BenchEvolver: Frontier Task Synthesis via Solution-Centric Evolution
Pith reviewed 2026-06-28 16:48 UTC · model grok-4.3
The pith
Evolving reference solutions through structured transformations generates harder coding tasks that remain challenging even for the generating model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
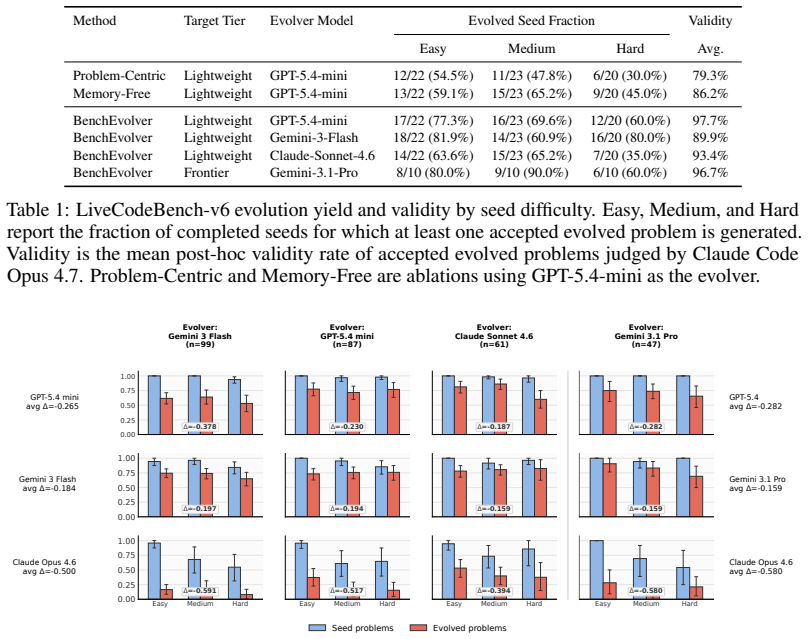
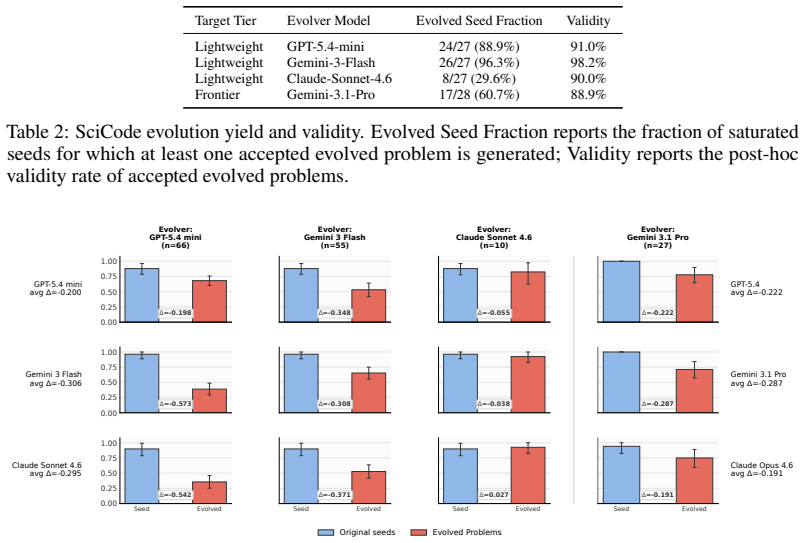
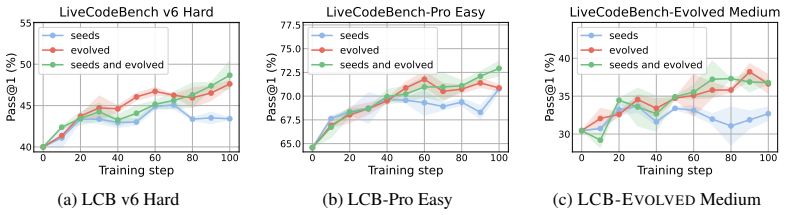
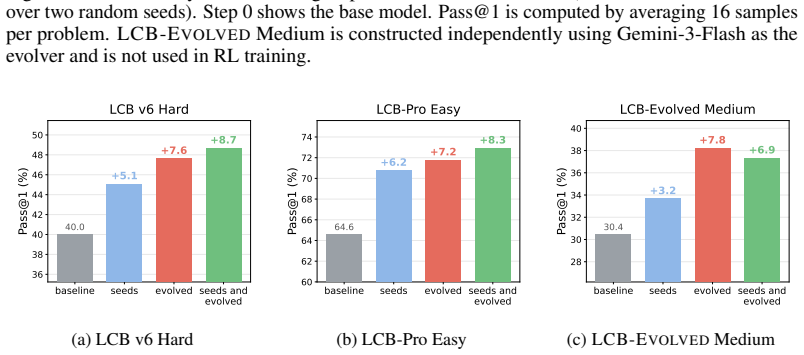
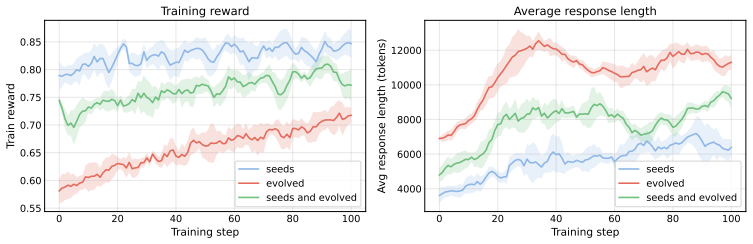
BenchEvolver evolves reference solutions of coding problems via structured transformations and derives corresponding statements and tests from those evolved solutions. This produces substantially harder tasks that maintain validity, reference correctness, and diversity. On the resulting LiveCodeBench-Plus benchmark of 91 problems, frontier-model Pass@1 scores range from 27.5% to 62.6%. Evolved tasks remain challenging even for the model that generates them, and reinforcement learning on these evolved LiveCodeBench tasks improves held-out coding performance, with seed-plus-evolved training yielding +8.7 and +8.3 Pass@1 gains on LCB v6 Hard and LCB-Pro Easy that exceed seed-only gains by 70.7%
