Recognition: no theorem link
EULER-ADAS: Energy-Efficient & SIMD-Unified Logarithmic-Posit Engine for Precision-Reconfigurable Approximate ADAS Acceleration
Pith reviewed 2026-05-11 00:47 UTC · model grok-4.3
The pith
A SIMD-unified logarithmic bounded-Posit engine enables precision-reconfigurable ADAS acceleration with major cuts in power, delay, and area while staying close to FP32 accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that a bounded-Posit representation with stage-adaptive logarithmic mantissa multiplication and bit truncation, realized in a SIMD-enabled datapath with shared quire accumulation, supports reconfigurable execution of Posit-8, Posit-16, and Posit-32 formats in unified hardware, delivering up to 41.4% fewer LUTs, 76.1% reduced delay, and 71.9% lower power on FPGA compared to exact Posit engines, along with up to 10x better energy-delay product, while preserving accuracy within 1.5 percentage points of FP32 on ADAS workloads.
What carries the argument
The SIMD-shared quire accumulation path combined with bounded-regime Posit encoding and logarithmic mantissa multiplication with bit truncation.
If this is right
- FPGA realizations of the bounded variants require fewer lookup tables, shorter critical paths, and less power than exact Posit compute engines.
- The energy-delay product improves by a factor of up to 10 relative to radix-4 Booth-based Posit multipliers.
- ASIC versions in 28-nm CMOS occupy 0.013-0.016 mm², consume 19.8-22.1 mW, and reach clock speeds up to 1.84 GHz.
- End-to-end evaluation with TinyYOLOv3 on Pynq-Z2 yields 78 ms latency per frame at 0.29 W and 22.6 mJ/frame.
- Posit-16 and Posit-32 configurations stay within approximately 1.5 percentage points of FP32 accuracy on image-classification and edge-inference benchmarks.
Where Pith is reading between the lines
- The reconfigurable precision could allow runtime selection of lower precision modes to further reduce power during less demanding driving conditions.
- Extending the logarithmic approximation techniques to other arithmetic operations might yield additional efficiency gains in similar edge accelerators.
- Integration into full ADAS pipelines would require verifying that the observed accuracy margins hold under varying environmental conditions and sensor inputs.
- Comparable designs could benefit autonomous systems in robotics or drones where area and energy constraints are equally tight.
Load-bearing premise
The errors from regime bounding, logarithmic approximation, and bit truncation remain small enough not to degrade ADAS decision quality beyond the margins seen in the evaluated workloads.
What would settle it
Demonstrating a case where the Posit-based engine produces an incorrect ADAS output, such as a missed obstacle detection, while the equivalent FP32 model succeeds on the same input.
