CLASP: Language-Driven Robot Skill Selection and Composition using Task-Parameterized Learning
Pith reviewed 2026-06-27 19:19 UTC · model grok-4.3
The pith
Pretrained vision-language models combined with task-parameterized movement primitives enable language-driven skill selection, composition, and active learning on robots without fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A modular architecture combines TP-KMPs with pretrained VLMs so that skills acquired from few kinesthetic demonstrations receive language-grounded schemas; at runtime the VLM selects skills, reasons about parameter bindings, and forms novel behaviors by covariance-weighted composition, while also detecting capability gaps and requesting active demonstrations, all without any fine-tuning of the models.
What carries the argument
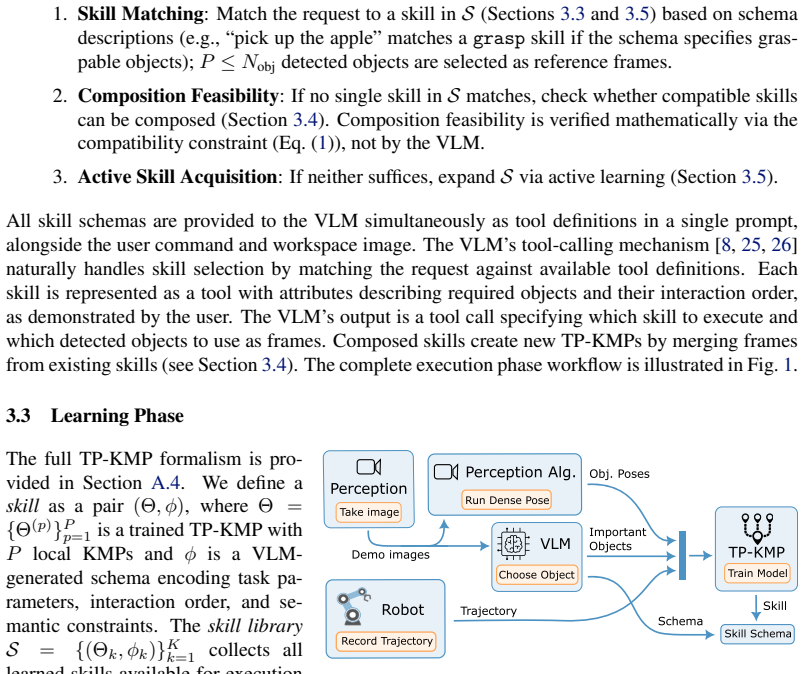
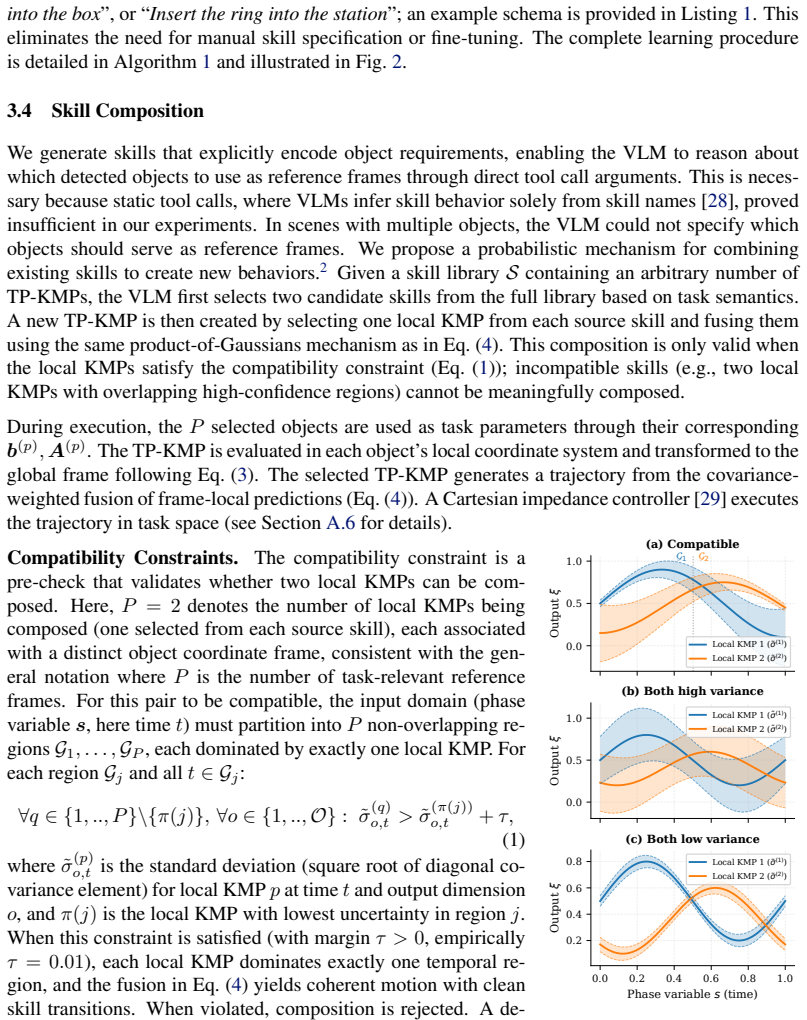
Covariance-weighted composition of TP-KMPs, driven by VLM-generated skill schemas that encode parameters and preconditions for selection and binding.
