Recognition: 1 theorem link
· Lean TheoremLearning What Matters: Adaptive Information-Theoretic Objectives for Robot Exploration
Pith reviewed 2026-05-13 05:02 UTC · model grok-4.3
The pith
Quasi-Optimal Experimental Design lets robots focus exploration on identifiable model parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
QOED performs eigenspace analysis of the Fisher information matrix to identify an observable subspace and select identifiable parameter directions. It modifies the exploration objective to emphasize these directions while suppressing nuisance effects from non-critical parameters. Under bounded nuisance influence and limited coupling between critical and nuisance directions, QOED provides a constant-factor approximation to the ideal information objective that explores all parameters.
What carries the argument
Quasi-Optimal Experimental Design (QOED) that uses eigenspace analysis on the Fisher information matrix to select identifiable parameter directions and suppress nuisance parameter effects in the objective.
If this is right
- Selection of identifiable directions improves performance by 35.23 percent in navigation and manipulation tasks.
- Nuisance suppression adds 21.98 percent further improvement.
- Integration as an exploration objective in model-based policy optimization beats established RL baselines.
Where Pith is reading between the lines
- The approach could help in other high-dimensional learning settings like vision-based control where many latent factors are unobservable.
- Relaxing the bounded coupling assumption might require new analysis to maintain the approximation guarantee.
- Testing on a wider range of robotic platforms would show how broadly the constant-factor result applies.
Load-bearing premise
The influence of nuisance parameters is bounded and their coupling to critical directions is limited.
What would settle it
An experiment in which nuisance parameters are allowed to strongly couple with critical ones, to check if the performance improvements from QOED disappear.
Figures





read the original abstract
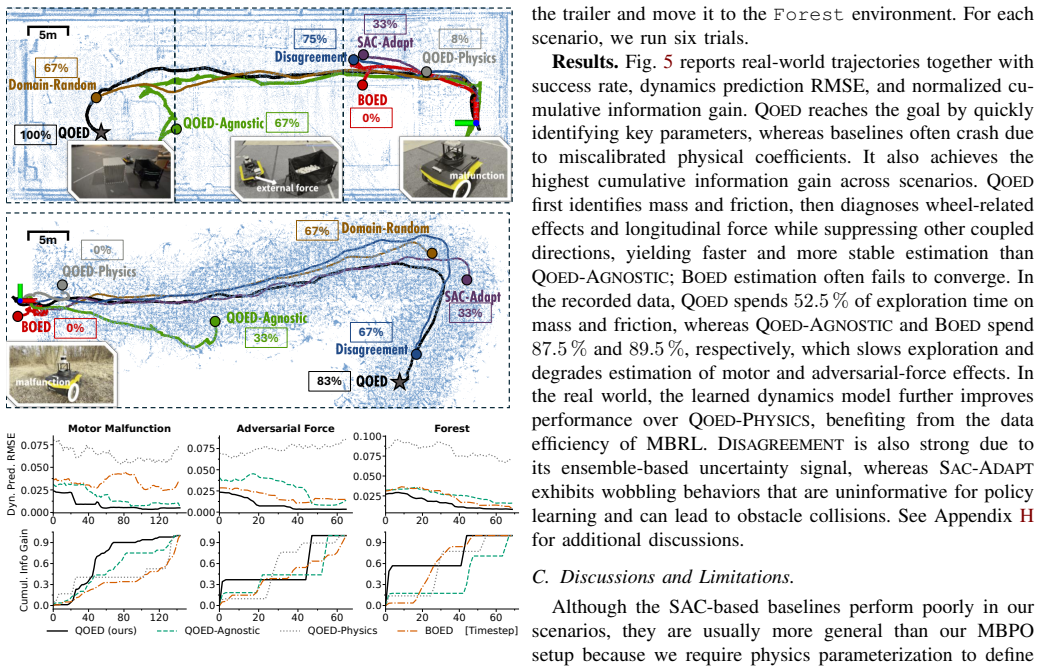
Designing learnable information-theoretic objectives for robot exploration remains challenging. Such objectives aim to guide exploration toward data that reduces uncertainty in model parameters, yet it is often unclear what information the collected data can actually reveal. Although reinforcement learning (RL) can optimize a given objective, constructing objectives that reflect parametric learnability is difficult in high-dimensional robotic systems. Many parameter directions are weakly observable or unidentifiable, and even when identifiable directions are selected, omitted directions can still influence exploration and distort information measures. To address this challenge, we propose Quasi-Optimal Experimental Design (Q{\footnotesize OED}), an adaptive information objective grounded in optimal experimental design. Q{\footnotesize OED} (i) performs eigenspace analysis of the Fisher information matrix to identify an observable subspace and select identifiable parameter directions, and (ii) modifies the exploration objective to emphasize these directions while suppressing nuisance effects from non-critical parameters. Under bounded nuisance influence and limited coupling between critical and nuisance directions, Q{\footnotesize OED} provides a constant-factor approximation to the ideal information objective that explores all parameters. We evaluate Q{\footnotesize OED} on simulated and real-world navigation and manipulation tasks, where identifiable-direction selection and nuisance suppression yield performance improvements of \SI{35.23}{\percent} and \SI{21.98}{\percent}, respectively. When integrated as an exploration objective in model-based policy optimization, Q{\footnotesize OED} further improves policy performance over established RL baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Quasi-Optimal Experimental Design (QOED) for robot exploration. QOED performs eigenspace analysis on the Fisher information matrix to isolate an observable subspace of identifiable parameters and re-weights the information objective to suppress nuisance directions. Under the assumptions of bounded nuisance influence and limited coupling between critical and nuisance directions, the method is claimed to deliver a constant-factor approximation to the ideal information objective that considers all parameters. Evaluations on simulated and real navigation and manipulation tasks report gains of 35.23% and 21.98%, respectively, and integration into model-based policy optimization yields improved policy performance over RL baselines.
