Recognition: unknown
How to Guide Your Flow: Few-Step Alignment via Flow Map Reward Guidance
Pith reviewed 2026-05-07 09:19 UTC · model grok-4.3
The pith
Reformulating guidance as deterministic optimal control lets the flow map steer trajectories to rewards in a single pass.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Guidance is equivalent to a deterministic optimal control task whose solution is given exactly by the flow map; this map simultaneously integrates the flow and applies the reward gradient, producing a training-free, single-trajectory algorithm that recovers earlier guidance schemes as special cases at coarser time discretizations.
What carries the argument
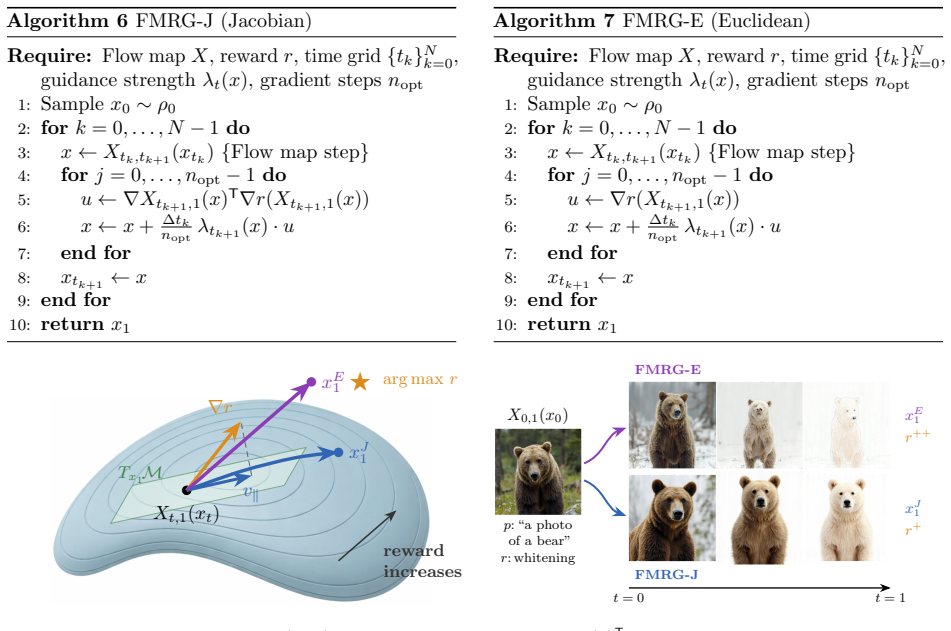
The flow map, the exact state-transition operator from time t to T, which here both advances the trajectory and supplies the control signal for reward maximization.
If this is right
- Existing guidance techniques appear as limiting cases of the same optimal-control hierarchy when the time grid is coarsened.
- No auxiliary training or multiple trajectories are required; any differentiable reward, including VLM scores, can be used directly.
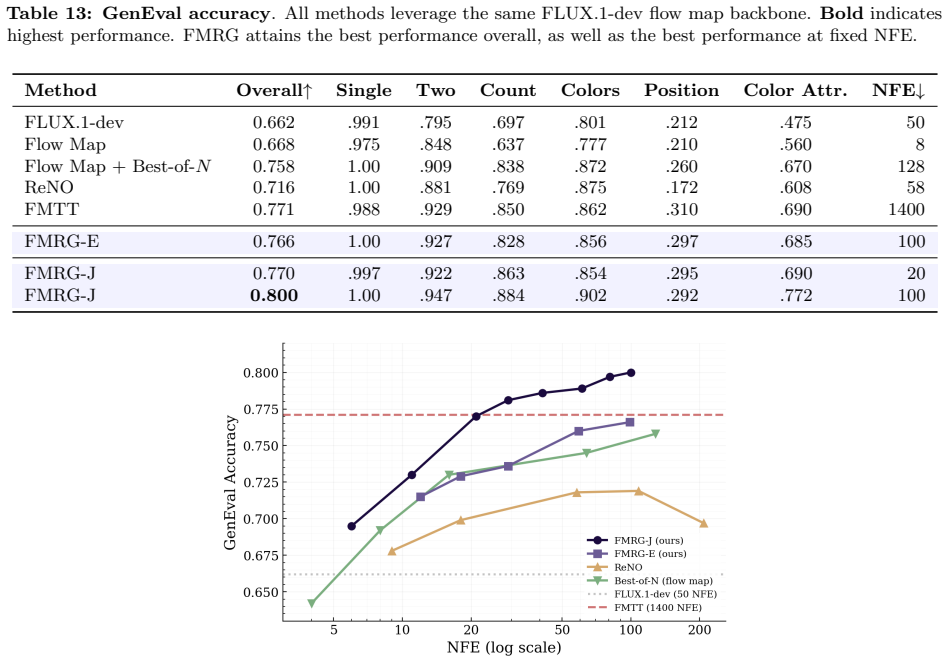
- Quality on inverse problems, style transfer, and preference alignment is preserved while the number of function evaluations drops by at least an order of magnitude.
