VCap: Hypergeometric Rewards for Weak-to-Strong Visual Captioning
Pith reviewed 2026-06-29 13:11 UTC · model grok-4.3
The pith
VCap pairs reference captions with visual signals as a Witness-Adjudicator reward to deliver hypergeometric-precision verification of factual consistency, enabling an 8B model to outperform larger SOTA systems on captioning benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
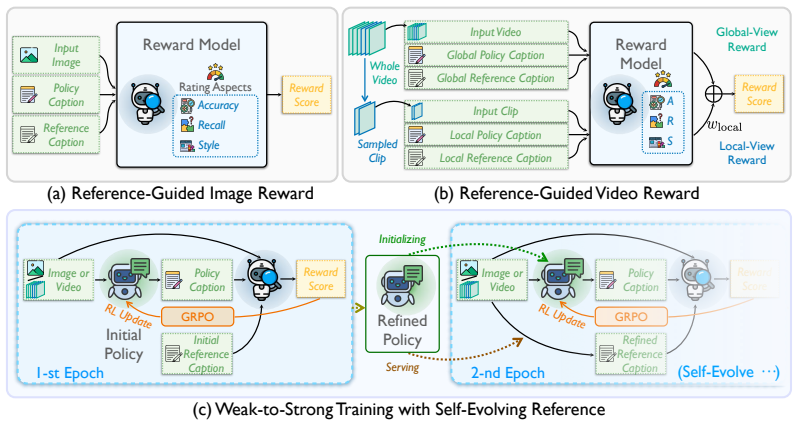
VCap is a Witness-Adjudicator reward that explicitly verifies factual consistency between the reference and policy-generated captions grounded in the visual signal, delivering a reward signal with hypergeometric-distribution-level precision for caption quality verification. This design enables effective learning even from imperfect references, facilitating weak-to-strong generalization in RL training.
What carries the argument
The Witness-Adjudicator reward, which pairs the reference caption as witness with the visual signal as adjudicator to score factual consistency at hypergeometric precision.
If this is right
- An 8B model trained with VCap outperforms open- and closed-source SOTA models on multiple image and video captioning benchmarks.
- Human evaluation confirms strong alignment with factual correctness.
- VCap improves MLLM perceptual capability and generalizes across tasks.
- VCap surpasses best-of-N distillation, challenging prior assumptions about RLVR.
Where Pith is reading between the lines
- Similar witness-adjudicator rewards could be tested on other generation tasks where reference data is noisy but a grounding signal like video frames is available.
- The approach may lower the data quality threshold needed for effective RL fine-tuning of captioners.
- If the precision claim holds, it suggests that verification mechanisms grounded in raw input can substitute for some of the benefits usually attributed to larger model scale.
Load-bearing premise
The visual signal can serve as a reliable, unbiased adjudicator that verifies factual consistency between reference and generated captions at the claimed hypergeometric precision without introducing new biases.
What would settle it
Train an 8B model with VCap and a control model with a standard reward on the same data, then have human raters score factual correctness on a held-out captioning set; if the VCap model shows no statistically significant advantage in factual alignment, the central claim is falsified.
Figures








read the original abstract
Visual captioning requires models to capture visual content faithfully while minimizing both omission and hallucination. As the dominant paradigm for captioning, MLLMs have achieved strong performance through scaling and high-quality data. Recently, RL has emerged as a key route to driving MLLMs toward higher precision and broader coverage, however, existing reward designs for captioning fail to provide fine-grained and reliable signals for factual verification, limiting their effectiveness. To address this, we propose VCap, a Witness-Adjudicator reward that pairs the reference caption (a witness) with the visual signal (an adjudicator). By explicitly verifying factual consistency between the reference and policy-generated captions grounded in the visual signal, VCap delivers a reward signal with hypergeometric-distribution-level precision for caption quality verification. This design enables effective learning even from imperfect references, facilitating weak-to-strong generalization in RL training. In our experiments, an 8B model trained with VCap outperforms open- and closed-source SOTA models on multiple image and video captioning benchmarks. Human evaluation further confirms its strong alignment with factual correctness. Additionally, VCap improves MLLM perceptual capability, generalizes across tasks, and surpasses best-of-N distillation, challenging prior assumptions about RLVR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes VCap, a witness-adjudicator reward for RL-based visual captioning in which a reference caption serves as witness and the visual signal as adjudicator to verify factual consistency between reference and policy-generated captions. The method is claimed to produce a reward with hypergeometric-distribution-level precision, enabling effective weak-to-strong generalization even from imperfect references. Experiments report that an 8B MLLM trained with VCap outperforms open- and closed-source SOTA models on multiple image and video captioning benchmarks, with human evaluation confirming factual alignment; additional claims include improved perceptual capability, cross-task generalization, and superiority over best-of-N distillation.
