Riding the Shifting Potential: When Reactive Control Suffices for Multi-Goal Behavior
Pith reviewed 2026-06-29 17:13 UTC · model grok-4.3
The pith
Reactive control suffices for multi-goal behavior when objective conflicts are resolved dynamically via nullspace projections in a graph-based model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Extending the graph-based world model with nullspace projections resolves conflicts where they arise by projecting lower-priority gradients into the nullspace of higher-priority ones, with priorities determined continuously from the current state, enabling reactive control to succeed in domains with central conflicts like non-convex navigation and planar pushing.
What carries the argument
Nullspace projections applied to gradients in the graph-based world model, using state-dependent priorities to handle objective interactions.
If this is right
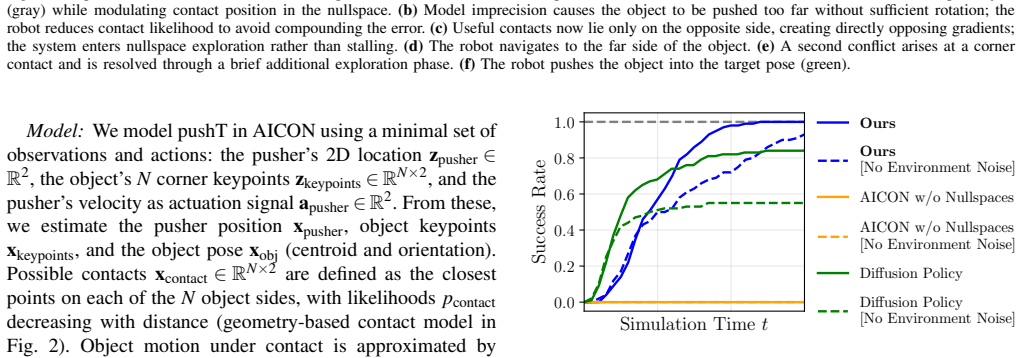
- 100% success rate across 100 configurations in planar pushing, compared to 0% for steepest-descent and about 55% for diffusion policy.
- Direct transfer to a real robot incorporating perceptual and kinematic constraints through the same mechanism.
- Successful navigation around non-convex obstacles where static potential fields fail.
Where Pith is reading between the lines
- Similar dynamic resolution could apply to other reactive control settings with multiple objectives, such as in legged locomotion.
- Reducing reliance on learned policies for tasks where structure can be modeled explicitly.
- The approach might scale to higher-dimensional problems if the graph model can be maintained efficiently.
Load-bearing premise
The graph-based world model correctly encodes the current interactions between objectives so that priorities can be set accurately.
What would settle it
A test case where the method gets stuck in a local minimum despite the graph accurately modeling objective interactions, or a configuration where priorities lead to failure.
Figures


read the original abstract
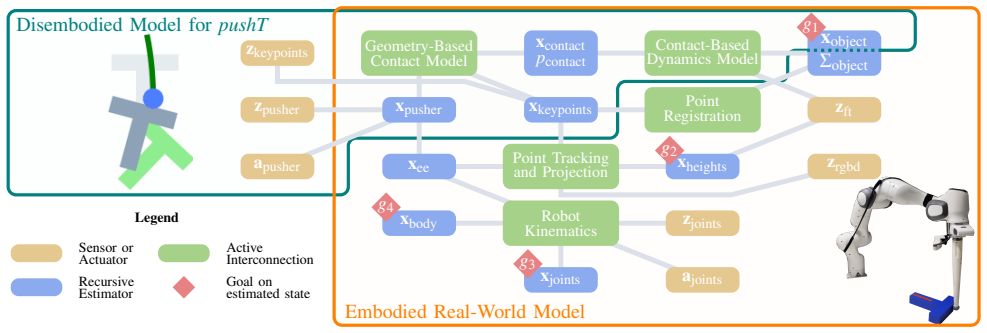
Reactive control is often considered insufficient for multi-objective tasks because conflicting objectives give rise to local minima. We argue this limitation is not inherent but arises from static encodings that fail to reflect how objectives currently interact. We exploit the interaction structure encoded in a graph-based world model by extending it with nullspace projections: conflicts are resolved where they arise by projecting lower-priority gradients into the nullspace of higher-priority ones, with priorities determined continuously from the current state. We demonstrate this in two domains where conflicts between objectives are central: navigation around non-convex obstacles, where static potential fields fundamentally fail, and planar pushing of non-convex objects, where our method achieves $100\%$ success across one-hundred configurations versus $0\%$ for the steepest-descent baseline and ${\sim}55\%$ for diffusion policy, without demonstrations or retraining. The same formulation transfers directly to a real robot with additional perceptual and kinematic constraints, accommodating them through the same mechanism.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that limitations of reactive control for multi-goal tasks arise from static encodings rather than being inherent, and proposes extending a graph-based world model with nullspace projections to resolve objective conflicts dynamically: lower-priority gradients are projected into the nullspace of higher-priority ones, with priorities set continuously from the current state. It reports 100% success over 100 planar pushing configurations (vs. 0% for steepest-descent and ~55% for diffusion policy) without demonstrations or retraining, plus direct transfer to a real robot handling additional perceptual and kinematic constraints.
