Recognition: 2 theorem links
· Lean TheoremHAGE: Harnessing Agentic Memory via RL-Driven Weighted Graph Evolution
Pith reviewed 2026-05-12 04:09 UTC · model grok-4.3
The pith
HAGE enables better long-horizon LLM reasoning by turning memory retrieval into adaptive traversal over RL-optimized weighted relational graphs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
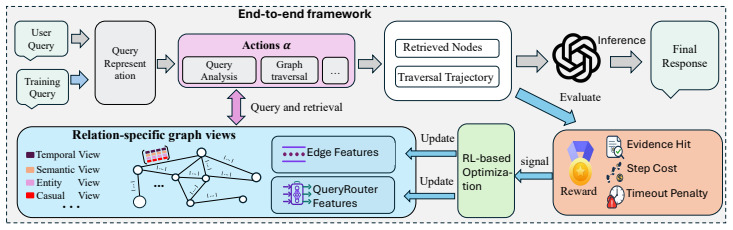
HAGE is a weighted multi-relational memory framework that reconceptualizes retrieval as sequential, query-conditioned traversal over a unified relational memory graph, with LLM intent classification and a routing network modulating trainable edge feature vectors, all jointly optimized via reinforcement learning on downstream task performance.
What carries the argument
Query-conditioned routing network that modulates trainable relation feature vectors on edges of a unified multi-relational memory graph, with RL optimizing the representations for traversal utility.
If this is right
- Agents achieve higher accuracy on extended multi-step reasoning by prioritizing high-utility relational paths during retrieval.
- Memory use becomes more efficient as the system softly suppresses noisy or low-relevance edges based on query context.
- The memory graph adapts its edge weights to the distribution of tasks encountered during RL training.
- A more favorable accuracy-efficiency trade-off emerges compared to flat vector search or fixed binary graphs.
Where Pith is reading between the lines
- The approach implies that memory in agents benefits from continuous, query-dependent relationship strengths rather than static structures.
- Similar RL-driven graph evolution could be tested in other structured knowledge settings such as knowledge bases or experience replay.
- Online versions of the framework might allow agents to refine their memory graphs continuously during deployment without separate training phases.
Load-bearing premise
The combination of an LLM-based relational intent classifier, query routing network, and RL-driven edge optimization will reliably improve traversal quality without overfitting to training tasks or destabilizing the learned graph structure.
What would settle it
Evaluation on a fresh set of long-horizon reasoning tasks held out from RL training, measuring whether accuracy gains and efficiency advantages over baselines disappear or reverse.
Figures

read the original abstract
Memory retrieval in agentic large language model (LLM) systems is often treated as a static lookup problem, relying on flat vector search or fixed binary relational graphs. However, fixed graph structures cannot capture the varying strength, confidence, and query-dependent relevance of relationships between events. In this paper, we propose HAGE, a weighted multi-relational memory framework that reconceptualizes retrieval as sequential, query-conditioned traversal over a unified relational memory graph. Memory is organized as relation-specific graph views over shared memory nodes, where each edge is associated with a trainable relation feature vector encoding multiple relational signals. Given a query, an LLM-based classifier identifies the relational intent, and a routing network dynamically modulates the corresponding dimensions of the edge embedding. Traversal scores are computed via a learned combination of semantic similarity and these query-conditioned edge representations. This allows memory traversal to prioritize high-utility relational paths while softly suppressing noisy or weakly relevant connections. Beyond adaptive traversal, HAGE further introduces a reinforcement learning-based training framework that jointly optimizes routing behavior and edge representations using downstream tasks. Finally, empirical results demonstrate improved long-horizon reasoning accuracy and a favorable accuracy-efficiency trade-off compared to state-of-the-art agentic memory systems. Our code is available at https://github.com/FredJiang0324/HAGE_MVPReview.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes HAGE, a weighted multi-relational memory framework for agentic LLMs that organizes memory as relation-specific graph views over shared nodes with trainable edge feature vectors. An LLM-based classifier identifies relational intent from a query, a routing network modulates edge embeddings, and traversal scores combine semantic similarity with query-conditioned representations. The system is trained via reinforcement learning to jointly optimize routing behavior and edge weights on downstream task rewards, with the abstract claiming improved long-horizon reasoning accuracy and a favorable accuracy-efficiency trade-off versus prior agentic memory systems.
