Recognition: 2 theorem links
· Lean TheoremLoopVLA: Learning Sufficiency in Recurrent Refinement for Vision-Language-Action Models
Pith reviewed 2026-05-12 04:03 UTC · model grok-4.3
The pith
A recurrent shared transformer with learned sufficiency scores lets VLA models exit early, cutting parameters 45 percent while keeping task success.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
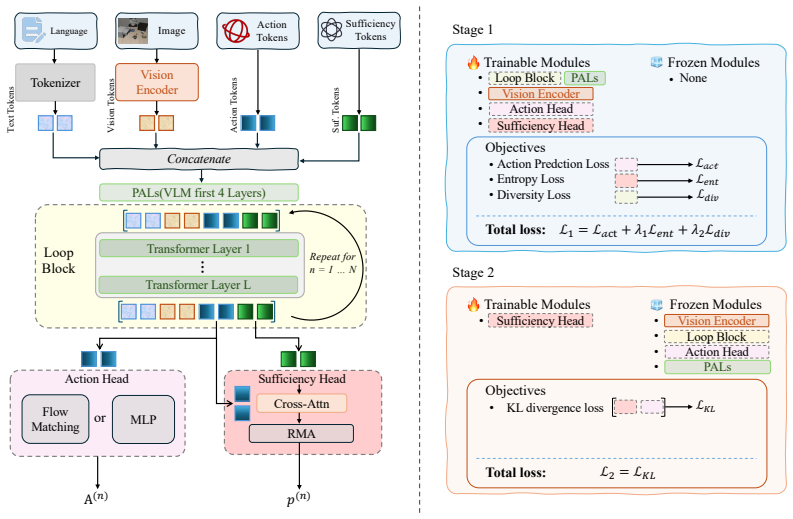
LoopVLA establishes that representation sufficiency for action prediction can be learned end-to-end inside a recurrent refinement process: a shared transformer block is applied repeatedly to the same multimodal tokens, each iteration produces an action head and a scalar sufficiency estimate, and a self-supervised distribution-alignment loss forces the sufficiency scores to track the monotonic improvement in action quality, thereby supplying a reliable early-exit signal that decouples computation depth from fixed layer indices.
What carries the argument
Shared recurrent Transformer block that refines multimodal tokens over iterations while outputting both an action prediction and a sufficiency score trained via self-supervised distribution alignment to relative action quality.
If this is right
- Inference throughput scales with input difficulty because the loop can terminate after few iterations on easy observations.
- Model size shrinks because parameters are shared across all refinement steps rather than duplicated per layer.
- Training jointly optimizes refinement depth, action accuracy, and stopping without requiring separate supervision for exits.
- The same weights generalize across tasks because sufficiency is grounded in the evolving representation rather than hand-crafted rules.
- Variable-depth execution becomes possible at deployment without retraining or post-hoc calibration.
Where Pith is reading between the lines
- The same sufficiency-learning pattern could be applied to other control policies where early layers preserve spatial detail that deep abstraction discards.
- Because the stopping signal is generated from the policy's own improvement curve, the method may transfer to new robot embodiments with minimal additional data.
- Hardware schedulers could use the real-time sufficiency score to allocate compute budgets dynamically in multi-robot systems.
- Extending the loop to include explicit uncertainty estimates might further improve robustness on out-of-distribution scenes.
Load-bearing premise
The self-supervised distribution alignment between sufficiency scores and relative action quality across refinement steps will produce a stopping signal that correctly identifies when further iterations add no value.
What would settle it
Run the model on a new set of manipulation tasks with early exits triggered by the learned sufficiency scores; if success rate drops below that of the fixed-depth baseline while the scores fail to correlate with measured action improvement, the sufficiency learning claim is falsified.