Significance. If the central mechanism holds and generalizes, the result would be significant for robotics control: it would show that reactive methods can suffice for tasks previously thought to require planning or learning when objective interactions are explicitly modeled, offering a lightweight, demonstration-free alternative with potential for real-time execution under constraints.
major comments (2)
- [Abstract] Abstract: the 100% success claim over 100 configurations is load-bearing for the central thesis, yet the manuscript provides no protocol details on graph construction (hand-specified per domain vs. derived), configuration sampling, or failure modes; if the graph must be supplied with accurate interaction structure, the method reduces to standard nullspace control whose performance depends on manual modeling rather than the claimed dynamic resolution.
- [Abstract] Abstract (real-robot transfer paragraph): the claim that the formulation 'transfers directly' with additional constraints accommodated 'through the same mechanism' is central to generality, but lacks quantitative metrics, success rates, or comparison to baselines on the physical system; without these, the transfer does not yet substantiate that the graph-plus-nullspace approach scales beyond simulation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting areas where additional detail would strengthen the manuscript. We address each major comment below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Abstract] Abstract: the 100% success claim over 100 configurations is load-bearing for the central thesis, yet the manuscript provides no protocol details on graph construction (hand-specified per domain vs. derived), configuration sampling, or failure modes; if the graph must be supplied with accurate interaction structure, the method reduces to standard nullspace control whose performance depends on manual modeling rather than the claimed dynamic resolution.
Authors: We agree that protocol details are required for reproducibility and to substantiate the 100% success claim. The graph encodes domain-level interaction structure (derived from object geometry and contact relations rather than hand-specified per configuration), while priorities are assigned continuously from the instantaneous state to resolve conflicts dynamically. This state-dependent prioritization is what enables success on non-convex instances where static nullspace or potential-field methods fail. In the revision we will add an experimental-protocol subsection describing graph derivation, configuration sampling procedure, and failure-mode analysis, together with a clarifying paragraph distinguishing the dynamic mechanism from standard static nullspace control. revision: yes
-
Referee: [Abstract] Abstract (real-robot transfer paragraph): the claim that the formulation 'transfers directly' with additional constraints accommodated 'through the same mechanism' is central to generality, but lacks quantitative metrics, success rates, or comparison to baselines on the physical system; without these, the transfer does not yet substantiate that the graph-plus-nullspace approach scales beyond simulation.
Authors: We acknowledge that the current manuscript reports only qualitative transfer observations for the real-robot case. To address this, the revised version will include quantitative success rates, trial counts, and baseline comparisons on the physical system, confirming that additional perceptual and kinematic constraints are handled by the same nullspace-projection mechanism without reformulation. revision: yes
Circularity Check
No significant circularity; method introduces independent mechanism
full rationale
The paper's core proposal extends a graph-based world model with state-dependent nullspace projections to resolve objective conflicts reactively. No equations, fitted parameters, or self-citations are shown in the provided text that reduce the claimed success (100% vs baselines) to inputs by construction. The graph encoding of interactions is treated as an input assumption rather than derived from the method itself, and empirical transfer to real robots is presented as external validation. This is a standard non-circular proposal of a control architecture; the derivation chain does not collapse to tautology.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A graph-based world model encodes the interaction structure of objectives
Forward citations
Cited by 1 Pith paper
-
World-Task Factorization for Robot Learning
Introduces world-task factorization for robot policies using Bayesian evidence and AICON graph plus learned modulator, outperforming baselines with zero-shot generalization in heterogeneous robotics settings.
