Recognition: unknown
Adaptive Smooth Tchebycheff Attention for Multi-Objective Policy Optimization
Pith reviewed 2026-05-14 19:26 UTC · model grok-4.3
The pith
Dynamic modulation of Tchebycheff curvature via gradient conflict detection enables stable access to non-convex Pareto fronts in multi-objective robotic RL.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Adaptive Smooth Tchebycheff framework uses a conflict-driven controller to regulate optimization smoothness based on real-time gradient interference, allowing the agent to anneal toward precise non-convex scalarization when objectives align and revert to stable smooth approximations during destructive conflicts.
What carries the argument
The conflict-driven controller that dynamically adjusts the curvature of the Tchebycheff scalarization according to detected gradient interference between objectives.
Load-bearing premise
The conflict-driven controller can reliably detect destructive gradient interference and modulate the scalarization curvature without introducing new instabilities or biases in the policy gradient estimates.
What would settle it
An experiment showing that the adaptive method does not outperform linear methods in non-convex regions or exhibits higher gradient variance than static Tchebycheff during conflicts would falsify the central claim.
Figures










read the original abstract
Multi-objective reinforcement learning in robotic domains requires balancing complex, non-convex trade-offs between conflicting objectives. While linear scalarization methods provide stability, they are theoretically incapable of recovering solutions within non-convex regions of the Pareto front. Conversely, static non-linear scalarizations (e.g., Tchebycheff) can theoretically access these regions but often suffer from severe gradient variance and optimization instability in deep RL. In this work, we propose an Adaptive Smooth Tchebycheff framework that resolves this tension by dynamically modulating the curvature of the optimization landscape. We introduce a novel conflict-driven controller that regulates the optimization smoothness based on real-time gradient interference. This allows the agent to anneal toward precise, non-convex scalarization when objectives align, while elastically reverting to stable, smooth approximations when destructive gradient conflicts emerge. We validate our approach on a challenging robotic stealth visual search task -- a proxy for monitoring of protected/fragile ecosystems -- where an agent must balance search, exposure/interference minimization and exploration speed. Extensive ablations confirm that our conflict-aware adaptation enables the robust discovery of Pareto-optimal policies in non-convex regions inaccessible to linear baselines and unstable for static non-linear methods. Website: https://alejandromllo.github.io/research/pasta/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an Adaptive Smooth Tchebycheff framework for multi-objective reinforcement learning in robotics. It introduces a conflict-driven controller that dynamically modulates the curvature of the Tchebycheff scalarization in real time according to detected gradient interference among objectives. When objectives align, the method anneals toward precise non-convex scalarization; when destructive conflicts arise, it elastically reverts to smoother approximations. The approach is evaluated on a robotic stealth visual search task balancing search, exposure minimization, and exploration speed, with ablations claimed to show superior recovery of non-convex Pareto-optimal policies compared with linear and static non-linear baselines.
Significance. If the central claims hold after rigorous verification, the work would offer a practical advance in multi-objective RL for robotic domains by bridging the stability of linear scalarization with access to non-convex Pareto regions. The conflict-aware adaptation could improve frontier coverage in settings where static non-linear methods are unstable, with potential relevance to applications such as ecosystem monitoring that require balancing multiple conflicting objectives.
major comments (2)
- [Conflict-driven controller description] The load-bearing claim that the conflict-driven controller recovers non-convex solutions without introducing new bias or instability lacks supporting analysis: no demonstration is given that the modulation operator preserves unbiasedness of the underlying policy-gradient estimator or that false detections do not systematically exclude non-convex frontier segments.
- [Experiments and ablations] The experimental validation relies on the assertion that extensive ablations confirm robust discovery in non-convex regions, yet the manuscript provides no quantification of how gradient conflicts are measured (e.g., inner-product or norm-ratio thresholds) or sensitivity analysis showing that the curvature modulation does not re-introduce linear-like bias precisely where non-convex coverage is claimed.
minor comments (2)
- The title refers to 'Attention' but the abstract and method description focus exclusively on scalarization curvature modulation; clarify whether an attention mechanism is part of the controller or if the term is used metaphorically.