Significance. If the constant-factor guarantee can be shown to apply in the evaluated domains, the approach would offer a principled way to focus exploration on learnable parameters in high-dimensional robotic systems, potentially improving sample efficiency. The empirical results on both simulation and hardware, together with the RL integration, constitute a concrete strength; however, the absence of verification for the key bounding assumptions limits the immediate impact of the theoretical claim.
major comments (2)
- [Abstract / theoretical section] Abstract and theoretical development section: The central claim that QOED yields a constant-factor approximation is explicitly conditioned on 'bounded nuisance influence and limited coupling between critical and nuisance directions,' yet no derivation of the required bounds on nuisance norms or cross-term magnitudes is supplied, nor are these quantities measured on the Fisher information matrices arising in the navigation and manipulation tasks.
- [Experimental results] Experimental results section (performance tables): The reported 35.23% and 21.98% improvements are presented as support for the method, but without evidence that the nuisance bounds hold in the evaluated domains these gains are consistent with the claim yet do not constitute confirmation of the approximation guarantee.
minor comments (2)
- [Method] The precise definition of the re-weighted objective (the modified information measure) would benefit from an explicit equation immediately following the eigenspace analysis description.
- [Experiments] Baseline details (exact RL algorithms, hyper-parameter ranges, and data-exclusion rules) are only summarized; a supplementary table listing these would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We agree that the theoretical claims regarding the constant-factor approximation would benefit from explicit derivations of the bounding assumptions and empirical verification in the evaluated domains. Below we address each major comment and describe the revisions we will incorporate.
read point-by-point responses
-
Referee: [Abstract / theoretical section] Abstract and theoretical development section: The central claim that QOED yields a constant-factor approximation is explicitly conditioned on 'bounded nuisance influence and limited coupling between critical and nuisance directions,' yet no derivation of the required bounds on nuisance norms or cross-term magnitudes is supplied, nor are these quantities measured on the Fisher information matrices arising in the navigation and manipulation tasks.
Authors: We acknowledge that the current manuscript does not supply an explicit derivation of the bounds on nuisance norms or cross-term magnitudes, nor does it report measurements of these quantities for the Fisher information matrices in the navigation and manipulation tasks. In the revised manuscript we will add a dedicated subsection in the theoretical development that derives the required bounds on nuisance influence and coupling terms under the stated assumptions. We will also compute and report the nuisance norms and cross-term magnitudes directly from the Fisher matrices obtained during the simulated and real-world experiments to verify that the assumptions hold in the evaluated domains. revision: yes
-
Referee: [Experimental results] Experimental results section (performance tables): The reported 35.23% and 21.98% improvements are presented as support for the method, but without evidence that the nuisance bounds hold in the evaluated domains these gains are consistent with the claim yet do not constitute confirmation of the approximation guarantee.
