Recognition: 2 theorem links
· Lean TheoremSmartEval: A Benchmark for Evaluating LLM-Generated Smart Contracts from Natural Language Specifications
Pith reviewed 2026-05-12 04:23 UTC · model grok-4.3
The pith
A new benchmark shows LLM-generated smart contracts score 8.29 points higher than expert ground-truth versions because of literal specification adherence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
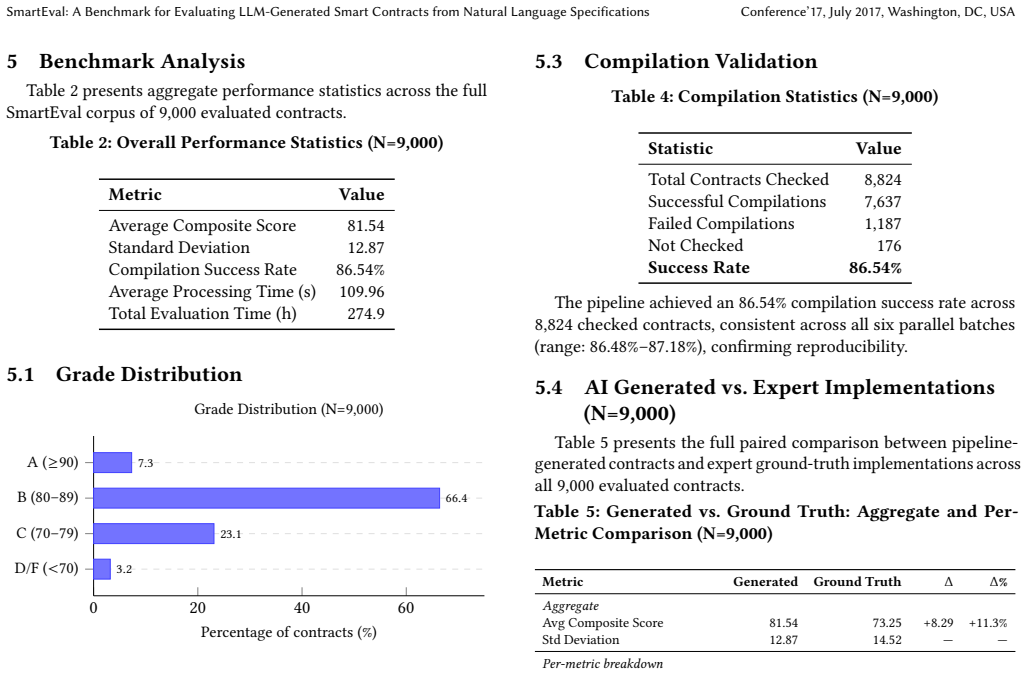
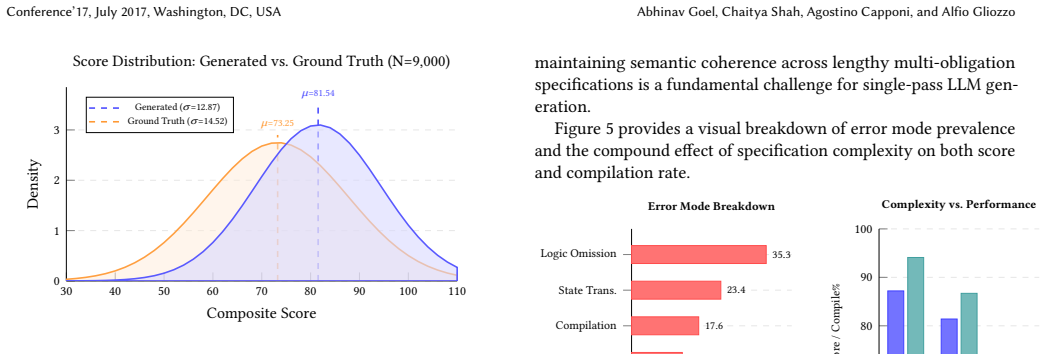
SmartEval establishes a validated benchmark that, through systematic scoring of 9,000 LLM-generated contracts against ground-truth implementations, identifies characteristic failure modes including logic omissions at 35.3 percent and state transition errors at 23.4 percent, while recording a +8.29 composite-score advantage for the generated contracts attributable to LLMs' literal following of the input specifications.
