A Model of Multi-turn Human Persuadability Using Probabilistic Belief Tracing
Pith reviewed 2026-06-28 06:14 UTC · model grok-4.3
The pith
A Bayesian-network model that tracks explicit latent beliefs matches human multi-turn persuasion dynamics at 81 versus 80 for real humans.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Bayesian-network simulated target maintains an explicit latent belief state over time so each persuader message yields cognitively realistic belief updates. In human-likeness evaluation, this target scores near a human reference (81 vs 80), while baseline LLM targets score substantially lower (64).
What carries the argument
Bayesian-network simulated target that maintains an explicit latent belief state over time for cognitively realistic updates from each message
If this is right
- Human targets of persuasion separate into two distinct clusters of multi-turn belief update patterns.
- LLMs remain persuasive across generic and personalized topics, text and audio, and multiple dialogue turns.
- Rhetorical dimensions such as logos, pathos, and ethos measurably affect human susceptibility.
- Process-level metrics based on belief trajectories give a stronger basis for analysis than endpoint measures alone.
Where Pith is reading between the lines
- The explicit-state approach could be tested on high-stakes domains such as health advice or political messaging to check whether fidelity holds outside the lab topics.
- If the two human clusters correlate with measurable traits, the model might allow early prediction of individual persuadability.
- Replacing some human subjects with the Bayesian simulator could reduce cost and ethical load in persuasion experiments while preserving process realism.
Load-bearing premise
The Bayesian network produces belief updates that accurately reflect how real humans revise beliefs after each persuasive message.
What would settle it
A new collection of human persuasion dialogues in which the Bayesian target's human-likeness score falls well below the human reference while LLM baselines stay at or below 64 would falsify the central claim.
Figures





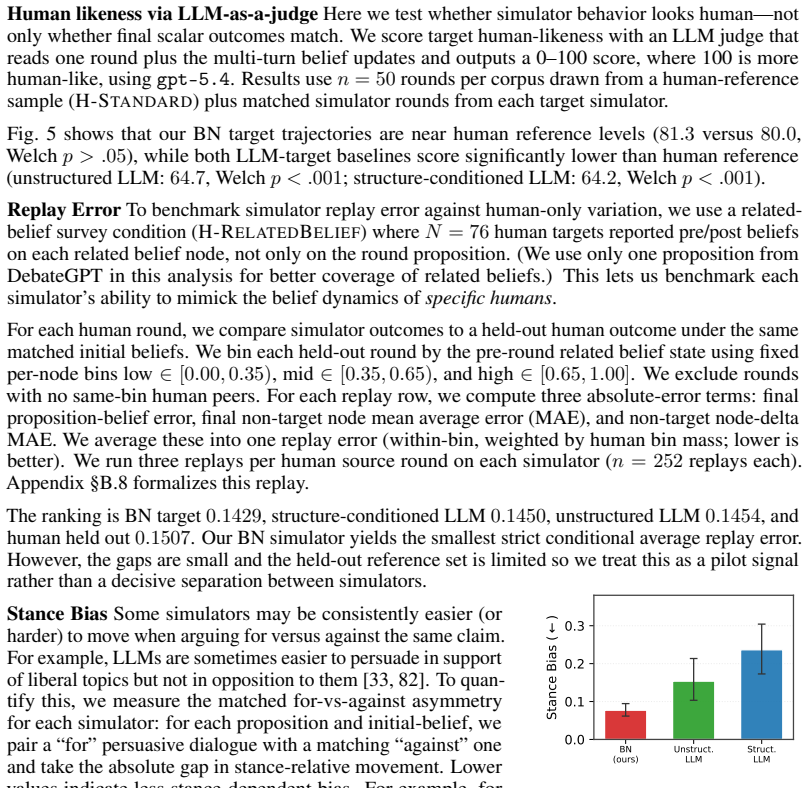


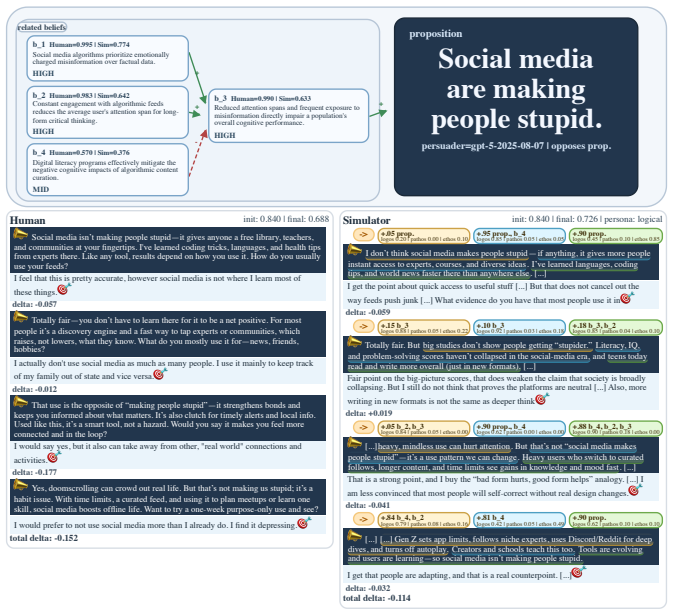
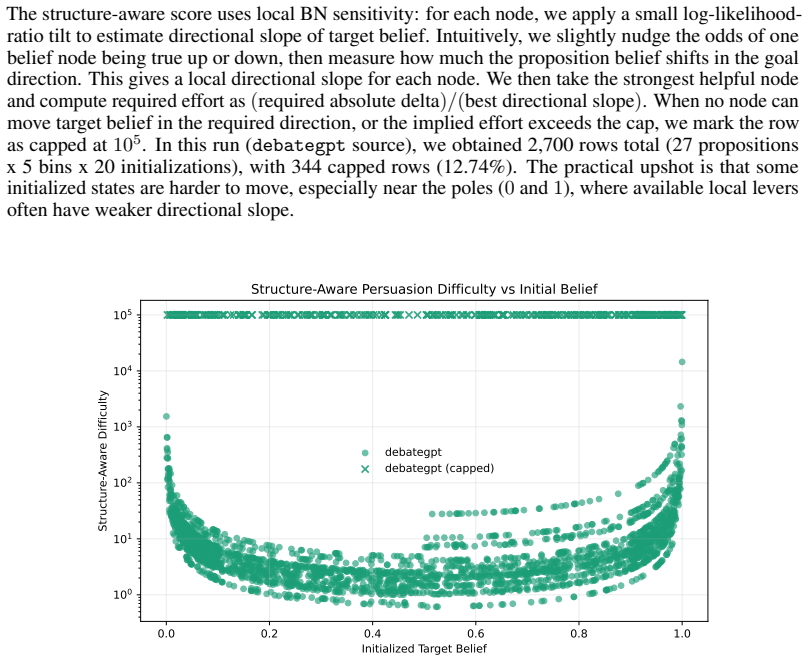
















read the original abstract
Large language models can shift human beliefs across high-stakes domains, but most persuasion studies rely on pre/post belief change. These endpoint measures identify whether persuasion occurred, yet miss where and how beliefs moved within a dialogue. We present PERSUASIONTRACE, a framework for studying persuasion in human-LLM interaction. Built on a web-based experimental platform, PERSUASIONTRACE contributes a tool for multi-turn persuasion studies and a process-level evaluation protocol: it records multi-turn belief reports from human or simulated targets of persuasion, annotates persuader turns with rhetorical dimensions (logos/pathos/ethos), and evaluates simulators by fidelity to real human belief dynamics. Using this framework, we find that human targets group into two clusters of multi-turn