Goal-Conditioned Agents that Learn Everything All at Once
Pith reviewed 2026-05-25 04:56 UTC · model grok-4.3
The pith
Goal-conditioned RL agents can learn from every possible goal in a single network pass instead of relabelling each transition.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
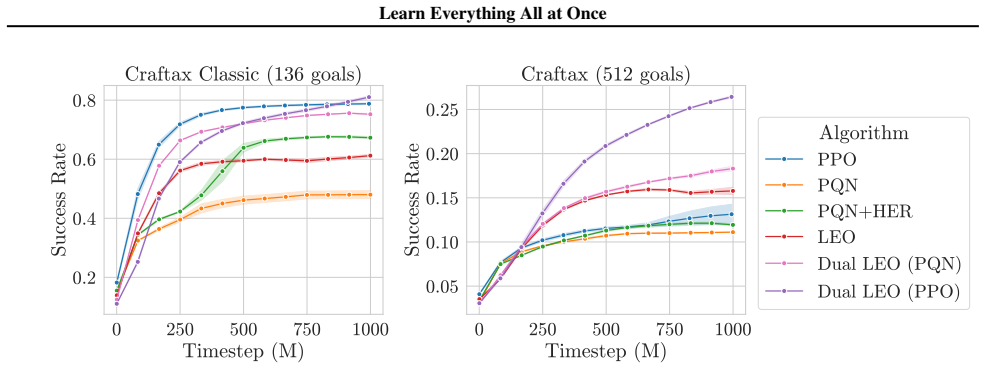
A network that jointly produces value estimates and actions for every goal in one forward pass enables efficient, parallel all-goals off-policy updates. This removes the need for naive relabelling while still extracting information about every goal from each transition, yielding more than 250 times faster training than relabelling methods, higher returns on goal-conditioned Craftax, and competitive results on continuous control benchmarks.
What carries the argument
The LEO network architecture that produces goal-conditioned value and action outputs for the entire goal set in a single forward pass.
If this is right
- All-goals learning becomes practical at the scale of environments like Craftax without prohibitive compute cost.
- Each trajectory yields useful training signals for every achievable goal rather than only the commanded one.
- The same joint-output network can be distilled into a separate actor for additional performance gains.
- Training time on goal-conditioned tasks drops by more than two orders of magnitude relative to relabelling.
Where Pith is reading between the lines
- The same joint-output trick could be applied to multi-task RL by treating each task as a pseudo-goal.
- Environments with continuous goal spaces might become tractable if the output layer is replaced by a parametric goal encoder.
- LEO-style networks could reduce the sample complexity gap between goal-conditioned and standard single-goal RL.
Load-bearing premise
Jointly outputting values and actions for every goal at once stays computationally and numerically stable without loss of accuracy as the number of goals or environment complexity increases.
What would settle it
Train an LEO agent on a goal-conditioned task with several thousand distinct goals and measure whether wall-clock time per update remains more than 100 times faster than relabelling while final task performance stays at or above the reported baselines.
