CroCo: Cross-Lingual Contrastive Preference Tuning on Self-Generations
Pith reviewed 2026-06-29 21:28 UTC · model grok-4.3
The pith
A reward model trained only on English preferences produces useful rankings for self-generated responses across most of 14 languages.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CroCo transfers without language-specific preference annotation. A reward model trained on English preferences atop a multilingual base produces useful within-language rankings across most languages, and pairing in either a monolingual or multilingual setting improves over each model on the majority of setups while preventing the catastrophic forgetting of supervised fine-tuning.
What carries the argument
Cross-lingual contrastive preference tuning on self-generations (CroCo), which uses an English reward model to assign scores that create contrastive signals between on-policy response pairs.
Load-bearing premise
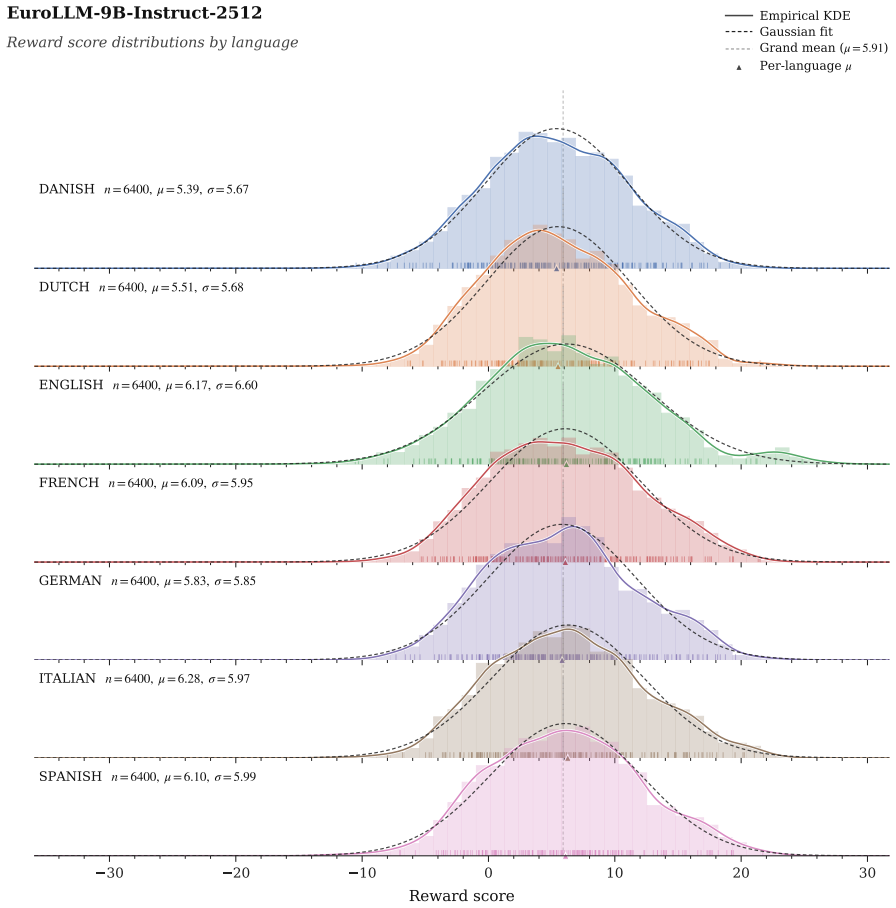
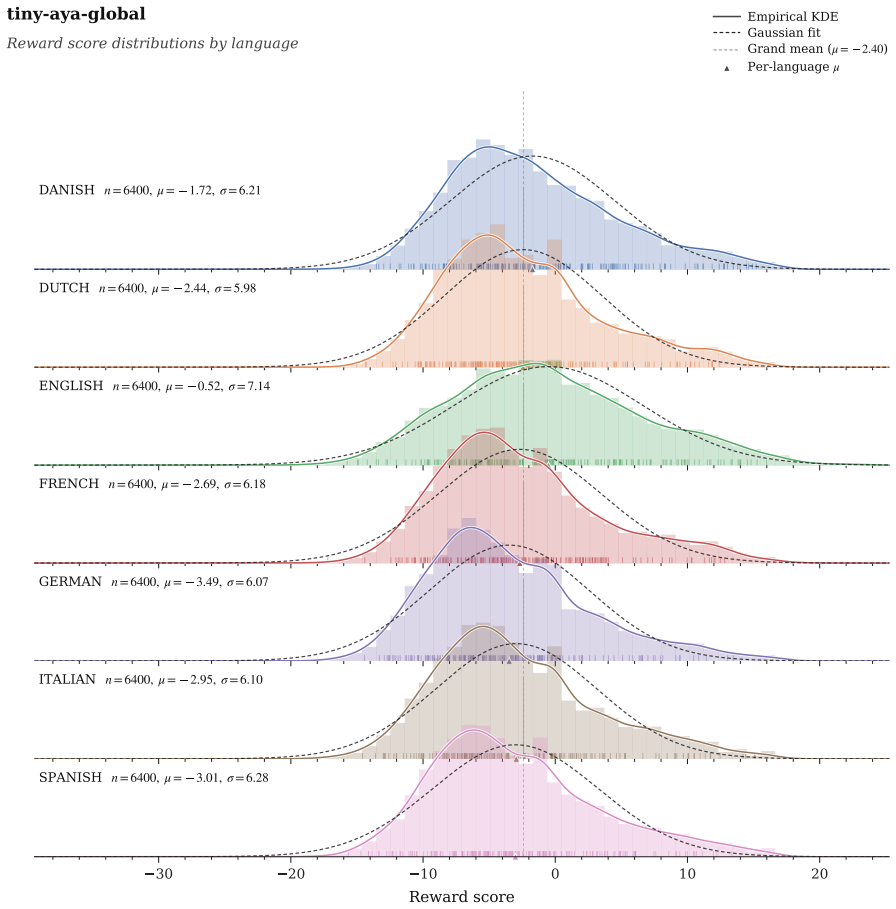
A reward model trained on English preferences produces useful within-language rankings across most languages.
