From Prompts to Pavement Through Time: Temporal Grounding in Agentic Scene-to-Plan Reasoning
Pith reviewed 2026-05-20 06:01 UTC · model grok-4.3
The pith
Temporal conditioning reshapes reasoning in autonomous vehicle planners without statistically significant metric improvements.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
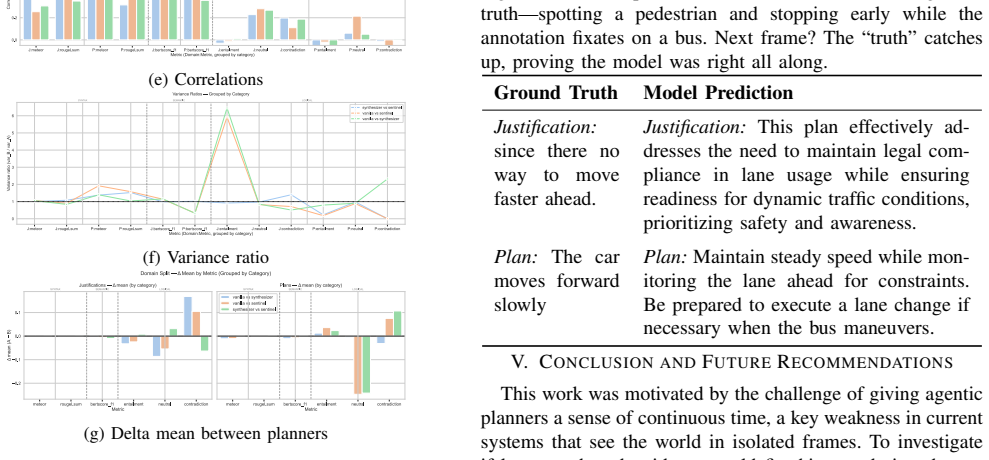
The authors establish that introducing temporal conditioning in the communication between agents for scene-to-plan reasoning in autonomous vehicles modifies the reasoning approach. Evaluation on subsets of the BDD-X dataset using semantic, syntactic, and logical metrics indicates no statistically significant enhancements in correctness. Qualitative examination, however, uncovers elements of predictive hazard reasoning, stable corrective behavior, and strategic divergence within the Sentinel planner. The study thus delineates the constraints of prompt-based temporal grounding and introduces an empirical benchmark for temporal scene-to-plan reasoning.
What carries the argument
Three planner architectures with progressively increasing temporal integration through inter-agent communication.
If this is right
- Temporal conditioning changes how planners reason about scenes and actions over time.
- No measurable improvement occurs in standard NLP correctness metrics despite the change in style.
- Qualitative benefits appear in the form of better anticipation of hazards and consistent corrections.
- The Sentinel architecture shows distinct strategic behavior under temporal conditioning.
- This sets up a baseline for measuring future advances in temporal scene-to-plan reasoning.
Where Pith is reading between the lines
- Future tests in closed-loop driving simulators could check if the qualitative hazard prediction gains actually lower collision rates.
- New time-sensitive evaluation measures might uncover benefits that current NLP metrics miss.
- Combining prompt-based temporal conditioning with direct sensor fusion could strengthen the observed strategic differences.
- The benchmark allows direct comparison of prompt methods against models that learn temporal patterns from data.
Load-bearing premise
The semantic, syntactic, and logical metrics combined with the curated subsets from the BDD-X dataset are sufficient to detect any real benefits of temporal grounding in continuous scene-to-plan reasoning.
What would settle it
A follow-up experiment using the same planners and dataset but with new metrics that directly score alignment of planned actions to time-stamped events, if it finds large gains from temporal conditioning, would contradict the reported lack of benefit.