Load-bearing premise
The pretrained VLM can reliably produce accurate skill schemas and correctly interpret commands to select and bind skills without hallucination or systematic error.
What would settle it
A command that causes the VLM to select the wrong skill or bind an incorrect parameter, resulting in execution failure or unsafe motion on the 7-DoF manipulator.
Figures








read the original abstract
Enabling robots to understand and execute tasks from natural language commands while maintaining data efficiency remains challenging. Foundation models such as vision-language-action (VLA) and vision-language models (VLMs) provide intuitive interaction channels but require extensive data; task-parameterized imitation learning achieves data efficiency but lacks natural language grounding. This work bridges this gap through a modular architecture combining task-parameterized kernelized movement primitives (TP-KMPs) with pretrained VLMs. During learning, skills are acquired from 2 to 5 kinesthetic demonstrations, and the VLM generates skill schemas describing each skill's parameters and preconditions. During execution, the VLM interprets commands to select skills, reason about parameter bindings, and create novel behaviors through covariance-weighted composition. When no skill or composition suffices, the system identifies capability gaps and requests targeted demonstrations, all without fine-tuning. Validation on a 7-DoF manipulator shows success rates of 73.3%-100% in scenarios requiring skill selection, composition, and active learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CLASP, a modular architecture integrating task-parameterized kernelized movement primitives (TP-KMPs) with pretrained vision-language models (VLMs) for language-driven robot skill selection, composition, and active learning. Skills are learned from 2-5 kinesthetic demonstrations, with the VLM generating schemas for parameters and preconditions. During execution, the VLM handles command interpretation, skill selection, parameter binding, covariance-weighted composition, and requests for new demos when needed, without fine-tuning. Experiments on a 7-DoF manipulator report success rates between 73.3% and 100% across scenarios involving selection, composition, and active learning.
Significance. If the empirical results hold under scrutiny, the work demonstrates a practical, data-efficient alternative to fine-tuning large vision-language-action models by combining modular imitation learning with off-the-shelf VLMs, enabling skill composition and active learning from natural language while avoiding extensive retraining.
major comments (2)
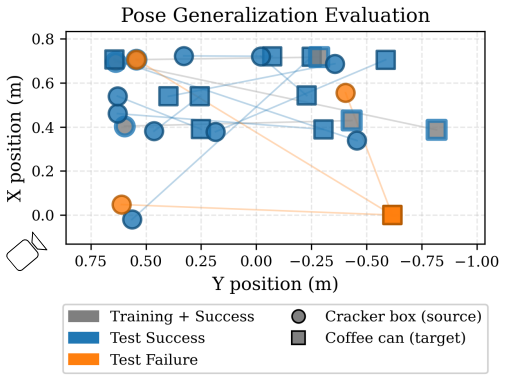
- Abstract: success rates of 73.3%-100% are stated without any description of the number of trials, task definitions, baselines, statistical measures, or failure modes, rendering the central validation claim unevaluable.