Figures




read the original abstract
Current Vision-Language-Action (VLA) models typically treat the deepest representation of a vision-language backbone as universally optimal for action prediction. However, robotic manipulation is composed of many frequent closed-loop spatial adjustments, for which excessive abstraction may waste computation and weaken low-level geometric cues essential for precise control. Existing early-exit strategies attempt to reduce computation by stopping at predefined layers or applying heuristic rules such as action consistency, but they do not directly answer when a representation is actually sufficient for action. In this paper, we present LoopVLA, a recurrent VLA architecture that jointly learns representation refinement, action prediction, and sufficiency estimation. LoopVLA iteratively applies a shared Transformer block to refine multimodal tokens, and at each iteration produces both a candidate action and a sufficiency score that estimates whether further refinement is necessary. By sharing parameters across iterations, LoopVLA decouples refinement from absolute layer indices and grounds sufficiency estimation in the evolving representation itself. Since sufficiency has no direct supervision, we introduce a self-supervised distribution alignment objective, where intermediate confidence scores are trained to match the relative action quality across refinement steps, thereby linking sufficiency learning to policy optimization signals. Experiments on LIBERO, LIBERO-Plus, and VLA-Arena show that LoopVLA pushes the efficiency-performance frontier of VLA policies, reducing parameters by 45% and improving inference throughput by up to 1.7 times while matching or outperforming strong baselines in task success.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LoopVLA, a recurrent VLA architecture that iteratively refines multimodal tokens via a shared Transformer block, producing both candidate actions and sufficiency scores at each step. Sufficiency estimation is trained through a self-supervised distribution alignment objective that matches intermediate scores to relative action quality improvements across refinement iterations. On LIBERO, LIBERO-Plus, and VLA-Arena, the method is reported to reduce parameters by 45%, increase inference throughput by up to 1.7×, and match or exceed strong baselines in task success.
Significance. If the sufficiency estimator proves reliable, the approach could advance efficient VLA deployment by replacing fixed-depth or heuristic early exits with learned, representation-grounded stopping decisions. Parameter sharing across iterations and the self-supervised linkage to policy signals are concrete strengths that address over-abstraction in closed-loop manipulation tasks.
major comments (3)
- [Abstract and Experiments] Abstract and Experiments: The reported 45% parameter reduction and 1.7× throughput gains are presented without error bars, ablation tables, baseline implementation details, or statistical tests. This makes it impossible to verify whether the efficiency-performance frontier claim holds under standard evaluation practices.
- [Method (self-supervised objective)] Method (self-supervised objective): The distribution alignment trains sufficiency scores to match relative action quality between successive steps, yet action quality is derived solely from the model's own outputs rather than task success or geometric accuracy. This creates a self-referential loop with no external anchor, directly threatening the reliability of the early-stopping signal.
- [Evaluation] Evaluation: No analysis or correlation study is provided showing that the learned sufficiency scores predict actual rollout success or task completion rates, which is load-bearing for the central claim that the model can safely exit early without performance degradation.
minor comments (2)
- [Method] Clarify the precise mathematical definition of the sufficiency score and the distribution alignment loss (e.g., via an explicit equation).
- [Figures and Tables] Add confidence intervals or variance measures to any plots or tables reporting success rates across refinement steps.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which have helped improve the rigor of our presentation. We address each major comment point by point below.
read point-by-point responses
-
Referee: The reported 45% parameter reduction and 1.7× throughput gains are presented without error bars, ablation tables, baseline implementation details, or statistical tests. This makes it impossible to verify whether the efficiency-performance frontier claim holds under standard evaluation practices.
Authors: We agree that the efficiency claims require stronger statistical support. In the revised manuscript we now report all metrics with standard deviations over five random seeds, add ablation tables varying the number of refinement iterations and sufficiency threshold, include full baseline implementation details and hyperparameters, and apply paired statistical tests (Wilcoxon signed-rank) to compare against baselines. These additions are placed in Section 4.3 and Appendix B. revision: yes
-
Referee: The distribution alignment trains sufficiency scores to match relative action quality between successive steps, yet action quality is derived solely from the model's own outputs rather than task success or geometric accuracy. This creates a self-referential loop with no external anchor, directly threatening the reliability of the early-stopping signal.
Authors: The objective is deliberately self-supervised because dense external task-success or geometric labels are unavailable in standard VLA benchmarks. Action quality is defined from the change in the action-head output distribution across iterations; because the model is trained end-to-end with the primary task loss, these relative improvements remain coupled to policy optimization. We have expanded the method section with an explicit derivation of the quality metric and a short discussion of its empirical alignment with task reward signals. revision: partial
-
Referee: No analysis or correlation study is provided showing that the learned sufficiency scores predict actual rollout success or task completion rates, which is load-bearing for the central claim that the model can safely exit early without performance degradation.
