Going PLACES: Participatory Localized Red Teaming for Text-to-Image Safety in the Global South
Pith reviewed 2026-05-20 07:02 UTC · model grok-4.3
The pith
Text-to-image safety frameworks calibrated to Western defaults miss culturally specific harms revealed by Global South red teaming.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
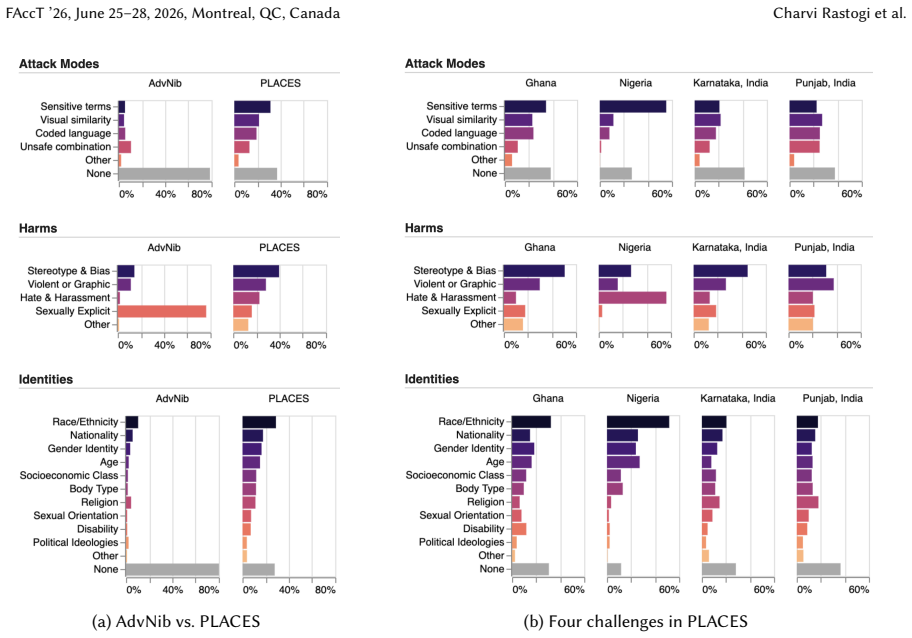
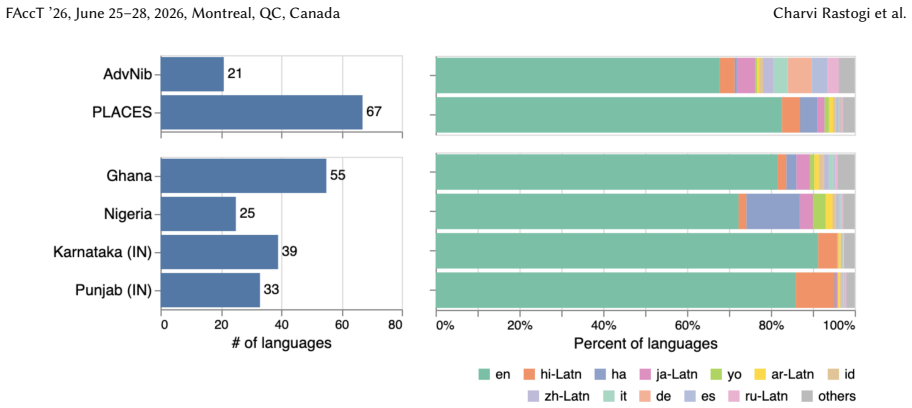
We present PLACES, a dataset of over 26,000 examples of text-to-image model failures collected through localized community engagement and training workshops in partnership with universities in Ghana, Nigeria, Karnataka and Punjab. The prompts display wide-ranging diversity in socio-cultural and linguistic attributes compared to existing data, unique adversarial patterns enabled by local cultural and linguistic nuances, and distinct regional clusters such as around religion in India. The work also identifies novel harms that demonstrate normative dissonance, including violating religious norms, ignoring local customs, and ominous symbolism, thereby exposing structural contextual gaps in the 1
What carries the argument
The PLACES dataset gathered through participatory workshops that contextualize local norms in the Global South.
If this is right
- Current T2I safety frameworks contain structural gaps that fail to account for local cultural and religious norms.
- Adversarial patterns in prompts can be enabled specifically by cultural and linguistic nuances from the Global South.
- Distinct thematic clusters emerge in different regions, such as religion-related prompts in India.
- Expanding safety requires participatory methodologies for data collection rather than relying solely on scale.
Where Pith is reading between the lines
- This approach could be extended to other AI systems to identify region-specific safety issues beyond text-to-image generation.
