approximation, and distribution shift.The Journal of Machine Learning Research, 22(1):4431–4506, 2021
Alekh Agarwal, Sham M Kakade, Jason D Lee, and Gaurav Mahajan. On the theory of policy gradient methods: Optimality, approximation, and distribution shift.The Journal of Machine Learning Research, 22(1):4431–4506, 2021
2021
-
[2]
Back to Basics: Revisiting REINFORCE Style Optimization for Learning from Human Feedback in LLMs
Arash Ahmadian, Chris Cremer, Matthias Gallé, Marzieh Fadaee, Julia Kreutzer, Olivier Pietquin, Ahmet Üstün, and Sara Hooker. Back to basics: Revisiting reinforce style optimization for learning from human feedback in llms.arXiv preprint arXiv:2402.14740, 2024
work page internal anchor Pith review arXiv 2024
-
[3]
Understanding the impact of entropy on policy optimization
Zafarali Ahmed, Nicolas Le Roux, Mohammad Norouzi, and Dale Schuurmans. Understanding the impact of entropy on policy optimization. InInternational conference on machine learning, pages 151–160. PMLR, 2019
2019
-
[4]
Concrete Problems in AI Safety
Dario Amodei, Chris Olah, Jacob Steinhardt, Paul Christiano, John Schulman, and Dan Mané. Concrete problems in ai safety.arXiv preprint arXiv:1606.06565, 2016
work page internal anchor Pith review arXiv 2016
-
[5]
Potential-based shaping in model-based reinforce- ment learning
John Asmuth, Michael L Littman, and Robert Zinkov. Potential-based shaping in model-based reinforce- ment learning. InAAAI, pages 604–609, 2008. 12
2008
-
[6]
arXiv preprint arXiv:2412.19792 , year=
Ananth Balashankar, Ziteng Sun, Jonathan Berant, Jacob Eisenstein, Michael Collins, Adrian Hutter, Jong Lee, Chirag Nagpal, Flavien Prost, Aradhana Sinha, et al. Infalign: Inference-aware language model alignment.arXiv preprint arXiv:2412.19792, 2024
-
[7]
Dota 2 with Large Scale Deep Reinforcement Learning
Christopher Berner, Greg Brockman, Brooke Chan, Vicki Cheung, Przemysław D˛ ebiak, Christy Dennison, David Farhi, Quirin Fischer, Shariq Hashme, Chris Hesse, et al. Dota 2 with large scale deep reinforcement learning.arXiv preprint arXiv:1912.06680, 2019
work page internal anchor Pith review arXiv 1912
-
[8]
Alberto Bietti, Joan Bruna, and Loucas Pillaud-Vivien. On learning gaussian multi-index models with gradient flow part i: General properties and two-timescale learning.Communications on Pure and Applied Mathematics, 78(12):2354–2435, 2025
2025
-
[9]
The accuracy paradox in rlhf: When better reward models don’t yield better language models
Yanjun Chen, Dawei Zhu, Yirong Sun, Xinghao Chen, Wei Zhang, and Xiaoyu Shen. The accuracy paradox in rlhf: When better reward models don’t yield better language models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024
2024
-
[10]
Heuristic-guided reinforcement learning
Ching-An Cheng, Andrey Kolobov, and Adith Swaminathan. Heuristic-guided reinforcement learning. Advances in Neural Information Processing Systems, 34:13550–13563, 2021
2021
-
[11]
Learning navigation behaviors end-to-end with autorl.IEEE Robotics and Automation Letters, 4(2):2007–2014, 2019
Hao-Tien Lewis Chiang, Aleksandra Faust, Marek Fiser, and Anthony Francis. Learning navigation behaviors end-to-end with autorl.IEEE Robotics and Automation Letters, 4(2):2007–2014, 2019
2007
-
[12]
More is less: inducing sparsity via overparameteriza- tion.Information and Inference: A Journal of the IMA, 12(3):1437–1460, 2023
Hung-Hsu Chou, Johannes Maly, and Holger Rauhut. More is less: inducing sparsity via overparameteriza- tion.Information and Inference: A Journal of the IMA, 12(3):1437–1460, 2023
2023
-
[13]
Reward model ensembles help mitigate overoptimization
Thomas Coste, Usman Anwar, Robert Kirk, and David Krueger. Reward model ensembles help mitigate overoptimization. InInternational Conference on Learning Representations, 2024
