Recognition: unknown
LaST-R1: Reinforcing Robotic Manipulation via Adaptive Physical Latent Reasoning
Pith reviewed 2026-05-08 02:55 UTC · model grok-4.3
The pith
LaST-R1 uses reinforcement learning to jointly optimize latent Chain-of-Thought reasoning and actions for robotic manipulation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
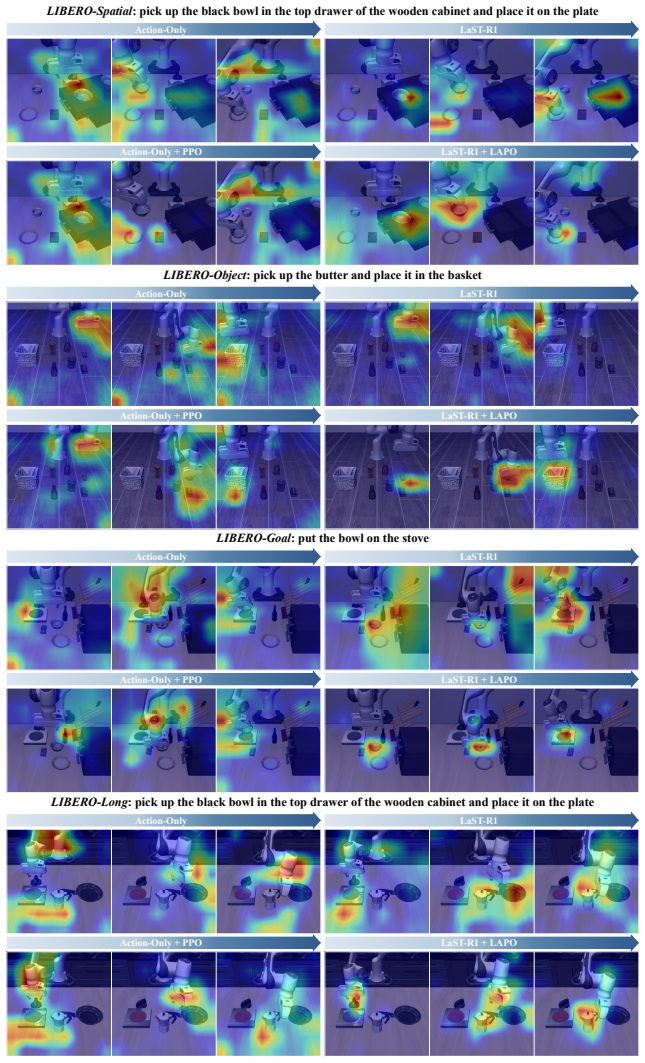
By embedding latent Chain-of-Thought reasoning directly inside the RL optimization loop via the LAPO algorithm and adding an adaptive horizon mechanism, the policy learns to model physical dynamics more robustly, enabling near-perfect simulated success and measurable real-world gains over supervised fine-tuning baselines.
What carries the argument
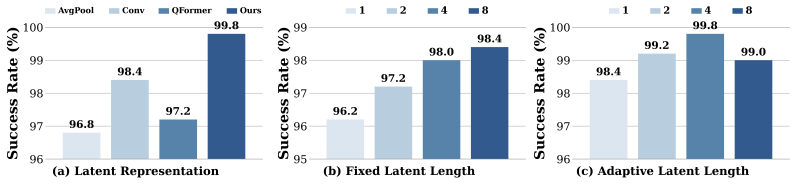
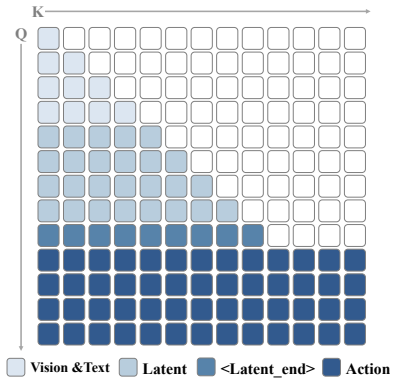
Latent-to-Action Policy Optimization (LAPO) jointly optimizes the latent reasoning process and action generation while an adaptive latent CoT mechanism dynamically adjusts the reasoning horizon based on environment state.
If this is right
- Robotic policies can reach high success rates with only one-shot supervised initialization followed by RL fine-tuning.
- Adaptive reasoning length improves handling of diverse environment states without manual tuning per task.
- The same latent-reasoning RL loop transfers from simulation to real single-arm and dual-arm settings.