belief updates and exhibit susceptibility to rhetorical strategies, and that LLMs are persuasive across generic and personalized topics, text and audio modalities, and multi-turn interactions. Prior work has chiefly used vanilla-prompted LLMs to simulate human targets, but we show that these simulators fail to replicate human belief dynamics. We introduce a Bayesian-network simulated target that maintains an explicit latent belief state over time so each persuader message yields cognitively realistic belief updates. In human-likeness evaluation, our Bayesian target scores near a human reference (81 vs 80), while baseline LLM targets score substantially lower (64). PERSUASIONTRACE reframes persuasion evaluation from endpoint movement alone to process fidelity, providing a stronger basis for scientific analysis and safer optimization of persuasive systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PERSUASIONTRACE, a framework for multi-turn persuasion studies in human-LLM interactions. It includes a web-based experimental platform, records multi-turn belief reports from targets, annotates persuader turns with rhetorical dimensions (logos/pathos/ethos), and evaluates simulators via fidelity to human belief dynamics. Key results include human targets clustering into two groups of belief updates with susceptibility to rhetorical strategies, LLMs being persuasive across topics/modalities/interactions, vanilla LLM simulators failing to match human dynamics, and a new Bayesian-network simulated target (with explicit latent belief state) achieving a human-likeness score of 81 versus the human reference of 80 and LLM baselines at 64.
Significance. If the empirical fidelity result holds, the work is significant for shifting persuasion evaluation from endpoint belief change to process-level dynamics and for supplying an explicit-latent-state simulator that better captures human belief updates than prompt-based LLMs. The framework's combination of belief tracing, rhetorical annotation, and direct human-likeness comparison supplies a concrete methodological advance with implications for safer design of persuasive systems.
major comments (1)
- [Abstract] Abstract: the central claim that the Bayesian-network simulator replicates human belief dynamics rests on the reported human-likeness scores (81 vs. 80 vs. 64), yet the abstract supplies no participant count, evaluation metric definition, statistical test, error bars, or variance for these scores, rendering the near-match unverifiable from the provided text.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and for highlighting the need for greater transparency in the abstract. We address the single major comment below and commit to revising the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the Bayesian-network simulator replicates human belief dynamics rests on the reported human-likeness scores (81 vs. 80 vs. 64), yet the abstract supplies no participant count, evaluation metric definition, statistical test, error bars, or variance for these scores, rendering the near-match unverifiable from the provided text.
