Recognition: unknown
Smart Ensemble Learning Framework for Predicting Groundwater Heavy Metal Pollution
Pith reviewed 2026-05-09 19:49 UTC · model grok-4.3
The pith
Gaussian copula transformation with stacked ensembles produces reliable high-accuracy maps of groundwater heavy metal pollution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that transforming the Heavy Metal Pollution Index via Gaussian copula and feeding it into a stacked Lasso ensemble produces an R² of 0.96 and RMSE of 0.19, with other learners also showing strong performance, improved residual patterns, and spatially plausible output maps, while raw-scale models reach near-perfect R² values that mask over-optimism and log-scale models sit slightly lower.
What carries the argument
The Gaussian copula transformation that converts the skewed and inter-correlated Heavy Metal Pollution Index values into approximately normal form before they enter the stacked ensemble learner.
Load-bearing premise
Random nested cross-validation is enough to control for spatial patterns and correlations in the groundwater measurements.
What would settle it
Running the identical models with spatial block cross-validation and seeing the top R² fall substantially below 0.9 would undermine the reliability of the reported accuracy.
Figures














read the original abstract
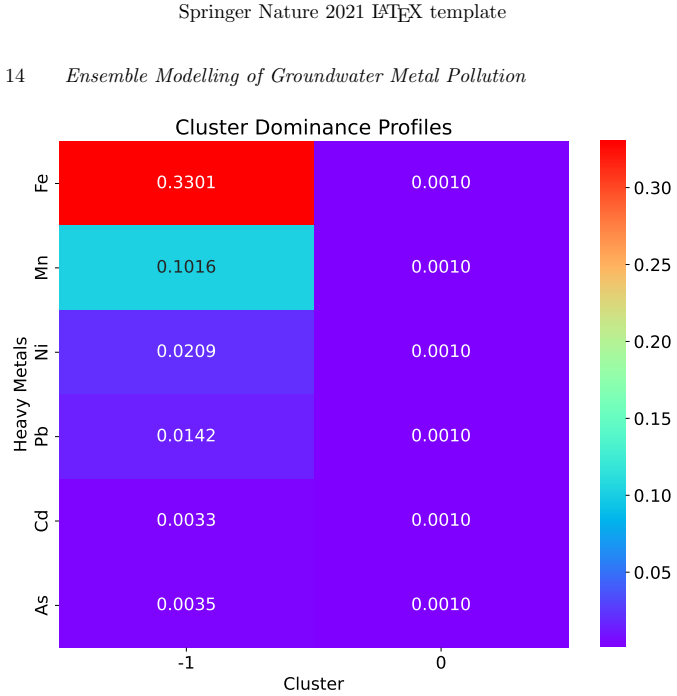
Groundwater in the Densu Basin is increasingly threatened by heavy metal contamination, but conventional methods fail to capture the statistical complexity and spatial heterogeneity of pollution indicators. A key challenge is modelling the Heavy Metal Pollution Index (HPI), which is typically skewed and affected by correlated contaminants, leading to biased predictions without transformation. This study develops a predictive framework integrating response transformations with nested cross-validated ensemble machine learning. Three transformations (raw, log, and Gaussian copula) were applied to HPI and evaluated across six learners: support vector regression (SVM), $k$-nearest neighbours (k-NN), CART, Elastic Net, kernel ridge regression, and a stacked Lasso ensemble. Raw-scale models produced deceptively high fits (Elastic Net and stacked ensemble $R^2 \approx 1.0$), suggesting over-optimism. The log transformation stabilised variance (SVM: $R^2 = 0.93$, RMSE $= 0.18$; k-NN: $R^2 = 0.92$, RMSE $= 0.20$). The Gaussian copula gave the most reliable results: stacked ensemble $R^2 = 0.96$ (RMSE $= 0.19$), with other learners maintaining high accuracy. Copula-based models improved residuals and produced spatially plausible maps. DBSCAN clustering revealed Fe and Mn as primary HPI contributors, consistent with regional hydrogeochemistry. Limitations include reliance on random (not spatial) cross-validation and basin-specific scope. Future work should explore spatial validation and other geological settings. Overall, distribution-aware ensembles with clustering diagnostics offer robust, interpretable assessments of groundwater contamination.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops an ensemble ML framework for predicting the Heavy Metal Pollution Index (HPI) in Densu Basin groundwater. It compares raw, log, and Gaussian copula transformations of the skewed HPI target across six learners (SVM, k-NN, CART, Elastic Net, kernel ridge, and stacked Lasso), reporting that the copula + stacked ensemble yields the strongest results (R² = 0.96, RMSE = 0.19) with better residuals and spatially plausible maps. DBSCAN clustering identifies Fe and Mn as dominant contributors, aligning with regional hydrogeochemistry. The work notes reliance on random (non-spatial) nested CV as a limitation and calls for future spatial validation.
