Symmetry-Compatible Principle for Optimizer Design: Embeddings, LM Heads, SwiGLU MLPs, and MoE Routers
Pith reviewed 2026-05-20 09:30 UTC · model grok-4.3
The pith
Gradient updates should be equivariant under the symmetry group of each weight block to improve training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the gradient update rule should be equivariant under the symmetry group acting on the corresponding weight block, yielding one-sided spectral, row-norm, hybrid row-norm/spectral, row-aware, column-aware, centered row-norm, and left-spectral updates for embeddings, LM heads, SwiGLU MLPs, and MoE routers that together outperform standard AdamW updates.
What carries the argument
The symmetry-compatible principle, requiring that the update rule be equivariant under the symmetry group of each weight block.
If this is right
- Symmetry-compatible updates improve final validation loss over AdamW across dense and MoE language models.
- The updates also improve training stability in several of the reported experiments.
- The constructions form a complete end-to-end layerwise optimizer stack that assigns each major matrix parameter class an update matching its symmetry group.
- The new rules include row-norm, one-sided spectral, and hybrid variants derived from permutation and shared-shift symmetries.
Where Pith is reading between the lines
- The same principle could be applied to other layer types whose symmetries have not yet been catalogued.
- Architectures might eventually be co-designed so that their parameter symmetries align more cleanly with efficient equivariant updates.
- Checking whether the loss gains persist or reverse when models are scaled by another order of magnitude would test the robustness of the reported improvements.
Load-bearing premise
That enforcing equivariance under the identified symmetry groups for these parameter blocks is sufficient to produce better optimizers without hidden costs that only appear at larger scale.
What would settle it
A controlled pre-training run on any of the tested model families in which the symmetry-compatible stack produces equal or higher validation loss than AdamW at the same compute budget would falsify the practical advantage.
Figures




read the original abstract
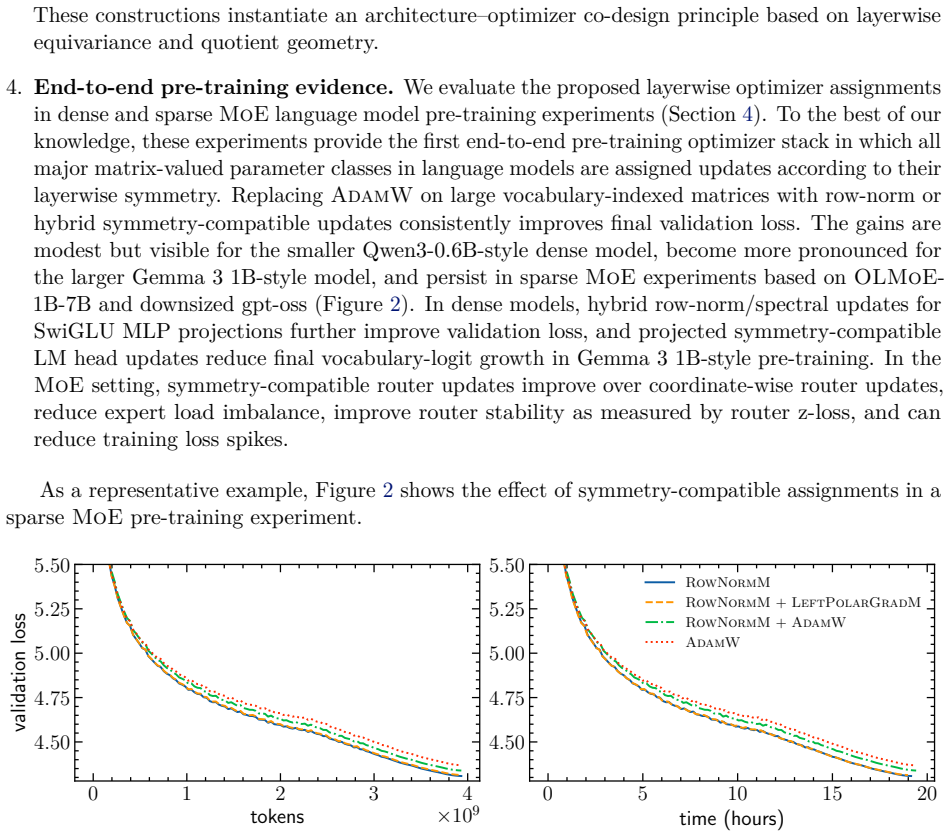
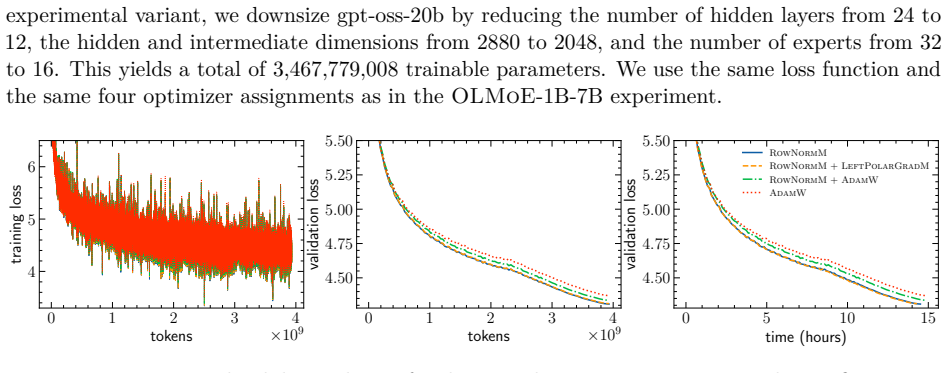
