Multimodal Large Language Models as Synthetic Participants in Video-Based Studies: An Evaluation
Pith reviewed 2026-07-01 08:05 UTC · model grok-4.3
The pith
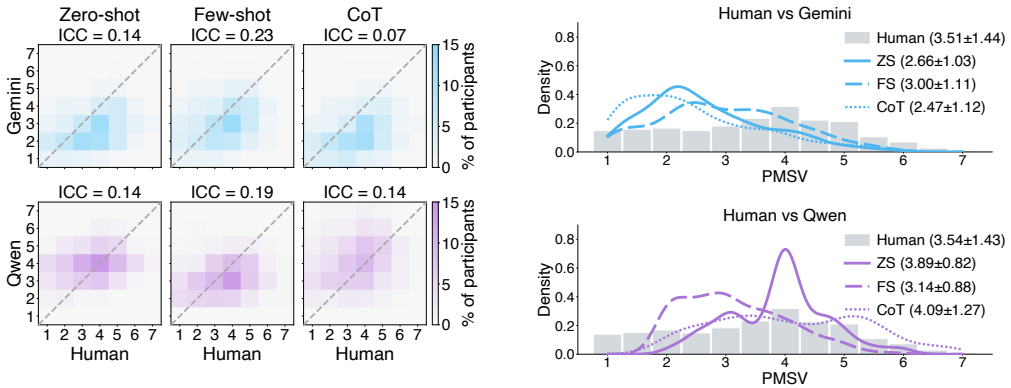
Leading MLLMs like Gemini 3 Flash and Qwen 3 Omni show limited agreement with human ratings of perceived sensory engagement in videos, exhibiting downward mean-shift and central-tendency biases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
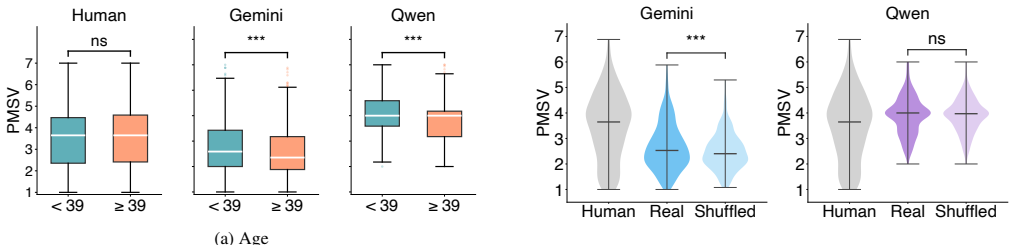
The central claim is that MLLMs remain limited as substitutes for human participants in subjective video studies: Gemini 3 Flash and Qwen 3 Omni display clear downward mean shifts and central-tendency compression relative to human ratings, they both introduce and flatten subgroup differences, and their sensitivity to participant profile information is inconsistent across prompting strategies.
What carries the argument
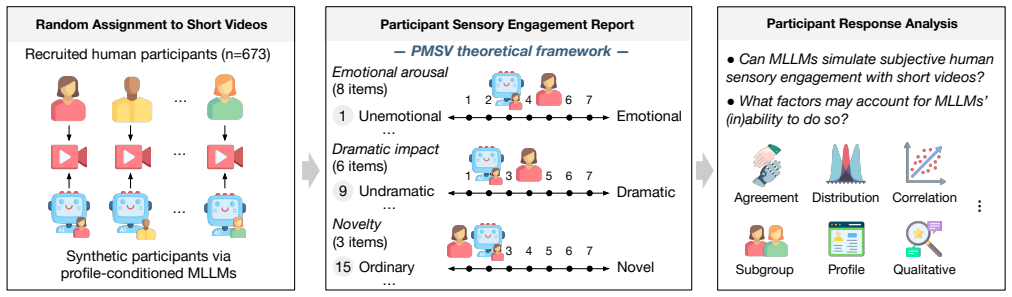
Profile-conditioned MLLM simulation outputs compared item-by-item against human responses on the 17-item PMSV scale.
If this is right
- MLLMs cannot yet serve as reliable replacements for human participants in video-based subjective research.
