Benchmarking Single-Factor Physical Video-to-Audio Generation
Pith reviewed 2026-06-29 07:40 UTC · model grok-4.3
The pith
Video-to-audio models rely more on text captions than visuals for physical accuracy, but captions degrade temporal alignment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FlatSounds audits V2A models through counterfactual pairs that isolate single physical factors and pattern tests that check internal consistency and trends. State-of-the-art models depend more on text captions than the visual stream; captions raise physical and semantic accuracy but lower temporal alignment, showing the need to learn physical processes directly from pixels.
What carries the argument
FlatSounds benchmark of controlled counterfactual pairs and single-video pattern tests that isolate and probe specific physical properties and timings.
If this is right
- Adding text captions improves physical and semantic accuracy in generated audio.
- Captions reduce the temporal alignment between generated audio and video events.
- Physics-based metrics from the benchmark correlate strongly with human preference ratings.
- Progress requires training that extracts physical processes from pixels rather than from text.
Where Pith is reading between the lines
- Strengthening the visual encoder could reduce the observed accuracy-alignment trade-off.
- Benchmarks that vary one factor at a time could be applied to other generation tasks such as text-to-video or audio-to-video.
- Training sets that emphasize visual-physical correspondences without captions might lessen reliance on text.
- Human preference alignment with the metrics suggests the benchmark can serve as a scalable proxy for subjective evaluation.
Load-bearing premise
The controlled counterfactual pairs and single-video pattern tests isolate specific physical properties and timings without confounding factors from video generation or model internals.
What would settle it
A model that receives only raw video input and still produces audio whose physical accuracy and timing match or exceed those of caption-conditioned models on the same counterfactual pairs would falsify the claim of primary caption reliance.
Figures



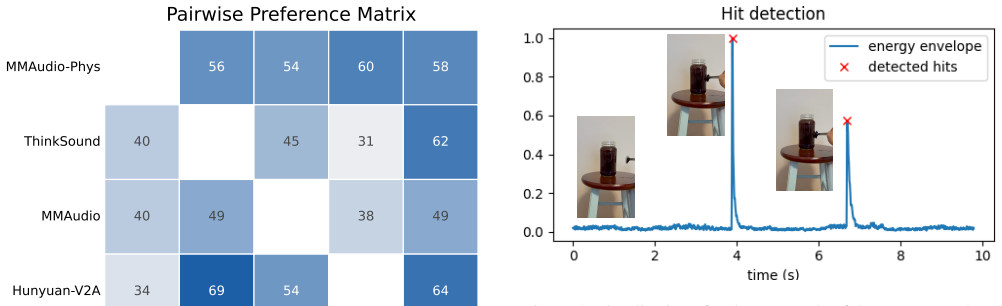

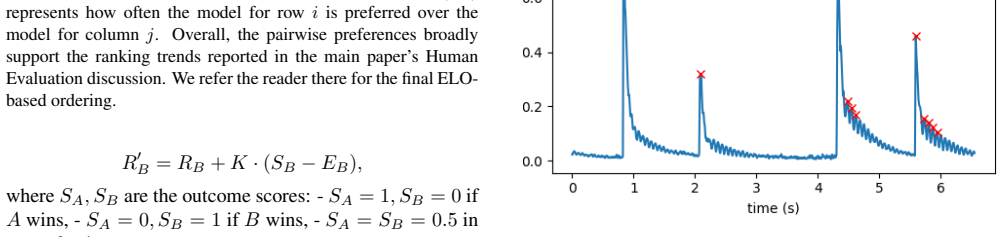
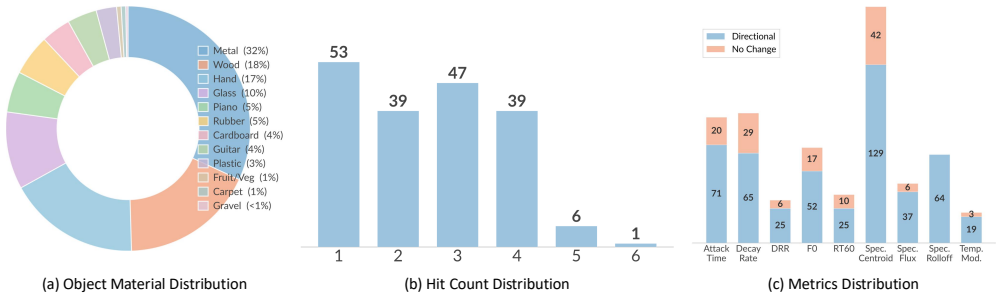




read the original abstract
Generative video-to-audio (V2A) models produce highly plausible soundtracks, but it remains unclear whether they capture the underlying physical processes. Existing evaluations emphasize perceptual realism and overlook physical correctness under controlled interventions. In this paper, we introduce FlatSounds, a benchmark that audits the physical reasoning of V2A models through: 1) controlled counterfactual pairs in which a single physical factor is varied, and 2) single-video pattern tests that probe internal consistency and directional trends. These settings test whether the generated audio correctly reflects specific physical properties and timings. Our evaluation of state-of-the-art models reveals a consistent trade-off: models rely more on text captions than the visual stream to infer physics and semantics. Captions generally improve physical and semantic accuracy, but paradoxically degrade temporal alignment. Our results highlight the need to move beyond audio quality toward learning physical processes directly from pixels. Finally, we find that our physics-based metrics correlate strongly with human preference tests on our own data. Project webpage: https://research.nvidia.com/labs/cosmos-lab/flatsounds/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FlatSounds, a benchmark for auditing physical reasoning in video-to-audio (V2A) models via (1) controlled counterfactual pairs that vary a single physical factor and (2) single-video pattern tests that probe internal consistency and directional trends. Evaluation of state-of-the-art models shows consistent reliance on text captions over the visual stream: captions improve physical and semantic accuracy but degrade temporal alignment. Physics-based metrics are reported to correlate strongly with human preference judgments.