2024
-
[14]
Ultrafeedback: Boosting language models with high-quality feedback
Ganqu Cui, Lifan Yuan, Ning Ding, Guanming Yao, Wei Zhu, Yuan Ni, Guotong Xie, Zhiyuan Liu, and Maosong Sun. Ultrafeedback: Boosting language models with high-quality feedback. InInternational Conference on Machine Learning, 2024
2024
-
[15]
Maximum expected hitting cost of a markov decision process and informativeness of rewards.Advances in Neural Information Processing Systems, 2019
Falcon Dai and Matthew Walter. Maximum expected hitting cost of a markov decision process and informativeness of rewards.Advances in Neural Information Processing Systems, 2019
2019
-
[16]
Exploration-guided reward shaping for reinforcement learning under sparse rewards.Advances in Neural Information Processing Systems, 2022
Rati Devidze, Parameswaran Kamalaruban, and Adish Singla. Exploration-guided reward shaping for reinforcement learning under sparse rewards.Advances in Neural Information Processing Systems, 2022
2022
-
[17]
Continuous vs
Omer Elkabetz and Nadav Cohen. Continuous vs. discrete optimization of deep neural networks.Advances in Neural Information Processing Systems, 2021
2021
-
[18]
The perils of optimizing learned reward functions: Low training error does not guarantee low regret
Lukas Fluri, Leon Lang, Alessandro Abate, Patrick Forré, David Krueger, and Joar Skalse. The perils of optimizing learned reward functions: Low training error does not guarantee low regret. InInternational Conference on Machine Learning, 2025
2025
-
[19]
Is a good foundation necessary for efficient reinforcement learning? the computational role of the base model in exploration
Dylan J Foster, Zakaria Mhammedi, and Dhruv Rohatgi. Is a good foundation necessary for efficient reinforcement learning? the computational role of the base model in exploration. InProceedings of Thirty Eighth Conference on Learning Theory, 2025
2025
-
[20]
How to evaluate reward models for rlhf
Evan Frick, Tianle Li, Connor Chen, Wei-Lin Chiang, Anastasios N Angelopoulos, Jiantao Jiao, Banghua Zhu, Joseph E Gonzalez, and Ion Stoica. How to evaluate reward models for rlhf. InInternational Conference on Learning Representations, 2025
2025
-
[21]
Scaling laws for reward model overoptimization
Leo Gao, John Schulman, and Jacob Hilton. Scaling laws for reward model overoptimization. In International Conference on Machine Learning, pages 10835–10866. PMLR, 2023
2023
-
[22]
An alternate policy gradient estimator for softmax policies
Shivam Garg, Samuele Tosatto, Yangchen Pan, Martha White, and Rupam Mahmood. An alternate policy gradient estimator for softmax policies. InProceedings of The 25th International Conference on Artificial Intelligence and Statistics, pages 6630–6689, 2022
2022
-
[23]
Quantifying differences in reward functions
Adam Gleave, Michael Dennis, Shane Legg, Stuart Russell, and Jan Leike. Quantifying differences in reward functions. InInternational Conference on Learning Representations, 2021
2021
-
[24]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al- Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review arXiv 2024
-
[25]
Reward shaping in episodic reinforcement learning
Marek Grzes. Reward shaping in episodic reinforcement learning. InProceedings of the 16th Conference on Autonomous Agents and MultiAgent Systems, 2017. 13
2017
-
[26]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review arXiv 2025
-
[27]
Unpacking reward shaping: Understanding the benefits of reward engineering on sample complexity.Advances in Neural Information Processing Systems, 2022