Authors: The reported performance gains illustrate the practical utility of QOED for focusing exploration on identifiable parameters. We agree, however, that these empirical results alone do not confirm the constant-factor approximation guarantee without verification that the nuisance bounds hold. As described in our response to the first comment, the revised manuscript will include explicit measurements of the nuisance norms and coupling terms from the experimental Fisher matrices; this will enable a direct assessment of whether the observed gains are consistent with the theoretical guarantee. revision: yes
Circularity Check
No significant circularity; derivation remains self-contained
full rationale
The paper's core construction applies standard eigenspace decomposition to the Fisher information matrix to isolate identifiable directions, then reweights the information objective to down-weight nuisance components. The constant-factor approximation claim is explicitly conditional on external assumptions (bounded nuisance norms and limited cross-coupling) rather than derived from or fitted to the same quantities. Reported performance deltas are empirical outcomes measured on navigation and manipulation tasks, not algebraic identities. No equation reduces a prediction to a fitted input by construction, no load-bearing self-citation chain is invoked, and the method does not rename a known result under new coordinates. The chain therefore retains independent grounding from classical optimal experimental design.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption bounded nuisance influence and limited coupling between critical and nuisance directions
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.lean (Jcost uniqueness, washburn_uniqueness_aczel); IndisputableMonolith/Foundation/RealityFromDistinction.lean (reality_from_one_distinction)reality_from_one_distinction; Jcost functional-equation uniqueness unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Under bounded nuisance influence and limited coupling between critical and nuisance directions, QOED provides a constant-factor approximation to the ideal information objective... via eigenspace analysis of the Fisher information matrix... Schur complement I_{k|k}=F_{kk}−F_{kk}F_{kk}^{−1}F_{kk}
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Modern Bayesian experimental design.Statistical Science, 39(1):100–114, 2024
Tom Rainforth, Adam Foster, Desi R Ivanova, and Fred- die Bickford Smith. Modern Bayesian experimental design.Statistical Science, 39(1):100–114, 2024
work page 2024
-
[2]
Wen Jiang, Boshu Lei, and Kostas Daniilidis. Fisherrf: Active view selection and uncertainty quantification for radiance fields using fisher information.arXiv preprint arXiv:2311.17874, 2023
-
[3]
GauSS-MI: Gaussian Splatting Shannon Mutual Information for Active 3D Reconstruction
Yuhan Xie, Yixi Cai, Yinqiang Zhang, Lei Yang, and Jia Pan. GauSS-MI: Gaussian Splatting Shannon Mutual Information for Active 3D Reconstruction. InProceed- ings of Robotics: Science and Systems, LosAngeles, CA, USA, June 2025
work page 2025
-
[4]
Next Best Sense: Guiding Vision and Touch with FisherRF for 3D Gaussian Splatting
Matthew Strong, Boshu Lei, Aiden Swann, Wen Jiang, Kostas Daniilidis, and Monroe Kennedy. Next Best Sense: Guiding Vision and Touch with FisherRF for 3D Gaussian Splatting. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 3204–3210, 2025
work page 2025
-
[5]
ASID: Active Explo- ration for System Identification in Robotic Manipulation
Marius Memmel, Andrew Wagenmaker, Chuning Zhu, Dieter Fox, and Abhishek Gupta. ASID: Active Explo- ration for System Identification in Robotic Manipulation. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[6]
Nikhil Sobanbabu, Guanqi He, Tairan He, Yuxiang Yang, and Guanya Shi. Sampling-based system identification with active exploration for legged robot sim2real learn- ing.arXiv preprint arXiv:2505.14266, 2025