- The single-trajectory formulation extends naturally to any flow-based generative model once a flow map is available.
Where Pith is reading between the lines
- Optimal-control views of sampling acceleration may unify other few-step techniques in diffusion and flow models.
- Jointly learning or fine-tuning flow maps with the guidance objective could further improve three-step performance.
- The approach could be tested on video or audio generation to check whether the same discretization tolerance holds outside images.
- Because only one trajectory is needed, the method lends itself to online, adaptive reward weighting during sampling.
Load-bearing premise
The deterministic optimal control formulation of guidance stays accurate when reduced to only a few discrete steps and when the flow map is applied without further approximation.
What would settle it
If FMRG samples generated with three network evaluations receive materially lower reward scores or human preference ratings than standard 20- or 50-step guidance baselines on the same text-to-image benchmarks, the few-step claim would be refuted.
Figures







read the original abstract
In generative modeling, we often wish to produce samples that maximize a user-specified reward such as aesthetic quality or alignment with human preferences, a problem known as guidance. Despite their widespread use, existing guidance methods either require expensive multi-particle, many-step schemes or rely on poorly understood approximations. We reformulate guidance as a deterministic optimal control problem, yielding a hierarchy of algorithms that subsumes existing approaches at the coarsest level. We show that the flow map, an object of significant recent interest for its role in fast inference, arises naturally in the optimal solution. Based on this observation, we propose Flow Map Reward Guidance (FMRG): a training-free, single-trajectory framework that uses the flow map to both integrate and guide the flow. At text-to-image scale, FMRG matches or surpasses baselines across inverse problems, style transfer, human preferences, and VLM rewards with as few as 3 NFEs, giving at least an order-of-magnitude speedup in comparison to prior state of the art.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reformulates guidance in generative modeling as a deterministic optimal control problem whose solution naturally involves the flow map. From this it derives Flow Map Reward Guidance (FMRG), a training-free single-trajectory method that uses the flow map for both integration and reward guidance. The central empirical claim is that FMRG matches or exceeds prior baselines on inverse problems, style transfer, human preferences, and VLM rewards while using as few as 3 NFEs, yielding at least an order-of-magnitude speedup.
Significance. If the claims hold, the work would be significant: it supplies a principled optimal-control unification of guidance methods, is training-free, and targets the practically important regime of very few NFEs. The explicit connection between the flow map and the optimal guidance policy is a conceptual strength that could influence subsequent algorithm design in flow-based generative modeling.
major comments (1)
- [Optimal control reformulation and FMRG derivation] The continuous-time deterministic optimal control derivation is used to obtain the FMRG update. When the method is instantiated at 3 NFEs, the direct substitution of the flow map into the discrete trajectory introduces an unanalyzed discretization error; no bound or convergence argument is supplied showing that the resulting policy remains close to the continuous optimum or that the claimed reward improvement is preserved. This gap is load-bearing for the few-step performance claims.
minor comments (2)
- [Abstract and Experiments] The abstract asserts strong empirical results across multiple tasks yet supplies no information on baselines, number of runs, error bars, or ablations; the full manuscript should include these details in the experimental section to allow assessment of the speedup and performance claims.
- [Notation and Preliminaries] Notation for the flow map, reward function, and control policy should be introduced with explicit definitions and kept consistent between the theoretical derivation and the algorithmic description.
Simulated Author's Rebuttal
We thank the referee for their careful reading and for recognizing the potential significance of the optimal-control unification. Below we respond directly to the single major comment.
read point-by-point responses
-
Referee: [Optimal control reformulation and FMRG derivation] The continuous-time deterministic optimal control derivation is used to obtain the FMRG update. When the method is instantiated at 3 NFEs, the direct substitution of the flow map into the discrete trajectory introduces an unanalyzed discretization error; no bound or convergence argument is supplied showing that the resulting policy remains close to the continuous optimum or that the claimed reward improvement is preserved. This gap is load-bearing for the few-step performance claims.
Authors: We agree that a rigorous error bound would strengthen the few-step claims. The continuous-time derivation yields the exact optimal guidance policy; FMRG discretizes it by using the flow map, which integrates the underlying ODE exactly between any pair of times. Consequently the only approximation is the application of the continuous guidance direction at finite intervals rather than an integration error from a numerical solver. In the revised manuscript we have inserted a new paragraph in Section 3.2 that supplies a first-order Lipschitz analysis of this guidance approximation, showing that the deviation from the continuous optimum scales linearly with step size. While a complete convergence theorem for arbitrary (non-Lipschitz) rewards is beyond the scope of the present work, the added analysis together with the consistent empirical gains at 3 NFEs across four distinct task families provides both theoretical insight and practical validation for the reported performance. revision: partial
Circularity Check
No significant circularity; derivation remains independent of its inputs
full rationale
The paper's central chain reformulates guidance as a deterministic optimal control problem in continuous time, observes that the flow map appears in the optimal solution, and constructs FMRG as a training-free method that substitutes the flow map for both integration and guidance. No step equates a claimed prediction or performance result to a fitted parameter by construction, renames a known empirical pattern, or relies on a load-bearing self-citation whose prior result is itself unverified or defined in terms of the target claim. The discretization to 3 NFEs is presented as a practical approximation without any definitional reduction of the reported speedup or reward improvement back to the continuous-time inputs. The derivation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Guidance in generative flows can be exactly recast as a deterministic optimal control problem whose solution involves the flow map.