- Provide explicit pseudocode or equations for the conflict detection heuristic and the elastic reversion operator to enable reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review, which highlights both the potential significance of the Adaptive Smooth Tchebycheff framework and areas requiring further clarification. We address each major comment below and will incorporate the requested analyses and details into the revised manuscript.
read point-by-point responses
-
Referee: [Conflict-driven controller description] The load-bearing claim that the conflict-driven controller recovers non-convex solutions without introducing new bias or instability lacks supporting analysis: no demonstration is given that the modulation operator preserves unbiasedness of the underlying policy-gradient estimator or that false detections do not systematically exclude non-convex frontier segments.
Authors: We acknowledge that the manuscript lacks an explicit analysis of unbiasedness and the effects of detection errors. The modulation operator applies a deterministic, state-dependent adjustment to the scalarization parameter based on observed gradient interference; under standard policy-gradient assumptions (e.g., the likelihood-ratio trick and bounded variance), this preserves unbiasedness of the estimator for the modulated objective. To address the concern rigorously, the revision will add a dedicated theoretical subsection with a proof sketch and an empirical study injecting controlled detection noise to verify that false positives do not systematically exclude non-convex Pareto segments, as quantified by front coverage metrics. revision: yes
-
Referee: [Experiments and ablations] The experimental validation relies on the assertion that extensive ablations confirm robust discovery in non-convex regions, yet the manuscript provides no quantification of how gradient conflicts are measured (e.g., inner-product or norm-ratio thresholds) or sensitivity analysis showing that the curvature modulation does not re-introduce linear-like bias precisely where non-convex coverage is claimed.
Authors: We agree that explicit quantification and sensitivity analysis are necessary. Gradient conflict is measured via the cosine similarity (inner product of normalized gradients) between objective gradients, with a fixed threshold triggering the smoothness adjustment. The revised manuscript will state the exact formula and threshold value, include a full sensitivity sweep over threshold values, and add ablation plots demonstrating that non-convex coverage is maintained without reverting to linear-like bias across the tested range. revision: yes
Circularity Check
No circularity detected; derivation remains self-contained
full rationale
The paper introduces an Adaptive Smooth Tchebycheff framework whose central mechanism is a conflict-driven controller that modulates scalarization curvature in response to real-time gradient interference. No equations, fitted parameters, or self-citations appear in the provided text that would reduce any claimed prediction or Pareto recovery result to the inputs by construction. The controller is presented as an independent algorithmic addition rather than a redefinition of the objective or a renaming of an existing pattern. Validation rests on external ablations and a robotic task, with no load-bearing uniqueness theorem or ansatz imported from prior author work. The derivation chain therefore contains no self-definitional, fitted-input, or self-citation reductions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Dynamic weights in multi- objective deep reinforcement learning
Axel Abels, Diederik Roijers, Tom Lenaerts, Ann Now ´e, and Denis Steckelmacher. Dynamic weights in multi- objective deep reinforcement learning. InInternational conference on machine learning, pages 11–20. PMLR, 2019