Significance. If the empirical results hold under rigorous validation, HAGE would represent a meaningful advance in dynamic memory retrieval for long-horizon agentic reasoning by replacing static graphs or flat vector search with query-adaptive, RL-evolved weighted structures. The joint optimization of relation features and routing is a technically interesting direction that could improve both accuracy and efficiency in complex tasks.
major comments (2)
- [Abstract] Abstract: the central claim of improved long-horizon reasoning accuracy and accuracy-efficiency trade-offs rests entirely on empirical results, yet the abstract supplies no quantitative metrics, baselines, datasets, ablation studies, or statistical significance tests. This prevents assessment of whether the data support the stated gains.
- [Method] RL training framework (described in the method section): edge representations and routing behavior are optimized directly via policy gradients on downstream LLM reasoning rewards. No mention is made of variance-reduction techniques (baseline subtraction, entropy regularization) or multi-seed reporting, which are required to establish that the learned graph structure is stable rather than high-variance or overfit to the finite training query distribution.
minor comments (1)
- [Abstract] The code repository link is provided, which supports reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract and the RL training framework. We address each major comment point by point below and will incorporate revisions to strengthen the presentation of results and training details.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of improved long-horizon reasoning accuracy and accuracy-efficiency trade-offs rests entirely on empirical results, yet the abstract supplies no quantitative metrics, baselines, datasets, ablation studies, or statistical significance tests. This prevents assessment of whether the data support the stated gains.
Authors: We agree that the abstract would be strengthened by including concrete quantitative support for the claims. In the revised version we will add specific metrics (e.g., accuracy improvements on long-horizon tasks, comparison to listed baselines, and the primary datasets), while keeping the abstract concise. Detailed ablation tables and statistical tests will remain in the main body but will be referenced briefly in the abstract to allow readers to evaluate the reported gains. revision: yes
-
Referee: [Method] RL training framework (described in the method section): edge representations and routing behavior are optimized directly via policy gradients on downstream LLM reasoning rewards. No mention is made of variance-reduction techniques (baseline subtraction, entropy regularization) or multi-seed reporting, which are required to establish that the learned graph structure is stable rather than high-variance or overfit to the finite training query distribution.
Authors: The referee correctly notes the absence of these details in the current text. Our implementation does employ entropy regularization and a learned value baseline for variance reduction in the policy-gradient updates, and all reported results were obtained across multiple random seeds. We will revise the method section to explicitly describe these variance-reduction techniques and will add multi-seed statistics (mean and standard deviation) for the key performance metrics to demonstrate stability of the learned edge weights and routing policy. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper describes an empirical method: an LLM classifier, query-conditioned routing network, and RL optimization of edge features and routing using downstream task rewards, followed by reported accuracy/efficiency gains versus SOTA baselines. No equations, first-principles derivations, or predictions are presented that reduce by construction to the fitted inputs. The optimization is a standard RL training step whose outputs are then evaluated empirically; no self-definitional loop, fitted-input-renamed-as-prediction, or load-bearing self-citation chain is quoted or exhibited. The central claims rest on experimental comparisons rather than any tautological reduction.
Axiom & Free-Parameter Ledger
free parameters (2)
- relation feature vectors
- routing network weights
axioms (2)
- domain assumption An LLM-based classifier can reliably identify the dominant relational intent of a query.
- domain assumption Reinforcement learning will converge to stable and useful edge representations and routing policies.