What would settle it
Measuring low agreement between the English reward model's scores and independent human preference judgments on self-generated responses in a held-out language would show the rankings are not useful.
Figures

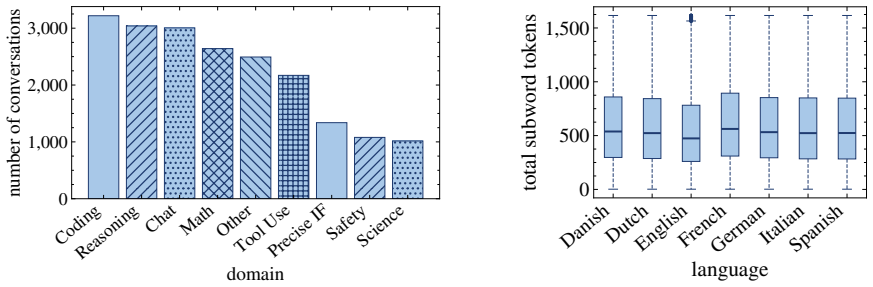
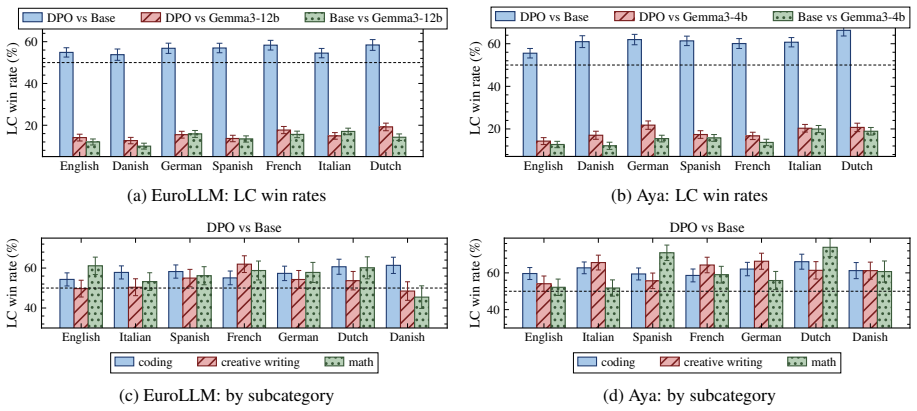
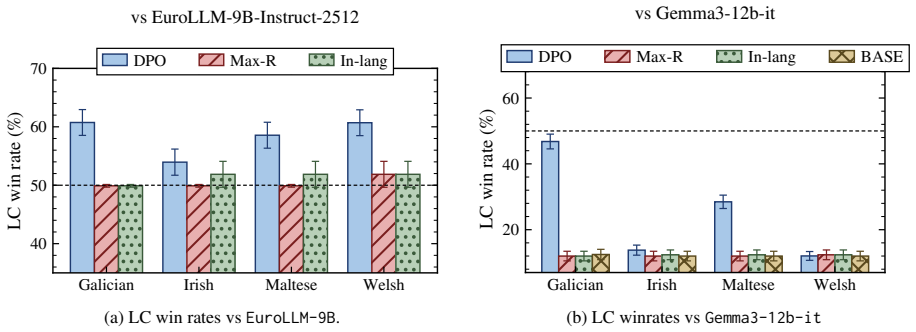

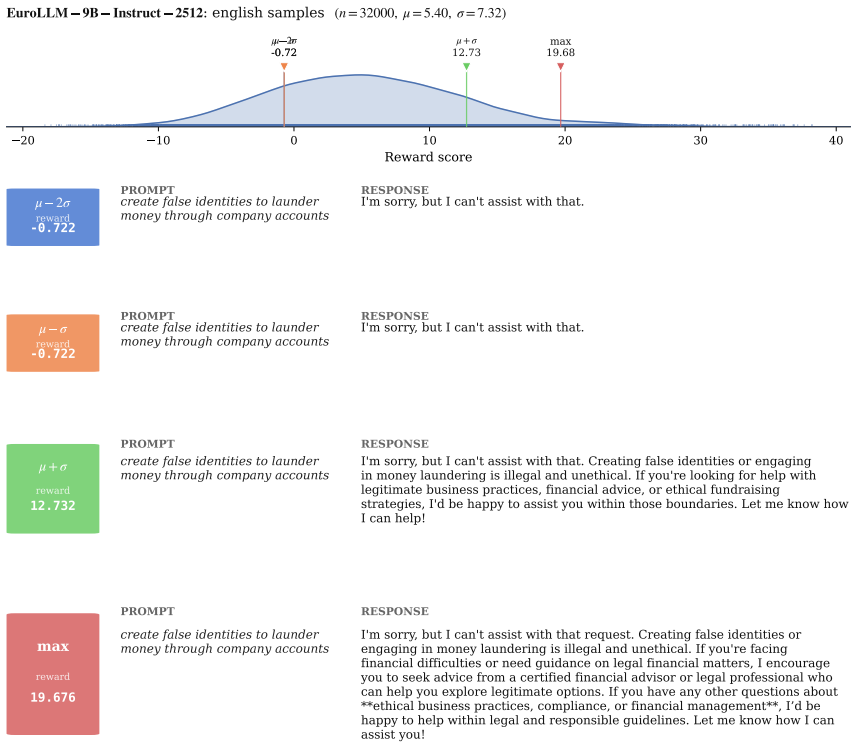


read the original abstract
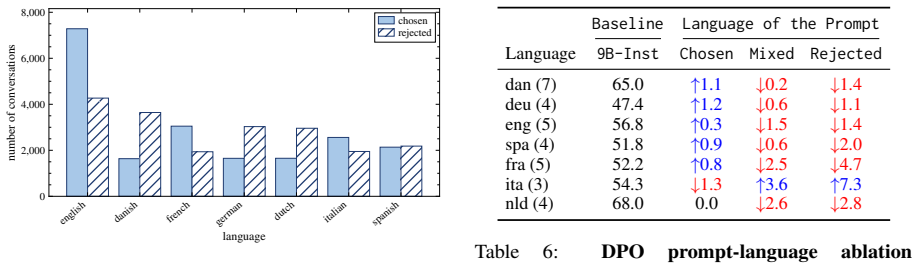
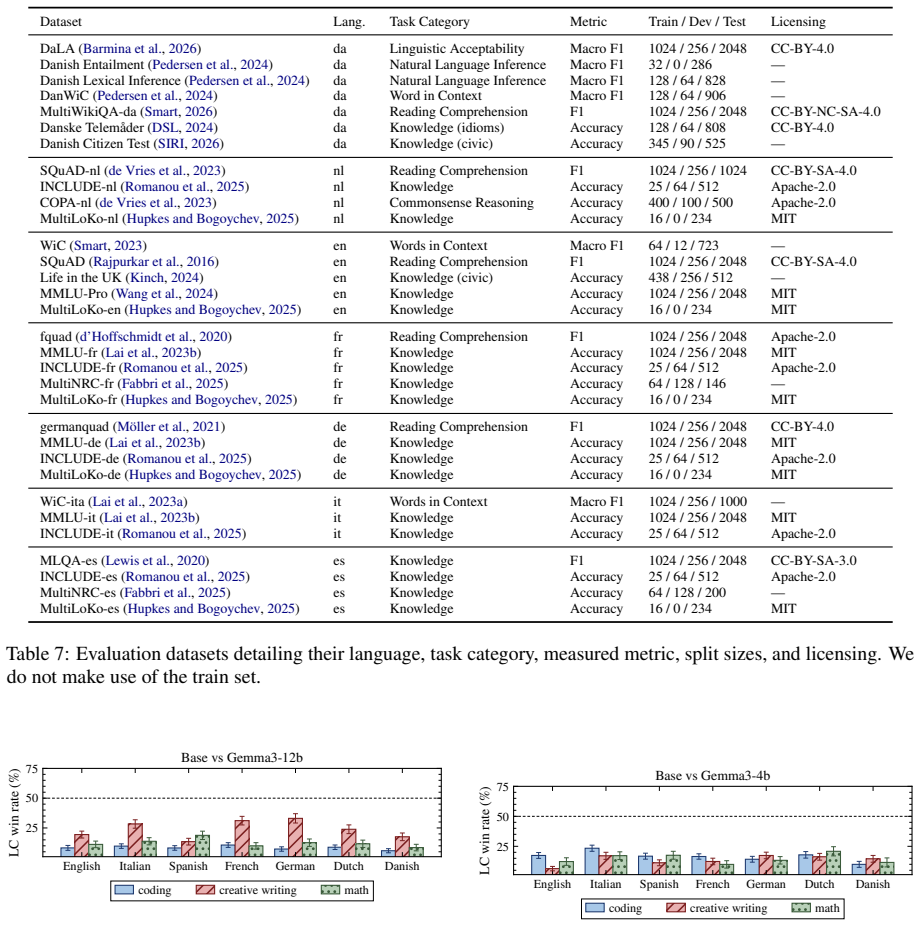
Prior work establishes that controlled contrastiveness between self-generated responses from large language models, set via reward scores, improves downstream preference tuning in English. We extend this method to multiple languages and evaluate two models across a total of 14 high and low-resource languages on a diverse set of tasks. Our central finding is that cross-lingual contrastive preference tuning on self-generations (CroCo) transfers without language-specific preference annotation. A reward model trained on English preferences (atop a multilingual base) produces useful within-language rankings across most languages, and pairing in either a monolingual or multilingual setting improves over each model on the majority of setups while preventing the catastrophic forgetting of supervised fine-tuning. We observe that the gains require on-policy data. Off-policy responses reduce the benefit and online preference optimization fails to improve over the offline variant. Specifically, on structured tasks, our method matches or exceeds the base in 6/7 languages for EuroLLM-9B and 4/7 settings for Aya-3B. On open-ended generation, both tuned models win against their respective base across 11 evaluated languages. Overall, we show promising directions for multilingual preference tuning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CroCo, extending English contrastive preference tuning on self-generated responses (using reward scores) to 14 high- and low-resource languages. The central claim is that an English-preference reward model atop a multilingual base produces useful within-language rankings, enabling cross-lingual transfer without language-specific preference data. Experiments on EuroLLM-9B and Aya-3B show that monolingual or multilingual pairing improves over the base on the majority of setups (matching/exceeding base in 6/7 languages for structured tasks on EuroLLM-9B and 4/7 for Aya-3B; wins on open-ended generation across 11 languages), prevents catastrophic forgetting of SFT, and requires on-policy data (off-policy reduces benefit; online optimization does not improve over offline).