Significance. If the results hold, the work provides a needed shift from perceptual realism metrics toward controlled tests of physical correctness in generative models. The documented caption-vs-visual trade-off and the correlation between automated physics metrics and human preferences are actionable findings that can guide future model development toward direct pixel-based physical learning.
minor comments (2)
- The abstract states that 'physics-based metrics correlate strongly with human preference tests on our own data' but does not report the exact correlation coefficient, sample size, or statistical test used; this detail should be added to the results section for reproducibility.
- Section describing the FlatSounds construction (counterfactual pairs) would benefit from an explicit statement of how video generation artifacts or model-internal confounders were ruled out, even if only as a limitations paragraph.
Simulated Author's Rebuttal
We thank the referee for their positive summary of our FlatSounds benchmark, its significance for shifting evaluation toward physical correctness in V2A models, and the recommendation of minor revision. No specific major comments were listed in the report.
Circularity Check
No significant circularity
full rationale
The paper introduces the FlatSounds benchmark consisting of controlled counterfactual pairs and single-video pattern tests, then reports empirical observations on model behavior (text vs. visual reliance, accuracy vs. alignment trade-offs) and a correlation between physics metrics and human preferences. No derivation chain, equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The central claims rest on direct evaluation of existing models against the new benchmark rather than any self-referential reduction of results to inputs by construction. This is a standard empirical benchmarking study with independent content.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Counterfactual vision and language learning
Ehsan Abbasnejad, Damien Teney, Amin Parvaneh, Javen Shi, and Anton van den Hengel. Counterfactual vision and language learning. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), pages 10044–10054, 2020. 3
2020
-
[2]
Cosmos World Foundation Model Platform for Physical AI
Niket Agarwal, Arslan Ali, Maciej Bala, Yogesh Balaji, Erik Barker, Tiffany Cai, Prithvijit Chattopadhyay, Yongxin Chen, Yin Cui, Yifan Ding, et al. Cosmos world foun- dation model platform for physical ai.arXiv preprint arXiv:2501.03575, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
gpt-oss-120b & gpt-oss-20b Model Card
Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K Arora, Yu Bai, Bowen Baker, Haiming Bao, et al. gpt-oss-120b & gpt-oss- 20b model card.arXiv preprint arXiv:2508.10925, 2025. 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
The sound of water: Inferring physi- cal properties from pouring liquids
Piyush Bagad, Makarand Tapaswi, Cees GM Snoek, and Andrew Zisserman. The sound of water: Inferring physi- cal properties from pouring liquids. InIEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5, 2025. 1
2025
-
[5]
The acquisition of physical knowledge in infancy: A summary in eight lessons.Blackwell Handbook of Childhood Cognitive Development, pages 47–83, 2002
Ren ´ee Baillargeon. The acquisition of physical knowledge in infancy: A summary in eight lessons.Blackwell Handbook of Childhood Cognitive Development, pages 47–83, 2002. 1