Significance. If the performance advantage survives spatial validation, the framework would supply a concrete, interpretable pipeline for handling non-Gaussian, correlated pollution indices in environmental monitoring. The explicit demonstration that raw-scale models produce near-perfect but over-optimistic fits, together with the clustering-hydrogeochemistry consistency check, strengthens the case for distribution-aware ensembles in groundwater studies.
major comments (2)
- [Methods and Results] Methods and Results sections (cross-validation description and performance tables): All reported metrics, including the headline Gaussian-copula stacked-ensemble result (R² = 0.96, RMSE = 0.19), were obtained with random nested cross-validation. Because groundwater samples exhibit spatial autocorrelation, random folds permit leakage between nearby points; the abstract flags this limitation yet supplies no quantitative check (spatial blocking, variogram of residuals, or comparison of random vs. spatial CV scores) to show that the claimed superiority of the copula transformation is robust to this bias.
- [Results] Results section (residual and map analysis): The claim that copula-based models produce 'improved residuals' and 'spatially plausible maps' is central to the reliability argument, but the manuscript provides neither quantitative residual diagnostics (e.g., Moran’s I, spatial variograms) nor side-by-side map comparisons with uncertainty bands. Without these, the visual and numerical improvement cannot be isolated from possible spatial leakage.
minor comments (2)
- [Abstract] Abstract: The list of learners ('six learners: SVM, k-NN, CART, Elastic Net, kernel ridge regression, and a stacked Lasso ensemble') is slightly ambiguous—clarify whether the stacked model counts as the sixth learner or is an additional meta-learner.
- [Clustering analysis] Clustering subsection: DBSCAN parameter choices (epsilon, min_samples) and any stability or validation metrics are not reported; adding these would strengthen the claim of consistency with hydrogeochemistry.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which highlight important considerations for spatial validation in environmental machine learning applications. We address each major comment below and outline targeted revisions to improve the manuscript's rigor.
read point-by-point responses
-
Referee: [Methods and Results] Methods and Results sections (cross-validation description and performance tables): All reported metrics, including the headline Gaussian-copula stacked-ensemble result (R² = 0.96, RMSE = 0.19), were obtained with random nested cross-validation. Because groundwater samples exhibit spatial autocorrelation, random folds permit leakage between nearby points; the abstract flags this limitation yet supplies no quantitative check (spatial blocking, variogram of residuals, or comparison of random vs. spatial CV scores) to show that the claimed superiority of the copula transformation is robust to this bias.
Authors: We agree that random nested cross-validation can introduce leakage due to spatial autocorrelation in groundwater data, potentially affecting the reliability of performance claims. Our current dataset size constrains the use of spatial blocking without compromising fold integrity, which is why we flagged this as a limitation and called for future spatial validation. In the revision, we will add a quantitative post-hoc check by computing Moran's I on the residuals of the Gaussian copula stacked ensemble and other top models to evaluate residual spatial structure. We will also expand the discussion to address how this impacts the relative advantage of the copula transformation. This provides the strongest feasible robustness assessment without requiring new data collection. revision: partial
-
Referee: [Results] Results section (residual and map analysis): The claim that copula-based models produce 'improved residuals' and 'spatially plausible maps' is central to the reliability argument, but the manuscript provides neither quantitative residual diagnostics (e.g., Moran’s I, spatial variograms) nor side-by-side map comparisons with uncertainty bands. Without these, the visual and numerical improvement cannot be isolated from possible spatial leakage.