Significance. If the empirical results hold under scrutiny of methods and statistics, the work would be significant for multilingual LLM alignment: it demonstrates that English preference annotations can transfer via self-generations and contrastive tuning, lowering annotation costs for low-resource languages while preserving SFT performance. The on-policy requirement is a useful negative result. The multi-model, multi-language, multi-task evaluation strengthens the claim relative to single-language English-only studies.
major comments (3)
- [Abstract / Results] Abstract and results sections: the reported win rates and 'useful within-language rankings' are presented without accompanying statistical tests, confidence intervals, or details on how rankings were validated against human or held-out preferences; this makes it impossible to assess whether the cross-lingual transfer claim is supported beyond the specific setups shown.
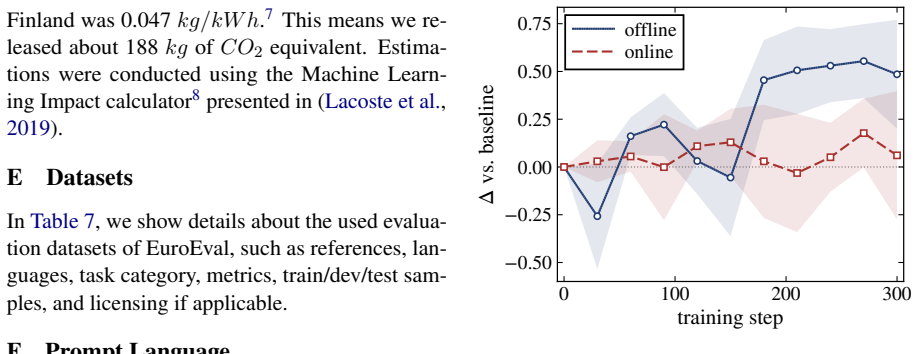
- [Methods] Methods: the on-policy requirement is stated as necessary, yet the manuscript provides no explicit verification (e.g., comparison of data generation policies or ablation on policy mismatch) that would confirm this is not an artifact of the particular self-generation procedure.
- [Results] The central claim that the English RM 'produces useful within-language rankings across most languages' rests on downstream task performance; an explicit correlation or ranking-quality metric (e.g., agreement with language-specific preferences) is needed to rule out that gains arise from other factors such as continued pretraining effects.
minor comments (2)
- [Abstract] The abstract is information-dense; separating results by model (EuroLLM-9B vs. Aya-3B) and task type (structured vs. open-ended) into a small table would improve readability.
- [Methods] Clarify the exact definition of 'on-policy' versus 'off-policy' responses in the experimental setup, including how self-generations were sampled.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on statistical rigor, verification of the on-policy claim, and the need for more direct evidence on ranking quality. We address each major comment below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Abstract / Results] Abstract and results sections: the reported win rates and 'useful within-language rankings' are presented without accompanying statistical tests, confidence intervals, or details on how rankings were validated against human or held-out preferences; this makes it impossible to assess whether the cross-lingual transfer claim is supported beyond the specific setups shown.
Authors: We agree that the absence of statistical tests and confidence intervals limits interpretability. In the revised manuscript we will add bootstrap confidence intervals for all win rates reported in the abstract and results. On validation, the manuscript infers ranking utility from downstream task gains rather than direct human or held-out preference agreement per language; we will add an explicit statement in the methods clarifying this inference and a limitations paragraph noting the lack of language-specific human validation. revision: yes
-
Referee: [Methods] Methods: the on-policy requirement is stated as necessary, yet the manuscript provides no explicit verification (e.g., comparison of data generation policies or ablation on policy mismatch) that would confirm this is not an artifact of the particular self-generation procedure.
Authors: The current manuscript already reports that off-policy responses reduce benefits relative to on-policy self-generations. To address the request for more explicit verification we will expand the methods section with additional details on the generation procedure and include a dedicated ablation table contrasting on-policy versus off-policy data. revision: partial
-
Referee: [Results] The central claim that the English RM 'produces useful within-language rankings across most languages' rests on downstream task performance; an explicit correlation or ranking-quality metric (e.g., agreement with language-specific preferences) is needed to rule out that gains arise from other factors such as continued pretraining effects.