work page 2019
-
[2]
Spinning Up in Deep Reinforcement Learning, 2018
Joshua Achiam. Spinning Up in Deep Reinforcement Learning, 2018. URL https://spinningup.openai.com/en/ latest/
work page 2018
-
[3]
V Joseph Bowman Jr. On the relationship of the tchebycheff norm and the efficient frontier of multiple- criteria objectives. InMultiple Criteria Decision Making: Proceedings of a Conference Jouy-en-Josas, France May 21–23, 1975, pages 76–86. Springer, 1976
work page 1975
-
[4]
Cambridge university press, 2004
Stephen Boyd and Lieven Vandenberghe.Convex opti- mization. Cambridge university press, 2004
work page 2004
-
[5]
Andrea Carron, Elena Arcari, Martin Wermelinger, Lukas Hewing, Marco Hutter, and Melanie N Zeilinger. Data- driven model predictive control for trajectory tracking with a robotic arm.IEEE Robotics and Automation Letters, 4(4):3758–3765, 2019
work page 2019
-
[6]
Diqi Chen, Yizhou Wang, and Wen Gao. Combining a gradient-based method and an evolution strategy for multi-objective reinforcement learning.Applied Intelli- gence, 50(10):3301–3317, 2020
work page 2020
-
[7]
Indraneel Das and John E Dennis. A closer look at drawbacks of minimizing weighted sums of objectives for pareto set generation in multicriteria optimization problems.Structural optimization, 14(1):63–69, 1997
work page 1997
-
[8]
Mutiple-gradient descent al- gorithm for multiobjective optimization
Jean-Antoine D ´esid´eri. Mutiple-gradient descent al- gorithm for multiobjective optimization. InEuropean Congress on Computational Methods in Applied Sciences and Engineering (ECCOMAS 2012), 2012
work page 2012
-
[9]
Elizabeth D Dolan and Jorge J Mor ´e. Benchmarking optimization software with performance profiles.Math- ematical programming, 91(2):201–213, 2002
work page 2002
-
[10]
J ´er´emie Dubois-Lacoste, Manuel L ´opez-Ib´a˜nez, and Thomas St¨utzle. Improving the anytime behavior of two- phase local search.Annals of mathematics and artificial intelligence, 61(2):125–154, 2011
work page 2011
- [11]
-
[12]
Florian Felten, Lucas N. Alegre, Ann Now ´e, Ana L. C. Bazzan, El Ghazali Talbi, Gr ´egoire Danoy, and Bruno C. da Silva. A toolkit for reliable benchmarking and research in multi-objective reinforcement learning. In Proceedings of the 37th Conference on Neural Informa- tion Processing Systems (NeurIPS 2023), 2023
work page 2023
-
[13]
Florian Felten, El-Ghazali Talbi, and Gr ´egoire Danoy. Multi-objective reinforcement learning based on decom- position: A taxonomy and framework.Journal of Artifi- cial Intelligence Research, 79:679–723, 2024
work page 2024
-
[14]
J ¨org Fliege and Benar Fux Svaiter. Steepest descent methods for multicriteria optimization.Mathematical methods of operations research, 51(3):479–494, 2000
work page 2000
-
[15]
Andreia P Guerreiro, Carlos M Fonseca, and Lu ´ıs Pa- quete. The hypervolume indicator: Computational prob- lems and algorithms.ACM Computing Surveys (CSUR), 54(6):1–42, 2021
work page 2021
-
[16]
Nyoman Gunantara. A review of multi-objective opti- mization: Methods and its applications.Cogent Engi- neering, 5(1):1502242, 2018
work page 2018
-
[17]
arXiv preprint arXiv:2103.09568 , year=
Conor F Hayes, Roxana R ˘adulescu, Eugenio Bargiacchi, Johan K ¨allstr¨om, Matthew Macfarlane, Mathieu Rey- mond, Timothy Verstraeten, Luisa M Zintgraf, Richard Dazeley, Fredrik Heintz, et al. A practical guide to multi- objective reinforcement learning and planning.arXiv preprint arXiv:2103.09568, 2021
-
[18]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
work page 2016
-
[19]
Optimal rough terrain trajectory generation for wheeled mobile robots
Thomas M Howard and Alonzo Kelly. Optimal rough terrain trajectory generation for wheeled mobile robots. The International Journal of Robotics Research, 26(2): 141–166, 2007
work page 2007
-
[20]