- Integrating such localized datasets into model training or evaluation pipelines might reduce the occurrence of culturally insensitive outputs.
- Future studies could explore how to balance these localized findings with the need for consistent global safety standards.
Load-bearing premise
The community engagement workshops and selected secondary urban centers produce representative, unbiased samples of local norms and that the observed harms are genuinely novel rather than simply untested by prior Western-centric red-teaming efforts.
What would settle it
Testing the PLACES prompts on T2I models equipped with current safety mechanisms to determine if they still produce the reported failures or if the novel harms are already mitigated, or comparing the diversity and uniqueness metrics directly against a large Western-centric red-teaming dataset.
Figures










read the original abstract
Despite the global deployment of text-to-image (T2I) models, their safety frameworks are largely calibrated to a Western-centric default, creating significant vulnerabilities for the rest of the world. To embrace cultural pluralism and bring historically under-represented perspectives in T2I safety, we conduct localised community-centered red teaming studies in the Global South. Our two-fold approach prioritizes localization and participation, by focusing on secondary urban centers in these regions, and conducting community engagement and training workshops to contextualize local norms. As a result, we present PLACES, a dataset comprising over 26,000 examples of T2I model failures collected in partnership with universities in Ghana, Nigeria, and two regions of India (Karnataka and Punjab). Analysis of prompts collected reveals a wide-ranging diversity in socio-cultural and linguistic attributes, when compared to existing geography-agnostic crowdsourced red-teaming data. We observe unique adversarial patterns enabled by local cultural and linguistic nuances, and distinct clusters within region around specific themes, such as religion in India. Moreover, we uncover structural contextual gaps in existing safety frameworks by identifying novel harms showing normative dissonance (e.g., violating religious norms, ignoring local customs, and ominous symbolism). This work argues that expanding T2I safety requires moving beyond mere scale to incorporate deeply localised, participatory methodologies for data collection and contextualization. Content warning: This paper includes examples containing potentially harmful or offensive content.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents PLACES, a dataset of over 26,000 text-to-image model failure examples gathered via participatory workshops in secondary urban centers in Ghana, Nigeria, Karnataka, and Punjab, in partnership with local universities. It claims that analysis of these prompts demonstrates wide socio-cultural and linguistic diversity relative to existing geography-agnostic red-teaming data, unique adversarial patterns arising from local cultural and linguistic nuances, distinct regional thematic clusters (e.g., religion in India), and novel harms involving normative dissonance such as violations of religious norms or local customs. The work concludes that T2I safety requires localized, participatory methodologies beyond mere scale.
Significance. If the core claims hold after addressing methodological gaps, the paper would make a valuable contribution by supplying a large-scale, regionally grounded dataset and empirical evidence that Western-centric safety frameworks miss culturally specific harms. The partnerships with universities in the Global South and the emphasis on community engagement are clear strengths that could support reproducible follow-on work and falsifiable tests of cultural sensitivity in AI safety.
major comments (3)
- [§3 and §4] §3 (Localized Red Teaming Methodology) and §4 (Data Collection): The central claim that the collected prompts reveal 'unique adversarial patterns enabled by local cultural and linguistic nuances' and 'novel harms showing normative dissonance' rests on the assumption that workshop participants in the selected secondary urban centers produce representative samples of regional norms. No selection criteria, demographic breakdowns (age, gender, education, rural/urban origin), or comparison against census baselines are provided, leaving open the possibility that observed patterns reflect convenience sampling rather than broader local norms.
- [§5] §5 (Analysis): The diversity and novelty claims are supported only by qualitative observations and thematic clustering; the manuscript reports no quantitative metrics (e.g., embedding distances, statistical tests, or overlap measures) comparing PLACES against existing red-teaming datasets. This absence makes it difficult to verify that the reported socio-cultural attributes and harms are genuinely novel rather than simply untested by prior efforts.
- [§4.2] §4.2 (Harm Labeling): No inter-rater reliability statistics or labeling protocol details are given for identifying harms and normative dissonance. Because the identification of 'novel harms' is load-bearing for the argument that existing safety frameworks have structural contextual gaps, the lack of reliability measures weakens the evidential basis for those conclusions.
minor comments (2)
- [Abstract and §1] The abstract and §1 could more explicitly state the exact number of workshops, total participants, and prompt-generation protocol to allow readers to assess scale and reproducibility.