invented entities (1)
-
Weighted multi-relational memory graph with query-conditioned edge modulation
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearTraversal scores are computed via a learned combination of semantic similarity and these query-conditioned edge representations... reinforcement learning-based training framework that jointly optimizes routing behavior and edge representations
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearHAGE is built on two key principles... weighted multi-relational memory graph... RL-based optimization
Reference graph
Works this paper leans on
-
[1]
SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning
SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning , author=. arXiv preprint arXiv:2602.08234 , year=
work page internal anchor Pith review arXiv
-
[2]
MemSkill: Learning and Evolving Memory Skills for Self-Evolving Agents
MemSkill: Learning and Evolving Memory Skills for Self-Evolving Agents , author=. arXiv preprint arXiv:2602.02474 , year=
work page internal anchor Pith review arXiv
- [3]
-
[4]
arXiv preprint arXiv:2507.07957 , year=
Mirix: Multi-agent memory system for llm-based agents , author=. arXiv preprint arXiv:2507.07957 , year=
-
[5]
A-MEM: Agentic Memory for LLM Agents
A-mem: Agentic memory for llm agents , author=. arXiv preprint arXiv:2502.12110 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Mem0: Building production-ready ai agents with scalable long-term memory , author=. arXiv preprint arXiv:2504.19413 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
What Deserves Memory: Adaptive Memory Distillation for LLM Agents
Nemori: Self-organizing agent memory inspired by cognitive science , author=. arXiv preprint arXiv:2508.03341 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
MemOS: A memory OS for AI system.arXiv preprintarXiv:2507.03724, 2025
MemOS: A Memory OS for AI System , author=. arXiv preprint arXiv:2507.03724 , year=
-
[9]
Zep: A Temporal Knowledge Graph Architecture for Agent Memory
Zep: a temporal knowledge graph architecture for agent memory , author=. arXiv preprint arXiv:2501.13956 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Memory OS of AI Agent , author=. arXiv preprint arXiv:2506.06326 , year=
-
[11]
2024 IEEE International Conference on Knowledge Graph (ICKG) , pages=
Emotional RAG: Enhancing role-playing agents through emotional retrieval , author=. 2024 IEEE International Conference on Knowledge Graph (ICKG) , pages=. 2024 , organization=
work page 2024
-
[12]
Evaluating Very Long-Term Conversational Memory of LLM Agents
Evaluating very long-term conversational memory of llm agents , author=. arXiv preprint arXiv:2402.17753 , year=
work page internal anchor Pith review arXiv
-
[13]
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
From local to global: A graph rag approach to query-focused summarization , author=. arXiv preprint arXiv:2404.16130 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Advances in Neural Information Processing Systems , volume=
Hipporag: Neurobiologically inspired long-term memory for large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory
Longmemeval: Benchmarking chat assistants on long-term interactive memory , author=. arXiv preprint arXiv:2410.10813 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
2024 2nd International Conference on Foundation and Large Language Models (FLLM) , year=
Self-Reflection in Large Language Model Agents: Effects on Problem-Solving Performance , author=. 2024 2nd International Conference on Foundation and Large Language Models (FLLM) , year=
work page 2024
-
[17]
Self-reflection in llm agents: Effects on problem-solving performance , author=. arXiv preprint arXiv:2405.06682 , year=
-
[18]
arXiv preprint arXiv:2602.13594 , year=
Hippocampus: An efficient and scalable memory module for agentic ai , author=. arXiv preprint arXiv:2602.13594 , year=
-
[19]
Proceedings of the AAAI conference on artificial intelligence , volume=
Memorybank: Enhancing large language models with long-term memory , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[20]
arXiv:2306.03901 [cs.AI] https://arxiv.org/abs/2306.03901
Chatdb: Augmenting llms with databases as their symbolic memory , author=. arXiv preprint arXiv:2306.03901 , year=
-
[21]
Think-in- memory: Recalling and post-thinking enable llms with long-term memory
Think-in-memory: Recalling and post-thinking enable llms with long-term memory , author=. arXiv preprint arXiv:2311.08719 , year=
-
[22]
Advances in Neural Information Processing Systems , volume=
Reflexion: Language agents with verbal reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
- [23]
-
[24]
arXiv preprint arXiv:2304.13343 , year=
Enhancing large language model with self-controlled memory framework , author=. arXiv preprint arXiv:2304.13343 , year=
-
[25]
Proceedings of the 36th annual acm symposium on user interface software and technology , pages=