- Explicit embedding of reasoning steps inside the policy gradient update strengthens generalization over pure imitation methods.
Where Pith is reading between the lines
- The method may reduce the data needed for new manipulation skills if latent reasoning transfers across related tasks.
- Future extensions could test whether the same adaptive CoT approach improves performance in partially observable or long-horizon tasks beyond the four evaluated.
Load-bearing premise
Jointly optimizing latent reasoning and action generation through LAPO will reliably produce stable, non-overfit physical world models without extra post-training adjustments.
What would settle it
A controlled experiment showing that removing the latent reasoning component or fixing the CoT horizon length eliminates the reported gains on LIBERO or real-robot tasks.
Figures










read the original abstract
Robotic foundation models require reasoning over complex visual scenes to execute adaptive actions in dynamic environments. While recent studies on latent-reasoning Vision-Language-Action (VLA) models have demonstrated the capability to capture fine-grained physical dynamics, they remain predominantly confined to static imitation learning, severely limiting their adaptability and generalization. In this paper, we present LaST-R1, a novel reinforcement learning (RL) post-training framework designed to effectively harness "latent reasoning-before-acting" policies. Specifically, we propose Latent-to-Action Policy Optimization (LAPO), a core RL algorithm that jointly optimizes the latent reasoning process and the action generation. By explicitly embedding latent Chain-of-Thought (CoT) reasoning directly within the RL optimization loop, LAPO stimulates profound physical world modeling, which in turn drives robust execution in interactive environments. Furthermore, an adaptive latent CoT mechanism is introduced, allowing the policy to dynamically modulate its reasoning horizon based on diverse environment states. Experiments show that LaST-R1 achieves a near-perfect 99.9% average success rate on the LIBERO benchmark with only one-shot supervised warm-up, significantly improving convergence speed and performance over prior state-of-the-art (SOTA) methods. In real-world deployments, LaST-R1 yields up to a 22.5% average improvement over SOTA supervised fine-tuning approach across four complex tasks, including both single-arm and dual-arm settings. Finally, LaST-R1 demonstrates strong generalization across simulated and real-world environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LaST-R1, a reinforcement learning post-training framework for Vision-Language-Action (VLA) robotic models. It proposes Latent-to-Action Policy Optimization (LAPO) to jointly optimize embedded latent Chain-of-Thought reasoning and action generation within the RL loop, along with an adaptive mechanism to dynamically adjust the latent CoT horizon based on environment states. Central claims include achieving a 99.9% average success rate on the LIBERO benchmark after only one-shot supervised warm-up (outperforming prior SOTA in convergence and performance) and up to 22.5% average improvement over supervised fine-tuning baselines in real-world single-arm and dual-arm tasks, with strong sim-to-real generalization.
Significance. If the empirical results hold under rigorous validation, this work would advance the field by showing how RL can be used to elicit robust physical world modeling from latent reasoning in VLA policies, moving beyond static imitation learning. The explicit embedding of CoT into the optimization objective and the adaptive horizon are potentially impactful for improving adaptability in dynamic manipulation tasks.
major comments (3)
- [§4 (Experiments)] §4 (Experiments), LIBERO results: the 99.9% average success rate is presented without reported standard deviations, number of evaluation seeds, or statistical significance tests against baselines; this is load-bearing for the claim of significant improvement in convergence speed and performance over prior SOTA.
- [§3.2 (LAPO)] §3.2 (LAPO formulation): the joint optimization of latent reasoning and action generation is described at a high level but lacks any analysis of training stability, potential for latent space collapse, or sensitivity to the adaptive CoT horizon length; this directly underpins the central assumption that LAPO produces reliable physical modeling without instability or overfitting.
- [§4.3 (Real-world)] §4.3 (Real-world deployments): the 22.5% average improvement across four tasks is stated without specifying per-task success criteria, number of trials, or variance; this is necessary to evaluate the sim-to-real transfer claim and rule out selection effects.
minor comments (2)
- [Abstract] The abstract and §3 introduce LAPO and adaptive CoT but could expand the first-use definition of 'one-shot supervised warm-up' to clarify the exact number of demonstrations used.
- [§4] Add a dedicated ablation subsection or table isolating the contribution of the adaptive horizon versus fixed CoT to strengthen attribution of gains.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will incorporate revisions to strengthen the experimental reporting and analysis.
read point-by-point responses
-
Referee: [§4 (Experiments)] §4 (Experiments), LIBERO results: the 99.9% average success rate is presented without reported standard deviations, number of evaluation seeds, or statistical significance tests against baselines; this is load-bearing for the claim of significant improvement in convergence speed and performance over prior SOTA.