Figures




read the original abstract
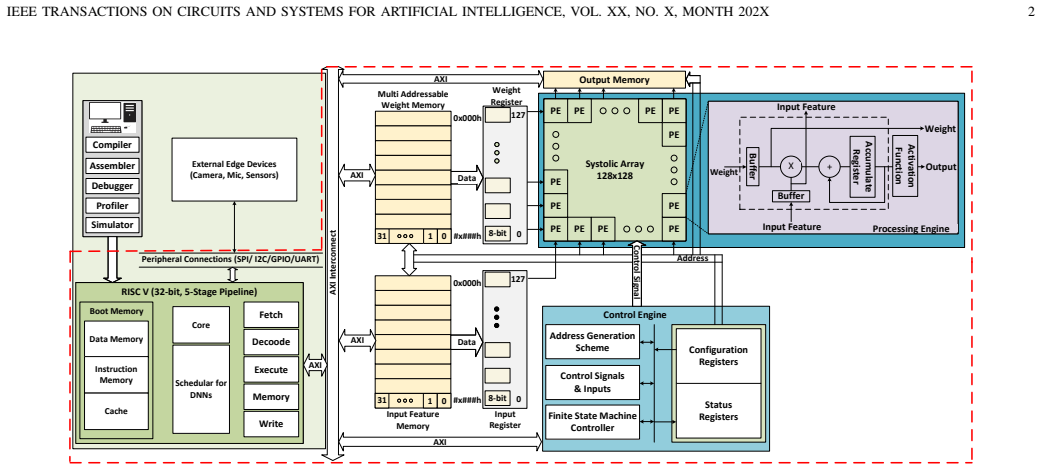
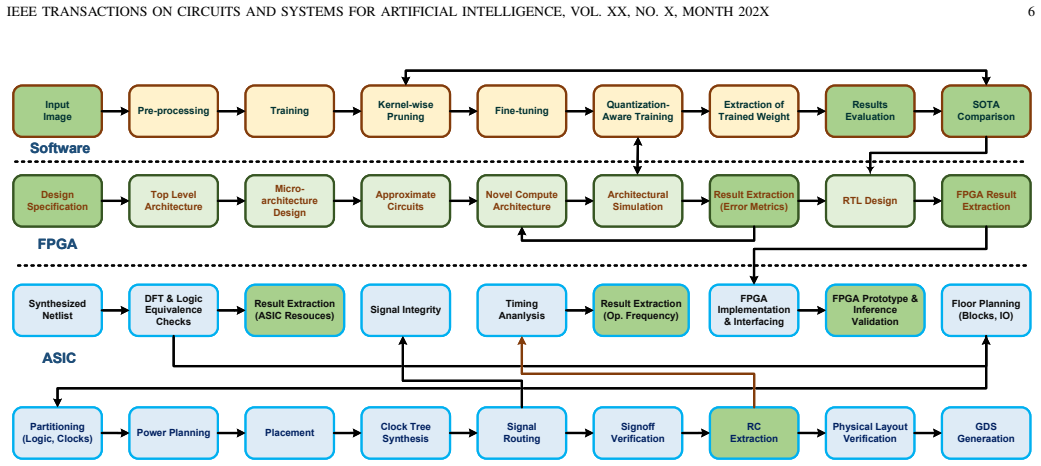
Advanced driver-assistance systems (ADAS) require neural compute engines that deliver low-latency inference under strict power and area constraints. Posit arithmetic is attractive for such accelerators because it provides high numerical fidelity at low precision, but its variable-length regime encoding increases encode/decode cost and exposes the datapath to large regime-field fault effects. This paper presents EULER-ADAS, a SIMD-enabled logarithmic bounded-Posit neural compute engine for energyefficient and reliability-aware ADAS acceleration. The proposed datapath combines bounded-regime Posit representation, stageadaptive logarithmic mantissa multiplication with bit truncation, and a SIMD-shared quire accumulation path supporting Posit- (8,0), Posit-(16,1), and Posit-(32,2) execution. The unified architecture enables 4xPosit-8, 2xPosit-16, or 1xPosit-32 operation without duplicating precision-specific hardware. FPGA implementation shows that the proposed configurations reduce LUT count by up to 41.4%, delay by up to 76.1%, and power by up to 71.9% relative to exact Posit neural compute engines, while achieving up to 10x lower energy-delay product than radix-4 Booth-based Posit multipliers. In 28-nm CMOS, the bounded variants occupy 0.013-0.016 mm2 , consume 19.8-22.1 mW, and operate at up to 1.84 GHz. Application-level evaluation across image-classification, ADAS, and edge-inference workloads shows that the evaluated Posit-16 and Posit-32 configurations remain within about 1.5 percentage points of FP32 accuracy. A TinyYOLOv3 prototype on Pynq-Z2 achieves 78 ms latency at 0.29 W and 22.6 mJ/frame, demonstrating the suitability of EULERADAS for low-power real-time ADAS inference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes EULER-ADAS, a SIMD-enabled logarithmic bounded-Posit neural compute engine for energy-efficient and reliability-aware ADAS acceleration. It introduces bounded-regime Posit representation, stage-adaptive logarithmic mantissa multiplication with bit truncation, and a unified quire accumulation path supporting Posit-(8,0), Posit-(16,1), and Posit-(32,2) modes in a single datapath. FPGA synthesis reports up to 41.4% LUT reduction, 76.1% delay reduction, 71.9% power reduction, and 10x lower EDP versus exact Posit and radix-4 Booth baselines; 28-nm ASIC results show 0.013-0.016 mm² area, 19.8-22.1 mW power, and up to 1.84 GHz operation. Application-level tests on image classification, ADAS, and edge-inference workloads (including TinyYOLOv3) claim Posit-16/32 accuracy within ~1.5 percentage points of FP32, with a Pynq-Z2 prototype at 78 ms latency, 0.29 W, and 22.6 mJ/frame.