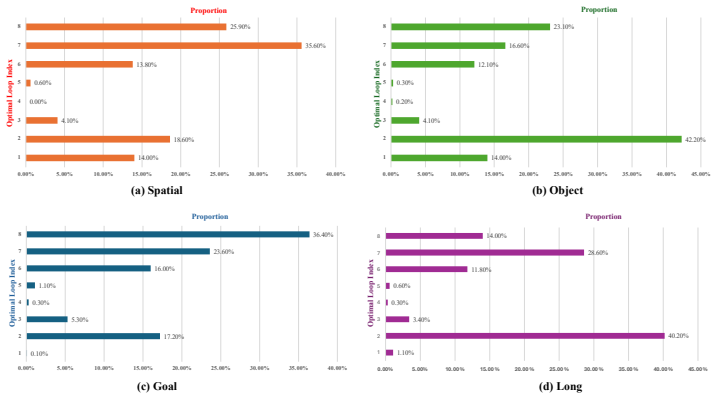
Authors: We acknowledge the absence of this validation in the original submission. The revised manuscript adds a dedicated subsection (4.5) that reports Pearson and Spearman correlations between sufficiency scores at each iteration and the final task success rates obtained when exiting at that iteration. The analysis includes figures showing that higher sufficiency scores reliably correspond to maintained or improved success rates, supporting safe early exit. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper presents a recurrent VLA architecture that jointly optimizes representation refinement, action prediction, and sufficiency estimation via a shared Transformer block. Sufficiency is trained with a self-supervised distribution alignment objective that aligns intermediate scores to relative action quality across steps. This is an empirical training design choice rather than a mathematical derivation. Central claims of parameter reduction (45%) and throughput gains (1.7x) while matching task success are supported by experiments on external benchmarks (LIBERO, LIBERO-Plus, VLA-Arena). No equations, self-citations, or uniqueness theorems are shown that reduce any result to its inputs by construction. The approach is self-contained with independent empirical validation.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A single transformer block can be reused across refinement iterations to produce progressively better multimodal representations.
- ad hoc to paper Relative improvement in action quality between successive refinement steps is a valid proxy for representation sufficiency.
invented entities (1)
-
sufficiency score
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
LoopVLA iteratively applies a shared Transformer block to refine multimodal tokens, and at each iteration produces both a candidate action and a sufficiency score... self-supervised distribution alignment objective, where intermediate confidence scores are trained to match the relative action quality across refinement steps
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Rt-1: Robotics transformer for real-world control at scale
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alexander Herzog, Jasmine Hsu, et al. Rt-1: Robotics transformer for real-world control at scale. InProceedings of Robotics: Science and Systems, 2023
work page 2023
-
[2]
Rt-2: Vision-language-action models transfer web knowledge to robotic control
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning, pages 2165–2183. PMLR, 2023
work page 2023
-
[3]
Openvla: An open-source vision-language-action model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan P Foster, Pannag R Sanketi, Quan Vuong, et al. Openvla: An open-source vision-language-action model. InConference on Robot Learning, pages 2679–2713. PMLR, 2025
work page 2025
-
[4]
Octo: An open-source generalist robot policy
Oier Mees, Dibya Ghosh, Karl Pertsch, Kevin Black, Homer Rich Walke, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, Jianlan Luo, et al. Octo: An open-source generalist robot policy. InFirst Workshop on Vision-Language Models for Navigation and Manipulation at ICRA 2024, 2024
work page 2024
-
[5]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
work page 2021
-
[6]
Pali: A jointly-scaled mul- tilingual language-image model
Xi Chen, Xiao Wang, Soravit Changpinyo, Anthony J Piergiovanni, Piotr Padlewski, Daniel Salz, Sebastian Goodman, Adam Grycner, Basil Mustafa, Lucas Beyer, et al. Pali: A jointly-scaled multilingual language-image model.arXiv preprint arXiv:2209.06794, 2022
-
[7]
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning.Advances in neural information processing systems, 35:23716–23736, 2022
work page 2022
-
[8]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational conference on machine learning, pages 19730–19742. PMLR, 2023
work page 2023
-
[9]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
work page 2023
-
[10]
Isaac L Kurtzer, J Andrew Pruszynski, and Stephen H Scott. Long-latency reflexes of the human arm reflect an internal model of limb dynamics.Current Biology, 18(6):449–453, 2008
work page 2008
-
[11]
J Andrew Pruszynski and Stephen H Scott. Optimal feedback control and the long-latency stretch response.Experimental brain research, 218(3):341–359, 2012
work page 2012
-
[12]
SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics
Mustafa Shukor, Dana Aubakirova, Francesco Capuano, Pepijn Kooijmans, Steven Palma, Adil Zouitine, Michel Aractingi, Caroline Pascal, Martino Russi, Andres Marafioti, et al. Smolvla: A vision-language-action model for affordable and efficient robotics.arXiv preprint arXiv:2506.01844, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Lucy Xiaoyang Shi, Laura Smith, James Tanner, Quan Vuong, Anna Walling, Haohuan Wang, and Ury Zhilinsk...
