Recognition: 2 theorem links
· Lean TheoremBefore the Body Moves: Learning Anticipatory Joint Intent for Language-Conditioned Humanoid Control
Pith reviewed 2026-05-15 02:11 UTC · model grok-4.3
The pith
DAJI learns dynamics-aligned joint intents so language commands produce humanoid actions that are both immediate and anticipatory of future contacts and balance shifts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
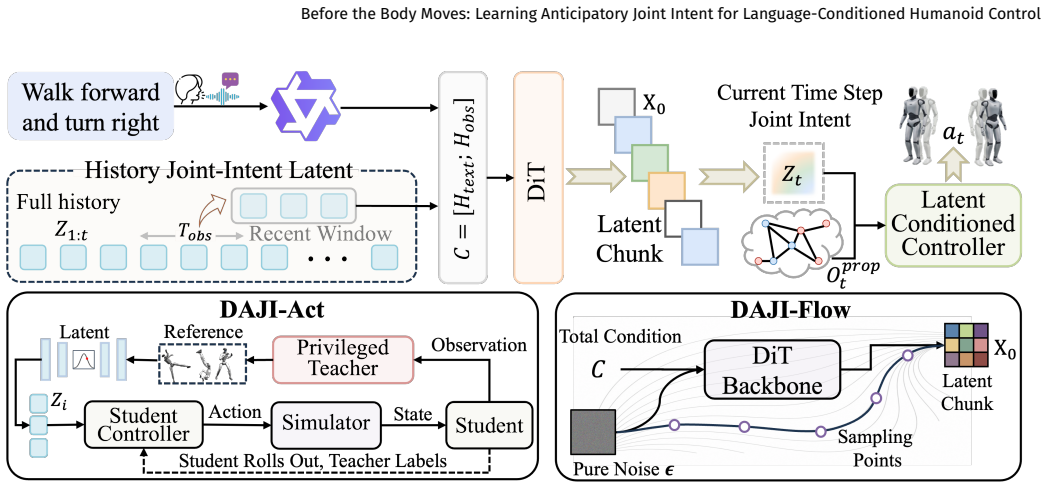
DAJI is a hierarchical framework whose DAJI-Act component distills a future-aware teacher policy into a deployable diffusion action policy through student-driven rollouts, while its DAJI-Flow component autoregressively generates future intent chunks conditioned on language and prior intent. This joint-intent layer sits between language generation and closed-loop control and explicitly encodes upcoming contact changes, support transfers, and balance preparation. Experiments report 94.42% rollout success on HumanML3D-style generation tasks and 0.152 subsequence FID on BABEL streaming benchmarks.
What carries the argument
Dynamics-Aligned Joint Intent (DAJI), a hierarchical anticipatory interface that encodes future contact and balance information between language inputs and low-level control outputs.
If this is right
- Enables language-conditioned generation of whole-body actions that prepare for upcoming contacts rather than repairing after the fact.
- Supports streaming instruction following at 0.152 subsequence FID while maintaining 94.42% rollout success on standard benchmarks.
- Provides an explicit latent representation of future joint states that low-level trackers can use without reactive correction.
- Allows single-instruction and multi-turn language commands to produce coherent sequences of anticipatory intents.
Where Pith is reading between the lines
- The same distillation-plus-autoregressive structure could be tested on non-humanoid platforms where anticipatory contact planning matters, such as wheeled or legged mobile manipulators.
- If the joint-intent layer proves stable, it could reduce reliance on separate kinematic reference generators that later require low-level repair.
- Extending the intent chunks to include visual or tactile predictions would be a direct next measurement of whether the anticipatory signal generalizes beyond motion only.
Load-bearing premise
Distilling a future-aware teacher policy into a deployable diffusion action policy via student-driven rollouts preserves the anticipatory properties without substantial degradation in closed-loop performance.
What would settle it
A closed-loop evaluation that shows substantially lower rollout success or markedly higher subsequence FID when the distilled student policy is used instead of the teacher would indicate that the distillation step fails to retain anticipatory capability.
