Efficient RAG with Intent-Aware Retrieval and Semantics-Preserving Chunking
Pith reviewed 2026-06-28 17:36 UTC · model grok-4.3
The pith
InSemRAG improves multi-hop RAG accuracy by dynamically weighting retrieval to query intent and repairing semantic damage in chunks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
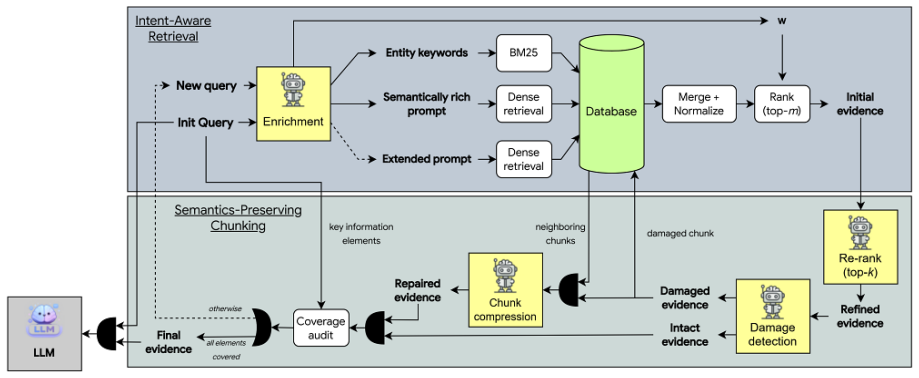
InSemRAG addresses intent-agnostic retrieval and information fragmentation in conventional RAG via an iterative retrieve-and-check mechanism. The intention-aware retriever implements dynamic hybrid retrieval that adaptively weights the retrieval channels based on the query intent. The semantics-preserving chunking performs detection and reparation to the damaged evidence chunks to preserve semantic integrity. Extensive experiments show a 2.65-point F1 improvement on HotPotQA, a 1.5-point accuracy increase on FEVER, and competitive results to Multi-Hop RAG at 4.32 times lower latency when using small language models.
What carries the argument
The iterative retrieve-and-check mechanism with intention-aware retriever (IAR) for dynamic weighting and semantics-preserving chunking (SPC) for evidence repair.
If this is right
- Gains of 2.65 F1 points on HotPotQA for multi-hop tasks.
- 1.5-point accuracy rise on FEVER for evidence-sensitive tasks.
- Competitive benchmark results across datasets with 4.32 times lower latency than Multi-Hop RAG.
- Overall competitiveness to recent state-of-the-art RAG methods.
Where Pith is reading between the lines
- The efficiency gains from small language models could make complex RAG viable on resource-limited hardware.
- Chunk repair may reduce downstream generation errors on queries not covered in the current benchmarks.
- Adaptive weighting of retrieval channels might extend to other hybrid search systems outside RAG.
Load-bearing premise
The iterative retrieve-and-check mechanism with IAR and SPC can accurately detect query intent, adapt retrieval weights, and repair semantic damage in chunks without introducing new errors or requiring extensive human tuning of the SLM components.
What would settle it
A direct comparison showing zero or negative F1 change on HotPotQA or higher latency than Multi-Hop RAG after applying the full InSemRAG pipeline would falsify the central performance claims.
Figures


read the original abstract
The demand for powerful instruction following and reasoning capability of large language models (LLMs) has promoted rapid development of retrieval-augmented generation (RAG). The RAG system assists LLM generation by retrieving chunks of query-fit supplementary knowledge from an external database. Conventional RAG systems, however, suffer from information insufficiency due to two factors, which are intent-agnostic retrieval and information fragmentation. Our work proposes a RAG framework, termed InSemRAG, that addresses these challenges via an iterative retrieve-and-check mechanism with two supporting modules, an intention-aware retriever (IAR) and semantics-preserving chunking (SPC). IAR implements a dynamic hybrid retrieval method that adaptively weights the retrieval channels based on the query intent, while SPC performs detection and reparation to the damaged evidence chunks to preserve the semantic integrity. To alleviate the computational latency brought by our iterative mechanism, we leverage small language models (SLMs). Extensive experiments across several benchmark datasets consistently demonstrate the competitiveness of our method against recent state-of-the-art RAG mechanisms. Particularly, our method achieves significant gains on multi-hop and evidence-sensitive tasks, with a 2.65-point improvement in F1 on HotPotQA and a 1.5-point increase in accuracy on FEVER. Our method also achieves competitive performance to Multi-Hop RAG with 4.32$\times$ lower latency with the utilization of SLM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes InSemRAG, a RAG framework using an iterative retrieve-and-check mechanism with an intent-aware retriever (IAR) that dynamically weights retrieval channels and semantics-preserving chunking (SPC) that detects and repairs damaged evidence chunks. It leverages SLMs to mitigate latency and reports competitive or superior results on multi-hop and evidence-sensitive benchmarks, including a 2.65-point F1 gain on HotPotQA and 1.5-point accuracy gain on FEVER, while achieving 4.32× lower latency than Multi-Hop RAG.
