Rethinking Continual Experience Internalization for Self-Evolving LLM Agents
Pith reviewed 2026-06-28 06:25 UTC · model grok-4.3
The pith
Multi-iteration experience internalization in LLMs produces progressive capability collapse instead of improvement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
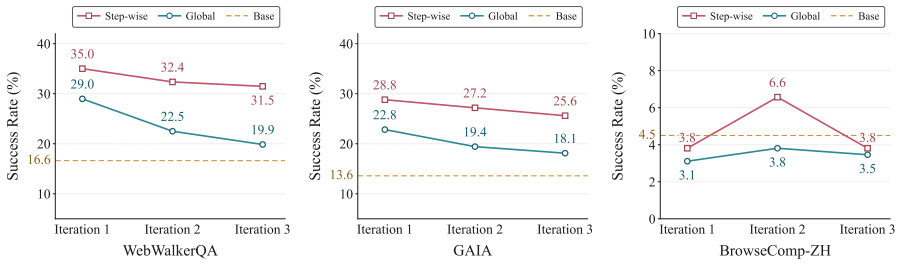
Under multi-iteration experience learning, existing methods suffer from a progressive capability collapse rather than compounding improvement. Systematic examination across three dimensions shows that principle-level experience abstracts transferable strategies more durably than instance-level experience, step-wise injection aligns experience with intermediate decision states better than global injection, and off-policy context-distillation on high-quality teacher trajectories supplies a more stable signal than on-policy distillation limited by student-induced errors. These findings produce a simple recipe for stable and sustainable experience internalization.
What carries the argument
Three dimensions of experience internalization—Experience Granularity (principle-level versus instance-level), Experience Injection Pattern (step-wise versus global), and Internalization Regime (off-policy context-distillation on teacher trajectories versus on-policy)—that determine whether repeated cycles compound or erode capability.
If this is right
- Principle-level experience transfers more reliably across iterations than instance-level experience.
- Step-wise injection maintains alignment with intermediate states and outperforms global injection for long-horizon tasks.
- Off-policy distillation from teacher trajectories avoids the error amplification that on-policy distillation encounters.
- Combining the three adjustments produces a stable recipe that supports continual learning rather than collapse.
- The resulting guidance directly informs engineering of self-evolving LLM agents.
Where Pith is reading between the lines
- The same three dimensions may explain collapse patterns in other continual-learning setups that rely on trajectory data.
- Testing the recipe on open-ended real-world agent deployments could reveal whether the stability holds when task horizons and error distributions differ from the study.
- The preference for teacher trajectories suggests a practical limit on fully autonomous self-improvement without periodic external high-quality data.
Load-bearing premise
The three examined dimensions are the primary drivers of the observed collapse and that the identified recipe will hold outside the specific tasks and setups tested.
What would settle it
A controlled multi-iteration run on the same agent tasks in which the proposed principle-level, step-wise, off-policy recipe still produces net capability decline after five or more cycles.
Figures







read the original abstract
Experience internalization converts contextual experience from past interactions into reusable parametric capability, offering a promising path toward continual learning in large language models (LLMs). While prior work has predominantly focused on single-iteration transfer, we discover that under multi-iteration experience learning, existing methods suffer from a progressive capability collapse rather than compounding improvement. We systematically examine this failure through three vital dimensions of experience internalization: (1) Experience Granularity: We find that principle-level experience is more durable than instance-level experience, as it effectively abstracts transferable strategies away from trajectory-specific details. (2) Experience Injection Pattern: Our analysis reveals that step-wise injection significantly outperforms global injection by aligning experience with intermediate decision states, a property that is critical for long-horizon tool use. (3) Internalization Regime: We demonstrate that off-policy context-distillation on high-quality teacher trajectories provides a substantially more stable training signal than on-policy context-distillation, which is inherently limited by local corrections on student-induced flawed states. Together, these insights yield a simple yet robust recipe for stable and sustainable experience internalization, providing concrete guidance for engineering self-evolving and continually learning LLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that multi-iteration experience internalization in LLM agents leads to progressive capability collapse rather than improvement under existing methods. It systematically analyzes this via three dimensions—Experience Granularity (principle-level abstractions outperform instance-level), Experience Injection Pattern (step-wise injection outperforms global), and Internalization Regime (off-policy context-distillation on high-quality teacher trajectories outperforms on-policy)—and derives a simple recipe for stable continual learning in self-evolving agents.