Forward citations
Cited by 1 Pith paper
-
Diffusion-Based Posterior Sampling: A Feynman-Kac Analysis of Bias and Stability
Diffusion posterior samplers produce biased outputs that can be expressed as an Ornstein-Uhlenbeck path expectation via a surrogate Gaussian path and Feynman-Kac representation, with STSL flattening the spatially vary...
Reference graph
Works this paper leans on
-
[1]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022. (pages 2, 3, and 10)
work page internal anchor Pith review arXiv 2022
-
[2]
Stochastic Interpolants: A Unifying Framework for Flows and Diffusions
Michael S Albergo, Nicholas M Boffi, and Eric Vanden-Eijnden. Stochastic interpolants: A unifying framework for flows and diffusions.arXiv preprint arXiv:2303.08797, 2023. (pages 2, 3, 10, 29, and 36)
work page internal anchor Pith review arXiv 2023
-
[3]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P. Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-Based Generative Modeling through Stochastic Differential Equations.arXiv:2011.13456 [cs, stat], February 2021. arXiv: 2011.13456. (pages 2 and 10)
work page internal anchor Pith review arXiv 2011
-
[4]
High-Resolution Image Synthesis with Latent Diffusion Models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨ orn Ommer. High-Resolution Image Synthesis with Latent Diffusion Models. Technical Report arXiv:2112.10752, arXiv, April 2022. arXiv:2112.10752 [cs] type: article. (page 2)
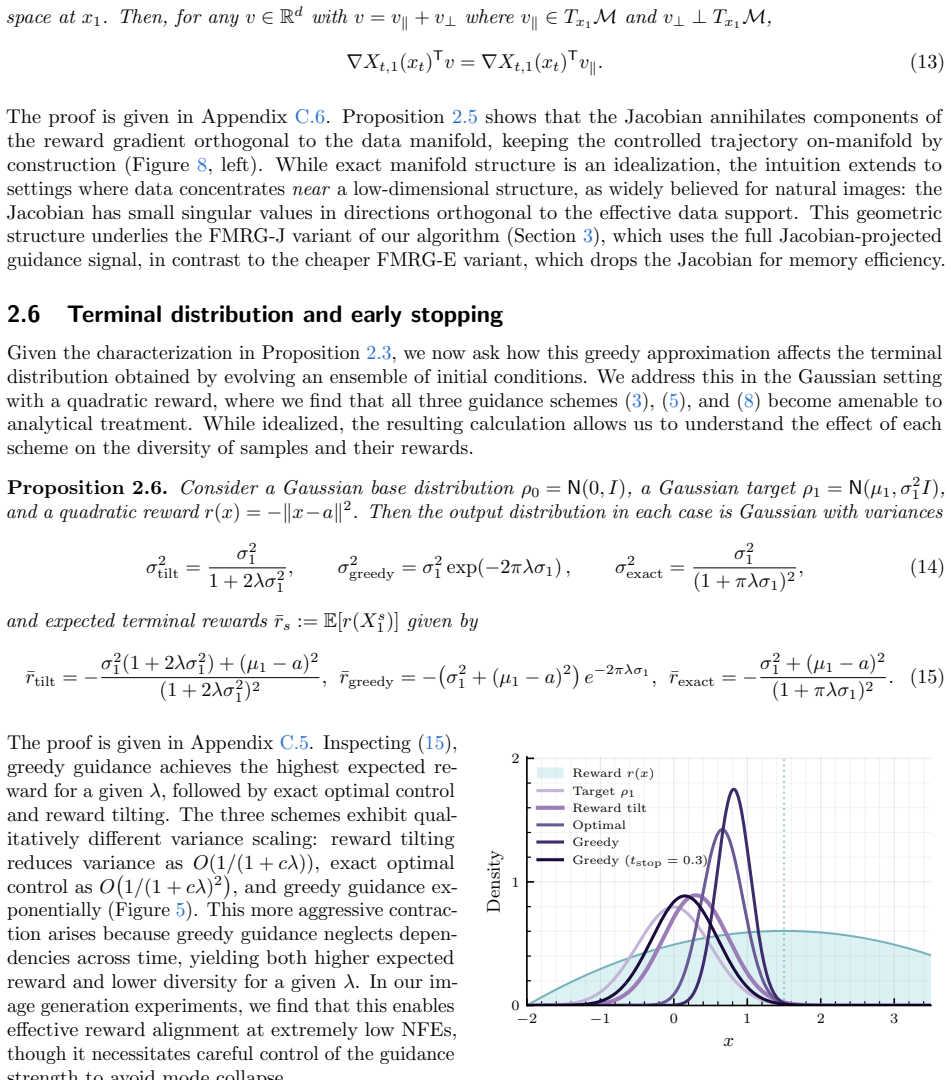
work page internal anchor Pith review arXiv 2022
-
[5]
Align Your Latents: High-Resolution Video Synthesis With Latent Diffusion Models
Andreas Blattmann, Robin Rombach, Huan Ling, Tim Dockhorn, Seung Wook Kim, Sanja Fidler, and Karsten Kreis. Align Your Latents: High-Resolution Video Synthesis With Latent Diffusion Models. pages 22563–22575, 2023. (page 2)
2023
-
[6]
Watson, David Juergens, Nathaniel R
Joseph L. Watson, David Juergens, Nathaniel R. Bennett, Brian L. Trippe, Jason Yim, Helen E. Eisenach, Woody Ahern, Andrew J. Borst, Robert J. Ragotte, Lukas F. Milles, Basile I. M. Wicky, Nikita Hanikel, Samuel J. Pellock, Alexis Courbet, William Sheffler, Jue Wang, Preetham Venkatesh, Isaac Sappington, Susana V´ azquez Torres, Anna Lauko, Valentin De Bo...