Significance. If the performance claims hold under rigorous controls, the work offers a practical advance in RAG by addressing intent-agnostic retrieval and chunk fragmentation while maintaining efficiency via SLMs. The emphasis on iterative intent detection and semantic repair could influence designs for complex reasoning tasks, provided the gains prove robust.
major comments (2)
- [Experiments] Experiments section: the reported gains (e.g., 2.65 F1 on HotPotQA, 1.5 accuracy on FEVER) are presented without error bars, statistical significance tests, or ablation studies isolating the iterative retrieve-and-check component, IAR weighting, and SPC repair; this directly limits verification of the central claim that IAR and SPC drive the improvements.
- [Methods] Methods section: concrete details on the SLM prompting or fine-tuning for intent classification, retrieval weighting, and chunk repair are insufficient to assess whether the iterative mechanism avoids introducing new errors or requires extensive tuning, which is load-bearing for the weakest assumption that the mechanism functions reliably.
minor comments (1)
- [Abstract] Abstract and §3: the latency comparison (4.32× lower) should specify the exact baseline implementation and hardware to allow direct replication.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address each major comment below and will incorporate revisions to strengthen the experimental reporting and methodological transparency.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the reported gains (e.g., 2.65 F1 on HotPotQA, 1.5 accuracy on FEVER) are presented without error bars, statistical significance tests, or ablation studies isolating the iterative retrieve-and-check component, IAR weighting, and SPC repair; this directly limits verification of the central claim that IAR and SPC drive the improvements.
Authors: We agree that the absence of error bars, statistical tests, and component-specific ablations limits the ability to verify the source of gains. In the revised version we will report means and standard deviations over multiple random seeds, include paired statistical significance tests against baselines, and add ablation tables that remove or isolate the iterative retrieve-and-check loop, the IAR weighting mechanism, and the SPC repair step individually. revision: yes
-
Referee: [Methods] Methods section: concrete details on the SLM prompting or fine-tuning for intent classification, retrieval weighting, and chunk repair are insufficient to assess whether the iterative mechanism avoids introducing new errors or requires extensive tuning, which is load-bearing for the weakest assumption that the mechanism functions reliably.
Authors: We will expand the Methods section with the exact prompt templates used by the SLM for intent classification, dynamic channel weighting, and chunk repair, together with any fine-tuning details, temperature settings, and stopping criteria for the iterative loop. We will also add a short discussion of observed error rates across iterations and the safeguards employed to limit error accumulation. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper proposes InSemRAG with IAR and SPC modules for RAG, evaluated via empirical gains on external benchmarks (HotPotQA F1, FEVER accuracy, latency vs Multi-Hop RAG). No equations, fitted parameters, or self-citations are presented that reduce claimed performance to inputs by construction. The iterative mechanism and SLM usage are described as design choices, not derived from the target metrics. Central claims rest on benchmark results rather than self-referential fitting or renamed ansatzes, making the derivation self-contained against external data.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
Advances in neural information processing systems , volume=
Retrieval-augmented generation for knowledge-intensive nlp tasks , author=. Advances in neural information processing systems , volume=
-
[9]
Retrieval-Augmented Generation for Large Language Models: A Survey
Retrieval-augmented generation for large language models: A survey , author=. arXiv preprint arXiv:2312.10997 , volume=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Advances in Neural Information Processing Systems , volume=
Augmenting language models with long-term memory , author=. Advances in Neural Information Processing Systems , volume=
-
[11]
arXiv preprint arXiv:2501.06713 , year=
Minirag: Towards extremely simple retrieval-augmented generation , author=. arXiv preprint arXiv:2501.06713 , year=
-
[12]
arXiv preprint arXiv:2410.20753 , year=
Plan* rag: Efficient test-time planning for retrieval augmented generation , author=. arXiv preprint arXiv:2410.20753 , year=
-
[13]
LightRAG: Simple and Fast Retrieval-Augmented Generation
Lightrag: Simple and fast retrieval-augmented generation , author=. arXiv preprint arXiv:2410.05779 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