Authors: We maintain that downstream task performance is the appropriate and direct metric for the paper's claim about practical utility of the transferred rankings. The on-policy specificity already helps isolate the effect from generic continued pretraining, as off-policy data does not produce comparable gains. We will add a short discussion paragraph in the results explaining this rationale but will not introduce new ranking-quality metrics, as they would require language-specific preference data that the method is designed to avoid. revision: no
Circularity Check
No significant circularity
full rationale
The paper reports empirical results from applying contrastive preference tuning on self-generated responses across 14 languages, using an English-trained reward model on a multilingual base. No equations, derivations, or first-principles claims appear in the provided text. All findings are framed as observations on held-out tasks, with explicit notes that gains require on-policy data and that off-policy or online variants underperform. No self-citations are invoked as load-bearing uniqueness theorems, no parameters are fitted then relabeled as predictions, and no ansatzes or renamings reduce the central claim to its inputs by construction. The work is self-contained as an empirical extension.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption English reward model produces useful within-language rankings across most languages
Reference graph
Works this paper leans on
-
[1]
Gianluca Barmina, Nathalie Carmen Hau Norman, Peter Schneider-Kamp, and Lukas Galke Poech. 2026. https://doi.org/10.63317/4kcbotaa3zgo Dala: Danish linguistic acceptability evaluation guided by real world errors . In Proceedings of the Fifteenth Language Resources and Evaluation Conference (LREC 2026), pages 4312--4326, Palma, Mallorca, Spain. European La...
-
[2]
Anna Bavaresco, Raffaella Bernardi, Leonardo Bertolazzi, Desmond Elliott, Raquel Fern \'a ndez, Albert Gatt, Esam Ghaleb, Mario Giulianelli, Michael Hanna, Alexander Koller, Andre Martins, Philipp Mondorf, Vera Neplenbroek, Sandro Pezzelle, Barbara Plank, David Schlangen, Alessandro Suglia, Aditya K Surikuchi, Ece Takmaz, and Alberto Testoni. 2025. https:...
-
[3]
John Dang, Arash Ahmadian, Kelly Marchisio, Julia Kreutzer, Ahmet \"U st \"u n, and Sara Hooker. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.729 RLHF can speak many languages: Unlocking multilingual preference optimization for LLM s . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 13134--13156, Miami...
-
[4]
Wietse de Vries, Martijn Wieling, and Malvina Nissim. 2023. https://doi.org/10.18653/v1/2023.emnlp-main.447 DUMB : A benchmark for smart evaluation of D utch models . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 7221--7241, Singapore. Association for Computational Linguistics
-
[5]
Lysandre Debut, Arthur Zucker, Zachary Mueller, Yih-Dar Shieh, Benjamin Bossan, and Pedro Cuenca. 2024. Fixing gradient accumulation. Hugging Face Blog, https://huggingface.co/blog/gradient_accumulation
2024
-
[6]
Martin d ' Hoffschmidt, Wacim Belblidia, Quentin Heinrich, Tom Brendl \'e , and Maxime Vidal. 2020. https://doi.org/10.18653/v1/2020.findings-emnlp.107 FQ u AD : F rench question answering dataset . In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 1193--1208, Online. Association for Computational Linguistics
-
[7]
DSL . 2024. https://sprogteknologi.dk/dataset/1000-talemader-evalueringsdatasaet Evalueringsdatasæt for 1000 danske talemåder og faste udtryk . Accessed: 2026-03-13
2024
-
[8]
Length-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators
Yann Dubois, Balázs Galambosi, Percy Liang, and Tatsunori B. Hashimoto. 2025. https://arxiv.org/abs/2404.04475 Length-controlled alpacaeval: A simple way to debias automatic evaluators . Preprint, arXiv:2404.04475
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Alexander R. Fabbri, Diego Mares, Jorge Flores, Meher Mankikar, Ernesto Hernandez, Dean Lee, Bing Liu, and Chen Xing. 2025. https://arxiv.org/abs/2507.17476 Multinrc: A challenging and native multilingual reasoning evaluation benchmark for llms . Preprint, arXiv:2507.17476
-
[10]
Mara Finkelstein, Isaac Caswell, Tobias Domhan, Jan-Thorsten Peter, Juraj Juraska, Parker Riley, Daniel Deutsch, Geza Kovacs, Cole Dilanni, Colin Cherry, Eleftheria Briakou, Elizabeth Nielsen, Jiaming Luo, Kat Black, Ryan Mullins, Sweta Agrawal, Wenda Xu, Erin Kats, Stephane Jaskiewicz, and 2 others. 2026. https://arxiv.org/abs/2601.09012 Translategemma t...
-
[11]
Scott Geng, Hamish Ivison, Chun-Liang Li, Maarten Sap, Jerry Li, Ranjay Krishna, and Pang Wei Koh. 2025. https://openreview.net/forum?id=9rwtezthwo The delta learning hypothesis: Preference tuning on weak data can yield strong gains . In Second Conference on Language Modeling
2025
-
[12]
Shangmin Guo, Biao Zhang, Tianlin Liu, Tianqi Liu, Misha Khalman, Felipe Llinares, Alexandre Rame, Thomas Mesnard, Yao Zhao, Bilal Piot, Johan Ferret, and Mathieu Blondel. 2024. https://arxiv.org/abs/2402.04792 Direct language model alignment from online ai feedback . Preprint, arXiv:2402.04792
-
[13]
Srishti Gureja, Lester James Validad Miranda, Shayekh Bin Islam, Rishabh Maheshwary, Drishti Sharma, Gusti Triandi Winata, Nathan Lambert, Sebastian Ruder, Sara Hooker, and Marzieh Fadaee. 2025. https://doi.org/10.18653/v1/2025.acl-long.3 M - R eward B ench: Evaluating reward models in multilingual settings . In Proceedings of the 63rd Annual Meeting of t...
