Let It Be Simple: One-Step Action Generation for Vision-Language-Action Models
Pith reviewed 2026-06-28 03:08 UTC · model grok-4.3
The pith
Simple bias toward high-noise timesteps in diffusion training enables one-step VLA policies to match or exceed ten-step decoding on standard benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under the condition-target asymmetry of VLA models, where the policy receives rich multimodal observations yet predicts only a compact low-dimensional action chunk, biasing the diffusion training time distribution toward high-noise timesteps produces one-step generators whose performance matches or exceeds that of ten-step decoding without teacher models, distillation, or extra objectives.
What carries the argument
High-noise biased training time distribution applied to standard velocity-prediction diffusion for action-chunk generation.
If this is right
- One-step policies match ten-step decoding across LIBERO, LIBERO-Plus, and LIBERO-Pro under the same training recipe.
- On standard LIBERO the one-step model exceeds the ten-step model trained with uniform time distribution.
- A 1.4B VLM with 30M action head reaches 95.6 percent success on LIBERO-Long using one-step decoding.
- Real-robot bimanual evaluation reproduces the same sampler trend across architectures.
Where Pith is reading between the lines
- The same bias schedule could be tested on other conditional generation problems that share rich context but compact output structure.
- Optimal bias strength may vary with action dimensionality, suggesting a tunable hyperparameter rather than a fixed recipe.
- If the asymmetry assumption holds, VLA research can focus on conditioning quality rather than on importing full image-generation few-step machinery.
Load-bearing premise
The action output remains a compact low-dimensional chunk even when the conditioning inputs are rich and multimodal.
What would settle it
A controlled experiment in which one-step policies trained with the high-noise bias fall short of ten-step decoding on a task whose action space is higher-dimensional or less structured than the LIBERO chunks.
Figures

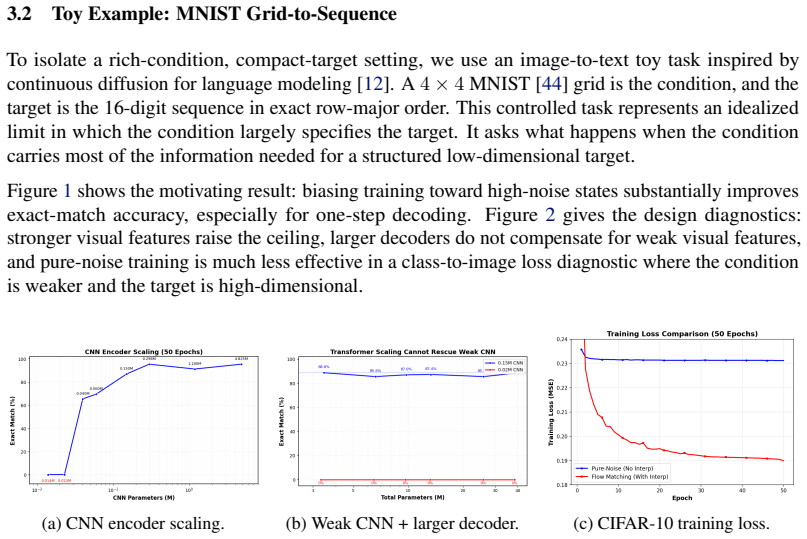
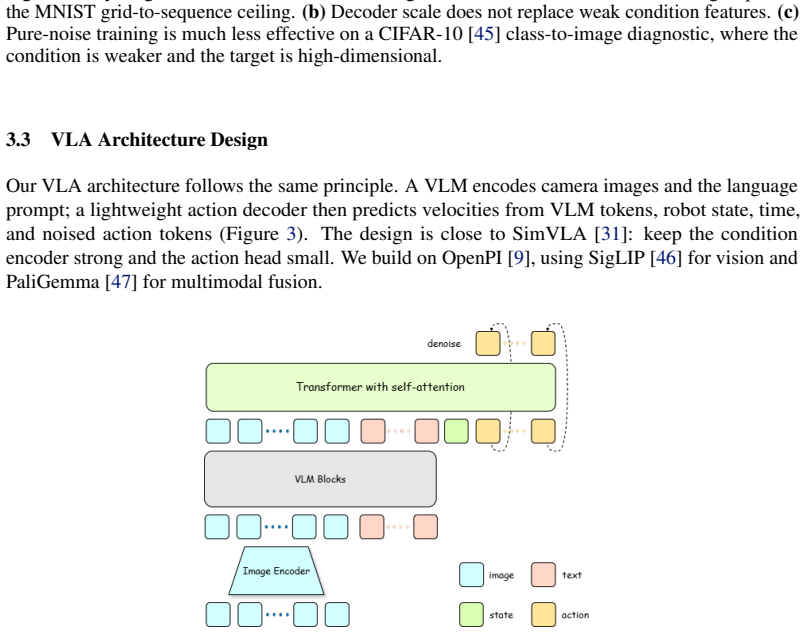