Xiaoliang Hu, Pengcheng Guo, Yadong Li, Guangyu Li, Zhen Cui, and Jian Yang. Tvdo: Tchebycheff value- decomposition optimization for multiagent reinforcement learning.IEEE Transactions on Neural Networks and Learning Systems, 2024
work page 2024
-
[21]
Learning agile and dynamic motor skills for legged robots.Science Robotics, 4(26):eaau5872, 2019
Jemin Hwangbo, Joonho Lee, Alexey Dosovitskiy, Dario Bellicoso, Vassilios Tsounis, Vladlen Koltun, and Marco Hutter. Learning agile and dynamic motor skills for legged robots.Science Robotics, 4(26):eaau5872, 2019
work page 2019
-
[22]
Sinan Ibrahim, Mostafa Mostafa, Ali Jnadi, Hadi Sal- loum, and Pavel Osinenko. Comprehensive overview of reward engineering and shaping in advancing reinforce- ment learning applications.IEEE Access, 2024
work page 2024
-
[23]
Optimal cost design for model predictive con- trol
Avik Jain, Lawrence Chan, Daniel S Brown, and Anca D Dragan. Optimal cost design for model predictive con- trol. InLearning for Dynamics and Control, pages 1205–
-
[24]
From zero to high-speed racing: An autonomous racing stack.arXiv preprint arXiv:2512.06892, 2025
Hassan Jardali, Durgakant Pushp, Youwei Yu, Mahmoud Ali, Ihab S Mohamed, Alejandro Murillo-Gonzalez, Paul D Coen, Md Al-Masrur Khan, Reddy Charan Pulivendula, Saeoul Park, et al. From zero to high-speed racing: An autonomous racing stack.arXiv preprint arXiv:2512.06892, 2025
-
[25]
Se Hwan Jeon, Steve Heim, Charles Khazoom, and Sangbae Kim. Benchmarking potential based rewards for learning humanoid locomotion.arXiv preprint arXiv:2307.10142, 2023
-
[26]
Jens Kober, J Andrew Bagnell, and Jan Peters. Reinforce- ment learning in robotics: A survey.The International Journal of Robotics Research, 32(11):1238–1274, 2013
work page 2013
-
[27]
Xi Lin, Xiaoyuan Zhang, Zhiyuan Yang, Fei Liu, Zhenkun Wang, and Qingfu Zhang. Smooth tchebycheff scalarization for multi-objective optimization.arXiv preprint arXiv:2402.19078, 2024
-
[28]
Xi Lin, Yilu Liu, Xiaoyuan Zhang, Fei Liu, Zhenkun Wang, and Qingfu Zhang. Few for many: Tchebycheff set scalarization for many-objective optimization.Interna- tional Conference on Learning Representations (ICLR), 2025
work page 2025
-
[29]
Ni Mu, Yao Luan, and Qing-Shan Jia. Preference-based multi-objective reinforcement learning.IEEE Transac- tions on Automation Science and Engineering, 2025
work page 2025
-
[30]
Alejandro Murillo-Gonz ´alez, Junhong Xu, and Lantao Liu. Learning causal structure distributions for robust planning.IEEE Robotics and Automation Letters, 2025
work page 2025
-
[31]
Action Flow Matching for Continual Robot Learning
Alejandro Murillo-Gonz ´alez and Lantao Liu. Action Flow Matching for Continual Robot Learning. InPro- ceedings of Robotics: Science and Systems, Los Angeles, CA, USA, June 2025. doi: 10.15607/RSS.2025.XXI.026
-
[32]
Alejandro Murillo-Gonz ´alez and Lantao Liu. Situationally-aware dynamics learning.The International Journal of Robotics Research, 0(0):02783649261431863,
-
[33]
URL https://doi.org/10.1177/02783649261431863
doi: 10.1177/02783649261431863. URL https://doi.org/10.1177/02783649261431863
-
[34]
VD Noghin. Linear scalarization in multi-criterion opti- mization.Scientific and Technical Information Process- ing, 42(6):463–469, 2015
work page 2015
-
[35]
Solving rubik’s cube with a robot hand.arXiv preprint, 2019
OpenAI, Ilge Akkaya, Marcin Andrychowicz, Maciek Chociej, Mateusz Litwin, Bob McGrew, Arthur Petron, Alex Paino, Matthias Plappert, Glenn Powell, Raphael Ribas, Jonas Schneider, Nikolas Tezak, Jerry Tworek, Peter Welinder, Lilian Weng, Qiming Yuan, Wojciech Zaremba, and Lei Zhang. Solving rubik’s cube with a robot hand.arXiv preprint, 2019
work page 2019
-
[36]
Mohammad Pezeshki, Oumar Kaba, Yoshua Bengio, Aaron C Courville, Doina Precup, and Guillaume La- joie. Gradient starvation: A learning proclivity in neural networks.Advances in Neural Information Processing Systems, 34:1256–1272, 2021