Significance. If the empirical results hold, the work provides a useful diagnostic framework for a key failure mode in continual agent learning and concrete engineering guidance. The explicit three-dimension breakdown and comparison of injection patterns and regimes are strengths that could inform follow-on studies on long-horizon tool use.
major comments (1)
- [Abstract] Abstract: the recommended recipe centers on off-policy context-distillation from high-quality teacher trajectories, yet the title and stated goal concern purely self-evolving agents that must generate and internalize from their own trajectories. No mechanism is described for bootstrapping or sustaining trajectory quality internally across iterations, weakening the direct applicability of the findings to the target self-evolving setting.
Simulated Author's Rebuttal
We thank the referee for the constructive comment regarding the alignment between our proposed recipe and the purely self-evolving agent setting. We address the point below and will revise the manuscript to improve clarity on this aspect.
read point-by-point responses
-
Referee: [Abstract] Abstract: the recommended recipe centers on off-policy context-distillation from high-quality teacher trajectories, yet the title and stated goal concern purely self-evolving agents that must generate and internalize from their own trajectories. No mechanism is described for bootstrapping or sustaining trajectory quality internally across iterations, weakening the direct applicability of the findings to the target self-evolving setting.
Authors: We agree with the referee that the current experiments and recipe rely on high-quality teacher trajectories for off-policy context-distillation, and the manuscript does not provide a detailed mechanism for bootstrapping or sustaining trajectory quality using only the agent's own self-generated trajectories across iterations. This is a valid observation about the scope of the work. The core analysis demonstrates why on-policy internalization leads to collapse while off-policy with high-quality data is more stable, which remains relevant as a diagnostic and engineering insight. In a self-evolving context, high-quality trajectories could in principle be selected from the agent's own past successful interactions (e.g., via outcome-based filtering), but we did not implement or evaluate such a selection process. To address this, we will revise the abstract to explicitly qualify the role of high-quality trajectories and add a dedicated paragraph in the discussion section outlining how the three-dimensional framework could be integrated into self-evolving loops, including potential use of curated replay buffers. This revision will better delineate the current contributions from the full self-evolving pipeline. revision: yes
Circularity Check
No significant circularity; empirical findings are self-contained
full rationale
The paper conducts an empirical examination of capability collapse under multi-iteration experience learning by testing variations across three dimensions (granularity, injection pattern, internalization regime) and reporting comparative performance. No equations, fitted parameters, or self-citations are presented as load-bearing derivations that reduce the central claims to inputs by construction. The recipe is presented as the outcome of observed experimental differences rather than a self-definitional or renamed result. The analysis remains independent of any prior author work invoked in a circular manner and is falsifiable via replication on the described setups.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A General Language Assistant as a Laboratory for Alignment
A general language assistant as a laboratory for alignment , author=. arXiv preprint arXiv:2112.00861 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
arXiv preprint arXiv:2209.15189 , year=
Learning by distilling context , author=. arXiv preprint arXiv:2209.15189 , year=
-
[3]
arXiv preprint arXiv:2601.13761 , year=
DARC: Decoupled Asymmetric Reasoning Curriculum for LLM Evolution , author=. arXiv preprint arXiv:2601.13761 , year=
-
[4]
2026 , eprint=
From Storage to Experience: A Survey on the Evolution of LLM Agent Memory Mechanisms , author=. 2026 , eprint=
2026
-
[5]
International Conference on Learning Representations , volume=
Synapse: Trajectory-as-exemplar prompting with memory for computer control , author=. International Conference on Learning Representations , volume=
-
[6]
Advances in neural information processing systems , volume=
Reflexion: Language agents with verbal reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[7]
Advances in Neural Information Processing Systems , volume=
A-mem: Agentic memory for llm agents , author=. Advances in Neural Information Processing Systems , volume=
-
[8]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Voyager: An open-ended embodied agent with large language models , author=. arXiv preprint arXiv:2305.16291 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Agent workflow memory , author=. arXiv preprint arXiv:2409.07429 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
ReasoningBank: Scaling Agent Self-Evolving with Reasoning Memory
Reasoningbank: Scaling agent self-evolving with reasoning memory , author=. arXiv preprint arXiv:2509.25140 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models
Agentic context engineering: Evolving contexts for self-improving language models , author=. arXiv preprint arXiv:2510.04618 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
arXiv preprint arXiv:2510.08191 , year=
Training-free group relative policy optimization , author=. arXiv preprint arXiv:2510.08191 , year=