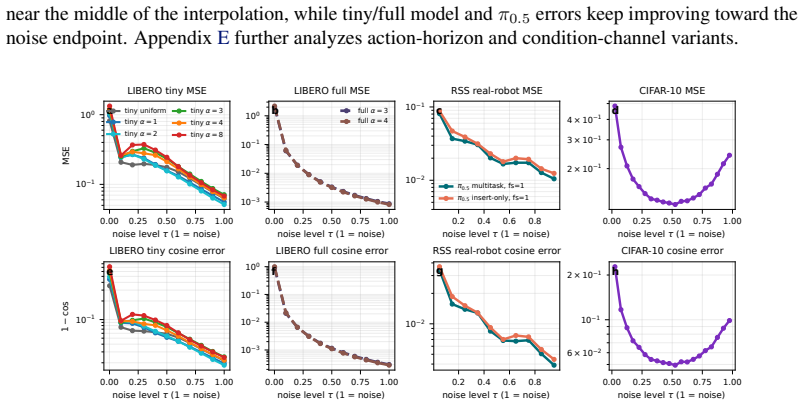


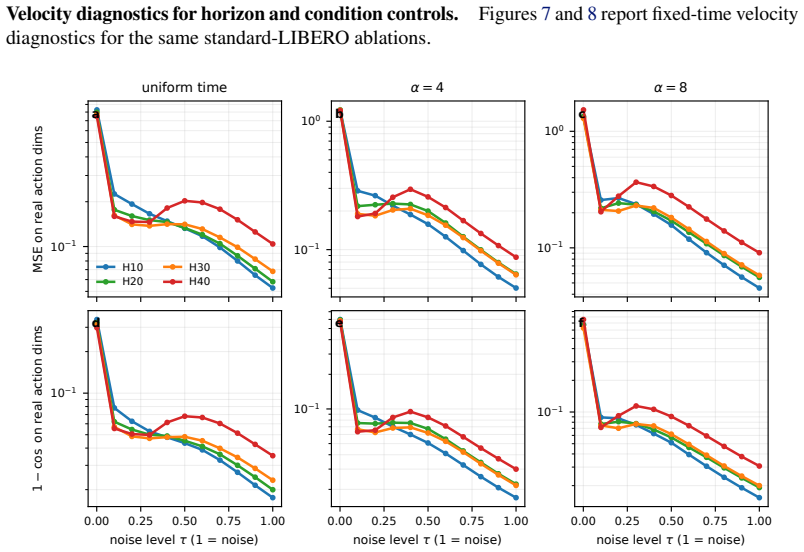



read the original abstract
Diffusion-based vision-language-action (VLA) models often inherit the image-generation view: actions are generated by iterative denoising. We argue that VLA action generation has a different condition-target structure: the policy is conditioned on rich observations, language, and state, but predicts only a compact, low-dimensional action chunk. Under this asymmetry, strong one-step action generation should not necessarily require the advanced one-step methods developed for image synthesis. We keep standard velocity prediction and add no teacher model, distillation stage, or auxiliary objective; in our main recipe, we simply bias the training time distribution toward high-noise states. We first isolate the effect in a controlled MNIST grid-to-sequence task, then test it with extensive robot-policy experiments. Across standard LIBERO, LIBERO-Plus, and LIBERO-Pro, one-step policies trained with high-noise biased schedules generally match ten-step decoding under the same recipe, and on standard LIBERO can exceed ten-step policies trained with a uniform time distribution. A real-robot bimanual YAM RSS evaluation gives a small-sample cross-architecture check of the same sampler trend. On a 1.4B VLM model with a 30M action head, one-step decoding reaches 95.6\% on LIBERO-Long. These results show that strong one-step VLA action generation can emerge from standard diffusion training, without importing the full few-step diffusion machinery developed for image generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that due to the asymmetry in VLA models (rich conditioning on observations/language/state versus compact low-dimensional action chunks), standard velocity-prediction diffusion training with a high-noise biased timestep distribution enables effective one-step action generation without advanced image-synthesis techniques, teacher models, or distillation. This is isolated on an MNIST grid-to-sequence task and validated empirically on LIBERO, LIBERO-Plus, LIBERO-Pro (one-step matching or exceeding ten-step, e.g. 95.6% on LIBERO-Long), plus a real-robot bimanual YAM RSS check.
