Towards Context-Invariant Safety Alignment for Large Language Models
Pith reviewed 2026-05-21 05:32 UTC · model grok-4.3
The pith
Anchor Invariance Regularization enforces safety behavior that depends on intent rather than prompt wording in large language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
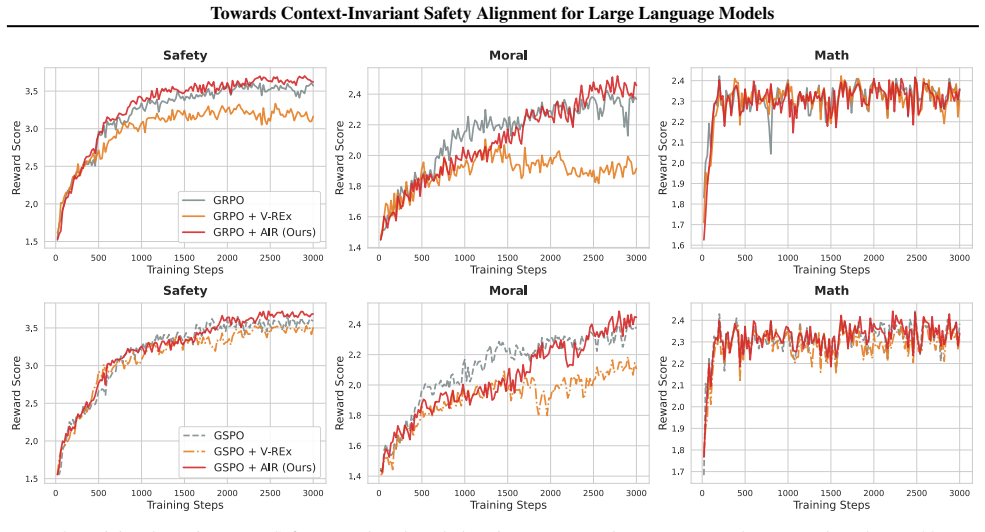
We introduce Anchor Invariance Regularization (AIR), which treats verifiable prompts as anchors and uses a stop-gradient target to regularize only the open-ended variants toward the anchor performance. AIR is implemented as a plug-in auxiliary loss and combined with group-based preference optimization via heterogeneous prompt grouping. Across Safety, Moral Reasoning, and Math, AIR improves context invariance, boosting in-distribution group accuracy by 12.71% and out-of-distribution consistency by 33.49%, making safety constraints robust to adversarial framings.
What carries the argument
Anchor Invariance Regularization (AIR), a plug-in auxiliary loss that designates verifiable prompts as stop-gradient anchors and regularizes open-ended variants toward their performance without symmetric penalties on the anchors.
If this is right
- Safety refusals remain consistent when the same harmful intent is rephrased in adversarial ways.
- In-distribution group accuracy rises by 12.71 percent across evaluated tasks.
- Out-of-distribution consistency rises by 33.49 percent on held-out prompt variants.
- The auxiliary loss combines directly with existing group-based preference methods such as GRPO.
- The gains appear in safety, moral reasoning, and math domains.
Where Pith is reading between the lines
- The same anchoring idea could apply to factual accuracy or hallucination reduction where some feedback signals are more reliable than others.
- Models trained this way might show greater resistance to real-world jailbreak attempts that rely on creative framing.
- Future experiments could test whether automatically generating verifiable variants for new domains preserves the gains.
- The distinction between trustworthy and noisy training signals may matter for alignment objectives beyond safety.
Load-bearing premise
Verifiable prompts such as multiple-choice questions supply trustworthy feedback that can safely serve as stop-gradient anchors without lowering performance on those prompts or introducing new biases on open-ended ones.
What would settle it
Train a model with AIR and measure whether accuracy on the verifiable anchor prompts drops or out-of-distribution consistency on adversarial safety prompts fails to improve relative to a baseline without AIR.