What carries the argument
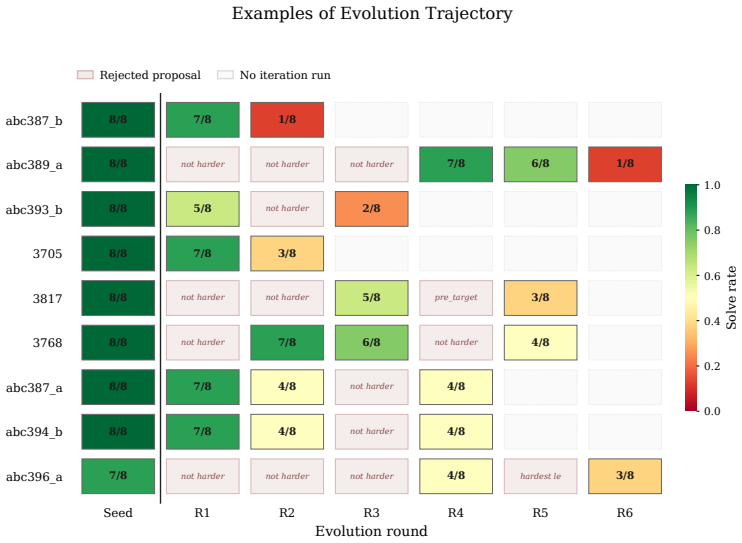
Solution-centric evolutionary framework that applies structured transformations to reference solutions to create harder variants and then derives problem statements and tests from the evolved solutions.
If this is right
- Evolved tasks support self-improvement loops because they stay difficult for the model that produced them.
- Reinforcement learning on evolved tasks delivers larger performance increases on held-out coding benchmarks than seed-only training.
- Saturated benchmarks can be converted into frontier-level evaluation suites with restored discrimination among strong models.
- The generated tasks preserve executable correctness and diversity without requiring post-hoc human filtering.
Where Pith is reading between the lines
- Iterative application of the evolution process could sustain benchmark difficulty as models continue to improve.
- The solution-centric method may transfer to other areas that have executable reference solutions, such as mathematical derivations.
- Training on evolved tasks could encourage models to handle more novel problem structures beyond the original distribution.