Significance. If the results hold, the work shows that VLA policies can achieve strong one-step performance from minimal modifications to standard diffusion training. Credit is due for the controlled isolation experiment, direct comparisons on standard benchmarks without new parameters beyond bias strength, absence of auxiliary objectives, and the real-robot cross-check providing an external validation point.
major comments (2)
- [Abstract] Abstract: the claim that one-step policies 'can exceed ten-step policies trained with a uniform time distribution' on standard LIBERO rests on point estimates (e.g., 95.6% on LIBERO-Long) without reported variance, number of runs, or standard deviations; this weakens assessment of whether the exceedance is reliable.
- [Experiments] Experiments section: the repeated assertion of results 'under the same recipe' requires explicit confirmation that all hyperparameters except the time-distribution bias (learning rate, optimizer, total steps, batch size, etc.) are identical between one-step and ten-step conditions; without this, the comparison is not fully controlled.
minor comments (2)
- [Abstract] Abstract: specify the numerical value or schedule parameters of the 'high-noise bias strength' used in the primary LIBERO experiments to aid reproducibility.
- [MNIST task] The MNIST isolation task description should include exact grid dimensions, sequence lengths, and noise schedule details so the controlled effect can be replicated independently.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and for recognizing the value of the controlled MNIST isolation experiment, direct benchmark comparisons, and real-robot validation. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that one-step policies 'can exceed ten-step policies trained with a uniform time distribution' on standard LIBERO rests on point estimates (e.g., 95.6% on LIBERO-Long) without reported variance, number of runs, or standard deviations; this weakens assessment of whether the exceedance is reliable.
Authors: We agree that variance estimates or multiple runs would allow a stronger statistical assessment of the exceedance. The reported numbers (including 95.6% on LIBERO-Long) are single-run point estimates, which is common in large-scale robotics experiments given the compute cost. We will revise the abstract to qualify the claim by noting that results are from single training runs per condition and will not perform additional runs for this revision. revision: partial
-
Referee: [Experiments] Experiments section: the repeated assertion of results 'under the same recipe' requires explicit confirmation that all hyperparameters except the time-distribution bias (learning rate, optimizer, total steps, batch size, etc.) are identical between one-step and ten-step conditions; without this, the comparison is not fully controlled.
Authors: All other hyperparameters are identical by design; the only change is the timestep sampling distribution. We will add an explicit statement in the Experiments section confirming that learning rate, optimizer, total training steps, batch size, model architecture, and all other settings remain unchanged between the one-step and ten-step conditions. revision: yes
Circularity Check
No significant circularity
full rationale
The paper advances an empirical claim that biasing the training-time distribution toward high-noise timesteps enables one-step velocity-prediction policies to match or exceed multi-step decoding on LIBERO benchmarks. No derivation chain, equations, or fitted-parameter predictions are present; the argument rests on controlled experiments (MNIST grid-to-sequence followed by robot-policy suites) and direct performance comparisons under identical recipes. No self-citations, ansatzes, or uniqueness theorems are invoked as load-bearing premises. The result is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
free parameters (1)
- high-noise bias strength
axioms (1)
- domain assumption Standard velocity-prediction diffusion process applies to compact action chunks.
