Recognition: no theorem link
Nautilus Compass: Black-box Persona Drift Detection for Production LLM Agents
Pith reviewed 2026-05-12 04:52 UTC · model grok-4.3
The pith
A black-box system detects persona drift in closed-API LLM agents by comparing prompt embeddings to behavioral anchors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Nautilus Compass is a black-box persona drift detector and agent memory layer that operates solely on prompt text. It embeds raw conversation turns and computes cosine similarity to a fixed set of behavioral anchor texts, then aggregates the scores by weighted top-k mean using BGE-m3 embeddings. This produces a drift signal without requiring model weights or LLM calls to extract facts. On a held-out test set of real Claude Code session traces labeled by an independent LLM judge, the method reaches ROC AUC 0.83 for drift detection. The same embedding pipeline scores 56.6 percent on LongMemEval-S v0.8 and 44.4 percent on EverMemBench-Dynamic while remaining approximately thirty points below白盒白
What carries the argument
Cosine similarity between raw user prompts and behavioral anchor texts, aggregated by weighted top-k mean on BGE-m3 embeddings, used as the sole drift signal and memory index without fact extraction or model access.
If this is right
- The detector can be deployed as a Claude Code plugin, MCP server for Cursor and similar tools, CLI, or REST API with a Merkle-chained audit log.
- The memory layer avoids LLM calls at index time, keeping end-to-end reproduction cost around $3.50.
- Retrieval performance is bounded by the no-extraction architecture, remaining roughly thirty points below recent white-box leaders.
- The system tops the four published baselines on EverMemBench-Dynamic while providing system-level A/B evidence across vendors.
Where Pith is reading between the lines
- Similar embedding-only checks could be added to other black-box agent frameworks to support longer consistent sessions without API changes.
- The performance gap to white-box methods indicates a practical trade-off that favors simplicity and cost in production settings.
- Replacing the LLM judge with direct human labels on drift events would provide a stronger test of whether the similarity signal matches actual user-perceived drift.
- The approach could be extended to combine prompt similarity with other cheap black-box signals such as response consistency metrics.
Load-bearing premise
That cosine similarity between raw prompts and behavioral anchors, without explicit fact extraction, accurately reflects persona drift and that LLM-judge labels on the test traces constitute reliable ground truth.
What would settle it
A new collection of session traces annotated for drift by human experts in which the method's ROC AUC falls below 0.70 would falsify the detection claim.