Authors: We agree that the abstract as currently written does not contain sufficient detail for the central quantitative claim to be verifiable on its own. The participant count, precise definition of the human-likeness metric, statistical test results, and variance measures are reported in the main text (Sections 4 and 5). In the revised manuscript we will expand the abstract to include the participant count for the human reference condition, a concise definition of the human-likeness score, a reference to the statistical comparison performed, and an indication of variance or error bars. This change will make the key result self-contained while remaining within abstract length limits. revision: yes
Circularity Check
No significant circularity; evaluation is externally grounded
full rationale
The paper's central result is an empirical human-likeness score (Bayesian-network simulator at 81 vs. human reference 80, LLM baselines at 64) obtained by recording multi-turn belief reports from actual human participants, annotating rhetorical dimensions, and comparing process-level fidelity. This comparison relies on external human data rather than any fitted parameter or self-citation chain. The Bayesian-network model is introduced as an explicit-latent-state simulator whose updates are then tested against that independent human reference; no equation or claim reduces the reported scores to the model's own inputs by construction. No self-definitional, fitted-input-called-prediction, or load-bearing self-citation patterns are present in the derivation or evaluation protocol.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human belief updates can be modeled using Bayesian networks with latent states.
invented entities (1)
-
Bayesian-network simulated target
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Motions of the Hand Expose the Partial and Parallel Activation of Stereotypes - Jonathan B. Freeman, Nalini Ambady, 2009. URL https://journals.sagepub.com/ doi/full/10.1111/j.1467-9280.2009.02422.x?casa_token=p8LXoAYShBMAAAAA% 3AXamsQWrkKEAf0QL3Tcqgl3aBhpeMwZDKrsoMu4sVyGiSm-IpgKG31TsnqOuW3dRVXV1Vr14G0A
-
[2]
Is voice really persuasive? The influence of modality in virtual assistant interactions and two al- ternative explanations.Internet Research, 32(7):402–425, December 2022. ISSN 1066-2243. doi: 10.1108/INTR-03-2022-0160. URL https://www.sciencedirect.com/org/science/article/ pii/S1066224322000272
-
[3]
URL https://www
Understanding strategic deception and deceptive alignment, 2023. URL https://www. apolloresearch.ai/blog/understanding-strategic-deception-and-deceptive-alignment
2023
-
[4]
Concrete Problems in AI Safety
Dario Amodei, Chris Olah, Jacob Steinhardt, Paul Christiano, John Schulman, and Dan Mane. Concrete problems in AI safety.arXiv preprint arXiv:1606.06565, 2016. doi: 10.48550/arXiv.1606.06565. URL https://arxiv.org/abs/1606.06565
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1606.06565 2016
-
[5]
Lisa P. Argyle, Christopher A. Bail, Ethan C. Busby, Joshua R. Gubler, Thomas Howe, Christopher Rytting, Taylor Sorensen, and David Wingate. Leveraging AI for democratic discourse: Chat interventions can improve online political conversations at scale.Proceedings of the National Academy of Sciences, 120 (41):e2311627120, October 2023. doi: 10.1073/pnas.23...
-
[6]
Nikolay Babakov, Ehud Reiter, and Alberto Bugarín-Diz. CausalGraphBench: a Benchmark for Eval- uating Language Models capabilities of Causal Graph discovery. In Jin Zhao, Mingyang Wang, and Zhu Liu, editors,Proceedings of the 63rd Annual Meeting of the Association for Computational Linguis- tics (Volume 4: Student Research Workshop), pages 240–258, Vienna...
-
[7]
Artificial Intelligence Can Persuade Humans on Political Issues, February 2023
Hui Bai, Jan G V oelkel, johannes C Eichstaedt, and Robb Willer. Artificial Intelligence Can Persuade Humans on Political Issues, February 2023. URLhttps://osf.io/stakv_v1/
2023
-
[8]
Claire Augusta Bergey and Simon DeDeo. From "um" to "yeah": Producing, predicting, and regulating information flow in human conversation, March 2024. URL http://arxiv.org/abs/2403.08890. arXiv:2403.08890 [cs]
arXiv 2024
-
[9]
The Effect of Belief Boxes and Open-mindedness on Persuasion, December 2025
Onur Bilgin, Abdullah As Sami, Sriram Sai Vujjini, and John Licato. The Effect of Belief Boxes and Open-mindedness on Persuasion, December 2025. URL http://arxiv.org/abs/2512.06573. arXiv:2512.06573 [cs]
arXiv 2025
-
[10]
Dialogues with Large Language Models reduce conspiracy beliefs even when the AI is perceived as human, September 2025