2002
-
[6]
Videophy: Evaluating phys- ical commonsense for video generation
Hritik Bansal, Zongyu Lin, Tianyi Xie, Zeshun Zong, Michal Yarom, Yonatan Bitton, Chenfanfu Jiang, Yizhou Sun, Kai- Wei Chang, and Aditya Grover. Videophy: Evaluating phys- ical commonsense for video generation. InInternational Conference on Learning Representations (ICLR), 2025. 3
2025
-
[7]
MIT press, 1997
Jens Blauert.Spatial hearing: the psychophysics of human sound localization. MIT press, 1997. 3
1997
-
[8]
MIT press, 1994
Albert S Bregman.Auditory scene analysis: The perceptual organization of sound. MIT press, 1994. 3
1994
-
[9]
Human sensitivity to acoustic information from vessel filling.Journal of Experi- mental Psychology: Human Perception and Performance, 26 (1):313, 2000
Patrick A Cabe and John B Pittenger. Human sensitivity to acoustic information from vessel filling.Journal of Experi- mental Psychology: Human Perception and Performance, 26 (1):313, 2000. 2
2000
-
[10]
Vggsound: A large-scale audio-visual dataset
Honglie Chen, Weidi Xie, Andrea Vedaldi, and Andrew Zis- serman. Vggsound: A large-scale audio-visual dataset. In IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 721–725, 2020. 2, 5, 9
2020
-
[11]
Video-guided foley sound generation with multimodal con- trols
Ziyang Chen, Prem Seetharaman, Bryan Russell, Oriol Ni- eto, David Bourgin, Andrew Owens, and Justin Salamon. Video-guided foley sound generation with multimodal con- trols. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 18770– 18781, 2025. 1
2025
-
[12]
Mmaudio: Taming multimodal joint training for high-quality video-to- audio synthesis
Ho Kei Cheng, Masato Ishii, Akio Hayakawa, Takashi Shibuya, Alexander Schwing, and Yuki Mitsufuji. Mmaudio: Taming multimodal joint training for high-quality video-to- audio synthesis. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), pages 28901–28911, 2025. 1, 2, 3, 5, 9
2025
-
[13]
Pitch perception
Alain de Cheveign ´e. Pitch perception. InOxford Hand- book of Auditory Science: Hearing. Oxford University Press,
-
[14]
Wei Chow, Jiageng Mao, Boyi Li, Daniel Seita, Vitor Guizilini, and Yue Wang. Physbench: Benchmarking and enhancing vision-language models for physical world under- standing.arXiv preprint arXiv:2501.16411, 2025. 3
-
[15]
A study of the just noticeable difference of early decay time for sym- phonic halls.The Journal of the Acoustical Society of Amer- ica, 151(1):80–94, 2022
Fernando del Solar Dorrego and Michelle C Vigeant. A study of the just noticeable difference of early decay time for sym- phonic halls.The Journal of the Acoustical Society of Amer- ica, 151(1):80–94, 2022. 3
2022
-
[16]
Cogview2: Faster and better text-to-image generation via hi- erarchical transformers
Ming Ding, Wendi Zheng, Wenyi Hong, and Jie Tang. Cogview2: Faster and better text-to-image generation via hi- erarchical transformers. InAdvances in Neural Information Processing Systems (NeurIPS), pages 16890–16902, 2022. 2
2022
-
[17]
Mit Press, 2010
Andy Farnell.Designing sound. Mit Press, 2010. 1, 3
2010
-
[18]
Auditory correlates of perceived mallet hard- ness for a set of recorded percussive sound events.The Jour- nal of the Acoustical Society of America, 87(1):311–322,
Daniel J Freed. Auditory correlates of perceived mallet hard- ness for a set of recorded percussive sound events.The Jour- nal of the Acoustical Society of America, 87(1):311–322,
-
[19]
What in the world do we hear?: An eco- logical approach to auditory event perception.Ecological Psychology, 5(1):1–29, 1993
William W Gaver. What in the world do we hear?: An eco- logical approach to auditory event perception.Ecological Psychology, 5(1):1–29, 1993. 3
1993
-
[20]
Shortcut learning in deep neural networks