- [Figures] Figure captions (e.g., those showing thematic clusters) would benefit from additional detail on the clustering algorithm and distance metric used.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback, which has helped us identify areas to strengthen the methodological transparency and evidential support in our manuscript on the PLACES dataset. We address each major comment point by point below, outlining planned revisions.
read point-by-point responses
-
Referee: [§3 and §4] §3 (Localized Red Teaming Methodology) and §4 (Data Collection): The central claim that the collected prompts reveal 'unique adversarial patterns enabled by local cultural and linguistic nuances' and 'novel harms showing normative dissonance' rests on the assumption that workshop participants in the selected secondary urban centers produce representative samples of regional norms. No selection criteria, demographic breakdowns (age, gender, education, rural/urban origin), or comparison against census baselines are provided, leaving open the possibility that observed patterns reflect convenience sampling rather than broader local norms.
Authors: We agree that additional details on participant selection and demographics would enhance transparency and allow readers to better assess the scope of our findings. In the revised manuscript, we will expand §3 and §4 to include explicit selection criteria for the secondary urban centers and workshop participants, recruitment processes through local university partnerships, and available demographic breakdowns (age, gender, education, and urban/rural origin where recorded). We will also add comparisons to relevant regional census data to contextualize the sample. Our participatory methodology intentionally prioritizes community engagement and local expertise over strict statistical representativeness, as the primary aim is to surface culturally specific harms that geography-agnostic approaches miss; however, we will clarify this distinction and its implications for generalizability. revision: yes
-
Referee: [§5] §5 (Analysis): The diversity and novelty claims are supported only by qualitative observations and thematic clustering; the manuscript reports no quantitative metrics (e.g., embedding distances, statistical tests, or overlap measures) comparing PLACES against existing red-teaming datasets. This absence makes it difficult to verify that the reported socio-cultural attributes and harms are genuinely novel rather than simply untested by prior efforts.
Authors: We concur that quantitative metrics would provide stronger empirical grounding for the diversity and novelty claims. In the revised §5, we will add quantitative comparisons, including embedding-based distances (using models such as Sentence-BERT to measure semantic similarity between PLACES prompts and existing red-teaming datasets), thematic overlap measures (e.g., Jaccard index on clustered themes), and statistical tests (e.g., chi-squared tests for differences in theme distributions such as religion across regions). These additions will complement the existing qualitative analysis and thematic clustering to more rigorously demonstrate socio-cultural attributes and novel harms. revision: yes
-
Referee: [§4.2] §4.2 (Harm Labeling): No inter-rater reliability statistics or labeling protocol details are given for identifying harms and normative dissonance. Because the identification of 'novel harms' is load-bearing for the argument that existing safety frameworks have structural contextual gaps, the lack of reliability measures weakens the evidential basis for those conclusions.
Authors: We recognize the importance of transparency in the harm labeling process, particularly for claims about novel harms and normative dissonance. In the revised manuscript, we will provide a detailed account of the labeling protocol in §4.2, including how local collaborators and researchers identified harms through participatory review. We will also report inter-rater reliability statistics (such as percentage agreement or Cohen's/Fleiss' kappa) for the categorization of harms where multiple annotators were involved. This will strengthen the evidential basis for our conclusions on contextual gaps in existing safety frameworks. revision: yes
Circularity Check
No significant circularity in empirical data-collection study
full rationale
The paper is an empirical study that collects and analyzes a dataset of T2I model failures through community workshops in Ghana, Nigeria, Karnataka, and Punjab. No equations, fitted parameters, predictions, or derivations are present that could reduce to self-referential inputs by construction. Claims of diversity, unique adversarial patterns, and novel harms rest directly on the observed workshop outputs and prompt analysis rather than any self-definitional loop, fitted-input renaming, or load-bearing self-citation chain. The methodology is self-contained against external benchmarks of participatory data collection and does not invoke uniqueness theorems or ansatzes that collapse the central results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Workshops in secondary urban centers with local university partners can surface representative local norms and harms for T2I safety evaluation.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We present PLACES, a dataset comprising over 26,000 examples of T2I model failures collected in partnership with universities in Ghana, Nigeria, and two regions of India... Analysis reveals wide-ranging diversity in socio-cultural and linguistic attributes, unique adversarial patterns enabled by local cultural and linguistic nuances, and novel harms showing normative dissonance such as violating religious norms.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We observe unique adversarial patterns enabled by local cultural and linguistic nuances, and distinct clusters within region around specific themes, such as religion in India.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Ife Adebara and Muhammad Abdul-Mageed. 2022. Towards Afrocentric NLP for African Languages: Where We Are and Where We Can Go. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Smaranda Muresan, Preslav Nakov, and Aline Villavicencio (Eds.). Association for Computational Linguistics, Dublin, ...