Load-bearing premise
Structured transformations applied to reference solutions will reliably produce harder tasks that maintain executable correctness, validity, and diversity without introducing invalid tests.
What would settle it
The generating model achieving high Pass@1 accuracy on the evolved tasks it created, or reinforcement learning on evolved tasks failing to produce larger held-out gains than training on seed tasks alone.
Figures



read the original abstract
The rapid progress of frontier large language models has led to widespread benchmark saturation, limiting the ability of existing datasets to differentiate model capabilities or provide useful training signal. For instance, on LiveCodeBench, frontier models achieve over 99% Pass@1 on easy splits and exceed 90% Pass@1 on average across difficulty levels. Constructing new, challenging datasets typically requires substantial human effort, creating a bottleneck for progress. We introduce BenchEvolver, a solution-centric evolutionary framework that automatically transforms existing coding problems into harder variants. Rather than generating problems from scratch, BenchEvolver evolves reference solutions through structured transformations and derives corresponding statements and tests from the evolved solutions. This design grounds generation in executable semantics, enabling scalable construction of high-quality, diverse, and difficult tasks with verifiable correctness. Applying BenchEvolver to LiveCodeBench and SciCode, we obtain evolved tasks that are substantially harder while maintaining validity, reference correctness, and diversity. We further curate LiveCodeBench-Plus, a 91-problem benchmark combining evolved and difficult original LCB-v6 tasks, where frontier-model Pass@1 ranges from 27.5% to 62.6%, restoring clear discrimination among strong coding models. Importantly, evolved tasks remain challenging even for the model that generates them, enabling self-improvement. We further show that RL on evolved LCB tasks improves held-out coding performance: for gpt-oss-20b, seed+evolved training achieves +8.7 and +8.3 Pass@1 gains on LCB v6 Hard and LCB-Pro Easy, exceeding seed-only gains by 70.7% and 34.8%, respectively. Our results show that BenchEvolver can convert saturated benchmarks into frontier-level evaluation suites and reusable training signal.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BenchEvolver, a solution-centric evolutionary framework that applies structured transformations to reference solutions of existing coding problems (from LiveCodeBench and SciCode) to generate harder variants, then derives corresponding problem statements and tests from the evolved solutions. It claims this produces valid, diverse, and substantially harder tasks; curates LiveCodeBench-Plus (91 problems) on which frontier models achieve only 27.5–62.6% Pass@1; shows that evolved tasks remain challenging even for the generating model; and reports that RL fine-tuning on evolved LCB tasks yields held-out gains of +8.7 and +8.3 Pass@1 (exceeding seed-only by 70.7% and 34.8%) on LCB v6 Hard and LCB-Pro Easy.
Significance. If the transformations reliably preserve executable correctness, test-solution alignment, and increased difficulty without post-hoc filtering, the approach would offer a scalable route to frontier-level coding benchmarks and reusable RL training signal, directly addressing saturation on existing suites such as LiveCodeBench.
major comments (2)
- [Abstract and §4] Abstract and §4 (results on LiveCodeBench-Plus and RL experiments): the central claims of validity, increased hardness, and RL gains exceeding seed-only by 70.7%/34.8% rest on unshown transformation operators, verification procedures for test-solution alignment, and quantitative checks (e.g., reference-solution pass rates on derived tests or Pass@1 difficulty deltas). Without these, the discrimination restored in LiveCodeBench-Plus and the self-improvement results cannot be evaluated.
- [§3] §3 (framework description): the weakest assumption—that structured transformations of reference solutions will reliably produce harder tasks while maintaining executable correctness, validity, and diversity—is stated but not supported by concrete operators, failure-rate statistics, or controls for selection bias, making the load-bearing claim that evolved tasks remain challenging for the generating model untestable from the manuscript.
minor comments (1)
- [Tables/Figures] Table or figure captions should explicitly state the number of evolved tasks retained after any validity filtering and the exact statistical test used for the reported percentage gains.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive feedback on our manuscript. We address each of the major comments below, providing clarifications and indicating revisions where appropriate to strengthen the presentation of our methodology and results.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (results on LiveCodeBench-Plus and RL experiments): the central claims of validity, increased hardness, and RL gains exceeding seed-only by 70.7%/34.8% rest on unshown transformation operators, verification procedures for test-solution alignment, and quantitative checks (e.g., reference-solution pass rates on derived tests or Pass@1 difficulty deltas). Without these, the discrimination restored in LiveCodeBench-Plus and the self-improvement results cannot be evaluated.