Robert Geirhos, J ¨orn-Henrik Jacobsen, Claudio Michaelis, Richard Zemel, Wieland Brendel, Matthias Bethge, and Fe- lix A Wichmann. Shortcut learning in deep neural networks. Nature Machine Intelligence, 2(11):665–673, 2020. 3
2020
-
[21]
Audio set: An ontology and human- labeled dataset for audio events
Jort F Gemmeke, Daniel PW Ellis, Dylan Freedman, Aren Jansen, Wade Lawrence, R Channing Moore, Manoj Plakal, and Marvin Ritter. Audio set: An ontology and human- labeled dataset for audio events. InIEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 776–780, 2017. 2
2017
-
[22]
Giordano and Stephen McAdams
Bruno L. Giordano and Stephen McAdams. Material iden- tification of real impact sounds: Effects of size variation in steel, glass, wood, and plexiglass plates.The Journal of the Acoustical Society of America, 119(2):1171–1181, 2006. 4
2006
-
[23]
Imagebind: One embedding space to bind them all
Rohit Girdhar, Alaaeldin El-Nouby, Zhuang Liu, Mannat Singh, Kalyan Vasudev Alwala, Armand Joulin, and Ishan Misra. Imagebind: One embedding space to bind them all. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR), pages 15180–15190,
-
[24]
David Ha and J ¨urgen Schmidhuber. World models.arXiv preprint arXiv:1803.10122, 2(3), 2018. 1
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[25]
Av-link: Temporally-aligned diffusion features for cross-modal audio-video generation
Moayed Haji-Ali, Willi Menapace, Aliaksandr Siarohin, Ivan Skorokhodov, Alper Canberk, Kwot Sin Lee, Vicente Ordonez, and Sergey Tulyakov. Av-link: Temporally-aligned diffusion features for cross-modal audio-video generation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 19373–19385, 2025. 2
2025
-
[26]
Routledge, 2013
David Howard and Jamie Angus.Acoustics and psychoa- coustics. Routledge, 2013. 2
2013
-
[27]
Vbench: Comprehensive bench- mark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al. Vbench: Comprehensive bench- mark suite for video generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 21807–21818, 2024. 2, 3
2024
-
[28]
Taming visually guided sound generation
Vladimir Iashin and Esa Rahtu. Taming visually guided sound generation. InThe British Machine Vision Conference (BMVC), 2021. 2
2021
-
[29]
Synchformer: Efficient synchronization from sparse cues
Vladimir Iashin, Weidi Xie, Esa Rahtu, and Andrew Zisser- man. Synchformer: Efficient synchronization from sparse cues. InIEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 5325–5329,
-
[30]
Krumhansl
Paul Iverson and Carol L. Krumhansl. Isolating the dynamic attributes of musical timbre.The Journal of the Acoustical Society of America, 94(5):2595–2603, 1993. 4
1993
-
[31]
Intro- ducing parselmouth: A python interface to praat.Journal of Phonetics, 71:1–15, 2018
Yannick Jadoul, Bill Thompson, and Bart De Boer. Intro- ducing parselmouth: A python interface to praat.Journal of Phonetics, 71:1–15, 2018. 3
2018
-
[32]
Clevr: A diagnostic dataset for compositional language and elementary visual reasoning
Justin Johnson, Bharath Hariharan, Laurens Van Der Maaten, Li Fei-Fei, C Lawrence Zitnick, and Ross Girshick. Clevr: A diagnostic dataset for compositional language and elementary visual reasoning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2901–2910, 2017. 3
2017
-
[33]
Frechet audio distance: A reference-free metric for evaluating music enhancement algorithms
Kevin Kilgour, Mauricio Zuluaga, Dominik Roblek, and Matthew Sharifi. Frechet audio distance: A reference-free metric for evaluating music enhancement algorithms. InIn- terspeech, 2019. 1, 2, 6
2019
-
[34]
Audiocaps: Generating captions for audios in the wild
Chris Dongjoo Kim, Byeongchang Kim, Hyunmin Lee, and Gunhee Kim. Audiocaps: Generating captions for audios in the wild. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computa- tional Linguistics: Human Language Technologies (NAACL- HLT), Volume 1 (Long and Short Papers), pages 119–132,