Figures




read the original abstract
Natural language is an intuitive interface for humanoid robots, yet streaming whole-body control requires control representations that are executable now and anticipatory of future physical transitions. Existing language-conditioned humanoid systems typically generate kinematic references that a low-level tracker must repair reactively, or use latent/action policies whose outputs do not explicitly encode upcoming contact changes, support transfers, and balance preparation. We propose \textbf{DAJI} (\emph{Dynamics-Aligned Joint Intent}), a hierarchical framework that learns an anticipatory joint-intent interface between language generation and closed-loop control. DAJI-Act distills a future-aware teacher into a deployable diffusion action policy through student-driven rollouts, while DAJI-Flow autoregressively generates future intent chunks from language and intent history. Experiments show that DAJI achieves strong results in anticipatory latent learning, single-instruction generation, and streaming instruction following, reaching 94.42\% rollout success on HumanML3D-style generation and 0.152 subsequence FID on BABEL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DAJI (Dynamics-Aligned Joint Intent), a hierarchical framework for language-conditioned humanoid control. DAJI-Act distills a future-aware teacher policy into a deployable diffusion action policy via student-driven rollouts, while DAJI-Flow autoregressively generates future intent chunks from language and intent history. Experiments claim strong performance in anticipatory latent learning, single-instruction generation, and streaming instruction following, with 94.42% rollout success on HumanML3D-style tasks and 0.152 subsequence FID on BABEL.
Significance. If the distillation successfully transfers anticipatory properties to the closed-loop diffusion policy, the work could advance language-conditioned whole-body control by enabling proactive handling of contact changes, support transfers, and balance preparation rather than relying on reactive low-level repairs. The separation of future-intent generation from executable action diffusion offers a scalable interface for streaming humanoid tasks.
major comments (1)
- [§3.2] §3.2 (DAJI-Act distillation procedure): the student-driven rollout objective contains no explicit future-horizon loss, teacher-student anticipation alignment term, or future-state prediction error regularizer. This is load-bearing for the central claim that the deployable diffusion policy encodes upcoming contact changes and balance preparation, because without such a term the policy can achieve high rollout success while collapsing to reactive behavior. Please add a quantitative alignment metric between teacher and student future predictions and report its value in the results.
minor comments (2)
- [Abstract] Abstract: quantitative claims (94.42% success, 0.152 FID) are stated without naming the baselines, ablation variants, or error-bar statistics; a one-sentence reference to the comparison methods would improve readability.
- [§2] Notation: the distinction between 'joint intent' and 'action' chunks is introduced without a compact equation or diagram in the early sections; adding a small schematic would clarify the hierarchical interface.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and constructive suggestion regarding the distillation procedure. We address the major comment below and outline the planned revision.
read point-by-point responses
-
Referee: [§3.2] §3.2 (DAJI-Act distillation procedure): the student-driven rollout objective contains no explicit future-horizon loss, teacher-student anticipation alignment term, or future-state prediction error regularizer. This is load-bearing for the central claim that the deployable diffusion policy encodes upcoming contact changes and balance preparation, because without such a term the policy can achieve high rollout success while collapsing to reactive behavior. Please add a quantitative alignment metric between teacher and student future predictions and report its value in the results.
Authors: We appreciate the referee's point that an explicit alignment term would more directly substantiate the transfer of anticipatory behavior. The current student-driven rollout objective matches the teacher policy's actions on trajectories that require proactive contact and balance decisions for success; this implicitly encourages the student to internalize future-aware behavior rather than purely reactive corrections. Nevertheless, we agree that a dedicated quantitative metric strengthens the central claim. In the revised manuscript we will introduce and report a teacher-student future-prediction alignment metric (mean L2 distance on predicted joint intents and contact flags over a 10-step horizon, computed on held-out rollouts) in the results section. revision: yes
Circularity Check
No significant circularity; claims rest on empirical rollouts
full rationale
The paper presents DAJI as a hierarchical framework with DAJI-Act performing distillation via student-driven rollouts from a future-aware teacher and DAJI-Flow generating intent chunks autoregressively. Reported metrics (94.42% rollout success, 0.152 subsequence FID) are obtained from closed-loop evaluations on HumanML3D and BABEL benchmarks. No equations, definitions, or self-citations in the abstract or described method reduce these outcomes to fitted parameters or prior results by construction. The distillation step is presented as an empirical procedure without a uniqueness theorem or ansatz imported from self-citation that would force the anticipatory properties. This is the common case of an empirical robotics paper whose central claims remain falsifiable via external rollouts.