Authors: We accept that additional quantitative diagnostics would strengthen the claims regarding residual improvement and map plausibility. In the revised manuscript, we will include Moran's I statistics and variogram analyses of residuals for the raw, log, and Gaussian copula transformations to provide objective measures of spatial structure. We will also add side-by-side predicted HPI maps with uncertainty bands (computed from ensemble variance) for direct comparison across transformations. These additions will help demonstrate that the reported improvements are not solely due to spatial leakage. revision: yes
Circularity Check
No circularity; empirical ML performance on held-out data
full rationale
The paper reports standard empirical results from applying transformations (including Gaussian copula) and training ML models (SVM, k-NN, etc.) with nested cross-validation, then evaluating R²/RMSE on held-out folds. No mathematical derivation chain exists that reduces predictions to inputs by construction, no self-citations are load-bearing, and no fitted parameters are relabeled as independent predictions. The Gaussian copula is a conventional preprocessing step whose parameters are estimated from training data only; test metrics remain external to that fit. Spatial CV limitations are noted but do not create circularity in the reported numbers.
Axiom & Free-Parameter Ledger
free parameters (2)
- Hyperparameters of SVM, k-NN, CART, Elastic Net, kernel ridge, and stacked Lasso
- Parameters of Gaussian copula transformation
axioms (2)
- domain assumption Random nested cross-validation adequately captures predictive performance despite spatial heterogeneity in pollution data
- domain assumption Transformations (raw, log, Gaussian copula) preserve predictive relationships without introducing bias
Reference graph
Works this paper leans on
-
[1]
In: 2021 International Conference on Electrical, Computer and Energy Technologies (ICECET), IEEE, pp 1--6
Afrifa GY, Ansah-Narh T, Loh YSA, et al (2021) Estimation of groundwater heavy metal pollution indices via an amalgam of stack ensemble learning. In: 2021 International Conference on Electrical, Computer and Energy Technologies (ICECET), IEEE, pp 1--6
2021
-
[2]
Turkish Journal of Emergency Medicine 18(3):91–93
Akoglu H (2018) User’s guide to correlation coefficients. Turkish Journal of Emergency Medicine 18(3):91–93. doi:10.1016/j.tjem.2018.08.001
-
[3]
Journal of Hydrology: Regional Studies 40:101,017
Akurugu BA, Obuobie E, Yidana SM, et al (2022) Groundwater resources assessment in the densu basin: A review. Journal of Hydrology: Regional Studies 40:101,017
2022
-
[4]
What about the other intervals? The American Statistician
Altman NS (1992) An introduction to kernel and nearest-neighbor nonparametric regression. The American Statistician 46(3):175–185. doi:10.1080/00031305.1992.10475879
-
[5]
Applied Water Science 1(1–2):41–48
Amoako J, Karikari AY, Ansa-Asare OD (2011) Physico-chemical quality of boreholes in densu basin of ghana. Applied Water Science 1(1–2):41–48. doi:10.1007/s13201-011-0007-0
-
[6]
International Scholarly Research Notices 2014:1–37
Armah FA, Quansah R, Luginaah I (2014) A systematic review of heavy metals of anthropogenic origin in environmental media and biota in the context of gold mining in ghana. International Scholarly Research Notices 2014:1–37. doi:10.1155/2014/252148
-
[7]
Environmental Geology 36(1–2):55–64
Backman B, Bodiš D, Lahermo P, et al (1998) Application of a groundwater contamination index in finland and slovakia. Environmental Geology 36(1–2):55–64. doi:10.1007/s002540050320, ://dx.doi.org/10.1007/s002540050320
-
[8]
Journal of the Royal Statistical Society Series B: Statistical Methodology 26(2):211--243
Box GE, Cox DR (1964) An analysis of transformations. Journal of the Royal Statistical Society Series B: Statistical Methodology 26(2):211--243
1964
-
[9]
wadsworth
Brieman L, Friedman JH, Olshen RA, et al (1984) Classification and regression trees. wadsworth
1984
-
[10]