2019
-
[35]
Hearing shape.Journal of Experimental Psychology: Human Per- ception and Performance, 26(1):279, 2000
Andrew J Kunkler-Peck and Michael T Turvey. Hearing shape.Journal of Experimental Psychology: Human Per- ception and Performance, 26(1):279, 2000. 1
2000
-
[36]
A path towards autonomous machine intelli- gence version 0.9
Yann LeCun. A path towards autonomous machine intelli- gence version 0.9. 2, 2022-06-27.OpenReview, 62(1):1–62,
2022
-
[37]
Wiley-IEEE Press, Hoboken, N.J, 2 edition, 2023
Alexander Lerch.An Introduction to Audio Content Anal- ysis: Music Information Retrieval Tasks and Applications. Wiley-IEEE Press, Hoboken, N.J, 2 edition, 2023. 4
2023
-
[38]
Detecting outliers: Do not use standard deviation around the mean, use absolute deviation around the median.Journal of Experimental Social Psychol- ogy, 49(4):764–766, 2013
Christophe Leys, Christophe Ley, Olivier Klein, Philippe Bernard, and Laurent Licata. Detecting outliers: Do not use standard deviation around the mean, use absolute deviation around the median.Journal of Experimental Social Psychol- ogy, 49(4):764–766, 2013. 5
2013
-
[39]
Audi- oldm: Text-to-audio generation with latent diffusion models
Haohe Liu, Zehua Chen, Yi Yuan, Xinhao Mei, Xubo Liu, Danilo Mandic, Wenwu Wang, and Mark D Plumbley. Audi- oldm: Text-to-audio generation with latent diffusion models. InInternational Conference on Machine Learning (ICML),
-
[40]
Thinksound: Chain-of- thought reasoning in multimodal large language models for audio generation and editing
Huadai Liu, Jialei Wang, Kaicheng Luo, Wen Wang, Qian Chen, Zhou Zhao, and Wei Xue. Thinksound: Chain-of- thought reasoning in multimodal large language models for audio generation and editing. InAdvances in Neural Infor- mation Processing Systems (NeurIPS), 2025. 1, 2, 5
2025
-
[41]
Tell what you hear from what you see-video to audio generation through text
Xiulong Liu, Kun Su, and Eli Shlizerman. Tell what you hear from what you see-video to audio generation through text. InAdvances in Neural Information Processing Systems (NeurIPS), pages 101337–101366, 2024. 2
2024
-
[42]
Diff-foley: Synchronized video-to-audio synthesis with la- tent diffusion models
Simian Luo, Chuanhao Yan, Chenxu Hu, and Hang Zhao. Diff-foley: Synchronized video-to-audio synthesis with la- tent diffusion models. InAdvances in Neural Information Processing Systems (NeurIPS), pages 48855–48876, 2023. 2
2023
-
[43]
Omni-captioner: Data pipeline, mod- els, and benchmark for omni detailed perception
Ziyang Ma, Ruiyang Xu, Zhenghao Xing, Yunfei Chu, Yux- uan Wang, Jinzheng He, Jin Xu, Pheng-Ann Heng, Kai Yu, Junyang Lin, et al. Omni-captioner: Data pipeline, mod- els, and benchmark for omni detailed perception. InInter- national Conference on Learning Representations (ICLR),
-
[44]
Sound texture perception via statistics of the auditory periphery: evidence from sound synthesis.Neuron, 71(5):926–940, 2011
Josh H McDermott and Eero P Simoncelli. Sound texture perception via statistics of the auditory periphery: evidence from sound synthesis.Neuron, 71(5):926–940, 2011. 1, 3
2011
-
[45]
Towards world simulator: Crafting physical commonsense-based benchmark for video generation
Fanqing Meng, Jiaqi Liao, Xinyu Tan, Wenqi Shao, Quan- feng Lu, Kaipeng Zhang, Yu Cheng, Dianqi Li, Yu Qiao, and Ping Luo. Towards world simulator: Crafting physical commonsense-based benchmark for video generation. InIn- ternational Conference on Machine Learning (ICML), 2025. 3
2025
-
[46]
Brill, 2012
Brian CJ Moore.An introduction to the psychology of hear- ing. Brill, 2012. 3
2012
-
[47]
Do generative video models understand physical principles?
