Recognition: 2 theorem links
· Lean TheoremEquiMem: Calibrating Shared Memory in Multi-Agent Debate via Game-Theoretic Equilibrium
Pith reviewed 2026-05-12 04:44 UTC · model grok-4.3
The pith
Shared memory in multi-agent debate can be calibrated by computing a game-theoretic equilibrium from agents' retrieval paths alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
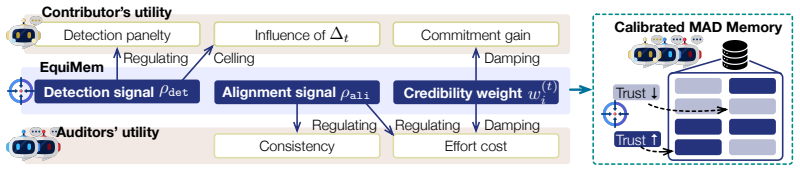
Memory updating in multi-agent debate is formulated as a zero-trust memory game in which the game's equilibrium serves as an indicator of optimal memory trust. EquiMem instantiates this calibration at inference time for embedding- and graph-based memories by quantifying each update against the shared memory state using only agents' retrieval queries and traversal paths as evidence, without soliciting LLM judgment.
What carries the argument
The zero-trust memory game, whose equilibrium quantifies trust in each memory update from observed agent retrieval behaviors.
Load-bearing premise
Agents' existing retrieval queries and traversal paths supply sufficient unbiased evidence to compute a reliable equilibrium trust value for memory entries.
What would settle it
A controlled experiment in which agents' paths are adversarially steered toward a known corrupted memory entry yet the computed equilibrium still assigns it high trust would falsify the claim that the equilibrium reliably indicates memory safety.
Figures


read the original abstract
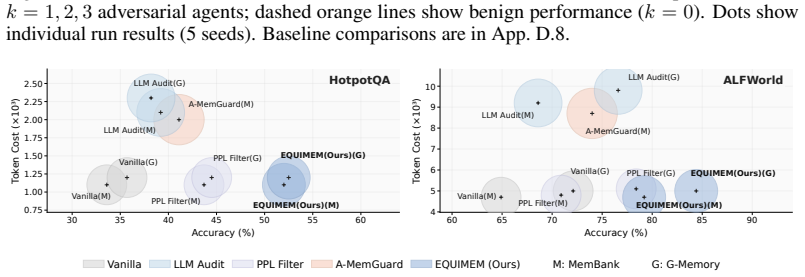
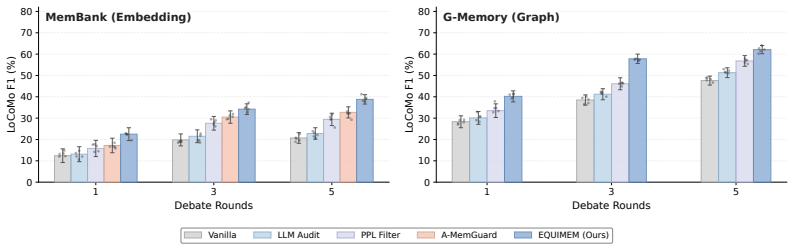
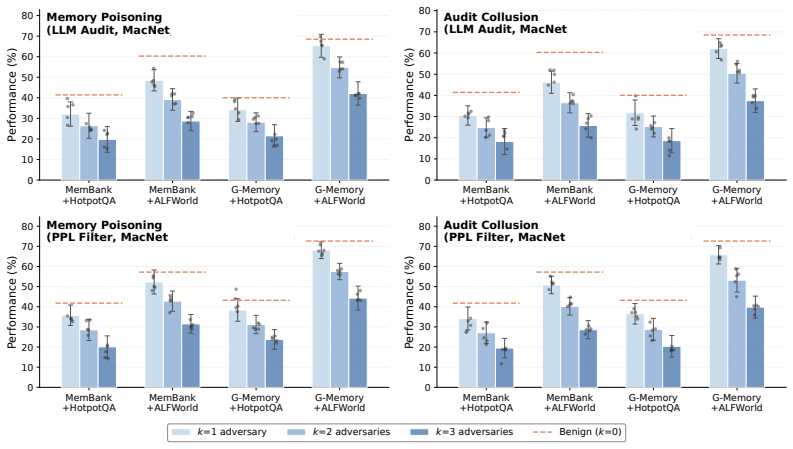
Multi-agent debate (MAD) systems increasingly rely on shared memory to support long-horizon reasoning, but this convenience opens a critical vulnerability: a single corrupted entry can contaminate the downstream memory-augmented reasoning, and debate alone fails to filter such errors. Existing safeguards filter entries via heuristics or LLM-based validation, yet they rely on AI judgments that share the same failure modes and overlook the cross-agent dynamics of MAD. We address this gap by formulating memory updating in MAD as a zero-trust memory game, in which no agent is assumed honest and the game's equilibrium serves as an indicator of optimal memory trust. Guided by this equilibrium, we propose EquiMem, an inference-time calibration mechanism that quantifies each update algorithmically against the shared memory state, using agents' existing retrieval queries and traversal paths as evidence rather than soliciting any LLM judgment. EquiMem instantiates calibration for both embedding- and graph-based memory, and across diverse benchmarks, MAD frameworks, and memory architectures, it consistently outperforms existing safeguards, remains robust under adversarial agents, and incurs negligible inference overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that memory updating in multi-agent debate (MAD) can be formulated as a zero-trust game whose equilibrium provides an algorithmic indicator of optimal trust for shared-memory entries. EquiMem uses only agents' existing retrieval queries and traversal paths (no additional LLM judgments) to instantiate this calibration for both embedding- and graph-based memories, and reports consistent outperformance over heuristic/LLM-based safeguards, robustness to adversarial agents, and negligible inference overhead across benchmarks, MAD frameworks, and memory architectures.
Significance. If the equilibrium derivation is sound and the empirical robustness holds, the work supplies a principled inference-time mechanism that avoids the circularity of LLM-based validation while exploiting the interaction graph already present in MAD. This could meaningfully improve reliability of long-horizon multi-agent reasoning without extra model calls.
major comments (2)
- [§3] §3 (zero-trust game formulation): the central claim that agents' retrieval queries and traversal paths alone supply sufficient unbiased evidence for a reliable equilibrium trust signal is load-bearing, yet the manuscript provides no uniqueness/stability proof or minimum-evidence bound under selective omission or fabrication by adversarial agents; a concrete counter-example or sensitivity analysis is needed to support the robustness assertion.
- [§5.3] §5.3 and Table 4 (adversarial robustness experiments): the reported outperformance under adversarial agents does not include an ablation that isolates the effect of biased query/path traces versus the equilibrium computation itself; without this, it is unclear whether the gains derive from the game-theoretic calibration or from other implementation details.
minor comments (2)
- [§3] Notation for the equilibrium indicator (e.g., Eq. (7)) is introduced without an explicit statement of the payoff matrix or strategy space; adding a short self-contained definition would improve readability.
- [Figure 3] Figure 3 caption does not state the number of random seeds or error bars; this makes it difficult to assess the consistency of the reported gains.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, indicating where revisions have been made to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (zero-trust game formulation): the central claim that agents' retrieval queries and traversal paths alone supply sufficient unbiased evidence for a reliable equilibrium trust signal is load-bearing, yet the manuscript provides no uniqueness/stability proof or minimum-evidence bound under selective omission or fabrication by adversarial agents; a concrete counter-example or sensitivity analysis is needed to support the robustness assertion.