Figures


read the original abstract
Recent attempts to support high-level scene interpretation and planning in Autonomous Vehicles (AVs) using ensembles of Large Language Models (LLMs) and Large Multimodal Models (LMMs) continue to treat time as a secondary property. This lack of temporal grounding leads to inconsistencies in reasoning about continuous actions, undermining both safety and interpretability. This work explores whether temporal conditioning within inter-agent communication can preserve or enhance coherence without introducing degradation in semantic or logical consistency. To investigate this, we introduce three planner architectures with progressively increasing temporal integration and evaluate them on curated subsets of the BDD-X dataset using semantic, syntactic, and logical metrics. Results show that while temporal conditioning reshapes reasoning style, it yields no statistically significant improvements in standard NLP-based correctness metrics. However, qualitative analysis reveals predictive hazard reasoning, stable corrective behavior, and strategic divergence in the Sentinel. These findings clarify the limits of prompt-based temporal grounding and establish the first empirical benchmark for temporal scene-to-plan reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that temporal conditioning within inter-agent communication for LLM/LMM-based planners in autonomous vehicles can preserve or enhance coherence in scene-to-plan reasoning without introducing degradation in semantic or logical consistency. It introduces three planner architectures with progressively increasing temporal integration and evaluates them on curated subsets of the BDD-X dataset using semantic, syntactic, and logical metrics. The results indicate that temporal conditioning reshapes reasoning style but yields no statistically significant improvements in standard NLP-based correctness metrics; qualitative analysis, however, reveals predictive hazard reasoning, stable corrective behavior, and strategic divergence in the Sentinel architecture. The work positions these findings as clarifying the limits of prompt-based temporal grounding and establishing the first empirical benchmark for temporal scene-to-plan reasoning.
Significance. If the results hold, this work provides a useful empirical benchmark for temporal scene-to-plan reasoning in agentic AV systems and highlights the potential mismatch between prompt-based temporal conditioning and standard NLP metrics. The introduction of three architectures with progressive temporal integration and the qualitative observations on hazard reasoning and corrective behavior are constructive contributions that could guide future development of safer, more interpretable planning systems. The paper also usefully flags the need for metrics that better capture cross-timestep consistency.
major comments (2)
- Evaluation section: The claim of no statistically significant improvements in standard NLP-based correctness metrics is presented without numerical values, error bars, exact metric definitions, sample sizes, or details on the statistical tests used. This absence makes it impossible to assess the power of the test or the practical magnitude of any differences between the three architectures.
- Evaluation section: The semantic, syntactic, and logical metrics applied to BDD-X subsets primarily target static scene interpretation and output validity. It is unclear whether these metrics are sensitive to the temporal benefits claimed for the architectures, such as cross-timestep consistency, forward simulation accuracy, or stable corrective behavior over time. This raises the possibility that the null quantitative result does not rule out genuine advantages of progressive temporal integration, especially given the unquantified qualitative observations for the Sentinel.
minor comments (2)
- Abstract: The abstract states results including lack of statistical significance but supplies no supporting numerical values or p-values; adding at least one concrete figure would strengthen the summary.
- The description of the three architectures would benefit from a concise table comparing their temporal integration mechanisms to improve readability.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which have helped us improve the clarity and rigor of the evaluation section. We address each major comment below, providing additional details and making revisions to the manuscript where necessary.
read point-by-point responses
-
Referee: Evaluation section: The claim of no statistically significant improvements in standard NLP-based correctness metrics is presented without numerical values, error bars, exact metric definitions, sample sizes, or details on the statistical tests used. This absence makes it impossible to assess the power of the test or the practical magnitude of any differences between the three architectures.
Authors: We agree with this observation. The original manuscript summarized the statistical findings at a high level without sufficient supporting data. In the revised version, we have included a detailed table (Table 3) with exact values for all metrics across the three architectures, including means, standard errors, sample sizes (n=50 per subset), and p-values from two-tailed t-tests comparing each pair of architectures. Error bars representing standard deviation have been added to Figure 2. These additions allow for a full assessment of effect sizes and statistical power. revision: yes
-
Referee: Evaluation section: The semantic, syntactic, and logical metrics applied to BDD-X subsets primarily target static scene interpretation and output validity. It is unclear whether these metrics are sensitive to the temporal benefits claimed for the architectures, such as cross-timestep consistency, forward simulation accuracy, or stable corrective behavior over time. This raises the possibility that the null quantitative result does not rule out genuine advantages of progressive temporal integration, especially given the unquantified qualitative observations for the Sentinel.