Saman Motamed, Laura Culp, Kevin Swersky, Priyank Jaini, and Robert Geirhos. Do generative video models understand physical principles?arXiv preprint arXiv:2501.09038, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
Synthesizing sounds from rigid-body simulations
James F O’Brien, Chen Shen, and Christine M Gatchalian. Synthesizing sounds from rigid-body simulations. InPro- ceedings of the 2002 ACM SIGGRAPH/Eurographics Sym- posium on Computer Animation, pages 175–181, 2002. 1, 3
2002
-
[49]
Toward verifiable and reproducible human evalu- ation for text-to-image generation
Mayu Otani, Riku Togashi, Yu Sawai, Ryosuke Ishigami, Yuta Nakashima, Esa Rahtu, Janne Heikkil ¨a, and Shin’ichi Satoh. Toward verifiable and reproducible human evalu- ation for text-to-image generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14277–14286, 2023. 2
2023
-
[50]
Visually indicated sounds
Andrew Owens, Phillip Isola, Josh McDermott, Antonio Tor- ralba, Edward H Adelson, and William T Freeman. Visually indicated sounds. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), pages 2405–2413, 2016. 1, 2, 9
2016
-
[51]
Masked generative video-to-audio transformers with enhanced synchronicity
Santiago Pascual, Chunghsin Yeh, Ioannis Tsiamas, and Joan Serr`a. Masked generative video-to-audio transformers with enhanced synchronicity. InEuropean Conference on Com- puter Vision (ECCV), pages 247–264. Springer, 2024. 2
2024
-
[52]
The MIT press, 2017
Jonas Peters, Dominik Janzing, and Bernhard Sch ¨olkopf.El- ements of causal inference: foundations and learning algo- rithms. The MIT press, 2017. 2, 3
2017
-
[53]
Movie Gen: A Cast of Media Foundation Models
Adam Polyak, Amit Zohar, Andrew Brown, Andros Tjandra, Animesh Sinha, Ann Lee, Apoorv Vyas, Bowen Shi, Chih- Yao Ma, Ching-Yao Chuang, et al. Movie gen: A cast of media foundation models.arXiv preprint arXiv:2410.13720,
work page internal anchor Pith review Pith/arXiv arXiv
-
[54]
Learn- ing transferable visual models from natural language super- vision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learn- ing transferable visual models from natural language super- vision. InInternational Conference on Machine Learning (ICML), pages 8748–8763. PmLR, 2021. 2
2021
-
[55]
Improved techniques for training gans
Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. Improved techniques for training gans. InAdvances in Neural Information Pro- cessing Systems (NeurIPS), 2016. 6
2016
-
[56]
New method of measuring reverbera- tion time.The Journal of the Acoustical Society of America, 37(3):409–412, 1965
Manfred R Schroeder. New method of measuring reverbera- tion time.The Journal of the Acoustical Society of America, 37(3):409–412, 1965. 5
1965
-
[57]
Estimates of the regression coefficient based on kendall’s tau.Journal of the American Statistical Association, 63(324):1379–1389, 1968
Pranab Kumar Sen. Estimates of the regression coefficient based on kendall’s tau.Journal of the American Statistical Association, 63(324):1379–1389, 1968. 5
1968
-
[58]
Sizhe Shan, Qiulin Li, Yutao Cui, Miles Yang, Yuehai Wang, Qun Yang, Jin Zhou, and Zhao Zhong. Hunyuanvideo- foley: Multimodal diffusion with representation alignment for high-fidelity foley audio generation.arXiv preprint arXiv:2508.16930, 2025. 2, 5