work page 2025
-
[14]
Flower: Democratizing generalist robot policies with efficient vision-language-flow models
Moritz Reuss, Hongyi Zhou, Marcel Rühle, Ömer Erdinç Ya˘gmurlu, Fabian Otto, and Rudolf Lioutikov. Flower: Democratizing generalist robot policies with efficient vision-language-flow models. InConference on Robot Learning, pages 3736–3761. PMLR, 2025. 10
work page 2025
-
[15]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Jim Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, Joel Jang, Zhenyu Jiang, Jan Kautz, Kaushil Kundalia, Lawrence Lao, Zhiqi Li, Zongyu Lin, Kevin Lin, Guilin Liu, Edith Llontop, Loic Magne, Ajay Mandlekar, Avnish Narayan, Soroush Nasiriany, Scott Reed, You Liang Tan,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Deer-vla: dynamic inference of multimodal large language models for efficient robot execution
Yang Yue, Yulin Wang, Bingyi Kang, Yizeng Han, Shenzhi Wang, Shiji Song, Jiashi Feng, and Gao Huang. Deer-vla: dynamic inference of multimodal large language models for efficient robot execution. InProceedings of the 38th International Conference on Neural Information Processing Systems, pages 56619–56643, 2024
work page 2024
-
[17]
Prismatic vlms: Investigating the design space of visually-conditioned language models
Siddharth Karamcheti, Suraj Nair, Ashwin Balakrishna, Percy Liang, Thomas Kollar, and Dorsa Sadigh. Prismatic vlms: Investigating the design space of visually-conditioned language models. InInternational Conference on Machine Learning, pages 23123–23144. PMLR, 2024
work page 2024
-
[18]
arXiv preprint arXiv:2412.03555 (2024) 1
Andreas Steiner, André Susano Pinto, Michael Tschannen, Daniel Keysers, Xiao Wang, Yonatan Bitton, Alexey Gritsenko, Matthias Minderer, Anthony Sherbondy, Shangbang Long, et al. Paligemma 2: A family of versatile vlms for transfer.arXiv preprint arXiv:2412.03555, 2024
-
[19]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Kento Kawaharazuka, Jihoon Oh, Jun Yamada, Ingmar Posner, and Yuke Zhu. Vision-language- action models for robotics: A review towards real-world applications.IEEE Access, 2025
work page 2025
-
[21]
GR-2: A Generative Video-Language-Action Model with Web-Scale Knowledge for Robot Manipulation
Chi-Lam Cheang, Guangzeng Chen, Ya Jing, Tao Kong, Hang Li, Yifeng Li, Yuxiao Liu, Hongtao Wu, Jiafeng Xu, Yichu Yang, et al. Gr-2: A generative video-language-action model with web-scale knowledge for robot manipulation.arXiv preprint arXiv:2410.06158, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Learning to act anywhere with task-centric latent actions
Qingwen Bu, Yanting Yang, Jisong Cai, Shenyuan Gao, Guanghui Ren, Maoqing Yao, Ping Luo, and Hongyang Li. Learning to act anywhere with task-centric latent actions. InProceedings of Robotics: Science and Systems, 2025
work page 2025
-
[23]
Rethinking visual layer selection in multimodal llms.arXiv e-prints, pages arXiv–2504, 2025
Haoran Chen, Junyan Lin, Xinhao Chen, Yue Fan, Xin Jin, Hui Su, Jianfeng Dong, Jinlan Fu, and Xiaoyu Shen. Rethinking visual layer selection in multimodal llms.arXiv e-prints, pages arXiv–2504, 2025
work page 2025
-
[24]
InternVLA-M1: A Spatially Guided Vision-Language-Action Framework for Generalist Robot Policy
Xinyi Chen, Yilun Chen, Yanwei Fu, Ning Gao, Jiaya Jia, Weiyang Jin, Hao Li, Yao Mu, Jiangmiao Pang, Yu Qiao, et al. Internvla-m1: A spatially guided vision-language-action framework for generalist robot policy.arXiv preprint arXiv:2510.13778, 2025
work page internal anchor Pith review arXiv 2025
-
[25]
Adaptive Computation Time for Recurrent Neural Networks
Alex Graves. Adaptive computation time for recurrent neural networks.arXiv preprint arXiv:1603.08983, 2016
work page internal anchor Pith review arXiv 2016
-
[26]
Mostafa Dehghani, Stephan Gouws, Oriol Vinyals, Jakob Uszkoreit, and Łukasz Kaiser. Uni- versal transformers. InInternational Conference on Learning Representations, 2019
work page 2019
-
[27]
Nikunj Saunshi, Nishanth Dikkala, Zhiyuan Li, Sanjiv Kumar, and Sashank J. Reddi. Reasoning with latent thoughts: On the power of looped transformers. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[28]
