Recognition: no theorem link
H\"older Policy Optimisation
Pith reviewed 2026-05-13 05:58 UTC · model grok-4.3
The pith
HölderPO resolves GRPO's aggregation trade-off by using a tunable Hölder mean with annealed parameter p to control gradient concentration and variance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
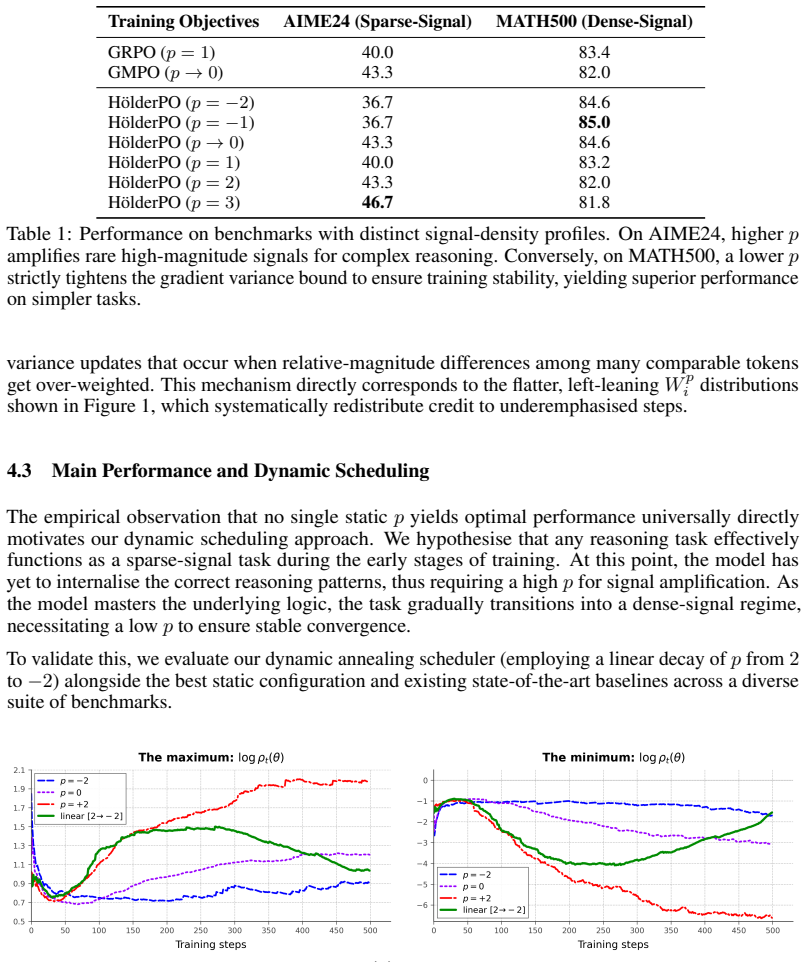
The central claim is that mapping trajectory advantages to policy updates in GRPO is limited by fixed aggregation mechanisms, but the Hölder mean unifies them and allows explicit control: larger p concentrates the gradient to amplify learning signals while smaller p strictly bounds gradient variance. Since no static p resolves the trade-off universally, dynamic annealing of p across the training lifecycle produces superior stability and performance over baselines.
What carries the argument
The Hölder mean applied to token-level probability aggregation within each trajectory, where the parameter p determines the degree of gradient concentration versus variance bounding.
Load-bearing premise
That modulating the single scalar p via annealing will reliably resolve the concentration-stability trade-off across different model sizes, tasks, and sampling budgets without introducing new failure modes.
What would settle it
A direct comparison of the annealed schedule against the best fixed p value, measured by whether the fixed version matches or exceeds the reported 54.9 percent average accuracy on the mathematical benchmarks.