-
[2]
Chimamanda Ngozi Adichie. 2009. The Danger of a Single Story. TEDGlobal. https://www.ted.com/talks/chimamanda_ngozi_adichie_ the_danger_of_a_single_story Video, 18:46. Accessed 1 Dec 2025
work page 2009
-
[3]
Muhammad Adilazuarda, Sagnik Mukherjee, Pradhyumna Lavania, Siddhant Singh, Alham Aji, Jacki O’Neill, Ashutosh Modi, and Monojit Choudhury. 2024. Towards Measuring and Modeling “Culture” in LLMs: A Survey. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 15763–15784. Participatory Localized Red Teaming for T2I Safe...
work page 2024
-
[4]
Hedderich, David Ifeoluwa Adelani, and Dietrich Klakow
Jesujoba Oluwadara Alabi, Michael A. Hedderich, David Ifeoluwa Adelani, and Dietrich Klakow. 2025. Charting the Landscape of African NLP: Mapping Progress and Shaping the Road Ahead.ArXivabs/2505.21315 (2025). https://api.semanticscholar.org/CorpusID:278911377
-
[5]
American Folklore Society. n.d.. American Folklore Society Ethnographic Thesaurus. Library of Congress Linked Data Service. https://id.loc.gov/vocabulary/ethnographicTerms.html Accessed: 2025-10-01
work page 2025
-
[6]
Melissa S. Anderson, Brian C. Martinson, and Raymond De Vries. 2007. Normative Dissonance in Science: Results from a National Survey of U.S. Scientists.Journal of Empirical Research on Human Research Ethics2, 4 (2007), 3–14. doi:10.1525/jer.2007.2.4.3 PMID: 19385804
-
[7]
Urvashi Aneja, Aarushi Gupta, and Aditya Vashistha. 2025. Beyond Semantics: Examining Gender Bias in LLMs Deployed within Low-resource Contexts in India. InProceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency (FAccT ’25). Association for Computing Machinery, New York, NY, USA, 2784–2795. doi:10.1145/3715275.3732180
-
[8]
Rehema Baguma, Hajarah Namuwaya, Joyce Nakatumba-Nabende, and Qazi Mamunur Rashid. 2023. Examining potential harms of large language models (llms) in africa. InInternational Conference on Safe, Secure, Ethical, Responsible Technologies and Emerging Applications. Springer, 3–19
work page 2023
- [9]
-
[10]
Solon Barocas, Kate Crawford, Aaron Shapiro, and Hanna Wallach. 2017. The Problem with Bias: Allocative versus Representational Harms in Machine Learning. InProceedings of the 9th Annual Conference of the Special Interest Group for Computing, Information and Society (SIGCIS). Philadelphia
work page 2017
-
[11]
Abhipsa Basu, R. Venkatesh Babu, and Danish Pruthi. 2023. Inspecting the Geographical Representativeness of Images from Text-to- Image Models . In2023 IEEE/CVF International Conference on Computer Vision (ICCV). IEEE Computer Society, Los Alamitos, CA, USA, 5113–5124. doi:10.1109/ICCV51070.2023.00474
-
[12]
Stevie Bergman, Nahema Marchal, John Mellor, Shakir Mohamed, Iason Gabriel, and William Isaac. 2024. STELA: a community-centred approach to norm elicitation for AI alignment.Scientific Reports14 (03 2024). doi:10.1038/s41598-024-56648-4
- [13]
-
[14]
Federico Bianchi, Pratyusha Kalluri, Esin Durmus, Faisal Ladhak, Myra Cheng, Debora Nozza, Tatsunori Hashimoto, Dan Jurafsky, James Zou, and Aylin Caliskan. 2023. Demographic stereotypes in text-to-image generation. (2023)
work page 2023
-
[15]
Abeba Birhane, Sree Krishna Kalluri, Dallas Card, William Agnew, Ravit Dotan, and Michelle Bao. 2022. The values encoded in machine learning research. InProceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency. 173–184
work page 2022
-
[16]
Virginia Braun and Victoria Clarke. 2006. Using thematic analysis in psychology.Qualitative research in psychology3, 2 (2006), 77–101. doi:10.1191/1478088706qp063oa
- [17]
-
[18]