2023
- [7]
-
[8]
arXiv preprint arXiv:2410.00083 , year=
Giannis Daras, Hyungjin Chung, Chieh-Hsin Lai, Yuki Mitsufuji, Jong Chul Ye, Peyman Milanfar, Alexandros G. Dimakis, and Mauricio Delbracio. A Survey on Diffusion Models for Inverse Problems, September 2024. arXiv:2410.00083 [cs]. (page 2)
-
[9]
Luhuan Wu, Brian L. Trippe, Christian A. Naesseth, David M. Blei, and John P. Cunningham. Practical and Asymptotically Exact Conditional Sampling in Diffusion Models, June 2023. arXiv:2306.17775 [cs, q-bio, stat]. (pages 2, 4, and 10)
-
[10]
A General Framework for Inference-time Scaling and Steering of Diffusion Models, July
Raghav Singhal, Zachary Horvitz, Ryan Teehan, Mengye Ren, Zhou Yu, Kathleen McKeown, and Rajesh Ranganath. A General Framework for Inference-time Scaling and Steering of Diffusion Models, July
-
[11]
arXiv preprint arXiv:2501.06848 (2025)
arXiv:2501.06848 [cs]. (pages 2, 43, and 44) 16
-
[12]
Carles Domingo-Enrich, Michal Drozdzal, Brian Karrer, and Ricky T. Q. Chen. Adjoint Matching: Fine-tuning Flow and Diffusion Generative Models with Memoryless Stochastic Optimal Control, January
-
[13]
arXiv:2409.08861 [cs]. (pages 2, 3, 4, 10, and 22)
-
[14]
Albergo, Carles Domingo-Enrich, Nicholas M
Amirmojtaba Sabour, Michael S. Albergo, Carles Domingo-Enrich, Nicholas M. Boffi, Sanja Fidler, Karsten Kreis, and Eric Vanden-Eijnden. Test-time scaling of diffusions with flow maps, November 2025. arXiv:2511.22688 [cs]. (pages 2 and 10)
-
[15]
Masatoshi Uehara, Yulai Zhao, Chenyu Wang, Xiner Li, Aviv Regev, Sergey Levine, and Tommaso Biancalani. Inference-Time Alignment in Diffusion Models with Reward-Guided Generation: Tutorial and Review, January 2025. arXiv:2501.09685 [cs]. (pages 2, 4, and 10)
-
[16]
Steering diffusion models with quadratic rewards: a fine-grained analysis, February 2026
Ankur Moitra, Andrej Risteski, and Dhruv Rohatgi. Steering diffusion models with quadratic rewards: a fine-grained analysis, February 2026. arXiv:2602.16570 [cs]. (pages 2 and 6)
-
[17]
Sequential Monte Carlo samplers.Journal of the Royal Statistical Society: Series B (Statistical Methodology), 68(3):411–436, 2006
Pierre Del Moral, Arnaud Doucet, and Ajay Jasra. Sequential Monte Carlo samplers.Journal of the Royal Statistical Society: Series B (Statistical Methodology), 68(3):411–436, 2006. (page 2)
2006
-
[18]
Diffusion Posterior Sampling for General Noisy Inverse Problems
Hyungjin Chung, Jeongsol Kim, Michael T. Mccann, Marc L. Klasky, and Jong Chul Ye. Diffusion Posterior Sampling for General Noisy Inverse Problems, May 2024. arXiv:2209.14687 [stat]. (pages 2, 6, 10, 11, and 35)
work page internal anchor Pith review arXiv 2024
-
[19]
Masatoshi Uehara, Yulai Zhao, Kevin Black, Ehsan Hajiramezanali, Gabriele Scalia, Nathaniel Lee Diamant, Alex M. Tseng, Tommaso Biancalani, and Sergey Levine. Fine-Tuning of Continuous-Time Diffusion Models as Entropy-Regularized Control, February 2024. arXiv:2402.15194 [cs, stat]. (pages 2, 3, 4, and 10)
-
[20]
Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas M¨ uller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, Dustin Podell, Tim Dockhorn, Zion English, Kyle Lacey, Alex Goodwin, Yannik Marek, and Robin Rombach. Scaling Rectified Flow Transformers for High-Resolution Image Synthesis, March 2024. arXiv:2403.03206 [cs]....