A striking geometric disparity has long persisted in the practice of deep learning. While modern neural network architectures naturally exhibit rich symmetry and equivariance properties, popular optimizers such as Adam and its variants operate inherently coordinate-wise, rendering them unable to respect the equivariance structures of the parameter space. We address this disparity by introducing a symmetry-compatible principle for optimizer design: the gradient update rule should be equivariant under the symmetry group acting on the corresponding weight block. Following this principle, we first provide a unified perspective on bi-orthogonally equivariant updates for general matrix layers, as employed by stochastic spectral descent, Muon, Scion, and polar gradient methods. More importantly, by moving from orthogonal groups to permutation and shared-shift symmetries, we derive symmetry-compatible optimizers for parameter blocks whose symmetries differ from those of general matrix layers: embedding and LM head matrices, SwiGLU MLP projections, and MoE router matrices. These constructions include one-sided spectral, row-norm, hybrid row-norm/spectral, row-aware, column-aware, centered row-norm, and left-spectral updates. They yield an end-to-end layerwise optimizer stack in which each major matrix-valued parameter class is assigned an update whose equivariance matches its symmetry group. We corroborate this principle through pre-training experiments on dense and sparse MoE language models, including Qwen3-0.6B-style, Gemma 3 1B-style, OLMoE-1B-7B-style, and downsized gpt-oss architectures. Across these experiments, symmetry-compatible updates consistently improve final validation loss, and in several cases training stability, over corresponding AdamW updates.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a symmetry-compatible principle for optimizer design: gradient updates must be equivariant under the symmetry group acting on each weight block. It unifies bi-orthogonally equivariant methods for matrix layers and derives new updates (row-norm, one-sided spectral, hybrid row-norm/spectral, centered row-norm, left-spectral, row-aware, column-aware) for blocks with permutation symmetries (embeddings, LM heads) and shared-shift symmetries (MoE routers, SwiGLU projections). These are assembled into a layerwise optimizer stack and tested via pre-training runs on Qwen3-0.6B-style, Gemma-3-1B-style, OLMoE-1B-7B-style, and downsized gpt-oss models, where the symmetry-compatible updates are reported to yield lower final validation loss and occasional stability gains relative to AdamW.