Figures


















read the original abstract
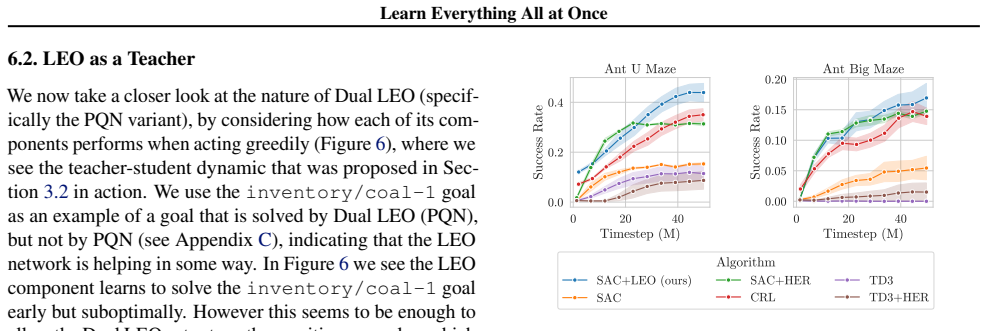
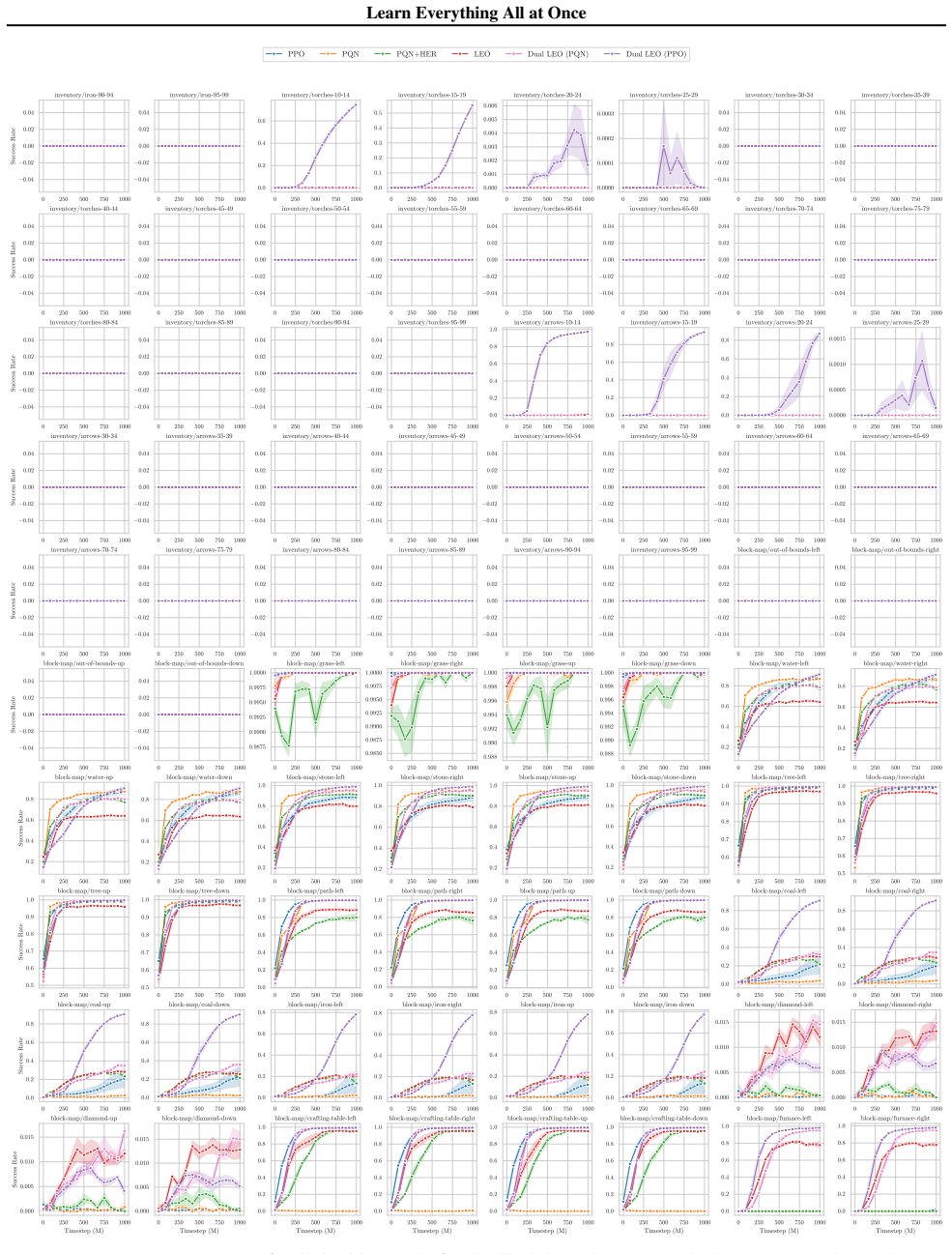
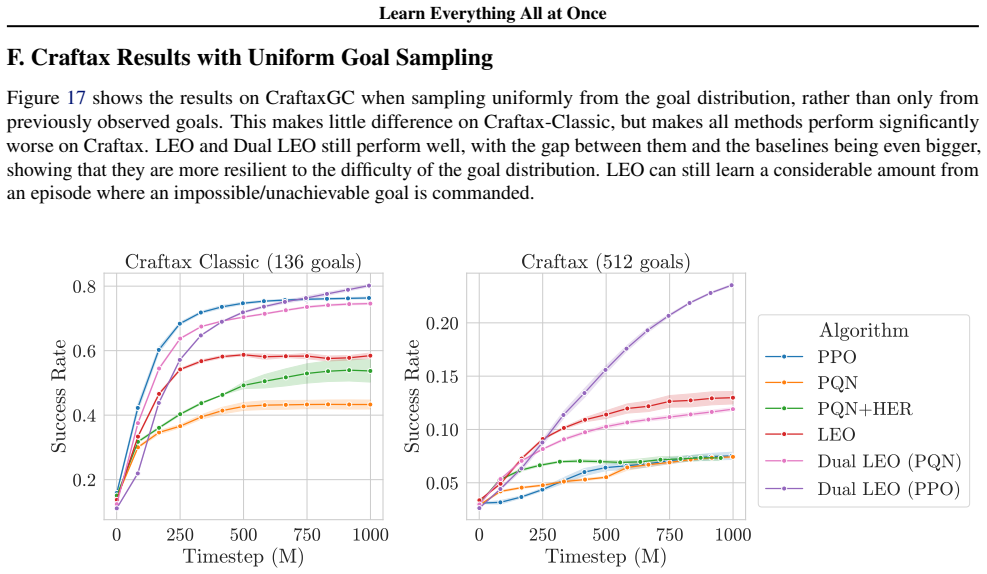
A goal-conditioned reinforcement learning agent exploring an environment will see a wealth of information throughout a trajectory, most of which is discarded when only performing on-policy updates with respect to the commanded goal. All-goals learning, where each transition is used for learning off-policy with respect to every goal, allows agents to extract maximal information, however it is usually computationally infeasible when done via naive relabelling. This can be overcome by jointly outputting values and actions for every goal at once, allowing for efficient, parallel all-goals updates with a single pass through the network, in a process we call Learning Everything all at Once (LEO). We show that this approach significantly outperforms other methods on goal-conditioned Craftax and is competitive with existing baselines on continuous control environments, while achieving a >250x speed-up compared to all-goals relabelling. We then go on to show that this approach can be made even more powerful by using LEO as a teacher network, rather than a direct actor. We hope that, by unlocking all-goals learning at scale, LEO can serve as a useful tool for RL practitioners in complex environments. We open source our code.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Learning Everything all at Once (LEO), a goal-conditioned RL method that replaces naive all-goals relabelling with a single forward pass through a network whose output head jointly predicts values and actions for every goal. The central claim is that this yields >250× wall-clock speedup while matching or exceeding the performance of all-goals relabelling, with reported gains on goal-conditioned Craftax and competitive results on continuous-control suites. An additional teacher-student variant is also presented.
Significance. If the efficiency and accuracy claims hold under scaling, LEO would make all-goals learning practical in environments where |G| is large, directly improving sample efficiency without extra passes. The open-sourced code is a concrete strength that supports reproducibility and follow-up work.
major comments (2)
- [§3] §3 (Method), joint-output architecture: the paper asserts equivalence to all-goals relabelling but provides no capacity or interference analysis showing that a fixed-size output head preserves per-goal accuracy once |G| exceeds the Craftax scale used in experiments. This directly bears on whether the reported speedup and performance gains survive larger goal sets.