Authors: We agree that a formal uniqueness or stability proof would further bolster the theoretical claims. The zero-trust game is formulated such that the Nash equilibrium is computed directly from the observed query-path interaction graph without external assumptions of honesty, and the manuscript demonstrates through multiple benchmarks that this yields a stable trust signal. To directly address the request, we have added a new sensitivity analysis subsection (with accompanying figures) that varies the fraction of fabricated or omitted traces and reports the resulting equilibrium deviation bounds, confirming robustness above a modest evidence threshold. We also include a brief discussion of why a general uniqueness proof is non-trivial in dynamic MAD settings but provide game-theoretic bounds on equilibrium stability under the zero-trust assumption. revision: yes
-
Referee: [§5.3] §5.3 and Table 4 (adversarial robustness experiments): the reported outperformance under adversarial agents does not include an ablation that isolates the effect of biased query/path traces versus the equilibrium computation itself; without this, it is unclear whether the gains derive from the game-theoretic calibration or from other implementation details.
Authors: The referee is correct that an explicit isolation ablation would make the attribution clearer. All methods evaluated in §5.3 and Table 4 operate on identical sets of (potentially biased) agent queries and traversal paths; the sole difference is the trust calibration procedure. EquiMem's consistent gains over heuristic and LLM baselines therefore already isolate the equilibrium computation. To make this isolation explicit, we have added an ablation in the revised §5.3 that replaces the equilibrium-derived trust values with random or uniform scores on the same adversarial traces, showing clear performance degradation. This new result is reported alongside the original table. revision: yes
Circularity Check
Game-theoretic equilibrium applied to existing traces introduces no definitional or fitted circularity
full rationale
The paper models memory updating as a zero-trust game whose equilibrium is computed directly from agents' observed retrieval queries and traversal paths, then uses that equilibrium value to calibrate trust. This is a standard application of game theory to an interaction graph rather than a self-definitional loop, a fitted parameter renamed as prediction, or a load-bearing self-citation. No equations reduce the claimed result to its inputs by construction, and the central claim retains independent modeling content. The derivation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption No agent is assumed honest; the game is zero-trust
invented entities (1)
-
Equilibrium indicator of optimal memory trust
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat_is_initial unclearWe formalize memory updating as a two-stage game... contributor utility uc(Δt,Mt)=Pr[C({vi})=1|Δt]·I(Δt,Mt)−D(Δt,Mt); auditor utility ui(vi,Δt,Mt)=Align(Δt,Mt)−ci·1[vi=scrutinize]. System reaches equilibrium when no participant can improve payoff unilaterally (Eq. 5).
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearCalibration indicator ρ=√ρdetect·ρalign computed algorithmically from retrieval queries and traversal paths; commitment iff ρ≥ρ* (running median).
Reference graph
Works this paper leans on
-
[1]
Detecting language model attacks with perplexity
Gabriel Alon and Michael Kamfonas. Detecting language model attacks with perplexity.arXiv preprint arXiv:2308.14132, 2023
-
[2]
Alfonso Amayuelas, Xianjun Yang, Antonis Antoniades, Wenyue Hua, Liangming Pan, and William Yang Wang. Multiagent collaboration attack: Investigating adversarial attacks in large language model collaborations via debate. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 6929–6948, 2024