Significance. If the performance gains are shown to arise specifically from the enforced equivariance (rather than incidental rescaling), the principle supplies a systematic route to architecture-aware optimizers that respect the permutation and shift structures already present in modern LLM components. The multi-architecture experimental sweep and the unified treatment of bi-orthogonal updates constitute concrete strengths that would remain valuable even if the central empirical claim requires additional controls.
major comments (2)
- [Experimental section] Experimental section: the manuscript reports consistent validation-loss improvements for the symmetry-compatible updates (row-norm, one-sided spectral, hybrid, centered row-norm, left-spectral) over AdamW across Qwen3-0.6B, Gemma-3-1B, OLMoE and gpt-oss runs, yet provides no per-method learning-rate sweeps or explicit matching of mean update norms / effective step lengths. Because the proposed rules embed explicit row/column normalizations and spectral projections absent from coordinate-wise AdamW, the observed gains could be produced by an implicit change in gradient magnitude rather than by permutation or shared-shift equivariance. This control is load-bearing for the central claim.
- [§3 (Derivations of symmetry-compatible updates)] §3 (Derivations of symmetry-compatible updates): the principle is introduced as an independent design axiom whose justification rests on external validation by the loss curves. It would strengthen the manuscript to demonstrate, even for a single block, that the derived equivariant update cannot be recovered from AdamW by a simple global rescaling or reparameterization of the learning rate.
minor comments (2)
- [Abstract] Abstract and experimental summary: the claim of 'consistent loss improvements' and 'several cases' of improved stability would be more informative if accompanied by quantitative effect sizes, number of independent runs, and standard deviations.
- [Notation and definitions] Notation: the precise definitions of 'one-sided spectral', 'hybrid row-norm/spectral', and 'left-spectral' updates should be stated with explicit matrix formulas in the main text rather than left to supplementary material.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We agree that isolating the role of equivariance from possible rescaling effects is essential for the central claim, and we outline revisions below to address both major comments.
read point-by-point responses
-
Referee: [Experimental section] Experimental section: the manuscript reports consistent validation-loss improvements for the symmetry-compatible updates (row-norm, one-sided spectral, hybrid, centered row-norm, left-spectral) over AdamW across Qwen3-0.6B, Gemma-3-1B, OLMoE and gpt-oss runs, yet provides no per-method learning-rate sweeps or explicit matching of mean update norms / effective step lengths. Because the proposed rules embed explicit row/column normalizations and spectral projections absent from coordinate-wise AdamW, the observed gains could be produced by an implicit change in gradient magnitude rather than by permutation or shared-shift equivariance. This control is load-bearing for the central claim.
Authors: We acknowledge that the current experiments lack per-method learning-rate sweeps and explicit matching of mean update norms. The symmetry-compatible rules do introduce row/column normalizations and spectral projections that alter effective magnitudes in a structured manner, so the referee's concern is valid. In the revised manuscript we will add experiments that tune learning rates separately for each method and explicitly match mean update norms (or effective step lengths) to AdamW baselines. This will allow direct comparison under comparable gradient magnitudes and thereby strengthen evidence that gains arise from permutation and shared-shift equivariance. revision: yes
-
Referee: [§3 (Derivations of symmetry-compatible updates)] §3 (Derivations of symmetry-compatible updates): the principle is introduced as an independent design axiom whose justification rests on external validation by the loss curves. It would strengthen the manuscript to demonstrate, even for a single block, that the derived equivariant update cannot be recovered from AdamW by a simple global rescaling or reparameterization of the learning rate.
Authors: We agree that an explicit demonstration would reinforce the independence of the derived updates. For the embedding-matrix case we will add a short algebraic comparison in §3 (or an appendix) showing that the row-norm update scales each row by the inverse of its own gradient norm. This per-row, data-dependent scaling cannot be reproduced by any fixed global multiplier applied to an AdamW update, because the latter remains strictly coordinate-wise and lacks the row-wise aggregation required by permutation equivariance. A brief numerical counter-example on a small matrix will be included to illustrate that no single rescaling factor equates the two rules. revision: yes
Circularity Check
Symmetry principle stated as independent axiom; derivation self-contained with external validation
full rationale
The paper introduces the symmetry-compatible principle as a design axiom (gradient update equivariant under the symmetry group of each weight block) and derives specific update rules for embeddings, LM heads, SwiGLU MLPs, and MoE routers from that axiom plus standard equivariance requirements. No step reduces a claimed prediction or result to a fitted parameter or self-citation by construction. Experiments on Qwen3, Gemma, OLMoE, and gpt-oss models serve as independent validation rather than the source of the updates. The central claim remains independent of the reported loss curves.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The gradient update rule should be equivariant under the symmetry group acting on the corresponding weight block.