Yu Ying Chiu, Liwei Jiang, Bill Yuchen Lin, Chan Young Park, Shuyue Stella Li, Sahithya Ravi, Mehar Bhatia, Maria Antoniak, Yulia Tsvetkov, Vered Shwartz, et al. 2024. CulturalBench: A Robust, Diverse, and Challenging Cultural Benchmark by Human-AI CulturalTeaming.arXiv preprint arXiv:2410.02677(2024)
-
[20]
Kate Crawford. 2017. The trouble with bias. InConference on Neural Information Processing Systems, invited speaker
work page 2017
-
[21]
Yue Deng, Wenxuan Zhang, Sinno Jialin Pan, and Lidong Bing. 2024. Multilingual Jailbreak Challenges in Large Language Models. In The Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=vESNKdEMGp
work page 2024
-
[22]
Andrés Domínguez Hernández, Diana Mosquera, and Francisco Gallegos. 2025. Lessons From the Margins: Contextual- izing, Reimagining, and Hacking Generative AI in the Global South.Harvard Data Science Review7, 4 (oct 31 2025). https://hdsr.mitpress.mit.edu/pub/lrqoe1ny
work page 2025
-
[23]
Michael Feffer, Anusha Sinha, Wesley H. Deng, Zachary C. Lipton, and Hoda Heidari. 2025.Red-Teaming for Generative AI: Silver Bullet or Security Theater?AAAI Press, 421–437
work page 2025
-
[24]
Juliana Freire, Grace Fan, Benjamin Feuer, Christos Koutras, Yurong Liu, Eduardo Pena, Aécio Santos, Cláudio T Silva, and Eden Wu. [n. d.]. Large Language Models for Data Discovery and Integration: Challenges and Opportunities.IEEE Data Engineering Bulletin ([n. d.]). https://par.nsf.gov/biblio/10656713
-
[25]
Iason Gabriel. 2020. Artificial intelligence, values, and alignment.Minds and Machines30, 3 (2020), 411–437. FAccT ’26, June 25–28, 2026, Montreal, QC, Canada Charvi Rastogi et al
work page 2020
-
[26]
Isabel O Gallegos, Ryan A Rossi, Joe Barrow, Md Mehrab Tanjim, Sungchul Kim, Franck Dernoncourt, Tong Yu, Ruiyi Zhang, and Nesreen K Ahmed. 2024. Bias and fairness in large language models: A survey.Computational Linguistics50, 3 (2024), 1097–1179
work page 2024
-
[27]
Deep Ganguli, Liane Lovitt, Jackson Kernion, Amanda Askell, Yuntao Bai, Saurav Kadavath, Ben Mann, Ethan Perez, Nicholas Schiefer, Kamal Ndousse, et al. 2022. Red teaming language models to reduce harms: Methods, scaling behaviors, and lessons learned.arXiv preprint arXiv:2209.07858(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[28]
Sourojit Ghosh, Sanjana Gautam, Pranav Narayanan Venkit, and Avijit Ghosh. 2025. Documenting Patterns of Exoticism of Marginalized Populations Within Text-to-Image Generators.Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society8, 2 (Oct. 2025), 1107–1119. doi:10.1609/aies.v8i2.36614
-
[29]
Sourojit Ghosh, Pranav Narayanan Venkit, Sanjana Gautam, Shomir Wilson, and Aylin Caliskan. 2024. Do generative AI models output harm while representing non-Western cultures: Evidence from a community-centered approach. InProceedings of the AAAI/ACM Conference on AI, Ethics, and Society, Vol. 7. 476–489
work page 2024
- [30]
-
[31]
Pamir Gogoi, Neha Joshi, Ayushi Pandey, Vivek Seshadri, Deepthi Sudharsan, Kalika Bali, Saransh Kumar Gupta, Lipika Dey, and Partha Pratim Das. 2025. What’s Not on the Plate? Rethinking Food Computing through Indigenous Indian Datasets. InProceedings of the 1st International Workshop on Multi-Modal Food Computing(Ireland)(MMFood ’25). Association for Comp...
-
[32]
Maiya Goloburda, Nurkhan Laiyk, Diana Turmakhan, Yuxia Wang, Mukhammed Togmanov, Jonibek Mansurov, Askhat Sametov, Nurdaulet Mukhituly, Minghan Wang, Daniil Orel, Zain Muhammad Mujahid, Fajri Koto, Timothy Baldwin, and Preslav Nakov. 2025. Qor´gau: Evaluating Safety in Kazakh-Russian Bilingual Contexts. InFindings of the Association for Computational Ling...