work page 2024
-
[3]
Petr Anokhin, Nikita Semenov, Artyom Sorokin, Dmitry Evseev, Andrey Kravchenko, Mikhail Burtsev, and Evgeny Burnaev. Arigraph: Learning knowledge graph world models with episodic memory for llm agents.arXiv preprint arXiv:2407.04363, 2024
-
[4]
Kenneth J Arrow.Social choice and individual values, volume 12. Yale university press, 2012
work page 2012
-
[5]
Llms will always hallucinate, and we need to live with this
Sourav Banerjee, Ayushi Agarwal, and Saloni Singla. Llms will always hallucinate, and we need to live with this. InIntelligent Systems Conference, pages 624–648. Springer, 2025
work page 2025
-
[6]
Ai sycophancy as social-moral behavior
Jaime Banks. Ai sycophancy as social-moral behavior. InProvoking Generative AI Futures, pages 99–116. Routledge, 2026
work page 2026
-
[7]
María Victoria Carro. Flattering to deceive: The impact of sycophantic behavior on user trust in large language model.arXiv preprint arXiv:2412.02802, 2024
-
[8]
Practical byzantine fault tolerance
Miguel Castro, Barbara Liskov, et al. Practical byzantine fault tolerance. InOsDI, volume 99, pages 173–186, 1999
work page 1999
-
[9]
ChatEval: Towards Better LLM-based Evaluators through Multi-Agent Debate
Chi-Min Chan, Weize Chen, Yusheng Su, Jianxuan Yu, Wei Xue, Shanghang Zhang, Jie Fu, and Zhiyuan Liu. Chateval: Towards better llm-based evaluators through multi-agent debate. arXiv preprint arXiv:2308.07201, 2023
work page internal anchor Pith review arXiv 2023
-
[10]
Agentverse: Facilitating multi-agent collaboration and exploring emergent behaviors
Weize Chen, Yusheng Su, Jingwei Zuo, Cheng Yang, Chenfei Yuan, Chi-Min Chan, Heyang Yu, Yaxi Lu, Yi-Hsin Hung, Chen Qian, et al. Agentverse: Facilitating multi-agent collaboration and exploring emergent behaviors. InThe Twelfth International Conference on Learning Representations, 2023
work page 2023
-
[11]
Zhaorun Chen, Zhen Xiang, Chaowei Xiao, Dawn Song, and Bo Li. Agentpoison: Red- teaming llm agents via poisoning memory or knowledge bases.Advances in Neural Information Processing Systems, 37:130185–130213, 2024
work page 2024
-
[12]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building production-ready ai agents with scalable long-term memory.arXiv preprint arXiv:2504.19413, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
The treatment of ties in rank-biased overlap
Matteo Corsi and Julián Urbano. The treatment of ties in rank-biased overlap. InProceedings of the 47th international ACM SIGIR conference on research and development in information retrieval, pages 251–260, 2024. 10
work page 2024
-
[14]
Or-bench: An over-refusal benchmark for large language models.arXiv preprint arXiv:2405.20947,
Justin Cui, Wei-Lin Chiang, Ion Stoica, and Cho-Jui Hsieh. Or-bench: An over-refusal benchmark for large language models.arXiv preprint arXiv:2405.20947, 2024
-
[15]
Shen Dong, Shaochen Xu, Pengfei He, Yige Li, Jiliang Tang, Tianming Liu, Hui Liu, and Zhen Xiang. Memory injection attacks on llm agents via query-only interaction.arXiv preprint arXiv:2503.03704, 2025
-
[16]
A practical memory injection attack against llm agents.arXiv e-prints, pages arXiv–2503, 2025
Shen Dong, Shaochen Xu, Pengfei He, Yige Li, Jiliang Tang, Tianming Liu, Hui Liu, and Zhen Xiang. A practical memory injection attack against llm agents.arXiv e-prints, pages arXiv–2503, 2025
work page 2025
-
[17]
Improv- ing factuality and reasoning in language models through multiagent debate
Yilun Du, Shuang Li, Antonio Torralba, Joshua B Tenenbaum, and Igor Mordatch. Improv- ing factuality and reasoning in language models through multiagent debate. InForty-first international conference on machine learning, 2024
work page 2024
-
[18]