-
[7]
Behavior Synthesis via Contact-Aware Fisher Information Max- imization
Hrishikesh Sathyanarayan and Ian Abraham. Behavior Synthesis via Contact-Aware Fisher Information Max- imization. InProceedings of Robotics: Science and Systems, LosAngeles, CA, USA, June 2025
work page 2025
-
[8]
Parker Ewen, Hao Chen, Yuzhen Chen, Anran Li, Anup Bagali, Gitesh Gunjal, and Ram Vasudevan. You’ve Got to Feel It To Believe It: Multi-Modal Bayesian Inference for Semantic and Property Prediction. InProceedings of Robotics: Science and Systems, Delft, Netherlands, July 2024
work page 2024
-
[9]
C. Cao, H. Zhu, Z. Ren, H. Choset, and J. Zhang. Rep- resentation granularity enables time-efficient autonomous exploration in large, complex worlds.Science Robotics, 8(80):eadf0970, 2023
work page 2023
-
[10]
Bayesian Q-learning.Aaai/iaai, 1998:761–768, 1998
Richard Dearden, Nir Friedman, Stuart Russell, et al. Bayesian Q-learning.Aaai/iaai, 1998:761–768, 1998
work page 1998
-
[11]
Efficient exploration through bayesian deep q-networks
Kamyar Azizzadenesheli, Emma Brunskill, and Ani- mashree Anandkumar. Efficient exploration through bayesian deep q-networks. In2018 Information Theory and Applications Workshop (ITA), pages 1–9. IEEE, 2018
work page 2018
-
[12]
Gen- eralization and Exploration via Randomized Value Func- tions
Ian Osband, Benjamin Van Roy, and Zheng Wen. Gen- eralization and Exploration via Randomized Value Func- tions. In Maria Florina Balcan and Kilian Q. Weinberger, editors,Proceedings of The 33rd International Confer- ence on Machine Learning, volume 48 ofProceedings of Machine Learning Research, pages 2377–2386, New York, New York, USA, 20–22 Jun 2016. PMLR
work page 2016
-
[13]
Ian Osband, Benjamin Van Roy, Daniel J. Russo, and Zheng Wen. Deep Exploration via Randomized Value Functions.Journal of Machine Learning Research, 20 (124):1–62, 2019
work page 2019
-
[14]
Information Di- rected Sampling and Bandits with Heteroscedastic Noise
Johannes Kirschner and Andreas Krause. Information Di- rected Sampling and Bandits with Heteroscedastic Noise. In S ´ebastien Bubeck, Vianney Perchet, and Philippe Rigollet, editors,Proceedings of the 31st Conference On Learning Theory, volume 75 ofProceedings of Machine Learning Research, pages 358–384. PMLR, 06–09 Jul 2018
work page 2018
-
[15]
Efficient exploration with double uncertain value networks.arXiv preprint arXiv:1711.10789, 2017
Thomas M Moerland, Joost Broekens, and Catholijn M Jonker. Efficient exploration with double uncertain value networks.arXiv preprint arXiv:1711.10789, 2017
-
[16]
A distributional perspective on reinforcement learning
Marc G Bellemare, Will Dabney, and R ´emi Munos. A distributional perspective on reinforcement learning. InInternational conference on machine learning, pages 449–458. PMLR, 2017
work page 2017
-
[17]
Distributional reinforcement learning for efficient exploration
Borislav Mavrin, Hengshuai Yao, Linglong Kong, Kai- wen Wu, and Yaoliang Yu. Distributional reinforcement learning for efficient exploration. InInternational con- ference on machine learning, pages 4424–4434. PMLR, 2019
work page 2019
-
[18]
Information-Directed Exploration for Deep Reinforcement Learning
Nikolay Nikolov, Johannes Kirschner, Felix Berkenkamp, and Andreas Krause. Information-Directed Exploration for Deep Reinforcement Learning. InInternational Conference on Learning Representations, 2019
work page 2019
-
[19]
#exploration: a study of count-based exploration for deep reinforcement learn- ing
Haoran Tang, Rein Houthooft, Davis Foote, Adam Stooke, OpenAI Xi Chen, Yan Duan, John Schulman, Filip DeTurck, and Pieter Abbeel. #exploration: a study of count-based exploration for deep reinforcement learn- ing. In I. Guyon, U. V on Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors, Advances in Neural Information Proces...
