Cross-Generational Transfer of Adversarial Attacks Reveals Non-Monotonic Safety Alignment in LLMs
Pith reviewed 2026-06-28 18:29 UTC · model grok-4.3
The pith
Safety alignment in LLMs does not improve monotonically across model generations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
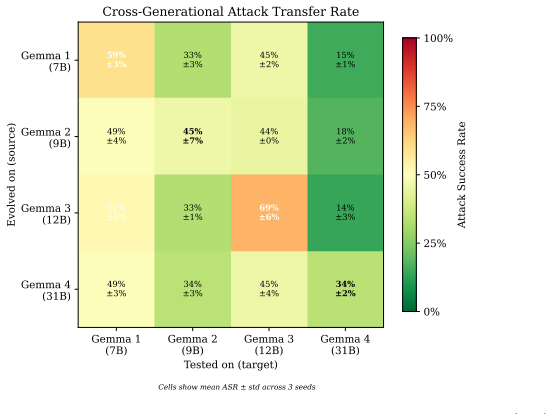
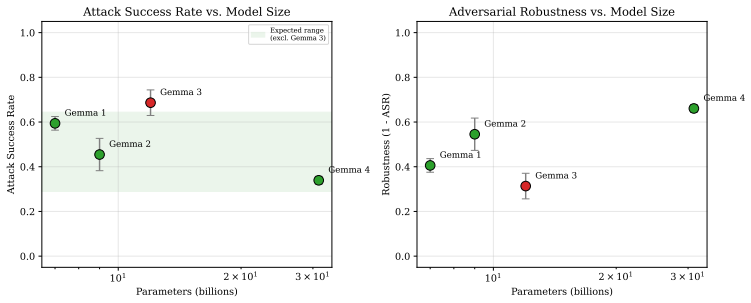
Safety alignment in LLMs does not improve monotonically across model generations. Studying four generations of Google's Gemma family (7B-31B) with quality-diversity evolution (MAP-Elites) as an automated red-teaming probe, we find that Gemma 3 (12B) exhibits 68.7% +/- 5.7% attack success rate, significantly higher than its predecessor Gemma 2 (45.5% +/- 7.2%) and its successor Gemma 4 (33.9% +/- 1.8%). Replaying evolved attack archives across generations reveals that attacks from other generations transfer to Gemma 3 at 44-46% but only 14-18% to Gemma 4, indicating that Gemma 4's safety gains generalize beyond the attack distributions evolved against earlier generations.
What carries the argument
Quality-diversity evolution (MAP-Elites) used as an automated red-teaming probe to generate and transfer attack archives across model generations.
If this is right
- Gemma 3 records 68.7% attack success rate compared with 45.5% for Gemma 2 and 33.9% for Gemma 4.
- Attacks transfer to Gemma 3 at 44-46% success but only 14-18% to Gemma 4.
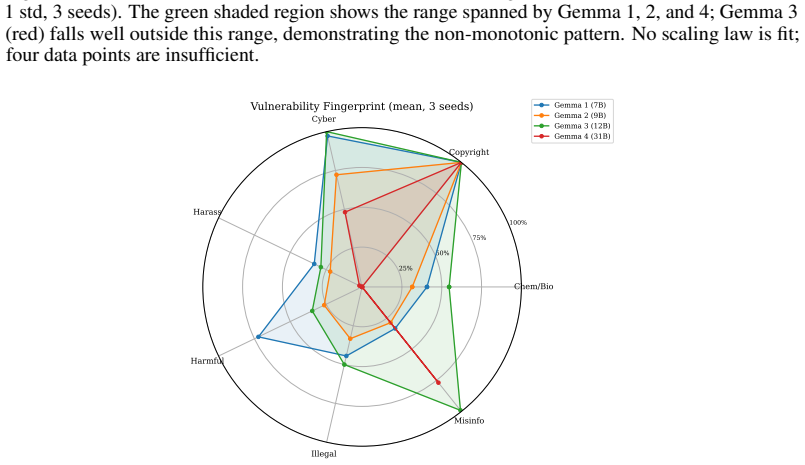
- Misinformation attack success rises from 29% in Gemma 2 to 99% in Gemma 3 and stays at 77% in Gemma 4.
- Copyright and cybercrime categories register near-100% success across all generations under the primary judge.
Where Pith is reading between the lines
- Developers may need to test new models against attack archives evolved on prior generations to confirm that safety gains are robust rather than narrow.