Syceval: Evaluating llm sycophancy
Aaron Fanous, Jacob Goldberg, Ank Agarwal, Joanna Lin, Anson Zhou, Sonnet Xu, Vasiliki Bikia, Roxana Daneshjou, and Sanmi Koyejo. Syceval: Evaluating llm sycophancy. In Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, volume 8, pages 893–900, 2025
work page 2025
-
[19]
Retrieval-Augmented Generation for Large Language Models: A Survey
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yixin Dai, Jiawei Sun, Haofen Wang, Haofen Wang, et al. Retrieval-augmented generation for large language models: A survey.arXiv preprint arXiv:2312.10997, 2(1):32, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Three brief proofs of arrow’s impossibility theorem.Economic Theory, 26(1):211–215, 2005
John Geanakoplos. Three brief proofs of arrow’s impossibility theorem.Economic Theory, 26(1):211–215, 2005
work page 2005
-
[21]
Allan Gibbard. Manipulation of voting schemes: a general result.Econometrica: journal of the Econometric Society, pages 587–601, 1973
work page 1973
-
[22]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Metagpt: Meta programming for a multi-agent collaborative framework
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, et al. Metagpt: Meta programming for a multi-agent collaborative framework. InThe twelfth international conference on learning representations, 2023
work page 2023
-
[24]
Debate-to-write: A persona-driven multi-agent framework for diverse argument generation
Zhe Hu, Hou Pong Chan, Jing Li, and Yu Yin. Debate-to-write: A persona-driven multi-agent framework for diverse argument generation. InProceedings of the 31st International Conference on Computational Linguistics, pages 4689–4703, 2025
work page 2025
-
[25]
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qiang- long Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, et al. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions.ACM Transactions on Information Systems, 43(2):1–55, 2025
work page 2025
-
[26]
Survey of hallucination in natural language generation
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. Survey of hallucination in natural language generation. ACM computing surveys, 55(12):1–38, 2023
work page 2023
-
[27]
Language Models (Mostly) Know What They Know
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, et al. Language models (mostly) know what they know.arXiv preprint arXiv:2207.05221, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[28]
Akbir Khan, John Hughes, Dan Valentine, Laura Ruis, Kshitij Sachan, Ansh Radhakrishnan, Edward Grefenstette, Samuel R Bowman, Tim Rocktäschel, and Ethan Perez. Debating with more persuasive llms leads to more truthful answers.arXiv preprint arXiv:2402.06782, 2024
-
[29]
Harold W Kuhn. Extensive games and the problem of information.Contributions to the Theory of Games, 2(28):193–216, 1953. 11
work page 1953
-
[30]
The byzantine generals problem
Leslie Lamport, Robert Shostak, and Marshall Pease. The byzantine generals problem. In Concurrency: the works of leslie lamport, pages 203–226. 2019
work page 2019
-
[31]
Prompt infection: Llm-to-llm prompt injection within multi-agent systems,
Donghyun Lee and Mo Tiwari. Prompt infection: Llm-to-llm prompt injection within multi- agent systems.arXiv preprint arXiv:2410.07283, 2024
-
[32]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020
work page 2020
-
[33]
Swe-debate: Competitive multi-agent debate for software issue resolution
Han Li, Yuling Shi, Shaoxin Lin, Xiaodong Gu, Heng Lian, Xin Wang, Yantao Jia, Tao Huang, and Qianxiang Wang. Swe-debate: Competitive multi-agent debate for software issue resolution. arXiv preprint arXiv:2507.23348, 2025
-
[34]
Lin Li, Guikun Chen, Hanrong Shi, Jun Xiao, and Long Chen. A survey on multimodal benchmarks: In the era of large ai models.arXiv preprint arXiv:2409.18142, 2024