arXiv preprint arXiv:2404.00610 , year=
Rq-rag: Learning to refine queries for retrieval augmented generation , author=. arXiv preprint arXiv:2404.00610 , year=
-
[15]
arXiv preprint arXiv:2411.13154 , year=
Dmqr-rag: Diverse multi-query rewriting for rag , author=. arXiv preprint arXiv:2411.13154 , year=
-
[16]
Precise zero-shot dense retrieval without relevance labels, 2022 , author=. URL https://arxiv. org/abs/2212.10496 , year=
-
[17]
arXiv preprint arXiv:2310.06117 , year=
Take a step back: Evoking reasoning via abstraction in large language models , author=. arXiv preprint arXiv:2310.06117 , year=
-
[18]
arXiv preprint arXiv:2402.03367 , year=
Rag-fusion: a new take on retrieval-augmented generation , author=. arXiv preprint arXiv:2402.03367 , year=
-
[19]
arXiv preprint arXiv:2503.23013 , year=
DAT: Dynamic alpha tuning for hybrid retrieval in retrieval-augmented generation , author=. arXiv preprint arXiv:2503.23013 , year=
-
[20]
Advances in Neural Information Processing Systems , volume=
Rankrag: Unifying context ranking with retrieval-augmented generation in llms , author=. Advances in Neural Information Processing Systems , volume=
-
[21]
arXiv preprint arXiv:2409.04701 , year=
Late chunking: contextual chunk embeddings using long-context embedding models , author=. arXiv preprint arXiv:2409.04701 , year=
-
[22]
Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
Is semantic chunking worth the computational cost? , author=. Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
2025
-
[23]
The twelveth international conference on learning representations , year=
Self-rag: Learning to retrieve, generate, and critique through self-reflection , author=. The twelveth international conference on learning representations , year=
-
[24]
Corrective retrieval augmented generation , author=
-
[25]
Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG
Agentic retrieval-augmented generation: A survey on agentic rag , author=. arXiv preprint arXiv:2501.09136 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Proceedings of the 16th conference of the european chapter of the association for computational linguistics: main volume , pages=
Leveraging passage retrieval with generative models for open domain question answering , author=. Proceedings of the 16th conference of the european chapter of the association for computational linguistics: main volume , pages=
-
[27]
The eleventh international conference on learning representations , year=
React: Synergizing reasoning and acting in language models , author=. The eleventh international conference on learning representations , year=
-
[28]
Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers) , pages=
Interleaving retrieval with chain-of-thought reasoning for knowledge-intensive multi-step questions , author=. Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers) , pages=
-
[29]
MultiHop-RAG: Benchmarking Retrieval-Augmented Generation for Multi-Hop Queries
Multihop-rag: Benchmarking retrieval-augmented generation for multi-hop queries , author=. arXiv preprint arXiv:2401.15391 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Transactions of the Association for Computational Linguistics , volume=
Natural questions: a benchmark for question answering research , author=. Transactions of the Association for Computational Linguistics , volume=. 2019 , publisher=
2019
-
[31]
TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension
Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension , author=. arXiv preprint arXiv:1705.03551 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Proceedings of the 2013 conference on empirical methods in natural language processing , pages=
Semantic parsing on freebase from question-answer pairs , author=. Proceedings of the 2013 conference on empirical methods in natural language processing , pages=
2013
-
[33]
Proceedings of the 2018 conference on empirical methods in natural language processing , pages=
HotpotQA: A dataset for diverse, explainable multi-hop question answering , author=. Proceedings of the 2018 conference on empirical methods in natural language processing , pages=
2018
-
[34]
Constructing A Multi-hop QA Dataset for Comprehensive Evaluation of Reasoning Steps
Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps , author=. arXiv preprint arXiv:2011.01060 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[35]
ELI5: Long Form Question Answering
ELI5: Long form question answering , author=. arXiv preprint arXiv:1907.09190 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[36]
FEVER: a large-scale dataset for Fact Extraction and VERification
FEVER: a large-scale dataset for fact extraction and VERification , author=. arXiv preprint arXiv:1803.05355 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
Text summarization branches out , pages=