Authors: We appreciate this point and acknowledge that our chosen metrics focus primarily on per-scene correctness rather than explicit temporal dynamics. This was intentional to compare against established NLP benchmarks for scene-to-plan tasks. The qualitative analysis in Section 5.3 provides concrete examples of predictive hazard reasoning and stable corrective behavior in the Sentinel architecture, which illustrate the temporal advantages not captured quantitatively. In the revision, we have added a paragraph in the discussion section explicitly addressing this metric sensitivity issue and outlining plans for future temporal-specific metrics, such as cross-timestep consistency scores. We believe the combination of null quantitative results and positive qualitative findings strengthens the paper's contribution by highlighting the limitations of prompt-based temporal grounding. revision: partial
Circularity Check
Empirical evaluation study with independent metrics; no derivation or self-citation reduces results to inputs
full rationale
The paper is an empirical evaluation introducing three planner architectures with increasing temporal integration, tested on BDD-X subsets via semantic/syntactic/logical metrics plus qualitative analysis. No equations, fitted parameters, or derivations are present that would reduce claims to inputs by construction. Results (no significant metric gains, qualitative benefits in Sentinel) rest on statistical tests and observations external to the architectures themselves. Self-citations are absent from the provided text, and the benchmark claim is a direct outcome of the experiment rather than a renaming or self-referential loop. This meets the criteria for a self-contained empirical study with score 0.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/ArrowOfTime.leanarrow_from_z unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
three planner architectures with progressively increasing temporal integration ... Sentinel ... Synthesizer ... logical continuity between successive plans
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
SAE International, “Taxonomy and definitions for terms related to driving automation systems for on-road motor vehicles (j3016),” https: //www.sae.org/standards/content/j3016 202104/, 2021, accessed: 2025- 04-29
work page 2021
-
[2]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in neural information processing systems, vol. 30, 2017
work page 2017
-
[3]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gellyet al., “An image is worth 16x16 words: Transformers for image recognition at scale,”arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[4]
Robotron-drive: All-in-one large multimodal model for autonomous driving,
Z. Huang, C. Feng, F. Yan, B. Xiao, Z. Jie, Y . Zhong, X. Liang, and L. Ma, “Robotron-drive: All-in-one large multimodal model for autonomous driving,” 2024
work page 2024
-
[5]
Eval- uation of large language models for decision making in autonomous driving,
K. Tanahashi, Y . Inoue, Y . Yamaguchi, H. Yaginuma, D. Shiotsuka, H. Shimatani, K. Iwamasa, Y . Inoue, T. Yamaguchi, K. Igariet al., “Eval- uation of large language models for decision making in autonomous driving,”arXiv preprint arXiv:2312.06351, 2023
-
[6]
T. Cai, Y . Liu, Z. Zhou, H. Ma, S. Z. Zhao, Z. Wu, and J. Ma, “Driving with regulation: Interpretable decision-making for autonomous vehicles with retrieval-augmented reasoning via llm,”arXiv preprint arXiv:2410.04759, 2024
-
[7]
Language models are few-shot learners,
T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-V oss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. M. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. Amo...