-
[35]
Improving multi-agent debate with sparse communication topology
Yunxuan Li, Yibing Du, Jiageng Zhang, Le Hou, Peter Grabowski, Yeqing Li, and Eugene Ie. Improving multi-agent debate with sparse communication topology. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 7281–7294, 2024
work page 2024
-
[36]
Encouraging divergent thinking in large language models through multi- agent debate
Tian Liang, Zhiwei He, Wenxiang Jiao, Xing Wang, Yan Wang, Rui Wang, Yujiu Yang, Shuming Shi, and Zhaopeng Tu. Encouraging divergent thinking in large language models through multi- agent debate. InProceedings of the 2024 conference on empirical methods in natural language processing, pages 17889–17904, 2024
work page 2024
-
[37]
Zijun Liu, Yanzhe Zhang, Peng Li, Yang Liu, and Diyi Yang. Dynamic llm-agent net- work: An llm-agent collaboration framework with agent team optimization.arXiv preprint arXiv:2310.02170, 2023
-
[38]
Chang Ma, Junlei Zhang, Zhihao Zhu, Cheng Yang, Yujiu Yang, Yaohui Jin, Zhenzhong Lan, Lingpeng Kong, and Junxian He. Agentboard: An analytical evaluation board of multi-turn llm agents.Advances in neural information processing systems, 37:74325–74362, 2024
work page 2024
-
[39]
Evaluating very long-term conversational memory of llm agents
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. Evaluating very long-term conversational memory of llm agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13851–13870, 2024
work page 2024
-
[40]
Yu A Malkov and Dmitry A Yashunin. Efficient and robust approximate nearest neighbor search using hierarchical navigable small world graphs.IEEE transactions on pattern analysis and machine intelligence, 42(4):824–836, 2018
work page 2018
-
[41]
Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models
Potsawee Manakul, Adian Liusie, and Mark Gales. Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 9004–9017, 2023
work page 2023
-
[42]
Small agent group is the future of digital health.arXiv preprint arXiv:2602.08013, 2026
Yuqiao Meng, Luoxi Tang, Dazheng Zhang, Rafael Brens, Elvys J Romero, Nancy Guo, Safa Elkefi, and Zhaohan Xi. Small agent group is the future of digital health.arXiv preprint arXiv:2602.08013, 2026
-
[43]
Vrushket More, Lyra Lu, Zeyu Ding, Zhaohan Xi, Seth Mizia, and Nancy L Guo. Theramind: a multi-llm ensemble for accelerating drug repurposing in lung cancer via case report mining.npj Precision Oncology, 2026
work page 2026
-
[44]
John F Nash Jr. Equilibrium points in n-person games.Proceedings of the national academy of sciences, 36(1):48–49, 1950
work page 1950
-
[45]
Memgpt: towards llms as operating systems
Charles Packer, Vivian Fang, Shishir_G Patil, Kevin Lin, Sarah Wooders, and Joseph_E Gonza- lez. Memgpt: towards llms as operating systems. 2023. 12
work page 2023
-
[46]
Generative agents: Interactive simulacra of human behavior
Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. Generative agents: Interactive simulacra of human behavior. InProceed- ings of the 36th annual acm symposium on user interface software and technology, pages 1–22, 2023
work page 2023
-
[47]
David Patterson, Joseph Gonzalez, Urs Hölzle, Quoc Le, Chen Liang, Lluis-Miquel Munguia, Daniel Rothchild, David R So, Maud Texier, and Jeff Dean. The carbon footprint of machine learning training will plateau, then shrink.Computer, 55(7):18–28, 2022
work page 2022
-
[48]
Red teaming language models with language models
Ethan Perez, Saffron Huang, Francis Song, Trevor Cai, Roman Ring, John Aslanides, Amelia Glaese, Nat McAleese, and Geoffrey Irving. Red teaming language models with language models. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 3419–3448, 2022
work page 2022
-
[49]
Scaling large language model-based multi-agent collabora- tion.arXiv preprint arXiv:2406.07155, 2024