Significance. If the empirical results and the hypergeometric reward construction hold under scrutiny, the work would be significant for RLVR in multimodal models: it offers a concrete mechanism to obtain fine-grained factual rewards without perfect references, demonstrates smaller models surpassing larger SOTA via this signal, and challenges the assumption that distillation is preferable to RL for captioning. The human-evaluation alignment and generalization results would strengthen the case for visual-signal adjudication in captioning pipelines.
major comments (2)
- [Abstract] Abstract and method description: the central claim that the witness-adjudicator pairing yields a reward with 'hypergeometric-distribution-level precision' is load-bearing for the weak-to-strong generalization argument, yet no derivation, probability model, or explicit mapping from the visual-adjudicator verification to the hypergeometric distribution is provided; without this, it is impossible to determine whether the distribution is derived or assumed and whether any parameters are fitted.
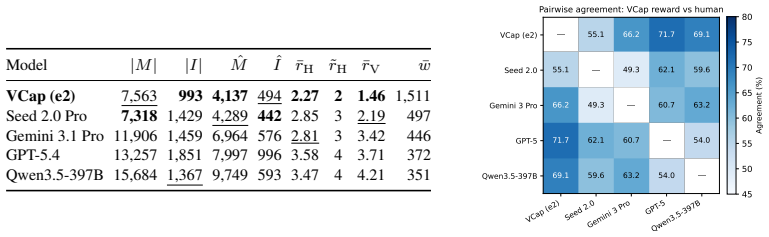
- [Experiments] Experiments section (implied by benchmark claims): the outperformance of the 8B model over SOTA on image and video captioning benchmarks is the primary empirical support, but the abstract provides no details on the exact benchmarks, metrics, baselines, or statistical significance tests; this information is required to evaluate whether the gains are attributable to the VCap reward rather than other training choices.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and commit to revisions that strengthen the clarity of the hypergeometric reward construction and the presentation of experimental details.
read point-by-point responses
-
Referee: [Abstract] Abstract and method description: the central claim that the witness-adjudicator pairing yields a reward with 'hypergeometric-distribution-level precision' is load-bearing for the weak-to-strong generalization argument, yet no derivation, probability model, or explicit mapping from the visual-adjudicator verification to the hypergeometric distribution is provided; without this, it is impossible to determine whether the distribution is derived or assumed and whether any parameters are fitted.
Authors: We agree that the abstract and current method description lack an explicit derivation and probability model. The manuscript presents the witness-adjudicator pairing and states the resulting precision level, but does not include the formal mapping. In the revised version we will insert a dedicated subsection deriving the reward from the hypergeometric distribution, specifying the underlying probability model, the combinatorial verification process, and any fitted parameters. This addition will make clear that the claimed precision follows directly from the distribution rather than being assumed. revision: yes
-
Referee: [Experiments] Experiments section (implied by benchmark claims): the outperformance of the 8B model over SOTA on image and video captioning benchmarks is the primary empirical support, but the abstract provides no details on the exact benchmarks, metrics, baselines, or statistical significance tests; this information is required to evaluate whether the gains are attributable to the VCap reward rather than other training choices.
Authors: The abstract is length-limited and therefore omits granular experimental details; these are provided in full in the Experiments section, which specifies the image benchmarks (COCO, NoCaps, Flickr30K), video benchmarks (MSVD, MSR-VTT), metrics (CIDEr, BLEU-4, METEOR, SPICE), all baselines, and statistical significance testing. To address the referee's concern we will expand the abstract with a concise enumeration of the primary benchmarks and metrics while retaining the overall length constraint. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The abstract and method description present VCap as an empirical reward design (witness-adjudicator pairing) whose hypergeometric precision is stated as an outcome of the construction rather than derived via equations that reduce to fitted inputs or self-citations. No load-bearing derivations, predictions, or uniqueness theorems are exhibited in the provided text. The central result is benchmark performance and human evaluation, which remain independent of any internal algebraic reduction. This is the most common honest finding for an empirical RL paper without visible first-principles claims.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Kwai Keye-VL-2.0 Technical Report
Kwai Keye-VL-2.0-30B-A3B is a 30B MoE model with 3B active parameters using DSA adaptation and MOPD distillation that reports SOTA results on video understanding and agent benchmarks.
Reference graph
Works this paper leans on
-
[1]
Wenhao Chai, Enxin Song, Yilun Du, Chenlin Meng, Vashisht Madhavan, Omer Bar-Tal, Jenq-Neng Hwang, Saining Xie, and Christopher D. Manning. Auroracap: Efficient, performant video detailed captioning and a new benchmark. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2025. URL...