Abhishek Gupta, Aldo Pacchiano, Yuexiang Zhai, Sham Kakade, and Sergey Levine. Unpacking reward shaping: Understanding the benefits of reward engineering on sample complexity.Advances in Neural Information Processing Systems, 2022
2022
-
[28]
Neural replicator dynamics.arXiv preprint arXiv:1906.00190, 2019
Daniel Hennes, Dustin Morrill, Shayegan Omidshafiei, Remi Munos, Julien Perolat, Marc Lanctot, Audrunas Gruslys, Jean-Baptiste Lespiau, Paavo Parmas, Edgar Duenez-Guzman, et al. Neural replicator dynamics.arXiv preprint arXiv:1906.00190, 2019
-
[29]
Is best-of-n the best of them? coverage, scaling, and optimality in inference-time alignment
Audrey Huang, Adam Block, Qinghua Liu, Nan Jiang, Akshay Krishnamurthy, and Dylan J Foster. Is best-of-n the best of them? coverage, scaling, and optimality in inference-time alignment. InInternational Conference on Machine Learning, 2025
2025
-
[30]
The Implicit Curriculum: Learning Dynamics in RL with Verifiable Rewards
Yu Huang, Zixin Wen, Yuejie Chi, Yuting Wei, Aarti Singh, Yingbin Liang, and Yuxin Chen. On the learning dynamics of rlvr at the edge of competence.arXiv preprint arXiv:2602.14872, 2026
work page internal anchor Pith review arXiv 2026
-
[31]
Yuzhen Huang, Weihao Zeng, Xingshan Zeng, Qi Zhu, and Junxian He. Pitfalls of rule-and model-based verifiers–a case study on mathematical reasoning.arXiv preprint arXiv:2505.22203, 2025
-
[32]
Goodhart’s law in reinforcement learning
Jacek Karwowski, Oliver Hayman, Xingjian Bai, Klaus Kiendlhofer, Charlie Griffin, and Joar Skalse. Goodhart’s law in reinforcement learning. InInternational Conference on Learning Representations, 2024
2024
-
[33]
Beyond stationarity: Convergence analysis of stochastic softmax policy gradient methods
Sara Klein, Simon Weissmann, and Leif Döring. Beyond stationarity: Convergence analysis of stochastic softmax policy gradient methods. InInternational Conference on Learning Representations, 2024
2024
-
[34]
Buy 4 reinforce samples, get a baseline for free!Deep Reinforcement Learning Meets Structured Prediction ICLR Workhsop, 2019
Wouter Kool, Herke van Hoof, and Max Welling. Buy 4 reinforce samples, get a baseline for free!Deep Reinforcement Learning Meets Structured Prediction ICLR Workhsop, 2019
2019
-
[35]
A neural collapse perspective on feature evolution in graph neural networks.Advances in Neural Information Processing Systems, 2023
Vignesh Kothapalli, Tom Tirer, and Joan Bruna. A neural collapse perspective on feature evolution in graph neural networks.Advances in Neural Information Processing Systems, 2023
2023
-
[36]
Correlated proxies: A new definition and improved mitigation for reward hacking
Cassidy Laidlaw, Shivam Singhal, and Anca Dragan. Correlated proxies: A new definition and improved mitigation for reward hacking. InInternational Conference on Learning Representations, 2025
2025
-
[37]
Tulu 3: Pushing Frontiers in Open Language Model Post-Training
Nathan Lambert, Jacob Morrison, Valentina Pyatkin, Shengyi Huang, Hamish Ivison, Faeze Brahman, Lester James V Miranda, Alisa Liu, Nouha Dziri, Shane Lyu, et al. Tulu 3: Pushing frontiers in open language model post-training.arXiv preprint arXiv:2411.15124, 2024
work page internal anchor Pith review arXiv 2024
-
[38]
Rewardbench: Evaluating reward models for language modeling
Nathan Lambert, Valentina Pyatkin, Jacob Morrison, LJ Miranda, Bill Yuchen Lin, Khyathi Chandu, Nouha Dziri, Sachin Kumar, Tom Zick, Yejin Choi, et al. Rewardbench: Evaluating reward models for language modeling. InFindings of the Association for Computational Linguistics: NAACL, 2025
2025
-
[39]
The influence of reward on the speed of reinforcement learning: An analysis of shaping