What carries the argument
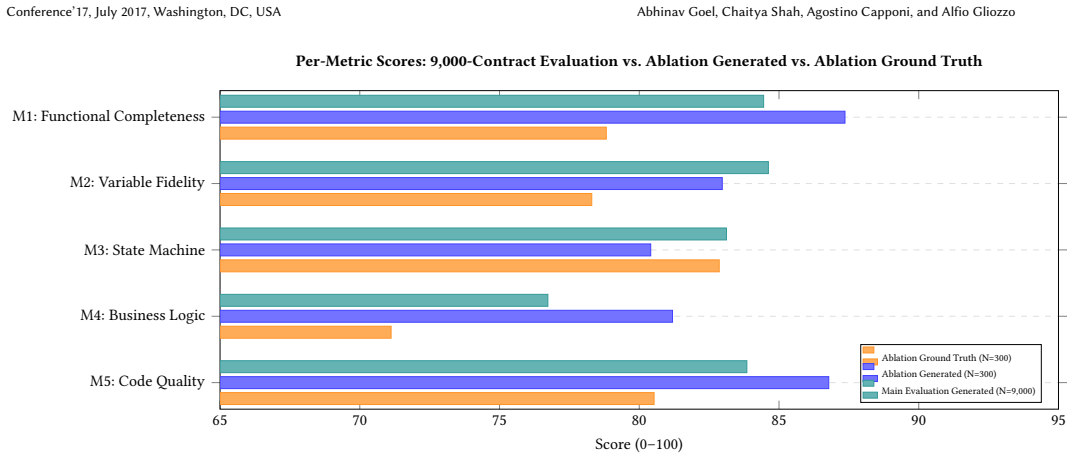
The five-dimensional evaluation rubric covering functional completeness, variable fidelity, state-machine correctness, business-logic fidelity, and code quality, applied through an automated pipeline to contracts drawn from the FSMSCG dataset.
If this is right
- Generated contracts receive higher overall scores than human-written ground truth but still exhibit systematic gaps in logic completeness and state management.
- Contract quality degrades as the complexity of the underlying natural language specification increases.
- The benchmark and its validation studies provide a foundation for empirical work on improving LLM performance in smart contract generation.
- Literal specification following explains both the scoring advantage and the specific error patterns observed.
Where Pith is reading between the lines
- Teams building smart contracts could use LLMs for initial drafts to reduce deviation from stated requirements before manual review.
- The documented failure modes point to specific areas for model fine-tuning, such as better handling of state transitions in code.
- The same evaluation approach could be adapted to test LLM code generation in other domains that rely on formal or semi-formal specifications.
Load-bearing premise
The five-dimensional rubric and automated pipeline produce scores that reflect real-world smart contract quality and security.
What would settle it
A test where contracts scoring high under the benchmark are deployed on a public testnet and exhibit security breaches or functional failures at rates that contradict the benchmark ratings.