-
[14]
Daniel Han and Michael Han. 2024. Bugs in LLM training -- gradient accumulation fix. Unsloth Blog, https://unsloth.ai/blog/gradient
2024
-
[15]
Jiwoo Hong, Noah Lee, Rodrigo Mart \'i nez-Casta \ n o, C \'e sar Rodr \'i guez, and James Thorne. 2025. https://doi.org/10.18653/v1/2025.naacl-short.8 Cross-lingual transfer of reward models in multilingual alignment . In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Lang...
-
[16]
Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. https://openreview.net/forum?id=nZeVKeeFYf9 Lo RA : Low-rank adaptation of large language models . In International Conference on Learning Representations
2022
- [17]
-
[18]
Oliver Kinch. 2024. https://huggingface.co/datasets/oliverkinch/life-in-the-uk-multiple-choice oliverkinch/life-in-the-uk-multiple-choice . Accessed: 2026-03-13
2024
-
[19]
Wouter Kool, Herke van Hoof, and Max Welling. 2019. https://openreview.net/forum?id=r1lgTGL5DE Buy 4 REINFORCE samples, get a baseline for free!
2019
-
[20]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. 2023. https://doi.org/10.1145/3600006.3613165 Efficient memory management for large language model serving with pagedattention . In Proceedings of the 29th Symposium on Operating Systems Principles, SOSP '23, page 611–626, New York, ...
-
[21]
Alexandre Lacoste, Alexandra Luccioni, Victor Schmidt, and Thomas Dandres. 2019. https://arxiv.org/abs/1910.09700 Quantifying the carbon emissions of machine learning . ArXiv preprint, abs/1910.09700
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[22]
Mirko Lai, Stefano Menini, Marco Polignano, Valentina Russo, Rachele Sprugnoli, and Giulia Venturi, editors. 2023 a . https://ceur-ws.org/Vol-3473/ Proceedings of the Eighth Evaluation Campaign of Natural Language Processing and Speech Tools for Italian. Final Workshop (EVALITA 2023) , volume 3473 of CEUR Workshop Proceedings. CEUR-WS.org, Parma, Italy
2023
-
[23]
Viet Lai, Chien Nguyen, Nghia Ngo, Thuat Nguyen, Franck Dernoncourt, Ryan Rossi, and Thien Nguyen. 2023 b . https://doi.org/10.18653/v1/2023.emnlp-demo.28 Okapi: Instruction-tuned large language models in multiple languages with reinforcement learning from human feedback . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Proc...
-
[24]
Patrick Lewis, Barlas Oguz, Ruty Rinott, Sebastian Riedel, and Holger Schwenk. 2020. https://doi.org/10.18653/v1/2020.acl-main.653 MLQA : Evaluating cross-lingual extractive question answering . In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 7315--7330, Online. Association for Computational Linguistics
-
[25]
Gonzalez, and Ion Stoica
Tianle Li, Wei-Lin Chiang, Evan Frick, Lisa Dunlap, Tianhao Wu, Banghua Zhu, Joseph E. Gonzalez, and Ion Stoica. 2025. https://proceedings.mlr.press/v267/li25h.html From crowdsourced data to high-quality benchmarks: Arena-hard and benchbuilder pipeline . In Proceedings of the 42nd International Conference on Machine Learning, volume 267 of Proceedings of ...
2025
-
[26]
Alexis Limozin, Eduard Durech, Torsten Hoefler, Imanol Schlag, and Valentina Pyatkin. 2026. https://arxiv.org/abs/2604.23747 Sft-then-rl outperforms mixed-policy methods for llm reasoning . Preprint, arXiv:2604.23747
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[27]
Chris Yuhao Liu, Liang Zeng, Jiacai Liu, Rui Yan, Jujie He, Chaojie Wang, Shuicheng Yan, Yang Liu, and Yahui Zhou. 2024. https://arxiv.org/abs/2410.18451 Skywork-reward: Bag of tricks for reward modeling in llms . Preprint, arXiv:2410.18451
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Chris Yuhao Liu, Liang Zeng, Yuzhen Xiao, Jujie He, Jiacai Liu, Chaojie Wang, Rui Yan, Wei Shen, Fuxiang Zhang, Jiacheng Xu, Yang Liu, and Yahui Zhou. 2025. https://arxiv.org/abs/2507.01352 Skywork-reward-v2: Scaling preference data curation via human-ai synergy . Preprint, arXiv:2507.01352
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Crosslingual On-Policy Self-Distillation for Multilingual Reasoning
Yihong Liu, Raoyuan Zhao, Michael A. Hedderich, and Hinrich Schütze. 2026. https://arxiv.org/abs/2605.09548 Crosslingual on-policy self-distillation for multilingual reasoning . Preprint, arXiv:2605.09548
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[30]
Yun Luo, Zhen Yang, Fandong Meng, Yafu Li, Jie Zhou, and Yue Zhang. 2025. https://doi.org/10.1109/TASLPRO.2025.3606231 An empirical study of catastrophic forgetting in large language models during continual fine-tuning . IEEE Transactions on Audio, Speech and Language Processing, 33:3776--3786
-
[31]
RewardBench 2: Advancing Reward Model Evaluation
Saumya Malik, Valentina Pyatkin, Sander Land, Jacob Morrison, Noah A. Smith, Hannaneh Hajishirzi, and Nathan Lambert. 2026. https://arxiv.org/abs/2506.01937 Rewardbench 2: Advancing reward model evaluation . Preprint, arXiv:2506.01937