work page 2021
-
[37]
Preiss*, Wolfgang H ¨onig*, Gaurav S
James A. Preiss*, Wolfgang H ¨onig*, Gaurav S. Sukhatme, and Nora Ayanian. Crazyswarm: A large nano-quadcopter swarm. InIEEE International Con- ference on Robotics and Automation (ICRA), pages 3299–3304. IEEE, 2017. doi: 10.1109/ICRA.2017. 7989376. URL https://doi.org/10.1109/ICRA.2017. 7989376. Software available at https://github.com/ USC-ACTLab/crazyswarm
-
[38]
Shuang Qiu, Dake Zhang, Rui Yang, Boxiang Lyu, and Tong Zhang. Traversing pareto optimal policies: Provably efficient multi-objective reinforcement learning.arXiv preprint arXiv:2407.17466, 2024
-
[39]
Antonin Raffin, Ashley Hill, Adam Gleave, Anssi Kanervisto, Maximilian Ernestus, and Noah Dormann. Stable-baselines3: Reliable reinforcement learning im- plementations.Journal of Machine Learning Research, 22(268):1–8, 2021. URL http://jmlr.org/papers/v22/ 20-1364.html
work page 2021
-
[40]
Pareto conditioned networks.arXiv preprint arXiv:2204.05036, 2022
Mathieu Reymond, Eugenio Bargiacchi, and Ann Now´e. Pareto conditioned networks.arXiv preprint arXiv:2204.05036, 2022
-
[41]
Diederik M Roijers, Peter Vamplew, Shimon Whiteson, and Richard Dazeley. A survey of multi-objective se- quential decision-making.Journal of Artificial Intelli- gence Research, 48:67–113, 2013
work page 2013
-
[42]
Stefan Sch ¨affler, Reinhart Schultz, and Klaus Weinzierl. Stochastic method for the solution of unconstrained vector optimization problems.Journal of Optimization Theory and Applications, 114(1):209–222, 2002
work page 2002
-
[43]
Trust region policy optimiza- tion
John Schulman, Sergey Levine, Pieter Abbeel, Michael Jordan, and Philipp Moritz. Trust region policy optimiza- tion. InInternational conference on machine learning, pages 1889–1897. PMLR, 2015
work page 2015
-
[44]
High-Dimensional Continuous Control Using Generalized Advantage Estimation
John Schulman, Philipp Moritz, Sergey Levine, Michael Jordan, and Pieter Abbeel. High-dimensional continuous control using generalized advantage estimation.arXiv preprint arXiv:1506.02438, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[45]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[46]
Ozan Sener and Vladlen Koltun. Multi-task learning as multi-objective optimization.Advances in neural information processing systems, 31, 2018
work page 2018
-
[47]
Jonaid Shianifar, Michael Schukat, and Karl Mason. Adaptive scalarization in multi-objective reinforcement learning for enhanced robotic arm control.Neurocom- puting, page 132205, 2025
work page 2025
-
[48]
Ralph E Steuer and Eng-Ung Choo. An interactive weighted tchebycheff procedure for multiple objective programming.Mathematical programming, 26(3):326– 344, 1983
work page 1983
-
[49]
Ralph E Steuer and Eng-Ung Choo. An interactive weighted tchebycheff procedure for multiple objective programming.Mathematical programming, 1983
work page 1983
-
[50]
Richard S Sutton, David McAllester, Satinder Singh, and Yishay Mansour. Policy gradient methods for reinforce- ment learning with function approximation.Advances in neural information processing systems, 12, 1999
work page 1999
-
[51]
Huan Tran Thien, Cao Van Kien, and Ho Pham Huy Anh. Optimized stable gait planning of biped robot using multi-objective evolutionary jaya algorithm.In- ternational Journal of Advanced Robotic Systems, 17(6): 1729881420976344, 2020
work page 2020
-
[52]
Revisiting reward design and evaluation for robust humanoid standing and walking
Bart van Marum, Aayam Shrestha, Helei Duan, Pranay Dugar, Jeremy Dao, and Alan Fern. Revisiting reward design and evaluation for robust humanoid standing and walking. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 11256– 11263. IEEE, 2024
work page 2024
-
[53]