Reference graph
Works this paper leans on
-
[1]
STRIPS: A new approach to the appli- cation of theorem proving to problem solving,
R. E. Fikes and N. J. Nilsson, “STRIPS: A new approach to the appli- cation of theorem proving to problem solving,”Artificial intelligence, vol. 2, no. 3-4, pp. 189–208, 1971
1971
-
[2]
Integrated task and motion planning,
C. R. Garrett, R. Chitnis, R. Holladay, B. Kim, T. Silver, L. P. Kael- bling, and T. Lozano-P ´erez, “Integrated task and motion planning,” Annual Review of Control, Robotics, and Autonomous Systems, vol. 4, no. 1, pp. 265–293, 2021
2021
-
[3]
Describing physics for physical reasoning: Force-based sequential manipulation planning,
M. Toussaint, J.-S. Ha, and D. Driess, “Describing physics for physical reasoning: Force-based sequential manipulation planning,”Robotics and Automation Letters, vol. 5, no. 4, pp. 6209–6216, 2020
2020
-
[4]
A robust layered control system for a mobile robot,
R. Brooks, “A robust layered control system for a mobile robot,” Journal on Robotics and Automation, vol. 2, no. 1, pp. 14–23, 1986
1986
-
[5]
A unified approach for motion and force control of robot manipulators: The operational space formulation,
O. Khatib, “A unified approach for motion and force control of robot manipulators: The operational space formulation,”Journal of Robotics and Automation, vol. 3, no. 1, pp. 43–53, 1987
1987
-
[6]
On three-layer architec- tures,
E. Gat, R. P. Bonnasso, R. Murphyet al., “On three-layer architec- tures,”Artificial Intelligence and Mobile Robots, vol. 195, art. no. 210, 1998
1998
-
[7]
Robot navigation functions on manifolds with boundary,
D. E. Koditschek and E. Rimon, “Robot navigation functions on manifolds with boundary,”Advances in Applied Mathematics, vol. 11, no. 4, pp. 412–442, 1990
1990
-
[8]
Exact robot navigation using artificial potential functions,
E. Rimon and D. Koditschek, “Exact robot navigation using artificial potential functions,”Transactions on Robotics and Automation, vol. 8, no. 5, pp. 501–518, 1992
1992
-
[9]
Subgoal chaining and the local minimum problem,
J. P. Lewis and M. Weir, “Subgoal chaining and the local minimum problem,”International Joint Conference on Neural Networks, pp. 1844–1849, 1999
1999
-
[10]
Determination of all stable and unstable equilibria for image-point-based visual servoing,
A. Colotti, J. G. Font ´an, A. Goldsztejn, S. Briot, F. Chaumette, O. Ker- morgant, and M. S. E. Din, “Determination of all stable and unstable equilibria for image-point-based visual servoing,”Transactions on Robotics, vol. 40, pp. 3406–3424, 2024
2024
-
[11]
Planning as search: A quantitative approach,
R. E. Korf, “Planning as search: A quantitative approach,”Artificial Intelligence, vol. 33, no. 1, pp. 65–88, 1987
1987
-
[12]
Characterizing subgoal interactions for planning,
A. Barret and D. Weld, “Characterizing subgoal interactions for planning,”International Joint Conference on Artificial Intelligence, pp. 1388–1393, 1993
1993
-
[13]
No plan but everything under control: Robustly solving sequential tasks with dynamically composed gradient descent,
V . Mengers and O. Brock, “No plan but everything under control: Robustly solving sequential tasks with dynamically composed gradient descent,”International Conference on Robotics and Automation, pp. 90–96, 2025
2025
-
[14]
Coupled recursive estimation for online interactive perception of articulated objects,