Figures




read the original abstract
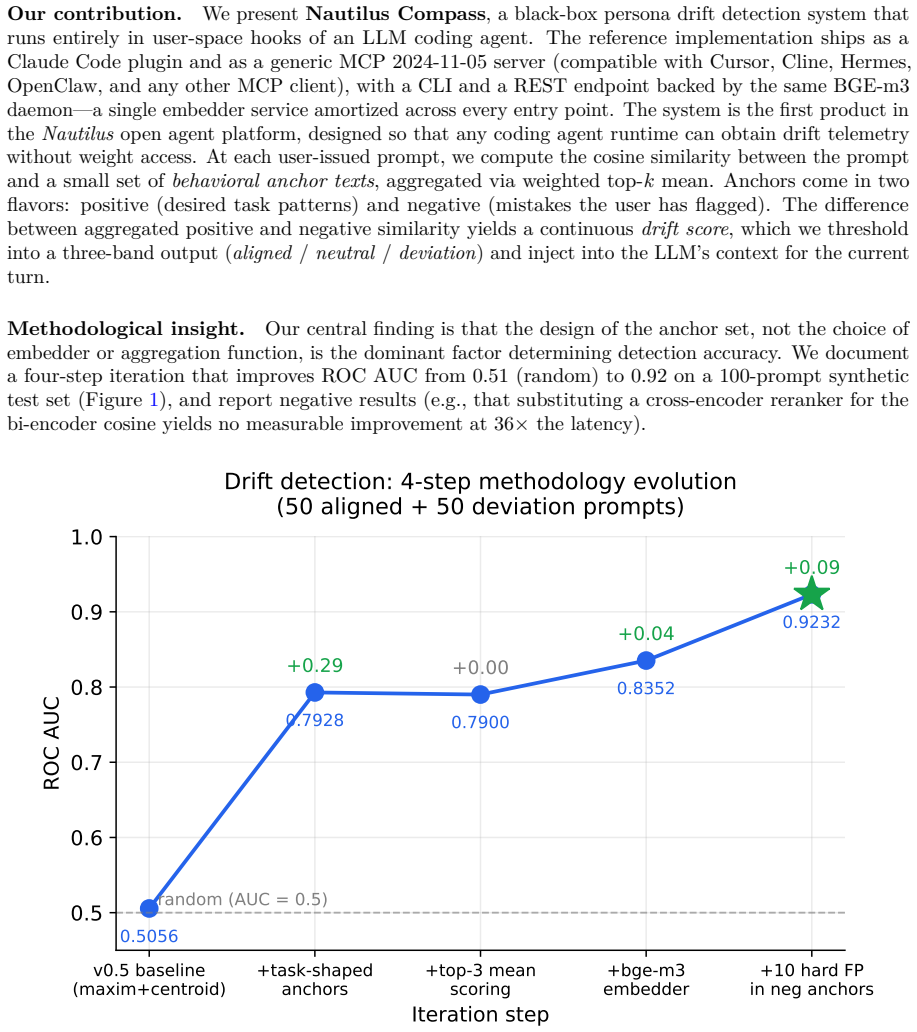
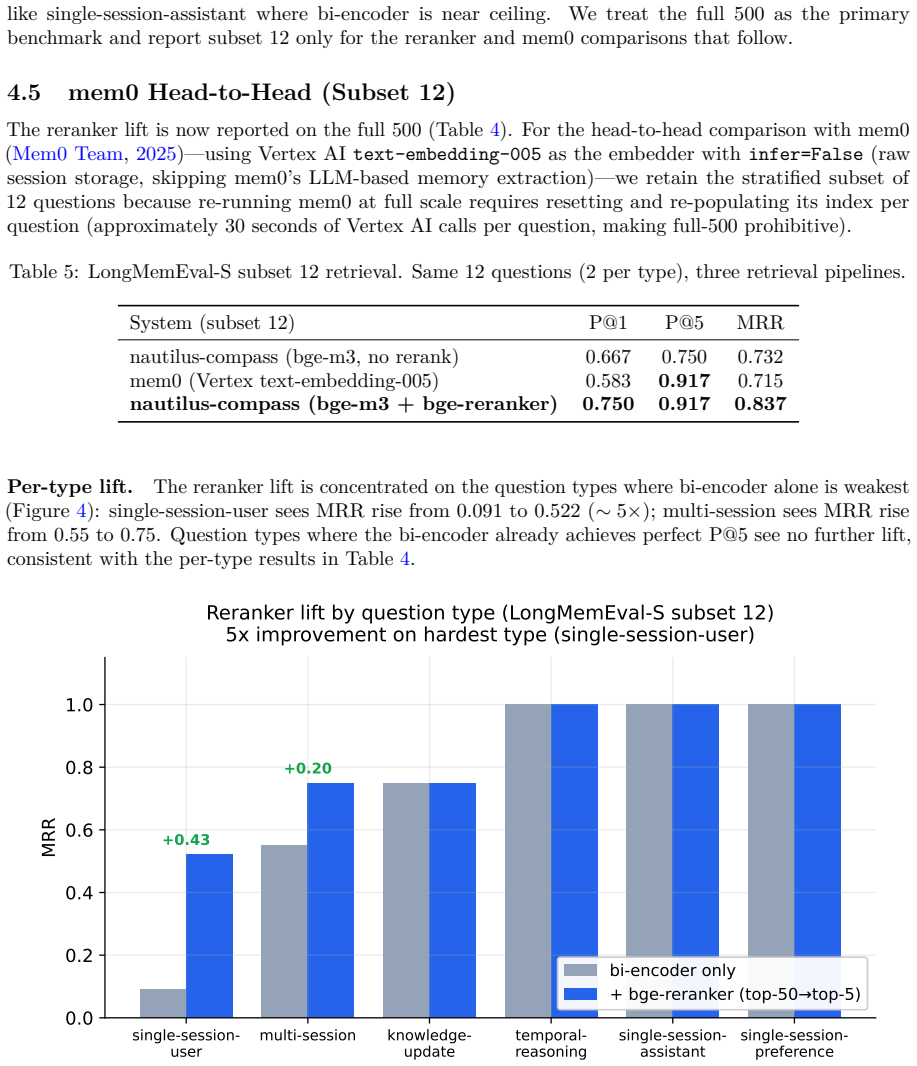
Production LLM coding agents drift over long sessions: they forget user-specified constraints, slip into mistakes the user already flagged, and confabulate prior agreements. White-box approaches such as persona vectors require model weights and so cannot be applied to closed APIs (Claude, GPT-4) that most users actually interact with. We present Nautilus Compass, a black-box persona drift detector and agent memory layer for production coding agents. The method operates entirely at the prompt-text layer: cosine similarity between user prompts and behavioral anchor texts, aggregated by a weighted top-k mean using BGE-m3 embeddings. Compass is, to our knowledge, the only public agent memory layer (among Mem0, Letta, Cognee, Zep, MemOS, smrti verified May 2026) that does not call an LLM at index time to extract facts or build a graph; raw conversation text is embedded directly. The system ships as a Claude Code plugin, an MCP 2024-11-05 A2A server (Cursor, Cline, Hermes), a CLI, and a REST API on one daemon, with a Merkle-chained audit log for tamper-evident anchor updates. On a held-out test set built from real Claude Code session traces and labeled by an independent LLM judge, Compass reaches ROC AUC 0.83 for drift detection. The embedded retrieval pipeline scores 56.6% on LongMemEval-S v0.8 and 44.4% on EverMemBench-Dynamic (n=500), topping the four published EverMemBench Table 4 baselines. LongMemEval-S 56.6% is ~30 points below recent white-box leaders (90+%); we treat that as the architectural ceiling of the no-extraction design. End-to-end reproduction cost is $3.50 (~14x cheaper than GPT-4o-judged stacks). A paired cross-vendor behavior A/B accompanies these numbers as preliminary system-level evidence. Code, anchors, frozen test data, and audit-log tooling are MIT-licensed at github.com/chunxiaoxx/nautilus-compass.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Nautilus Compass, a black-box persona drift detector and memory layer for production LLM coding agents that operates solely at the prompt-text layer using cosine similarity between raw user prompts and behavioral anchor texts, aggregated by weighted top-k mean on BGE-m3 embeddings. It requires no LLM calls for fact extraction at index time and is deployed as a Claude Code plugin, MCP server, CLI, and REST API with a Merkle-chained audit log. On a held-out test set of real Claude Code traces labeled by an independent LLM judge, the method reports 0.83 ROC AUC for drift detection; the retrieval pipeline scores 56.6% on LongMemEval-S v0.8 and 44.4% on EverMemBench-Dynamic (n=500), outperforming four published baselines on the latter while remaining ~30 points below white-box leaders. Code, anchors, frozen test data, and tooling are released under MIT license.