Figures


read the original abstract
Group Relative Policy Optimisation (GRPO) enhances large language models by estimating advantages across a group of sampled trajectories. However, mapping these trajectory-level advantages to policy updates requires aggregating token-level probabilities within each sequence. Relying on a fixed aggregation mechanism for this step fundamentally limits the algorithm's adaptability. Empirically, we observe a critical trade-off: certain fixed aggregations frequently suffer from training collapse, while others fail to yield satisfactory performance. To resolve this, we propose \textbf{H\"{o}lderPO}, a generalised policy optimisation framework unifying token-level probability aggregation via the H\"{o}lder mean. By explicitly modulating the parameter $p$, our framework provides continuous control over the trade-off between gradient concentration and variance bounds. Theoretically, we prove that a larger $p$ concentrates the gradient to amplify sparse learning signals, whereas a smaller $p$ strictly bounds gradient variance. Because no static configuration can universally resolve this concentration-stability trade-off, we instantiate the framework with a dynamic annealing algorithm that progressively schedules $p$ across the training lifecycle. Extensive evaluations demonstrate superior stability and convergence over existing baselines. Specifically, our approach achieves a state-of-the-art average accuracy of $54.9\%$ across multiple mathematical benchmarks, yielding a substantial $7.2\%$ relative gain over standard GRPO and secures an exceptional $93.8\%$ success rate on ALFWorld.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes HölderPO as a generalization of Group Relative Policy Optimisation (GRPO) for LLM policy optimization. It replaces fixed aggregation of token-level probabilities with the Hölder mean, controlled by a scalar parameter p that trades off gradient concentration (large p) against variance bounds (small p). Theoretical claims establish the limiting behaviors of p, and a dynamic annealing schedule is introduced because no fixed p works universally. Experiments report 54.9% average accuracy on mathematical benchmarks (+7.2% relative to GRPO) and 93.8% success on ALFWorld.
Significance. If the gradient-concentration and variance-bound results are rigorously derived and the empirical gains survive proper ablations and statistical controls, the framework would supply a continuous, theoretically grounded knob for the stability-performance trade-off that appears in many group-based RL methods for LLMs. The explicit unification via Hölder means and the annealing instantiation are the primary contributions.
major comments (3)
- [§3] §3 (theoretical analysis): the claim that larger p concentrates the gradient to amplify sparse signals and that smaller p strictly bounds variance is asserted without the key intermediate inequalities or proof steps; the load-bearing step is the mapping from the Hölder mean definition to the advantage-weighted policy gradient, which must be shown explicitly under the GRPO group-relative advantage estimator.
- [Experimental section] Experimental section, results table for mathematical benchmarks: the reported 54.9% average and 7.2% relative gain lack error bars, number of random seeds, and any ablation that isolates the annealing schedule from fixed-p Hölder means or from extra hyper-parameter search; without these controls the claim that dynamic p “resolves” the trade-off cannot be distinguished from post-hoc fitting on the same evaluation suites.
- [§4.2] §4.2 (annealing algorithm): the specific functional form and timing of the p schedule constitute an additional free parameter whose selection procedure is not described; if this schedule was tuned on the math and ALFWorld data used for final reporting, the performance numbers are at risk of circularity and the universality claim is under-supported.
minor comments (2)
- [§2] The Hölder-mean formula itself should be written explicitly once (e.g., as Eq. (3)) rather than left implicit, to aid readers unfamiliar with the family.
- [Figures] Figure captions for training curves should state the exact p-annealing schedule used in each run.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed report. We address each major comment below and will incorporate revisions to improve the rigor and clarity of the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (theoretical analysis): the claim that larger p concentrates the gradient to amplify sparse signals and that smaller p strictly bounds variance is asserted without the key intermediate inequalities or proof steps; the load-bearing step is the mapping from the Hölder mean definition to the advantage-weighted policy gradient, which must be shown explicitly under the GRPO group-relative advantage estimator.