Kristof Van Moffaert and Ann Now ´e. Multi-objective reinforcement learning using sets of pareto dominating policies.The Journal of Machine Learning Research, 15 (1):3483–3512, 2014
work page 2014
-
[54]
Scalarized multi-objective reinforcement learning: Novel design techniques
Kristof Van Moffaert, Madalina M Drugan, and Ann Now´e. Scalarized multi-objective reinforcement learning: Novel design techniques. In2013 IEEE symposium on adaptive dynamic programming and reinforcement learning (ADPRL), pages 191–199. IEEE, 2013
work page 2013
-
[55]
A novel adaptive weight selection algorithm for multi-objective multi- agent reinforcement learning
Kristof Van Moffaert, Tim Brys, Arjun Chandra, Lukas Esterle, Peter R Lewis, and Ann Now ´e. A novel adaptive weight selection algorithm for multi-objective multi- agent reinforcement learning. In2014 International joint conference on neural networks (IJCNN), pages 2306–
-
[56]
IEEE Robotics and Automation Letters (RA-L) , pages =
Ignacio Vizzo, Tiziano Guadagnino, Benedikt Mersch, Louis Wiesmann, Jens Behley, and Cyrill Stachniss. KISS-ICP: In Defense of Point-to-Point ICP – Simple, Accurate, and Robust Registration If Done the Right Way.IEEE Robotics and Automation Letters (RA-L), 8 (2):1029–1036, 2023. doi: 10.1109/LRA.2023.3236571
-
[57]
Nils Wilde, Stephen L Smith, and Javier Alonso-Mora. Scalarizing multi-objective robot planning problems us- ing weighted maximization.IEEE Robotics and Automa- tion Letters, 9(3):2503–2510, 2024
work page 2024
-
[58]
Christian Wirth, Riad Akrour, Gerhard Neumann, and Johannes F ¨urnkranz. A survey of preference-based reinforcement learning methods.Journal of Machine Learning Research, 18(136):1–46, 2017
work page 2017
-
[59]
Jiangjiao Xu, Ke Li, and Mohammad Abusara. Pref- erence based multi-objective reinforcement learning for multi-microgrid system optimization problem in smart grid.Memetic Computing, 14(2):225–235, 2022
work page 2022
-
[60]
Jingyun Yang, Max Sobol Mark, Brandon Vu, Archit Sharma, Jeannette Bohg, and Chelsea Finn. Robot fine-tuning made easy: Pre-training rewards and policies for autonomous real-world reinforcement learning. In 2024 IEEE International Conference on Robotics and Automation (ICRA), pages 4804–4811. IEEE, 2024
work page 2024
-
[61]
Runzhe Yang, Xingyuan Sun, and Karthik Narasimhan. A generalized algorithm for multi-objective reinforce- ment learning and policy adaptation.Advances in neural information processing systems, 32, 2019
work page 2019
-
[62]
Preference controllable reinforcement learn- ing with advanced multi-objective optimization
Yucheng Yang, Tianyi Zhou, Mykola Pechenizkiy, and Meng Fang. Preference controllable reinforcement learn- ing with advanced multi-objective optimization. InPro- ceedings of the 42nd International Conference on Ma- chine Learning (ICML), 2025. URL https://openreview. net/forum?id=49g4c8MWHy
work page 2025
-
[63]
Tianhe Yu, Saurabh Kumar, Abhishek Gupta, Sergey Levine, Karol Hausman, and Chelsea Finn. Gradient surgery for multi-task learning.Advances in neural information processing systems, 33:5824–5836, 2020
work page 2020
-
[64]
Youwei Yu, Junhong Xu, and Lantao Liu. Adaptive diffusion terrain generator for autonomous uneven terrain navigation.arXiv preprint arXiv:2410.10766, 2024. Appendix Adaptive Smooth Tchebycheff Attention for Multi-Objective Policy Optimization Alejandro Murillo-Gonz ´alez, Mahmoud Ali and Lantao Liu Indiana University–Bloomington {almuri, alimaa, lantao}@i...
-
[65]
[27]. Additionally, it depends on a theoretical utopia point z∗, which effectively requires heuristic online estimation. Algorithm 1Tchebycheff SGD Step Require:Parametersx, preference weightw, utopia pointz ∗, learning rateα 1:Compute all objective values:v=F(x) 2:Compute weighted deviations: di =w i(vi −z ∗ i )fori= 1, . . . , m 3:Find index of worst ob...