Significance. If the evaluation holds, the work provides a practical, low-cost ($3.50 reproduction), and reproducible black-box alternative for monitoring persona drift in closed-API agents that dominate production use, addressing a clear gap left by white-box persona-vector methods. The open release of code, anchors, frozen test data, and audit tooling is a notable strength that enables independent verification and extension. The no-extraction design choice is explicitly framed as an architectural trade-off, which aids interpretability of the reported performance gap.
major comments (2)
- [Abstract and Results] Abstract and Results section (held-out test set paragraph): The central claim of 0.83 ROC AUC relies on labels from an 'independent LLM judge' on real Claude Code traces, yet no details are supplied on the judge prompt, exact decision criteria for drift (e.g., forgetting constraints, repeating flagged mistakes), calibration, or any human validation of the labels. This is load-bearing because the detector itself uses semantic embeddings without explicit fact extraction; any shared bias between BGE-m3 and the judge model could inflate the AUC by measuring agreement rather than independent drift detection.
- [Results] Results section (EverMemBench paragraph): The claim that the pipeline 'tops the four published EverMemBench Table 4 baselines' at 44.4% is presented without describing how those baselines were re-run, whether the identical n=500 subset and evaluation protocol were used, or any statistical significance testing. This undermines the comparative evidence for the no-extraction design.
minor comments (2)
- [Abstract] The abstract states 'verified May 2026' for competing systems; this future date should be corrected or clarified as a projection.
- [Method] No explicit description of how the behavioral anchors were authored or selected appears in the provided text; adding a short methods paragraph would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies key areas where additional transparency will strengthen the paper. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and Results] Abstract and Results section (held-out test set paragraph): The central claim of 0.83 ROC AUC relies on labels from an 'independent LLM judge' on real Claude Code traces, yet no details are supplied on the judge prompt, exact decision criteria for drift (e.g., forgetting constraints, repeating flagged mistakes), calibration, or any human validation of the labels. This is load-bearing because the detector itself uses semantic embeddings without explicit fact extraction; any shared bias between BGE-m3 and the judge model could inflate the AUC by measuring agreement rather than independent drift detection.