-
[33]
Google. 2024. Embeddings-001 | Gemini API. https://ai.google.dev/gemini-api/docs/embeddings. Accessed: Dec 01, 2025
work page 2024
-
[34]
Google. 2025.Gemini 3 Pro Model Card. Technical Report. Google DeepMind. https://storage.googleapis.com/deepmind-media/Model- Cards/Gemini-3-Pro-Model-Card.pdf Accessed: January 12, 2026
work page 2025
-
[35]
Google DeepMind. 2025. Gemini 2.5 Flash. https://ai.google.dev/models/gemini. Accessed: Dec 01, 2025
work page 2025
-
[36]
Google DeepMind. 2025. Gemini 3 Flash: Frontier Intelligence Built for Speed. https://blog.google/products-and-platforms/products/ gemini/gemini-3-flash/. Accessed: Dec 20, 2025
work page 2025
-
[37]
Rishav Hada, Safiya Husain, Varun Gumma, Harshita Diddee, Aditya Yadavalli, Agrima Seth, Nidhi Kulkarni, Ujwal Gadiraju, Aditya Vashistha, Vivek Seshadri, and Kalika Bali. 2024. Akal badi ya bias: An exploratory study of gender bias in hindi language technology. InProceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency. 1926–1939
work page 2024
-
[38]
Bell, Candace Ross, Adina Williams, Michal Drozdzal, and Adriana Romero Soriano
Melissa Hall, Samuel J. Bell, Candace Ross, Adina Williams, Michal Drozdzal, and Adriana Romero Soriano. 2024. Towards Geographic Inclusion in the Evaluation of Text-to-Image Models. InProceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency(Rio de Janeiro, Brazil)(FAccT ’24). Association for Computing Machinery, New York, NY, ...
-
[39]
Siobhan Mackenzie Hall, Samantha Dalal, Raesetje Sefala, Foutse Yuehgoh, Aisha Alaagib, Imane Hamzaoui, Shu Ishida, Jabez Magomere, Lauren Crais, Aya Salama, and Tejumade Afonja. 2025. The Human Labour of Data Work: Capturing Cultural Diversity through World Wide Dishes.Proc. ACM Hum.-Comput. Interact.9, 7, Article CSCW492 (Oct. 2025), 43 pages. doi:10.11...
- [40]
- [41]
-
[42]
Yujia Hu, Ming Shan Hee, Preslav Nakov, and Roy Ka-Wei Lee. 2025. Toxicity Red-Teaming: Benchmarking LLM Safety in Singapore’s Low-Resource Languages. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 12194–12212
work page 2025
-
[43]
Akshita Jha, Vinodkumar Prabhakaran, Remi Denton, Sarah Laszlo, Shachi Dave, Rida Qadri, Chandan Reddy, and Sunipa Dev. 2024. ViSAGe: A Global-Scale Analysis of Visual Stereotypes in Text-to-Image Generation. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Lun-Wei Ku, Andre Martins, and Vi...
work page 2024
-
[44]
Haotian Jin, Haihui Fan, Jinchao Zhang, Yang Li, Bo Li, and Junhao Zhou. 2025. Dangerous Language Habits! Exploiting Code-Mixing for Backdoor Attacks on NLP Models. InProceedings of the 34th ACM International Conference on Information and Knowledge Management. 1220–1230
work page 2025
-
[45]
Nari Johnson, Hamna ., Deepthi Sudharsan, Theo Holroyd, Samantha Dalal, Siobhan Mackenzie Hall, Jennifer Wortman Vaughan, Daniela Massiceti, and Cecily Morrison. 2025. Position: To Make Text-to-Image Models that Work for Marginalized Communities, We Need New Measurement Practices for the Long Tail. (July 2025). https://www.microsoft.com/en-us/research/pub...
work page 2025
-
[46]
Kyuheon Jung, Noah Lee, and Sungchul Choi. 2025. KoDi: A Korean Diffusion Model for Bilingual Text-to-Image Generation and Cultural Fidelity.IEEE Access13 (2025), 200290–200307. doi:10.1109/ACCESS.2025.3633798
-
[47]
FACE: Feasible and actionable counterfactual explanations
Amba Kak. 2020. "The Global South is everywhere, but also always somewhere": National Policy Narratives and AI Justice. InProceedings of the AAAI/ACM Conference on AI, Ethics, and Society(New York, NY, USA)(AIES ’20). Association for Computing Machinery, New York, NY, USA, 307–312. doi:10.1145/3375627.3375859
- [48]
-
[49]
Douwe Kiela, Max Bartolo, Yixin Nie, Divyansh Kaushik, Atticus Geiger, Zhengxuan Wu, Bertie Vidgen, Grusha Prasad, Amanpreet Singh, Pratik Ringshia, et al. 2021. Dynabench: Rethinking benchmarking in NLP. InProceedings of the 2021 conference of the North American chapter of the Association for Computational Linguistics: human language technologies. 4110–4124
work page 2021
-
[50]
Hannah Kirk, Abeba Birhane, Bertie Vidgen, and Leon Derczynski. 2022. Handling and Presenting Harmful Text in NLP Research. In Findings of the Association for Computational Linguistics: EMNLP 2022. Association for Computational Linguistics, Abu Dhabi, United Arab Emirates, 497–510. https://aclanthology.org/2022.findings-emnlp.35
work page 2022
-
[51]
Hannah R Kirk, Alexander Whitefield, Paul Röttger, Andrew Bean, Katerina Margatina, Juan Ciro, Rafael Mosquera, Max Bartolo, Adina Williams, He He, et al. 2024. The prism alignment dataset: What participatory, representative and individualised human feedback reveals about the subjective and multicultural alignment of large language models.Advances in Neur...