Significance. If the accuracy margins hold under safety-critical conditions, the work offers a concrete datapath design that trades controlled approximation for substantial efficiency gains in low-power ADAS inference. The unified SIMD architecture and reported synthesis metrics provide measurable contributions to approximate posit-based accelerators, though the absence of formal error bounds limits the strength of the safety claims.
major comments (2)
- [Application-level evaluation] Application-level evaluation: the statement that Posit-16 and Posit-32 configurations remain within about 1.5 percentage points of FP32 accuracy on image-classification, ADAS, and TinyYOLOv3 workloads is presented without reported methodology details, error-bar analysis, dataset sizes, or worst-case deviation bounds under the bit-truncation and bounded-regime scheme. This is load-bearing for the central claim of suitability for safety-critical ADAS, as average accuracy margins do not address heavy-tailed errors or false-negative rates on rare inputs.
- [Abstract and FPGA/ASIC implementation sections] Abstract and implementation results: the FPGA and ASIC efficiency numbers (LUT/delay/power/EDP reductions, area/power/frequency) are given relative to 'exact Posit neural compute engines' and 'radix-4 Booth-based Posit multipliers,' but the manuscript does not define the precise baseline architectures, synthesis constraints, or whether the baselines incorporate equivalent SIMD unification, making direct comparison of the claimed gains difficult to verify.
minor comments (1)
- [Abstract] The abstract uses 'about 1.5 percentage points' without specifying the exact metric (top-1 accuracy, mAP, etc.) or the number of evaluated configurations.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive comments on our manuscript. We address each of the major comments in detail below, indicating where revisions will be made to improve clarity and completeness.
read point-by-point responses
-
Referee: [Application-level evaluation] Application-level evaluation: the statement that Posit-16 and Posit-32 configurations remain within about 1.5 percentage points of FP32 accuracy on image-classification, ADAS, and TinyYOLOv3 workloads is presented without reported methodology details, error-bar analysis, dataset sizes, or worst-case deviation bounds under the bit-truncation and bounded-regime scheme. This is load-bearing for the central claim of suitability for safety-critical ADAS, as average accuracy margins do not address heavy-tailed errors or false-negative rates on rare inputs.
Authors: We agree that additional details on the application-level evaluation are necessary to support the claims, particularly for safety-critical applications. The current manuscript summarizes the results at a high level. In the revised manuscript, we will include a dedicated subsection detailing the evaluation methodology. This will encompass the specific datasets used (with sizes), the number of experimental runs for statistical significance, error bar reporting, the exact application of bit-truncation and bounded-regime in the workloads, and an analysis of worst-case deviations and potential impacts on false-negative rates. We believe this will address the concern while preserving the empirical nature of our evaluation. revision: yes
-
Referee: [Abstract and FPGA/ASIC implementation sections] Abstract and implementation results: the FPGA and ASIC efficiency numbers (LUT/delay/power/EDP reductions, area/power/frequency) are given relative to 'exact Posit neural compute engines' and 'radix-4 Booth-based Posit multipliers,' but the manuscript does not define the precise baseline architectures, synthesis constraints, or whether the baselines incorporate equivalent SIMD unification, making direct comparison of the claimed gains difficult to verify.
Authors: We acknowledge that the baseline comparisons could be more precisely defined to facilitate verification. The baselines refer to standard implementations of Posit arithmetic units without the proposed bounded-regime, logarithmic multiplication, or unified SIMD features. In the revised version, we will expand the implementation sections to explicitly describe the baseline architectures, including their hardware configurations, the synthesis tools and constraints applied (such as target frequency, area optimization settings, and technology node specifics), and confirm that the baselines do not include the SIMD unification present in EULER-ADAS. This will allow for a clearer assessment of the efficiency improvements. revision: yes
Circularity Check
No circularity: claims rest on direct synthesis measurements and workload evaluations
full rationale
The paper describes a hardware architecture (bounded-regime Posit, stage-adaptive log mantissa multiplication, SIMD quire) and reports concrete FPGA LUT/delay/power numbers, 28-nm CMOS area/power/frequency, and application accuracy on image-classification/ADAS/TinyYOLOv3 workloads. These are implementation results obtained from synthesis and execution, not quantities derived from equations that loop back to fitted parameters or self-citations. No load-bearing step reduces by construction to its own inputs; the efficiency and accuracy statements are falsifiable measurements external to any internal derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Posit arithmetic provides high numerical fidelity at low precision and is therefore attractive for power-constrained accelerators.