2025
-
[2]
Soravit Changpinyo, Piyush Sharma, Nan Ding, and Radu Soricut. Conceptual 12m: Pushing web-scale image-text pre-training to recognize long-tail visual concepts. InIEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, virtual, June 19-25, 2021, pages 3558–3568. Computer Vision Foundation / IEEE, 2021. doi: 10.1109/CVPR46437.2021.00356. URL...
-
[3]
ALLaVA: Harnessing GPT4V-Synthesized Data for Lite Vision-Language Models
Guiming Hardy Chen, Shunian Chen, Ruifei Zhang, Junying Chen, Xiangbo Wu, Zhiyi Zhang, Zhihong Chen, Jianquan Li, Xiang Wan, and Benyou Wang. Allava: Harnessing gpt4v-synthesized data for lite vision-language models.ArXiv preprint, abs/2402.11684, 2024. URL https://arxiv.org/abs/2402. 11684
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
URLhttps://arxiv.org/abs/2311.12793
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Sharegpt4video: Improving video understanding and generation with better captions
Lin Chen, Xilin Wei, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Lin Bin, Zhenyu Tang, Li Yuan, Yu Qiao, Dahua Lin, Feng Zhao, and Jiaqi Wang. Sharegpt4video: Improving video understanding and generation with better captions. In Amir Globersons, Lester Mackey, Danielle Belgrave, Angela Fan, Ulrich Paquet, Jakub M. Tomczak, a...
2024
-
[7]
Tsai-Shien Chen, Aliaksandr Siarohin, Willi Menapace, Ekaterina Deyneka, Hsiang-wei Chao, Byung Eun Jeon, Yuwei Fang, Hsin-Ying Lee, Jian Ren, Ming-Hsuan Yang, and Sergey Tulyakov. Panda-70m: Captioning 70m videos with multiple cross-modality teachers. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-2...
-
[8]
Microsoft COCO Captions: Data Collection and Evaluation Server
Xinlei Chen, Hao Fang, Tsung-Yi Lin, Ramakrishna Vedantam, Saurabh Gupta, Piotr Dollár, and C. Lawrence Zitnick. Microsoft COCO captions: Data collection and evaluation server.ArXiv preprint, abs/1504.00325, 2015. URLhttps://arxiv.org/abs/1504.00325
work page internal anchor Pith review Pith/arXiv arXiv 2015
- [10]
-
[11]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, et al. Deepseek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning.ArXiv preprint, abs/2501.12948, 2025. URL https://arxiv.org/abs/2501. 12948
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Vision-Language Models
Matt Deitke, Christopher Clark, Sangho Lee, Rohun Tripathi, Yue Yang, Jae Sung Park, Mohammadreza Salehi, Niklas Muennighoff, Kyle Lo, Luca Soldaini, Jiasen Lu, Taira Anderson, Erin Bransom, Kiana Ehsani, Huong Ngo, YenSung Chen, Ajay Patel, Mark Yatskar, Chris Callison-Burch, Andrew Head, Rose Hendrix, Favyen Bastani, Eli VanderBilt, Nathan Lambert, Yvon...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Improving CLIP train- ing with language rewrites
Lijie Fan, Dilip Krishnan, Phillip Isola, Dina Katabi, and Yonglong Tian. Improving CLIP train- ing with language rewrites. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors,Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, ...
2023
-
[14]
Roopal Garg, Andrea Burns, Burcu Karagol Ayan, Yonatan Bitton, Ceslee Montgomery, Yasumasa Onoe, Andrew Bunner, Ranjay Krishna, Jason Michael Baldridge, and Radu Soricut. ImageInWords: Unlocking hyper-detailed image descriptions. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors, Proceedings of the 2024 Conference on Empirical Methods in Natur...
-
[15]
John Gkountouras and Ivan Titov. Clarification as supervision: Reinforcement learning for vision-language interfaces.ArXiv preprint, abs/2509.26594, 2025. URLhttps://arxiv.org/abs/2509.26594
-
[16]
Tianrui Guan, Fuxiao Liu, Xiyang Wu, Ruiqi Xian, Zongxia Li, Xiaoyu Liu, Xijun Wang, Lichang Chen, Furong Huang, Yaser Yacoob, Dinesh Manocha, and Tianyi Zhou. Hallusionbench: An advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models. InIEEE/CVF Conference on Computer Vision and Pattern Recogniti...