Authors: We agree that standard deviations, the number of evaluation seeds, and statistical significance tests are necessary to rigorously support the performance claims. In the revised manuscript, we will report results from multiple evaluation seeds with standard deviations and include statistical tests comparing LaST-R1 to prior SOTA baselines. revision: yes
-
Referee: [§3.2 (LAPO)] §3.2 (LAPO formulation): the joint optimization of latent reasoning and action generation is described at a high level but lacks any analysis of training stability, potential for latent space collapse, or sensitivity to the adaptive CoT horizon length; this directly underpins the central assumption that LAPO produces reliable physical modeling without instability or overfitting.
Authors: We acknowledge the value of explicit analysis on these aspects. The revised manuscript will include additional experiments and discussion on training stability (via loss and reward curves), monitoring for latent space collapse, and ablations on CoT horizon sensitivity to demonstrate that LAPO yields stable and reliable physical modeling. revision: yes
-
Referee: [§4.3 (Real-world)] §4.3 (Real-world deployments): the 22.5% average improvement across four tasks is stated without specifying per-task success criteria, number of trials, or variance; this is necessary to evaluate the sim-to-real transfer claim and rule out selection effects.
Authors: We agree that per-task success criteria, trial counts, and variance measures are required for full transparency. The revision will expand §4.3 with a detailed table or description specifying success definitions, number of trials per task, and performance variance for each of the four real-world tasks. revision: yes
Circularity Check
No significant circularity; claims rest on empirical benchmarks
full rationale
The paper introduces LaST-R1 and LAPO as an RL post-training framework that embeds latent CoT reasoning into the optimization loop, with an adaptive horizon mechanism. However, the provided text (abstract and description) contains no equations, derivations, or first-principles predictions. Central claims of 99.9% LIBERO success and 22.5% real-world gains are presented as experimental outcomes after one-shot warm-up, not as results forced by self-definition, fitted parameters renamed as predictions, or self-citation chains. No load-bearing step reduces to its own inputs by construction; the work is self-contained as standard empirical RL robotics research.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Prismatic vlms: Inves- tigating the design space of visually-conditioned language models
Siddharth Karamcheti, Suraj Nair, Ashwin Balakrishna, Percy Liang, Thomas Kollar, and Dorsa Sadigh. Prismatic vlms: Investigating the design space of visually-conditioned language models. arXiv preprint arXiv:2402.07865, 2024
-
[2]
Qwen3-vl technical report, 2025
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
2025
-
[3]
PaliGemma: A versatile 3B VLM for transfer
Lucas Beyer, Andreas Steiner, André Susano Pinto, Alexander Kolesnikov, Xiao Wang, Daniel Salz, Maxim Neumann, Ibrahim Alabdulmohsin, Michael Tschannen, Emanuele Bugliarello, et al. Paligemma: A versatile 3b vlm for transfer.arXiv preprint arXiv:2407.07726, 2024
work page internal anchor Pith review arXiv 2024
-
[4]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review arXiv 2024
-
[5]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Moo Jin Kim, Chelsea Finn, and Percy Liang. Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645, 2025
work page internal anchor Pith review arXiv 2025
-
[6]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. π_0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review arXiv 2024
-