- The partial persistence of the misinformation regression suggests that later training steps can leave some vulnerability categories incompletely addressed.
- Static benchmarks risk missing regressions because they do not adapt attack distributions to the specific weaknesses of each model generation.
Load-bearing premise
The 8B judge used to score attack success provides a stable and generalizable measure of vulnerability.
What would settle it
Attack success rates that decrease steadily with each successive Gemma generation when the same MAP-Elites procedure and judge are applied.
Figures
read the original abstract
Safety alignment in LLMs does not improve monotonically across model generations. Studying four generations of Google's Gemma family (7B-31B) with quality-diversity evolution (MAP-Elites) as an automated red-teaming probe, we find that Gemma 3 (12B) exhibits 68.7% +/- 5.7% attack success rate (ASR; mean +/- std, 3 seeds), significantly higher than its predecessor Gemma 2 (45.5% +/- 7.2%; p = 0.030, paired bootstrap) and its successor Gemma 4 (33.9% +/- 1.8%). Replaying evolved attack archives across generations reveals that attacks from other generations transfer to Gemma 3 at 44-46% but only 14-18% to Gemma 4, indicating that Gemma 4's safety gains generalize beyond the attack distributions evolved against earlier generations. Under our 8B judge, copyright and cybercrime vulnerabilities register at near-100% across all generations, though a second-judge audit (Section 6) suggests the copyright result is sensitive to judge choice. Misinformation ASR jumps from 29% to 99% between Gemma 2 and Gemma 3 and remains elevated at 77% in Gemma 4, indicating the regression was not fully addressed. These patterns are invisible to static benchmarks and emerge only through adaptive, longitudinal probing. All experiments use 3 random seeds with a unified self-hosted judge; code and artifacts are available at https://github.com/bassrehab/red-queen.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLM safety alignment is non-monotonic across model generations. Using MAP-Elites quality-diversity evolution to generate adversarial attacks against four generations of Google's Gemma family (7B-31B), it reports that Gemma 3 (12B) has a significantly higher attack success rate (68.7% +/- 5.7%) than Gemma 2 (45.5% +/- 7.2%, p=0.030) and Gemma 4 (33.9% +/- 1.8%). Cross-generation transfer shows attacks transfer at 44-46% to Gemma 3 but only 14-18% to Gemma 4. Category-specific results include near-100% copyright/cybercrime ASR across generations (with noted judge sensitivity) and a misinformation ASR jump from 29% to 99% (Gemma 2 to 3) remaining at 77% in Gemma 4. Experiments use 3 seeds and a unified 8B self-hosted judge; code is released.
Significance. If the ASR measurements prove robust to judge choice, the result would be significant: it demonstrates that safety does not improve monotonically with scale/generation, that regressions (e.g., misinformation) can persist, and that static benchmarks miss these patterns while adaptive longitudinal red-teaming (MAP-Elites + transfer) can surface them. The explicit cross-generational transfer analysis and open artifacts are strengths that would support broader adoption of such probing methods.
major comments (1)
- [Abstract / Section 6] Abstract and Section 6: The central non-monotonic claim (Gemma 3 ASR 68.7% significantly exceeding Gemma 2/4, plus the misinformation jump 29%→99%→77%) is measured exclusively by a single 8B LLM judge. The abstract states that a second-judge audit finds the near-100% copyright rates sensitive to judge choice, but reports no equivalent cross-judge validation for the overall ASR or misinformation ASR that drive the headline ordering and significance test. Because the same judge is applied uniformly to attacks evolved against and replayed across generations, any generation-correlated bias in the judge would directly produce the reported non-monotonic pattern without reflecting true vulnerability differences.
minor comments (1)
- [Methods] The MAP-Elites configuration, prompt filtering rules, and full judge prompt are referenced but not fully detailed in the abstract view; expanding these in the methods section would aid reproducibility even with the released code.
Simulated Author's Rebuttal
We thank the referee for highlighting the judge validation gap for our central claims. We agree this is a substantive limitation of the current manuscript and will address it directly in revision.
read point-by-point responses
-
Referee: The central non-monotonic claim (Gemma 3 ASR 68.7% significantly exceeding Gemma 2/4, plus the misinformation jump 29%→99%→77%) is measured exclusively by a single 8B LLM judge. The abstract states that a second-judge audit finds the near-100% copyright rates sensitive to judge choice, but reports no equivalent cross-judge validation for the overall ASR or misinformation ASR that drive the headline ordering and significance test. Because the same judge is applied uniformly to attacks evolved against and replayed across generations, any generation-correlated bias in the judge would directly produce the reported non-monotonic pattern without reflecting true vulnerability differences.