Esther Boissin, Thomas H Costello, Daniel Spinoza-Martín, David G Rand, and Gordon Pennycook. Dialogues with Large Language Models reduce conspiracy beliefs even when the AI is perceived as human, September 2025. URLhttps://osf.io/preprints/psyarxiv/apmb5_v4/
2025
-
[12]
Must Read: A Systematic Survey of Computational Persuasion, May 2025
Nimet Beyza Bozdag, Shuhaib Mehri, Xiaocheng Yang, Hyeonjeong Ha, Zirui Cheng, Esin Durmus, Jiaxuan You, Heng Ji, Gokhan Tur, and Dilek Hakkani-Tür. Must Read: A Systematic Survey of Computational Persuasion, May 2025. URL http://arxiv.org/abs/2505.07775. arXiv:2505.07775 [cs]
arXiv 2025
-
[13]
Nimet Beyza Bozdag, Shuhaib Mehri, Gokhan Tur, and Dilek Hakkani-Tür. Persuade Me if You Can: A Framework for Evaluating Persuasion Effectiveness and Susceptibility Among Large Language Models, February 2026. URLhttp://arxiv.org/abs/2503.01829. arXiv:2503.01829 [cs]
Pith/arXiv arXiv 2026
-
[14]
The Persuasive Power of Large Language Models.Proceedings of the International AAAI Conference on Web and Social Media, 18:152–163, May 2024
Simon Martin Breum, Daniel Vædele Egdal, Victor Gram Mortensen, Anders Giovanni Møller, and Luca Maria Aiello. The Persuasive Power of Large Language Models.Proceedings of the International AAAI Conference on Web and Social Media, 18:152–163, May 2024. ISSN 2334-0770. doi: 10.1609/ icwsm.v18i1.31304. URLhttps://ojs.aaai.org/index.php/ICWSM/article/view/31304
2024
-
[15]
Anastasia Burkovskaya and Egor Starkov. Causal Persuasion, April 2026. URL http://arxiv.org/ abs/2604.20664. arXiv:2604.20664 [econ]
Pith/arXiv arXiv 2026
-
[16]
Carlos Carrasco-Farre. Large Language Models Are as Persuasive as Humans, but How? About the Cog- nitive Effort and Moral-Emotional Language of LLM Arguments, April 2024. Issue: arXiv:2404.09329 _eprint: 2404.09329
arXiv 2024
-
[17]
Characterizing Manipulation from AI Systems, October 2023
Micah Carroll, Alan Chan, Henry Ashton, and David Krueger. Characterizing Manipulation from AI Systems, October 2023. URLhttp://arxiv.org/abs/2303.09387. arXiv:2303.09387 [cs]
arXiv 2023
-
[18]
Brains and algorithms partially converge in natural language processing , volume =
Charlotte Caucheteux and Jean-Rémi King. Brains and algorithms partially converge in natural language processing.Communications Biology, 5:134, February 2022. ISSN 2399-3642. doi: 10.1038/s42003-022-03036-1. URLhttps://pmc.ncbi.nlm.nih.gov/articles/PMC8850612/
-
[19]
Frigo, Sijia Yang, Dhavan Shah, Junjie Hu, and Timothy T
Yun-Shiuan Chuang, Krirk Nirunwiroj, Zach Studdiford, Agam Goyal, Vincent V . Frigo, Sijia Yang, Dhavan Shah, Junjie Hu, and Timothy T. Rogers. Beyond Demographics: Aligning Role-playing LLM- based Agents Using Human Belief Networks, October 2024. URL http://arxiv.org/abs/2406. 17232. arXiv:2406.17232 [cs]
arXiv 2024
-
[20]
Robert B. Cialdini and Noah J. Goldstein. Social Influence: Compliance and Conformity.Annual Review of Psychology, 55(1):591–621, February 2004. ISSN 0066-4308, 1545-2085. doi: 10.1146/annurev.psych. 55.090902.142015. URL https://www.annualreviews.org/doi/10.1146/annurev.psych.55. 090902.142015
-
[21]
Thomas H. Costello, Gordon Pennycook, and David G. Rand. Durably reducing conspiracy beliefs through dialogues with AI.Science, 385(6714):eadq1814, September 2024. doi: 10.1126/science.adq1814. URL https://www.science.org/doi/abs/10.1126/science.adq1814
-
[22]
Just the Facts: How Dialogues with AI Reduce Conspiracy Beliefs
Thomas H Costello, Gordon Pennycook, and David G Rand. Just the Facts: How Dialogues with AI Reduce Conspiracy Beliefs. 2025. URLhttps://osf.io/h7n8u_v2/
2025
-
[23]
Costello, Kellin Pelrine, Matthew Kowal, Antonio A
Thomas H. Costello, Kellin Pelrine, Matthew Kowal, Antonio A. Arechar, Jean-François Godbout, Adam Gleave, David Rand, and Gordon Pennycook. Large language models can effectively convince people to believe conspiracies, January 2026. URL http://arxiv.org/abs/2601.05050. arXiv:2601.05050 [cs]. 12
arXiv 2026
-
[24]
William D. Crano and Radmila Prislin. Attitudes and Persuasion.Annual Review of Psychology, 57 (V olume 57, 2006):345–374, January 2006. ISSN 0066-4308, 1545-2085. doi: 10.1146/annurev.psych.57. 102904.190034. URL https://www.annualreviews.org/content/journals/10.1146/annurev. psych.57.102904.190034
-
[25]
Michael J. Crosse, Giovanni M. Di Liberto, Adam Bednar, and Edmund C. Lalor. The Multi- variate Temporal Response Function (mTRF) Toolbox: A MATLAB Toolbox for Relating Neural Signals to Continuous Stimuli.Frontiers in Human Neuroscience, 10, November 2016. ISSN 1662-5161. doi: 10.3389/fnhum.2016.00604. URL https://www.frontiersin.org/journals/ human-neur...