-
[13]
International Conference on Learning Representations , volume=
Minillm: Knowledge distillation of large language models , author=. International Conference on Learning Representations , volume=
-
[14]
International Conference on Learning Representations , volume=
On-policy distillation of language models: Learning from self-generated mistakes , author=. International Conference on Learning Representations , volume=
-
[15]
On-Policy Context Distillation for Language Models
On-policy context distillation for language models , author=. arXiv preprint arXiv:2602.12275 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
RAGEN: Understanding Self-Evolution in LLM Agents via Multi-Turn Reinforcement Learning
Ragen: Understanding self-evolution in llm agents via multi-turn reinforcement learning , author=. arXiv preprint arXiv:2504.20073 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Search-r1: Training llms to reason and leverage search engines with reinforcement learning , author=. arXiv preprint arXiv:2503.09516 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Advances in Neural Information Processing Systems , volume=
Webdancer: Towards autonomous information seeking agency , author=. Advances in Neural Information Processing Systems , volume=
-
[20]
Advances in Neural Information Processing Systems , volume=
Generalizing Experience for Language Agents with Hierarchical MetaFlows , author=. Advances in Neural Information Processing Systems , volume=
-
[21]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Webagent-r1: Training web agents via end-to-end multi-turn reinforcement learning , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[22]
Complementary RL: Towards Efficient Experience-Driven Agent Learning
Complementary Reinforcement Learning , author=. arXiv preprint arXiv:2603.17621 , year=
work page internal anchor Pith review arXiv
-
[23]
arXiv e-prints , pages=
SLEA-RL: Step-Level Experience Augmented Reinforcement Learning for Multi-Turn Agentic Training , author=. arXiv e-prints , pages=
-
[24]
SEARL: Joint Optimization of Policy and Tool Graph Memory for Self-Evolving Agents
SEARL: Joint Optimization of Policy and Tool Graph Memory for Self-Evolving Agents , author=. arXiv preprint arXiv:2604.07791 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning
Skillrl: Evolving agents via recursive skill-augmented reinforcement learning , author=. arXiv preprint arXiv:2602.08234 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Reinforcement Learning for Self-Improving Agent with Skill Library
Reinforcement learning for self-improving agent with skill library , author=. arXiv preprint arXiv:2512.17102 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
EvolveR: Self-Evolving LLM Agents through an Experience-Driven Lifecycle
Evolver: Self-evolving llm agents through an experience-driven lifecycle , author=. arXiv preprint arXiv:2510.16079 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models , author=. arXiv preprint arXiv:2601.18734 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Tongyi DeepResearch Technical Report
Tongyi deepresearch technical report , author=. arXiv preprint arXiv:2510.24701 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
arXiv preprint arXiv:2509.10446 , year=
Deepdive: Advancing deep search agents with knowledge graphs and multi-turn rl , author=. arXiv preprint arXiv:2509.10446 , year=
-
[31]
arXiv preprint arXiv:2507.15061 , year=
Webshaper: Agentically data synthesizing via information-seeking formalization , author=. arXiv preprint arXiv:2507.15061 , year=
-
[32]
WebSailor: Navigating Super-human Reasoning for Web Agent
Websailor: Navigating super-human reasoning for web agent , author=. arXiv preprint arXiv:2507.02592 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Webwalker: Benchmarking llms in web traversal , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[34]
International Conference on Learning Representations , volume=
Gaia: a benchmark for general ai assistants , author=. International Conference on Learning Representations , volume=
-
[35]
Proceedings of the Twentieth European Conference on Computer Systems , pages=
Hybridflow: A flexible and efficient rlhf framework , author=. Proceedings of the Twentieth European Conference on Computer Systems , pages=
-
[36]
Learning beyond Teacher: Generalized On-Policy Distillation with Reward Extrapolation
Learning beyond teacher: Generalized on-policy distillation with reward extrapolation , author=. arXiv preprint arXiv:2602.12125 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
Rethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe
Rethinking on-policy distillation of large language models: Phenomenology, mechanism, and recipe , author=. arXiv preprint arXiv:2604.13016 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
Distilling the Knowledge in a Neural Network
Distilling the knowledge in a neural network , author=. arXiv preprint arXiv:1503.02531 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
arXiv preprint arXiv:2404.14387 , year=
A survey on self-evolution of large language models , author=. arXiv preprint arXiv:2404.14387 , year=
-
[40]
A comprehensive survey of self-evolving ai agents: A new paradigm bridging foundation models and lifelong agentic systems , author=. arXiv preprint arXiv:2508.07407 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
R-Zero: Self-Evolving Reasoning LLM from Zero Data
R-zero: Self-evolving reasoning llm from zero data , author=. arXiv preprint arXiv:2508.05004 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