invented entities (2)
-
Bounded-regime Posit representation
no independent evidence
-
Stage-adaptive logarithmic mantissa multiplication with bit truncation
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Dedicated FPGA Implementation of the Gaussian TinyYOLOv3 Accelerator,
S. Ki, J. Park, and H. Kim, “Dedicated FPGA Implementation of the Gaussian TinyYOLOv3 Accelerator,”IEEE Transactions on Circuits and Systems II: Express Briefs, vol. 70, no. 10, pp. 3882–3886, 2023
2023
-
[2]
Temporal Frame Filtering for Au- tonomous Driving Using 3D-Stacked Global Shutter CIS With IWO Buffer Memory & Near-Pixel Compute,
J. Sharda, W. Li, Q. Wu,et al., “Temporal Frame Filtering for Au- tonomous Driving Using 3D-Stacked Global Shutter CIS With IWO Buffer Memory & Near-Pixel Compute,”IEEE Transactions on Circuits and Systems I: Regular Papers, vol. 70, no. 5, pp. 2074–2084, 2023
2074
-
[3]
TPU v4: An Optically Reconfig- urable Supercomputer for Machine Learning with Hardware Support for Embeddings,
N. Jouppi, G. Kurian, S. Li,et al., “TPU v4: An Optically Reconfig- urable Supercomputer for Machine Learning with Hardware Support for Embeddings,” inProc. 50th Annu. Int. Symp. Comput. Archit. (ISCA), (New York, NY , USA), 2023
2023
-
[4]
Unified Posit/IEEE-754 Vector MAC Unit for Transprecision Computing,
L. Crespo, P. Tom ´as, N. Roma, and N. Neves, “Unified Posit/IEEE-754 Vector MAC Unit for Transprecision Computing,”IEEE Trans. Circuits Syst. II, Exp. Briefs, vol. 69, no. 5, pp. 2478–2482, 2022
2022
-
[5]
Single-Step Hardware-Aware NN Quantization with Mixed Precision,
J. Hu, Z. Zhang, Z. Li,et al., “Single-Step Hardware-Aware NN Quantization with Mixed Precision,”IEEE Trans. Comput., 2026
2026
-
[6]
Reliability exploration of system-on-chip with multi- bit-width accelerator for multi-precision deep neural networks,
Q. Cheng, M. Huang, C. Man, A. Shen, L. Dai, H. Yu, and M. Hashimoto, “Reliability exploration of system-on-chip with multi- bit-width accelerator for multi-precision deep neural networks,”IEEE Transactions on Circuits and Systems I: Regular Papers, vol. 70, no. 10, pp. 3978–3991, 2023
2023
-
[7]
Navigating posit arithmetic: A comprehensive survey of principles, hardware, and applications,
D. Mallas ´en, R. Murillo, G. Botella, and A. A. Del Barrio, “Navigating posit arithmetic: A comprehensive survey of principles, hardware, and applications,”ACM Comput. Surv., vol. 58, Nov. 2025. IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR ARTIFICIAL INTELLIGENCE, VOL. XX, NO. X, MONTH 202X 12 TABLE VIII PERFORMANCE EVALUATION FORADASALGORITHMS. Algo Me...
-
[8]
LPRE: Logarithmic Posit-Enabled Reconfigurable Edge-AI Engine,
O. Kokane, M. Lokhande, G. Raut, A. Teman, and S. K. Vishvakarma, “LPRE: Logarithmic Posit-Enabled Reconfigurable Edge-AI Engine,” in Proc. IEEE Int. Symp. Circuits Syst. (ISCAS), pp. 1–5, 2025
2025
-
[9]
Invited Paper: Hardware-Software Co- Design for Highly Optimized, Customized, and Reliable AI Systems,
J. Henkel, M. Tahoori, H. Khdr, H. Nassar, V . Meyers, D. Chen, S. Yildirim, Y . Huang,et al., “Invited Paper: Hardware-Software Co- Design for Highly Optimized, Customized, and Reliable AI Systems,” inIEEE/ACM International Conference On Computer Aided Design (ICCAD), pp. 1–9, 2025
2025
-
[10]
Fixed-Posit: A Floating- Point Representation for Error-Resilient Applications,
V . Gohil, S. Walia, J. Mekie, and M. Awasthi, “Fixed-Posit: A Floating- Point Representation for Error-Resilient Applications,”IEEE Trans- actions on Circuits and Systems II: Express Briefs, vol. 68, no. 10, pp. 3341–3345, 2021
2021
-
[11]
Closing the gap between float and posit hardware efficiency,