-
[17]
Tzu-Heng Huang, Sirajul Salekin, Javier Movellan, Frederic Sala, and Manjot Bilkhu. Rubicap: Rubric- guided reinforcement learning for dense image captioning.ArXiv preprint, abs/2603.09160, 2026. URL https://arxiv.org/abs/2603.09160
-
[18]
Liqiang Jing, Ruosen Li, Yunmo Chen, and Xinya Du. FaithScore: Fine-grained evaluations of hallucina- tions in large vision-language models. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors, Findings of the Association for Computational Linguistics: EMNLP 2024, pages 5042–5063, Miami, Florida, USA, 2024. Association for Computational Linguist...
-
[19]
URLhttps://aclanthology.org/2024.findings-emnlp.290/
2024
-
[20]
Miradata: A large-scale video dataset with long durations and structured cap- tions
Xuan Ju, Yiming Gao, Zhaoyang Zhang, Ziyang Yuan, Xintao Wang, Ailing Zeng, Yu Xiong, Qiang Xu, and Ying Shan. Miradata: A large-scale video dataset with long durations and structured cap- tions. In Amir Globersons, Lester Mackey, Danielle Belgrave, Angela Fan, Ulrich Paquet, Jakub M. Tomczak, and Cheng Zhang, editors,Advances in Neural Information Proces...
2024
-
[21]
Toward robust hyper-detailed image captioning: A multiagent approach and dual evaluation metrics for factuality and coverage
Saehyung Lee, Seunghyun Yoon, Trung Bui, Jing Shi, and Sungroh Yoon. Toward robust hyper-detailed image captioning: A multiagent approach and dual evaluation metrics for factuality and coverage. In Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste-Julien, Felix Berkenkamp, Tegan Maharaj, Kiri Wagstaff, and Jerry Zhu, editors,Forty-second International ...
2025
-
[22]
Junnan Li, Dongxu Li, Caiming Xiong, and Steven C. H. Hoi. BLIP: bootstrapping language-image pre-training for unified vision-language understanding and generation. In Kamalika Chaudhuri, Stefanie Jegelka, Le Song, Csaba Szepesvári, Gang Niu, and Sivan Sabato, editors,International Conference on Machine Learning, ICML 2022, 17-23 July 2022, Baltimore, Mar...
2022
-
[23]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven C. H. Hoi. BLIP-2: bootstrapping language- image pre-training with frozen image encoders and large language models. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett, editors,Inter- national Conference on Machine Learning, ICML 2023, 23-29 July 2023, ...
2023
-
[24]
Densefusion- 1m: Merging vision experts for comprehensive multimodal perception
Xiaotong Li, Fan Zhang, Haiwen Diao, Yueze Wang, Xinlong Wang, and Lingyu Duan. Densefusion- 1m: Merging vision experts for comprehensive multimodal perception. In Amir Globersons, Lester Mackey, Danielle Belgrave, Angela Fan, Ulrich Paquet, Jakub M. Tomczak, and Cheng Zhang, editors,Advances in Neural Information Processing Systems 38: Annual Conference ...
2024
-
[25]
VideoChat-R1: Enhancing Spatio-Temporal Perception via Reinforcement Fine-Tuning
Xinhao Li, Ziang Yan, Desen Meng, Lu Dong, Xiangyu Zeng, Yinan He, Yali Wang, Yu Qiao, Yi Wang, and Limin Wang. Videochat-R1: Enhancing spatio-temporal perception via reinforcement fine-tuning. ArXiv preprint, abs/2504.06958, 2025. URLhttps://arxiv.org/abs/2504.06958
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Evaluating object hallucination in large vision-language models
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Xin Zhao, and Ji-Rong Wen. Evaluating object hallucination in large vision-language models. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 292–305, Singapore,
2023
-
[27]
doi: 10.18653/v1/2023.emnlp-main.20
Association for Computational Linguistics. doi: 10.18653/v1/2023.emnlp-main.20. URL https: //aclanthology.org/2023.emnlp-main.20/
-
[28]
Zhihang Liu, Chen-Wei Xie, Bin Wen, Feiwu Yu, Jixuan Chen, Pandeng Li, Boqiang Zhang, Nianzu Yang, Yinglu Li, Zuan Gao, Yun Zheng, and Hongtao Xie. CAPability: A comprehensive visual caption benchmark for evaluating both correctness and thoroughness.ArXiv preprint, abs/2502.14914, 2025. URL https://arxiv.org/abs/2502.14914
-
[29]
Fan Lu, Wei Wu, Kecheng Zheng, Shuailei Ma, Biao Gong, Jiawei Liu, Wei Zhai, Yang Cao, Yujun Shen, and Zheng-Jun Zha. Benchmarking large vision-language models via directed scene graph for comprehensive image captioning.ArXiv preprint, abs/2412.08614, 2024. URL https://arxiv.org/ abs/2412.08614