- Model rating distributions remain biased even under profile conditioning.
- Subgroup response patterns are neither preserved nor accurately simulated.
- Different prompting approaches improve some metrics while degrading others.
- Opportunities remain for targeted improvements in subjective simulation capability.
Where Pith is reading between the lines
- The observed flattening of subgroup differences implies that current MLLMs may systematically under-represent demographic variation in subjective responses.
- If the biases prove stable across tasks, fine-tuning on paired human-model subjective data may be required rather than relying on prompting alone.
- The same evaluation approach could be applied to other subjective domains such as product testing or public opinion simulation to test generality.
- A controlled experiment swapping the video set while holding the scale fixed would isolate whether the mismatch is content-specific or model-intrinsic.
Load-bearing premise
The 17-item PMSV scale and the recruited human sample supply a stable, representative ground truth for subjective sensory engagement that can be compared directly to model outputs.
What would settle it
Replicating the study with a different validated subjective scale or a larger, more demographically varied human sample and finding close statistical agreement between model and human distributions would falsify the limited-agreement result.
Figures
read the original abstract
Multimodal large language models (MLLMs) have shown strong performance on objective tasks such as video understanding and reasoning. However, it remains unclear whether they can approximate subjective human responses, which depend not only on content comprehension but also on individuals' social contexts. To address this gap, we evaluate MLLMs as synthetic participants in an emerging task: assessing perceived sensory engagement with short videos. Grounded in the Perceived Message Sensation Value (PMSV) framework, we compare ratings from recruited human participants and profile-conditioned MLLM simulations (n=673) using a 17-item scale measuring emotional arousal, dramatic impact, and novelty. We find that even leading MLLMs (Gemini 3 Flash and Qwen 3 Omni) show limited agreement with human participants. The models exhibit distinct downward mean-shift and central-tendency biases in their rating distributions. They both introduce and flatten subgroup differences, while showing inconsistent sensitivity to participant profiles. Prompting strategies affect these metrics differently, modestly improving some aspects while worsening others. These results highlight both the challenges and opportunities of developing MLLMs as synthetic participants in video-based research. Data and code: https://github.com/MINDLab25/mllm-human-simulation-eval
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates multimodal LLMs (Gemini 3 Flash, Qwen 3 Omni) as synthetic participants for rating perceived sensory engagement in short videos via the 17-item PMSV scale. It reports a direct comparison of profile-conditioned model outputs (n=673 simulations) against recruited human ratings, documenting limited agreement together with downward mean-shift, central-tendency, and subgroup-flattening biases, plus inconsistent profile sensitivity and mixed effects of prompting strategies. Data and code are released.
Significance. If the human reference distribution is shown to be reliable and representative, the work supplies a concrete, reproducible empirical benchmark that quantifies specific failure modes when MLLMs are asked to simulate subjective video responses. The open repository is a clear strength that enables follow-up work on synthetic-participant methods in video-based HCI and communication research.
major comments (3)
- [Methods (human data collection and PMSV administration)] Methods (human data section): the manuscript provides no human sample size, no inter-rater reliability statistic (Cronbach’s α, ICC, or equivalent), and no test of scale invariance across video types or demographic subgroups. Because the central claims of mean-shift, central-tendency, and subgroup-flattening biases rest on treating the human ratings as a stable ground-truth distribution, the absence of these diagnostics is load-bearing.
- [Results (rating distribution comparisons)] Results (bias quantification): the reported downward mean-shift and central-tendency patterns are described qualitatively; no effect sizes, confidence intervals, or statistical tests comparing model vs. human rating distributions are referenced, making it impossible to judge the magnitude or robustness of the claimed biases.
- [Methods (MLLM simulation setup)] Methods (profile conditioning): it is unclear how the participant profiles supplied to the models were constructed and whether their marginal distributions exactly match the recruited human sample demographics; any mismatch would confound the reported flattening of subgroup differences.
minor comments (2)
- [Abstract] The abstract states n=673 for simulations but does not state the corresponding human N; this should be added for immediate readability.