-
[59]
I hear your true colors: Image guided audio generation
Roy Sheffer and Yossi Adi. I hear your true colors: Image guided audio generation. InIEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5, 2023. 2
2023
-
[60]
The development of em- bodied cognition: Six lessons from babies.Artificial Life, 11 (1-2):13–29, 2005
Linda Smith and Michael Gasser. The development of em- bodied cognition: Six lessons from babies.Artificial Life, 11 (1-2):13–29, 2005. 1
2005
-
[61]
From vision to au- dio and beyond: A unified model for audio-visual representa- tion and generation
Kun Su, Xiulong Liu, and Eli Shlizerman. From vision to au- dio and beyond: A unified model for audio-visual representa- tion and generation. InInternational Conference on Machine Learning (ICML), 2024. 2
2024
-
[62]
Qwen3-vl: the multimodal large language model series.https://github.com/QwenLM/Qwen3- VL,
Qwen Team. Qwen3-vl: the multimodal large language model series.https://github.com/QwenLM/Qwen3- VL,
-
[63]
Temporally aligned audio for video with autoregression
Ilpo Viertola, Vladimir Iashin, and Esa Rahtu. Temporally aligned audio for video with autoregression. InIEEE Inter- national Conference on Acoustics, Speech and Signal Pro- cessing (ICASSP), pages 1–5, 2025. 2
2025
-
[64]
Evaluating generative audio systems and their metrics
Ashvala Vinay and Alexander Lerch. Evaluating generative audio systems and their metrics. InInternational Society for Music Information Retrieval Conference (ISMIR), pages 858–865, 2022. 2
2022
-
[65]
Oliphant, Matt Haberland, Tyler Reddy, David Cournapeau, Evgeni Burovski, Pearu Peterson, Warren Weckesser, Jonathan Bright, St ´efan J
Pauli Virtanen, Ralf Gommers, Travis E. Oliphant, Matt Haberland, Tyler Reddy, David Cournapeau, Evgeni Burovski, Pearu Peterson, Warren Weckesser, Jonathan Bright, St ´efan J. van der Walt, Matthew Brett, Joshua Wil- son, K. Jarrod Millman, Nikolay Mayorov, Andrew R. J. Nelson, Eric Jones, Robert Kern, Eric Larson, C J Carey, ˙Ilhan Polat, Yu Feng, Eric ...
2020
-
[66]
Sharpness as an attribute of the tim- bre of steady sounds.Acustica, 30:159–172, 1974
Gottfried von Bismarck. Sharpness as an attribute of the tim- bre of steady sounds.Acustica, 30:159–172, 1974. 4
1974
-
[67]
Jun Wang, Xijuan Zeng, Chunyu Qiang, Ruilong Chen, Shiyao Wang, Le Wang, Wangjing Zhou, Pengfei Cai, Ji- ahui Zhao, Nan Li, et al. Kling-foley: Multimodal diffu- sion transformer for high-quality video-to-audio generation. arXiv preprint arXiv:2506.19774, 2025. 2, 3
-
[68]
The sound of simu- lation: Learning multimodal sim-to-real robot policies with generative audio
Renhao Wang, Haoran Geng, Tingle Li, Philipp Wu, Feishi Wang, Gopala Anumanchipalli, Trevor Darrell, Boyi Li, Pieter Abbeel, Jitendra Malik, et al. The sound of simu- lation: Learning multimodal sim-to-real robot policies with generative audio. InProceedings of the 9th Conference on Robot Learning (CoRL), 2025. 1
2025
-
[69]
Frieren: Efficient video-to-audio generation network with rectified flow matching
Yongqi Wang, Wenxiang Guo, Rongjie Huang, Jiawei Huang, Zehan Wang, Fuming You, Ruiqi Li, and Zhou Zhao. Frieren: Efficient video-to-audio generation network with rectified flow matching. InAdvances in Neural Informa- tion Processing Systems (NeurIPS), pages 128118–128138,