work page 2024
- [52]
-
[53]
Zilong Liu, Krzysztof Janowicz, Ivan Majic, Meilin Shi, Alexandra Fortacz, Mina Karimi, Gengchen Mai, and Kitty Currier. 2025. Operationalizing Geographic Diversity for the Evaluation of AI -Generated Content.Transactions in GIS29 (05 2025). doi:10.1111/tgis. 70057
-
[54]
Alexandra Sasha Luccioni, Christopher Akiki, Margaret Mitchell, and Yacine Jernite. 2023. Stable Bias: Analyzing Societal Representa- tions in Diffusion Models. InAdvances in Neural Information Processing Systems, Vol. 36. 56338–56351
work page 2023
-
[55]
Jabez Magomere, Shu Ishida, Tejumade Afonja, Aya Salama, Daniel Kochin, Yuehgoh Foutse, Imane Hamzaoui, Raesetje Sefala, Aisha Alaagib, Samantha Dalal, Beatrice Marchegiani, Elizaveta Semenova, Lauren Crais, and Siobhan Mackenzie Hall. 2025. The World Wide recipe: A community-centred framework for fine-grained data collection and regional bias operational...
- [56]
-
[57]
J. Nathan Matias and Megan Price. 2025. How public involvement can improve the science of AI.Proceedings of the National Academy of Sciences122, 48 (2025), e2421111122. arXiv:https://www.pnas.org/doi/pdf/10.1073/pnas.2421111122 doi:10.1073/pnas.2421111122
-
[58]
Leland McInnes, John Healy, and Steve Astels. 2017. hdbscan: Hierarchical density based clustering.Journal of Open Source Software2, 11 (2017), 205. doi:10.21105/joss.00205
-
[59]
Leland McInnes, John Healy, and James Melville. 2018. Umap: Uniform manifold approximation and projection for dimension reduction. arXiv preprint arXiv:1802.03426(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[60]
Shakir Mohamed, Marie-Therese Png, and William Isaac. 2020. Decolonial AI: Decolonial theory as sociotechnical foresight in artificial intelligence.Philosophy & Technology33, 4 (2020), 659–684
work page 2020
-
[61]
Shamsuddeen Hassan Muhammad, Idris Abdulmumin, Abinew Ali Ayele, David Ifeoluwa Adelani, Ibrahim Sa’id Ahmad, Saminu Mo- hammad Aliyu, Paul Röttger, Abigail Oppong, Andiswa Bukula, Chiamaka Ijeoma Chukwuneke, et al. 2025. Afrihate: A multilingual collection of hate speech and abusive language datasets for african languages. InProceedings of the 2025 Confe...
work page 2025
-
[62]
Shamsuddeen Hassan Muhammad, Idris Abdulmumin, Abinew Ali Ayele, Nedjma Ousidhoum, David Ifeoluwa Adelani, Seid Muhie Yimam, Ibrahim Sa’id Ahmad, Meriem Beloucif, Saif M. Mohammad, Sebastian Ruder, Oumaima Hourrane, Pavel Brazdil, Alipio Jorge, Felermino Dário Mário António Ali, Davis David, Salomey Osei, Bello Shehu Bello, Falalu Ibrahim, Tajuddeen Gwada...
-
[63]
Shravan Nayak, Kanishk Jain, Rabiul Awal, Siva Reddy, Sjoerd Van Steenkiste, Lisa Anne Hendricks, Karolina Stanczak, and Aishwarya Agrawal. 2024. Benchmarking Vision Language Models for Cultural Understanding. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (Eds.)....