Figures




read the original abstract
We introduce SmartEval, a benchmark for systematically evaluating the quality of Solidity smart contracts generated by large language models (LLMs) from natural language specifications. SmartEval provides a corpus of 9,000 generated contracts paired with expert-written ground-truth implementations drawn from the FSMSCG dataset, a five-dimensional evaluation rubric covering functional completeness, variable fidelity, state-machine correctness, business-logic fidelity, and code quality, and a reproducible generation-and-evaluation pipeline. To validate the benchmark's reliability, we conduct three independent empirical studies: a five-condition ablation study (N=300 per condition) isolating the contribution of each pipeline component, a human expert evaluation by three Columbia University PhD researchers confirming automated scores align with expert judgment to within 0.34 points, and external security analysis via the Slither static analyzer confirming 79.4% agreement between the LLM auditor and a non-LLM rule-based tool. Systematic analysis of 9,000 generated contracts reveals characteristic failure modes (logic omissions at 35.3%, state transition errors at 23.4%, and complexity-driven degradation) and quantifies a +8.29 composite-score advantage of generated contracts over ground-truth implementations, attributable to LLMs' literal specification-following behavior. SmartEval establishes a reproducible, validated foundation for empirical research on LLM smart contract synthesis quality, with all data, evaluation code, and generated contracts publicly released.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SmartEval, a benchmark for assessing the quality of smart contracts generated by LLMs from natural language specifications. It comprises a corpus of 9,000 generated contracts and corresponding expert-written ground-truth implementations from the FSMSCG dataset, a five-dimensional rubric (functional completeness, variable fidelity, state-machine correctness, business-logic fidelity, code quality), and an automated evaluation pipeline. The authors validate the benchmark through an ablation study (N=300 per condition), human expert evaluation by three PhD researchers (alignment within 0.34 points), and external analysis with the Slither tool (79.4% agreement). Key findings include characteristic failure modes (logic omissions at 35.3%, state transition errors at 23.4%, complexity-driven degradation) and a +8.29 composite score advantage for LLM-generated contracts over ground-truth, attributed to LLMs' literal adherence to specifications. All artifacts are publicly released.
Significance. Should the central claims hold after addressing the comments below, this paper would offer a valuable, reproducible benchmark for the growing field of LLM-assisted smart contract development. The quantified failure modes and the public release of the full dataset, code, and generated contracts are particular strengths that enable follow-on empirical research. The work helps establish empirical baselines for LLM performance in a high-stakes domain where correctness is critical.
major comments (2)
- [§4.3] §4.3 (external security analysis): The 79.4% agreement between the LLM auditor and Slither is reported without a per-vulnerability breakdown, false-negative rates on security issues, or analysis of cases where the rubric and Slither diverge. Because the five rubric dimensions do not explicitly target security properties, this leaves open the possibility that the +8.29 composite-score advantage reflects literal spec adherence while missing defects that would reverse the quality interpretation.
- [§5] §5 (results): The +8.29 composite-score advantage and failure-mode percentages (35.3% logic omissions, 23.4% state transition errors) are presented without raw per-dimension scores, the exact aggregation formula for the five rubric dimensions, statistical significance tests, or data-exclusion criteria for the 9,000-contract corpus. These omissions make it impossible to verify whether post-hoc choices affect the headline claims.
minor comments (2)
- [§4.1] The ablation study description would benefit from an explicit table listing the five conditions and their individual contributions to the final scores.
- [§3.2] Notation for the composite score in the rubric definition could be clarified with an equation showing how the five dimensions are combined.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on SmartEval. The comments identify areas where additional transparency will strengthen the manuscript. We address each major comment below and have revised the relevant sections accordingly.
read point-by-point responses
-
Referee: [§4.3] §4.3 (external security analysis): The 79.4% agreement between the LLM auditor and Slither is reported without a per-vulnerability breakdown, false-negative rates on security issues, or analysis of cases where the rubric and Slither diverge. Because the five rubric dimensions do not explicitly target security properties, this leaves open the possibility that the +8.29 composite-score advantage reflects literal spec adherence while missing defects that would reverse the quality interpretation.