Advances in Neural Information Processing Systems , volume=
Absolute zero: Reinforced self-play reasoning with zero data , author=. Advances in Neural Information Processing Systems , volume=
-
[43]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Contextual experience replay for self-improvement of language agents , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[44]
arXiv preprint arXiv:2511.16043 , year=
Agent0: Unleashing self-evolving agents from zero data via tool-integrated reasoning , author=. arXiv preprint arXiv:2511.16043 , year=
-
[45]
Online Experiential Learning for Language Models
Online experiential learning for language models , author=. arXiv preprint arXiv:2603.16856 , year=
work page internal anchor Pith review arXiv
-
[46]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[49]
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[51]
Advances in neural information processing systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in neural information processing systems , volume=
-
[52]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
2024 , eprint=
ExpeL: LLM Agents Are Experiential Learners , author=. 2024 , eprint=
2024
-
[54]
Google AI , volume=
Welcome to the era of experience , author=. Google AI , volume=
-
[55]
Proceedings of the 31st International Conference on Computational Linguistics , pages=
Distilling rule-based knowledge into large language models , author=. Proceedings of the 31st International Conference on Computational Linguistics , pages=
-
[56]
Uni-OPD: Unifying On-Policy Distillation with a Dual-Perspective Recipe
Uni-OPD: Unifying on-policy distillation with a dual-perspective recipe , author=. arXiv preprint arXiv:2605.03677 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[57]
Revisiting On-Policy Distillation: Empirical Failure Modes and Simple Fixes
Revisiting on-policy distillation: Empirical failure modes and simple fixes , author=. arXiv preprint arXiv:2603.25562 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[58]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[59]
Openai o1 system card , author=. arXiv preprint arXiv:2412.16720 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[60]
Agentic Reasoning for Large Language Models
Agentic reasoning for large language models , author=. arXiv preprint arXiv:2601.12538 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[61]
Evaluating Large Language Models Trained on Code
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[62]
Advances in neural information processing systems , volume=
Toolformer: Language models can teach themselves to use tools , author=. Advances in neural information processing systems , volume=
-
[63]
International Conference on Learning Representations , volume=
Toolllm: Facilitating large language models to master 16000+ real-world apis , author=. International Conference on Learning Representations , volume=
-
[64]
StarCoder: may the source be with you!
Starcoder: may the source be with you! , author=. arXiv preprint arXiv:2305.06161 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[65]
Qwen3-Coder-Next Technical Report
Qwen3-coder-next technical report , author=. arXiv preprint arXiv:2603.00729 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[66]
arXiv preprint arXiv:2602.21320 , year=
Tool-R0: Self-Evolving LLM Agents for Tool-Learning from Zero Data , author=. arXiv preprint arXiv:2602.21320 , year=
-
[67]
ReAct: Synergizing Reasoning and Acting in Language Models
React: Synergizing reasoning and acting in language models , author=. arXiv preprint arXiv:2210.03629 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[68]
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
Ui-tars: Pioneering automated gui interaction with native agents , author=. arXiv preprint arXiv:2501.12326 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[69]
Proceedings of the 2024 conference on empirical methods in natural language processing , pages=
A survey on in-context learning , author=. Proceedings of the 2024 conference on empirical methods in natural language processing , pages=
2024
-
[70]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[71]
From Explicit CoT to Implicit CoT: Learning to Internalize CoT Step by Step
From explicit cot to implicit cot: Learning to internalize cot step by step , author=. arXiv preprint arXiv:2405.14838 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[72]
arXiv preprint arXiv:2412.14964 , year=
Efficient knowledge injection in llms via self-distillation , author=. arXiv preprint arXiv:2412.14964 , year=
-
[73]
arXiv preprint arXiv:2602.15902 , year=
Doc-to-lora: Learning to instantly internalize contexts , author=. arXiv preprint arXiv:2602.15902 , year=
-
[74]
arXiv preprint arXiv:2402.01364 , year=
Continual learning for large language models: A survey , author=. arXiv preprint arXiv:2402.01364 , year=
-
[75]
A survey of self-evolving agents: On path to artificial super intelligence , author=. arXiv preprint arXiv:2507.21046 , volume=
work page internal anchor Pith review Pith/arXiv arXiv
-
[76]
BrowseComp-ZH: Benchmarking Web Browsing Ability of Large Language Models in Chinese
Browsecomp-zh: Benchmarking web browsing ability of large language models in chinese , author=. arXiv preprint arXiv:2504.19314 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[77]
2025 , eprint=
DeepSeek-V3 Technical Report , author=. 2025 , eprint=
2025
-
[78]
DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence , author=
-
[79]
Self-Distillation Enables Continual Learning
Self-Distillation Enables Continual Learning , author=. arXiv preprint arXiv:2601.19897 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.