R. Mart ´ın-Mart´ın and O. Brock, “Coupled recursive estimation for online interactive perception of articulated objects,”The International Journal of Robotics Research, vol. 41, no. 8, pp. 741–777, 2019
2019
-
[15]
An overview of null space projections for redundant, torque-controlled robots,
A. Dietrich, C. Ott, and A. Albu-Sch ¨affer, “An overview of null space projections for redundant, torque-controlled robots,”The International Journal of Robotics Research, vol. 34, no. 11, pp. 1385–1400, 2015
2015
-
[16]
Pushing everything everywhere all at once: Probabilistic prehensile pushing,
P. Perugini, J. Lundell, K. Friedl, and D. Kragic, “Pushing everything everywhere all at once: Probabilistic prehensile pushing,”Robotics and Automation Letters, vol. 10, no. 5, pp. 4540–4547, 2025
2025
-
[17]
Diffusion policy: Visuomotor policy learning via action diffusion,
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song, “Diffusion policy: Visuomotor policy learning via action diffusion,”The International Journal of Robotics Research, vol. 44, no. 10-11, pp. 1684–1704, 2025
2025
-
[18]
Sequential manipulation planning on scene graph,
Z. Jiao, Y . Niu, Z. Zhang, S.-C. Zhu, Y . Zhu, and H. Liu, “Sequential manipulation planning on scene graph,”International Conference on Intelligent Robots and Systems, pp. 8203–8210, 2022
2022
-
[19]
A direct method for trajectory op- timization of rigid bodies through contact,
M. Posa, C. Cantu, and R. Tedrake, “A direct method for trajectory op- timization of rigid bodies through contact,”The International Journal of Robotics Research, vol. 33, no. 1, pp. 69–81, 2014
2014
-
[20]
Learning problem decomposition for efficient sequential multi-object manipulation plan- ning,
Y . Zhang, T. Xue, A. Razmjoo, and S. Calinon, “Learning problem decomposition for efficient sequential multi-object manipulation plan- ning,”Robotics and Automation Letters, vol. 10, no. 12, pp. 13 367– 13 374, 2025
2025
-
[21]
Do as i can, not as i say: Grounding language in robotic affordances,
A. Brohan, Y . Chebotar, C. Finn, K. Hausman, A. Herzog, D. Ho, J. Ibarz, A. Irpan, E. Jang, R. Julianet al., “Do as i can, not as i say: Grounding language in robotic affordances,”Conference on Robot Learning, pp. 287–318, 2023
2023
-
[22]
PaLM-E: an embodied multimodal language model,
D. Driess, F. Xia, M. S. M. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, A. Wahid, J. Tompson, Q. Vuong, T. Yu, W. Huang, Y . Chebotar, P. Sermanet, D. Duckworth, S. Levine, V . Vanhoucke, K. Hausman, M. Toussaint, K. Greff, A. Zeng, I. Mordatch, and P. Florence, “PaLM-E: an embodied multimodal language model,”International Conference on Machine Learning, ...
2023
-
[23]
Scalable deep reinforcement learning for vision-based robotic manipulation,
D. Kalashnikov, A. Irpan, P. Pastor, J. Ibarz, A. Herzog, E. Jang, D. Quillen, E. Holly, M. Kalakrishnan, V . Vanhouckeet al., “Scalable deep reinforcement learning for vision-based robotic manipulation,” Conference on Robot Learning, pp. 651–673, 2018
2018
-
[24]
Challenges of real-world reinforcement learning: definitions, benchmarks and analysis,
G. Dulac-Arnold, N. Levine, D. J. Mankowitz, J. Li, C. Paduraru, S. Gowal, and T. Hester, “Challenges of real-world reinforcement learning: definitions, benchmarks and analysis,”Machine Learning, vol. 110, no. 9, pp. 2419–2468, 2021
2021
-
[25]
Demystifying diffusion policies: Action memorization and simple lookup table alternatives,