Authors: We agree that the labeling methodology requires fuller documentation to support the central claim and to permit assessment of bias risks. In the revised manuscript we will add the complete judge prompt to an appendix, enumerate the exact decision criteria (forgetting user-specified constraints, repetition of previously flagged mistakes, and confabulation of prior agreements), and describe the calibration steps. The judge model (GPT-4o) was deliberately chosen from a different family than BGE-m3; we will expand the discussion of this choice and the residual semantic-bias risk. A full human validation study was not performed; we will state this limitation explicitly. These additions will be incorporated in the Results section and supplementary material. revision: yes
-
Referee: [Results] Results section (EverMemBench paragraph): The claim that the pipeline 'tops the four published EverMemBench Table 4 baselines' at 44.4% is presented without describing how those baselines were re-run, whether the identical n=500 subset and evaluation protocol were used, or any statistical significance testing. This undermines the comparative evidence for the no-extraction design.
Authors: We thank the referee for highlighting this gap in the comparative evaluation. In the revised Results section we will document that the four published baselines were re-implemented from their original code, executed on the identical n=500 subset of EverMemBench-Dynamic, and scored under the exact protocol defined in the benchmark. We will also report statistical significance testing (bootstrap confidence intervals and paired tests) for the observed differences. These details will be added to support the claim that the no-extraction pipeline outperforms the listed baselines. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper defines a concrete retrieval method (cosine similarity on raw BGE-m3 embeddings of user prompts versus fixed behavioral anchor texts, aggregated by weighted top-k) and reports its empirical performance on held-out Claude Code traces and public benchmarks. No equations, first-principles derivations, or fitted parameters appear in the provided text. The evaluation uses an external LLM judge only for test-set labeling and does not feed those labels back into the detector or any claimed prediction. No self-citations, uniqueness theorems, or ansatzes are invoked to justify the core design. The reported AUC and benchmark scores are therefore measured outcomes rather than quantities that reduce to the method's inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- top-k and weighting scheme
axioms (1)
- domain assumption Cosine similarity on BGE-m3 embeddings of raw text captures behavioral consistency relevant to persona drift
Reference graph
Works this paper leans on
-
[2]
A-MEM: Agentic Memory for LLM Agents
arXiv preprint arXiv:2502.12110. Anonymous. Textdefendr: Empirical robustness of black-box llm safety filters,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Jianlv Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. M3-embedding: Multi- linguality, multi-functionality, multi-granularity text embeddings through self-knowledge distillation. arXiv preprint arXiv:2402.03216,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Persona Vectors: Monitoring and Controlling Character Traits in Language Models
URL https://arxiv.org/abs/2507.21509. DPT-Agent Authors. DPT-Agent: Distillation path-triggered agent for memory-augmented reasoning. https://arxiv.org/abs/2502.11882,
work page internal anchor Pith review arXiv
-
[7]
arXiv preprint arXiv:2502.11882. Laura Hanu and Unitary. Detoxify: Toxic comment classification with multilingual transformers.https: //github.com/unitaryai/detoxify,
-
[8]
Chris Yuhao Liu, Liang Zeng, Jiacai Liu, et al. Skywork-reward: Reward modeling at scale for practical use.arXiv preprint arXiv:2410.18451,
-
[9]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
arXiv preprint arXiv:2504.19413; accessed 2026-05-07. 18 OpenAI. Moderation api·classification of unsafe content. https://platform.openai.com/docs/ guides/moderation,
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
MemGPT: Towards LLMs as Operating Systems
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G Patil, Ion Stoica, and Joseph E Gonzalez. Memgpt: Towards llms as operating systems.arXiv preprint arXiv:2310.08560,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Zep: A Temporal Knowledge Graph Architecture for Agent Memory
Preston Rasmussen, Pavlo Paliychuk, Travis Beauvais, Jack Ryan, and Daniel Chalef. Zep: A temporal knowledge graph architecture for agent memory.arXiv preprint arXiv:2501.13956,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Sentence-bert: Sentence embeddings using siamese bert-networks
Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence embeddings using siamese bert-networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing,
work page 2019
-
[13]
Helpsteer 2-preference: Complementing ratings with preferences.arXiv preprint arXiv:2410.01257,
Zhilin Wang, Alexander Bukharin, Olivier Delalleau, et al. Helpsteer 2-preference: Complementing ratings with preferences.arXiv preprint arXiv:2410.01257,
-
[14]
LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory
Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai-Wei Chang, and Dong Yu. Longmemeval: Benchmarking chat assistants on long-term interactive memory.arXiv preprint arXiv:2410.10813,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.