Authors: We agree that the external validation section would benefit from greater detail. In the revised manuscript we add a per-vulnerability breakdown of agreement rates, report false-negative cases where Slither flags issues missed by the LLM auditor, and analyze the specific divergence instances. We also clarify that the five rubric dimensions are intentionally scoped to functional completeness, variable fidelity, state-machine correctness, business-logic fidelity, and code quality rather than explicit security properties; the +8.29 advantage is therefore measured only on those dimensions. The Slither comparison serves as an independent check on the automated pipeline rather than a comprehensive security audit. revision: yes
-
Referee: [§5] §5 (results): The +8.29 composite-score advantage and failure-mode percentages (35.3% logic omissions, 23.4% state transition errors) are presented without raw per-dimension scores, the exact aggregation formula for the five rubric dimensions, statistical significance tests, or data-exclusion criteria for the 9,000-contract corpus. These omissions make it impossible to verify whether post-hoc choices affect the headline claims.
Authors: We accept that the results presentation requires additional detail for reproducibility. The revised §5 now includes the raw per-dimension scores for both LLM-generated and ground-truth contracts, states the aggregation formula explicitly (unweighted arithmetic mean of the five normalized dimension scores), reports paired t-test results with p-values for the composite-score difference, and documents the data-exclusion criteria (non-compiling contracts and those exceeding the 8k-token generation limit, which removed 4.7% of the initial corpus). These additions enable direct verification of the reported figures and failure-mode statistics. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper defines a new benchmark (SmartEval) with an explicit five-dimensional rubric and applies it to measure scores on 9,000 LLM-generated contracts versus expert ground-truth implementations from an external dataset. The headline +8.29 composite advantage and failure-mode statistics are direct empirical outputs of this rubric applied to the generated corpus. Reliability is checked via separate human-expert alignment (Columbia PhD researchers) and agreement with the independent external Slither static analyzer; neither validation step is defined in terms of the rubric scores themselves nor reduces to a self-citation or fitted parameter. No equations, predictions, or uniqueness claims collapse by construction to the paper's own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The five-dimensional rubric (functional completeness, variable fidelity, state-machine correctness, business-logic fidelity, code quality) accurately measures smart-contract quality
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquationwashburn_uniqueness_aczel unclearfive-dimensional evaluation rubric covering functional completeness, variable fidelity, state-machine correctness, business-logic fidelity, and code quality
-
IndisputableMonolith/Foundation/RealityFromDistinctionreality_from_one_distinction unclearseverity-gated reinforcement loop and multi-agent pipeline
Reference graph
Works this paper leans on
-
[1]
Nicola Atzei, Massimo Bartoletti, and Tiziana Cimoli. 2017. A Survey of Attacks on Ethereum Smart Contracts (SoK). InProceedings of the 6th International Conference on Principles of Security and Trust. Springer, 164–186
work page 2017
-
[2]
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. 2021. Program Synthesis with Large Language Models. InarXiv preprint arXiv:2108.07732
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language Models are Few-Shot Learners.Advances in Neural Information Processing Systems33 (2020), 1877–1901
work page 2020
-
[4]
Vitalik Buterin. 2014. A Next-Generation Smart Contract and Decentralized Application Platform. InEthereum White Paper
work page 2014
-
[5]
Agostino Capponi, Garud Iyengar, and Jay Sethuraman. 2023. Decentralized Finance: Protocols, Risks, and Governance.Foundations and Trends in Privacy and Security5, 3 (2023), 144–188. doi:10.1561/3300000036
-
[6]
Huashan Chen, Marcus Pendleton, Laurent Njilla, and Shouhuai Xu. 2020. A Survey on Ethereum Systems Security: Vulnerabilities, Attacks, and Defenses. In ACM Computing Surveys, Vol. 53. ACM, 1–43
work page 2020
-
[7]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harrison Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. 2021. Evaluating Large Language Models Trained on Code. InarXiv preprint arXiv:2107.03374
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
CrewAI. 2024. CrewAI: Building Multi-Agent Systems with Ease. https://github. com/joaomdmoura/crewAI
work page 2024
-
[9]
Ethereum Foundation. 2024. Solidity Documentation. https://docs.soliditylang. org/. Accessed: 2025-01-15
work page 2024
-
[10]
Josselin Feist, Gustavo Grieco, and Alex Groce. 2019. Slither: A Static Analysis Framework for Smart Contracts.2019 IEEE/ACM 2nd International Workshop on Emerging Trends in Software Engineering for Blockchain (WETSEB)(2019), 8–15
work page 2019
-
[11]
IBM Research. 2024. IBM Agentics: A Framework for Building Agentic AI Systems. IBM Technical Report(2024)
work page 2024
-
[12]
Hao Luo, Yuhao Lin, Xiao Yan, Xintong Hu, Yuxiang Wang, Qiming Zeng, Hao Wang, and Jiawei Jiang. 2025. Guiding LLM-based Smart Contract Generation with Finite State Machine. InProceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence. IJCAI, 5869–5877. doi:10.24963/ijcai.2025/653 Main Track. Available at: https://www.ijcai...