[7]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al. π_0.5: a vision- language-action model with open-world generalization.arXiv preprint arXiv:2504.16054, 2025
work page internal anchor Pith review arXiv 2025
-
[8]
Jiaming Liu, Hao Chen, Pengju An, Zhuoyang Liu, Renrui Zhang, Chenyang Gu, Xiaoqi Li, Ziyu Guo, Sixiang Chen, Mengzhen Liu, et al. Hybridvla: Collaborative diffusion and autoregression in a unified vision-language-action model.arXiv preprint arXiv:2503.10631, 2025. 10
-
[9]
Hao Chen, Jiaming Liu, Chenyang Gu, Zhuoyang Liu, Renrui Zhang, Xiaoqi Li, Xiao He, Yandong Guo, Chi-Wing Fu, Shanghang Zhang, et al. Fast-in-slow: A dual-system foundation model unifying fast manipulation within slow reasoning.arXiv preprint arXiv:2506.01953, 2025
-
[10]
Qixiu Li, Yaobo Liang, Zeyu Wang, Lin Luo, Xi Chen, Mozheng Liao, Fangyun Wei, Yu Deng, Sicheng Xu, Yizhong Zhang, et al. Cogact: A foundational vision-language-action model for synergizing cognition and action in robotic manipulation.arXiv preprint arXiv:2411.19650, 2024
work page Pith review arXiv 2024
-
[11]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022
2022
-
[12]
Vla-r1: Enhancing reasoning in vision-language-action models.arXiv preprint arXiv:2510.01623, 2025
Angen Ye, Zeyu Zhang, Boyuan Wang, Xiaofeng Wang, Dapeng Zhang, and Zheng Zhu. Vla-r1: Enhancing reasoning in vision-language-action models.arXiv preprint arXiv:2510.01623, 2025
-
[13]
Chi-Pin Huang, Yueh-Hua Wu, Min-Hung Chen, Yu-Chiang Frank Wang, and Fu-En Yang. Thinkact: Vision-language-action reasoning via reinforced visual latent planning.arXiv preprint arXiv:2507.16815, 2025
-
[14]
Onetwovla: A unified vision-language-action model with adaptive reasoning
Fanqi Lin, Ruiqian Nai, Yingdong Hu, Jiacheng You, Junming Zhao, and Yang Gao. Onet- wovla: A unified vision-language-action model with adaptive reasoning.arXiv preprint arXiv:2505.11917, 2025
-
[15]
Robotic control via embodied chain-of-thought reasoning,
Michał Zawalski, William Chen, Karl Pertsch, Oier Mees, Chelsea Finn, and Sergey Levine. Robotic control via embodied chain-of-thought reasoning.arXiv preprint arXiv:2407.08693, 2024
-
[16]
Cot-vla: Visual chain-of-thought reasoning for vision-language-action models
Qingqing Zhao, Yao Lu, Moo Jin Kim, Zipeng Fu, Zhuoyang Zhang, Yecheng Wu, Zhaoshuo Li, Qianli Ma, Song Han, Chelsea Finn, et al. Cot-vla: Visual chain-of-thought reasoning for vision-language-action models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 1702–1713, 2025
2025
-
[17]
Chenyang Gu, Jiaming Liu, Hao Chen, Runzhong Huang, Qingpo Wuwu, Zhuoyang Liu, Xiaoqi Li, Ying Li, Renrui Zhang, Peng Jia, et al. Manualvla: A unified vla model for chain-of-thought manual generation and robotic manipulation.arXiv preprint arXiv:2512.02013, 2025
-
[18]
Zhuoyang Liu, Jiaming Liu, Jiadong Xu, Nuowei Han, Chenyang Gu, Hao Chen, Kaichen Zhou, Renrui Zhang, Kai Chin Hsieh, Kun Wu, et al. Mla: A multisensory language-action model for multimodal understanding and forecasting in robotic manipulation.arXiv preprint arXiv:2509.26642, 2025
-
[19]
WorldVLA: Towards Autoregressive Action World Model
Jun Cen, Chaohui Yu, Hangjie Yuan, Yuming Jiang, Siteng Huang, Jiayan Guo, Xin Li, Yibing Song, Hao Luo, Fan Wang, et al. Worldvla: Towards autoregressive action world model.arXiv preprint arXiv:2506.21539, 2025
work page internal anchor Pith review arXiv 2025
-
[20]
${\pi}_{0.7}$: a Steerable Generalist Robotic Foundation Model with Emergent Capabilities
Physical Intelligence, Bo Ai, Ali Amin, Raichelle Aniceto, Ashwin Balakrishna, Greg Balke, Kevin Black, George Bokinsky, Shihao Cao, Thomas Charbonnier, et al. pi0.7: a steerable gen- eralist robotic foundation model with emergent capabilities.arXiv preprint arXiv:2604.15483, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