- Execution phase (as described): the architecture has no fallback or correction for VLM outputs, yet the central claim depends on the VLM reliably producing accurate skill schemas from 2-5 demos and correctly interpreting commands for selection, binding, and composition; no quantitative VLM error analysis or robustness tests are referenced.
minor comments (1)
- The abstract would be strengthened by naming the specific VLM and providing at least one concrete example of a skill schema or command interpretation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the clarity of our experimental claims and the need for robustness analysis. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core contributions.
read point-by-point responses
-
Referee: [—] Abstract: success rates of 73.3%-100% are stated without any description of the number of trials, task definitions, baselines, statistical measures, or failure modes, rendering the central validation claim unevaluable.
Authors: The abstract serves as a concise summary, while the full experimental protocol—including 15 trials per scenario, explicit task definitions, baseline comparisons, mean success rates with standard deviations, and failure mode analysis—is detailed in Section V. To improve self-containment, we will revise the abstract to briefly reference the number of trials, key metrics, and that results are aggregated over multiple runs. revision: yes
-
Referee: [—] Execution phase (as described): the architecture has no fallback or correction for VLM outputs, yet the central claim depends on the VLM reliably producing accurate skill schemas from 2-5 demos and correctly interpreting commands for selection, binding, and composition; no quantitative VLM error analysis or robustness tests are referenced.
Authors: The active learning component functions as a built-in response to insufficient VLM outputs by requesting new demonstrations when no skill or composition matches. We agree that quantitative VLM error analysis is absent and will add a dedicated subsection in the Experiments section reporting observed error rates for schema generation and command interpretation, along with robustness tests across prompt variations. revision: yes
Circularity Check
No significant circularity; modular system uses external pretrained components
full rationale
The paper presents an engineering architecture that combines existing TP-KMPs (from prior literature) with off-the-shelf pretrained VLMs for skill schema generation, selection, binding, and covariance-weighted composition. No equations, parameter fits, or first-principles derivations are described whose outputs reduce to the inputs by construction. Empirical success rates (73.3%-100%) are reported from robot experiments rather than any self-referential prediction step. The central premise (reliable VLM behavior) is an external assumption, not a derived quantity internal to the paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
S. Schaal. Is imitation learning the route to humanoid robots?Trends in Cognitive Sciences, 3 (6):233–242, 1999. doi:10.1016/S1364-6613(99)01327-3
-
[2]
B. D. Argall, S. Chernova, M. Veloso, and B. Browning. A survey of robot learning from demonstration.Robotics and Autonomous Systems, 57(5):469–483, 2009. doi:10.1016/j.robot. 2008.10.024
-
[3]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. P. Foster, P. R. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn. Openvla: An open-source vision-language-action model. InConference on Robot Learning (CoRL), volume 270 ofProceedings of Machine Learning Research, pag...