Adam Laud and Gerald DeJong. The influence of reward on the speed of reinforcement learning: An analysis of shaping. InProceedings of the 20th International Conference on Machine Learning (ICML-03), pages 440–447, 2003
2003
-
[40]
Softmax policy gradient methods can take exponential time to converge
Gen Li, Yuting Wei, Yuejie Chi, Yuantao Gu, and Yuxin Chen. Softmax policy gradient methods can take exponential time to converge. InConference on Learning Theory. PMLR, 2021
2021
-
[41]
Hashimoto
Xuechen Li, Tianyi Zhang, Yann Dubois, Rohan Taori, Ishaan Gulrajani, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. Alpacaeval: An automatic evaluator of instruction-following models. https://github.com/tatsu-lab/alpaca_eval, 5 2023
2023
-
[42]
Max Qiushi Lin, Jincheng Mei, Matin Aghaei, Michael Lu, Bo Dai, Alekh Agarwal, Dale Schuurmans, Csaba Szepesvari, and Sharan Vaswani. Rethinking the global convergence of softmax policy gradient with linear function approximation.arXiv preprint arXiv:2505.03155, 2025
-
[43]
Chris Yuhao Liu, Liang Zeng, Yuzhen Xiao, Jujie He, Jiacai Liu, Chaojie Wang, Rui Yan, Wei Shen, Fuxiang Zhang, Jiacheng Xu, Yang Liu, and Yahui Zhou. Skywork-reward-v2: Scaling preference data curation via human-ai synergy.arXiv preprint arXiv:2507.01352, 2025
-
[44]
Elementary analysis of policy gradient methods.arXiv preprint arXiv:2404.03372, 2024
Jiacai Liu, Wenye Li, and Ke Wei. Elementary analysis of policy gradient methods.arXiv preprint arXiv:2404.03372, 2024
-
[45]
RLTF: Reinforce- ment learning from unit test feedback.Transactions on Machine Learning Research, 2023
Jiate Liu, Yiqin Zhu, Kaiwen Xiao, QIANG FU, Xiao Han, Yang Wei, and Deheng Ye. RLTF: Reinforce- ment learning from unit test feedback.Transactions on Machine Learning Research, 2023. 14
2023
-
[46]
Rm-bench: Benchmarking reward mod- els of language models with subtlety and style
Yantao Liu, Zijun Yao, Rui Min, Yixin Cao, Lei Hou, and Juanzi Li. Rm-bench: Benchmarking reward mod- els of language models with subtlety and style. InInternational Conference on Learning Representations, 2025
2025
-
[47]
RewardBench 2: Advancing Reward Model Evaluation
Saumya Malik, Valentina Pyatkin, Sander Land, Jacob Morrison, Noah A Smith, Hannaneh Hajishirzi, and Nathan Lambert. Rewardbench 2: Advancing reward model evaluation.arXiv preprint arXiv:2506.01937, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
Md Rayhanul Masud, Azmine Toushik Wasi, Salman Rahman, and Md Rizwan Parvez. Reward engineering for reinforcement learning in software tasks.arXiv preprint arXiv:2601.19100, 2026
-
[49]
Reward functions for accelerated learning
Maja J Mataric. Reward functions for accelerated learning. InMachine learning proceedings 1994, pages 181–189. Elsevier, 1994
1994
-
[50]
Escaping the gravitational pull of softmax.Advances in Neural Information Processing Systems, 2020
Jincheng Mei, Chenjun Xiao, Bo Dai, Lihong Li, Csaba Szepesvári, and Dale Schuurmans. Escaping the gravitational pull of softmax.Advances in Neural Information Processing Systems, 2020
2020
-
[51]
On the global convergence rates of softmax policy gradient methods
Jincheng Mei, Chenjun Xiao, Csaba Szepesvari, and Dale Schuurmans. On the global convergence rates of softmax policy gradient methods. InInternational Conference on Machine Learning, pages 6820–6829. PMLR, 2020
2020
-
[52]
Leveraging non-uniformity in first-order non-convex optimization
Jincheng Mei, Yue Gao, Bo Dai, Csaba Szepesvari, and Dale Schuurmans. Leveraging non-uniformity in first-order non-convex optimization. InInternational Conference on Machine Learning, pages 7555–7564. PMLR, 2021
2021
-
[53]
Ordering-based conditions for global convergence of policy gradient methods.Advances in Neural Information Processing Systems, 2023