Zhuoyang Liu, Jiaming Liu, Hao Chen, Jiale Yu, Ziyu Guo, Chengkai Hou, Chenyang Gu, Xiangju Mi, Renrui Zhang, Kun Wu, et al. Last _{0}: Latent spatio-temporal chain-of-thought for robotic vision-language-action model.arXiv preprint arXiv:2601.05248, 2026
-
[22]
Internvla-a1: Unifying understanding, generation and action for robotic manipulation, 2026
Junhao Cai, Zetao Cai, Jiafei Cao, Yilun Chen, Zeyu He, Lei Jiang, Hang Li, Hengjie Li, Yang Li, Yufei Liu, et al. Internvla-a1: Unifying understanding, generation and action for robotic manipulation.arXiv preprint arXiv:2601.02456, 2026
-
[23]
Kang Chen, Zhihao Liu, Tonghe Zhang, Zhen Guo, Si Xu, Hao Lin, Hongzhi Zang, Quanlu Zhang, Zhaofei Yu, Guoliang Fan, et al. πrl: Online rl fine-tuning for flow-based vision- language-action models.arXiv preprint arXiv:2510.25889, 2025. 11
-
[24]
Simplevla-rl: Scaling vla training via reinforcement learning.arXiv preprint arXiv:2509.09674, 2025
Haozhan Li, Yuxin Zuo, Jiale Yu, Yuhao Zhang, Zhaohui Yang, Kaiyan Zhang, Xuekai Zhu, Yuchen Zhang, Tianxing Chen, Ganqu Cui, et al. Simplevla-rl: Scaling vla training via reinforcement learning.arXiv preprint arXiv:2509.09674, 2025
-
[25]
Vla-rl: Towards masterful and general robotic manipulation with scalable reinforcement learning,
Guanxing Lu, Wenkai Guo, Chubin Zhang, Yuheng Zhou, Haonan Jiang, Zifeng Gao, Yansong Tang, and Ziwei Wang. Vla-rl: Towards masterful and general robotic manipulation with scalable reinforcement learning.arXiv preprint arXiv:2505.18719, 2025
-
[26]
Yuhui Chen, Shuai Tian, Shugao Liu, Yingting Zhou, Haoran Li, and Dongbin Zhao. Con- rft: A reinforced fine-tuning method for vla models via consistency policy.arXiv preprint arXiv:2502.05450, 2025
-
[27]
Qinwen Xu, Jiaming Liu, Rui Zhou, Shaojun Shi, Nuowei Han, Zhuoyang Liu, Chenyang Gu, Shuo Gu, Yang Yue, Gao Huang, et al. Twinrl-vla: Digital twin-driven reinforcement learning for real-world robotic manipulation.arXiv preprint arXiv:2602.09023, 2026
-
[28]
What can rl bring to vla generalization? an empirical study.arXiv preprint, arXiv:2505.19789, 2025
Jijia Liu, Feng Gao, Bingwen Wei, Xinlei Chen, Qingmin Liao, Yi Wu, Chao Yu, and Yu Wang. What can rl bring to vla generalization? an empirical study.arXiv preprint arXiv:2505.19789, 2025
-
[29]
Gr-rl: Going dexterous and precise for long-horizon robotic manipulation
Yunfei Li, Xiao Ma, Jiafeng Xu, Yu Cui, Zhongren Cui, Zhigang Han, Liqun Huang, Tao Kong, Yuxiao Liu, Hao Niu, et al. Gr-rl: Going dexterous and precise for long-horizon robotic manipulation.arXiv preprint arXiv:2512.01801, 2025
-
[30]
$\pi^{*}_{0.6}$: a VLA That Learns From Experience
Physical Intelligence, Ali Amin, Raichelle Aniceto, Ashwin Balakrishna, Kevin Black, Ken Conley, Grace Connors, James Darpinian, Karan Dhabalia, Jared DiCarlo, et al. π∗ 0.6: a vla that learns from experience.arXiv preprint arXiv:2511.14759, 2025
work page Pith review arXiv 2025
-
[31]
Oriane Siméoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, et al. Dinov3. arXiv preprint arXiv:2508.10104, 2025
work page internal anchor Pith review arXiv 2025
-
[32]
Open x- embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0
Abby O’Neill, Abdul Rehman, Abhiram Maddukuri, Abhishek Gupta, Abhishek Padalkar, Abraham Lee, Acorn Pooley, Agrim Gupta, Ajay Mandlekar, Ajinkya Jain, et al. Open x- embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6892–6903. IEEE, 2024
2024
-
[33]
Robomind: Benchmark on multi-embodiment intelligence normative data for robot manipulation,
Kun Wu, Chengkai Hou, Jiaming Liu, Zhengping Che, Xiaozhu Ju, Zhuqin Yang, Meng Li, Yinuo Zhao, Zhiyuan Xu, Guang Yang, et al. Robomind: Benchmark on multi-embodiment intelligence normative data for robot manipulation.arXiv preprint arXiv:2412.13877, 2024
-
[34]