Burnham KP, Anderson DR (2004) Multimodel inference: Understanding aic and bic in model selection. Sociological Methods and Research 33(2):261–304. doi:10.1177/0049124104268644
-
[11]
In: International workshop on multiple classifier systems, Springer, pp 1--15
Dietterich TG (2000) Ensemble methods in machine learning. In: International workshop on multiple classifier systems, Springer, pp 1--15
2000
-
[12]
Advances in neural information processing systems 9
Drucker H, Burges CJ, Kaufman L, et al (1996) Support vector regression machines. Advances in neural information processing systems 9
1996
-
[13]
Environmental Research Letters 7(2):021,003
Edmunds WM (2012) Limits to the availability of groundwater in africa. Environmental Research Letters 7(2):021,003. doi:10.1088/1748-9326/7/2/021003
-
[14]
Environmental Geochemistry and Health 46(10):409
Eid MH, Awad M, Mohamed EA, et al (2024) Comprehensive approach integrating water quality index and toxic element analysis for environmental and health risk assessment enhanced by simulation techniques. Environmental Geochemistry and Health 46(10):409
2024
-
[15]
International Journal of Environmental Research and Public Health 17(4):1245
Eldaw E, Huang T, Elubid B, et al (2020) A novel approach for indexing heavy metals pollution to assess groundwater quality for drinking purposes. International Journal of Environmental Research and Public Health 17(4):1245
2020
-
[16]
In: kdd, pp 226--231
Ester M, Kriegel HP, Sander J, et al (1996) A density-based algorithm for discovering clusters in large spatial databases with noise. In: kdd, pp 226--231
1996
-
[17]
Journal of hydrologic engineering 12(4):347--368
Genest C, Favre AC (2007) Everything you always wanted to know about copula modeling but were afraid to ask. Journal of hydrologic engineering 12(4):347--368
2007
-
[18]
Spatial Statistics 10:87--102
Gr \"a ler B (2014) Modelling skewed spatial random fields through the spatial vine copula. Spatial Statistics 10:87--102
2014
-
[19]
Journal of Hydrology 377(1–2):80–91
Gupta HV, Kling H, Yilmaz KK, et al (2009) Decomposition of the mean squared error and nse performance criteria: Implications for improving hydrological modelling. Journal of Hydrology 377(1–2):80–91. doi:10.1016/j.jhydrol.2009.08.003
-
[20]
The Elements of Statistical Learning
Hastie T, Tibshirani R, Friedman J (2009) The Elements of Statistical Learning. Springer New York, doi:10.1007/978-0-387-84858-7
-
[21]
Hengl T, Nussbaum M, Wright MN, et al (2018) Random forest as a generic framework for predictive modeling of spatial and spatio-temporal variables. PeerJ 6:e5518. doi:10.7717/peerj.5518
-
[22]
Computer Methods and Programs in Biomedicine 240:107,725
Hutson AD, Yu H (2023) Exact inference around ordinal measures of association is often not exact. Computer Methods and Programs in Biomedicine 240:107,725. doi:10.1016/j.cmpb.2023.107725
-
[23]
Pattern Recognition Letters 31(8):651--666
Jain AK (2010) Data clustering: 50 years beyond k-means. Pattern Recognition Letters 31(8):651--666. doi:10.1016/j.patrec.2009.09.011
-
[24]
Springer US, doi:10.1007/978-1-0716-1418-1
James G, Witten D, Hastie T, et al (2021) An Introduction to Statistical Learning: with Applications in R. Springer US, doi:10.1007/978-1-0716-1418-1
-
[25]
Soft Computing 29(3):1331--1346
Kazemi U, Soleimani S (2025) A new approach data processing: density-based spatial clustering of applications with noise (dbscan) clustering using game-theory. Soft Computing 29(3):1331--1346
2025
-
[26]
Krupskii P, Huser R, Genton MG (2018) Factor copula models for replicated spatial data. Journal of the American Statistical Association 113(521):467–479. doi:10.1080/01621459.2016.1261712
-
[27]
Springer New York, doi:10.1007/978-1-4614-6849-3
Kuhn M, Johnson K (2013) Applied Predictive Modeling. Springer New York, doi:10.1007/978-1-4614-6849-3
-
[28]
Simon and Schuster
Kunapuli G (2023) Ensemble methods for machine learning. Simon and Schuster
2023
-
[29]
Applied geochemistry 17(5):569--581