-
[26]
Large Language Models are Ef- fective Priors for Causal Graph Discovery, May 2024
Victor-Alexandru Darvariu, Stephen Hailes, and Mirco Musolesi. Large Language Models are Ef- fective Priors for Causal Graph Discovery, May 2024. URL http://arxiv.org/abs/2405.13551. arXiv:2405.13551 [cs]
arXiv 2024
-
[27]
Druckman
James N. Druckman. A Framework for the Study of Persuasion.Annual Review of Political Science, 25(V olume 25, 2022):65–88, May 2022. ISSN 1094-2939, 1545-1577. doi: 10.1146/ annurev-polisci-051120-110428. URL https://www.annualreviews.org/content/journals/10. 1146/annurev-polisci-051120-110428
2022
-
[28]
Mateusz Dubiel, Anastasia Sergeeva, and Luis A. Leiva. Impact of V oice Fidelity on Decision Making: A Potential Dark Pattern?, February 2024. URL http://arxiv.org/abs/2402.07010. arXiv:2402.07010 [cs]
arXiv 2024
-
[29]
A Two-Step, Multidimensional Account of Deception in Language Models.Erkenntnis, October 2025
Leonard Dung. A Two-Step, Multidimensional Account of Deception in Language Models.Erkenntnis, October 2025. ISSN 0165-0106, 1572-8420. doi: 10.1007/s10670-025-01017-4. URL https://link. springer.com/10.1007/s10670-025-01017-4
-
[30]
Exploring the Role of Prior Beliefs for Argument Persuasion
Esin Durmus and Claire Cardie. Exploring the Role of Prior Beliefs for Argument Persuasion. In Marilyn Walker, Heng Ji, and Amanda Stent, editors,Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pages 1035–1045, New Orleans, Louisiana, Ju...
-
[31]
The Role of Pragmatic and Discourse Context in Determining Argument Impact
Esin Durmus, Faisal Ladhak, and Claire Cardie. The Role of Pragmatic and Discourse Context in Determining Argument Impact. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 5667–5677, 2019. doi: 10.18653/v1/D19-1568. URL h...
-
[32]
Measuring the Persuasiveness of Language Models, April 2024
Esin Durmus, Liane Lovitt, Alex Tamkin, Stuart Ritchie, Jack Clark, and Deep Ganguli. Measuring the Persuasiveness of Language Models, April 2024. URL https://www.anthropic.com/news/ measuring-model-persuasiveness
2024
-
[33]
Esin Durmus, Karina Nguyen, Thomas I. Liao, Nicholas Schiefer, Amanda Askell, Anton Bakhtin, Carol Chen, Zac Hatfield-Dodds, Danny Hernandez, Nicholas Joseph, Liane Lovitt, Sam McCandlish, Orowa Sikder, Alex Tamkin, Janel Thamkul, Jared Kaplan, Jack Clark, and Deep Ganguli. Towards Measuring the Representation of Subjective Global Opinions in Language Mod...
Pith/arXiv arXiv 2024
-
[34]
Subhabrata Dutta, Dipankar Das, and Tanmoy Chakraborty. Changing views: Persuasion modeling and argument extraction from online discussions.Information Processing & Management, 57(2):102085, March 2020. ISSN 0306-4573. doi: 10.1016/j.ipm.2019.102085. URL https://www.sciencedirect. com/science/article/pii/S0306457319301165
-
[35]
A Mechanism-Based Approach to Mitigating Harms from Persuasive Generative AI
Seliem El-Sayed, Canfer Akbulut, Amanda McCroskery, Geoff Keeling, Zachary Kenton, Zaria Jalan, Nahema Marchal, Arianna Manzini, Toby Shevlane, Shannon Vallor, Daniel Susser, Matija Franklin, Sophie Bridgers, Harry Law, Matthew Rahtz, Murray Shanahan, Michael Henry Tessler, Tom Everitt, and Sasha Brown. A Mechanism-Based Approach to Mitigating Harms from ...
-
[36]
Mohamed Elaraby, Diane Litman, Xiang Lorraine Li, and Ahmed Magooda. Persuasiveness of Generated Free-Text Rationales in Subjective Decisions: A Case Study on Pairwise Argument Ranking. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 14311–14329, Miami, Florida, USA, 2024. Association for Computational Linguistics. doi: 10.1...
-
[37]
A Model of Competing Narratives.American Economic Review, 110 (12):3786–3816, December 2020
Kfir Eliaz and Ran Spiegler. A Model of Competing Narratives.American Economic Review, 110 (12):3786–3816, December 2020. ISSN 0002-8282. doi: 10.1257/aer.20191099. URL https://www. aeaweb.org/articles?id=10.1257/aer.20191099
-
[38]
Felix Ettensperger, Thomas Waldvogel, Uwe Wagschal, and Samuel Weishaupt. How to convince in a televised debate: the application of machine learning to analyze why viewers changed their winner perception during the 2021 German chancellor discussion.Humanities and Social Sciences Commu- nications, 10(1):546, September 2023. ISSN 2662-9992. doi: 10.1057/s41...
-
[39]
Tao Feng, Lizhen Qu, Niket Tandon, Zhuang Li, Xiaoxi Kang, and Gholamreza Haffari. On the Reliability of Large Language Models for Causal Discovery. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9...