Chen Qian, Zihao Xie, Yifei Wang, Wei Liu, Kunlun Zhu, Hanchen Xia, Yufan Dang, Zhuoyun Du, Weize Chen, Cheng Yang, et al. Scaling large language model-based multi-agent collabora- tion.arXiv preprint arXiv:2406.07155, 2024
-
[50]
Harsh Raj, Domenic Rosati, and Subhabrata Majumdar. Measuring reliability of large language models through semantic consistency.arXiv preprint arXiv:2211.05853, 2022
-
[51]
Zep: A Temporal Knowledge Graph Architecture for Agent Memory
Preston Rasmussen, Pavlo Paliychuk, Travis Beauvais, Jack Ryan, and Daniel Chalef. Zep: a temporal knowledge graph architecture for agent memory.arXiv preprint arXiv:2501.13956, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
Collaborative memory: Multi-user memory sharing in LLM agents with dynamic access control,
Alireza Rezazadeh, Zichao Li, Ange Lou, Yuying Zhao, Wei Wei, and Yujia Bao. Collaborative memory: Multi-user memory sharing in llm agents with dynamic access control.arXiv preprint arXiv:2505.18279, 2025
-
[53]
Anirban Saha, Binay Gupta, Anirban Chatterjee, and Kunal Banerjee. You believe your llm is not delusional? think again! a study of llm hallucination on foundation models under perturbation.Discover Data, 3(1):20, 2025
work page 2025
-
[54]
Mark Allen Satterthwaite. Strategy-proofness and arrow’s conditions: Existence and correspon- dence theorems for voting procedures and social welfare functions.Journal of economic theory, 10(2):187–217, 1975
work page 1975
-
[55]
Towards Understanding Sycophancy in Language Models
Mrinank Sharma, Meg Tong, Tomasz Korbak, David Duvenaud, Amanda Askell, Samuel R Bowman, Newton Cheng, Esin Durmus, Zac Hatfield-Dodds, Scott R Johnston, et al. Towards understanding sycophancy in language models.arXiv preprint arXiv:2310.13548, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[56]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning.Advances in neural information processing systems, 36:8634–8652, 2023
work page 2023
-
[57]
ALFWorld: Aligning Text and Embodied Environments for Interactive Learning
Mohit Shridhar, Xingdi Yuan, Marc-Alexandre Côté, Yonatan Bisk, Adam Trischler, and Matthew Hausknecht. Alfworld: Aligning text and embodied environments for interactive learning.arXiv preprint arXiv:2010.03768, 2020
work page internal anchor Pith review arXiv 2010
-
[58]
Andries Smit, Paul Duckworth, Nathan Grinsztajn, Thomas D Barrett, and Arnu Pretorius. Should we be going mad? a look at multi-agent debate strategies for llms.arXiv preprint arXiv:2311.17371, 2023
-
[59]
Maojia Song, Tej Deep Pala, Ruiwen Zhou, Weisheng Jin, Amir Zadeh, Chuan Li, Dorien Herremans, and Soujanya Poria. Llms can’t handle peer pressure: Crumbling under multi-agent social interactions.arXiv preprint arXiv:2508.18321, 2025
-
[60]
Gaurang Sriramanan, Siddhant Bharti, Vinu Sankar Sadasivan, Shoumik Saha, Priyatham Kattakinda, and Soheil Feizi. Llm-check: Investigating detection of hallucinations in large language models.Advances in Neural Information Processing Systems, 37:34188–34216, 2024
work page 2024
-
[61]
Cognitive architectures for language agents.Transactions on Machine Learning Research, 2023
Theodore Sumers, Shunyu Yao, Karthik R Narasimhan, and Thomas L Griffiths. Cognitive architectures for language agents.Transactions on Machine Learning Research, 2023. 13
work page 2023
-
[62]
Luoxi Tang, Yuqiao Meng, Joseph Costa, Yingxue Zhang, Muchao Ye, and Zhaohan Xi. The value of variance: Mitigating debate collapse in multi-agent systems via uncertainty-driven policy optimization.arXiv preprint arXiv:2602.07186, 2026
- [63]
-
[64]
Katherine Tian, Eric Mitchell, Allan Zhou, Archit Sharma, Rafael Rafailov, Huaxiu Yao, Chelsea Finn, and Christopher D Manning. Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages ...