work page internal anchor Pith review arXiv 2024
-
[21]
FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dockhorn, Jack English, Zion English, Patrick Esser, Sumith Kulal, Kyle Lacey, Yam Levi, Cheng Li, Dominik Lorenz, Jonas M¨ uller, Dustin Podell, Robin Rombach, Harry Saini, Axel Sauer, and Luke Smith. FLUX.1 Kontext: Flow Matching for In-Context Imag...
work page internal anchor Pith review arXiv 2025
-
[22]
Boffi, Michael S
Nicholas M. Boffi, Michael S. Albergo, and Eric Vanden-Eijnden. How to build a consistency model: Learning flow maps via self-distillation, May 2025. (pages 2, 3, 10, 11, 21, and 39)
2025
-
[23]
Nicholas M. Boffi, Michael S. Albergo, and Eric Vanden-Eijnden. Flow map matching with stochastic interpolants: A mathematical framework for consistency models, June 2025. arXiv:2406.07507 [cs]. (pages 2, 3, 10, and 21)
-
[24]
Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. Consistency Models, May 2023. arXiv:2303.01469 [cs, stat]. (pages 2, 4, and 10)
work page internal anchor Pith review arXiv 2023
-
[25]
Mean Flows for One-step Generative Modeling
Zhengyang Geng, Mingyang Deng, Xingjian Bai, J. Zico Kolter, and Kaiming He. Mean Flows for One-step Generative Modeling, May 2025. arXiv:2505.13447 [cs]. (pages 2, 4, 10, and 21)
work page internal anchor Pith review arXiv 2025
-
[26]
Consistency Trajectory Models: Learning Probability Flow ODE Trajectory of Diffusion, March 2024
Dongjun Kim, Chieh-Hsin Lai, Wei-Hsiang Liao, Naoki Murata, Yuhta Takida, Toshimitsu Uesaka, Yutong He, Yuki Mitsufuji, and Stefano Ermon. Consistency Trajectory Models: Learning Probability Flow ODE Trajectory of Diffusion, March 2024. arXiv:2310.02279 [cs, stat]. (pages 2, 4, and 10) 17
- [27]
-
[28]
Masatoshi Uehara, Yulai Zhao, Tommaso Biancalani, and Sergey Levine. Understanding Reinforcement Learning-Based Fine-Tuning of Diffusion Models: A Tutorial and Review, July 2024. arXiv:2407.13734 [cs]. (pages 3 and 10)
-
[30]
Zhengyang Geng, Ashwini Pokle, William Luo, Justin Lin, and J. Zico Kolter. Consistency Models Made Easy, October 2024. arXiv:2406.14548 [cs]. (pages 4 and 10)
-
[31]
Bidirectional Consistency Models, September 2024
Liangchen Li and Jiajun He. Bidirectional Consistency Models, September 2024. arXiv:2403.18035 [cs]. (page 4)
-
[32]
Simplifying, Stabilizing and Scaling Continuous-Time Consistency Models
Cheng Lu and Yang Song. Simplifying, Stabilizing and Scaling Continuous-Time Consistency Models, October 2024. arXiv:2410.11081 [cs] version: 1. (page 4)
work page internal anchor Pith review arXiv 2024
-
[33]
Improved Mean Flows: On the Challenges of Fastforward Generative Models
Zhengyang Geng, Yiyang Lu, Zongze Wu, Eli Shechtman, J. Zico Kolter, and Kaiming He. Improved Mean Flows: On the Challenges of Fastforward Generative Models, December 2025. arXiv:2512.02012 [cs]. (pages 4 and 10)
work page internal anchor Pith review arXiv 2025
-
[34]
One step diffusion via shortcut models.arXiv preprint arXiv:2410.12557, 2024
Kevin Frans, Danijar Hafner, Sergey Levine, and Pieter Abbeel. One Step Diffusion via Shortcut Models, October 2024. arXiv:2410.12557 [cs]. (pages 4 and 10)
-
[35]
Terminal Velocity Matching, November
Linqi Zhou, Mathias Parger, Ayaan Haque, and Jiaming Song. Terminal Velocity Matching, November
- [36]
-
[37]
A Taxonomy of Loss Functions for Stochastic Optimal Control, October 2024
Carles Domingo-Enrich. A Taxonomy of Loss Functions for Stochastic Optimal Control, October 2024. arXiv:2410.00345 [cs]. (page 4)
-
[38]
Variational and optimal control representations of conditioned and driven processes.Journal of Statistical Mechanics: Theory and Experiment, 2015(12):P12001, December 2015
Rapha¨ el Chetrite and Hugo Touchette. Variational and optimal control representations of conditioned and driven processes.Journal of Statistical Mechanics: Theory and Experiment, 2015(12):P12001, December 2015. (page 4)
2015
-
[39]
Springer, New York, NY, 1975