Lee G, Bigham JM, Faure G (2002) Removal of trace metals by coprecipitation with fe, al and mn from natural waters contaminated with acid mine drainage in the ducktown mining district, tennessee. Applied geochemistry 17(5):569--581
2002
-
[30]
Guangxi Sci 25:393--399
Li S, Xiong J, Deng C, et al (2018) The assessment of the heavy metal pollution and health risks in the liujiang river, xijiang region. Guangxi Sci 25:393--399
2018
-
[31]
A Concordance Correlation Coefficient to Evaluate Reproducibility
Lin LIK (1989) A concordance correlation coefficient to evaluate reproducibility. Biometrics 45(1):255. doi:10.2307/2532051
-
[32]
Environmental Research Letters 7(2):024,009
MacDonald AM, Bonsor HC, Dochartaigh B \'E \'O , et al (2012) Quantitative maps of groundwater resources in africa. Environmental Research Letters 7(2):024,009
2012
-
[33]
Environmental science and pollution research 23(8):7255--7265
Mamat Z, Haximu S, Zhang ZY, et al (2016) An ecological risk assessment of heavy metal contamination in the surface sediments of bosten lake, northwest china. Environmental science and pollution research 23(8):7255--7265
2016
-
[34]
Technology Innovation Office, Office of Solid Waste and Emergency Response
McLean JE (1992) Behavior of metals in soils. Technology Innovation Office, Office of Solid Waste and Emergency Response
1992
-
[35]
Journal of Environmental Science & Health Part A 31(2):283--289
Mohan SV, Nithila P, Reddy SJ (1996) Estimation of heavy metals in drinking water and development of heavy metal pollution index. Journal of Environmental Science & Health Part A 31(2):283--289
1996
-
[36]
Journal of Geographic Information System 8(05):618
Nyamekye C, Nyame FK, Ofosu SA, et al (2016) Using geospatial information component to monitor the watersheds along the densu basin in ghana. Journal of Geographic Information System 8(05):618
2016
-
[37]
Sustainable Chemistry for the Environment 2:100,015
Osei-Owusu J, Heve WK, Duker RQ, et al (2023) Assessments of microbial and heavy metal contaminations in water supply systems at the university of environment and sustainable development in ghana. Sustainable Chemistry for the Environment 2:100,015. doi:10.1016/j.scenv.2023.100015
-
[38]
Environmental Geology 41(1–2):183–188
Prasad B, Bose J (2001) Evaluation of the heavy metal pollution index for surface and spring water near a limestone mining area of the lower himalayas. Environmental Geology 41(1–2):183–188. doi:10.1007/s002540100380
-
[39]
Groundwater for Sustainable Development 9:100,245
Rezaei A, Hassani H, Hassani S, et al (2019) Evaluation of groundwater quality and heavy metal pollution indices in bazman basin, southeastern iran. Groundwater for Sustainable Development 9:100,245. doi:10.1016/j.gsd.2019.100245
-
[40]
Ecography 40(8):913--929
Roberts DR, Bahn V, Ciuti S, et al (2017) Cross-validation strategies for data with temporal, spatial, hierarchical, or phylogenetic structure. Ecography 40(8):913--929
2017
-
[41]
Environmental Geochemistry and Health 45(12):9757–9784
Saeed O, Székács A, Jordán G, et al (2023) Investigating the impacts of heavy metal(loid)s on ecology and human health in the lower basin of hungary’s danube river: A python and monte carlo simulation-based study. Environmental Geochemistry and Health 45(12):9757–9784. doi:10.1007/s10653-023-01769-4
-
[42]
In: Proceedings of the 15th International Conference on Machine Learning (ICML 1998)
Saunders C, Gammerman A, Vovk V (1998) Ridge regression learning algorithm in dual variables. In: Proceedings of the 15th International Conference on Machine Learning (ICML 1998). Morgan Kaufmann, San Francisco, CA, pp 515--521
1998
-
[43]
Shmueli G (2010) To explain or to predict? Statistical science pp 289--310
2010
-
[44]
Environment, Development and Sustainability 22(8):7847–7864
Singh KR, Dutta R, Kalamdhad AS, et al (2019) Review of existing heavy metal contamination indices and development of an entropy-based improved indexing approach. Environment, Development and Sustainability 22(8):7847–7864. doi:10.1007/s10668-019-00549-4
-
[45]
Applied Geochemistry 17(5):517--568