work page 2023
-
[65]
Christian Tomani, Kamalika Chaudhuri, Ivan Evtimov, Daniel Cremers, and Mark Ibrahim. Uncertainty-based abstention in llms improves safety and reduces hallucinations.arXiv preprint arXiv:2404.10960, 2024
-
[66]
Memory poisoning and secure multi-agent systems
Vicenç Torra and Maria Bras-Amorós. Memory poisoning and secure multi-agent systems. arXiv preprint arXiv:2603.20357, 2026
-
[67]
Miles Turpin, Julian Michael, Ethan Perez, and Samuel Bowman. Language models don’t always say what they think: Unfaithful explanations in chain-of-thought prompting.Advances in Neural Information Processing Systems, 36:74952–74965, 2023
work page 2023
-
[68]
Fei Wang, Xingchen Wan, Ruoxi Sun, Jiefeng Chen, and Sercan O Arik. Astute rag: Over- coming imperfect retrieval augmentation and knowledge conflicts for large language models. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 30553–30571, 2025
work page 2025
-
[69]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models. arXiv preprint arXiv:2305.16291, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[70]
Learning to break: Knowledge-enhanced reasoning in multi-agent debate system
Haotian Wang, Xiyuan Du, Weijiang Yu, Qianglong Chen, Kun Zhu, Zheng Chu, Lian Yan, and Yi Guan. Learning to break: Knowledge-enhanced reasoning in multi-agent debate system. Neurocomputing, 618:129063, 2025
work page 2025
-
[71]
Madra: Multi-agent debate for risk-aware embodied planning.arXiv preprint arXiv:2511.21460, 2025
Junjian Wang, Lidan Zhao, and Xi Sheryl Zhang. Madra: Multi-agent debate for risk-aware embodied planning.arXiv preprint arXiv:2511.21460, 2025
-
[72]
Qineng Wang, Zihao Wang, Ying Su, Hanghang Tong, and Yangqiu Song. Rethinking the bounds of llm reasoning: Are multi-agent discussions the key? InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 6106–6131, 2024
work page 2024
-
[73]
Wenhui Wang, Furu Wei, Li Dong, Hangbo Bao, Nan Yang, and Ming Zhou. Minilm: Deep self-attention distillation for task-agnostic compression of pre-trained transformers.Advances in neural information processing systems, 33:5776–5788, 2020
work page 2020
-
[74]
Resolving knowledge conflicts in large language models,
Yike Wang, Shangbin Feng, Heng Wang, Weijia Shi, Vidhisha Balachandran, Tianxing He, and Yulia Tsvetkov. Resolving knowledge conflicts in large language models.arXiv preprint arXiv:2310.00935, 2023
-
[75]
Mirix: Multi-agent memory system for llm-based agents.arXiv preprint arXiv:2507.07957, 2025
Yu Wang and Xi Chen. Mirix: Multi-agent memory system for llm-based agents.arXiv preprint arXiv:2507.07957, 2025
-
[76]
Self-guard: Empower the llm to safeguard itself
Zezhong Wang, Fangkai Yang, Lu Wang, Pu Zhao, Hongru Wang, Liang Chen, Qingwei Lin, and Kam-Fai Wong. Self-guard: Empower the llm to safeguard itself. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 1648–1668, 2024
work page 2024
-
[77]
Zhenhailong Wang, Shaoguang Mao, Wenshan Wu, Tao Ge, Furu Wei, and Heng Ji. Unleashing the emergent cognitive synergy in large language models: A task-solving agent through multi- persona self-collaboration. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Vol...
work page 2024
-
[78]
Weitang Liu, Xiaoyun Wang, John Owens, and Yixuan Li
Qianshan Wei, Tengchao Yang, Yaochen Wang, Xinfeng Li, Lijun Li, Zhenfei Yin, Yi Zhan, Thorsten Holz, Zhiqiang Lin, and XiaoFeng Wang. A-memguard: A proactive defense frame- work for llm-based agent memory.arXiv preprint arXiv:2510.02373, 2025
-
[79]
Autogen: Enabling next-gen llm applications via multi-agent conversations
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, et al. Autogen: Enabling next-gen llm applications via multi-agent conversations. InFirst conference on language modeling, 2024
work page 2024
-
[80]
Yaxiong Wu, Sheng Liang, Chen Zhang, Yichao Wang, Yongyue Zhang, Huifeng Guo, Ruiming Tang, and Yong Liu. From human memory to ai memory: A survey on memory mechanisms in the era of llms.arXiv preprint arXiv:2504.15965, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.