Reference graph
Works this paper leans on
-
[1]
E. Abbe and E. Boix-Adsera. On the non-universality of deep learning: quantifying the cost of symmetry. InAdvances in Neural Information Processing Systems (NeurIPS). 2022
work page 2022
- [2]
- [3]
-
[4]
J. Ainslie, J. Lee-Thorp, M. De Jong, Y. Zemlyanskiy, F. Lebrón, and S. Sanghai. GQA: Training gen- eralized multi-query transformer models from multi-head checkpoints. InProceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP). 2023
work page 2023
- [5]
-
[6]
K. An, Y. Liu, R. Pan, S. Ma, D. Goldfarb, and T. Zhang. ASGO: Adaptive structured gradient optimization. InAdvances in Neural Information Processing Systems (NeurIPS). 2025
work page 2025
- [7]
-
[8]
Q. Anthony, Y. Tokpanov, S. Szot, S. Rajagopal, P. Medepalli, R. Iyer, V. Shyam, A. Golubeva, A. Chaurasia, et al. Training foundation models on a full-stack AMD platform: Compute, networking, and system design.arXiv preprint arXiv:2511.17127, 2025
-
[9]
L. Autonne. Sur les groupes linéaires, réels et orthogonaux.Bulletin de la Société Mathématique de France, 30:121–134, 1902
work page 1902
- [10]
- [11]
- [12]
-
[13]
J. Bernstein and L. Newhouse. Old optimizer, new norm: An anthology. InOPT 2024: Optimization for Machine Learning. 2024
work page 2024
-
[14]
J. Bernstein and L. Newhouse. Modular duality in deep learning. InProceedings of the International Conference on Machine Learning (ICML). 2025
work page 2025
-
[15]
J. Bernstein, Y.-X. Wang, K. Azizzadenesheli, and A. Anandkumar. signSGD: Compressed optimisation for non-convex problems. InProceedings of the International Conference on Machine Learning (ICML). 2018
work page 2018
-
[16]
Bhatia.Matrix Analysis, volume 169
R. Bhatia.Matrix Analysis, volume 169. Springer Science & Business Media, 2013
work page 2013
-
[17]
T. Boissin, T. Massena, F. Mamalet, and M. Serrurier. Turbo-Muon: Accelerating orthogonality-based optimization with pre-conditioning.arXiv preprint arXiv:2512.04632, 2025
-
[18]
F. Bordes, R. Y. Pang, A. Ajay, A. C. Li, A. Bardes, S. Petryk, O. Mañas, Z. Lin, A. Mahmoud, et al. An introduction to vision-language modeling.arXiv preprint arXiv:2405.17247, 2024. 30
-
[19]
T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, et al. Language models are few-shot learners. InAdvances in Neural Information Processing Systems (NeurIPS). 2020
work page 2020
- [20]
-
[21]
D. Carlson, V. Cevher, and L. Carin. Stochastic spectral descent for restricted Boltzmann machines. In Proceedings of the International Conference on Artificial Intelligence and Statistics (AISTATS). 2015
work page 2015
-
[22]
D. Carlson, E. Collins, Y.-P. Hsieh, L. Carin, and V. Cevher. Preconditioned spectral descent for deep learning. InAdvances in Neural Information Processing Systems (NeurIPS). 2015
work page 2015
-
[23]
D. Carlson, Y.-P. Hsieh, E. Collins, L. Carin, and V. Cevher. Stochastic spectral descent for discrete graphical models.IEEE Journal of Selected Topics in Signal Processing, 10(2):296–311, 2016
work page 2016
-
[24]
On the Convergence of Muon and Beyond
D. Chang, Y. Liu, and G. Yuan. On the convergence of Muon and beyond.arXiv preprint arXiv:2509.15816, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
MuonEq: Balancing Before Orthogonalization with Lightweight Equilibration
D. Chang, Q. Shi, L. Zhang, Y. Li, R. Zhang, Y. Lu, Y. Liu, and G. Yuan. MuonEq: Balancing before orthogonalization with lightweight equilibration.arXiv preprint arXiv:2603.28254, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [26]
-
[27]