2025
-
[4]
W. Yuan, J. Duan, V . Blukis, W. Pumacay, R. Krishna, A. Murali, A. Mousavian, and D. Fox. Robopoint: A vision-language model for spatial affordance prediction in robotics. InCon- ference on Robot Learning (CoRL), volume 270 ofProceedings of Machine Learning Re- search, pages 4005–4020. PMLR, 2025. URLhttps://proceedings.mlr.press/v270/ yuan25c.html
2025
-
[5]
Raman, Ankit Shah, and Stefanie Tellex
A. O’Neill, A. Rehman, A. Maddukuri, A. Gupta, et al. Open X-Embodiment: Robotic learn- ing datasets and RT-X models. InIEEE International Conference on Robotics and Automation (ICRA), pages 6892–6903, 2024. doi:10.1109/ICRA57147.2024.10611477
-
[6]
S. Calinon. A tutorial on task-parameterized movement learning and retrieval.Intelligent Service Robotics, 9(1):1–29, 2016. doi:10.1007/s11370-015-0187-9
-
[7]
Huang, L
Y . Huang, L. Rozo, J. Silv ´erio, and D. G. Caldwell. Kernelized movement primitives. International Journal of Robotics Research (IJRR), 38(7):833–852, 2019. doi:10.1177/ 0278364919846363
2019
-
[8]
M. Knauer, A. Albu-Sch ¨affer, F. Stulp, and J. Silv ´erio. Interactive incremental learning of generalizable skills with local trajectory modulation.IEEE Robotics and Automation Letters (RA-L), 10(4):3398–3405, 2025. doi:10.1109/LRA.2025.3542209
-
[9]
M. Saveriano, F. J. Abu-Dakka, A. Kramberger, and L. Peternel. Dynamic movement primi- tives in robotics: A tutorial survey.International Journal of Robotics Research (IJRR), 42(13): 1133–1184, 2023. doi:10.1177/02783649231201196
-
[10]
S. Calinon, D. Bruno, and D. G. Caldwell. A task-parameterized probabilistic model with minimal intervention control. InIEEE International Conference on Robotics and Automation (ICRA), pages 3339–3344, 2014. doi:10.1109/ICRA.2014.6907339. 9
-
[11]
Radford, J
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever. Learning transferable visual models from natural language supervision. InInternational Conference on Machine Learning (ICML), vol- ume 139, pages 8748–8763. PMLR, 2021. URLhttps://proceedings.mlr.press/v139/ radford21a.html
2021
-
[12]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polo- sukhin. Attention is all you need. InAdvances in Neural Information Processing Systems (NeurIPS), volume 30, pages 6000–6010, 2017. URLhttps://proceedings.neurips. cc/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html
2017
-
[13]
Driess, F
D. Driess, F. Xia, M. S. M. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, A. Wahid, J. Tompson, Q. Vuong, T. Yu, W. Huang, Y . Chebotar, P. Sermanet, D. Duckworth, S. Levine, V . Vanhoucke, K. Hausman, M. Toussaint, K. Greff, A. Zeng, I. Mordatch, and P. Florence. Palm-e: An embodied multimodal language model. InInternational Conference on Machine Learning ...
2023
-
[14]
X. Li, M. Liu, H. Zhang, C. Yu, J. Xu, H. Wu, C. Cheang, Y . Jing, W. Zhang, H. Liu, H. Li, and T. Kong. Vision-language foundation models as effective robot imitators. InInternational Conference on Learning Representations (ICLR), 2024. URLhttps://openreview.net/ forum?id=lFYj0oibGR
2024
-
[15]
Grannen, S
J. Grannen, S. Karamcheti, S. Mirchandani, P. Liang, and D. Sadigh. V ocal sandbox: Contin- ual learning and adaptation for situated human-robot collaboration. InConference on Robot Learning (CoRL), volume 270 ofProceedings of Machine Learning Research. PMLR, 2024. URLhttps://proceedings.mlr.press/v270/grannen25a.html
2024
-
[16]