Wendell Fleming and Raymond Rishel.Deterministic and Stochastic Optimal Control. Springer, New York, NY, 1975. (pages 4, 24, and 25)
1975
-
[40]
Birkh¨ auser, Boston, MA, 1997
Martino Bardi and Italo Capuzzo-Dolcetta.Optimal Control and Viscosity Solutions of Hamilton-Jacobi- Bellman Equations. Birkh¨ auser, Boston, MA, 1997. (pages 5 and 31)
1997
-
[41]
FlowDPS: Flow-Driven Posterior Sampling for Inverse Problems, March 2025
Jeongsol Kim, Bryan Sangwoo Kim, and Jong Chul Ye. FlowDPS: Flow-Driven Posterior Sampling for Inverse Problems, March 2025. arXiv:2503.08136 [cs]. (pages 6, 8, 10, 11, and 36)
-
[42]
Metaxas, and Yezhou Yang
Maitreya Patel, Song Wen, Dimitris N. Metaxas, and Yezhou Yang. FlowChef: Steering Rectified Flow Models for Controlled Generation. 2025. (pages 6, 8, 10, 11, and 37)
2025
-
[43]
Manifold preserv- ing guided diffusion.arXiv preprint arXiv:2311.16424, 2023
Yutong He, Naoki Murata, Chieh-Hsin Lai, Yuhta Takida, Toshimitsu Uesaka, Dongjun Kim, Wei-Hsiang Liao, Yuki Mitsufuji, J. Zico Kolter, Ruslan Salakhutdinov, and Stefano Ermon. Manifold Preserving Guided Diffusion, November 2023. arXiv:2311.16424 [cs]. (pages 6, 8, 10, 12, 38, and 41)
-
[44]
ReNO: Enhancing One-step Text-to-Image Models through Reward-based Noise Optimization, October 2024
Luca Eyring, Shyamgopal Karthik, Karsten Roth, Alexey Dosovitskiy, and Zeynep Akata. ReNO: Enhancing One-step Text-to-Image Models through Reward-based Noise Optimization, October 2024. arXiv:2406.04312 [cs]. (pages 6, 8, 10, 13, 39, 42, and 44) 18
-
[45]
D-Flow: Differen- tiating through Flows for Controlled Generation, July 2024
Heli Ben-Hamu, Omri Puny, Itai Gat, Brian Karrer, Uriel Singer, and Yaron Lipman. D-Flow: Differen- tiating through Flows for Controlled Generation, July 2024. arXiv:2402.14017 [cs]. (pages 6, 10, and 39)
-
[46]
On the construction and comparison of difference schemes.SIAM Journal on Numerical Analysis, 5(3):506–517, 1968
Gilbert Strang. On the construction and comparison of difference schemes.SIAM Journal on Numerical Analysis, 5(3):506–517, 1968. (page 8)
1968
-
[47]
Litu Rout, Yujia Chen, Nataniel Ruiz, Abhishek Kumar, Constantine Caramanis, Sanjay Shakkottai, and Wen-Sheng Chu. RB-Modulation: Training-Free Personalization of Diffusion Models using Stochastic Optimal Control, May 2024. arXiv:2405.17401 [cs]. (pages 8 and 10)
-
[48]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow, September 2022. arXiv:2209.03003 [cs]. (page 10)
work page internal anchor Pith review arXiv 2022
-
[49]
Multistep Consistency Models, November 2024
Jonathan Heek, Emiel Hoogeboom, and Tim Salimans. Multistep Consistency Models, November 2024. arXiv:2403.06807 [cs]. (page 10)
-
[50]
Align your flow: Scaling continuous-time flow map distillation.arXiv preprint arXiv:2506.14603, 2025
Amirmojtaba Sabour, Sanja Fidler, and Karsten Kreis. Align Your Flow: Scaling Continuous-Time Flow Map Distillation, June 2025. arXiv:2506.14603 [cs]. (pages 10 and 21)
-
[51]
Yinuo Ren, Wenhao Gao, Lexing Ying, Grant M. Rotskoff, and Jiequn Han. DriftLite: Lightweight Drift Control for Inference-Time Scaling of Diffusion Models, September 2025. arXiv:2509.21655 [cs]. (page 10)
-
[52]
Diamond Maps: Efficient Reward Alignment via Stochastic Flow Maps
Peter Holderrieth, Douglas Chen, Luca Eyring, Ishin Shah, Giri Anantharaman, Yutong He, Zeynep Akata, Tommi Jaakkola, Nicholas Matthew Boffi, and Max Simchowitz. Diamond maps: Efficient reward alignment via stochastic flow maps, February 2026. arXiv:2602.05993 [cs]. (page 10)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[53]
Peter Potaptchik, Adhi Saravanan, Abbas Mammadov, Alvaro Prat, Michael S. Albergo, and Yee Whye Teh. Meta flow maps enable scalable reward alignment, January 2026. arXiv:2601.14430 [cs]. (page 10)
-
[54]
Training Diffusion Models with Reinforcement Learning
Kevin Black, Michael Janner, Yilun Du, Ilya Kos s, and Sergey Levine. Training Diffusion Models with Reinforcement Learning, January 2024. arXiv:2305.13301 [cs]. (page 10)