Authors: We acknowledge the concern is valid: the headline non-monotonic ordering, significance test, and misinformation jump rest on a single 8B judge, while the second-judge audit was performed only for copyright. Although the judge is held fixed across all models and seeds (ensuring relative comparisons use identical criteria), a generation-correlated bias in the judge could artifactually produce the reported pattern. In the revision we will extend the second-judge audit to the aggregate ASR and to the misinformation category, reporting inter-judge agreement and re-computing the key statistical comparisons under the second judge. This will directly test robustness of the non-monotonic result. revision: yes
Circularity Check
No circularity: all claims are direct empirical measurements of attack success rates via fixed judge
full rationale
The paper reports attack success rates (ASRs) and transfer percentages obtained by running evolved attacks against Gemma generations and scoring outputs with a fixed 8B judge. No equations, fitted parameters, or self-citations are used to derive the headline non-monotonic pattern (Gemma 3 ASR 68.7% vs. 45.5% and 33.9%); the quantities are raw experimental counts. The abstract explicitly flags judge sensitivity only for the copyright category and does not invoke any self-referential definition or prediction step that would collapse the reported differences to the measurement procedure itself. The MAP-Elites evolution is a search procedure whose outputs are then evaluated externally; it does not create a closed loop in which the success metric is defined in terms of the same quantity being predicted.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption MAP-Elites with quality-diversity evolution serves as a valid automated red-teaming probe that surfaces meaningful safety differences across model generations.
- domain assumption The 8B judge produces attack-success labels that generalize across vulnerability categories and model generations.
Forward citations
Cited by 1 Pith paper
-
Actionable Activation Directions for Detecting and Mitigating Emergent Misalignment Across Language Model Families
Difference-in-means activation directions detect and mitigate emergent misalignment from insecure code fine-tuning across four LLM families, with effective within-model steering but non-specific cross-model transfer.
Reference graph
Works this paper leans on
-
[1]
Mazeika, Mantas and Phan, Long and Yin, Xuwang and McDuff, Daniel and Zick, Yaron and others , booktitle=
-
[2]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Universal and Transferable Adversarial Attacks on Aligned Language Models , author=. arXiv preprint arXiv:2307.15043 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Jailbreaking Black Box Large Language Models in Twenty Queries
Jailbreaking Black Box Large Language Models in Twenty Queries , author=. arXiv preprint arXiv:2310.08419 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Tree of Attacks: Jailbreaking Black-Box
Mehrotra, Anay and Zampetakis, Manolis and Kassianik, Paul and Nelson, Blaine and Anderson, Hyrum and Singer, Yaron and Karbasi, Amin , journal=. Tree of Attacks: Jailbreaking Black-Box
-
[5]
Liu, Xiaogeng and Xu, Nan and Chen, Muhao and Xiao, Chaowei , journal=
-
[6]
Illuminating search spaces by mapping elites
Illuminating Search Spaces by Mapping Elites , author=. arXiv preprint arXiv:1504.04909 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Genetic and Evolutionary Computation Conference (GECCO) , year=
Covariance Matrix Adaptation for the Rapid Illumination of Behavior Space , author=. Genetic and Evolutionary Computation Conference (GECCO) , year=
-
[8]
Nature , volume=
Robots that can adapt like animals , author=. Nature , volume=
-
[9]
Scaling Laws for Neural Language Models
Scaling Laws for Neural Language Models , author=. arXiv preprint arXiv:2001.08361 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[10]
Training Compute-Optimal Large Language Models
Training Compute-Optimal Large Language Models , author=. arXiv preprint arXiv:2203.15556 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Souly, Alexandra and Lu, Qingyun and Bowen, Dillon and Trinh, Tu and Hsieh, Elvis and Pandey, Sana and Abbeel, Pieter and Svegliato, Justin and Emmons, Scott and Watkins, Olivia and Toyer, Sam , journal=
-
[12]
Quality-Diversity Evolution for Discovering Diverse Vulnerabilities in
Mitra, Subhadip , booktitle=. Quality-Diversity Evolution for Discovering Diverse Vulnerabilities in
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.