-
[30]
Xingyu Lu, Jinpeng Wang, YiFan Zhang, Shijie Ma, Xiao Hu, Tianke Zhang, Haonan fan, Kaiyu Jiang, Changyi Liu, Kaiyu Tang, Bin Wen, Fan Yang, Tingting Gao, Han Li, and Chun Yuan. Contextrl: Enhancing mllm’s knowledge discovery efficiency with context-augmented rl.ArXiv preprint, abs/2602.22623, 2026. URLhttps://arxiv.org/abs/2602.22623
-
[31]
Desen Meng, Rui Huang, Zhilin Dai, Xinhao Li, Yifan Xu, Jun Zhang, Zhenpeng Huang, Meng Zhang, Lingshu Zhang, Yi Liu, and Limin Wang. Videocap-R1: Enhancing MLLMs for video captioning via structured thinking.ArXiv preprint, abs/2506.01725, 2025. URL https://arxiv.org/abs/2506. 01725
-
[32]
OpenVid-1M: A Large-Scale High-Quality Dataset for Text-to-video Generation
Kepan Nan, Rui Xie, Penghao Zhou, Tiehan Fan, Zhenheng Yang, Zhijie Chen, Xiang Li, Jian Yang, and Ying Tai. Openvid-1M: A large-scale high-quality dataset for text-to-video generation.ArXiv preprint, abs/2407.02371, 2024. URLhttps://arxiv.org/abs/2407.02371
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F. Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human fee...
2022
-
[34]
Prism: A framework for decoupling and assessing the capabilities of vlms
Yuxuan Qiao, Haodong Duan, Xinyu Fang, Junming Yang, Lin Chen, Songyang Zhang, Jiaqi Wang, Dahua Lin, and Kai Chen. Prism: A framework for decoupling and assessing the capabilities of vlms. In Amir Globersons, Lester Mackey, Danielle Belgrave, Angela Fan, Ulrich Paquet, Jakub M. Tomczak, and Cheng Zhang, editors,Advances in Neural Information Processing S...
2024
-
[35]
ARGUS: Hallucination and omission evaluation in video-LLMs.ArXiv preprint, abs/2506.07371, 2025
Ruchit Rawal, Reza Shirkavand, Heng Huang, Gowthami Somepalli, and Tom Goldstein. ARGUS: Hallucination and omission evaluation in video-LLMs.ArXiv preprint, abs/2506.07371, 2025. URL https://arxiv.org/abs/2506.07371
-
[36]
LAION-5B: an open 12 large-scale dataset for training next generation image-text models
Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, Patrick Schramowski, Srivatsa Kun- durthy, Katherine Crowson, Ludwig Schmidt, Robert Kaczmarczyk, and Jenia Jitsev. LAION-5B: an open 12 large-scale dataset for training next generation image-text mo...
2022
-
[37]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y .K. Li, Y . Wu, and Daya Guo. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models.ArXiv preprint, abs/2402.03300, 2024. URL https://arxiv.org/abs/2402. 03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
VLM-R1: A Stable and Generalizable R1-style Large Vision-Language Model
Haozhan Shen, Peng Liu, Jingcheng Li, Chunxin Fang, Yibo Ma, Jiajia Liao, Qiaoli Shen, Zilun Zhang, Kangjia Zhao, Qianqian Zhang, Ruochen Xu, and Tiancheng Zhao. Vlm-R1: A stable and generalizable R1-style large vision-language model.ArXiv preprint, abs/2504.07615, 2025. URL https://arxiv. org/abs/2504.07615
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
From pixels to prose: A large dataset of dense image captions.ArXiv preprint, abs/2406.10328, 2024
Vasu Singla, Kaiyu Yue, Sukriti Paul, Reza Shirkavand, Mayuka Jayawardhana, Alireza Ganjdanesh, Heng Huang, Abhinav Bhatele, Gowthami Somepalli, and Tom Goldstein. From pixels to prose: A large dataset of dense image captions.ArXiv preprint, abs/2406.10328, 2024. URL https://arxiv.org/abs/2406. 10328
-
[40]
Yanpeng Sun, Jing Hao, Ke Zhu, Jiang-Jiang Liu, Yuxiang Zhao, Xiaofan Li, Na Zhao, Zechao Li, and Jingdong Wang. Enhancing descriptive captions with visual attributes for multimodal perception.ArXiv preprint, abs/2412.14233, 2024. URLhttps://arxiv.org/abs/2412.14233
-
[41]
Aligning large multimodal models with factually augmented RLHF
Zhiqing Sun, Sheng Shen, Shengcao Cao, Haotian Liu, Chunyuan Li, Yikang Shen, Chuang Gan, Liangyan Gui, Yu-Xiong Wang, Yiming Yang, Kurt Keutzer, and Trevor Darrell. Aligning large multimodal models with factually augmented RLHF. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors, Findings of the Association for Computational Linguistics: ACL 2024,...