Figures




read the original abstract
Preference-based post-training aligns LLMs with human intent, yet safety behavior often remains brittle. A model may refuse a harmful request in a standard prompt but comply when the same intent is wrapped in adversarial wording. We suggest that robust safety requires context-invariant alignment, where behavior depends on the underlying intent rather than surface form. Enforcing invariance is difficult in alignment because not all training signals are equally trustworthy; for some prompt variants we can obtain verifiable feedback (e.g., multiple-choice), while for open-ended variants we typically rely on noisy, gameable reward proxies (e.g., learned judges). As a result, standard symmetric invariance regularizers can reduce cross-context discrepancies by lowering performance on reliable variants instead of improving open-ended robustness. To address this, we introduce Anchor Invariance Regularization (AIR), which treats verifiable prompts as anchors and uses a stop-gradient target to regularize only the open-ended variants toward the anchor performance. AIR is implemented as a plug-in auxiliary loss and combined with group-based preference optimization (e.g., GRPO) via heterogeneous prompt grouping. Across Safety, Moral Reasoning, and Math, AIR improves context invariance, boosting in-distribution group accuracy by 12.71% and out-of-distribution consistency by 33.49%, making safety constraints robust to adversarial framings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that safety alignment in LLMs is brittle because behavior depends on prompt surface form rather than underlying intent. It introduces Anchor Invariance Regularization (AIR), an auxiliary loss that treats verifiable multiple-choice prompts as stop-gradient anchors and regularizes open-ended variants toward them, combined with heterogeneous grouping in group-based preference optimization (e.g., GRPO). Experiments on Safety, Moral Reasoning, and Math tasks report that AIR improves context invariance, with +12.71% in-distribution group accuracy and +33.49% out-of-distribution consistency.
Significance. If the empirical gains are robust and the anchor assumption holds, the method offers a practical way to enforce context-invariant safety without symmetrically degrading performance on reliable signals. The heterogeneous grouping and stop-gradient design is a targeted response to the problem that not all alignment feedback is equally trustworthy, which could influence future work on robust post-training.
major comments (3)
- Abstract and §4 (Experiments): The abstract states precise gains of 12.71% in-distribution group accuracy and 33.49% out-of-distribution consistency, yet the provided text supplies no baselines, variance estimates, number of runs, or controls for confounds such as prompt length or option ordering. Without these, the central claim that AIR produces genuine context invariance cannot be evaluated.
- §3.1 (AIR construction): The stop-gradient anchor on verifiable multiple-choice prompts assumes these encode the desired safety behavior without format-specific artifacts. If anchors admit superficial heuristics (keyword matching or option ordering), the regularization may transfer a different brittleness to open-ended variants rather than achieving intent-based invariance; an ablation isolating anchor quality is required to support the reported gains.
- §3.2 (Heterogeneous grouping with GRPO): The claim that shared parameters do not allow gradients from open-ended items to indirectly affect anchor optimization is not demonstrated. A direct measurement of anchor performance before and after joint training would be needed to confirm that the stop-gradient truly isolates the reliable signal.
minor comments (2)
- Notation for the auxiliary loss could be clarified with an explicit equation showing how the stop-gradient target is computed and combined with the GRPO objective.
- Figure captions should explicitly state whether error bars represent standard deviation across seeds or across prompt groups.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our work. We address each of the major comments in detail below, indicating where we will revise the manuscript to incorporate the suggestions.
read point-by-point responses
-
Referee: Abstract and §4 (Experiments): The abstract states precise gains of 12.71% in-distribution group accuracy and 33.49% out-of-distribution consistency, yet the provided text supplies no baselines, variance estimates, number of runs, or controls for confounds such as prompt length or option ordering. Without these, the central claim that AIR produces genuine context invariance cannot be evaluated.
Authors: We appreciate this observation. The reported gains are relative improvements over the GRPO baseline, with full baseline results and comparisons presented in Section 4. To address the lack of details, we will revise the abstract to indicate that the gains are based on averaged results. In the revised manuscript, we will expand the description of the experimental setup to include the number of runs, variance estimates, and details on controls for prompt length and option ordering. Specifically, we will clarify how we matched prompt lengths and randomized option orders to mitigate potential confounds. revision: yes
-
Referee: §3.1 (AIR construction): The stop-gradient anchor on verifiable multiple-choice prompts assumes these encode the desired safety behavior without format-specific artifacts. If anchors admit superficial heuristics (keyword matching or option ordering), the regularization may transfer a different brittleness to open-ended variants rather than achieving intent-based invariance; an ablation isolating anchor quality is required to support the reported gains.
Authors: This is a valid concern regarding potential artifacts in the anchors. We chose multiple-choice formats because they allow for objective verification of correctness, reducing reliance on subjective or gameable signals. However, to directly address the possibility of transferring format-specific heuristics, we will include a new ablation in the experiments section. This ablation will involve training with anchors that have been perturbed (e.g., by shuffling options or adding irrelevant keywords) and compare the resulting invariance gains to the original setup. We believe this will demonstrate that the benefits stem from the verifiable nature rather than superficial cues. revision: yes
-
Referee: §3.2 (Heterogeneous grouping with GRPO): The claim that shared parameters do not allow gradients from open-ended items to indirectly affect anchor optimization is not demonstrated. A direct measurement of anchor performance before and after joint training would be needed to confirm that the stop-gradient truly isolates the reliable signal.