- [Figures] Figure captions and axis labels for the rating-distribution plots should explicitly state the number of observations per condition.
Simulated Author's Rebuttal
We thank the referee for the constructive comments emphasizing methodological transparency and statistical rigor. We address each major point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: Methods (human data collection and PMSV administration): the manuscript provides no human sample size, no inter-rater reliability statistic (Cronbach’s α, ICC, or equivalent), and no test of scale invariance across video types or demographic subgroups. Because the central claims of mean-shift, central-tendency, and subgroup-flattening biases rest on treating the human ratings as a stable ground-truth distribution, the absence of these diagnostics is load-bearing.
Authors: We agree these diagnostics are necessary to support the human ratings as ground truth. The revised Methods section will explicitly report the human sample size. We will add Cronbach’s α and ICC calculations using the released data. We will also include tests of scale invariance across video types and demographic subgroups (or acknowledge limitations if full testing exceeds the dataset scope). revision: yes
-
Referee: Results (rating distribution comparisons): the reported downward mean-shift and central-tendency patterns are described qualitatively; no effect sizes, confidence intervals, or statistical tests comparing model vs. human rating distributions are referenced, making it impossible to judge the magnitude or robustness of the claimed biases.
Authors: We acknowledge the need for quantitative support. The revision will add effect sizes (e.g., Cohen’s d), 95% confidence intervals, and statistical tests (t-tests for mean differences, Levene’s test for variance, and Kolmogorov-Smirnov tests for distribution shape) to quantify the biases. revision: yes
-
Referee: Methods (MLLM simulation setup): it is unclear how the participant profiles supplied to the models were constructed and whether their marginal distributions exactly match the recruited human sample demographics; any mismatch would confound the reported flattening of subgroup differences.
Authors: We will revise the Methods to detail profile construction and provide evidence (tables or supplementary figures) that marginal demographic distributions in the simulated profiles match the human sample, clarifying the basis for subgroup analyses. revision: yes
Circularity Check
No circularity: direct empirical comparison without derivations or self-referential predictions
full rationale
The paper performs an empirical evaluation by collecting human PMSV ratings and comparing them to MLLM outputs under profile conditioning. No mathematical derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described structure. The central findings (limited agreement, mean-shift biases, subgroup flattening) are reported as observed differences against the human sample rather than derived from any internal model or prior author result. The absence of any claimed first-principles chain or self-definitional steps makes the work self-contained as a measurement study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The Perceived Message Sensation Value (PMSV) framework and its 17-item scale provide a valid measure of subjective sensory engagement with videos.
Reference graph
Works this paper leans on
-
[1]
P.; Busby, E
Argyle, L. P.; Busby, E. C.; Fulda, N.; Gubler, J. R.; Rytting, C.; and Wingate, D. 2023. Out of one, many: Using language models to simulate human samples. Political Analysis, 31(3): 337--351
2023
-
[2]
Fleury, D. 2024. Video-Language Models as Flexible Social and Physical Reasoners. bioRxiv, 2024--05
2024
-
[3]
Garcia, K.; and Isik, L. 2025. Aligning Video Models with Human Social Judgments via Behavior-Guided Fine-Tuning. arXiv preprint arXiv:2510.01502
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Hong, Y.; Yao, H.; Shen, B.; Xu, W.; Wei, H.; and Dong, Y. 2026. RULERS: Locked Rubrics and Evidence-Anchored Scoring for Robust LLM Evaluation. arXiv preprint arXiv:2601.08654