Reference graph
Works this paper leans on
-
[1]
J. Ho, A. Jain, and P. Abbeel. Denoising diffusion probabilistic models. InNeurIPS, 2020
2020
-
[2]
Y . Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole. Score-based generative modeling through stochastic differential equations. InICLR, 2021
2021
-
[3]
T. X. Pham, K. Zhang, J. W. Hong, and C. D. Yoo. A hidden semantic bottleneck in conditional embeddings of diffusion transformers. InICLR, 2026
2026
-
[4]
Y . Song, P. Dhariwal, M. Chen, and I. Sutskever. Consistency models. InICML, 2023
2023
-
[5]
T. Yin, M. Gharbi, R. Zhang, E. Shechtman, F. Durand, W. T. Freeman, and T. Park. One-step diffusion with distribution matching distillation. InCVPR, pages 6613–6623, 2024
2024
-
[6]
Frans, D
K. Frans, D. Hafner, S. Levine, and P. Abbeel. One step diffusion via shortcut models. InICLR, 2025
2025
-
[7]
Z. Geng, M. Deng, X. Bai, J. Z. Kolter, and K. He. Mean flows for one-step generative modeling. InNeurIPS, 2025. URL https://papers.neurips.cc/paper_files/paper/ 2025/hash/6d13e085b79d454da5910e4ca82a3d9d-Abstract-Conference.html
2025
-
[8]
N. M. Boffi, M. S. Albergo, and E. Vanden-Eijnden. Flow map matching with stochastic interpolants: A mathematical framework for consistency models.Transactions on Machine Learning Research, 2025. URLhttps://openreview.net/forum?id=cqDH0e6ak2
2025
-
[9]
K. Black, N. Brown, D. Driess, A. Esmail, M. R. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, L. X. Shi, L. Smith, J. Tanner, Q. Vuong, A. Walling, H. Wang, and U. Zhilinsky.π0: A vision- language-action flow model for general robot control. InRobotics: Sc...
-
[10]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10–11):1684–1704, 2025. doi:10.1177/02783649241273668
-
[11]
Octo Model Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, C. Xu, J. Luo, T. Kreiman, Y . Tan, L. Y . Chen, P. Sanketi, Q. Vuong, T. Xiao, D. Sadigh, C. Finn, and S. Levine. Octo: An open-source generalist robot policy. InRobotics: Science and Systems, Delft, Netherlands, 2024. doi:10.15607/rss.2024.xx.090
-
[12]
Y . Chen, C. Liang, H. Sui, R. Guo, C. Cheng, J. You, and G. Liu. LangFlow: Continuous diffusion rivals discrete in language modeling. arXiv preprint arXiv:2604.11748, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. LIBERO: Benchmarking knowledge transfer for lifelong robot learning. InNeurIPS Datasets and Benchmarks, pages 44776–44791, 2023
2023
-
[14]
S. Fei, S. Wang, J. Shi, Z. Dai, J. Cai, P. Qian, L. Ji, X. He, S. Zhang, Z. Fei, J. Fu, J. Gong, and X. Qiu. LIBERO-Plus: In-depth robustness analysis of vision-language-action models. arXiv preprint arXiv:2510.13626, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
X. Zhou, Y . Xu, G. Tie, Y . Chen, G. Zhang, D. Chu, P. Zhou, and L. Sun. LIBERO-PRO: Towards robust and fair evaluation of vision-language-action models beyond memorization. arXiv preprint arXiv:2510.03827, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
Zhang, Y
S. Zhang, Y . Wang, H. Chang, H. Zhao, Y . Liu, V . Guizilini, A. Bobu, A. Wagenmaker, A. Dixit, C. Yu, D. Shah, and M. Simchowitz. Post-training for robotics foundation models dataset and challenge. RSS 2026 Workshop & Challenge, 2026. URL https: //posttraining-for-robotics.github.io. 9
2026
-
[17]
Black, N
K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. R. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner, Q. Vuong, H. Walke...