work page 2017
-
[20]
Unifying Count-Based Exploration and Intrinsic Motivation
Marc Bellemare, Sriram Srinivasan, Georg Ostrovski, Tom Schaul, David Saxton, and Remi Munos. Unifying Count-Based Exploration and Intrinsic Motivation. In D. Lee, M. Sugiyama, U. Luxburg, I. Guyon, and R. Gar- nett, editors,Advances in Neural Information Processing Systems, volume 29. Curran Associates, Inc., 2016
work page 2016
-
[21]
Leshem Choshen, Lior Fox, and Yonatan Loewenstein. Dora the explorer: Directed outreaching reinforcement action-selection.arXiv preprint arXiv:1804.04012, 2018
-
[22]
Adrien Ecoffet, Joost Huizinga, Joel Lehman, Kenneth O Stanley, and Jeff Clune. First return, then explore. Nature, 590(7847):580–586, 2021
work page 2021
-
[23]
Exploration by Random Network Distillation
Yuri Burda, Harrison Edwards, Amos Storkey, and Oleg Klimov. Exploration by random network distillation. arXiv preprint arXiv:1810.12894, 2018
work page Pith review arXiv 2018
-
[24]
Bradly C Stadie, Sergey Levine, and Pieter Abbeel. Incentivizing exploration in reinforcement learning with deep predictive models.arXiv preprint arXiv:1507.00814, 2015
-
[25]
Pierre-Yves Oudeyer, Frdric Kaplan, and Verena V . Hafner. Intrinsic Motivation Systems for Autonomous Mental Development.IEEE Transactions on Evolution- ary Computation, 11(2):265–286, 2007
work page 2007
-
[26]
Deepak Pathak, Pulkit Agrawal, Alexei A. Efros, and Trevor Darrell. Curiosity-driven Exploration by Self- supervised Prediction. InICML, 2017
work page 2017
-
[27]
Misha Denil, Pulkit Agrawal, Tejas D Kulkarni, Tom Erez, Peter Battaglia, and Nando De Freitas. Learning to perform physics experiments via deep reinforcement learning.arXiv preprint arXiv:1611.01843, 2016
-
[28]
Andrew D. Wilson, Jarvis A. Schultz, and Todd D. Murphey. Trajectory Synthesis for Fisher Information Maximization.IEEE Transactions on Robotics, 30(6): 1358–1370, 2014
work page 2014
-
[29]
Rafael Oliveira, Dino Sejdinovic, David Howard, and Edwin V . Bonilla. Bayesian Adaptive Calibration and Optimal Design. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
work page 2024
-
[30]
Paul G. Constantine.Active Subspaces. Society for Industrial and Applied Mathematics, Philadelphia, PA, 2015
work page 2015
-
[31]
Sloman, Ayush Bharti, Julien Martinelli, and Samuel Kaski
Sabina J. Sloman, Ayush Bharti, Julien Martinelli, and Samuel Kaski. Bayesian Active Learning in the Presence of Nuisance Parameters. InThe 40th Conference on Uncertainty in Artificial Intelligence, 2024
work page 2024
-
[32]
TD- MPC2: Scalable, Robust World Models for Continuous Control
Nicklas Hansen, Hao Su, and Xiaolong Wang. TD- MPC2: Scalable, Robust World Models for Continuous Control. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[33]
David Hoeller, Nikita Rudin, Dhionis Sako, and Marco Hutter. ANYmal parkour: Learning agile navigation for quadrupedal robots.Science Robotics, 9(88):eadi7566, 2024
work page 2024
-
[34]
Ziwen Zhuang, Shenzhe Yao, and Hang Zhao. Humanoid Parkour Learning. In8th Annual Conference on Robot Learning, 2024
work page 2024
-
[35]
DTC: Deep Tracking Control.Science Robotics, 9(86):eadh5401, 2024
Fabian Jenelten, Junzhe He, Farbod Farshidian, and Marco Hutter. DTC: Deep Tracking Control.Science Robotics, 9(86):eadh5401, 2024
work page 2024
-
[36]
DeX- treme: Transfer of Agile In-hand Manipulation from Simulation to Reality
Ankur Handa, Arthur Allshire, Viktor Makoviychuk, Aleksei Petrenko, Ritvik Singh, Jingzhou Liu, Denys Makoviichuk, Karl Van Wyk, Alexander Zhurkevich, Balakumar Sundaralingam, and Yashraj Narang. DeX- treme: Transfer of Agile In-hand Manipulation from Simulation to Reality. In2023 IEEE International Conference on Robotics and Automation (ICRA), pages 5977...