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
H.; Stephenson, M
Hoyle, R. H.; Stephenson, M. T.; Palmgreen, P.; Lorch, E. P.; and Donohew, R. L. 2002. Reliability and validity of a brief measure of sensation seeking. Personality and Individual Differences, 32(3): 401--414
2002
-
[6]
Large Language Models Cannot Self-Correct Reasoning Yet
Huang, J.; Chen, X.; Mishra, S.; Zheng, H. S.; Yu, A. W.; Song, X.; and Zhou, D. 2023. Large language models cannot self-correct reasoning yet. arXiv preprint arXiv:2310.01798
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
S.; and Bernstein, M
Kolluri, A.; Wu, S.; Park, J. S.; and Bernstein, M. S. 2025. Finetuning LLMs for Human Behavior Prediction in Social Science Experiments. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP), 30084--30099
2025
-
[8]
Ma, B.; Yoztyurk, B.; Haensch, A.-C.; Wang, X.; Herklotz, M.; Kreuter, F.; Plank, B.; and Assenmacher, M. 2025. Algorithmic fidelity of large language models in generating synthetic german public opinions: A case study. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 1785--1809
2025
-
[9]
S.; Zhu, K.; and Horton, J
Manning, B. S.; Zhu, K.; and Horton, J. J. 2024. Automated social science: Language models as scientist and subjects. Technical report, National Bureau of Economic Research
2024
-
[10]
Min, S.; Lyu, X.; Holtzman, A.; Artetxe, M.; Lewis, M.; Hajishirzi, H.; and Zettlemoyer, L. 2022. Rethinking the Role of Demonstrations: What Makes In-Context Learning Work? In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP), 11048--11064
2022
-
[11]
E.; Brewer, K
O’Brien, J. E.; Brewer, K. B.; Jones, L. M.; Corkhum, J.; and Rizo, C. F. 2022. Rigor and Respect: Recruitment Strategies for Engaging Vulnerable Populations in Research. Journal of Interpersonal Violence, 37(17-18): NP17052--NP17072
2022
-
[12]
T.; Everett, M
Palmgreen, P.; Stephenson, M. T.; Everett, M. W.; Baseheart, J. R.; and Francies, R. 2002. Perceived message sensation value (PMSV) and the dimensions and validation of a PMSV scale. Health Communication, 14(4): 403--428
2002
-
[13]
C.; and Xu, H
Qian, S.; Lu, Y.; Peng, Y.; Shen, C. C.; and Xu, H. 2024. Convergence or divergence? A cross-platform analysis of climate change visual content categories, features, and social media engagement on Twitter and Instagram. Public Relations Review, 50(2): 102454
2024
-
[14]
J.; Pavel, S.; and Gross, C
UyBico, S. J.; Pavel, S.; and Gross, C. P. 2007. Recruiting Vulnerable Populations into Research: A Systematic Review of Recruitment Interventions. Journal of General Internal Medicine, 22(6): 852--863
2007
-
[15]
Wang, Y.; Tao, Z.; Chang, H.; Huang, N.; Jin, L.; and Luo, X. 2025. Multimodal understanding of human values in videos: A benchmark dataset and PLM-based method. Neurocomputing, 638: 130170
2025
-
[16]
V.; Zhou, D.; et al
Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Xia, F.; Chi, E.; Le, Q. V.; Zhou, D.; et al. 2022. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. Advances in Neural Information Processing Systems (NeurIPS), 35: 24824--24837
2022
-
[17]
Xu, J.; Guo, Z.; Hu, H.; Chu, Y.; Wang, X.; He, J.; Wang, Y.; Shi, X.; He, T.; Zhu, X.; et al. 2025. Qwen3-Omni Technical Report. arXiv preprint arXiv:2509.17765
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Xue, H.; Zhang, J.; Wang, X.; Kim, D. D.; and Song, Y. 2026. A Computational Model of Message Sensation Value in Short Video Multimodal Features that Predicts Sensory and Behavioral Engagement. arXiv preprint arXiv:2604.19995
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
Yue, X.; Ni, Y.; Zhang, K.; Zheng, T.; Liu, R.; Zhang, G.; Stevens, S.; Jiang, D.; Ren, W.; Sun, Y.; et al. 2024. MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 9556--9567
2024
-
[20]
P.; Redmiles, E
Zannettou, S.; Nemes-Nemeth, O.; Ayalon, O.; Goetzen, A.; Gummadi, K. P.; Redmiles, E. M.; and Roesner, F. 2024. Analyzing User Engagement with TikTok's Short Format Video Recommendations using Data Donations. In Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems (CHI), 1--16
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.