Authors: We clarify that the stop-gradient mechanism mathematically prevents any gradient flow from the open-ended loss terms back to the anchor predictions, even with shared parameters. This isolation is by design in the computation graph. That said, we acknowledge that an empirical verification would strengthen the argument. In the revised version, we will add a table or plot showing the anchor accuracy on verifiable prompts at the start and end of training, demonstrating that it does not degrade and in fact often improves due to the overall optimization. revision: yes
Circularity Check
No circularity: empirical auxiliary loss with measured gains
full rationale
The paper introduces AIR as a plug-in auxiliary loss that applies stop-gradient to verifiable (multiple-choice) prompts as anchors while regularizing open-ended variants toward them, then combines it with GRPO via heterogeneous grouping. Reported gains (12.71% in-distribution accuracy, 33.49% out-of-distribution consistency) are presented as empirical measurements on Safety, Moral Reasoning, and Math benchmarks rather than quantities derived from equations or parameters that reduce to the method's own inputs by construction. No self-definitional loops, fitted-input-as-prediction patterns, or load-bearing self-citations appear in the described derivation; the central claim remains an independent empirical regularization technique whose validity rests on external benchmark results.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
AIR replaces the symmetric variance penalty with an anchor-referenced penalty applied exclusively to non-anchor contexts: Ω_AIR(θ) = Σ (Rc(θ) − τ_acr(θ))² where τ_acr(θ) = sg[Rc_acr(θ)]
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We identify that symmetric invariance regularization fails in safety alignment... propose Anchor Invariance Regularization (AIR)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
work page 2000
-
[2]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
work page 1980
-
[3]
M. J. Kearns , title =
-
[4]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
work page 1983
-
[5]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
work page 2000
-
[6]
Suppressed for Anonymity , author=
-
[7]
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
work page 1981
-
[8]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
work page 1959
-
[9]
Deep reinforcement learning from human preferences , author=. NeurIPS , year=
-
[10]
Training language models to follow instructions with human feedback , author=. NeurIPS , year=
-
[12]
Direct preference optimization: Your language model is secretly a reward model , author=. NeurIPS , year=
-
[15]
Simpo: Simple preference optimization with a reference-free reward , author=. NeurIPS , year=
-
[19]
Generalizing to unseen domains: A survey on domain generalization , author=. IEEE TKDE , year=
-
[21]
An invariant learning characterization of controlled text generation , author=. ACL , year=
- [22]
-
[23]
Scaling laws for reward model overoptimization in direct alignment algorithms , author=. NeurIPS , year=
- [26]
-
[27]
Rewardbench: Evaluating reward models for language modeling , author=. Findings of NAACL , year=
-
[28]
Rethinking Reward Model Evaluation Through the Lens of Reward Overoptimization , author=. ACL , year=
-
[29]
Judging llm-as-a-judge with mt-bench and chatbot arena , author=. NeurIPS , year=
-
[30]
Chatbot arena: An open platform for evaluating llms by human preference , author=. ICML , year=
- [33]
-
[34]
Out-of-distribution generalization via risk extrapolation (rex) , author=. ICML , year=
- [36]
- [38]
-
[39]
Does safety training of llms generalize to semantically related natural prompts?, 2025
Does Safety Training of LLMs Generalize to Semantically Related Natural Prompts? , author=. arXiv preprint arXiv:2412.03235 , year=
- [41]
- [42]
- [43]
-
[45]
Concrete Problems in AI Safety
Concrete problems in AI safety , author=. arXiv preprint arXiv:1606.06565 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
Quantifying Language Models' Sensitivity to Spurious Features in Prompt Design or: How I learned to start worrying about prompt formatting , author=. arXiv preprint arXiv:2310.11324 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
Keeping llms aligned after fine-tuning: The crucial role of prompt templates , author=. NeurIPS , year=
- [49]
-
[54]
The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation , author =. 2025 , url =