C. He, X. Liu, G. S. Camps, G. Sartoretti, and M. Schwager, “Demystifying diffusion policies: Action memorization and simple lookup table alternatives,”Preprint arXiv:2505.05787, 2025
-
[26]
Why generalization in RL is difficult: Epistemic POMDPs and implicit partial observability,
D. Ghosh, J. Rahme, A. Kumar, A. Zhang, R. P. Adams, and S. Levine, “Why generalization in RL is difficult: Epistemic POMDPs and implicit partial observability,”Advances in Neural Information Processing Systems, vol. 34, pp. 25 502–25 515, 2021
2021
-
[27]
Wall-following control of a mobile robot,
P. Van Turennout, G. Honderd, and L. Van Schelven, “Wall-following control of a mobile robot,”International Conference on Robotics and Automation, pp. 280–285, 1992
1992
-
[28]
A wall-following method for escaping lo- cal minima in potential field based motion planning,
X. Yun and K.-C. Tan, “A wall-following method for escaping lo- cal minima in potential field based motion planning,”International Conference on Advanced Robotics, pp. 421–426, 1997
1997
-
[29]
Comparison between behavior trees and finite state machines,
M. Iovino, J. F ¨orster, P. Falco, J. J. Chung, R. Siegwart, and C. Smith, “Comparison between behavior trees and finite state machines,”Trans- actions on Automation Science and Engineering, vol. 22, pp. 21 098– 21 117, 2025
2025
-
[30]
N. D. Ratliff, J. Issac, D. Kappler, S. Birchfield, and D. Fox, “Rie- mannian motion policies,”Preprint arXiv:1801.02854, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[31]
Prob- abilistic roadmaps for path planning in high-dimensional configuration spaces,
L. E. Kavraki, P. Svestka, J.-C. Latombe, and M. H. Overmars, “Prob- abilistic roadmaps for path planning in high-dimensional configuration spaces,”Transactions on Robotics and Automation, vol. 12, no. 4, pp. 566–580, 2002
2002
-
[32]
Mechanics and planning of manipulator pushing operations,
M. T. Mason, “Mechanics and planning of manipulator pushing operations,”The International Journal of Robotics Research, vol. 5, no. 3, pp. 53–71, 1986
1986
-
[33]
A data-efficient approach to precise and controlled pushing,
M. Bauza, F. R. Hogan, and A. Rodriguez, “A data-efficient approach to precise and controlled pushing,”Conference on Robot Learning, pp. 336–345, 2018
2018
-
[34]
Revisiting scalarization in multi-task learning: A theoretical perspective,
Y . Hu, R. Xian, Q. Wu, Q. Fan, L. Yin, and H. Zhao, “Revisiting scalarization in multi-task learning: A theoretical perspective,”Neural Information Processing Systems, pp. 48 510–48 533, 2023
2023
-
[35]
Conflict-averse gradi- ent descent for multi-task learning,
B. Liu, X. Liu, X. Jin, P. Stone, and Q. Liu, “Conflict-averse gradi- ent descent for multi-task learning,”Neural Information Processing Systems, pp. 18 878–18 890, 2021
2021
-
[36]
Auto-lambda: Disentan- gling dynamic task relationships,
S. Liu, S. James, A. J. Davison, and E. Johns, “Auto-lambda: Disentan- gling dynamic task relationships,”Transactions on Machine Learning Research, 2022
2022
-
[37]
On the convergence of stochastic multi-objective gradient manipulation and beyond,
S. Zhou, W. Zhang, J. Jiang, W. Zhong, J. Gu, and W. Zhu, “On the convergence of stochastic multi-objective gradient manipulation and beyond,”Neural Information Processing Systems, pp. 38 103–38 115, 2022
2022
-
[38]
An alternative view: When does SGD escape local minima?