Authors: We agree that the theoretical claims in §3 require more explicit intermediate steps. In the revised manuscript we will expand the section to include the full derivation: starting from the definition of the Hölder mean, we will show the explicit mapping to the advantage-weighted policy gradient under the GRPO estimator, followed by the inequalities establishing gradient concentration for large p and strict variance bounds for small p. revision: yes
-
Referee: Experimental section, results table for mathematical benchmarks: the reported 54.9% average and 7.2% relative gain lack error bars, number of random seeds, and any ablation that isolates the annealing schedule from fixed-p Hölder means or from extra hyper-parameter search; without these controls the claim that dynamic p “resolves” the trade-off cannot be distinguished from post-hoc fitting on the same evaluation suites.
Authors: We will revise the experimental section to report error bars computed across multiple random seeds, state the number of seeds employed, and add ablation studies that compare the dynamic annealing schedule against fixed-p Hölder means while controlling for hyper-parameter search effort. These additions will allow readers to isolate the contribution of the annealing procedure. revision: yes
-
Referee: [§4.2] §4.2 (annealing algorithm): the specific functional form and timing of the p schedule constitute an additional free parameter whose selection procedure is not described; if this schedule was tuned on the math and ALFWorld data used for final reporting, the performance numbers are at risk of circularity and the universality claim is under-supported.
Authors: We will expand §4.2 to give the exact functional form of the p schedule, the timing parameters, and the procedure used to select them. The schedule was chosen via preliminary runs on a held-out validation split distinct from the final reported benchmarks; we will state this explicitly and list the concrete hyper-parameters to remove any ambiguity about circularity. revision: yes
Circularity Check
No significant circularity detected in the HölderPO derivation
full rationale
The paper's chain begins with an empirical observation of trade-offs in fixed aggregations for GRPO, introduces the Hölder mean (a pre-existing mathematical object) to unify them, derives theoretical bounds on gradient concentration for large p and variance for small p, and motivates dynamic annealing of p because no fixed value resolves the trade-off universally. None of these steps reduce by construction to the final benchmark numbers; the annealing schedule is an explicit algorithmic choice whose specific form is not shown to be equivalent to fitting on the reported math or ALFWorld results. The performance claims are presented as downstream experimental outcomes rather than tautological consequences of the inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- p
axioms (1)
- standard math Hölder mean properties hold for the token-probability vectors arising in LLM policy gradients
Reference graph
Works this paper leans on
-
[1]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
- [4]
-
[5]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Understanding R1-Zero-Like Training: A Critical Perspective
Understanding r1-zero-like training: A critical perspective , author=. arXiv preprint arXiv:2503.20783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
arXiv preprint arXiv:2507.20673 , year=
Geometric-mean policy optimization , author=. arXiv preprint arXiv:2507.20673 , year=
-
[8]
Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement
Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement , author=. arXiv preprint arXiv:2409.12122 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Measuring Mathematical Problem Solving With the MATH Dataset
Measuring mathematical problem solving with the math dataset , author=. arXiv preprint arXiv:2103.03874 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Advances in neural information processing systems , volume=
Solving quantitative reasoning problems with language models , author=. Advances in neural information processing systems , volume=
-
[11]
He, Chaoqun and Luo, Renjie and Bai, Yuzhuo and Hu, Shengding and Thai, Zhen and Shen, Junhao and Hu, Jinyi and Han, Xu and Huang, Yujie and Zhang, Yuxiang and Liu, Jie and Qi, Lei and Liu, Zhiyuan and Sun, Maosong. O lympiad B ench: A Challenging Benchmark for Promoting AGI with Olympiad-Level Bilingual Multimodal Scientific Problems. Proceedings of the ...