2025
-
[18]
Brohan, N
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Haus- man, A. Herzog, J. Hsu, J. Ibarz, B. Ichter, A. Irpan, T. Jackson, S. Jesmonth, N. J. Joshi, R. Julian, D. Kalashnikov, Y . Kuang, I. Leal, K.-H. Lee, S. Levine, Y . Lu, U. Malla, D. Manju- nath, I. Mordatch, O. Nachum, C. Parada, J. Peralta, E. Perez, K. Pertsc...
-
[19]
doi:10.15607/rss.2023.xix.025
-
[20]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, Q. Vuong, V . Vanhoucke, H. Tran, R. Soricut, A. Singh, J. Singh, P. Sermanet, P. R. Sanketi, G. Salazar, M. S. Ryoo, K. Reymann, K. Rao, K. Pertsch, I. Mordatch, H. Michalewski, Y . Lu, S. Levine, L. Lee, T.-W. E. Lee, I. Leal, Y . Kuang, D. Kalashnikov, R. Julia...
2023
-
[21]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. P. Foster, P. R. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn. OpenVLA: An open-source vision-language-action model. InProceedings of The 8th Conference on Robot Learning, volume 270 ofProceedings of Machine Learni...
2025
-
[22]
K. Pertsch, K. Stachowicz, B. Ichter, D. Driess, S. Nair, Q. Vuong, O. Mees, C. Finn, and S. Levine. FAST: Efficient action tokenization for vision-language-action models. InRobotics: Science and Systems, 2025. doi:10.15607/rss.2025.xxi.012
-
[23]
K. Tian, Y . Jiang, Z. Yuan, B. Peng, and L. Wang. Visual autoregressive modeling: Scalable image generation via next-scale prediction. InNeurIPS, pages 84839–84865, 2024
2024
-
[24]
L. Yu, Y . Cheng, K. Sohn, J. Lezama, H. Zhang, H. Chang, A. G. Hauptmann, M.-H. Yang, Y . Hao, I. Essa, and L. Jiang. MAGVIT: Masked generative video transformer. InCVPR, pages 10459–10469, 2023
2023
-
[25]
L. Yu, J. Lezama, N. B. Gundavarapu, L. Versari, K. Sohn, D. Minnen, Y . Cheng, A. Gupta, X. Gu, A. G. Hauptmann, B. Gong, M.-H. Yang, I. Essa, D. Ross, and L. Jiang. Language model beats diffusion: Tokenizer is key to visual generation. InICLR, 2024
2024
-
[26]
Y . Liu, S. Zhang, Z. Dong, B. Ye, T. Yuan, X. Yu, L. Yin, C. Lu, J. Shi, L. J.-T. Yu, L. Zheng, J. Gong, T. Jiang, X. Qiu, and H. Zhao. FASTer: Toward powerful and efficient autoregressive vision–language–action models with learnable action tokenizer and block-wise decoding. In ICLR, 2026. URLhttps://openreview.net/forum?id=k6nTUFoqeT
2026
-
[27]
Rombach, A
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer. High-resolution image synthesis with latent diffusion models. InCVPR, pages 10674–10685, 2022. 10
2022
- [28]
-
[29]
Dieleman
S. Dieleman. Generative modelling in latent space. Blog post, 2025. URL https://sander. ai/2025/04/15/latents.html
2025
-
[30]
J. Yao, B. Yang, and X. Wang. Reconstruction vs. generation: Taming optimization dilemma in latent diffusion models. InCVPR, pages 15703–15712, 2025
2025
-
[31]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
NVIDIA, J. Bjorck, F. Casta˜neda, N. Cherniadev, X. Da, R. Ding, L. J. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, J. Jang, Z. Jiang, J. Kautz, K. Kundalia, L. Lao, Z. Li, Z. Lin, K. Lin, G. Liu, E. Llontop, L. Magne, A. Mandlekar, A. Narayan, S. Nasiriany, S. Reed, Y . L. Tan, G. Wang, Z. Wang, J. Wang, Q. Wang, J. Xiang, Y . Xie, Y . Xu, Z. Xu, S. Ye, Z. Yu...