Rouge: A package for automatic evaluation of summaries , author=. Text summarization branches out , pages=
-
[38]
ACM Transactions on Intelligent Systems and Technology , volume=
A comprehensive survey of small language models in the era of large language models: Techniques, enhancements, applications, collaboration with llms, and trustworthiness , author=. ACM Transactions on Intelligent Systems and Technology , volume=. 2025 , publisher=
2025
-
[39]
arXiv preprint arXiv:2410.09037 , year=
Mentor-kd: Making small language models better multi-step reasoners , author=. arXiv preprint arXiv:2410.09037 , year=
-
[40]
The Twelfth International Conference on Learning Representations , year=
Ra-dit: Retrieval-augmented dual instruction tuning , author=. The Twelfth International Conference on Learning Representations , year=
-
[41]
Proceedings of the 2024 10th International Conference on Communication and Information Processing , pages=
Evaluating Sparse and Dense Retrieval in Retrieval-Augmented Generation Systems: A Study , author=. Proceedings of the 2024 10th International Conference on Communication and Information Processing , pages=
2024
-
[42]
International conference on machine learning , pages=
Improving language models by retrieving from trillions of tokens , author=. International conference on machine learning , pages=. 2022 , organization=
2022
-
[43]
Atlas: Few-shot Learning with Retrieval Augmented Language Models
Few-shot learning with retrieval augmented language models , author=. arXiv preprint arXiv:2208.03299 , volume=
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
Transactions of the Association for Computational Linguistics , volume=
In-context retrieval-augmented language models , author=. Transactions of the Association for Computational Linguistics , volume=. 2023 , publisher=
2023
-
[45]
Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
Old ir methods meet rag , author=. Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
-
[46]
arXiv preprint arXiv:2401.07883 , year=
The chronicles of rag: The retriever, the chunk and the generator , author=. arXiv preprint arXiv:2401.07883 , year=
-
[47]
2025 10th International Conference on Intelligent Computing and Signal Processing (ICSP) , pages=
SLM-based Hybrid Retrieval for Resource Constrained Retrieval-Augmented Generation on Open Super-Large Crawled Data , author=. 2025 10th International Conference on Intelligent Computing and Signal Processing (ICSP) , pages=. 2025 , organization=
2025
-
[48]
Findings of the Association for Computational Linguistics ACL 2024 , pages=
Retrieval-augmented retrieval: Large language models are strong zero-shot retriever , author=. Findings of the Association for Computational Linguistics ACL 2024 , pages=
2024
-
[49]
Foundations and Trends
The probabilistic relevance framework: BM25 and beyond , author=. Foundations and Trends. 2009 , publisher=
2009
-
[50]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[51]
2025 IEEE 41st International Conference on Data Engineering Workshops (ICDEW) , pages=
Structured Retrieval-Augmented Generation for Multi-Entity Question Answering over Heterogeneous Sources , author=. 2025 IEEE 41st International Conference on Data Engineering Workshops (ICDEW) , pages=. 2025 , organization=
2025
-
[52]
arXiv preprint arXiv:2602.13035 , year =
Look Inward to Explore Outward: Learning Temperature Policy from LLM Internal States via Hierarchical RL , author =. arXiv preprint arXiv:2602.13035 , year =
-
[53]
arXiv preprint arXiv:2512.06690 , year =
Think-While-Generating: On-the-Fly Reasoning for Personalized Long-Form Generation , author =. arXiv preprint arXiv:2512.06690 , year =
-
[54]
TDA-RC: Task-Driven Alignment for Knowledge-Based Reasoning Chains in Large Language Models
TDA-RC: Task-Driven Alignment for Knowledge-Based Reasoning Chains in Large Language Models , author =. arXiv preprint arXiv:2604.04942 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[55]
The Fourteenth International Conference on Learning Representations , year =
Learning Global Hypothesis Space for Enhancing Synergistic Reasoning Chain , author =. The Fourteenth International Conference on Learning Representations , year =
-
[56]
The Fourteenth International Conference on Learning Representations , year =
Text summarization via global structure awareness , author =. The Fourteenth International Conference on Learning Representations , year =
-
[57]
arXiv preprint arXiv:2603.12933 , year =
Efficient and Interpretable Multi-Agent LLM Routing via Ant Colony Optimization , author =. arXiv preprint arXiv:2603.12933 , year =
-
[58]
arXiv preprint arXiv:2603.16060 , year=
ARISE: Agent Reasoning with Intrinsic Skill Evolution in Hierarchical Reinforcement Learning , author =. arXiv preprint arXiv:2603.16060 , year =
-
[59]
arXiv preprint arXiv:2603.13134 , year =