R. Kleinberg, Y . Li, and Y . Yuan, “An alternative view: When does SGD escape local minima?”International Conference on Machine Learning, pp. 2698–2707, 2018
2018
-
[39]
Leveraging uncertainty in collective opinion dynamics with hetero- geneity,
V . Mengers, M. Raoufi, O. Brock, H. Hamann, and P. Romanczuk, “Leveraging uncertainty in collective opinion dynamics with hetero- geneity,”Scientific Reports, vol. 14, art. no. 27314, 2024
2024
-
[40]
An information processing pattern from robotics predicts properties of the human visual system,
A. Battaje, A. Godinez, N. M. Hanning, M. Rolfs, and O. Brock, “An information processing pattern from robotics predicts properties of the human visual system,”Preprint bioRxiv:2024.06.20.599814, 2024
2024
-
[41]
A robotics-inspired scanpath model reveals the importance of uncertainty and semantic object cues for gaze guidance in dynamic scenes,
V . Mengers, N. Roth, O. Brock, K. Obermayer, and M. Rolfs, “A robotics-inspired scanpath model reveals the importance of uncertainty and semantic object cues for gaze guidance in dynamic scenes,” Journal of Vision, vol. 25, no. 2, art. no. 6, 2025
2025
-
[42]
No Plan, Yet Human: A Reactive Robotics Model Predicts Human Planning Failures on a Clinical Task
M. Migacev, V . Mengers, A. K ¨ongeter, and O. Brock, “No plan, yet human: A reactive robotics model predicts human planning failures on a clinical task,”Preprint arXiv:2605.16514, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[43]
The uncontrolled manifold concept: identifying control variables for a functional task,
J. P. Scholz and G. Sch ¨oner, “The uncontrolled manifold concept: identifying control variables for a functional task,”Experimental Brain Research, vol. 126, no. 3, pp. 289–306, 1999
1999
-
[44]
Motor control strategies revealed in the structure of motor variability,
M. L. Latash, J. P. Scholz, and G. Sch ¨oner, “Motor control strategies revealed in the structure of motor variability,”Exercise and Sport Sciences Reviews, vol. 30, no. 1, pp. 26–31, 2002
2002
-
[45]
Muscle coordination is habitual rather than optimal,
A. d. Rugy, G. E. Loeb, and T. J. Carroll, “Muscle coordination is habitual rather than optimal,”Journal of Neuroscience, vol. 32, no. 21, pp. 7384–7391, 2012
2012
-
[46]
Decomposing motion that changes over time into task-relevant and task-irrelevant components in a data-driven manner: application to motor adaptation in whole-body movements,
D. Furuki and K. Takiyama, “Decomposing motion that changes over time into task-relevant and task-irrelevant components in a data-driven manner: application to motor adaptation in whole-body movements,” Scientific Reports, vol. 9, no. 1, art. no. 7246, 2019
2019
-
[47]
Exploration of joint redundancy but not task space variability facilitates supervised motor learning,
P. Singh, S. Jana, A. Ghosal, and A. Murthy, “Exploration of joint redundancy but not task space variability facilitates supervised motor learning,”Proceedings of the National Academy of Sciences, vol. 113, no. 50, pp. 14 414–14 419, 2016
2016
-
[48]
Neural population dynamics during reaching,
M. M. Churchland, J. P. Cunningham, M. T. Kaufman, J. D. Foster, P. Nuyujukian, S. I. Ryu, and K. V . Shenoy, “Neural population dynamics during reaching,”Nature, vol. 487, no. 7405, pp. 51–56, 2012
2012
-
[49]
Reorganization between preparatory and movement population responses in motor cortex,
G. F. Elsayed, A. H. Lara, M. T. Kaufman, M. M. Churchland, and J. P. Cunningham, “Reorganization between preparatory and movement population responses in motor cortex,”Nature Communications, vol. 7, no. 1, art. no. 13239, 2016
2016
-
[50]
Long-term stability of motor cortical activity: Implications for brain machine interfaces and optimal feedback control,
R. D. Flint, M. R. Scheid, Z. A. Wright, S. A. Solla, and M. W. Slutzky, “Long-term stability of motor cortical activity: Implications for brain machine interfaces and optimal feedback control,”Journal of Neuroscience, vol. 36, no. 12, pp. 3623–3632, 2016
2016
-
[51]
Context- dependent computation by recurrent dynamics in prefrontal cortex,
V . Mante, D. Sussillo, K. V . Shenoy, and W. T. Newsome, “Context- dependent computation by recurrent dynamics in prefrontal cortex,” Nature, vol. 503, no. 7474, pp. 78–84, 2013
2013
-
[52]
Why neurons mix: high di- mensionality for higher cognition,
S. Fusi, E. K. Miller, and M. Rigotti, “Why neurons mix: high di- mensionality for higher cognition,”Current Opinion in Neurobiology, vol. 37, pp. 66–74, 2016
2016
-
[53]
Mixed selectivity morphs population codes in prefrontal cortex,
A. Parthasarathy, R. Herikstad, J. H. Bong, F. S. Medina, C. Libedin- sky, and S.-C. Yen, “Mixed selectivity morphs population codes in prefrontal cortex,”Nature Neuroscience, vol. 20, no. 12, pp. 1770– 1779, 2017
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.