-
[13]
Loi Luu, Duc-Hiep Chu, Hrishi Olickel, Prateek Saxena, and Aquinas Hobor
-
[14]
InProceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security
Making Smart Contracts Smarter. InProceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security. ACM, 254–269
work page 2016
-
[15]
Anastasia Mavridou and Aron Laszka. 2018. Designing Secure Ethereum Smart Contracts: A Finite State Machine Based Approach.Financial Cryptography and Data Security(2018), 523–540
work page 2018
-
[16]
Muhammad Izhar Mehar, Charles Shier, Alana Giambattista, Elgar Gong, Gabrielle Fletcher, Ryan Sanayhie, Henry M. Kim, and Marek Laskowski. 2019. Under- standing a Revolutionary and Flawed Grand Experiment in Blockchain: The DAO Attack.Journal of Cases on Information Technology21, 1 (2019), 19–32
work page 2019
-
[17]
Bernhard Mueller. 2018. Smashing Ethereum Smart Contracts for Fun and Real Profit. In9th Annual HITB Security Conference
work page 2018
-
[18]
Satoshi Nakamoto. 2008. Bitcoin: A Peer-to-Peer Electronic Cash System.Decen- tralized Business Review(2008), 21260
work page 2008
-
[19]
OpenAI. 2024. GPT-4 Technical Report.arXiv preprint arXiv:2303.08774(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiao- qing Ellen Tan, Yossi Adi, Jingyu Liu, Romain Sauvestre, Tal Remez, et al. 2024. Code Llama: Open Foundation Models for Code.arXiv preprint arXiv:2308.12950 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [21]
-
[22]
Sally Junsong Wang, Jianan Yao, Kexin Pei, Hideaki Takahashi, and Junfeng Yang
-
[23]
arXiv:2409.04597 [cs.SE] arXiv:2409.04597
Detecting Buggy Contracts via Smart Testing. arXiv:2409.04597 [cs.SE] arXiv:2409.04597
-
[24]
Gavin Wood. 2014. Ethereum: A Secure Decentralised Generalised Transaction Ledger.Ethereum Project Yellow Paper151 (2014), 1–32
work page 2014
-
[25]
Winnie Xiao, Cole Killian, Henry Sleight, Alan Chan, Nicholas Carlini, and Alwin Peng. 2025. AI Agents Find $4.6M in Blockchain Smart Contract Exploits. https://red.anthropic.com/2025/smart-contracts/. Anthropic AI Safety Research. SCONE-bench: Smart CONtracts Exploitation Benchmark
work page 2025
-
[26]
indexed": true where declared indexed in Solidity. •stateMutability is set correctly:
Zibin Zheng, Shaoan Xie, Hong-Ning Dai, Weili Chen, Xiangping Chen, Jian Weng, and Muhammad Imran. 2020. An Overview on Smart Contracts: Chal- lenges, Advances and Platforms.Future Generation Computer Systems105 (2020), 475–491. A Phase 1: Requirement Specification Agent The UniversalContractSchema captures the following fields, all extracted with exact s...
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.