Authors: The manuscript describes the solution-centric evolutionary framework in Section 3, which includes the application of structured transformations to reference solutions from LiveCodeBench and SciCode. However, we recognize that explicit details on the transformation operators, verification procedures, and quantitative checks such as reference-solution pass rates and difficulty deltas are not presented in sufficient detail. We will revise the manuscript by adding an appendix that details the specific operators used, provides failure-rate statistics, and includes quantitative verification of test-solution alignment and Pass@1 difficulty deltas. This will allow readers to fully evaluate the claims regarding validity, hardness, and the RL gains reported in Section 4. revision: yes
-
Referee: [§3] §3 (framework description): the weakest assumption—that structured transformations of reference solutions will reliably produce harder tasks while maintaining executable correctness, validity, and diversity—is stated but not supported by concrete operators, failure-rate statistics, or controls for selection bias, making the load-bearing claim that evolved tasks remain challenging for the generating model untestable from the manuscript.
Authors: We agree that Section 3 would benefit from more concrete support for the assumption. The current description outlines the framework but lacks explicit operator definitions, failure rates, and bias controls. In the revised version, we will expand Section 3 to include concrete examples of the transformation operators, empirical failure-rate statistics from the evolution process, and discussion of selection bias controls. This will substantiate the claim that evolved tasks remain challenging for the generating model and make the results more testable. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper describes a procedural evolutionary framework for generating coding tasks via structured transformations of reference solutions, with no equations, mathematical derivations, fitted parameters, or self-referential definitions present. Claims about task hardness, validity, and RL gains rest on the described generation process and empirical evaluations rather than any reduction to inputs by construction or load-bearing self-citations. No instances of the enumerated circularity patterns apply.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Ar- mando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code.arXiv preprint arXiv:2403.07974, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Introducing gpt-5.5
OpenAI. Introducing gpt-5.5. https://openai.com/index/introducing-gpt-5-5/ , 2026
2026
-
[3]
Deepseek-v4: Towards highly efficient million-token context intelligence, 2026
DeepSeek-AI. Deepseek-v4: Towards highly efficient million-token context intelligence, 2026
2026
-
[4]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding.arXiv preprint arXiv:2009.03300, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[5]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. Gpqa: A graduate-level google-proof q&a benchmark.arXiv preprint arXiv:2311.12022, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Scicode: A research coding benchmark curated by scientists.Advances in Neural Information Processing Systems, 37:30624–30650, 2024
Minyang Tian, Luyu Gao, Shizhuo D Zhang, Xinan Chen, Cunwei Fan, Xuefei Guo, Roland Haas, Pan Ji, Kittithat Krongchon, Yao Li, et al. Scicode: A research coding benchmark curated by scientists.Advances in Neural Information Processing Systems, 37:30624–30650, 2024
2024
-