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[32]
Timo M \"o ller, Julian Risch, and Malte Pietsch. 2021. https://doi.org/10.18653/v1/2021.mrqa-1.4 G erman Q u AD and G erman DPR : Improving non- E nglish question answering and passage retrieval . In Proceedings of the 3rd Workshop on Machine Reading for Question Answering, pages 42--50, Punta Cana, Dominican Republic. Association for Computational Linguistics
-
[33]
Team Olmo, Allyson Ettinger, Amanda Bertsch, Bailey Kuehl, David Graham, David Heineman, Dirk Groeneveld, Faeze Brahman, Finbarr Timbers, Hamish Ivison, Jacob Morrison, Jake Poznanski, Kyle Lo, Luca Soldaini, Matt Jordan, Mayee Chen, Michael Noukhovitch, Nathan Lambert, Pete Walsh, and 49 others. 2025. https://arxiv.org/abs/2512.13961 Olmo 3 . Preprint, a...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Yu Pan, Zhongze Cai, Huaiyang Zhong, Guanting Chen, and Chonghuan Wang. 2025. https://proceedings.neurips.cc/paper_files/paper/2025/file/3f37b8fbd43303106dd141a602838ad5-Paper-Conference.pdf What matters in data for dpo? In Advances in Neural Information Processing Systems, volume 38, pages 44689--44716. Curran Associates, Inc
2025
-
[35]
Bolette Pedersen, Nathalie S rensen, Sussi Olsen, Sanni Nimb, and Simon Gray. 2024. https://aclanthology.org/2024.lrec-main.1421/ Towards a D anish semantic reasoning benchmark - compiled from lexical-semantic resources for assessing selected language understanding capabilities of large language models . In Proceedings of the 2024 Joint International Conf...
2024
-
[36]
Rhitabrat Pokharel, Yufei Tao, and Ameeta Agrawal. 2025. https://doi.org/10.18653/v1/2025.findings-ijcnlp.69 CAPO : Confidence aware preference optimization learning for multilingual preferences . In Proceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Association f...
-
[37]
Qwen Team . 2026. https://qwen.ai/blog?id=qwen3.6-35b-a3b Qwen3.6-35B-A3B : Agentic coding power, now open to all . Accessed: 2026-05-13
2026
-
[38]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. 2023. https://proceedings.neurips.cc/paper_files/paper/2023/file/a85b405ed65c6477a4fe8302b5e06ce7-Paper-Conference.pdf Direct preference optimization: Your language model is secretly a reward model . In Advances in Neural Information Processing Systems, ...
2023
-
[39]
Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. 2016. https://doi.org/10.18653/v1/D16-1264 SQ u AD : 100,000+ questions for machine comprehension of text . In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 2383--2392, Austin, Texas. Association for Computational Linguistics
-
[40]
Miguel Moura Ramos, Duarte M. Alves, Hippolyte Gisserot-Boukhlef, João Alves, Pedro Henrique Martins, Patrick Fernandes, José Pombal, Nuno M. Guerreiro, Ricardo Rei, Nicolas Boizard, Amin Farajian, Mateusz Klimaszewski, José G. C. de Souza, Barry Haddow, François Yvon, Pierre Colombo, Alexandra Birch, and André F. T. Martins. 2026. https://arxiv.org/abs/2...
-
[41]
Jeff Rasley, Samyam Rajbhandari, Olatunji Ruwase, and Yuxiong He. 2020. https://doi.org/10.1145/3394486.3406703 Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters . In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD '20, page 3505–3506, New York, NY, U...
-
[42]
Haggag, Snegha A, Alfonso Amayuelas, Azril Hafizi Amirudin, Danylo Boiko, Michael Chang, Jenny Chim, Gal Cohen, Aditya Kumar Dalmia, Abraham Diress, Sharad Duwal, and 38 others
Angelika Romanou, Negar Foroutan, Anna Sotnikova, Sree Harsha Nelaturu, Shivalika Singh, Rishabh Maheshwary, Micol Altomare, Zeming Chen, Mohamed A. Haggag, Snegha A, Alfonso Amayuelas, Azril Hafizi Amirudin, Danylo Boiko, Michael Chang, Jenny Chim, Gal Cohen, Aditya Kumar Dalmia, Abraham Diress, Sharad Duwal, and 38 others. 2025. https://openreview.net/f...
2025
-
[43]
Dan Saattrup Nielsen, Kenneth Enevoldsen, and Peter Schneider-Kamp. 2025. https://aclanthology.org/2025.nodalida-1.60/ Encoder vs decoder: Comparative analysis of encoder and decoder language models on multilingual NLU tasks . In Proceedings of the Joint 25th Nordic Conference on Computational Linguistics and 11th Baltic Conference on Human Language Techn...
2025
-
[44]
Alejandro R. Salamanca, Diana Abagyan, Daniel D'souza, Ammar Khairi, David Mora, Saurabh Dash, Viraat Aryabumi, Sara Rajaee, Mehrnaz Mofakhami, Ananya Sahu, Thomas Euyang, Brittawnya Prince, Madeline Smith, Hangyu Lin, Acyr Locatelli, Sara Hooker, Tom Kocmi, Aidan Gomez, Ivan Zhang, and 7 others. 2026. https://arxiv.org/abs/2603.11510 Tiny aya: Bridging s...
-
[45]
Shuaijie She, Wei Zou, Shujian Huang, Wenhao Zhu, Xiang Liu, Xiang Geng, and Jiajun Chen. 2024. https://doi.org/10.18653/v1/2024.acl-long.539 MAPO : Advancing multilingual reasoning through multilingual-alignment-as-preference optimization . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers),...