G. Tziafas and H. Kasaei. Lifelong robot library learning: Bootstrapping composable and generalizable skills for embodied control with language models. InIEEE International Con- ference on Robotics and Automation (ICRA), pages 515–522, 2024. doi:10.1109/ICRA57147. 2024.10611448
-
[17]
W. Gu, S. Kondepudi, A. Gupta, L. Huang, and N. Gopalan. Continual robot skill and task learning via dialogue. InIEEE International Conference on Robotics and Automation (ICRA) Workshop on Human-Centered Robot Learning, 2025. URLhttps://openreview.net/ forum?id=r7PpkXMoVk
2025
-
[18]
Paraschos, C
A. Paraschos, C. Daniel, J. Peters, and G. Neumann. Probabilistic move- ment primitives. InAdvances in Neural Information Processing Systems (NeurIPS), 2013. URLhttps://proceedings.neurips.cc/paper/2013/hash/ e53a0a2978c28872a4505bdb51db06dc-Abstract.html
2013
-
[19]
In: 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
J. Silv ´erio, Y . Huang, F. J. Abu-Dakka, L. Rozo, and D. G. Caldwell. Uncertainty-aware imi- tation learning using kernelized movement primitives. InIEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 90–97, 2019. doi:10.1109/IROS40897.2019. 8967996
-
[20]
In: 2022 International Conference on Robotics and Automation (ICRA)
P. Oikonomou, A. Dometios, M. Khamassi, and C. S. Tzafestas. Reproduction of human demonstrations with a soft-robotic arm based on a library of learned probabilistic movement primitives. In2022 International Conference on Robotics and Automation (ICRA), pages 5212–5218, 2022. doi:10.1109/ICRA46639.2022.9811627
-
[21]
Y . Huang, J. Silv ´erio, L. Rozo, and D. G. Caldwell. Generalized task-parameterized skill learning. InIEEE International Conference on Robotics and Automation (ICRA), 2018. doi: 10.1109/ICRA.2018.8461079
-
[22]
J. Zhu, M. Gienger, and J. Kober. Learning task-parameterized skills from few demon- strations.IEEE Robotics and Automation Letters (RA-L), 7(2):4063–4070, 2022. doi: 10.1109/LRA.2022.3150013. 10
-
[23]
Hoyos, F
J. Hoyos, F. Prieto, G. Aleny `a, and C. Torras. Incremental learning of skills in a task- parameterized gaussian mixture model.Journal of Intelligent & Robotic Systems, 82:81–99,
-
[24]
doi:10.1007/s10846-015-0290-3
-
[25]
Q. Team. Qwen3 technical report, 2025. doi:10.48550/arXiv.2505.09388
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.09388 2025
-
[26]
Z. Wang, Z. Cheng, H. Zhu, D. Fried, and G. Neubig. What are tools anyway? a survey from the language model perspective. InConference on Language Modeling (COLM), 2024. URL https://openreview.net/pdf?id=Xh1B90iBSR
2024
-
[27]
Y . Qin, S. Hu, Y . Lin, W. Chen, N. Ding, G. Cui, Z. Zeng, Y . Huang, C. Xiao, C. Han, et al. Tool learning with foundation models.ACM Computing Surveys (CSUR), 57:101:1–101:40,
-
[28]
T. Mai, R. Sakagami, G. Quere, G. Mesesan, R. Schuller, K. Fr ¨und, J. V ogel, A. Hagengruber, J. Lee, A. D ¨omel, F. Stulp, and S. Bustamante. LLM tool workflows for robot explainability and natural language commanding. InICRA 2026 Workshop on Semantics for Reliable Robot Autonomy: From Environment Understanding and Reasoning to Safe Interaction, 2026. U...
2026
-
[29]
Ichter, A
B. Ichter, A. Brohan, Y . Chebotar, C. Finn, K. Hausman, A. Herzog, D. Ho, J. Ibarz, A. Irpan, E. Jang, R. Julian, D. Kalashnikov, S. Levine, Y . Lu, C. Parada, K. Rao, P. Sermanet, A. T. To- shev, V . Vanhoucke, F. Xia, T. Xiao, P. Xu, M. Yan, N. Brown, M. Ahn, O. Cortes, N. Sievers, C. Tan, S. Xu, D. Reyes, J. Rettinghouse, J. Quiambao, P. Pastor, L. Lu...