-
[64]
Aidan Peppin, Julia Kreutzer, Alice Schoenauer Sebag, Kelly Marchisio, Beyza Ermis, John Dang, Samuel Cahyawijaya, Shivalika Singh, Seraphina Goldfarb-Tarrant, Viraat Aryabumi, et al. 2025. The Multilingual Divide and Its Impact on Global AI Safety.arXiv preprint arXiv:2505.21344(2025)
-
[65]
Ethan Perez, Saffron Huang, Francis Song, Trevor Cai, Roman Ring, John Aslanides, Amelia Glaese, Nat McAleese, and Geoffrey Irving
-
[66]
InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing
Red teaming language models with language models. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 3419–3448
work page 2022
-
[67]
Chau Minh Pham, Alexander Hoyle, Simeng Sun, Philip Resnik, and Mohit Iyyer. 2024. TopicGPT: A Prompt-based Topic Modeling Framework. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), Kevin Duh, Helena Gomez, and Steven Bethard (Eds.). A...
-
[68]
Mahika Phutane and Aditya Vashistha. 2025. Disability Across Cultures: A Human-Centered Audit of Ableism in Western and Indic LLMs. InProceedings of the AAAI/ACM Conference on AI, Ethics, and Society, Vol. 8. 2000–2014
work page 2025
-
[69]
1978.Syntactic structure and social function of code-switching
Shana Poplack. 1978.Syntactic structure and social function of code-switching. Vol. 2. Centro de Estudios Puertorriqueños,[City University of New York]
work page 1978
-
[70]
Rida Qadri, Mark Diaz, Ding Wang, and Michael Madaio. 2025. The case for" thick evaluations" of cultural representation in ai.arXiv preprint arXiv:2503.19075(2025)
-
[71]
Rida Qadri, Michael Madaio, and Mary L. Gray. 2025. Confusing the Map for the Territory.Commun. ACM68, 10 (Sept. 2025), 32–34. doi:10.1145/3731655
-
[72]
Rida Qadri, Renee Shelby, Cynthia L. Bennett, and Remi Denton. 2023. AI’s Regimes of Representation: A Community-centered Study of Text-to-Image Models in South Asia. InProceedings of the 2023 ACM Conference on Fairness, Accountability, and Transparency(Chicago, IL, USA)(FAccT ’23). Association for Computing Machinery, New York, NY, USA, 506–517. doi:10.1...
-
[73]
Jessica Quaye, Alicia Parrish, Oana Inel, Charvi Rastogi, Hannah Rose Kirk, Minsuk Kahng, Erin Van Liemt, Max Bartolo, Jess Tsang, Justin White, Nathan Clement, Rafael Mosquera, Juan Ciro, Vijay Janapa Reddi, and Lora Aroyo. 2024. Adversarial Nibbler: An Open Red-Teaming Method for Identifying Diverse Harms in Text-to-Image Generation. InProceedings of th...
- [74]
-
[75]
Bhaktipriya Radharapu, Kevin Robinson, Lora Aroyo, and Preethi Lahoti. 2023. Aart: Ai-assisted red-teaming with diverse data generation for new llm-powered applications. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: Industry Track. 380–395
work page 2023
-
[76]
Charvi Rastogi, Tian Huey Teh, Pushkar Mishra, Roma Patel, Ding Wang, Mark Díaz, Alicia Parrish, Aida Mostafazadeh Davani, Zoe Ashwood, Michela Paganini, et al. 2025. Whose view of safety? a deep dive dataset for pluralistic alignment of text-to-image models. arXiv preprint arXiv:2507.13383(2025)
-
[77]
Charvi Rastogi, Marco Tulio Ribeiro, Nicholas King, Harsha Nori, and Saleema Amershi. 2023. Supporting human-ai collaboration in auditing llms with llms. InProceedings of the 2023 AAAI/ACM Conference on AI, Ethics, and Society. 913–926
work page 2023
-
[78]
Aniket Rege, Zinnia Nie, Mahesh Ramesh, Unmesh Raskar, Zhuoran Yu, Aditya Kusupati, Yong Jae Lee, and Ramya Korlakai Vinayak
-
[79]
InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
CuRe: Cultural Gaps in the Long -Tail of Text-to-Image Models. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). https://aniketrege.github.io/cure
-
[80]
Bixuan Ren, EunJeong Cheon, and Jianghui Li. 2025. Organization Matters: A Qualitative Study of Organizational Dynamics in Red Teaming Practices For Generative AI.Proc. ACM Hum.-Comput. Interact.9, 7, Article CSCW460 (Oct. 2025), 26 pages. doi:10.1145/3757641
-
[81]
Marco Tulio Ribeiro and Scott Lundberg. 2022. Adaptive Testing and Debugging of NLP Models. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Smaranda Muresan, Preslav Nakov, and Aline Villavicencio (Eds.). Association for Computational Linguistics, Dublin, Ireland, 3253–3267. doi:10.18653/v...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.