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Alexander Khazatsky, Karl Pertsch, Suraj Nair, Ashwin Balakrishna, Sudeep Dasari, Siddharth Karamcheti, Soroush Nasiriany, Mohan Kumar Srirama, Lawrence Yunliang Chen, Kirsty Ellis, et al. Droid: A large-scale in-the-wild robot manipulation dataset.arXiv preprint arXiv:2403.12945, 2024
work page internal anchor Pith review arXiv 2024
-
[35]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review arXiv 2017
-
[36]
Hongzhi Zang, Mingjie Wei, Si Xu, Yongji Wu, Zhen Guo, Yuanqing Wang, Hao Lin, Liangzhi Shi, Yuqing Xie, Zhexuan Xu, et al. Rlinf-vla: A unified and efficient framework for vla+ rl training.arXiv preprint arXiv:2510.06710, 2025
-
[37]
Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
2023
- [38]
-
[39]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems, 36:53728–53741, 2023
2023
-
[40]
Tgrpo :fine- tuning vision-language-action model via trajectory-wise group relative policy optimization, 2025
Zengjue Chen, Runliang Niu, He Kong, Qi Wang, Qianli Xing, and Zipei Fan. Tgrpo :fine- tuning vision-language-action model via trajectory-wise group relative policy optimization, 2025
2025
-
[41]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review arXiv 2024
-
[42]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025
work page internal anchor Pith review arXiv 2025
-
[43]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InProceedings of the IEEE/CVF international conference on computer vision, pages 11975–11986, 2023
2023
-
[44]
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational conference on machine learning, pages 19730–19742. PMLR, 2023
2023
-
[45]
Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
2022
-
[46]
RDT-1B: a Diffusion Foundation Model for Bimanual Manipulation
Songming Liu, Lingxuan Wu, Bangguo Li, Hengkai Tan, Huayu Chen, Zhengyi Wang, Ke Xu, Hang Su, and Jun Zhu. Rdt-1b: a diffusion foundation model for bimanual manipulation.arXiv preprint arXiv:2410.07864, 2024
work page internal anchor Pith review arXiv 2024
-
[47]
Yulin Luo, Hao Chen, Zhuangzhe Wu, Bowen Sui, Jiaming Liu, Chenyang Gu, Zhuoyang Liu, Qiuxuan Feng, Jiale Yu, Shuo Gu, et al. Look before acting: Enhancing vision foundation representations for vision-language-action models.arXiv preprint arXiv:2603.15618, 2026
-
[48]
FAST: Efficient Action Tokenization for Vision-Language-Action Models
Karl Pertsch, Kyle Stachowicz, Brian Ichter, Danny Driess, Suraj Nair, Quan Vuong, Oier Mees, Chelsea Finn, and Sergey Levine. Fast: Efficient action tokenization for vision-language-action models.arXiv preprint arXiv:2501.09747, 2025
work page internal anchor Pith review arXiv 2025
-
[49]
arXiv preprint arXiv:2412.03293 , year=
Junjie Wen, Minjie Zhu, Yichen Zhu, Zhibin Tang, Jinming Li, Zhongyi Zhou, Chengmeng Li, Xiaoyu Liu, Yaxin Peng, Chaomin Shen, et al. Diffusion-vla: Generalizable and interpretable robot foundation model via self-generated reasoning.arXiv preprint arXiv:2412.03293, 2024
-
[50]
Songming Liu, Bangguo Li, Kai Ma, Lingxuan Wu, Hengkai Tan, Xiao Ouyang, Hang Su, and Jun Zhu. Rdt2: Exploring the scaling limit of umi data towards zero-shot cross-embodiment generalization.arXiv preprint arXiv:2602.03310, 2026
-
[51]
3D-VLA: A 3D Vision-Language-Action Generative World Model
Haoyu Zhen, Xiaowen Qiu, Peihao Chen, Jincheng Yang, Xin Yan, Yilun Du, Yining Hong, and Chuang Gan. 3d-vla: A 3d vision-language-action generative world model.arXiv preprint arXiv:2403.09631, 2024
work page internal anchor Pith review arXiv 2024
-
[52]
SpatialVLA: Exploring Spatial Representations for Visual-Language-Action Model
Delin Qu, Haoming Song, Qizhi Chen, Yuanqi Yao, Xinyi Ye, Yan Ding, Zhigang Wang, JiaYuan Gu, Bin Zhao, Dong Wang, et al. Spatialvla: Exploring spatial representations for visual-language-action model.arXiv preprint arXiv:2501.15830, 2025