[8]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues?arXiv preprint arXiv:2310.06770, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Mike A Merrill, Alexander G Shaw, Nicholas Carlini, Boxuan Li, Harsh Raj, Ivan Bercovich, Lin Shi, Jeong Yeon Shin, Thomas Walshe, E Kelly Buchanan, et al. Terminal-bench: Benchmarking agents on hard, realistic tasks in command line interfaces.arXiv preprint arXiv:2601.11868, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
Ziyang Luo, Can Xu, Pu Zhao, Qingfeng Sun, Xiubo Geng, Wenxiang Hu, Chongyang Tao, Jing Ma, Qingwei Lin, and Daxin Jiang. Wizardcoder: Empowering code large language models with evol-instruct.arXiv preprint arXiv:2306.08568, 2023
-
[11]
WizardLM: Empowering large pre-trained language models to follow complex instructions
Can Xu, Qingfeng Sun, Kai Zheng, Xiubo Geng, Pu Zhao, Jiazhan Feng, Chongyang Tao, Qingwei Lin, and Daxin Jiang. Wizardlm: Empowering large pre-trained language models to follow complex instructions, 2025. URLhttps://arxiv.org/abs/2304.12244
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Magicoder: Empow- ering code generation with oss-instruct, 2024
Yuxiang Wei, Zhe Wang, Jiawei Liu, Yifeng Ding, and Lingming Zhang. Magicoder: Empow- ering code generation with oss-instruct, 2024. URL https://arxiv.org/abs/2312.02120
-
[13]
Selfcodealign: Self-alignment for code generation.Advances in Neural Information Processing Systems, 37:62787–62874, 2024
Yuxiang Wei, Federico Cassano, Jiawei Liu, Yifeng Ding, Naman Jain, Zachary Mueller, Harm de Vries, Leandro V on Werra, Arjun Guha, and Lingming Zhang. Selfcodealign: Self-alignment for code generation.Advances in Neural Information Processing Systems, 37:62787–62874, 2024
2024
-
[14]
OpenCodeReasoning: Advancing Data Distillation for Competitive Coding
Wasi Uddin Ahmad, Sean Narenthiran, Somshubra Majumdar, Aleksander Ficek, Siddhartha Jain, Jocelyn Huang, Vahid Noroozi, and Boris Ginsburg. Opencodereasoning: Advancing data distillation for competitive coding.arXiv preprint arXiv:2504.01943, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Minh VT Pham, Huy N Phan, Hoang N Phan, Cuong Le Chi, Tien N Nguyen, and Nghi DQ Bui. Swe-synth: Synthesizing verifiable bug-fix data to enable large language models in resolving real-world bugs.arXiv preprint arXiv:2504.14757, 2025
-
[16]
Cansu Sancaktar, David Zhang, Gabriel Synnaeve, and Taco Cohen. A deep dive into scaling rl for code generation with synthetic data and curricula.arXiv preprint arXiv:2603.24202, 2026. 13
-
[17]
Autocode: Llms as problem setters for competitive programming.arXiv preprint arXiv:2510.12803, 2025
Shang Zhou, Zihan Zheng, Kaiyuan Liu, Zeyu Shen, Zerui Cheng, Zexing Chen, Hansen He, Jianzhu Yao, Huanzhi Mao, Qiuyang Mang, et al. Autocode: Llms as problem setters for competitive programming.arXiv preprint arXiv:2510.12803, 2025
-
[18]
Jie Wu, Haoling Li, Xin Zhang, Jiani Guo, Jane Luo, Steven Liu, Yangyu Huang, Ruihang Chu, Scarlett Li, and Yujiu Yang. X-coder: Advancing competitive programming with fully synthetic tasks, solutions, and tests.arXiv preprint arXiv:2601.06953, 2026
-
[19]
Self-challenging language model agents.arXiv preprint arXiv:2506.01716, 2025
Yifei Zhou, Sergey Levine, Jason Weston, Xian Li, and Sainbayar Sukhbaatar. Self-challenging language model agents.arXiv preprint arXiv:2506.01716, 2025
-
[20]
Scaling Self-Play with Self-Guidance
Luke Bailey, Kaiyue Wen, Kefan Dong, Tatsunori Hashimoto, and Tengyu Ma. Scaling self-play with self-guidance.arXiv preprint arXiv:2604.20209, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
Qiushi Sun, Jinyang Gong, Lei Li, Qipeng Guo, and Fei Yuan. Codeevo: Interaction- driven synthesis of code-centric data through hybrid and iterative feedback.arXiv preprint arXiv:2507.22080, 2025
-