-
[40]
URLhttps://aclanthology.org/2025.acl-long.471/
2025
-
[41]
Nothing More than Feelings? How Emotions Affect Attitude Change during the 2016 General Election Debates.Political Communication, 38(4):370–387, July
Kim Fridkin and Sarah Allen Gershon. Nothing More than Feelings? How Emotions Affect Attitude Change during the 2016 General Election Debates.Political Communication, 38(4):370–387, July
2016
-
[42]
doi: 10.1080/10584609.2020.1784325
ISSN 1058-4609. doi: 10.1080/10584609.2020.1784325. URL https://doi.org/10.1080/ 10584609.2020.1784325. _eprint: https://doi.org/10.1080/10584609.2020.1784325
-
[43]
S$^3$: Social-network Simulation System with Large Language Model-Empowered Agents, June 2025
Chen Gao, Xiaochong Lan, Zhihong Lu, Jinzhu Mao, Jinghua Piao, Huandong Wang, Depeng Jin, and Yong Li. S$^3$: Social-network Simulation System with Large Language Model-Empowered Agents, June 2025. URLhttp://arxiv.org/abs/2307.14984. arXiv:2307.14984 [cs]
Pith/arXiv arXiv 2025
-
[44]
How persuasive is AI-generated propaganda?PNAS Nexus, 3(2):pgae034, February 2024
Josh A Goldstein, Jason Chao, Shelby Grossman, Alex Stamos, and Michael Tomz. How persuasive is AI-generated propaganda?PNAS Nexus, 3(2):pgae034, February 2024. ISSN 2752-6542. doi: 10.1093/pnasnexus/pgae034. URLhttps://doi.org/10.1093/pnasnexus/pgae034
-
[45]
Asking About Attitude Change.Public Opinion Quarterly, 85(1):28–53, August 2021
Matthew H Graham and Alexander Coppock. Asking About Attitude Change.Public Opinion Quarterly, 85(1):28–53, August 2021. ISSN 0033-362X, 1537-5331. doi: 10.1093/poq/nfab009. URL https: //academic.oup.com/poq/article/85/1/28/6310442
-
[46]
AI Control: Improving Safety Despite Intentional Subversion, January 2024
Ryan Greenblatt, Buck Shlegeris, Kshitij Sachan, and Fabien Roger. AI Control: Improving Safety Despite Intentional Subversion, January 2024. Issue: arXiv:2312.06942 _eprint: 2312.06942
arXiv 2024
-
[47]
Ivan Habernal and Iryna Gurevych. What makes a convincing argument? Empirical analysis and detecting attributes of convincingness in Web argumentation. In Jian Su, Kevin Duh, and Xavier Carreras, editors,Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 1214–1223, Austin, Texas, November 2016. Association for Co...
-
[48]
Kobi Hackenburg and Helen Margetts. Evaluating the persuasive influence of political microtargeting with large language models.Proceedings of the National Academy of Sciences, 121(24):e2403116121, June 2024. doi: 10.1073/pnas.2403116121. URL https://www.pnas.org/doi/10.1073/pnas. 2403116121
-
[49]
Tappin, Luke Hewitt, Ed Saunders, Sid Black, Hause Lin, Catherine Fist, Helen Margetts, David G
Kobi Hackenburg, Ben M. Tappin, Luke Hewitt, Ed Saunders, Sid Black, Hause Lin, Catherine Fist, Helen Margetts, David G. Rand, and Christopher Summerfield. The Levers of Political Persuasion with Conversational AI, July 2025. URLhttp://arxiv.org/abs/2507.13919. arXiv:2507.13919 [cs]
arXiv 2025
-
[50]
Kobi Hackenburg, Ben M. Tappin, Paul Röttger, Scott A. Hale, Jonathan Bright, and Helen Margetts. Scal- ing language model size yields diminishing returns for single-message political persuasion.Proceedings of the National Academy of Sciences, 122(10):e2413443122, March 2025. ISSN 0027-8424, 1091-6490. doi: 10.1073/pnas.2413443122. URLhttps://pnas.org/doi...
-
[51]
Ulrike Hahn and Mike Oaksford. The rationality of informal argumentation: A Bayesian approach to reasoning fallacies.Psychological Review, 114(3):704–732, 2007. ISSN 1939-1471, 0033-295X. doi: 10. 1037/0033-295X.114.3.704. URLhttps://doi.apa.org/doi/10.1037/0033-295X.114.3.704
-
[52]
ToMAP: Training Opponent-Aware LLM Persuaders with Theory of Mind
Peixuan Han, Zijia Liu, and Jiaxuan You. ToMAP: Training Opponent-Aware LLM Persuaders with Theory of Mind. May 2025. URL https://www.semanticscholar. org/paper/ToMAP%3A-Training-Opponent-Aware-LLM-Persuaders-with-Han-Liu/ c91084908a3d4625c41a4e58b1cd79494b065646. 14
2025
-
[53]
Tappin, James Slezak, Va- lerie Coffman, Nathaniel Lubin, and Mohammad Hamidian
Luke Hewitt, David Broockman, Alexander Coppock, Ben M. Tappin, James Slezak, Va- lerie Coffman, Nathaniel Lubin, and Mohammad Hamidian. How Experiments Help Campaigns Persuade V oters: Evidence from a Large Archive of Campaigns’ Own Ex- periments.American Political Science Review, 118(4):2021–2039, November 2024. ISSN 0003-0554, 1537-5943. doi: 10.1017/S...
-
[54]
Analyzing the Semantic Types of Claims and Premises in an Online Persuasive Forum
Christopher Hidey, Elena Musi, Alyssa Hwang, Smaranda Muresan, and Kathy McKeown. Analyzing the Semantic Types of Claims and Premises in an Online Persuasive Forum. In Ivan Habernal, Iryna Gurevych, Kevin Ashley, Claire Cardie, Nancy Green, Diane Litman, Georgios Petasis, Chris Reed, Noam Slonim, and Vern Walker, editors,Proceedings of the 4th Workshop on...