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [32]
-
[33]
Y . Wang, P. Ding, L. Li, C. Cui, Z. Ge, X. Tong, W. Song, H. Zhao, W. Zhao, P. Hou, S. Huang, Y . Tang, W. Wang, R. Zhang, J. Liu, and D. Wang. VLA-Adapter: An effective paradigm for tiny-scale vision-language-action model.Proceedings of the AAAI Conference on Artificial Intelligence, 40(22):18638–18646, 2026. doi:10.1609/aaai.v40i22.38931
-
[34]
Radford, J
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever. Learning transferable visual models from natural language supervision. InICML, 2021
2021
-
[35]
Raffel, N
C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y . Zhou, W. Li, and P. J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of Machine Learning Research, 2020
2020
-
[36]
W. Kong, Q. Tian, Z. Zhang, R. Min, Z. Dai, J. Zhou, J. Xiong, X. Li, B. Wu, J. Zhang, K. Wu, Q. Lin, J. Yuan, Y . Long, A. Wang, A. Wang, C. Li, D. Huang, F. Yang, H. Tan, H. Wang, J. Song, J. Bai, J. Wu, J. Xue, J. Wang, K. Wang, M. Liu, P. Li, S. Li, W. Wang, W. Yu, X. Deng, Y . Li, Y . Chen, Y . Cui, Y . Peng, Z. Yu, Z. He, Z. Xu, Z. Zhou, Z. Xu, Y . ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
X. Liu, C. Gong, and Q. Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InICLR, 2023. URLhttps://openreview.net/forum?id=XVjTT1nw5z
2023
- [38]
-
[39]
W. Luan, J. Li, W. Zhao, W. Zhang, T. Wu, and R. Ma. SnapFlow: One-step action generation for flow-matching VLAs via progressive self-distillation. arXiv preprint arXiv:2604.05656, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[40]
Esser, S
P. Esser, S. Kulal, A. Blattmann, R. Entezari, J. M¨uller, H. Saini, Y . Levi, D. Lorenz, A. Sauer, F. Boesel, D. Podell, T. Dockhorn, Z. English, and R. Rombach. Scaling rectified flow trans- formers for high-resolution image synthesis. InICML, 2024
2024
-
[41]
Li and K
T. Li and K. He. Back to basics: Let denoising generative models denoise. InCVPR, pages 36115–36125, 2026
2026
-
[42]
Zheng, N
B. Zheng, N. Ma, S. Tong, and S. Xie. Diffusion transformers with representation autoencoders. InThe Fourteenth International Conference on Learning Representations, 2026. URLhttps: //openreview.net/forum?id=0u1LigJaab. 11
2026
-
[43]
Lipman, R
Y . Lipman, R. T. Q. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling. InICLR, 2023
2023
-
[44]
M. S. Albergo, N. M. Boffi, and E. Vanden-Eijnden. Stochastic interpolants: A unifying framework for flows and diffusions.Journal of Machine Learning Research, 26(209):1–80,
-
[45]
URLhttps://jmlr.org/papers/v26/23-1605.html
-
[46]
LeCun, C
Y . LeCun, C. Cortes, and C. J. C. Burges. The MNIST database of handwritten digits. Website,
-
[47]
URLhttps://yann.lecun.com/exdb/mnist/
-
[48]
Krizhevsky
A. Krizhevsky. Learning multiple layers of features from tiny images. Technical report, University of Toronto, 2009
2009
-
[49]
X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer. Sigmoid loss for language image pre-training. InICCV, pages 11941–11952, 2023
2023
-
[50]
PaliGemma: A versatile 3B VLM for transfer
L. Beyer, A. Steiner, A. S. Pinto, A. Kolesnikov, X. Wang, D. Salz, M. Neumann, I. Alab- dulmohsin, M. Tschannen, E. Bugliarello, T. Unterthiner, D. Keysers, S. Koppula, F. Liu, A. Grycner, A. Gritsenko, N. Houlsby, M. Kumar, K. Rong, J. Eisenschlos, R. Kabra, M. Bauer, M. Boˇsnjak, X. Chen, M. Minderer, P. V oigtlaender, I. Bica, I. Balazevic, J. Puigcer...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.