Smedley PL, Kinniburgh DG (2002) A review of the source, behaviour and distribution of arsenic in natural waters. Applied Geochemistry 17(5):517--568. doi:10.1016/S0883-2927(02)00018-5
-
[46]
Statistics and Computing 14(3):199–222
Smola AJ, Sch\" o lkopf B (2004) A tutorial on support vector regression. Statistics and Computing 14(3):199–222. doi:10.1023/b:stco.0000035301.49549.88
-
[47]
Statistical Theory and Related Fields 6(1):87–87
Sohil F, Sohali MU, Shabbir J (2021) An introduction to statistical learning with applications in r. Statistical Theory and Related Fields 6(1):87–87. doi:10.1080/24754269.2021.1980261
-
[48]
In: Advances in pharmacology, vol 96
Speer RM, Zhou X, Volk LB, et al (2023) Arsenic and cancer: Evidence and mechanisms. In: Advances in pharmacology, vol 96. Elsevier, p 151--202
2023
-
[49]
West African Journal of Applied Ecology 12(1)
Tay C, Kortatsi B (2008) Groundwater quality studies: A case study of the densu basin, ghana. West African Journal of Applied Ecology 12(1). doi:10.4314/wajae.v12i1.45760
-
[50]
Journal of the Royal Statistical Society Series B: Statistical Methodology , author =
Tibshirani R (1996) Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society Series B: Statistical Methodology 58(1):267–288. doi:10.1111/j.2517-6161.1996.tb02080.x
-
[51]
Journal of Artificial Intelligence Research 10:271–289
Ting KM, Witten IH (1999) Issues in stacked generalization. Journal of Artificial Intelligence Research 10:271–289. doi:10.1613/jair.594
-
[52]
Bias in error estimation when using cross- validation for model selection,
Varma S, Simon R (2006) Bias in error estimation when using cross-validation for model selection. BMC Bioinformatics 7(1). doi:10.1186/1471-2105-7-91
-
[53]
World Health Organization
WHO (2022) Guidelines for drinking-water quality: incorporating the first and second addenda. World Health Organization
2022
-
[54]
Willmott C, Matsuura K (2005) Advantages of the mean absolute error (mae) over the root mean square error (rmse) in assessing average model performance. Climate Research 30:79–82. doi:10.3354/cr030079
-
[55]
Wolpert DH (1992) Stacked generalization. Neural Networks 5(2):241–259. doi:10.1016/s0893-6080(05)80023-1
-
[56]
Communications in Statistics - Theory and Methods 53(6):2141–2153
Yu H, Hutson AD (2022) A robust spearman correlation coefficient permutation test. Communications in Statistics - Theory and Methods 53(6):2141–2153. doi:10.1080/03610926.2022.2121144
-
[57]
International Journal of Environmental Research and Public Health 19(6):3571
Zhai Y, Zheng F, Li D, et al (2022) Distribution, genesis, and human health risks of groundwater heavy metals impacted by the typical setting of songnen plain of ne china. International Journal of Environmental Research and Public Health 19(6):3571. doi:10.3390/ijerph19063571
-
[58]
In: Proceedings of the 14th ACM international conference on web search and data mining, pp 418--426
Zhang Z, Rudra K, Anand A (2021) Explain and predict, and then predict again. In: Proceedings of the 14th ACM international conference on web search and data mining, pp 418--426
2021
-
[59]
CRC press
Zhou ZH (2025) Ensemble methods: foundations and algorithms. CRC press
2025
-
[60]
Science of the total environment 275(1-3):19--26
Zietz B, de Vergara JD, Kevekordes S, et al (2001) Lead contamination in tap water of households with children in lower saxony, germany. Science of the total environment 275(1-3):19--26
2001
-
[61]
Journal of the Royal Statistical Society Series B: Statistical Methodology , author =
Zou H, Hastie T (2005) Regularization and variable selection via the elastic net. Journal of the Royal Statistical Society Series B: Statistical Methodology 67(2):301–320. doi:10.1111/j.1467-9868.2005.00503.x
-
[62]
Geochemistry: Exploration, Environment, Analysis 19(2):129--137
Z \'u \ n iga-V \'a zquez D, Armienta MA, Deng Y, et al (2019) Evaluation of fe, zn, pb, cd and as mobility from tailings by sequential extraction and experiments under imposed physico-chemical conditions. Geochemistry: Exploration, Environment, Analysis 19(2):129--137
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.