Generative agents: Interactive simulacra of human behavior , author=. Proceedings of the 36th annual acm symposium on user interface software and technology , pages=
-
[26]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Voyager: An open-ended embodied agent with large language models , author=. arXiv preprint arXiv:2305.16291 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Transactions of the Association for Computational Linguistics , volume=
Lost in the middle: How language models use long contexts , author=. Transactions of the Association for Computational Linguistics , volume=
-
[30]
Advances in neural information processing systems , volume=
Judging llm-as-a-judge with mt-bench and chatbot arena , author=. Advances in neural information processing systems , volume=
-
[31]
Survey of Hallucination in Natural Language Generation , author=. ACM Computing Surveys , year=
-
[32]
Advances in neural information processing systems , volume=
Retrieval-augmented generation for knowledge-intensive nlp tasks , author=. Advances in neural information processing systems , volume=
-
[33]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[34]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[35]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[36]
Longformer: The Long-Document Transformer
Longformer: The long-document transformer , author=. arXiv preprint arXiv:2004.05150 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[37]
arXiv preprint arXiv:1805.04623 , year=
Sharp nearby, fuzzy far away: How neural language models use context , author=. arXiv preprint arXiv:1805.04623 , year=
-
[38]
Proceedings of the 3rd Workshop on Natural Language Processing for Conversational AI , pages=
Investigating pretrained language models for graph-to-text generation , author=. Proceedings of the 3rd Workshop on Natural Language Processing for Conversational AI , pages=
-
[39]
Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation
Train short, test long: Attention with linear biases enables input length extrapolation , author=. arXiv preprint arXiv:2108.12409 , year=
work page internal anchor Pith review arXiv
-
[40]
Trends in cognitive sciences , volume=
What learning systems do intelligent agents need? Complementary learning systems theory updated , author=. Trends in cognitive sciences , volume=. 2016 , publisher=
work page 2016
-
[41]
and Clarke, Charles L A and Buettcher, Stefan , month = jul, year =
Cormack, Gordon V. and Clarke, Charles L A and Buettcher, Stefan , title =. Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval , pages =. 2009 , isbn =. doi:10.1145/1571941.1572114 , abstract =
-
[42]
A Comprehensive Survey of Graph Neural Networks for Knowledge Graphs , author=. IEEE Access , volume=. 2022 , publisher=
work page 2022
-
[43]
arXiv preprint arXiv:2502.06049 , year=
Lm2: Large memory models , author=. arXiv preprint arXiv:2502.06049 , year=
-
[44]
Proceedings of the ACM on Web Conference 2025 , pages=
Memorag: Boosting long context processing with global memory-enhanced retrieval augmentation , author=. Proceedings of the ACM on Web Conference 2025 , pages=
work page 2025
-
[45]
Proceedings of the 52nd Annual International Symposium on Computer Architecture , pages=
Rago: Systematic performance optimization for retrieval-augmented generation serving , author=. Proceedings of the 52nd Annual International Symposium on Computer Architecture , pages=
-
[46]
M-RAG: Reinforcing large language model performance through retrieval-augmented generation with multiple partitions , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[47]
arXiv preprint arXiv:2406.15319
Longrag: Enhancing retrieval-augmented generation with long-context llms , author=. arXiv preprint arXiv:2406.15319 , year=
-
[48]
From rag to memory: Non-parametric continual learning for large language models , author=. arXiv preprint arXiv:2502.14802 , year=
-
[49]
arXiv preprint arXiv:2511.02919 , year=
Cache Mechanism for Agent RAG Systems , author=. arXiv preprint arXiv:2511.02919 , year=
-
[50]
Transactions on Machine Learning Research , year=
Causal reasoning and large language models: Opening a new frontier for causality , author=. Transactions on Machine Learning Research , year=
-
[51]
Advances in Neural Information Processing Systems , volume=
Cladder: Assessing causal reasoning in language models , author=. Advances in Neural Information Processing Systems , volume=
-
[52]
ACM Computing Surveys , volume=
Igniting language intelligence: The hitchhiker’s guide from chain-of-thought reasoning to language agents , author=. ACM Computing Surveys , volume=. 2025 , publisher=
work page 2025
-
[53]
IEEE Transactions on Big Data , volume=
Billion-scale similarity search with GPUs , author=. IEEE Transactions on Big Data , volume=. 2019 , publisher=
work page 2019
-
[54]
Sequence-to-sequence learning as beam-search optimization , author=. arXiv preprint arXiv:1606.02960 , year=
-
[55]
B leu: a Method for Automatic Evaluation of Machine Translation