work page 2023
-
[37]
Reconciling Reality through Simulation: A Real-To-Sim-to-Real Approach for Robust Manipulation
Marcel Torne Villasevil, Anthony Simeonov, Zechu Li, April Chan, Tao Chen, Abhishek Gupta, and Pulkit Agrawal. Reconciling Reality through Simulation: A Real-To-Sim-to-Real Approach for Robust Manipulation. InProceedings of Robotics: Science and Systems, Delft, Netherlands, July 2024
work page 2024
-
[38]
Newton: GPU-accelerated physics simulation for robotics, and simulation research., 2025
Newton Contributors. Newton: GPU-accelerated physics simulation for robotics, and simulation research., 2025
work page 2025
-
[39]
When to Trust Your Model: Model-Based Policy Optimization
Michael Janner, Justin Fu, Marvin Zhang, and Sergey Levine. When to Trust Your Model: Model-Based Policy Optimization. In H. Wallach, H. Larochelle, A. Beygelz- imer, F. d'Alch ´e-Buc, E. Fox, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019
work page 2019
-
[40]
Chenhao Li, Andreas Krause, and Marco Hutter. Robotic world model: A neural network simulator for ro- bust policy optimization in robotics.arXiv preprint arXiv:2501.10100, 2025
-
[41]
Kronecker- Factored Approximate Curvature for Modern Neural Net- work Architectures
Runa Eschenhagen, Alexander Immer, Richard E Turner, Frank Schneider, and Philipp Hennig. Kronecker- Factored Approximate Curvature for Modern Neural Net- work Architectures. InThirty-seventh Conference on Neural Information Processing Systems, 2023
work page 2023
-
[42]
Springer Science & Business Media, 2012
Mark J Schervish.Theory of statistics. Springer Science & Business Media, 2012
work page 2012
-
[43]
Society for Industrial and Applied Mathematics, 2006
Friedrich Pukelsheim.Optimal Design of Experiments. Society for Industrial and Applied Mathematics, 2006
work page 2006
-
[44]
Universal statistics of fisher information in deep neural networks: Mean field approach
Ryo Karakida, Shotaro Akaho, and Shun-ichi Amari. Universal statistics of fisher information in deep neural networks: Mean field approach. InThe 22nd Interna- tional Conference on Artificial Intelligence and Statistics, pages 1032–1041. PMLR, 2019
work page 2019
-
[45]
Hauber, Marcus Rosen- blatt, Christian T ¨onsing, and Jens Timmer
Franz-Georg Wieland, Adrian L. Hauber, Marcus Rosen- blatt, Christian T ¨onsing, and Jens Timmer. On structural and practical identifiability.Current Opinion in Systems Biology, 25:60–69, 2021. ISSN 2452-3100
work page 2021
-
[46]
Reuven Rubinstein. The cross-entropy method for com- binatorial and continuous optimization.Methodology and computing in applied probability, 1(2):127–190, 1999
work page 1999
-
[47]
DART: Dense Articulated Real-Time Tracking
Tanner Schmidt, Richard Newcombe, and Dieter Fox. DART: Dense Articulated Real-Time Tracking. InPro- ceedings of Robotics: Science and Systems, Berkeley, USA, July 2014
work page 2014
-
[48]
C. Radhakrishna Rao. Minimum variance and the esti- mation of several parameters.Mathematical Proceedings of the Cambridge Philosophical Society, 43(2):280–283, 1947
work page 1947
-
[49]
Accelerated greedy algorithms for maximizing submodular set functions
Michel Minoux. Accelerated greedy algorithms for maximizing submodular set functions. In J. Stoer, editor, Optimization Techniques, pages 234–243, Berlin, Heidel- berg, 1978. Springer Berlin Heidelberg. ISBN 978-3- 540-35890-9
work page 1978
-
[50]
One Step Diffusion via Shortcut Models
Kevin Frans, Danijar Hafner, Sergey Levine, and Pieter Abbeel. One Step Diffusion via Shortcut Models. In The Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[51]