Rui-Jie Zhu, Zixuan Wang, Kai Hua, Tianyu Zhang, Ziniu Li, Haoran Que, Boyi Wei, Zixin Wen, Fan Yin, He Xing, et al. Scaling latent reasoning via looped language models.arXiv preprint arXiv:2510.25741, 2025
-
[29]
Diffusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research, 44(10-11):1684–1704, 2025. 11
work page 2025
-
[30]
FAST: Efficient Action Tokenization for Vision-Language-Action Models
Karl Pertsch, Kyle Stachowicz, Brian Ichter, Danny Driess, Suraj Nair, Quan Vuong, Oier Mees, Chelsea Finn, and Sergey Levine. Fast: Efficient action tokenization for vision-language-action models.arXiv preprint arXiv:2501.09747, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Graspvla: a grasping foundation model pre-trained on billion-scale synthetic action data
Shengliang Deng, Mi Yan, Songlin Wei, Haixin Ma, Yuxin Yang, Jiayi Chen, Zhiqi Zhang, Taoyu Yang, Xuheng Zhang, Heming Cui, et al. Graspvla: a grasping foundation model pre-trained on billion-scale synthetic action data. InConference on Robot Learning, pages 1004–1029. PMLR, 2025
work page 2025
-
[32]
Qi Lv, Weijie Kong, Hao Li, Jia Zeng, Zherui Qiu, Delin Qu, Haoming Song, Qizhi Chen, Xiang Deng, and Jiangmiao Pang. F1: A vision-language-action model bridging understanding and generation to actions.arXiv preprint arXiv:2509.06951, 2025
-
[33]
Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Robert Equi, Chelsea Finn, Niccolo Fusai, Manuel Y . Galliker, Dibya Ghosh, Lachy Groom, Karol Hausman, brian ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Devin LeBlanc, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Allen Z. Ren,...
work page 2025
-
[34]
Vla-adapter: An effective paradigm for tiny-scale vision-language-action model
Yihao Wang, Pengxiang Ding, Lingxiao Li, Can Cui, Zirui Ge, Xinyang Tong, Wenxuan Song, Han Zhao, Wei Zhao, Pengxu Hou, et al. Vla-adapter: An effective paradigm for tiny-scale vision-language-action model. InProceedings of the AAAI conference on artificial intelligence, volume 40, pages 18638–18646, 2026
work page 2026
-
[35]
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
work page 2023
-
[36]
Borong Zhang, Jiahao Li, Jiachen Shen, Yishuai Cai, Yuhao Zhang, Yuanpei Chen, Juntao Dai, Jiaming Ji, and Yaodong Yang. Vla-arena: An open-source framework for benchmarking vision-language-action models.arXiv preprint arXiv:2512.22539, 2025
-
[37]
LIBERO-Plus: In-depth Robustness Analysis of Vision-Language-Action Models
Senyu Fei, Siyin Wang, Junhao Shi, Zihao Dai, Jikun Cai, Pengfang Qian, Li Ji, Xinzhe He, Shiduo Zhang, Zhaoye Fei, et al. Libero-plus: In-depth robustness analysis of vision-language- action models.arXiv preprint arXiv:2510.13626, 2025
work page internal anchor Pith review arXiv 2025
-
[38]
Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Alab- dulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, et al. Siglip 2: Multilingual vision-language encoders with improved semantic understanding, localization, and dense features.arXiv preprint arXiv:2502.14786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Fine-tuning vision-language-action models: Optimizing speed and success
Moo Jin Kim, Chelsea Finn, and Percy Liang. Fine-tuning vision-language-action models: Optimizing speed and success. InProceedings of Robotics: Science and Systems, 2025
work page 2025
-
[40]
StarVLA: A Lego-like Codebase for Vision-Language-Action Model Developing
StarVLA Community. Starvla: A lego-like codebase for vision-language-action model develop- ing.arXiv preprint arXiv:2604.05014, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[41]
vla-eval: A Unified Evaluation Harness for Vision-Language-Action Models
Suhwan Choi, Yunsung Lee, Yubeen Park, Chris Dongjoo Kim, Ranjay Krishna, Dieter Fox, and Youngjae Yu. vla-eval: A unified evaluation harness for vision-language-action models. arXiv preprint arXiv:2603.13966, 2026. 12 A Appendix A.1 LIBERO-Plus Benchmark We evaluate the generalization capability of LoopVLA on LIBERO-Plus, a benchmark designed for in-dept...
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.