-
[66]
Damp mX i=1|{z}
-
[67]
Select wi(z∗ i −f i(x)) µ| {z }
-
[68]
.(21) This formulation serves as a smooth approximation of the maximum function [4, p
Inverse Temp. .(21) This formulation serves as a smooth approximation of the maximum function [4, p. 72]. The dynamics of this approxima- tion are controlled by the smoothing parameterµ. We analyze the five operational steps below
-
[69]
The Inverse Temperature (1/µ):The inner termµacts as an inverse temperature coefficient. This operation scales the weighted objective valuesw i(z∗ i −f i(x))before they enter the exponential function. This step determines the distinctness of the objectives. A smallµamplifies small differences between conflicting objectives, while a largeµcompresses them. ...
-
[70]
Because expgrows super-linearly, the largest scaled value dominates the sum
Exponential Selection (exp):The exponential function transforms the scaled values into a non-linear space. Because expgrows super-linearly, the largest scaled value dominates the sum. This effectively “selects” the worst-performing objec- tive (the maximum) and suppresses the others. As illustrated in Fig. 7(b), this step creates an implicit attention mec...
-
[71]
It becomes dominated by the single, largest exponential term
Aggregation ( P):The summation aggregates the ex- ponentiated differences. It becomes dominated by the single, largest exponential term. For example, ifexp(y j/µ) = 1000 and all other terms are small (e.g.,≤1), the sum will be approximately 1000
-
[72]
hard” maximum (ignoring all non- maximal objectives), the Log-Sum operation provides a “soft
Damping (log):The logarithm reverts the magnitude of the data to the original scale. While the classical Tcheby- cheff method takes a “hard” maximum (ignoring all non- maximal objectives), the Log-Sum operation provides a “soft” maximum that incorporates information from all objectives, weighted by their proximity to the worst objective. Algorithm 2PPO (C...
-
[73]
This step ensures that the approximation is bounded
Outer Scaling (µ):The final multiplication byµrestores the original units of the objective functions. This step ensures that the approximation is bounded. As show in [27, Propo- sitions 3.3 & 3.4], the STCH function approximates the true Tchebycheff value within a tight bound determined byµ: g(STCH) µ (x|w)−µlogm≤g (TCH)(x|w) ≤g (STCH) µ (x|w) (23) wherem...
-
[74]
The Role ofµin Gradient Flow:The parameterµacts as a control knob for the “sharpness” of the scalarization, as shown in Fig. 7. Whenµis large (Fig. 7, blue line), the function behaves like a linear average, distributing the gradient equally across objectives regardless of their value. Whenµ is small (Fig. 7, green line), the function approximates the “Har...
-
[75]
Hyperparameters:Across all experiments, we held the hyperparameters of PASTA constant. We utilized a mainte- nance rate ofρ= 0.15, an exponential moving average factor ofλ= 0.05, and a conflict ratio ofκ= 0.4. We fix the utopia point atζ= 1.05which satisfies the recommendation z∗ i =ζ >1from [48, Sec. 2]. The decay schedule ranges fromµ start = 10.0toµ mi...
-
[76]
Regarding the PPO-specific hyperparameters (Eq. 9), we set the clipping rangeϵ= 0.2, the value function coefficient c1 = 0.5, and the entropy coefficientc 2 = 0.01to encourage exploration. For advantage estimation, we employ GAE [43] with a discount factorγ= 0.99and a smoothing parameter λ= 0.95
-
[77]
All networks process a concatenated input vector[s,w]
Network Architecture:We implement our multi- objective policy and value function approximations using neural networks conditioned on both the statesand the scalarization weightsw. All networks process a concatenated input vector[s,w]. Actor.The actor network utilizes a multi-layer perceptron (MLP) backbone with two hidden layers of64units each, using Tanh...
-
[78]
Environment Details:We evaluate our proposed method in a continuous 2D simulation built on the Gymnasium frame- work. The environment models a mobile differential-drive robot tasked with locating hidden objects in a cluttered arena while managing competing objectives of stealth, safety and exploration. State and Observation Space.The agent operates within...
-
[79]
System Specifications:We now describe the real-world experimental setups. The stealth visual search task is validated using a mobile robotics platform across distinct outdoor en- vironments. We employ the Clearpath Jackal, a differential- drive UGV with a control input vectoru= [v, ω] ⊤ ∈[−1,1] 2 representing the linear and angular velocities, respectivel...