-
[42]
Changli Tang, Yixuan Li, Yudong Yang, Jimin Zhuang, Guangzhi Sun, Wei Li, Zejun Ma, and Chao Zhang. video-SALMONN 2: Caption-enhanced audio-visual large language models.ArXiv preprint, abs/2506.15220, 2025. URLhttps://arxiv.org/abs/2506.15220
-
[43]
Shamma, Gerald Friedland, Benjamin Elizalde, Karl Ni, Douglas Poland, Damian Borth, and Li-Jia Li
Bart Thomee, David A. Shamma, Gerald Friedland, Benjamin Elizalde, Karl Ni, Douglas Poland, Damian Borth, and Li-Jia Li. YFCC100M: The new data in multimedia research.Communications of the ACM, 59 (2):64–73, 2016
2016
-
[44]
Jack Urbanek, Florian Bordes, Pietro Astolfi, Mary Williamson, Vasu Sharma, and Adriana Romero- Soriano. A picture is worth more than 77 text tokens: Evaluating clip-style models on dense captions. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, pages 26690–26699. IEEE, 2024. doi: 10.1109/CV...
-
[45]
Huang, Nan Xu, Sheng Zhang, Hoifung Poon, and Muhao Chen
Fei Wang, Wenxuan Zhou, James Y . Huang, Nan Xu, Sheng Zhang, Hoifung Poon, and Muhao Chen. mDPO: Conditional preference optimization for multimodal large language models. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 8078–8088, Miami, Florida, US...
-
[46]
Jiawei Wang, Liping Yuan, Yuchen Zhang, and Haomiao Sun. Tarsier: Recipes for training and evaluating large video description models.ArXiv preprint, abs/2407.00634, 2024. URL https://arxiv.org/abs/ 2407.00634
-
[47]
AMBER: An LLM-free Multi-dimensional Benchmark for MLLMs Hallucination Evaluation
Junyang Wang, Yuhang Wang, Guohai Xu, Jing Zhang, Yukai Gu, Haitao Jia, Jiaqi Wang, Haiyang Xu, Ming Yan, Ji Zhang, and Jitao Sang. AMBER: An LLM-free multi-dimensional benchmark for MLLMs hallucination evaluation.ArXiv preprint, abs/2311.07397, 2023. URL https://arxiv.org/abs/2311. 07397
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[48]
Qiang Wang, Xinyuan Gao, SongLin Dong, Jizhou Han, Jiangyang Li, Yuhang He, and Yihong Gong. Vdc-agent: When video detailed captioners evolve themselves via agentic self-reflection.ArXiv preprint, abs/2511.19436, 2025. URLhttps://arxiv.org/abs/2511.19436. 13
-
[49]
Xiyao Wang, Zhengyuan Yang, Chao Feng, Yongyuan Liang, Yuhang Zhou, Xiaoyu Liu, Ziyi Zang, Ming Li, Chung-Ching Lin, Kevin Lin, Linjie Li, Furong Huang, and Lijuan Wang. Vicrit: A verifiable reinforcement learning proxy task for visual perception in VLMs.ArXiv preprint, abs/2506.10128, 2025. URLhttps://arxiv.org/abs/2506.10128
-
[50]
Detecting and mitigating hallucination in large vision language models via fine-grained AI feedback
Wenyi Xiao, Ziwei Huang, Leilei Gan, Wanggui He, Haoyuan Li, Zhelun Yu, Fangxun Shu, Hao Jiang, and Linchao Zhu. Detecting and mitigating hallucination in large vision language models via fine-grained AI feedback. In Toby Walsh, Julie Shah, and Zico Kolter, editors,Thirty-Ninth AAAI Conference on Artificial Intelligence, Thirty-Seventh Conference on Innov...
-
[51]
NeMo guardrails: A toolkit for controllable and safe LLM applications with pro- grammable rails
Yuxi Xie, Guanzhen Li, Xiao Xu, and Min-Yen Kan. V-DPO: Mitigating hallucination in large vision language models via vision-guided direct preference optimization. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Findings of the Association for Computational Linguistics: EMNLP 2024, pages 13258–13273, Miami, Florida, USA, 2024. Association for...