[22]
Embarrassingly Simple Self-Distillation Improves Code Generation
Ruixiang Zhang, Richard He Bai, Huangjie Zheng, Navdeep Jaitly, Ronan Collobert, and Yizhe Zhang. Embarrassingly simple self-distillation improves code generation.arXiv preprint arXiv:2604.01193, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
Aozhe Wang, Yuchen Yan, Nan Zhou, Zhengxi Lu, Weiming Lu, Jun Xiao, Yueting Zhuang, and Yongliang Shen. Code-a1: Adversarial evolving of code llm and test llm via reinforcement learning.arXiv preprint arXiv:2603.15611, 2026
-
[24]
Promptbreeder: Self-Referential Self-Improvement Via Prompt Evolution
Chrisantha Fernando, Dylan Banarse, Henryk Michalewski, Simon Osindero, and Tim Rock- täschel. Promptbreeder: Self-referential self-improvement via prompt evolution.arXiv preprint arXiv:2309.16797, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Evoprompt: Connecting llms with evolutionary algorithms yields powerful prompt optimizers.arXiv e-prints, pages arXiv–2309, 2023
Qingyan Guo, Rui Wang, Junliang Guo, Bei Li, Kaitao Song, Xu Tan, Guoqing Liu, Jiang Bian, and Yujiu Yang. Evoprompt: Connecting llms with evolutionary algorithms yields powerful prompt optimizers.arXiv e-prints, pages arXiv–2309, 2023
2023
-
[26]
GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning
Lakshya A Agrawal, Shangyin Tan, Dilara Soylu, Noah Ziems, Rishi Khare, Krista Opsahl-Ong, Arnav Singhvi, Herumb Shandilya, Michael J Ryan, Meng Jiang, et al. Gepa: Reflective prompt evolution can outperform reinforcement learning.arXiv preprint arXiv:2507.19457, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Mathematical discoveries from program search with large language models
Bernardino Romera-Paredes, Mohammadamin Barekatain, Alexander Novikov, Matej Balog, M Pawan Kumar, Emilien Dupont, Francisco JR Ruiz, Jordan S Ellenberg, Pengming Wang, Omar Fawzi, et al. Mathematical discoveries from program search with large language models. Nature, 625(7995):468–475, 2024
2024
-
[28]
AlphaEvolve: A coding agent for scientific and algorithmic discovery
Alexander Novikov, Ngân V˜u, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco JR Ruiz, Abbas Mehrabian, et al. Alphaevolve: A coding agent for scientific and algorithmic discovery.arXiv preprint arXiv:2506.13131, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Automated Design of Agentic Systems
Shengran Hu, Cong Lu, and Jeff Clune. Automated design of agentic systems.arXiv preprint arXiv:2408.08435, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
EvolveR: Self-Evolving LLM Agents through an Experience-Driven Lifecycle
Rong Wu, Xiaoman Wang, Jianbiao Mei, Pinlong Cai, Daocheng Fu, Cheng Yang, Licheng Wen, Xuemeng Yang, Yufan Shen, Yuxin Wang, et al. Evolver: Self-evolving llm agents through an experience-driven lifecycle.arXiv preprint arXiv:2510.16079, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Yangzhen Wu, Zhiqing Sun, Shanda Li, Sean Welleck, and Yiming Yang. Inference scaling laws: An empirical analysis of compute-optimal inference for problem-solving with language models.arXiv preprint arXiv:2408.00724, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Absolute zero: Reinforced self-play reasoning with zero data.Advances in Neural Information Processing Systems, 38:105816–105879, 2026
Andrew Zhao, Yiran Wu, Tong Wu, Quentin Xu, Yang Yue, Matthieu Lin, Shenzhi Wang, Qingyun Wu, Zilong Zheng, and Gao Huang. Absolute zero: Reinforced self-play reasoning with zero data.Advances in Neural Information Processing Systems, 38:105816–105879, 2026. 14
2026
-
[33]
R-zero: Self-evolving reasoning llm from zero data,