Jincheng Mei, Bo Dai, Alekh Agarwal, Mohammad Ghavamzadeh, Csaba Szepesvári, and Dale Schuur- mans. Ordering-based conditions for global convergence of policy gradient methods.Advances in Neural Information Processing Systems, 2023
2023
-
[54]
Stochastic gradient succeeds for bandits
Jincheng Mei, Zixin Zhong, Bo Dai, Alekh Agarwal, Csaba Szepesvari, and Dale Schuurmans. Stochastic gradient succeeds for bandits. InInternational Conference on Machine Learning, pages 24325–24360. PMLR, 2023
2023
-
[55]
Policy invariance under reward transformations: Theory and application to reward shaping
Andrew Y Ng, Daishi Harada, and Stuart Russell. Policy invariance under reward transformations: Theory and application to reward shaping. InIcml, volume 99, pages 278–287, 1999
1999
-
[56]
Team OLMo, Pete Walsh, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Shane Arora, Akshita Bhagia, Yuling Gu, Shengyi Huang, Matt Jordan, et al. 2 olmo 2 furious.arXiv preprint arXiv:2501.00656, 2024
work page internal anchor Pith review arXiv 2024
-
[57]
Team Olmo, Allyson Ettinger, Amanda Bertsch, Bailey Kuehl, David Graham, David Heineman, Dirk Groeneveld, Faeze Brahman, Finbarr Timbers, Hamish Ivison, et al. Olmo 3.arXiv preprint arXiv:2512.13961, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[58]
Training language models to follow instructions with human feedback.Advances in Neural Information Processing Systems, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in Neural Information Processing Systems, 2022
2022
-
[59]
Reward gaming in conditional text generation
Richard Yuanzhe Pang, Vishakh Padmakumar, Thibault Sellam, Ankur Parikh, and He He. Reward gaming in conditional text generation. InThe 61st Annual Meeting Of The Association For Computational Linguistics, 2023
2023
-
[60]
Automatic differentiation in pytorch
Adam Paszke, Sam Gross, Soumith Chintala, Gregory Chanan, Edward Yang, Zachary DeVito, Zeming Lin, Alban Desmaison, Luca Antiga, and Adam Lerer. Automatic differentiation in pytorch. InNIPS-W, 2017
2017
-
[61]
Amp: Adversarial motion priors for stylized physics-based character control.ACM Transactions on Graphics (ToG), 40(4):1–20, 2021
Xue Bin Peng, Ze Ma, Pieter Abbeel, Sergey Levine, and Angjoo Kanazawa. Amp: Adversarial motion priors for stylized physics-based character control.ACM Transactions on Graphics (ToG), 40(4):1–20, 2021
2021
-
[62]
Generalizing verifiable instruction following
Valentina Pyatkin, Saumya Malik, Victoria Graf, Hamish Ivison, Shengyi Huang, Pradeep Dasigi, Nathan Lambert, and Hannaneh Hajishirzi. Generalizing verifiable instruction following. InAdvances in Neural Information Processing Systems, 2025
2025
-
[63]
Yuval Ran-Milo, Yotam Alexander, Shahar Mendel, and Nadav Cohen. Outcome-based rl provably leads transformers to reason, but only with the right data.arXiv preprint arXiv:2601.15158, 2026
-
[64]
Learning to drive a bicycle using reinforcement learning and shaping
Jette Randløv and Preben Alstrøm. Learning to drive a bicycle using reinforcement learning and shaping. InInternational Conference on Machine Learning, 1999. 15
1999
-
[65]
Implicit regularization in deep learning may not be explainable by norms
Noam Razin and Nadav Cohen. Implicit regularization in deep learning may not be explainable by norms. InAdvances in Neural Information Processing Systems, 2020
2020
-
[66]
Implicit regularization in tensor factorization
Noam Razin, Asaf Maman, and Nadav Cohen. Implicit regularization in tensor factorization. InInterna- tional Conference on Machine Learning, 2021
2021
-
[67]
Implicit regularization in hierarchical tensor factorization and deep convolutional neural networks