A. A. Jonnalagadda, R. Thotli, and J. L. Gustafson, “Closing the gap between float and posit hardware efficiency,”arXiv preprint arXiv:2603.01615, 2026
-
[12]
PC-Posits: Enhanced Soft Error Resilience of Posit Arithmetic Through Analytical Modeling,
V . Mishra, M. Traiola, A. Kritikakou, F. F. dos Santos, and U. Chatterjee, “PC-Posits: Enhanced Soft Error Resilience of Posit Arithmetic Through Analytical Modeling,” 2026
2026
-
[13]
Approximate computing survey, part i: Terminology and software & hardware approximation techniques,
V . Leon, M. A. Hanif, G. Armeniakos, X. Jiao, M. Shafique, K. Pekmestzi, and D. Soudris, “Approximate computing survey, part i: Terminology and software & hardware approximation techniques,”ACM Comput. Surv., vol. 57, Mar. 2025
2025
-
[14]
A Design Framework for Hardware- Efficient Logarithmic Floating-Point Multipliers,
T. Zhang, Z. Niu, and J. Han, “A Design Framework for Hardware- Efficient Logarithmic Floating-Point Multipliers,”IEEE Transactions on Emerging Topics in Computing, vol. 12, no. 4, pp. 991–1001, 2024
2024
-
[15]
Design and Analysis of Energy Ef- ficient Approximate Multipliers for Image Processing and Deep Neural Network,
A. Kumari and R. P. Palathinkal, “Design and Analysis of Energy Ef- ficient Approximate Multipliers for Image Processing and Deep Neural Network,”IEEE Transactions on Circuits and Systems I: Regular Papers, vol. 72, no. 2, pp. 854–867, 2025
2025
-
[16]
TransAxx: Efficient Transformers With Approximate Computing,
D. Danopoulos, G. Zervakis, D. Soudris, and J. Henkel, “TransAxx: Efficient Transformers With Approximate Computing,”IEEE Transac- tions on Circuits and Systems for Artificial Intelligence, vol. 2, no. 4, pp. 288–301, 2025
2025
-
[17]
ACE-CNN: Approximate Carry Disregard Mul- tipliers for Energy-Efficient CNN-Based Image Classification,
S. Shakibhamedan, N. Amirafshar, A. S. Baroughi, H. S. Shahhoseini, and N. TaheriNejad, “ACE-CNN: Approximate Carry Disregard Mul- tipliers for Energy-Efficient CNN-Based Image Classification,”IEEE Transactions on Circuits and Systems I: Regular Papers, vol. 71, no. 5, pp. 2280–2293, 2024
2024
-
[18]
Hardware-Efficient Multipliers With FPGA-Based Approximation for Error-Resilient Applications,
Y . Guo, Q. Zhou, X. Chen, and H. Sun, “Hardware-Efficient Multipliers With FPGA-Based Approximation for Error-Resilient Applications,” IEEE Transactions on Circuits and Systems I: Regular Papers, vol. 71, no. 12, pp. 5919–5930, 2024
2024
-
[19]
Y . Guo, X. Li, X. Luo, H. Sun, H. Waris, and W. Liu, “FPGA-Based Low-Power Signed Approximate Multipliers for Diverse Error-Resilient IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR ARTIFICIAL INTELLIGENCE, VOL. XX, NO. X, MONTH 202X 13 Applications,”IEEE Transactions on Very Large Scale Integration (VLSI) Systems, vol. 34, no. 3, pp. 1029–1042, 2026
2026
-
[20]
An efficient approximate radix-8 booth multiplier for edge detection in bioimages by field programmable gate array,
H. Jianget al., “An efficient approximate radix-8 booth multiplier for edge detection in bioimages by field programmable gate array,”IEEE Transactions on Circuits and Systems II: Express Briefs, 2025
2025
-
[21]
A Low-Power Sparse CNN Accelerator With Pre-Encoding Radix-4 Booth Multiplier,
Q. Cheng, L. Dai, M. Huang, A. Shen, W. Mao, M. Hashimoto, and H. Yu, “A Low-Power Sparse CNN Accelerator With Pre-Encoding Radix-4 Booth Multiplier,”IEEE Transactions on Circuits and Systems II: Express Briefs, vol. 70, no. 6, pp. 2246–2250, 2023
2023
-
[22]
Approximate Hybrid High Radix Encoding for Energy-Efficient Inexact Multipliers,