Neural ordinary differential equations.Advances in neural information processing systems, 31, 2018
Ricky TQ Chen, Yulia Rubanova, Jesse Bettencourt, and David K Duvenaud. Neural ordinary differential equations.Advances in neural information processing systems, 31, 2018
work page 2018
-
[52]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is All you Need. In Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017
work page 2017
-
[53]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[54]
Understanding Domain Randomization for Sim- to-real Transfer
Xiaoyu Chen, Jiachen Hu, Chi Jin, Lihong Li, and Liwei Wang. Understanding Domain Randomization for Sim- to-real Transfer. InInternational Conference on Learning Representations, 2022
work page 2022
-
[55]
MuJoCo: A physics engine for model-based control
Emanuel Todorov, Tom Erez, and Yuval Tassa. MuJoCo: A physics engine for model-based control. In2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 5026–5033. IEEE, 2012
work page 2012
-
[56]
mjlab: A Lightweight Framework for GPU-Accelerated Robot Learning
Kevin Zakka, Qiayuan Liao, Brent Yi, Louis Le Lay, Koushil Sreenath, and Pieter Abbeel. mjlab: A Lightweight Framework for GPU-Accelerated Robot Learning. 2026
work page 2026
-
[57]
Action Flow Matching for Continual Robot Learning
Alejandro Murillo-Gonz ´alez and Lantao Liu. Action Flow Matching for Continual Robot Learning. InPro- ceedings of Robotics: Science and Systems, Los Angeles, CA, USA, June 2025
work page 2025
-
[58]
Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. InInternational conference on machine learning, pages 1861–1870. Pmlr, 2018
work page 2018
-
[59]
Redeeming intrinsic rewards via constrained optimization
Eric Chen, Hong Zhang-Wei, Joni Pajarinen, and Pulkit Agrawal. Redeeming intrinsic rewards via constrained optimization. InAdvances in Neural Information Pro- cessing Systems (NeurIPS), 2022
work page 2022
-
[60]
Self- Supervised Exploration via Disagreement
Deepak Pathak, Dhiraj Gandhi, and Abhinav Gupta. Self- Supervised Exploration via Disagreement. InICML, 2019
work page 2019
-
[61]
Planning to Explore via Self-Supervised World Models
Ramanan Sekar, Oleh Rybkin, Kostas Daniilidis, Pieter Abbeel, Danijar Hafner, and Deepak Pathak. Planning to Explore via Self-Supervised World Models. InICML, 2020
work page 2020
-
[62]
Discovering and Achieving Goals via World Models
Russell Mendonca, Oleh Rybkin, Kostas Daniilidis, Danijar Hafner, and Deepak Pathak. Discovering and Achieving Goals via World Models. In M. Ranzato, A. Beygelzimer, Y . Dauphin, P.S. Liang, and J. Wortman Vaughan, editors,Advances in Neural Information Pro- cessing Systems, volume 34, pages 24379–24391. Curran Associates, Inc., 2021
work page 2021
-
[63]
Antonin Raffin, Ashley Hill, Adam Gleave, Anssi Kanervisto, Maximilian Ernestus, and Noah Dormann. Stable-Baselines3: Reliable Reinforcement Learning Im- plementations.Journal of Machine Learning Research, 22(268):1–8, 2021
work page 2021
-
[64]
Deep Reinforcement Learning in a Handful of Trials using Probabilistic Dynamics Models
Kurtland Chua, Roberto Calandra, Rowan McAllister, and Sergey Levine. Deep Reinforcement Learning in a Handful of Trials using Probabilistic Dynamics Models. In S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, editors,Advances in Neural Information Processing Systems, volume 31. Cur- ran Associates, Inc., 2018
work page 2018
-
[65]
Hu, James Springer, Oleh Rybkin, and Dinesh Jayaraman