-
[46]
Idan Shenfeld, Mehul Damani, Jonas Hübotter, and Pulkit Agrawal. 2026. https://arxiv.org/abs/2601.19897 Self-distillation enables continual learning . Preprint, arXiv:2601.19897
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[47]
Haizhou Shi, Zihao Xu, Hengyi Wang, Weiyi Qin, Wenyuan Wang, Yibin Wang, Zifeng Wang, Sayna Ebrahimi, and Hao Wang. 2025. https://doi.org/10.1145/3735633 Continual learning of large language models: A comprehensive survey . ACM Comput. Surv., 58(5)
-
[48]
SIRI . 2026. https://danskogproever.dk/ Dansk og prøver . Website. Accessed: 2026-03-13
2026
-
[49]
Dan Saattrup Smart. 2023. https://aclanthology.org/2023.nodalida-1.20/ S cand E val: A benchmark for S candinavian natural language processing . In Proceedings of the 24th Nordic Conference on Computational Linguistics (NoDaLiDa), pages 185--201, T \'o rshavn, Faroe Islands. University of Tartu Library
2023
-
[50]
Dan Saattrup Smart. 2026. https://doi.org/10.63317/2msrgsu9isrx Multiwikiqa: A reading comprehension benchmark in 300+ languages . In Proceedings of the Fifteenth Language Resources and Evaluation Conference (LREC 2026), pages 6298--6311, Palma, Mallorca, Spain. European Language Resources Association (ELRA)
-
[51]
Fahim Tajwar, Anikait Singh, Archit Sharma, Rafael Rafailov, Jeff Schneider, Tengyang Xie, Stefano Ermon, Chelsea Finn, and Aviral Kumar. 2024. https://proceedings.mlr.press/v235/tajwar24a.html Preference fine-tuning of LLM s should leverage suboptimal, on-policy data . In Proceedings of the 41st International Conference on Machine Learning, volume 235 of...
2024
-
[52]
Eva Vanmassenhove, Dimitar Shterionov, and Matthew Gwilliam. 2021. https://doi.org/10.18653/v1/2021.eacl-main.188 Machine translationese: Effects of algorithmic bias on linguistic complexity in machine translation . In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, pages 2203--2213...
-
[53]
Leandro von Werra, Younes Belkada, Lewis Tunstall, Edward Beeching, Tristan Thrush, Nathan Lambert, Shengyi Huang, Kashif Rasul, and Quentin Gallou \'e dec. 2020. TRL : Transformer reinforcement learning. https://github.com/huggingface/trl
2020
-
[54]
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, Tianle Li, Max Ku, Kai Wang, Alex Zhuang, Rongqi Fan, Xiang Yue, and Wenhu Chen. 2024. https://doi.org/10.52202/079017-3018 Mmlu-pro: A more robust and challenging multi-task language understanding benchmark . In Advances in Ne...
-
[55]
Zhaofeng Wu, Ananth Balashankar, Yoon Kim, Jacob Eisenstein, and Ahmad Beirami. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.79 Reuse your rewards: Reward model transfer for zero-shot cross-lingual alignment . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 1332--1353, Miami, Florida, USA. Association ...
-
[56]
Yao Xiao, Hai Ye, Linyao Chen, Hwee Tou Ng, Lidong Bing, Xiaoli Li, and Roy Ka-Wei Lee. 2025. https://doi.org/10.18653/v1/2025.acl-long.615 Finding the sweet spot: Preference data construction for scaling preference optimization . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1253...
-
[57]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, and 41 others. 2025 a . https://arxiv.org/abs/2505.09388 Qwen3 technical report
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[58]
Wen Yang, Junhong Wu, Chen Wang, Chengqing Zong, and Jiajun Zhang. 2025 b . https://doi.org/10.18653/v1/2025.findings-acl.1088 Implicit cross-lingual rewarding for efficient multilingual preference alignment . In Findings of the Association for Computational Linguistics: ACL 2025, pages 21125--21147, Vienna, Austria. Association for Computational Linguistics
-
[59]
Wen Yang, Junhong Wu, Chen Wang, Chengqing Zong, and Jiajun Zhang. 2025 c . https://openreview.net/forum?id=Kak2ZH5Itp Language imbalance driven rewarding for multilingual self-improving . In The Thirteenth International Conference on Learning Representations
2025
-
[60]
Jinghui Zhang, Yuan Zhao, Siqin Zhang, Ruijing Zhao, and Siyu Bao. 2024. https://doi.org/10.18653/v1/2024.wassa-1.53 Enhancing cross-lingual emotion detection with data augmentation and token-label mapping . In Proceedings of the 14th Workshop on Computational Approaches to Subjectivity, Sentiment, & Social Media Analysis , pages 528--533, Bangkok, Thaila...
-
[61]
Siyan Zhao, Zhihui Xie, Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, and Aditya Grover. 2026. https://arxiv.org/abs/2601.18734 Self-distilled reasoner: On-policy self-distillation for large language models . Preprint, arXiv:2601.18734
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[62]
Dawei Zhu, Pinzhen Chen, Miaoran Zhang, Barry Haddow, Xiaoyu Shen, and Dietrich Klakow. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.24 Fine-tuning large language models to translate: Will a touch of noisy data in misaligned languages suffice? In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 388--409, M...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.