Y. Chen, Y. Chi, J. Fan, and C. Ma. Spectral methods for data science: A statistical perspective. Foundations and Trends®in Machine Learning, 14(5):566–806, 2021
work page 2021
-
[28]
M. Crawshaw, C. Modi, M. Liu, and R. M. Gower. An exploration of non-Euclidean gradient descent: Muon and its many variants.arXiv preprint arXiv:2510.09827, 2025
- [29]
- [30]
-
[31]
Y. N. Dauphin, A. Fan, M. Auli, and D. Grangier. Language modeling with gated convolutional networks. InProceedings of the International Conference on Machine Learning (ICML). 2017
work page 2017
-
[32]
D. Davis and D. Drusvyatskiy. When do spectral gradient updates help in deep learning?arXiv preprint arXiv:2512.04299, 2025
-
[33]
DeepSeek-V4: Towards highly efficient million-token context intelligence
DeepSeek-AI. DeepSeek-V4: Towards highly efficient million-token context intelligence. 2026
work page 2026
-
[34]
DeepSeek-AI, A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. Deng, et al. DeepSeek-V3 technical report.arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
M. Dehghani, J. Djolonga, B. Mustafa, P. Padlewski, J. Heek, J. Gilmer, A. Steiner, M. Caron, R. Geirhos, et al. Scaling vision transformers to 22 billion parameters. InProceedings of the International Conference on Machine Learning (ICML). 2023
work page 2023
-
[36]
S. Deng, Z. Ouyang, T. Pang, Z. Liu, R. Jin, S. Yu, and Y. Yang. RMNP: Row-momentum normalized preconditioning for scalable matrix-based optimization.arXiv preprint arXiv:2603.20527, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [37]
-
[38]
C. Ding, D. Sun, J. Sun, and K.-C. Toh. Spectral operators of matrices.Mathematical Programming, 168(1):509–531, 2018
work page 2018
-
[39]
C. Ding, D. Sun, J. Sun, and K.-C. Toh. Spectral operators of matrices: Semismoothness and characterizations of the generalized Jacobian.SIAM Journal on Optimization, 30(1):630–659, 2020
work page 2020
-
[40]
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, et al. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representations (ICLR). 2021
work page 2021
-
[41]
Z. Du, H. He, and W. Su. Uncovering symmetry transfer in large language models via layer-peeled optimization.arXiv preprint arXiv:2605.12756, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [42]
- [43]
-
[44]
R. Eschenhagen, A. Cai, T.-H. Lee, and H.-J. M. Shi. Clarifying Shampoo: Adapting spectral descent to stochasticity and the parameter trajectory.arXiv preprint arXiv:2602.09314, 2026
-
[45]
R. Eschenhagen, A. Immer, R. Turner, F. Schneider, and P. Hennig. Kronecker-factored approximate curvature for modern neural network architectures. InAdvances in Neural Information Processing Systems (NeurIPS). 2023
work page 2023
-
[46]
Layer sharding for large-scale training with Muon.https://www.essential.ai/research/ infra, 2025
Essential AI. Layer sharding for large-scale training with Muon.https://www.essential.ai/research/ infra, 2025
work page 2025
- [47]
-
[48]
O. Filatov, J. Wang, J. Ebert, and S. Kesselheim. Optimal scaling needs optimal norm.arXiv preprint arXiv:2510.03871, 2025
- [49]
-
[50]
Gemma Team, A. Kamath, J. Ferret, S. Pathak, N. Vieillard, R. Merhej, S. Perrin, T. Matejovicova, A. Ramé, et al. Gemma 3 technical report.arXiv preprint arXiv:2503.19786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
A. Glentis, J. Li, A. Han, and M. Hong. A minimalist optimizer design for LLM pretraining.arXiv preprint arXiv:2506.16659, 2025
work page internal anchor Pith review arXiv 2025
-
[52]