- [§4] §4 (Experiments), Craftax and continuous-control tables: results are reported for a fixed goal cardinality; no ablation varies |G| or goal dimensionality while measuring value-error or policy degradation relative to the relabelling baseline. Without this, the claim that joint prediction incurs “no accuracy loss” remains untested at the scales where the computational advantage would matter most.
minor comments (2)
- [Abstract] Abstract and §1: performance and speedup numbers are stated without reference to the exact baselines or number of seeds; adding these citations would improve immediate readability.
- [§2] Notation: the distinction between the commanded goal g and the full goal set G is occasionally ambiguous in the equations; a short clarifying sentence in §2 would help.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below, focusing on the technical points raised regarding the joint-output architecture and experimental validation.
read point-by-point responses
-
Referee: [§3] §3 (Method), joint-output architecture: the paper asserts equivalence to all-goals relabelling but provides no capacity or interference analysis showing that a fixed-size output head preserves per-goal accuracy once |G| exceeds the Craftax scale used in experiments. This directly bears on whether the reported speedup and performance gains survive larger goal sets.
Authors: The LEO architecture produces identical per-goal value and policy outputs to naive relabelling by expanding the final layer to a joint head whose size scales linearly with |G|, while requiring only a single forward pass through the shared backbone. On the Craftax goal cardinalities tested, this yields performance matching or exceeding the relabelling baseline, indicating that any representational interference is not detrimental at those scales. We agree that an explicit capacity analysis for substantially larger |G| is absent from the current manuscript and will add a dedicated paragraph in §3 of the revision discussing output-head scaling and potential interference, together with a brief complexity argument. revision: partial
-
Referee: [§4] §4 (Experiments), Craftax and continuous-control tables: results are reported for a fixed goal cardinality; no ablation varies |G| or goal dimensionality while measuring value-error or policy degradation relative to the relabelling baseline. Without this, the claim that joint prediction incurs “no accuracy loss” remains untested at the scales where the computational advantage would matter most.
Authors: We acknowledge that the reported experiments use the fixed goal sets native to each environment and do not include an explicit sweep over |G|. The >250× wall-clock speedup arises precisely because forward-pass cost is independent of |G|, while relabelling cost grows linearly. To address the concern, we will add an appendix ablation that varies |G| on a controlled synthetic goal-conditioned task, reporting both value error and policy performance relative to the relabelling baseline. revision: yes
Circularity Check
No circularity: empirical engineering method with no self-referential derivations
full rationale
The paper describes LEO as a practical implementation of joint value/action heads for all-goals updates in goal-conditioned RL, with performance claims based on empirical results on Craftax and continuous control tasks. No equations, derivations, or load-bearing self-citations appear in the provided text that would reduce any claimed prediction or result to a fitted quantity or prior author work by construction. The approach is presented as an efficiency technique built on standard components, making the derivation chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Conference on robot learning , pages=
Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning , author=. Conference on robot learning , pages=. 2020 , organization=
2020
-
[2]
Advances in Neural Information Processing Systems , volume=
Multi-task reinforcement learning with soft modularization , author=. Advances in Neural Information Processing Systems , volume=
-
[3]
Journal of Artificial Intelligence Research , volume=
Reward machines: Exploiting reward function structure in reinforcement learning , author=. Journal of Artificial Intelligence Research , volume=
-
[4]
Advances in Neural Information Processing Systems , volume=
Learning one representation to optimize all rewards , author=. Advances in Neural Information Processing Systems , volume=
-
[5]
arXiv preprint arXiv:2504.11054 , year=