-
[8]
Language Models are Few-Shot Learners
[Online]. Available: https://arxiv.org/abs/2005.14165
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[9]
Large Language Models are Zero-Shot Reasoners
T. Kojima, S. S. Gu, M. Reid, Y . Matsuo, and Y . Iwasawa, “Large language models are zero-shot reasoners,” 2023. [Online]. Available: https://arxiv.org/abs/2205.11916
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Z. Wang, S. Cai, G. Chen, A. Liu, X. Ma, and Y . Liang, “Describe, explain, plan and select: Interactive planning with large language models enables open-world multi-task agents,” 2024. [Online]. Available: https://arxiv.org/abs/2302.01560
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
L. Xu, Z. Hu, D. Zhou, H. Ren, Z. Dong, K. Keutzer, S.- K. Ng, and J. Feng, “MAgIC: Investigation of large language model powered multi-agent in cognition, adaptability, rationality and collaboration,” pp. 7315–7332, Nov. 2024. [Online]. Available: https://aclanthology.org/2024.emnlp-main.416/
work page 2024
-
[12]
O. Y . Goba, A. Y . Gado, C. M. Elias, and A. Hussein, “From prompts to pavement: Lmms-based agentic behavior-tree generation framework for autonomous vehicles,”arXiv preprint arXiv:2601.12358, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
J. Yu, “Agentic vehicles for human-centered mobility systems,”arXiv preprint arXiv:2507.04996, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Agentic ai: The age of reasoning—a review,
U. Nisa, M. Shirazi, M. A. Saip, and M. S. M. Pozi, “Agentic ai: The age of reasoning—a review,”Journal of Automation and Intelligence, 2025
work page 2025
-
[15]
Situational perception in distracted driving: an agentic multi-modal llm framework,
A. Nazar, M. Y . Selim, A. Gaffar, and D. Qiao, “Situational perception in distracted driving: an agentic multi-modal llm framework,”Frontiers in Artificial Intelligence, vol. 8, p. 1669937, 2025
work page 2025
-
[16]
O. Y . Goba, A. Y . Gado, C. M. Elias, and A. Hussein, “From prompts to pavement: Lmms-based agentic behavior-tree generation framework for autonomous vehicles,” inProceedings of the IEEE Intelligent Trans- portation Systems Conference (ITSC), Gold Coast, Australia, 2025, to appear; conference date: November 15–18, 2025; proceedings publica- tion: Novembe...
work page 2025
-
[17]
Nonlinear model predictive control for un- manned aerial vehicles,
P. Ru and K. Subbarao, “Nonlinear model predictive control for un- manned aerial vehicles,”Aerospace, vol. 4, p. 31, 06 2017
work page 2017
-
[18]
V . Konda and J. Tsitsiklis, “Actor-critic algorithms,” in Advances in Neural Information Processing Systems, S. Solla, T. Leen, and K. M ¨uller, Eds., vol. 12. MIT Press, 1999. [Online]. Available: https://proceedings.neurips.cc/paper files/paper/ 1999/file/6449f44a102fde848669bdd9eb6b76fa-Paper.pdf
work page 1999
-
[19]
Textual explanations for self-driving vehicles,
J. Kim, A. Rohrbach, T. Darrell, J. Canny, and Z. Akata, “Textual explanations for self-driving vehicles,”Proceedings of the European Conference on Computer Vision (ECCV), 2018
work page 2018
-
[20]
Meteor: An automatic metric for mt evalua- tion with improved correlation with human judgments,
S. Banerjee and A. Lavie, “Meteor: An automatic metric for mt evalua- tion with improved correlation with human judgments,” inProceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization, 2005, pp. 65–72
work page 2005
-
[21]
Rouge: A package for automatic evaluation of sum- maries,
L. Chin-Yew, “Rouge: A package for automatic evaluation of sum- maries,” inProceedings of the Workshop on Text Summarization Branches Out, 2004, 2004
work page 2004
-
[22]
BERTScore: Evaluating Text Generation with BERT
T. Zhang, V . Kishore, F. Wu, K. Q. Weinberger, and Y . Artzi, “Bertscore: Evaluating text generation with bert,”arXiv preprint arXiv:1904.09675, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[23]
M. Lewis, Y . Liu, N. Goyal, M. Ghazvininejad, A. Mohamed, O. Levy, V . Stoyanov, and L. Zettlemoyer, “Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehen- sion,”arXiv preprint arXiv:1910.13461, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1910
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.