V . Leon, G. Zervakis, D. Soudris, and K. Pekmestzi, “Approximate Hybrid High Radix Encoding for Energy-Efficient Inexact Multipliers,” IEEE Transactions on Very Large Scale Integration (VLSI) Systems, vol. 26, no. 3, pp. 421–430, 2022
2022
-
[23]
An Ultra- Efficient Approximate Multiplier With Error Compensation for Error- Resilient Applications,
F. Sabetzadeh, M. H. Moaiyeri, and M. Ahmadinejad, “An Ultra- Efficient Approximate Multiplier With Error Compensation for Error- Resilient Applications,”IEEE Transactions on Circuits and Systems II: Express Briefs, vol. 70, no. 2, pp. 776–780, 2023
2023
-
[24]
A Cost and Speed Co- Optimized Parallel Stochastic Multiplier for Binary Inputs Supporting Variable Bit-Widths,
Q. He, Y . Zhao, Z. Zhang, G. Du, X. Nie,et al., “A Cost and Speed Co- Optimized Parallel Stochastic Multiplier for Binary Inputs Supporting Variable Bit-Widths,”IEEE Transactions on Circuits and Systems II: Express Briefs, vol. 72, no. 8, pp. 1068–1072, 2025
2025
-
[25]
Computer Multiplication and Division Using Binary Logarithms,
J. N. Mitchell, “Computer Multiplication and Division Using Binary Logarithms,”IRE Transactions on Electronic Computers, vol. EC-11, no. 4, pp. 512–517, 1962
1962
-
[26]
Design and Evaluation of Approximate Logarithmic Multipliers for Low Power Error-Tolerant Applications,
W. Liu, J. Xu, D. Wang, C. Wang, P. Montuschi, and F. Lombardi, “Design and Evaluation of Approximate Logarithmic Multipliers for Low Power Error-Tolerant Applications,”IEEE Transactions on Circuits and Systems I: Regular Papers, vol. 65, no. 9, pp. 2856–2868, 2018
2018
-
[27]
LUT-ALMs: Trading Off Accuracy and Power for Approximate Logarithmic Multipliers via LUT Optimiza- tion,
W. Zhang, X. Geng, X. Hu,et al., “LUT-ALMs: Trading Off Accuracy and Power for Approximate Logarithmic Multipliers via LUT Optimiza- tion,”IEEE Trans. Comput., 2026
2026
-
[28]
A Two-Stage Operand Trimming Approximate Logarithmic Multiplier,
R. Pilipovi ´c, P. Buli´c, and U. Lotri ˇc, “A Two-Stage Operand Trimming Approximate Logarithmic Multiplier,”IEEE Trans. Circuits Syst. I, Reg. Papers, vol. 68, no. 6, pp. 2535–2545, 2021
2021
-
[29]
Design and Analysis of Energy-Efficient Dynamic Range Approximate Logarithmic Multipliers for Machine Learning,
P. Yin, C. Wang, H. Waris, W. Liu, Y . Han, and F. Lombardi, “Design and Analysis of Energy-Efficient Dynamic Range Approximate Logarithmic Multipliers for Machine Learning,”IEEE Transactions on Sustainable Computing, vol. 6, no. 4, pp. 612–625, 2021
2021
-
[30]
An iterative logarithmic multiplier,
“An iterative logarithmic multiplier,”Microprocessors and Microsys- tems, vol. 35, no. 1, pp. 23–33, 2011
2011
-
[31]
Efficient Mitchell’s Approximate Log Multipliers for Convolutional Neural Networks,
M. S. Kim, A. A. D. Barrio, L. T. Oliveira, R. Hermida, and N. Bagherzadeh, “Efficient Mitchell’s Approximate Log Multipliers for Convolutional Neural Networks,”IEEE Trans. Comput., vol. 68, no. 5, pp. 660–675, 2019
2019
-
[32]
Efficient Approximate Floating-Point Multiplier With Runtime Recon- figurable Frequency and Precision,
Z. Li, Z. Lu, W. Jia, R. Yu, H. Zhang, G. Zhou, Z. Liu, and G. Qu, “Efficient Approximate Floating-Point Multiplier With Runtime Recon- figurable Frequency and Precision,”IEEE Transactions on Circuits and Systems II: Express Briefs, vol. 71, no. 7, pp. 3533–3537, 2024
2024
-
[33]
Area-Efficient Iterative Logarithmic Approximate Multipliers for IEEE 754 and Posit Numbers,
S. Kim, C. J. Norris, J. I. Oelund, and R. A. Rutenbar, “Area-Efficient Iterative Logarithmic Approximate Multipliers for IEEE 754 and Posit Numbers,”IEEE Trans. Very Large Scale Integr. (VLSI) Syst., vol. 32, no. 3, pp. 455–467, 2024