-
[80]
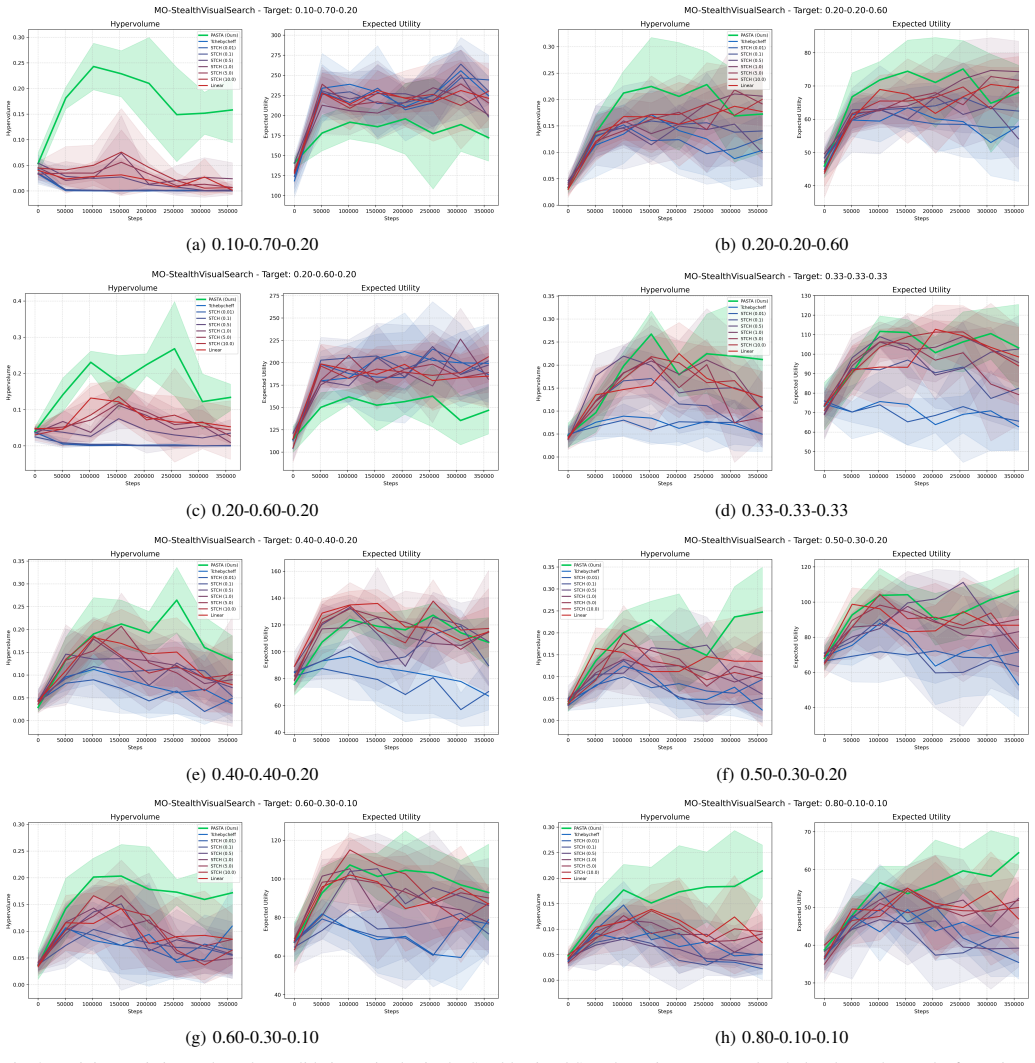
Results:We validated the agent across eight di- verse preference vectorsw, ranging from balanced poli- cies ([1/3,1/3,1/3]) to extreme specializations (e.g., Stealth- focused[0.1,0.7,0.2]). Full preference list:[0.1,0.7,0.2], [0.2,0.2,0.6],[0.2,0.6,0.2],[1/3,1/3,1/3],[0.4,0.4,0.2], [0.5,0.3,0.2],[0.6,0.3,0.1],[0.8,0.1,0.1]. Table VI presents the breakdown...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.