-
[12]
Jia, LI and Edward, Beeching and Lewis, Tunstall and Ben, Lipkin and Roman, Soletskyi and Shengyi Costa, Huang and Kashif, Rasul and Longhui, Yu and Albert, Jiang and Ziju, Shen and Zihan, Qin and Bin, Dong and Li, Zhou and Yann, Fleureau and Guillaume, Lample and Stanislas, Polu , title =. 2024 , publisher =
work page 2024
-
[13]
ALFWorld: Aligning Text and Embodied Environments for Interactive Learning
Alfworld: Aligning text and embodied environments for interactive learning , author=. arXiv preprint arXiv:2010.03768 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[14]
Simple statistical gradient-following algorithms for connectionist reinforcement learning , author=. Machine learning , volume=. 1992 , publisher=
work page 1992
-
[15]
Advances in Neural Information Processing Systems (NIPS) , volume=
Policy gradient methods for reinforcement learning with function approximation , author=. Advances in Neural Information Processing Systems (NIPS) , volume=
-
[16]
Group Sequence Policy Optimization
Group sequence policy optimization , author=. arXiv preprint arXiv:2507.18071 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Group-in-Group Policy Optimization for LLM Agent Training
Group-in-group policy optimization for llm agent training , author=. arXiv preprint arXiv:2505.10978 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Advances in neural information processing systems , volume=
Learning to summarize with human feedback , author=. Advances in neural information processing systems , volume=
-
[19]
Reinforcement learning with verifiable rewards implicitly incentivizes correct reasoning in base llms , author=. arXiv preprint arXiv:2506.14245 , year=
work page internal anchor Pith review arXiv
-
[20]
Openai o1 system card , author=. arXiv preprint arXiv:2412.16720 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Gpg: A simple and strong reinforcement learning baseline for model reasoning , author=. arXiv preprint arXiv:2504.02546 , year=
-
[24]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Dapo: An open-source llm reinforcement learning system at scale , author=. arXiv preprint arXiv:2503.14476 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
AAPO: Enhancing the Reasoning Capabilities of LLMs with Advantage Margin
AAPO: Enhancing the Reasoning Capabilities of LLMs with Advantage Momentum , author=. arXiv preprint arXiv:2505.14264 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
arXiv preprint arXiv:2506.02864 , year=
Bnpo: Beta normalization policy optimization , author=. arXiv preprint arXiv:2506.02864 , year=
-
[27]
Open-Reasoner-Zero: An Open Source Approach to Scaling Up Reinforcement Learning on the Base Model
Open-reasoner-zero: An open source approach to scaling up reinforcement learning on the base model , author=. arXiv preprint arXiv:2503.24290 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Process Reinforcement through Implicit Rewards
Process reinforcement through implicit rewards , author=. arXiv preprint arXiv:2502.01456 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
What’s behind ppo’s collapse in long-cot? value optimization holds the secret, 2025
What's Behind PPO's Collapse in Long-CoT? Value Optimization Holds the Secret , author=. arXiv preprint arXiv:2503.01491 , year=
-
[30]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Token-level proximal policy optimization for query generation , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2025
-
[31]
SimpleRL-Zoo: Investigating and Taming Zero Reinforcement Learning for Open Base Models in the Wild
Simplerl-zoo: Investigating and taming zero reinforcement learning for open base models in the wild , author=. arXiv preprint arXiv:2503.18892 , year=
work page internal anchor Pith review arXiv
-
[32]
Advancing llm rea- soning generalists with preference trees.arXiv preprint arXiv:2404.02078, 2024
Advancing llm reasoning generalists with preference trees , author=. arXiv preprint arXiv:2404.02078 , year=
-
[33]
Optimization methods for large-scale machine learning , author=. SIAM review , volume=. 2018 , publisher=
work page 2018
-
[34]
International conference on machine learning , pages=
Trust region policy optimization , author=. International conference on machine learning , pages=. 2015 , organization=
work page 2015
- [35]
-
[36]