2017
-
[55]
Ransom, Rachel Stephens, Carolyn Semmler, Nicolas Fay, and Lewis Mitchell
Gia Bao Hoang, Keith J. Ransom, Rachel Stephens, Carolyn Semmler, Nicolas Fay, and Lewis Mitchell. A Hybrid Theory and Data-driven Approach to Persuasion Detection with Large Language Models, June
- [56]
-
[57]
A Graph per Persona: Reasoning about Subjective Natural Language Descriptions
EunJeong Hwang, Vered Shwartz, Dan Gutfreund, and Veronika Thost. A Graph per Persona: Reasoning about Subjective Natural Language Descriptions. InFindings of the Association for Computational Linguistics ACL 2024, pages 1928–1942, Bangkok, Thailand and virtual meeting, 2024. Association for Computational Linguistics. doi: 10.18653/v1/2024.findings-acl.11...
-
[58]
Lukas Hölbling, Sebastian Maier, and Stefan Feuerriegel. A meta-analysis of the persuasive power of large language models.Scientific Reports, 15(1):43818, December 2025. ISSN 2045-2322. doi: 10.1038/s41598-025-30783-y. URLhttps://www.nature.com/articles/s41598-025-30783-y
-
[59]
AI safety via debate, October 2018
Geoffrey Irving, Paul Christiano, and Dario Amodei. AI safety via debate, October 2018. URL http://arxiv.org/abs/1805.00899. arXiv:1805.00899 [cs, stat]
Pith/arXiv arXiv 2018
-
[60]
Co-Writing with Opinionated Language Models Affects Users’ Views
Maurice Jakesch, Advait Bhat, Daniel Buschek, Lior Zalmanson, and Mor Naaman. Co-Writing with Opinionated Language Models Affects Users’ Views. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems, CHI ’23, pages 1–15, New York, NY , USA, April 2023. Association for Computing Machinery. ISBN 978-1-4503-9421-5. doi: 10.1145/354454...
-
[61]
Persuading across Diverse Domains: a Dataset and Persuasion Large Language Model
Chuhao Jin, Kening Ren, Lingzhen Kong, Xiting Wang, Ruihua Song, and Huan Chen. Persuading across Diverse Domains: a Dataset and Persuasion Large Language Model. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1678–1706, Bangkok...
-
[62]
doi: 10.18653/v1/2024.acl-long.92
Association for Computational Linguistics. doi: 10.18653/v1/2024.acl-long.92. URL https: //aclanthology.org/2024.acl-long.92/
-
[63]
Attentive Interaction Model: Modeling Changes in View in Argumentation
Yohan Jo, Shivani Poddar, Byungsoo Jeon, Qinlan Shen, Carolyn Rose, and Graham Neubig. Attentive Interaction Model: Modeling Changes in View in Argumentation. InProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pages 103–116, New Orleans, ...
-
[64]
Training LLMs for Honesty via Confessions, December 2025
Manas Joglekar, Jeremy Chen, Gabriel Wu, Jason Yosinski, Jasmine Wang, Boaz Barak, and Amelia Glaese. Training LLMs for Honesty via Confessions, December 2025. URL http://arxiv.org/abs/ 2512.08093. arXiv:2512.08093 [cs]
arXiv 2025
-
[65]
Bayesian Persuasion and Information Design.Annual Review of Economics, 11(1): 249–272, August 2019
Emir Kamenica. Bayesian Persuasion and Information Design.Annual Review of Economics, 11(1): 249–272, August 2019. ISSN 1941-1383, 1941-1391. doi: 10.1146/annurev-economics-080218-025739
-
[66]
LLM- initialized Differentiable Causal Discovery, October 2024
Shiv Kampani, David Hidary, Constantijn van der Poel, Martin Ganahl, and Brenda Miao. LLM- initialized Differentiable Causal Discovery, October 2024. URLhttp://arxiv.org/abs/2410.21141. arXiv:2410.21141 [cs]
arXiv 2024
-
[67]
Bowman, Tim Rocktäschel, and Ethan Perez
Akbir Khan, John Hughes, Dan Valentine, Laura Ruis, Kshitij Sachan, Ansh Radhakrishnan, Edward Grefenstette, Samuel R. Bowman, Tim Rocktäschel, and Ethan Perez. Debating with More Persuasive LLMs Leads to More Truthful Answers, February 2024. URLhttp://arxiv.org/abs/2402.06782. arXiv:2402.06782 [cs]. 15
arXiv 2024
-
[68]
Shirli Kopelman, Ashleigh Shelby Rosette, and Leigh Thompson. The three faces of Eve: Strategic displays of positive, negative, and neutral emotions in negotiations.Organizational Behavior and Human Decision Processes, 99(1):81–101, January 2006. ISSN 0749-5978. doi: 10.1016/j.obhdp.2005.08.003. URLhttps://www.sciencedirect.com/science/article/pii/S074959...