When Right Meets Wrong: Bilateral Context Conditioning with Reward-Confidence Correction for GRPO , author =. arXiv preprint arXiv:2603.13134 , year =
-
[60]
Inspo: Unlocking intrinsic self-reflection for llm preference optimization , author =. arXiv preprint arXiv:2512.23126 , year =
-
[61]
arXiv preprint arXiv:2508.19639 , year=
FakeSV-VLM: Taming VLM for Detecting Fake Short-Video News via Progressive Mixture-Of-Experts Adapter , author=. arXiv preprint arXiv:2508.19639 , year=
-
[62]
StreamMeCo: Long-Term Agent Memory Compression for Efficient Streaming Video Understanding
StreamMeCo: Long-Term Agent Memory Compression for Efficient Streaming Video Understanding , author=. arXiv preprint arXiv:2604.09000 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[63]
Lightweight LLM Agent Memory with Small Language Models
Lightweight LLM Agent Memory with Small Language Models , author=. arXiv preprint arXiv:2604.07798 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[64]
and Li, Haizhou , journal=
Zhang, Malu and Wang, Jiadong and Wu, Jibin and Belatreche, Ammar and Amornpaisannon, Burin and Zhang, Zhixuan and Miriyala, Venkata Pavan Kumar and Qu, Hong and Chua, Yansong and Carlson, Trevor E. and Li, Haizhou , journal=. Rectified Linear Postsynaptic Potential Function for Backpropagation in Deep Spiking Neural Networks , year=
-
[65]
A Highly Effective and Robust Membrane Potential-Driven Supervised Learning Method for Spiking Neurons , year=
Zhang, Malu and Qu, Hong and Belatreche, Ammar and Chen, Yi and Yi, Zhang , journal=. A Highly Effective and Robust Membrane Potential-Driven Supervised Learning Method for Spiking Neurons , year=
-
[66]
Toward Building Human-Like Sequential Memory Using Brain-Inspired Spiking Neural Models , year=
Zhang, Malu and Luo, Xiaoling and Wu, Jibin and Belatreche, Ammar and Cai, Siqi and Yang, Yang and Li, Haizhou , journal=. Toward Building Human-Like Sequential Memory Using Brain-Inspired Spiking Neural Models , year=
-
[67]
Spike-Driven Lightweight Large Language Model With Evolutionary Computation , year=
Zhang, Malu and Wei, Wenjie and Zhou, Zijian and Liu, Wanlong and Zhang, Jie and Belatreche, Ammar and Yang, Yang , journal=. Spike-Driven Lightweight Large Language Model With Evolutionary Computation , year=
-
[68]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
What is overlap knowledge in event argument extraction? APE: A cross-datasets transfer learning model for EAE , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[69]
Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Beyond the granularity: Multi-perspective dialogue collaborative selection for dialogue state tracking , author=. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[70]
Dual slot selector via local reliability verification for dialogue state tracking , author=. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , pages=
-
[71]
Proceedings of the AAAI conference on artificial intelligence , volume=
Learning to imagine: distillation-based interactive context exploitation for dialogue state tracking , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[72]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
HASH-RAG: bridging deep hashing with retriever for efficient, fine retrieval and augmented generation , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[73]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Accelerating adaptive retrieval augmented generation via instruction-driven representation reduction of retrieval overlaps , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[74]
Experience Transfer for Multimodal LLM Agents in Minecraft Game
Experience Transfer for Multimodal LLM Agents in Minecraft Game , author=. arXiv preprint arXiv:2604.05533 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[75]
Transforming External Knowledge into Triplets for Enhanced Retrieval in RAG of LLMs
Transforming External Knowledge into Triplets for Enhanced Retrieval in RAG of LLMs , author=. arXiv preprint arXiv:2604.12610 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[76]
arXiv preprint arXiv:2602.00135 , year=
LLaVA-FA: Learning Fourier Approximation for Compressing Large Multimodal Models , author=. arXiv preprint arXiv:2602.00135 , year=
-
[77]
TechRxiv , volume =
Pengcheng Zheng and Chaoning Zhang and Mingzheng Cui and Guo Chen and Qigan Sun and Jiaxin Huang and Jiaquan Zhang and Tae-Ho Kim and Caiyan Qin and Yazhou Ren and Guoqing Wang and Yang Yang , title =. TechRxiv , volume =. 2026 , doi =
2026
-
[78]
arXiv preprint arXiv:2112.01488 , year=
ColBERTv2: Effective and Efficient Retrieval via Lightweight Late Interaction , author=. arXiv preprint arXiv:2112.01488 , year=
-
[79]
Journal of Machine Learning Research , volume=
Atlas: Few-shot Learning with Retrieval Augmented Language Models , author =. Journal of Machine Learning Research , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.