-
[70]
Zihan Wang, Songlin Li, Lingyan Hao, Xinyu Hu, and Bowen Song. What you see is what matters: A novel vi- sual and physics-based metric for evaluating video genera- tion quality.arXiv preprint arXiv:2411.13609, 2024. 3
-
[71]
Peter Welch. The use of fast fourier transform for the esti- mation of power spectra: A method based on time averaging over short, modified periodograms.IEEE Transactions on Audio and Electroacoustics, 15(2):70–73, 2003. 4
2003
-
[72]
Large-scale con- trastive language-audio pretraining with feature fusion and keyword-to-caption augmentation
Yusong Wu, Ke Chen, Tianyu Zhang, Yuchen Hui, Taylor Berg-Kirkpatrick, and Shlomo Dubnov. Large-scale con- trastive language-audio pretraining with feature fusion and keyword-to-caption augmentation. InIEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5, 2023. 1, 2, 6
2023
-
[73]
A survey on video dif- fusion models.ACM Computing Surveys, 57(2):1–42, 2024
Zhen Xing, Qijun Feng, Haoran Chen, Qi Dai, Han Hu, Hang Xu, Zuxuan Wu, and Yu-Gang Jiang. A survey on video dif- fusion models.ACM Computing Surveys, 57(2):1–42, 2024. 2
2024
-
[74]
Jin Xu, Zhifang Guo, Hangrui Hu, Yunfei Chu, Xiong Wang, Jinzheng He, Yuxuan Wang, Xian Shi, Ting He, Xinfa Zhu, et al. Qwen3-omni technical report.arXiv preprint arXiv:2509.17765, 2025. 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[75]
Video-to-audio generation with hidden alignment.arXiv preprint arXiv:2407.07464,
Manjie Xu, Chenxing Li, Xinyi Tu, Yong Ren, Rilin Chen, Yu Gu, Wei Liang, and Dong Yu. Video-to-audio generation with hidden alignment.arXiv preprint arXiv:2407.07464,
-
[76]
Chenyu Zhang, Daniil Cherniavskii, Andrii Zadaianchuk, Antonios Tragoudaras, Antonios V ozikis, Thijmen Nijdam, Derck WE Prinzhorn, Mark Bodracska, Nicu Sebe, and Ef- stratios Gavves. Morpheus: Benchmarking physical reason- ing of video generative models with real physical experi- ments.arXiv preprint arXiv:2504.02918, 2025. 3
-
[77]
Uniavgen: Unified audio and video generation with asymmetric cross-modal interactions, 2025
Guozhen Zhang, Zixiang Zhou, Teng Hu, Ziqiao Peng, You- liang Zhang, Yi Chen, Yuan Zhou, Qinglin Lu, and Limin Wang. Uniavgen: Unified audio and video generation with asymmetric cross-modal interactions, 2025. 2
2025
-
[78]
Yiming Zhang, Yicheng Gu, Yanhong Zeng, Zhening Xing, Yuancheng Wang, Zhizheng Wu, and Kai Chen. Foley- crafter: Bring silent videos to life with lifelike and synchro- nized sounds.arXiv preprint arXiv:2407.01494, 2024. 1, 2, 5
-
[79]
Pai-bench: A comprehensive benchmark for physical ai.arXiv preprint arXiv:2512.01989, 2025
Fengzhe Zhou, Jiannan Huang, Jialuo Li, Deva Ramanan, and Humphrey Shi. Pai-bench: A comprehensive benchmark for physical ai.arXiv preprint arXiv:2512.01989, 2025. 3
-
[80]
Visual to sound: Generating natural sound for videos in the wild
Yipin Zhou, Zhaowen Wang, Chen Fang, Trung Bui, and Tamara L Berg. Visual to sound: Generating natural sound for videos in the wild. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3550–3558, 2018. 1
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.