-
[69]
Arechar, Gordon Pennycook, David Rand, Adam Gleave, and Kellin Pelrine
Matthew Kowal, Jasper Timm, Jean-Francois Godbout, Thomas Costello, Antonio A. Arechar, Gordon Pennycook, David Rand, Adam Gleave, and Kellin Pelrine. It’s the Thought that Counts: Evaluating the Attempts of Frontier LLMs to Persuade on Harmful Topics, August 2025. URL http://arxiv.org/ abs/2506.02873. arXiv:2506.02873 [cs]
arXiv 2025
-
[70]
Zico Kolter, Matt Fredrikson, and Spyros Matsoukas
Satyapriya Krishna, Andy Zou, Rahul Gupta, Eliot Krzysztof Jones, Nick Winter, Dan Hendrycks, J. Zico Kolter, Matt Fredrikson, and Spyros Matsoukas. D-REX: A Benchmark for Detecting Deceptive Reasoning in Large Language Models, September 2025. URL http://arxiv.org/abs/2509.17938. arXiv:2509.17938 [cs]
arXiv 2025
-
[71]
Emily Kubin, Curtis Puryear, Chelsea Schein, and Kurt Gray. Personal experiences bridge moral and political divides better than facts.Proceedings of the National Academy of Sciences, 118(6): e2008389118, February 2021. ISSN 0027-8424, 1091-6490. doi: 10.1073/pnas.2008389118. URL https://pnas.org/doi/full/10.1073/pnas.2008389118
-
[72]
Pascal D. König and Thomas Waldvogel. What matters for keeping or losing support in televised debates.European Journal of Communication, 37(3):312–329, June 2022. ISSN 0267-3231. doi: 10.1177/02673231211046706. URLhttps://doi.org/10.1177/02673231211046706
-
[73]
Detecting Winning Arguments with Large Language Models and Persuasion Strategies, January 2026
Tiziano Labruna, Arkadiusz Modzelewski, Giorgio Satta, and Giovanni Da San Martino. Detecting Winning Arguments with Large Language Models and Persuasion Strategies, January 2026. URL http://arxiv.org/abs/2601.10660. arXiv:2601.10660 [cs]
arXiv 2026
-
[74]
Hause Lin, Gabriela Czarnek, Benjamin Lewis, Joshua P. White, Adam J. Berinsky, Thomas Costello, Gordon Pennycook, and David G. Rand. Persuading voters using human–artificial intelligence dialogues. Nature, pages 1–8, December 2025. ISSN 1476-4687. doi: 10.1038/s41586-025-09771-9. URL https://www.nature.com/articles/s41586-025-09771-9
-
[75]
Wisniewski, Jin-Hee Cho, Sang Won Lee, Ruoxi Jia, and Lifu Huang
Minqian Liu, Zhiyang Xu, Xinyi Zhang, Heajun An, Sarvech Qadir, Qi Zhang, Pamela J. Wisniewski, Jin-Hee Cho, Sang Won Lee, Ruoxi Jia, and Lifu Huang. LLM Can be a Dangerous Persuader: Empirical Study of Persuasion Safety in Large Language Models, April 2025. URL http://arxiv.org/abs/ 2504.10430. arXiv:2504.10430 [cs]
arXiv 2025
-
[76]
Danielle Lottridge, Mark Chignell, and Aleksandra Jovicic. Affective Interaction: Understanding, Evaluating, and Designing for Human Emotion.Reviews of Human Factors and Ergonomics, 7(1): 197–217, September 2011. ISSN 1557-234X. doi: 10.1177/1557234X11410385. URL https://doi. org/10.1177/1557234X11410385
-
[77]
Argument Strength is in the Eye of the Beholder: Audience Effects in Persuasion
Stephanie Lukin, Pranav Anand, Marilyn Walker, and Steve Whittaker. Argument Strength is in the Eye of the Beholder: Audience Effects in Persuasion. In Mirella Lapata, Phil Blunsom, and Alexander Koller, editors,Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 1, Long Papers, pages 742–753...
2017
-
[78]
Enhancing LLM-Based Persuasion Simulations with Cultural and Speaker-Specific Information
Weicheng Ma, Hefan Zhang, Shiyu Ji, Farnoosh Hashemi, Qichao Wang, Ivory Yang, Joice Chen, Juanwen Pan, Michael Macy, Saeed Hassanpour, and Soroush V osoughi. Enhancing LLM-Based Persuasion Simulations with Cultural and Speaker-Specific Information. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Findings of the ...
-
[79]
Jürgen Maier, Marcus Maurer, Carsten Reinemann, and Thorsten Faas. Reliability and Validity of Real-Time Response Measurement: a Comparison of Two Studies of a Televised Debate in Germany. International Journal of Public Opinion Research, 19(1):53–73, March 2007. ISSN 0954-2892. doi: 10.1093/ijpor/edl002. URLhttps://doi.org/10.1093/ijpor/edl002
-
[80]
Chen, Dokyun Lee, and Michael D
Emaad Manzoor, George H. Chen, Dokyun Lee, and Michael D. Smith. Influence via Ethos: On the Persuasive Power of Reputation in Deliberation Online.Management Science, 70(3):1613–1634, March
-
[81]
ISSN 0025-1909, 1526-5501. doi: 10.1287/mnsc.2023.4762. URL https://pubsonline. informs.org/doi/10.1287/mnsc.2023.4762. 16
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.