work page internal anchor Pith review arXiv 2025
-
[53]
Xinghao Chen, Anhao Zhao, Heming Xia, Xuan Lu, Hanlin Wang, Yanjun Chen, Wei Zhang, Jian Wang, Wenjie Li, and Xiaoyu Shen. Reasoning beyond language: A comprehensive survey on latent chain-of-thought reasoning.arXiv preprint arXiv:2505.16782, 2025
-
[54]
Zeyuan Yang, Xueyang Yu, Delin Chen, Maohao Shen, and Chuang Gan. Machine men- tal imagery: Empower multimodal reasoning with latent visual tokens.arXiv preprint arXiv:2506.17218, 2025. 13
-
[55]
Latent Reasoning VLA: Latent Thinking and Prediction for Vision-Language-Action Models
Shuanghao Bai, Jing Lyu, Wanqi Zhou, Zhe Li, Dakai Wang, Lei Xing, Xiaoguang Zhao, Pengwei Wang, Zhongyuan Wang, Cheng Chi, et al. Latent reasoning vla: Latent thinking and prediction for vision-language-action models.arXiv preprint arXiv:2602.01166, 2026
work page internal anchor Pith review arXiv 2026
-
[56]
Interactive post-training for vision-language- action models, 2025
Shuhan Tan, Kairan Dou, Yue Zhao, and Philipp Krähenbühl. Interactive post-training for vision-language-action models.arXiv preprint arXiv:2505.17016, 2025
-
[57]
Hongyin Zhang, Zifeng Zhuang, Han Zhao, Pengxiang Ding, Hongchao Lu, and Donglin Wang. Reinbot: Amplifying robot visual-language manipulation with reinforcement learning.arXiv preprint arXiv:2505.07395, 2025
-
[58]
Mingjie Pan, Siyuan Feng, Qinglin Zhang, Xinchen Li, Jianheng Song, Chendi Qu, Yi Wang, Chuankang Li, Ziyu Xiong, Zhi Chen, et al. Sop: A scalable online post-training system for vision-language-action models.arXiv preprint arXiv:2601.03044, 2026
-
[59]
Bridge data: Boosting generalization of robotic skills with cross-domain datasets
Frederik Ebert, Yanlai Yang, Karl Schmeckpeper, Bernadette Bucher, Georgios Georgakis, Kostas Daniilidis, Chelsea Finn, and Sergey Levine. Bridge data: Boosting generalization of robotic skills with cross-domain datasets. InRSS, 2022
2022
-
[60]
Bridgedata v2: A dataset for robot learning at scale, 2023
Homer Walke, Kevin Black, Abraham Lee, Moo Jin Kim, Max Du, Chongyi Zheng, Tony Zhao, Philippe Hansen-Estruch, Quan Vuong, Andre He, Vivek Myers, Kuan Fang, Chelsea Finn, and Sergey Levine. Bridgedata v2: A dataset for robot learning at scale, 2023
2023
-
[61]
From play to policy: Conditional behavior genera- tion from uncurated robot data
Zichen Jeff Cui, Yibin Wang, Nur Muhammad Mahi Shafiullah, and Lerrel Pinto. From play to policy: Conditional behavior generation from uncurated robot data.arXiv preprint arXiv:2210.10047, 2022
-
[62]
Qt-opt: Scalable deep reinforcement learning for vision-based robotic manipulation, 2018
Dmitry Kalashnikov, Alex Irpan, Peter Pastor, Julian Ibarz, Alexander Herzog, Eric Jang, Deirdre Quillen, Ethan Holly, Mrinal Kalakrishnan, Vincent Vanhoucke, et al. QT-Opt: Scalable deep reinforcement learning for vision-based robotic manipulation.arXiv preprint arXiv:1806.10293, 2018
-
[63]
Hydra: Hybrid robot actions for imitation learning.arxiv, 2023
Suneel Belkhale, Yuchen Cui, and Dorsa Sadigh. Hydra: Hybrid robot actions for imitation learning.arxiv, 2023
2023
-
[64]
RT-1: Robotics Transformer for Real-World Control at Scale
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, Julian Ibarz, et al. Rt-1: Robotics transformer for real-world control at scale. InarXiv preprint arXiv:2212.06817, 2022
work page internal anchor Pith review arXiv 2022
-
[65]
Robonet: Large-scale multi-robot learning
Sudeep Dasari, Frederik Ebert, Stephen Tian, Suraj Nair, Bernadette Bucher, Karl Schmeckpeper, Siddharth Singh, Sergey Levine, and Chelsea Finn. Robonet: Large-scale multi-robot learning. InConference on Robot Learning, pages 885–897. PMLR, 2020
2020
-
[66]
Shivin Dass, Jullian Yapeter, Jesse Zhang, Jiahui Zhang, Karl Pertsch, Stefanos Nikolaidis, and Joseph J. Lim. CLVR jaco play dataset, 2023