Zero-shot whole-body humanoid control via behavioral foundation models , author=. arXiv preprint arXiv:2504.11054 , year=
-
[6]
arXiv preprint arXiv:2310.00166 , year=
Motif: Intrinsic motivation from artificial intelligence feedback , author=. arXiv preprint arXiv:2310.00166 , year=
-
[7]
International Conference on Machine Learning , pages=
Cell-free latent go-explore , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[8]
Advances in Neural Information Processing Systems , volume=
Compositional automata embeddings for goal-conditioned reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[9]
International Conference on Machine Learning , pages=
Ltl2action: Generalizing ltl instructions for multi-task rl , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[10]
Intelligence, Physical and Amin, Ali and Aniceto, Raichelle and Balakrishna, Ashwin and Black, Kevin and Conley, Ken and Connors, Grace and Darpinian, James and Dhabalia, Karan and DiCarlo, Jared and others , journal=. ^*_
-
[11]
Gemini Robotics: Bringing AI into the Physical World
Gemini robotics: Bringing ai into the physical world , author=. arXiv preprint arXiv:2503.20020 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
OpenVLA: An Open-Source Vision-Language-Action Model
Openvla: An open-source vision-language-action model , author=. arXiv preprint arXiv:2406.09246 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
_0 : A Vision-Language-Action Flow Model for General Robot Control , author=. arXiv preprint arXiv:2410.24164 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Conference on Robot Learning , pages=
Rt-2: Vision-language-action models transfer web knowledge to robotic control , author=. Conference on Robot Learning , pages=. 2023 , organization=
2023
-
[15]
Advances in Neural Information Processing Systems , volume=
XLand-minigrid: Scalable meta-reinforcement learning environments in JAX , author=. Advances in Neural Information Processing Systems , volume=
-
[16]
arXiv preprint arXiv:2510.06288 , year=
BuilderBench--A benchmark for generalist agents , author=. arXiv preprint arXiv:2510.06288 , year=
-
[17]
2018 , Eprint =
Matthias Plappert and Marcin Andrychowicz and Alex Ray and Bob McGrew and Bowen Baker and Glenn Powell and Jonas Schneider and Josh Tobin and Maciek Chociej and Peter Welinder and Vikash Kumar and Wojciech Zaremba , Title =. 2018 , Eprint =
2018
-
[18]
Advances in Neural Information Processing Systems , volume=
Minigrid & miniworld: Modular & customizable reinforcement learning environments for goal-oriented tasks , author=. Advances in Neural Information Processing Systems , volume=
-
[19]
T., Coward, S., and Foerster, J
Kinetix: Investigating the training of general agents through open-ended physics-based control tasks , author=. arXiv preprint arXiv:2410.23208 , year=
-
[20]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Voyager: An open-ended embodied agent with large language models , author=. arXiv preprint arXiv:2305.16291 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Advances in Neural Information Processing Systems , volume=
Steve-1: A generative model for text-to-behavior in minecraft , author=. Advances in Neural Information Processing Systems , volume=
-
[22]
Advances in Neural Information Processing Systems , volume=
Minedojo: Building open-ended embodied agents with internet-scale knowledge , author=. Advances in Neural Information Processing Systems , volume=
-
[23]
arXiv preprint arXiv:1907.13440 , year=
Minerl: A large-scale dataset of minecraft demonstrations , author=. arXiv preprint arXiv:1907.13440 , year=
-
[24]
Behavioral Cloning from Observation
Behavioral cloning from observation , author=. arXiv preprint arXiv:1805.01954 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
AWAC: Accelerating Online Reinforcement Learning with Offline Datasets
Awac: Accelerating online reinforcement learning with offline datasets , author=. arXiv preprint arXiv:2006.09359 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[26]
arXiv preprint arXiv:2506.14045 , year=
Discovering Temporal Structure: An Overview of Hierarchical Reinforcement Learning , author=. arXiv preprint arXiv:2506.14045 , year=
-
[27]
Learning to Navigate in Complex Environments
Learning to navigate in complex environments , author=. arXiv preprint arXiv:1611.03673 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Hyperbolic Discounting and Learning over Multiple Horizons