-
[53]
Long Xing, Xiaoyi Dong, Yuhang Zang, Yuhang Cao, Jianze Liang, Qidong Huang, Jiaqi Wang, Feng Wu, and Dahua Lin. Caprl: Stimulating dense image caption capabilities via reinforcement learning.ArXiv preprint, abs/2509.22647, 2025. URLhttps://arxiv.org/abs/2509.22647
-
[54]
LLaV A-Critic: Learning to evaluate multimodal models.ArXiv preprint, abs/2410.02712, 2024
Tianyi Xiong, Xiyao Wang, Dong Guo, Qinghao Ye, Haoqi Fan, Quanquan Gu, Heng Huang, and Chunyuan Li. LLaV A-Critic: Learning to evaluate multimodal models.ArXiv preprint, abs/2410.02712, 2024. URL https://arxiv.org/abs/2410.02712
-
[55]
Vript: A video is worth thousands of words
Dongjie Yang, Suyuan Huang, Chengqiang Lu, Xiaodong Han, Haoxin Zhang, Yan Gao, Yao Hu, and Hai Zhao. Vript: A video is worth thousands of words. In Amir Globersons, Lester Mackey, Danielle Belgrave, Angela Fan, Ulrich Paquet, Jakub M. Tomczak, and Cheng Zhang, editors,Advances in Neural Information Processing Systems 38: Annual Conference on Neural Infor...
2024
-
[56]
Painting with words: Elevating detailed image captioning with benchmark and alignment learning
Qinghao Ye, Xianhan Zeng, Fu Li, Chunyuan Li, and Haoqi Fan. Painting with words: Elevating detailed image captioning with benchmark and alignment learning. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2025. URL https://openreview.net/forum?id=636M0nNbPs
2025
-
[57]
Peter Young, Alice Lai, Micah Hodosh, and Julia Hockenmaier. From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions.Transactions of the Association for Computational Linguistics, 2:67–78, 2014. doi: 10.1162/tacl_a_00166. URL https: //aclanthology.org/Q14-1006/
-
[58]
Qiying Yu, Quan Sun, Xiaosong Zhang, Yufeng Cui, Fan Zhang, Yue Cao, Xinlong Wang, and Jingjing Liu. Capsfusion: Rethinking image-text data at scale. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, pages 14022–14032. IEEE, 2024. doi: 10.1109/CVPR52733.2024.01330. URLhttps://doi.org/10.1109/C...
-
[59]
Tianyu Yu, Yuan Yao, Haoye Zhang, Taiwen He, Yifeng Han, Ganqu Cui, Jinyi Hu, Zhiyuan Liu, Hai-Tao Zheng, and Maosong Sun. RLHF-V: towards trustworthy mllms via behavior alignment from fine-grained correctional human feedback. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, pages 13807–13816...
-
[60]
Showui: One vision-language- action model for GUI visual agent
Tianyu Yu, Haoye Zhang, Qiming Li, Qixin Xu, Yuan Yao, Da Chen, Xiaoman Lu, Ganqu Cui, Yunkai Dang, Taiwen He, Xiaocheng Feng, Jun Song, Bo Zheng, Zhiyuan Liu, Tat-Seng Chua, and Maosong Sun. RLAIF-V: open-source AI feedback leads to super GPT-4V trustworthiness. InIEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN,...
-
[61]
Liping Yuan, Jiawei Wang, Haomiao Sun, Yuchen Zhang, and Yuan Lin. Tarsier2: Advancing large vision-language models from detailed video description to comprehensive video understanding.ArXiv preprint, abs/2501.07888, 2025. URLhttps://arxiv.org/abs/2501.07888
-
[62]
Lin Zhang, Xianfang Zeng, Kangcong Li, Gang Yu, and Tao Chen. Sc-captioner: Improving image captioning with self-correction by reinforcement learning.ArXiv preprint, abs/2508.06125, 2025. URL https://arxiv.org/abs/2508.06125
-
[63]
Chunlin Zhong, Qiuxia Hou, Zhangjun Zhou, Shuang Hao, Haonan Lu, Yanhao Zhang, He Tang, and Xiang Bai. Owlcap: Harmonizing motion-detail for video captioning via HMD-270K and caption set equivalence reward.ArXiv preprint, abs/2508.18634, 2025. URLhttps://arxiv.org/abs/2508.18634. 15 A Appendix Appendix Contents A.1 Experimental Setup Details . . . . . . ....
-
[64]
all elements have been described
Analyze the Generated Caption on three dimensions: • Correctness: does it accurately represent the image, free of objects not present, inaccuracies, or contradictions? Fewer mistakes is better. • Completeness: does it cover all objects in detail with no omissions of details or objects? Fewer omissions is better. • Text Quality: is it logically fluent, coh...