Chengsong Huang, Wenhao Yu, Xiaoyang Wang, Hongming Zhang, Zongxia Li, Ruosen Li, Jiaxin Huang, Haitao Mi, and Dong Yu. R-zero: Self-evolving reasoning llm from zero data,
-
[34]
URLhttps://arxiv.org/abs/2508.05004
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models
Qizheng Zhang, Changran Hu, Shubhangi Upasani, Boyuan Ma, Fenglu Hong, Vamsidhar Ka- manuru, Jay Rainton, Chen Wu, Mengmeng Ji, Hanchen Li, et al. Agentic context engineering: Evolving contexts for self-improving language models.arXiv preprint arXiv:2510.04618, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Parshin Shojaee, Ngoc-Hieu Nguyen, Kazem Meidani, Amir Barati Farimani, Khoa D Doan, and Chandan K Reddy. Llm-srbench: A new benchmark for scientific equation discovery with large language models.arXiv preprint arXiv:2504.10415, 2025
-
[37]
Barbarians at the gate: How ai is upending systems research.arXiv preprint arXiv:2510.06189, 2025
Audrey Cheng, Shu Liu, Melissa Pan, Zhifei Li, Bowen Wang, Alex Krentsel, Tian Xia, Mert Cemri, Jongseok Park, Shuo Yang, et al. Barbarians at the gate: How ai is upending systems research.arXiv preprint arXiv:2510.06189, 2025
-
[38]
ShinkaEvolve: Towards Open-Ended And Sample-Efficient Program Evolution
Robert Tjarko Lange, Yuki Imajuku, and Edoardo Cetin. Shinkaevolve: Towards open-ended and sample-efficient program evolution.arXiv preprint arXiv:2509.19349, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Jiachen Jiang, Tianyu Ding, and Zhihui Zhu. Deltaevolve: Accelerating scientific discovery through momentum-driven evolution.arXiv preprint arXiv:2602.02919, 2026
-
[40]
Minghao Yan, Bo Peng, Benjamin Coleman, Ziqi Chen, Zhouhang Xie, Shuo Chen, Zhankui He, Noveen Sachdeva, Isabella Ye, Weili Wang, et al. Pacevolve: Enabling long-horizon progress-aware consistent evolution.arXiv preprint arXiv:2601.10657, 2026
-
[41]
Adaevolve: Adaptive llm driven zeroth-order optimization.arXiv preprint arXiv:2602.20133, 2026
Mert Cemri, Shubham Agrawal, Akshat Gupta, Shu Liu, Audrey Cheng, Qiuyang Mang, Ashwin Naren, Lutfi Eren Erdogan, Koushik Sen, Matei Zaharia, et al. Adaevolve: Adaptive llm driven zeroth-order optimization.arXiv preprint arXiv:2602.20133, 2026
-
[42]
Evox: Meta-evolution for automated discovery.arXiv preprint arXiv:2602.23413, 2026
Shu Liu, Shubham Agarwal, Monishwaran Maheswaran, Mert Cemri, Zhifei Li, Qiuyang Mang, Ashwin Naren, Ethan Boneh, Audrey Cheng, Melissa Z Pan, et al. Evox: Meta-evolution for automated discovery.arXiv preprint arXiv:2602.23413, 2026
-
[43]
CodeEvolve: an open source evolutionary coding agent for algorithmic discovery and optimization
Henrique Assumpção, Diego Ferreira, Leandro Campos, and Fabricio Murai. Codeevolve: an open source evolutionary coding agent for algorithmic discovery and optimization, 2026. URL https://arxiv.org/abs/2510.14150
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[44]
Tinker, 2025
Thinking Machines Lab. Tinker, 2025. URLhttps://thinkingmachines.ai/tinker/. 15 A Additional Related Work Synthetic coding tasks.Synthetic data generation has become a central approach for improving and evaluating LLMs’ coding capabilities, especially as human-written programming tasks are expensive to collect and curate at scale. Early work primarily syn...
2025
-
[45]
""Run an RK4 integrator for pendulum motion
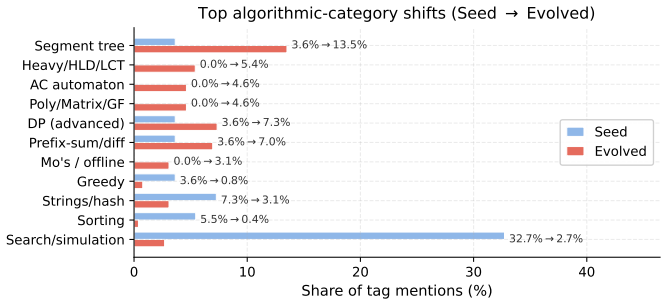
Finally, panels e–f and Figure 9 show that the evolved problems broaden the algorithmic coverage: 20 Config name Purpose LCB SciCode Model and evaluation target_eval_kAttempts per target model for evolved problems.4 4 temperatureSampling temperature for generation.0.8 0.8 timeoutLLM request timeout in seconds.600 600 Difficulty and acceptance allowed_seed...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.