2024
-
[34]
C-SIMD: CORDIC-Driven SIMD Processing Element for Resource- Efficient Multi-Precision DL Inference,
V . Trivedi, G. Raut, B. Mohammad, S. K. Vishvakarma, and A. Kumar, “C-SIMD: CORDIC-Driven SIMD Processing Element for Resource- Efficient Multi-Precision DL Inference,”IEEE Access, 2026
2026
-
[35]
A Reconfigurable Processing Element for Multiple-Precision Floating/Fixed-Point HPC,
B. Li, K. Li, J. Zhou,et al., “A Reconfigurable Processing Element for Multiple-Precision Floating/Fixed-Point HPC,”IEEE Trans. Circuits Syst. II, Exp. Briefs, vol. 71, no. 3, pp. 1401–1405, 2024
2024
-
[36]
Reconfigurable FPU With Precision Auto- Tuning for Next-Generation Transprecision Computing,
G. Dias, L. Crespo,et al., “Reconfigurable FPU With Precision Auto- Tuning for Next-Generation Transprecision Computing,”IEEE Trans. Circuits Syst. I, Reg. Papers, vol. 73, no. 3, pp. 1553–1564, 2026
2026
-
[37]
A Configurable Floating-Point Multiple-Precision Processing Element for HPC and AI Converged Computing,
W. Mao, K. Li, Q. Cheng, L. Dai, B. Li, X. Xie, H. Li, L. Lin, and H. Yu, “A Configurable Floating-Point Multiple-Precision Processing Element for HPC and AI Converged Computing,”IEEE Trans. Very Large Scale Integr. (VLSI) Syst., vol. 30, no. 2, pp. 213–226, 2022
2022
-
[38]
A Configurable Floating-Point Fused Multiply-Add Design With Mixed Precision for AI Accelerators,
F. Niknia, Z. Wang, S. Liu, P. Reviriego, Z. Gao, P. Montuschi, and F. Lombardi, “A Configurable Floating-Point Fused Multiply-Add Design With Mixed Precision for AI Accelerators,”IEEE Trans. Circuits Syst. AI, vol. 2, no. 3, pp. 248–261, 2025
2025
-
[39]
Flex-PE: Flexible and SIMD Multiprecision Processing Element for AI Workloads,
M. Lokhande, G. Raut, and S. K. Vishvakarma, “Flex-PE: Flexible and SIMD Multiprecision Processing Element for AI Workloads,”IEEE Trans. Very Large Scale Integr. (VLSI) Syst., vol. 33, no. 6, pp. 1610– 1623, 2025
2025
-
[40]
A Low-Cost Floating-Point FMA Unit Supporting Package Operations for HPC-AI Applications,
H. Tan, J. Zhang, X. He,et al., “A Low-Cost Floating-Point FMA Unit Supporting Package Operations for HPC-AI Applications,”IEEE Trans. Circuits Syst. II, Exp. Briefs, vol. 71, no. 7, pp. 3488–3492, 2024
2024
-
[41]
A Low-Cost Floating- Point Dot-Product-Dual-Accumulate Architecture for HPC-Enabled AI,
H. Tan, L. Huang, Z. Zheng, H. Guo,et al., “A Low-Cost Floating- Point Dot-Product-Dual-Accumulate Architecture for HPC-Enabled AI,” IEEE Trans. Comput.-Aided Design Integr. Circuits Syst., vol. 43, no. 2, pp. 681–693, 2024
2024
-
[42]
Maestro: A 302 GFLOPS/W and 19.8 GFLOPS RISC-V Vector-Tensor Architec- ture for Wearable Ultrasound Edge Computing,
M. Sinigaglia, A. Kiamarzi, M. Bertuletti, L. Ghionda,et al., “Maestro: A 302 GFLOPS/W and 19.8 GFLOPS RISC-V Vector-Tensor Architec- ture for Wearable Ultrasound Edge Computing,”IEEE Trans. Circuits Syst. I, Reg. Papers, vol. 72, no. 11, pp. 6665–6678, 2025
2025
-
[43]
Hybrid Low Radix Encoding-Based Approximate Booth Multipliers,
H. Waris, C. Wang, and W. Liu, “Hybrid Low Radix Encoding-Based Approximate Booth Multipliers,”IEEE Transactions on Circuits and Systems II: Express Briefs, vol. 67, no. 12, pp. 3367–3371, 2023
2023
-
[44]
RoBA Multiplier: A Rounding-Based Approximate Multiplier for High-Speed yet Energy-Efficient Digital Signal Processing,
R. Zendegani, M. Kamal, M. Bahadori, A. Afzali-Kusha, and M. Pe- dram, “RoBA Multiplier: A Rounding-Based Approximate Multiplier for High-Speed yet Energy-Efficient Digital Signal Processing,”IEEE Transactions on Very Large Scale Integration (VLSI) Systems, vol. 25, no. 2, pp. 393–401, 2021