-
[65]
Analysis
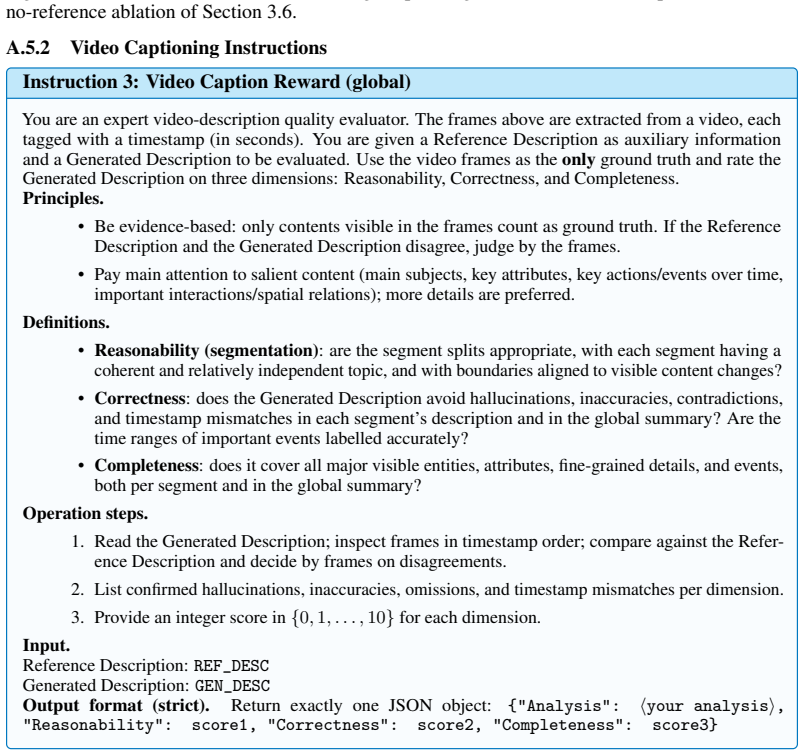
Provide an integer score in{0,1, . . . ,10}for each dimension. Input. Reference Caption:ref_answer Generated Caption:gen_solution Output format (strict).Return exactly one JSON object: {"Analysis":⟨your analysis⟩, "Correctness": score1, "Completeness": score2, "Text Quality": score3} Figure 4: Reward-model instruction for image captioning when a reference...
-
[66]
Read the Generated Description; inspect frames in timestamp order; compare against the Refer- ence Description and decide by frames on disagreements
-
[67]
List confirmed hallucinations, inaccuracies, omissions, and timestamp mismatches per dimension
-
[68]
Analysis
Provide an integer score in{0,1, . . . ,10}for each dimension. Input. Reference Description:REF_DESC Generated Description:GEN_DESC Output format (strict).Return exactly one JSON object: {"Analysis":⟨your analysis⟩, "Reasonability": score1, "Correctness": score2, "Completeness": score3} Figure 6: Reward-model instruction for the global pass over a full vi...
-
[69]
the image actually shows A, but the caption says B,
inconsistent (the image clearly contradicts the assertion), or3. undecidable (the referenced object is absent, or visible but not resolvable to the required level of detail due to occlusion, low resolution, or ambiguous angle). For an inconsistent proposition with the form “the image actually shows A, but the caption says B,” Step 1 only adjudicates the “...
-
[70]
Step 2: proposition vs
undecidable is reserved for genuinely unresolvable cases: whenever the relevant object is visible and clear, the annotator must commit to either consistent or inconsistent. Step 2: proposition vs. caption (conditional).Step 2 is executed only when Step 1 returns
-
[71]
consistent ; otherwise it is left blank. The annotator first locates the relevant object in the image, then locates the corresponding span in the caption (most captions follow a fore- ground/midground/background or left/center/right organization), and compares the proposition, 27 Table 8: Quick reference for the two-step proposition labels used in the hum...
-
[72]
image showsA
consistent 1. not holding Image really contains the asserted content; caption is too vague to decide1. consistent 3. ambiguous Image does not contain the asserted content2. inconsistent— Object is occluded / blurred / unresolvable in the image3. undecidable— Proposition: “image showsA”; image is indeedA; caption saysB1. consistent 2. holding Proposition: ...
-
[73]
image showsA
consistent 1. not holding Proposition: “image showsA”; image actually showsC(̸=A,̸=B)2. inconsistent— the caption span, and the image jointly. The verdict is one of: 1. not holding (the proposition does not in fact hold against the caption: a missing proposition whose content is already covered by the caption via a synonym or hypernym, or an inconsistent ...
-
[74]
subjective
holding , because models frequently distribute related content across non-adjacent paragraphs. If a caption self-contradicts, the existence of the erroneous wording is sufficient to label2. holding on the inconsistent side. Step 3 per-image rankings.After all propositions for the five captions of an image are anno- tated, the annotator produces three inde...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.