Noam Razin, Asaf Maman, and Nadav Cohen. Implicit regularization in hierarchical tensor factorization and deep convolutional neural networks. InInternational Conference on Machine Learning, 2022
2022
-
[68]
Susskind, and Etai Littwin
Noam Razin, Hattie Zhou, Omid Saremi, Vimal Thilak, Arwen Bradley, Preetum Nakkiran, Joshua M. Susskind, and Etai Littwin. Vanishing gradients in reinforcement finetuning of language models. In International Conference on Learning Representations, 2024
2024
-
[69]
What makes a reward model a good teacher? an optimization perspective
Noam Razin, Zixuan Wang, Hubert Strauss, Stanley Wei, Jason D Lee, and Sanjeev Arora. What makes a reward model a good teacher? an optimization perspective. InAdvances in Neural Information Processing Systems, 2025
2025
-
[70]
Why is your language model a poor implicit reward model? InInternational Conference on Learning Representations, 2026
Noam Razin, Yong Lin, Jiarui Yao, and Sanjeev Arora. Why is your language model a poor implicit reward model? InInternational Conference on Learning Representations, 2026
2026
-
[71]
On the effective number of linear regions in shallow univariate relu networks: Convergence guarantees and implicit bias.Advances in Neural Information Processing Systems, 2022
Itay Safran, Gal Vardi, and Jason D Lee. On the effective number of linear regions in shallow univariate relu networks: Convergence guarantees and implicit bias.Advances in Neural Information Processing Systems, 2022
2022
-
[72]
Exact solutions to the nonlinear dynamics of learning in deep linear neural networks
Andrew M Saxe, James L McClelland, and Surya Ganguli. Exact solutions to the nonlinear dynamics of learning in deep linear neural networks. InInternational Conference on Learning Representations, 2014
2014
-
[73]
Ray interference: A source of plateaus in deep reinforcement learning,
Tom Schaul, Diana Borsa, Joseph Modayil, and Razvan Pascanu. Ray interference: a source of plateaus in deep reinforcement learning.arXiv preprint arXiv:1904.11455, 2019
-
[74]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review arXiv 2017
-
[75]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review arXiv 2024
-
[76]
Intrinsically motivated reinforce- ment learning: An evolutionary perspective.IEEE Transactions on Autonomous Mental Development, 2 (2):70–82, 2010
Satinder Singh, Richard L Lewis, Andrew G Barto, and Jonathan Sorg. Intrinsically motivated reinforce- ment learning: An evolutionary perspective.IEEE Transactions on Autonomous Mental Development, 2 (2):70–82, 2010
2010
-
[77]
Defining and characterizing reward gaming.Advances in Neural Information Processing Systems, 2022
Joar Skalse, Nikolaus Howe, Dmitrii Krasheninnikov, and David Krueger. Defining and characterizing reward gaming.Advances in Neural Information Processing Systems, 2022
2022
-
[78]
Starc: A general framework for quantifying differences between reward functions
Joar Skalse, Lucy Farnik, Sumeet Ramesh Motwani, Erik Jenner, Adam Gleave, and Alessandro Abate. Starc: A general framework for quantifying differences between reward functions. InInternational Conference on Learning Representations, 2024
2024
-
[79]
The implicit bias of structured state space models can be poisoned with clean labels
Yonatan Slutzky, Yotam Alexander, Noam Razin, and Nadav Cohen. The implicit bias of structured state space models can be poisoned with clean labels. InAdvances in Neural Information Processing Systems, 2025
2025
-
[80]
Reward design via online gradient ascent.Advances in Neural Information Processing Systems, 23, 2010
Jonathan Sorg, Richard L Lewis, and Satinder Singh. Reward design via online gradient ascent.Advances in Neural Information Processing Systems, 23, 2010
2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.