Axiom & Free-Parameter Ledger
free parameters (1)
- diffusion and flow model hyperparameters
axioms (1)
- domain assumption A future-aware teacher policy can be distilled into a real-time student without loss of anticipatory capability
Reference graph
Works this paper leans on
-
[1]
Movement,postureandequilibrium:Interaction and coordination
J.Massion,“Movement,postureandequilibrium:Interaction and coordination”,Progress in neurobiology, vol. 38, no. 1, pp.35–56,1992
work page 1992
-
[2]
Posture,dynamicstability,andvol- untarymovement
S.BouissetandM.-C.Do,“Posture,dynamicstability,andvol- untarymovement”,NeurophysiologieClinique/ClinicalNeuro- physiology,vol.38,no.6,pp.345–362,2008
work page 2008
-
[3]
E.Todorov,T.Erez,andY.Tassa,“Mujoco:Aphysicsengine formodel-basedcontrol”,in2012IEEE/RSJInternationalCon- ferenceonIntelligentRobotsandSystems,IEEE,2012,pp.5026– 5033.doi:10.1109/IROS.2012.6386109
-
[4]
The kit motion- languagedataset
M. Plappert, C. Mandery, and T. Asfour, “The kit motion- languagedataset”,BigData,vol.4,no.4,pp.236–252,2016
work page 2016
-
[5]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms”,CoRR, vol.abs/1707.06347,2017.arXiv:1707.06347.[Online].Avail- able:http://arxiv.org/abs/1707.06347
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[6]
Deep- mimic:Example-guideddeepreinforcementlearningofphysics- basedcharacterskills
X.B.Peng,P.Abbeel,S.Levine,andM.VandePanne,“Deep- mimic:Example-guideddeepreinforcementlearningofphysics- basedcharacterskills”,ACMTransactionsOnGraphics(TOG), vol.37,no.4,pp.1–14,2018
work page 2018
-
[7]
Denoisingdiffusionprobabilistic models
J.Ho,A.Jain,andP.Abbeel,“Denoisingdiffusionprobabilistic models”,inAdvancesinNeuralInformationProcessingSystems, vol.33,CurranAssociates,Inc.,2020,pp.6840–6851.[Online]. Available: https://proceedings.neurips.cc/paper/2020/file/ 4c5bcfec8584af0d967f1ab10179ca4b-Paper.pdf
work page 2020
-
[8]
Babel:Bodies,actionandbehavior withenglishlabels
A.R.Punnakkal,A.Chandrasekaran,N.Athanasiou,A.Quiros- Ramirez,andM.J.Black,“Babel:Bodies,actionandbehavior withenglishlabels”,inProceedingsoftheIEEE/CVFConference onComputerVisionandPatternRecognition(CVPR),Jun.2021, pp.722–731
work page 2021
-
[9]
Denoisingdiffusionimplicit models
J.Song,C.Meng,andS.Ermon,“Denoisingdiffusionimplicit models”,in9thInternationalConferenceonLearningRepresen- tations,ICLR2021,OpenReview.net,2021.[Online].Available: https://openreview.net/forum?id=St1giarCHLP
work page 2021
-
[10]
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
M.Ahnetal.,“Doasican,notasisay:Groundinglanguagein roboticaffordances”,arXivpreprintarXiv:2204.01691,2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[11]
Generatingdiverseandnatural3dhumanmo- tionsfromtext
C.Guoetal.,“Generatingdiverseandnatural3dhumanmo- tionsfromtext”,inCVPR,2022
work page 2022
-
[12]
G.Tevet,S.Raab,B.Gordon,Y.Shafir,D.Cohen-Or,andA.H. Bermano, “Human motion diffusion model”,arXiv preprint arXiv:2209.14916,2022
work page internal anchor Pith review arXiv 2022
-
[13]
Momask: Generative masked modeling of 3d human motions
C.Guo,Y.Mu,M.G.Javed,S.Wang,andL.Cheng,“Momask: Generative masked modeling of 3d human motions”,arXiv preprintarXiv:2312.00063,2023
-
[14]
Motionflowmatchingforhumanmotionsyn- thesisandediting
V.T.Huetal.,“Motionflowmatchingforhumanmotionsyn- thesisandediting”,arXivpreprintarXiv:2312.08895,2023
-
[15]
VoxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models