2023
-
[67]
Interactive language: Talking to robots in real time.IEEE Robotics and Automation Letters, 2023
Corey Lynch, Ayzaan Wahid, Jonathan Tompson, Tianli Ding, James Betker, Robert Baruch, Travis Armstrong, and Pete Florence. Interactive language: Talking to robots in real time.IEEE Robotics and Automation Letters, 2023
2023
-
[68]
On bringing robots home, 2023
Nur Muhammad Mahi Shafiullah, Anant Rai, Haritheja Etukuru, Yiqian Liu, Ishan Misra, Soumith Chintala, and Lerrel Pinto. On bringing robots home, 2023
2023
-
[69]
Bc-z: Zero-shot task generalization with robotic imitation learning
Eric Jang, Alex Irpan, Mohi Khansari, Daniel Kappler, Frederik Ebert, Corey Lynch, Sergey Levine, and Chelsea Finn. Bc-z: Zero-shot task generalization with robotic imitation learning. InConference on Robot Learning, pages 991–1002. PMLR, 2022
2022
-
[70]
Train offline, test online: A real robot learning benchmark, 2023
Gaoyue Zhou, Victoria Dean, Mohan Kumar Srirama, Aravind Rajeswaran, Jyothish Pari, Kyle Hatch, Aryan Jain, Tianhe Yu, Pieter Abbeel, Lerrel Pinto, Chelsea Finn, and Abhinav Gupta. Train offline, test online: A real robot learning benchmark, 2023
2023
-
[71]
Maniskill2: A unified benchmark for generalizable manipulation skills, 2023
Jiayuan Gu, Fanbo Xiang, Xuanlin Li, Zhan Ling, Xiqiang Liu, Tongzhou Mu, Yihe Tang, Stone Tao, Xinyue Wei, Yunchao Yao, Xiaodi Yuan, Pengwei Xie, Zhiao Huang, Rui Chen, and Hao Su. Maniskill2: A unified benchmark for generalizable manipulation skills, 2023. 14
2023
-
[72]
Minho Heo, Youngwoon Lee, Doohyun Lee, and Joseph J. Lim. Furniturebench: Reproducible real-world benchmark for long-horizon complex manipulation. InRobotics: Science and Systems, 2023
2023
-
[73]
X-embodiment u-tokyo pr2 datasets, 2023
Jihoon Oh, Naoaki Kanazawa, and Kento Kawaharazuka. X-embodiment u-tokyo pr2 datasets, 2023
2023
-
[74]
Robohive: A unified framework for robot learning
Vikash Kumar, Rutav Shah, Gaoyue Zhou, Vincent Moens, Vittorio Caggiano, Abhishek Gupta, and Aravind Rajeswaran. Robohive: A unified framework for robot learning. InThirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2023
2023
-
[75]
Weblab xarm dataset, 2023
Tatsuya Matsushima, Hiroki Furuta, Yusuke Iwasawa, and Yutaka Matsuo. Weblab xarm dataset, 2023
2023
-
[76]
FMB: A functional manipulation benchmark for generalizable robotic learning
Jianlan Luo, Charles Xu, Fangchen Liu, Liam Tan, Zipeng Lin, Jeffrey Wu, Pieter Abbeel, and Sergey Levine. FMB: A functional manipulation benchmark for generalizable robotic learning. https://functional-manipulation-benchmark.github.io, 2023
2023
-
[77]
Structured world models from human videos.CoRL, 2023
Russell Mendonca, Shikhar Bahl, and Deepak Pathak. Structured world models from human videos.CoRL, 2023
2023
-
[78]
La- tent plans for task agnostic offline reinforcement learning
Erick Rosete-Beas, Oier Mees, Gabriel Kalweit, Joschka Boedecker, and Wolfram Burgard. La- tent plans for task agnostic offline reinforcement learning. InProceedings of the 6th Conference on Robot Learning (CoRL), 2022
2022
-
[79]
Grounding language with visual af- fordances over unstructured data
Oier Mees, Jessica Borja-Diaz, and Wolfram Burgard. Grounding language with visual af- fordances over unstructured data. InProceedings of the IEEE International Conference on Robotics and Automation (ICRA), London, UK, 2023
2023
-
[80]
A guided reinforcement learning approach using shared control templates for learning manipulation skills in the real world
Abhishek Padalkar, Gabriel Quere, Antonin Raffin, João Silvério, and Freek Stulp. A guided reinforcement learning approach using shared control templates for learning manipulation skills in the real world. 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.