Edward S. Hu, James Springer, Oleh Rybkin, and Dinesh Jayaraman. Privileged Sensing Scaffolds Reinforcement Learning. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[66]
Alexander Schperberg, Yusuke Tanaka, Feng Xu, Mar- cel Menner, and Dennis Hong. Real-to-Sim: Predict- ing Residual Errors of Robotic Systems with Sparse Data using a Learning-Based Unscented Kalman Filter. In2023 20th International Conference on Ubiquitous Robots (UR), pages 27–34, 2023
work page 2023
-
[67]
Chunge Bai, Tao Xiao, Yajie Chen, Haoqian Wang, Fang Zhang, and Xiang Gao. Faster-LIO: Lightweight Tightly Coupled Lidar-Inertial Odometry Using Parallel Sparse Incremental V oxels.IEEE Robotics and Automation Letters, 7(2):4861–4868, 2022
work page 2022
-
[68]
Fast Extrinsic Calibration for Multiple Inertial Mea- surement Units in Visual-Inertial System
Youwei Yu, Yanqing Liu, Fengjie Fu, Sihan He, Dongchen Zhu, Lei Wang, Xiaolin Zhang, and Jiamao Li. Fast Extrinsic Calibration for Multiple Inertial Mea- surement Units in Visual-Inertial System. In2023 IEEE International Conference on Robotics and Automation (ICRA), pages 01–07, 2023
work page 2023
-
[69]
Adaptive Diffusion Terrain Generator for Autonomous Uneven Terrain Navigation
Youwei Yu, Junhong Xu, and Lantao Liu. Adaptive Diffusion Terrain Generator for Autonomous Uneven Terrain Navigation. In8th Annual Conference on Robot Learning, 2024. APPENDIX A. Shortcut Flow Matching In the main text, we instantiate the surrogate transition like- lihoodq θ using shortcut models [50]. This appendix provides the full training objective an...
work page 2024
-
[70]
Setup and notation:For each transition(s t,a t,ϕ,s t+1) in the dataset, we define the conditioning variable c= (s t,a t,ϕ). To match the dynamics model definition in the main text, we model the state increment x=s t+1 −s t Let the base noise distribution bep 0(δ) =N(0,I). Given a data incrementx, a noise sampleδ, and a “time”u∈[0,1], we define the linear ...
-
[71]
The total loss is L(θ) :=L FM(θ) +L SC(θ)
Learning objective:Shortcut models learn a conditional velocity fieldv θ(zu, u,c, d), whered≥0is an extra input that represents a step size. The total loss is L(θ) :=L FM(θ) +L SC(θ). The flow-matching termL FM matches the predicted veloc- ity to the target velocity: LFM(θ) =E (x,c)∼D,δ∼p 0,u∼U[0,1] h vθ(zu, u,c,0)−(δ−x) 2i . The self-consistency termL SC...
-
[72]
Givenδ∼p 0(·)and conditioning c, define the one-step map Tθ(δ,c) :=δ−v θ(δ,1,c,1)
One-step sampling:After training, we can generate an increment in a single step. Givenδ∼p 0(·)and conditioning c, define the one-step map Tθ(δ,c) :=δ−v θ(δ,1,c,1). We sample an increment ˆx=T θ(δ,c)and then sets t+1 = st + ˆx. In the main text, we overload notation and write this transport map asT θ(δ,s t,a t,ϕ)
-
[73]
Conditional log-density:IfT θ(·,c)is a diffeomorphism inδ, the conditional density follows from the change-of- variables formula: logq θ(x|c) = logp 0(δ)−log|det∇ δTθ(δ,c)|, withδ=T −1 θ (x,c). For the shortcut-model transport map, the Jacobian is ∇δTθ(δ,c) =I− ∇ δvθ(δ,1,c,1), so the conditional log-density becomes logq θ(x|c) = logp 0(δ)−log|det(I− ∇ δvθ...
-
[74]
SinceF ϕ =E[gg ⊤], E[˜g˜g⊤] =E[W ⊤gg⊤W] =W ⊤F ϕW=Λ
Third, we take expectations using the eigen-decomposition. SinceF ϕ =E[gg ⊤], E[˜g˜g⊤] =E[W ⊤gg⊤W] =W ⊤F ϕW=Λ. ThereforeE[ ˜go˜g⊤ o ] =Λ o = diag({λi}i /∈o)and E h ∥˜go∥2 2 i = tr(Λo) = X i /∈o λi. Combining with the second step gives the last equality. Finally, the trace form follows fromE∥(I−P o)g∥2 2 =E[g ⊤(I− Po)g] = tr((I−P o)E[gg⊤]), which yields th...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.