W. Huang, C. Wang, R. Zhang, Y. Li, J. Wu, and L. Fei-Fei, “Voxposer:Composable3dvaluemapsforroboticmanipulation withlanguagemodels”,arXivpreprintarXiv:2307.05973,2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Codeaspolicies:Languagemodelprogramsfor embodiedcontrol
J.Liangetal.,“Codeaspolicies:Languagemodelprogramsfor embodiedcontrol”,in2023IEEEInternationalconferenceon roboticsandautomation(ICRA),IEEE,2023,pp.9493–9500
work page 2023
-
[17]
Flowmatchingforgenerativemodeling
Y.Lipman,R.T.Q.Chen,H.Ben-Hamu,M.Nickel,andM.Le, “Flowmatchingforgenerativemodeling”,inTheEleventhIn- ternationalConferenceonLearningRepresentations,ICLR2023, OpenReview.net,2023.[Online].Available:https://openreview. net/forum?id=PqvMRDCJT9t
work page 2023
-
[18]
Perpetual humanoid controlforreal-timesimulatedavatars
Z. Luo, J. Cao, K. Kitani, W. Xu, et al., “Perpetual humanoid controlforreal-timesimulatedavatars”,inProceedingsofthe IEEE/CVFInternationalConferenceonComputerVision,2023, pp.10895–10904
work page 2023
-
[19]
Scalable diffusion models with trans- formers
W. Peebles and S. Xie, “Scalable diffusion models with trans- formers”,inProceedingsoftheIEEE/CVFInternationalConfer- enceonComputerVision(ICCV),Oct.2023,pp.4195–4205
work page 2023
-
[20]
Calm: Conditional adversarial latent models for directablevirtualcharacters
C. Tessler, Y. Kasten, Y. Guo, S. Mannor, G. Chechik, and X. B. Peng, “Calm: Conditional adversarial latent models for directablevirtualcharacters”,inACMSIGGRAPH2023confer- enceproceedings,2023,pp.1–9
work page 2023
-
[21]
T2m-gpt:Generatinghumanmotionfromtex- tualdescriptionswithdiscreterepresentations
J.Zhangetal.,“T2m-gpt:Generatinghumanmotionfromtex- tualdescriptionswithdiscreterepresentations”,inCVPR,2023
work page 2023
-
[22]
Seamless human motion composition with blended positional encodings
G. Barquero, S. Escalera, and C. Palmero, “Seamless human motion composition with blended positional encodings”, in CVPR,2024
work page 2024
-
[23]
Sato:Stabletext-to-motionframework
W.chenetal.,“Sato:Stabletext-to-motionframework”,inPro- ceedings of the 32nd ACM International Conference on Mul- timedia, ser. MM ’24, Melbourne VIC, Australia: Associa- tion for Computing Machinery, 2024, pp. 6989–6997,isbn: 9798400706868.doi:10.1145/3664647.3681034[Online].Avail- able:https://doi.org/10.1145/3664647.3681034
-
[24]
Harmon: Whole-bodymotiongenerationofhumanoidrobotsfromlan- guage descriptions
Z. Jiang, Y. Xie, J. Li, Y. Yuan, Y. Zhu, and Y. Zhu, “Harmon: Whole-bodymotiongenerationofhumanoidrobotsfromlan- guage descriptions”, inConference on Robot Learning, 2024. arXiv:2410.12773[cs.RO]
-
[25]
S. Bai, Y. Cai, R. Chen, K. Chen, et al., “Qwen3-vl technical report”,arXivpreprintarXiv:2511.21631,2025.[Online].Avail- able:https://arxiv.org/abs/2511.21631
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Ant: Adaptive neural temporal-aware text- to-motion model
W. Chen et al., “Ant: Adaptive neural temporal-aware text- to-motion model”, inProceedings of the 33rd ACM Interna- tionalConferenceonMultimedia,ser.MM’25,ACM,Oct.2025, pp.9852–9861.doi:10.1145/3746027.3755168[Online].Avail- able:http://dx.doi.org/10.1145/3746027.3755168
-
[27]
W. Chen et al.,Free-t2m:Robusttext-to-motiongenerationfor humanoidrobotsviafrequency-domain,2025.arXiv:2501.18232 [cs.CV].[Online].Available:https://arxiv.org/abs/2501.18232
- [28]
-
[29]
H. Jia et al.,Luma: Low-dimension unified motion alignment with dual-path anchoring for text-to-motion diffusion model,
- [30]
- [31]
-
[32]
Physics-informed representation alignment for sparse radio-map reconstruction