Hyperbolic discounting and learning over multiple horizons , author=. arXiv preprint arXiv:1902.06865 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1902
-
[29]
Reinforcement Learning with Unsupervised Auxiliary Tasks
Reinforcement learning with unsupervised auxiliary tasks , author=. arXiv preprint arXiv:1611.05397 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Universal Successor Features Approximators
Universal successor features approximators , author=. arXiv preprint arXiv:1812.07626 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Advances in neural information processing systems , volume=
Successor features for transfer in reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[32]
Neural computation , volume=
Improving generalization for temporal difference learning: The successor representation , author=. Neural computation , volume=. 1993 , publisher=
1993
-
[33]
arXiv preprint arXiv:2207.11584 , year=
Hierarchical kickstarting for skill transfer in reinforcement learning , author=. arXiv preprint arXiv:2207.11584 , year=
-
[34]
Scalable Option Learning in High-Throughput Environments
Scalable Option Learning in High-Throughput Environments , author=. arXiv preprint arXiv:2509.00338 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
arXiv preprint arXiv:2309.00987 , year=
Sequential dexterity: Chaining dexterous policies for long-horizon manipulation , author=. arXiv preprint arXiv:2309.00987 , year=
-
[36]
Horizon reduction makes rl scalable.arXiv preprint arXiv:2506.04168, 2025
Horizon Reduction Makes RL Scalable , author=. arXiv preprint arXiv:2506.04168 , year=
-
[37]
arXiv preprint arXiv:2412.08542 , year=
Maestromotif: Skill design from artificial intelligence feedback , author=. arXiv preprint arXiv:2412.08542 , year=
-
[38]
International conference on machine learning , pages=
Feudal networks for hierarchical reinforcement learning , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[39]
Advances in neural information processing systems , volume=
Feudal reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[40]
Advances in Neural Information Processing Systems , volume=
Flexible option learning , author=. Advances in Neural Information Processing Systems , volume=
-
[41]
Proceedings of the AAAI conference on artificial intelligence , volume=
The option-critic architecture , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[42]
2000 , publisher=
Temporal abstraction in reinforcement learning , author=. 2000 , publisher=
2000
-
[43]
Artificial intelligence , volume=
Between MDPs and semi-MDPs: A framework for temporal abstraction in reinforcement learning , author=. Artificial intelligence , volume=. 1999 , publisher=
1999
-
[44]
arXiv preprint arXiv:2410.20092 , year=
Ogbench: Benchmarking offline goal-conditioned rl , author=. arXiv preprint arXiv:2410.20092 , year=
-
[45]
Advantage-Weighted Regression: Simple and Scalable Off-Policy Reinforcement Learning
Advantage-weighted regression: Simple and scalable off-policy reinforcement learning , author=. arXiv preprint arXiv:1910.00177 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[46]
Advances in Neural Information Processing Systems , volume=
Hiql: Offline goal-conditioned rl with latent states as actions , author=. Advances in Neural Information Processing Systems , volume=
-
[47]
arXiv preprint arXiv:1912.06088 , year=
Learning to reach goals via iterated supervised learning , author=. arXiv preprint arXiv:1912.06088 , year=
-
[48]
Conference on robot learning , pages=
Learning latent plans from play , author=. Conference on robot learning , pages=. 2020 , organization=
2020
-
[49]
arXiv preprint arXiv:2011.08909 , year=
C-learning: Learning to achieve goals via recursive classification , author=. arXiv preprint arXiv:2011.08909 , year=
-
[50]
International conference on machine learning , pages=
Addressing function approximation error in actor-critic methods , author=. International conference on machine learning , pages=. 2018 , organization=
2018
-
[51]
International conference on machine learning , pages=
Deterministic policy gradient algorithms , author=. International conference on machine learning , pages=. 2014 , organization=
2014
-
[52]
Continuous control with deep reinforcement learning
Continuous control with deep reinforcement learning , author=. arXiv preprint arXiv:1509.02971 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
Nature , volume=
First return, then explore , author=. Nature , volume=. 2021 , publisher=
2021
-
[54]
International conference on machine learning , pages=