arXiv preprint arXiv:2601.22521 , year=
One Ring to Rule Them All: Unifying Group-Based RL via Dynamic Power-Mean Geometry , author=. arXiv preprint arXiv:2601.22521 , year=
-
[37]
ERPO: Token-Level Entropy-Regulated Policy Optimization for Large Reasoning Models
ERPO: Token-Level Entropy-Regulated Policy Optimization for Large Reasoning Models , author=. arXiv preprint arXiv:2603.28204 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
arXiv preprint arXiv:2508.03772 , year=
Gtpo: Stabilizing group relative policy optimization via gradient and entropy control , author=. arXiv preprint arXiv:2508.03772 , year=
-
[39]
Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning for llm reasoning , author=. arXiv preprint arXiv:2506.01939 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
Tgrpo: Fine-tuning vision-language-action model via trajectory-wise group relative policy optimization , author=. arXiv preprint arXiv:2506.08440 , year=
-
[41]
arXiv preprint arXiv:2505.12929 , year=
Do not let low-probability tokens over-dominate in rl for llms , author=. arXiv preprint arXiv:2505.12929 , year=
-
[42]
arXiv preprint arXiv:2510.03669 , year=
Token hidden reward: Steering exploration-exploitation in group relative deep reinforcement learning , author=. arXiv preprint arXiv:2510.03669 , year=
-
[43]
arXiv preprint arXiv:2510.09369 , year=
Token-Level Policy Optimization: Linking Group-Level Rewards to Token-Level Aggregation via Markov Likelihood , author=. arXiv preprint arXiv:2510.09369 , year=
-
[44]
Advances in Neural Information Processing Systems , volume=
Lima: Less is more for alignment , author=. Advances in Neural Information Processing Systems , volume=
-
[45]
The Twelfth International Conference on Learning Representations , year=
Rain: Your language models can align themselves without finetuning , author=. The Twelfth International Conference on Learning Representations , year=
-
[46]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in
Yue, Yang and Chen, Zhiqi and Lu, Rui and Zhao, Andrew and Wang, Zhaokai and Song, Shiji and Huang, Gao , booktitle=. Does Reinforcement Learning Really Incentivize Reasoning Capacity in
-
[47]
Rewarding the Unlikely: Lifting
He, Andre Wang and Fried, Daniel and Welleck, Sean , booktitle=. Rewarding the Unlikely: Lifting. 2025 , publisher=
work page 2025
-
[48]
Advances in Neural Information Processing Systems , volume=
Star: Bootstrapping reasoning with reasoning , author=. Advances in Neural Information Processing Systems , volume=
-
[49]
Let's verify step by step , author=. arXiv preprint arXiv:2305.20050 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
Advances in Neural Information Processing Systems , volume=
Tree of thoughts: Deliberate problem solving with large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[51]
arXiv preprint arXiv:2510.06870 , year=
lambda -GRPO: Unifying the GRPO Frameworks with Learnable Token Preferences , author=. arXiv preprint arXiv:2510.06870 , year=
-
[52]
On-policy rl with optimal reward baseline.arXiv preprint arXiv:2505.23585, 2025
On-policy rl with optimal reward baseline , author=. arXiv preprint arXiv:2505.23585 , year=
-
[53]
Seed-grpo: Semantic entropy enhanced grpo for uncertainty-aware policy optimization , author=. arXiv preprint arXiv:2505.12346 , year=
-
[54]
Reinforcement learning: An introduction , author=. 2018 , publisher=
work page 2018
-
[55]
International conference on machine learning , pages=
Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor , author=. International conference on machine learning , pages=. 2018 , organization=
work page 2018
-
[56]
Spurious rewards: Rethinking training signals in RLVR.arXiv preprint arXiv:2506.10947,
Spurious Rewards: Rethinking Training Signals in RLVR , author=. arXiv preprint arXiv:2506.10947 , year=
-
[57]
High-dimensional probability: An introduction with applications in data science , author=. 2018 , publisher=
work page 2018
-
[58]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
Transformer Feed-Forward Layers Are Key-Value Memories , author=. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2021
-
[59]
Transformer Circuits Thread , year=
Towards monosemanticity: Decomposing language models with dictionary learning , author=. Transformer Circuits Thread , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.