GLM-4.5 Team, A. Zeng, X. Lv, Q. Zheng, Z. Hou, B. Chen, C. Xie, C. Wang, D. Yin, et al. GLM-4.5: Agentic, reasoning, and coding (ARC) foundation models.arXiv preprint arXiv:2508.06471, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
GLM-5 Team, A. Zeng, X. Lv, Z. Hou, Z. Du, Q. Zheng, B. Chen, D. Yin, C. Ge, et al. GLM-5: from vibe coding to agentic engineering.arXiv preprint arXiv:2602.15763, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[54]
D. Goldfarb, Y. Ren, and A. Bahamou. Practical quasi-Newton methods for training deep neural networks. InAdvances in Neural Information Processing Systems (NeurIPS). 2020
work page 2020
-
[55]
S. Gong, S. Agarwal, Y. Zhang, J. Ye, L. Zheng, M. Li, C. An, P. Zhao, W. Bi, et al. Scaling diffusion language models via adaptation from autoregressive models. InInternational Conference on Learning Representations (ICLR). 2025
work page 2025
- [56]
-
[57]
A. Gonon, A.-A. Muşat, and N. Boumal. Insights on Muon from simple quadratics.arXiv preprint arXiv:2602.11948, 2026
- [58]
-
[59]
E. Grishina, M. Smirnov, and M. Rakhuba. Accelerating Newton-Schulz iteration for orthogonalization via Chebyshev-type polynomials.arXiv preprint arXiv:2506.10935, 2025
- [60]
- [61]
- [62]
-
[63]
K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2016
work page 2016
-
[64]
N. J. Higham. Computing the polar decomposition—with applications.SIAM Journal on Scientific and Statistical Computing, 7(4):1160–1174, 1986
work page 1986
-
[65]
N. J. Higham. Stable iterations for the matrix square root.Numerical Algorithms, 15(2):227–242, 1997
work page 1997
-
[66]
N. J. Higham.Functions of Matrices: Theory and Computation. Society for Industrial and Applied Mathematics, 2008
work page 2008
-
[67]
J. Hoffmann, S. Borgeaud, A. Mensch, E. Buchatskaya, T. Cai, E. Rutherford, D. de las Casas, L. A. Hendricks, J. Welbl, et al. Training compute-optimal large language models. InAdvances in Neural Information Processing Systems (NeurIPS). 2022
work page 2022
-
[68]
R. A. Horn and C. R. Johnson.Topics in Matrix Analysis. Cambridge University Press, 1994
work page 1994
-
[69]
R. A. Horn and C. R. Johnson.Matrix Analysis. Cambridge University Press, 2nd edition, 2012
work page 2012
-
[70]
Y. Hu, H. Song, J. Deng, J. Wang, J. Chen, K. Zhou, Y. Zhu, J. Jiang, Z. Dong, et al. YuLan-Mini: Pushing the limits of open data-efficient language model. InProceedings of the Annual Meeting of the Association for Computational Linguistics (ACL) (Volume 1: Long Papers). 2025
work page 2025
- [71]
-
[72]
A. Q. Jiang, A. Sablayrolles, A. Roux, A. Mensch, B. Savary, C. Bamford, D. S. Chaplot, D. de las Casas, E. B. Hanna, et al. Mixtral of experts.arXiv preprint arXiv:2401.04088, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [73]
- [74]
- [75]
- [76]
-
[77]
Scaling Laws for Neural Language Models
J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, et al. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[78]
P. Kasimbeg, F. Schneider, R. Eschenhagen, J. Bae, C. S. Sastry, M. Saroufim, B. Feng, L. Wright, E. Z. Yang, et al. Accelerating neural network training: An analysis of the AlgoPerf competition. In International Conference on Learning Representations (ICLR). 2025
work page 2025
-
[79]
G. Y. Kim and M.-h. Oh. Convergence of Muon with Newton-Schulz. InInternational Conference on Learning Representations (ICLR). 2026
work page 2026
-
[80]
Kimi K2: Open Agentic Intelligence
Kimi Team. Kimi K2: Open agentic intelligence.arXiv preprint arXiv:2507.20534, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.