work page 2025
- [56]
-
[57]
Foundations and Trends in Privacy and Security , year=
Safety at scale: A comprehensive survey of large model and agent safety , author=. Foundations and Trends in Privacy and Security , year=
-
[58]
JailBound: Jailbreaking Internal Safety Boundaries of Vision-Language Models , author=. NeurIPS , year=
-
[59]
arXiv preprint arXiv:2601.01592 , year=
OpenRT: An Open-Source Red Teaming Framework for Multimodal LLMs , author=. arXiv preprint arXiv:2601.01592 , year=
-
[60]
Improving Generalization of Alignment with Human Preferences through Group Invariant Learning , author=. ICLR , year=
-
[61]
Flames: Benchmarking value alignment of llms in chinese , author=. NAACL , year=
-
[62]
Mllmguard: A multi-dimensional safety evaluation suite for multimodal large language models , author=. NeurIPS , year=
-
[63]
A mousetrap: Fooling large reasoning models for jailbreak with chain of iterative chaos , author=. Findings of ACL , year=
-
[64]
Safeevalagent: Toward agentic and self-evolving safety evaluation of llms , author=. Findings of ACL , year=
-
[65]
Safevid: Toward safety aligned video large multimodal models , author=. NeurIPS , year=
-
[66]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[67]
The llama 4 herd: The beginning of a new era of natively multimodal ai innovation, 2025
AI, M. The llama 4 herd: The beginning of a new era of natively multimodal ai innovation, 2025. URL https://ai.meta.com/blog/llama-4-multimodal-intelligence/
work page 2025
-
[68]
Anil, C., Durmus, E., Panickssery, N., Sharma, M., Benton, J., Kundu, S., Batson, J., Tong, M., Mu, J., Ford, D., et al. Many-shot jailbreaking. NeurIPS, 2024
work page 2024
-
[69]
Arjovsky, M., Bottou, L., Gulrajani, I., and Lopez-Paz, D. Invariant risk minimization. arXiv preprint arXiv:1907.02893, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[70]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Bai, Y., Jones, A., Ndousse, K., Askell, A., Chen, A., DasSarma, N., Drain, D., Fort, S., Ganguli, D., Henighan, T., et al. Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv preprint arXiv:2204.05862, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [71]
-
[72]
N., Li, T., Li, D., Zhu, B., Zhang, H., Jordan, M., Gonzalez, J
Chiang, W.-L., Zheng, L., Sheng, Y., Angelopoulos, A. N., Li, T., Li, D., Zhu, B., Zhang, H., Jordan, M., Gonzalez, J. E., et al. Chatbot arena: An open platform for evaluating llms by human preference. In ICML, 2024
work page 2024
-
[73]
Choe, Y. J., Ham, J., and Park, K. An empirical study of invariant risk minimization. arXiv preprint arXiv:2004.05007, 2020
-
[74]
F., Leike, J., Brown, T., Martic, M., Legg, S., and Amodei, D
Christiano, P. F., Leike, J., Brown, T., Martic, M., Legg, S., and Amodei, D. Deep reinforcement learning from human preferences. NeurIPS, 2017
work page 2017
-
[75]
Training Verifiers to Solve Math Word Problems
Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., Hesse, C., and Schulman, J. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[76]
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[77]
KTO: Model Alignment as Prospect Theoretic Optimization
Ethayarajh, K., Xu, W., Muennighoff, N., Jurafsky, D., and Kiela, D. Kto: Model alignment as prospect theoretic optimization. arXiv preprint arXiv:2402.01306, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[78]
Scaling laws for reward model overoptimization
Gao, L., Schulman, J., and Hilton, J. Scaling laws for reward model overoptimization. In ICML, 2023
work page 2023
-
[79]
Alignment faking in large language models
Greenblatt, R., Denison, C., Wright, B., Roger, F., MacDiarmid, M., Marks, S., Treutlein, J., Belonax, T., Chen, J., Duvenaud, D., et al. Alignment faking in large language models. arXiv preprint arXiv:2412.14093, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[80]
Gu, J., Jiang, X., Shi, Z., Tan, H., Zhai, X., Xu, C., Li, W., Shen, Y., Ma, S., Liu, H., Wang, Y., and Guo, J. A survey on llm-as-a-judge. arXiv preprint arXiv: 2411.15594, 2024 a
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[81]
Mllmguard: A multi-dimensional safety evaluation suite for multimodal large language models
Gu, T., Zhou, Z., Huang, K., Liang, D., Wang, Y., Zhao, H., Yao, Y., Qiao, X., Wang, K., Yang, Y., et al. Mllmguard: A multi-dimensional safety evaluation suite for multimodal large language models. NeurIPS, 2024 b
work page 2024
-
[82]
ORPO: Monolithic Preference Optimization without Reference Model