work page internal anchor Pith review arXiv 2024
-
[55]
DPOK: Reinforcement Learning for Fine- tuning Text-to-Image Diffusion Models, November 2023
Ying Fan, Olivia Watkins, Yuqing Du, Hao Liu, Moonkyung Ryu, Craig Boutilier, Pieter Abbeel, Mohammad Ghavamzadeh, Kangwook Lee, and Kimin Lee. DPOK: Reinforcement Learning for Fine- tuning Text-to-Image Diffusion Models, November 2023. arXiv:2305.16381 [cs]. (page 10)
-
[56]
FLUX.1 [dev]: A 12 billion parameter rectified flow transformer, 2024
Black Forest Labs. FLUX.1 [dev]: A 12 billion parameter rectified flow transformer, 2024. Model available on Hugging Face. (pages 11, 13, and 39)
2024
-
[57]
ImageReward: Learning and Evaluating Human Preferences for Text-to-Image Generation, December
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, and Yuxiao Dong. ImageReward: Learning and Evaluating Human Preferences for Text-to-Image Generation, December
- [58]
-
[59]
Xiaoshi Wu, Yiming Hao, Keqiang Sun, Yixiong Chen, Feng Zhu, Rui Zhao, and Hongsheng Li. Human Preference Score v2: A Complementary Metric for Evaluating Human Preferences in Vision-Language Tasks, 2023. arXiv:2306.09341. (page 13)
work page internal anchor Pith review arXiv 2023
-
[60]
Pick-a-Pic: An Open Dataset of User Preferences for Text-to-Image Generation
Yuval Kirstain, Adam Polyak, Uriel Singer, Shahbuland Matiana, Joe Penna, and Omer Levy. Pick-a-Pic: An Open Dataset of User Preferences for Text-to-Image Generation. InAdvances in Neural Information Processing Systems, 2023. (page 13)
2023
-
[61]
GenEval: An Object-Focused Framework for Evaluating Text-to-Image Alignment, 2023
Dhruba Ghosh, Hannaneh Hajishirzi, and Luke Zettlemoyer. GenEval: An Object-Focused Framework for Evaluating Text-to-Image Alignment, 2023. arXiv:2310.11513. (pages 13 and 42) 19
-
[62]
Xiaokun Wang, Peiyu Wang, Jiangbo Pei, Wei Shen, Yi Peng, Yunzhuo Hao, Weijie Qiu, Ai Jian, Tianyidan Xie, Xuchen Song, Yang Liu, and Yahui Zhou. Skywork-VL reward: An effective reward model for multimodal understanding and reasoning.arXiv preprint arXiv:2505.07263, 2025. (pages 13 and 45)
-
[63]
J. L. Doob. Conditional Brownian motion and the boundary limits of harmonic functions.Bulletin de la Soci´ et´ e Math´ ematique de France, 85:431–458, 1957. (page 22)
1957
-
[64]
Stargan v2: Diverse image synthesis for multiple domains
Yunjey Choi, Youngjung Uh, Jaejun Yoo, and Jung-Woo Ha. Stargan v2: Diverse image synthesis for multiple domains. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8188–8197, 2020. (page 40)
2020
-
[65]
A style-based generator architecture for generative adversarial networks
Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4401–4410, 2019. (page 40) 20 A Background on flow maps In this section, we provide some brief further background on flow maps. For complete details, ...
2019
-
[66]
TheSemigroup property:for all(s, u, t)∈[0,1] 3 and for allx∈R d, Xs,t(x) =X u,t(Xs,u(x)).(21)
-
[67]
TheLagrangian equation:for all(s, t)∈[0,1] 2 and for allx∈R d, ∂tXs,t(x) =b t(Xs,t(x)).(22)
-
[68]
On the diagonal s = t, the Lagrangian equation implies vt,t(x) =b t(x),(25) i.e., the parameterized velocity recovers the probability flow drift
TheEulerian equation:for all(s, t)∈[0,1] 2 and for allx∈R d, ∂sXs,t(x) +∇X s,t(x)b s(x) = 0.(23) Following recent work on accelerated sampling [20, 23, 47], we parameterize the flow map as Xs,t(x) =x+ (t−s)v s,t(x),(24) where v : [0, 1]2 ×R d →R d is a learned velocity function. On the diagonal s = t, the Lagrangian equation implies vt,t(x) =b t(x),(25) i...
-
[69]
is pt =∇X u t,1(xu t )Tp1 =−∇X u t,1(xu t )T∇r(xu 1).(52) Substituting into the optimality conditionu ∗ t =−λ(t)p ∗ t yields the optimal control u∗ t =λ(t)∇X u t,1(xu t )T∇r(xu 1).(53) This completes the proof. C.3 HJB characterization and small-λexpansion By Bellman’s principle of optimality, the value function (38) satisfies the Hamilton–Jacobi–Bellman ...