H. Jia et al., “Physics-informed representation alignment for sparse radio-map reconstruction”, inProceedings of the 33rd ACM International Conference on Multimedia, ser. MM ’25, Dublin,Ireland:AssociationforComputingMachinery,2025, pp.12352–12360,isbn:9798400720352.doi:10.1145/3746027. 3758161[Online].Available:https://doi.org/10.1145/3746027. 3758161
-
[33]
Jiang et al.,UniAct: Unified motion generation and ac- tion streaming for humanoid robots, 2025
N. Jiang et al.,UniAct: Unified motion generation and ac- tion streaming for humanoid robots, 2025. arXiv: 2512.24321 [cs.CV]
-
[34]
Z. Li et al.,From language to locomotion: Retargeting-free hu- manoidcontrolviamotionlatentguidance, 2025. arXiv: 2510. 14952[cs.RO]. 9–20 Before the Body Moves: Learning Anticipatory Joint Intent for Language-Conditioned Humanoid Control
work page 2025
- [35]
-
[36]
M.Ningetal.,Dctdiff:Intriguingpropertiesofimagegenerative modeling in the dct space, 2025. arXiv: 2412.15032[cs.CV]. [Online].Available:https://arxiv.org/abs/2412.15032
- [37]
-
[38]
Text2weight: Bridgingnaturallanguageandneuralnetworkweightspaces
B.Tian,W.Chen,Z.Li,S.Lai,J.Wu,andY.Yue,“Text2weight: Bridgingnaturallanguageandneuralnetworkweightspaces”, inProceedingsofthe33rdACMInternationalConferenceonMul- timedia,ser.MM’25,Dublin,Ireland:AssociationforComput- ingMachinery,2025,pp.10152–10160,isbn:9798400720352. doi:10.1145/3746027.3755441[Online].Available:https://doi. org/10.1145/3746027.3755441
- [39]
-
[40]
MotionStreamer:Streamingmotiongeneration viadiffusion-basedautoregressivemodelincausallatentspace
L.Xiaoetal.,“MotionStreamer:Streamingmotiongeneration viadiffusion-basedautoregressivemodelincausallatentspace”, inProceedings of the IEEE/CVF International Conference on ComputerVision,2025.arXiv:2503.15451[cs.CV]
-
[41]
H. Jia et al.,ECHO: Edge-cloud humanoid orchestration for language-to-motioncontrol,2026.arXiv:2603.16188[cs.CV]
-
[42]
H. Li, W. Chen, S. Liang, L. Wang, K. Yuan, and Y. Yue,𝑍2- sampling: Zero-cost zigzag trajectories for semantic alignment indiffusionmodels,2026.arXiv:2604.23536 [cs.CV].[Online]. Available:https://arxiv.org/abs/2604.23536
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[43]
H. Li, W. Chen, L. Wang, S. Liang, H. Jia, and Y. Yue,Oracle noise:Fastersemanticsphericalalignmentforinterpretablela- tent optimization, 2026. arXiv: 2604.23540[cs.CV]. [Online]. Available:https://arxiv.org/abs/2604.23540
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[44]
Delta Score Matters! Spatial Adaptive Multi Guidance in Diffusion Models
H.Lietal.,Deltascorematters!spatialadaptivemultiguidance indiffusionmodels,2026.arXiv:2604.26503 [cs.CV].[Online]. Available:https://arxiv.org/abs/2604.26503
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[45]
P.Lietal.,FRoM-W1:Towardsgeneralhumanoidwhole-body control with language instructions, 2026. arXiv: 2601.12799 [cs.RO]
-
[46]
W.Xieetal.,TextOp:Real-timeinteractivetext-drivenhumanoid robotmotiongenerationandcontrol, 2026. arXiv: 2602.07439 [cs.RO]
-
[47]
X. Yuan et al.,RoboForge: Physically optimized text-guided whole-bodylocomotionforhumanoids,2026.arXiv:2603.17927 [cs.RO]
-
[48]
Towards betterevaluationmetricsfortext-to-motiongeneration
W.Chen,H.Jia,K.Yu,S.Lai,L.Wang,andY.Yue,“Towards betterevaluationmetricsfortext-to-motiongeneration”,inThe SecondInternationalWorkshoponTransformativeInsightsin MultifacetedEvaluationatTheWebConference2026. 10–20 Before the Body Moves: Learning Anticipatory Joint Intent for Language-Conditioned Humanoid Control A. EVALUATION PROTOCOL AND EXPERIMENTAL SETU...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.