Papineni, Kishore and Roukos, Salim and Ward, Todd and Zhu, Wei-Jing. B leu: a Method for Automatic Evaluation of Machine Translation. Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics. 2002. doi:10.3115/1073083.1073135
-
[56]
Computational Linguistics , pages=
Siren’s Song in the AI Ocean: A Survey on Hallucination in Large Language Models , author=. Computational Linguistics , pages=. 2025 , publisher=
work page 2025
-
[57]
The Twelfth International Conference on Learning Representations , year=
Gaia: a benchmark for general ai assistants , author=. The Twelfth International Conference on Learning Representations , year=
-
[58]
AgentBench: Evaluating LLMs as Agents
Agentbench: Evaluating llms as agents , author=. arXiv preprint arXiv:2308.03688 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[59]
IEEE Transactions on Knowledge and Data Engineering , volume=
Unifying large language models and knowledge graphs: A roadmap , author=. IEEE Transactions on Knowledge and Data Engineering , volume=. 2024 , publisher=
work page 2024
-
[60]
Revisiting relation extraction in the era of large language models , author=. Proceedings of the conference. association for computational linguistics. meeting , volume=
-
[61]
Science China Information Sciences , volume=
The rise and potential of large language model based agents: A survey , author=. Science China Information Sciences , volume=. 2025 , publisher=
work page 2025
-
[62]
Memory in the Age of AI Agents
Memory in the Age of AI Agents , author=. arXiv preprint arXiv:2512.13564 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[63]
Proceedings of the 2018 conference on empirical methods in natural language processing , pages=
HotpotQA: A dataset for diverse, explainable multi-hop question answering , author=. Proceedings of the 2018 conference on empirical methods in natural language processing , pages=
work page 2018
-
[64]
MAGMA: A Multi-Graph based Agentic Memory Architecture for AI Agents
MAGMA: A Multi-Graph based Agentic Memory Architecture for AI Agents , author=. arXiv preprint arXiv:2601.03236 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[65]
International conference on machine learning , pages=
Improving language models by retrieving from trillions of tokens , author=. International conference on machine learning , pages=. 2022 , organization=
work page 2022
-
[66]
Advances in neural information processing systems , volume=
Minilm: Deep self-attention distillation for task-agnostic compression of pre-trained transformers , author=. Advances in neural information processing systems , volume=
-
[67]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[68]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[69]
Sentence-bert: Sentence embeddings using siamese bert-networks , author=. Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP) , pages=
work page 2019
-
[70]
Adam: A Method for Stochastic Optimization
Adam: A method for stochastic optimization , author=. arXiv preprint arXiv:1412.6980 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[71]
Gpt-4o system card , author=. arXiv preprint arXiv:2410.21276 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[72]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[73]
arXiv preprint arXiv:2407.04363 , year =
Arigraph: Learning knowledge graph world models with episodic memory for llm agents , author=. arXiv preprint arXiv:2407.04363 , year=
-
[74]
arXiv preprint arXiv:2511.18423 , year=
General agentic memory via deep research , author=. arXiv preprint arXiv:2511.18423 , year=
-
[75]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Crafting personalized agents through retrieval-augmented generation on editable memory graphs , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2024
-
[76]
GAM: Hierarchical Graph-based Agentic Memory for LLM Agents
GAM: Hierarchical Graph-based Agentic Memory for LLM Agents , author=. arXiv preprint arXiv:2604.12285 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[77]
Agentic memory: Learning unified long-term and short-term memory management for large language model agents , author=. arXiv preprint arXiv:2601.01885 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[78]
How to reconstruct (anonymously) a secret cellular automaton
How to reconstruct (anonymously) a secret cellular automaton , author=. arXiv preprint arXiv:2604.11362 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[79]
ReAct: Synergizing Reasoning and Acting in Language Models
React: Synergizing reasoning and acting in language models , author=. arXiv preprint arXiv:2210.03629 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[80]
Advances in neural information processing systems , volume=
Hipporag: Neurobiologically inspired long-term memory for large language models , author=. Advances in neural information processing systems , volume=
-
[81]
arXiv preprint arXiv:2512.09487 , year=
RouteRAG: Efficient Retrieval-Augmented Generation from Text and Graph via Reinforcement Learning , author=. arXiv preprint arXiv:2512.09487 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.