-
[70]
to the control u, we compute the first-order expansion of the terminal pointx u 1 inδt. Applying Lemma C.5 with (s, t)→(t,1) and using thatuvanishes outside [t, t+δt], X u t,1(xt) =X t,1(xt) + Z t+δt t ∇Xτ,1(xu τ )u τ(xu τ )dτ.(77) The integrand is continuous in τ and equals ∇Xt,1(xt) ut at τ = t, since the controlled trajectory satisfies xu t =x t at the...
-
[71]
=r(X t,1(xt)) +∇r(X t,1(xt))T∇Xt,1(xt)u t δt+o(δt).(79) Substituting into the objective (11) and retaining leading-order terms inδt, min ut ∥ut∥2 2λt − ∇r(Xt,1(xt))T∇Xt,1(xt)u t.(80) This is a convex quadratic inu t, and setting its gradient to zero gives the optimal control u∗ t =λ t ∇Xt,1(xt)T∇r(Xt,1(xt)),(81) which completes the proof. C.5 Gaussian cas...
-
[72]
The Jacobian is∇X t,1(x) =M t, which is state-independent. Proof.The probability flow velocity is given by [2], bt(x) =µ 1 + ˙Ct 2Ct (x−tµ 1),(87) ˙Ct =−2(1−t) + 2tσ 2 1.(88) To find the flow map, we solve ˙xτ = bτ(xτ) from time t to time 1. Substituting yτ := xτ −τ µ 1 gives the linear ODE ˙yτ = ˙Cτ 2Cτ yτ, with solution yτ =y t exp Z τ t ˙Cs 2Cs ds ! =y...
-
[73]
As s ranges over [0, 1], z ranges over [0,∞ ), and Z 1 0 σ2 1 Cs ds=σ 2 1 Z ∞ 0 dz 1 +σ 2 1z2 =σ 1 arctan(σ1z) ∞ 0 = πσ1 2 .(96) Using (95) and (96), we obtain y1 = σ1 e−πλσ1 y0
For the second, the substitution z := s/(1 −s ) gives ds = dz/(1 + z)2 and Cs = (1 + σ2 1z2)/(1 + z)2, so that σ2 1 ds/Cs = σ2 1 dz/(1 + σ2 1z2). As s ranges over [0, 1], z ranges over [0,∞ ), and Z 1 0 σ2 1 Cs ds=σ 2 1 Z ∞ 0 dz 1 +σ 2 1z2 =σ 1 arctan(σ1z) ∞ 0 = πσ1 2 .(96) Using (95) and (96), we obtain y1 = σ1 e−πλσ1 y0. Since x0 ∼ N(0, 1) and xM 0 = ( ...
-
[74]
together with q0 = 1 2σ2 1 + λ·π/ (2σ1) = 1+πλσ1 2σ2 1 (the integral R 1 0 dτ /Cτ = π/(2σ1) is (96) divided by σ2
-
[75]
Since x0 ∼N(0,1) andx OC 0 =x M 0 = (a−µ 1)/σ1 by Proposition C.11, we havey 0 ∼N −(a−µ 1)/σ1,1 , so y1 ∼N µ1 −a 1 +πλσ 1 , σ2 1 (1 +πλσ 1)2 .(109) Sincex 1 =a+y 1, we obtain (106)
yields (108). Since x0 ∼N(0,1) andx OC 0 =x M 0 = (a−µ 1)/σ1 by Proposition C.11, we havey 0 ∼N −(a−µ 1)/σ1,1 , so y1 ∼N µ1 −a 1 +πλσ 1 , σ2 1 (1 +πλσ 1)2 .(109) Sincex 1 =a+y 1, we obtain (106). C.5.4 Comparison of guidance schemes We now compare the three guidance schemes using the closed-form terminal distributions established above. With the means and...
-
[76]
+ (µ1 −a) 2 (1 + 2λσ2 1)2 , E[r(Xgreedy 1 )] =− σ2 1 + (µ1 −a) 2 e−2πλσ1 , E[r(Xexact 1 )] =− σ2 1 + (µ1 −a) 2 (1 +πλσ 1)2 . (110) Proof.For any GaussianX∼N(µ, σ 2), the quadratic rewardr(x) =−(x−a) 2 has expectation E[r(X)] =− Var(X) + (E[X]−a) 2 =− σ2 + (µ−a) 2 .(111) Applying this identity to the closed-form means and variances from (82), (92) and (106...
-
[77]
shortcut
+ (µ1 −a) 2 (1 + 2λσ2 1)2 ∼ − 1 λ , Greedy:E[r(X greedy 1 )] =−(σ 2 1 + (µ1 −a) 2)e−2πλσ1 ∼ −e −2πλσ1 , Exact OC:E[r(X exact 1 )] =− σ2 1 + (µ1 −a) 2 (1 +πλσ 1)2 ∼ − 1 λ2 , (114) where the asymptotics hold as λ→ ∞ . Greedy guidance achieves exponentially higher reward (closer to zero) compared to the polynomial rates for exact optimal control and reward t...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.