Hong, J., Lee, N., and Thorne, J. Orpo: Monolithic preference optimization without reference model. arXiv preprint arXiv:2403.07691, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[83]
Flames: Benchmarking value alignment of llms in chinese
Huang, K., Liu, X., Guo, Q., Sun, T., Sun, J., Wang, Y., Zhou, Z., Wang, Y., Teng, Y., Qiu, X., et al. Flames: Benchmarking value alignment of llms in chinese. In NAACL, 2024
work page 2024
-
[84]
Out-of-distribution generalization via risk extrapolation (rex)
Krueger, D., Caballero, E., Jacobsen, J.-H., Zhang, A., Binas, J., Zhang, D., Le Priol, R., and Courville, A. Out-of-distribution generalization via risk extrapolation (rex). In ICML, 2021
work page 2021
-
[85]
Lambert, N., Pyatkin, V., Morrison, J., Miranda, L. J. V., Lin, B. Y., Chandu, K., Dziri, N., Kumar, S., Zick, T., Choi, Y., et al. Rewardbench: Evaluating reward models for language modeling. In Findings of NAACL, 2025
work page 2025
-
[86]
G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment
Liu, Y., Iter, D., Xu, Y., Wang, S., Xu, R., and Zhu, C. G-eval: Nlg evaluation using gpt-4 with better human alignment. arXiv preprint arXiv:2303.16634, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[87]
Safety at scale: A comprehensive survey of large model and agent safety
Ma, X., Gao, Y., Wang, Y., Wang, R., Wang, X., Sun, Y., Ding, Y., Xu, H., Chen, Y., Zhao, Y., et al. Safety at scale: A comprehensive survey of large model and agent safety. Foundations and Trends in Privacy and Security, 2026
work page 2026
-
[88]
Rethinking reward model evaluation through the lens of reward overoptimization
Mac Kim, S., Kang, D., Kwon, T., Chae, H., Lee, D., and Yeo, J. Rethinking reward model evaluation through the lens of reward overoptimization. In ACL, 2025
work page 2025
-
[89]
Simpo: Simple preference optimization with a reference-free reward
Meng, Y., Xia, M., and Chen, D. Simpo: Simple preference optimization with a reference-free reward. NeurIPS, 2024
work page 2024
-
[90]
K., Strouse, D., Sandholm, T., Salakhutdinov, R., Dragan, A
Moskovitz, T., Singh, A. K., Strouse, D., Sandholm, T., Salakhutdinov, R., Dragan, A. D., and McAleer, S. Confronting reward model overoptimization with constrained rlhf. arXiv preprint arXiv:2310.04373, 2023
-
[91]
Rule based rewards for language model safety
Mu, T., Helyar, A., Heidecke, J., Achiam, J., Vallone, A., Kivlichan, I., Lin, M., Beutel, A., Schulman, J., and Weng, L. Rule based rewards for language model safety. NeurIPS, 2024
work page 2024
-
[92]
WebGPT: Browser-assisted question-answering with human feedback
Nakano, R., Hilton, J., Balaji, S., Wu, J., Ouyang, L., Kim, C., Hesse, C., Jain, S., Kosaraju, V., Saunders, W., et al. Webgpt: Browser-assisted question-answering with human feedback. arXiv preprint arXiv:2112.09332, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[93]
OpenAI. Gpt-5 system card. Technical report, 2025. URL https://cdn.openai.com/gpt-5-system-card.pdf
work page 2025
-
[94]
Training language models to follow instructions with human feedback
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., et al. Training language models to follow instructions with human feedback. NeurIPS, 2022
work page 2022
-
[95]
Rafailov, R., Sharma, A., Mitchell, E., Manning, C. D., Ermon, S., and Finn, C. Direct preference optimization: Your language model is secretly a reward model. NeurIPS, 2023
work page 2023
-
[96]
S., Hejna, J., Knox, B., Finn, C., and Niekum, S
Rafailov, R., Chittepu, Y., Park, R., Sikchi, H. S., Hejna, J., Knox, B., Finn, C., and Niekum, S. Scaling laws for reward model overoptimization in direct alignment algorithms. NeurIPS, 2024
work page 2024
-
[97]
Evaluating the moral beliefs encoded in llms
Scherrer, N., Shi, C., Feder, A., and Blei, D. Evaluating the moral beliefs encoded in llms. In NeurIPS, 2023
work page 2023
-
[98]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[99]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y., Wu, Y., et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[100]
Defining and characterizing reward gaming
Skalse, J., Howe, N., Krasheninnikov, D., and Krueger, D. Defining and characterizing reward gaming. NeurIPS, 2022
work page 2022
-
[101]
Jailbound: Jailbreaking internal safety boundaries of vision-language models
Song, J., Wang, Y., Li, J., Yu, R., Teng, Y., Ma, X., and Wang, Y. Jailbound: Jailbreaking internal safety boundaries of vision-language models. In NeurIPS, 2025
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.