Modular multitask reinforcement learning with policy sketches , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[55]
Playing Atari with Deep Reinforcement Learning
Playing atari with deep reinforcement learning , author=. arXiv preprint arXiv:1312.5602 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[56]
Machine learning , volume=
Q-learning , author=. Machine learning , volume=. 1992 , publisher=
1992
-
[57]
D4RL: Datasets for Deep Data-Driven Reinforcement Learning
D4rl: Datasets for deep data-driven reinforcement learning , author=. arXiv preprint arXiv:2004.07219 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[58]
Proceedings of the IEEE conference on Computer Vision and Pattern Recognition , pages=
Large-scale video classification with convolutional neural networks , author=. Proceedings of the IEEE conference on Computer Vision and Pattern Recognition , pages=
-
[59]
Many-Goals Reinforcement Learning
Many-goals reinforcement learning , author=. arXiv preprint arXiv:1806.09605 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[60]
Q-map: a convolutional approach for goal-oriented reinforcement learning , author=
-
[61]
Layer normalization , author=. arXiv preprint arXiv:1607.06450 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[62]
arXiv preprint arXiv:2408.11052 , year=
Accelerating goal-conditioned rl algorithms and research , author=. arXiv preprint arXiv:2408.11052 , year=
-
[63]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[64]
Advances in neural information processing systems , volume=
Visual reinforcement learning with imagined goals , author=. Advances in neural information processing systems , volume=
-
[65]
The 10th International Conference on Autonomous Agents and Multiagent Systems-Volume 2 , pages=
Horde: A scalable real-time architecture for learning knowledge from unsupervised sensorimotor interaction , author=. The 10th International Conference on Autonomous Agents and Multiagent Systems-Volume 2 , pages=
-
[66]
IJCAI , volume=
Learning to achieve goals , author=. IJCAI , volume=
-
[67]
Soft Actor-Critic Algorithms and Applications
Soft actor-critic algorithms and applications , author=. arXiv preprint arXiv:1812.05905 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[68]
Simplifying deep temporal difference learning , author=. arXiv preprint arXiv:2407.04811 , year=
-
[69]
Advances in Neural Information Processing Systems , volume=
Contrastive learning as goal-conditioned reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[70]
Advances in Neural Information Processing Systems , volume=
The nethack learning environment , author=. Advances in Neural Information Processing Systems , volume=
-
[71]
arXiv preprint arXiv:2109.06780 , year=
Benchmarking the spectrum of agent capabilities , author=. arXiv preprint arXiv:2109.06780 , year=
-
[72]
International conference on machine learning , pages=
Universal value function approximators , author=. International conference on machine learning , pages=. 2015 , organization=
2015
-
[73]
Advances in neural information processing systems , volume=
Hindsight experience replay , author=. Advances in neural information processing systems , volume=
-
[74]
International Conference on Machine Learning (
Michael Matthews and Michael Beukman and Benjamin Ellis and Mikayel Samvelyan and Matthew Jackson and Samuel Coward and Jakob Foerster , title =. International Conference on Machine Learning (
-
[75]
International conference on machine learning , pages=
Planning to explore via self-supervised world models , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[76]
arXiv preprint arXiv:2311.00344 , year=
A definition of open-ended learning problems for goal-conditioned agents , author=. arXiv preprint arXiv:2311.00344 , year=
-
[77]
Advances in Neural Information Processing Systems , volume=
Language as a cognitive tool to imagine goals in curiosity driven exploration , author=. Advances in Neural Information Processing Systems , volume=
-
[78]
CURIOUS: Intrinsically motivated multi-task multi-goal reinforcement learning , author=
-
[79]
Journal of Artificial Intelligence Research , volume=
Autotelic agents with intrinsically motivated goal-conditioned reinforcement learning: a short survey , author=. Journal of Artificial Intelligence Research , volume=
-
[80]
Advances in neural information processing systems , volume=
Randomized prior functions for deep reinforcement learning , author=. Advances in neural information processing systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.