2021
-
[45]
TOSAM: An Energy-Efficient Truncation- and Rounding-Based Scalable Approx- imate Multiplier,
S. Vahdat, M. Kamal, A. Afzali-Kusha, and M. Pedram, “TOSAM: An Energy-Efficient Truncation- and Rounding-Based Scalable Approx- imate Multiplier,”IEEE Transactions on Very Large Scale Integration (VLSI) Systems, vol. 27, no. 5, pp. 1161–1173, 2019
2019
-
[46]
Energy Effi- cient Compact Approximate Multiplier for Error-Resilient Applications,
A. Sadeghi, R. Rasheedi, I. Partin-Vaisband, and D. Pal, “Energy Effi- cient Compact Approximate Multiplier for Error-Resilient Applications,” IEEE Transactions on Circuits and Systems II: Express Briefs, vol. 71, no. 12, pp. 4989–4993, 2024
2024
-
[47]
Design and analysis of an accuracy configurable fast approximate recursive multiplier,
V . Joshi, A. Agarwal, and P. Mane, “Design and analysis of an accuracy configurable fast approximate recursive multiplier,”Circuits, Systems, and Signal Processing, pp. 1–32, 2025
2025
-
[48]
Carry Disregard Approximate Multipliers,
N. Amirafshar, A. S. Baroughi,et al., “Carry Disregard Approximate Multipliers,”IEEE Transactions on Circuits and Systems I: Regular Papers, vol. 70, no. 12, pp. 4840–4853, 2023
2023
-
[49]
ACE-CNN: Approximate Carry Disregard Multipliers for Energy-Efficient CNN- Based Image Classification,
S. Shakibhamedan, N. Amirafshar, A. S. Baroughi,et al., “ACE-CNN: Approximate Carry Disregard Multipliers for Energy-Efficient CNN- Based Image Classification,”IEEE Transactions on Circuits and Systems I: Regular Papers, vol. 71, no. 5, pp. 2280–2293, 2024
2024
-
[50]
ACSAM: Accuracy-configurable Segmentation-based Approximate Multiplier for Error-resilient Edge-AI Applications,
V . Trivedi and S. K. Vishvakarma, “ACSAM: Accuracy-configurable Segmentation-based Approximate Multiplier for Error-resilient Edge-AI Applications,”IEEE Embedded Systems Letters, pp. 1–1, 2026
2026
-
[51]
HPR-Mul: An Area and Energy-Efficient High- Precision Redundancy Multiplier by Approximate Computing,
J. Vafaei and O. Akbari, “HPR-Mul: An Area and Energy-Efficient High- Precision Redundancy Multiplier by Approximate Computing,”IEEE Transactions on Very Large Scale Integration (VLSI) Systems, vol. 32, no. 11, pp. 2012–2022, 2024
2012
-
[52]
Retrospective: A CORDIC Based Configurable Activation Function for NN Applications,
O. Kokane, G. Raut, S. Ullah, M. Lokhande, A. Teman, A. Kumar, and S. K. Vishvakarma, “Retrospective: A CORDIC Based Configurable Activation Function for NN Applications,” in2025 IEEE Computer Society Annual Symposium on VLSI (ISVLSI), vol. 1, pp. 1–6, 2025. IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR ARTIFICIAL INTELLIGENCE, VOL. XX, NO. X, MONTH 202X ...
2025
-
[53]
He submitted his doctoral dissertation at IIT Indore, India, in December 2025, and is currently with Qualcomm Technologies, Inc., Bengaluru, In- dia. His research interests include hardware-software codesign for efficient edge-AI workloads, multi- precision NPU architectures, approximate arithmetic engines, and digital processing-in-memory architec- tures...
2025
-
[54]
Teman is an Associate Editor of IEEE TCAD
Prof. Teman is an Associate Editor of IEEE TCAD. Santosh Kumar Vishvakarma(Senior Member, IEEE) received the Ph.D. degree from the Indian Institute of Technology Roorkee, India, in 2010. From 2009 to 2010, he was with the University Graduate Centre, Norway, as a Postdoctoral Fellow under a European Union project. He is a Professor in the Department of Ele...
2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.