2023
-
[30]
N. Hogan. Impedance control of industrial robots.Robotics and Computer-Integrated Manu- facturing, 1(1):97–113, 1984. doi:10.1016/0736-5845(84)90084-X
-
[31]
M. Iskandar, C. Ott, O. Eiberger, M. Keppler, A. Albu-Sch ¨affer, and A. Dietrich. Joint-level control of the dlr lightweight robot sara. InIEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 8903–8910, 2020. doi:10.1109/IROS45743.2020.9340700
-
[32]
M. Iskandar, C. Ott, A. Albu-Sch ¨affer, B. Siciliano, and A. Dietrich. Hybrid force-impedance control for fast end-effector motions.IEEE Robotics and Automation Letters (RA-L), 8(7): 3931–3938, 2023. doi:10.1109/LRA.2023.3270036
-
[33]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner, Q. V...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2504.16054 2025
-
[34]
Strobl, Matthias Humt, and Rudolph Triebel
M. Denninger, D. Winkelbauer, M. Sundermeyer, W. Boerdijk, M. Knauer, K. H. Strobl, M. Humt, and R. Triebel. Blenderproc2: A procedural pipeline for photorealistic rendering. Journal of Open Source Software (JOSS), 8(82):4901, 2023. doi:10.21105/joss.04901
-
[35]
Vbench: Comprehensive benchmark suite for video generative models
X. Long, Y .-C. Guo, C. Lin, Y . Liu, Z. Dou, L. Liu, Y . Ma, S.-H. Zhang, M. Habermann, C. Theobalt, and W. Wang. Wonder3D: Single Image to 3D Using Cross-Domain Diffusion. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9970–9980, 2024. doi:10.1109/CVPR52733.2024.00951
-
[36]
Y . Yin, Z. Wang, Y . Sharma, D. Niu, T. Darrell, and R. Herzig. In-context learning enables robot action prediction in llms. InIEEE International Conference on Robotics and Automation (ICRA), 2025. doi:10.1109/ICRA55743.2025.11128807. 11
-
[37]
Certo, B
A. Certo, B. Martins, C. Azevedo, and P. U. Lima. Large language model-based robot task planning from voice command transcriptions. InIEEE/RSJ International Conference on Intelli- gent Robots and Systems (IROS), 2025. URLhttps://ieeexplore.ieee.org/document/ 11246378
2025
-
[38]
Schick, J
T. Schick, J. Dwivedi-Yu, R. Dess `ı, R. Raileanu, M. Lomeli, E. Hambro, L. Zettle- moyer, N. Cancedda, and T. Scialom. Toolformer: Language models can teach them- selves to use tools. InAdvances in Neural Information Processing Systems (NeurIPS), vol- ume 36, 2023. URLhttps://proceedings.neurips.cc/paper_files/paper/2023/ hash/d842425e4bf79ba039352da0f65...
2023
-
[39]
J. Huang and K. C.-C. Chang. Towards reasoning in large language models: A survey. InFind- ings of the Association for Computational Linguistics: ACL 2023, pages 1049–1065, 2023. doi:10.18653/v1/2023.findings-acl.67
-
[40]
W. Xu, M. Wang, W. Zhou, and H. Li. P-rag: Progressive retrieval augmented generation for planning on embodied everyday task. InACM International Conference on Multimedia (MM). ACM, 2024. doi:10.1145/3664647.3680661
-
[41]
arXiv preprint arXiv:2402.03610 , year=
T. Kagaya, T. J. Yuan, Y . Lou, J. Karlekar, S. Pranata, A. Kinose, K. Oguri, F. Wick, and Y . You. Rap: Retrieval-augmented planning with contextual memory for multimodal llm agents, 2024. doi:10.48550/arXiv.2402.03610
-
[42]
Petruzzellis, C
F. Petruzzellis, C. Cornelio, and P. Lio. Hierarchical planning for complex tasks with knowl- edge graph-rag and symbolic verification. InInternational Conference on Machine Learn- ing (ICML), volume 267 ofProceedings of Machine Learning Research. PMLR, 2025. URL https://proceedings.mlr.press/v267/petruzzellis25a.html
2025
-
[43]
M. U. Din, J. Rosell, W. Akram, I. Zaplana, M. A. Roa, and I. Hussain. Llm-guided task and motion planning using knowledge-based reasoning, 2025. doi:10.48550/arXiv.2412.07493
-
[44]
M. Lei, G. Wang, Y . Zhao, Z. Mai, Q. Zhao, Y . Guo, Z. Li, S. Cui, Y . Han, and J. Ren. Clea: Closed-loop embodied agent for enhancing task execution in dynamic environments, 2025. doi:10.48550/arXiv.2503.00729
-
[45]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, Q. Vuong, V . Vanhoucke, H. Tran, R. Soricut, A. Singh, J. Singh, P. Sermanet, P. R. Sanketi, G. Salazar, M. S. Ryoo, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning (CoRL), volume 229, pages 216...
2023
-
[46]
A Careful Examination of Large Behavior Models for Multitask Dexterous Manipulation
J. Barreiros, A. Beaulieu, A. Bhat, R. Cory, E. Cousineau, H. Dai, C.-H. Fang, K. Hashimoto, M. Z. Irshad, M. Itkina, N. Kuppuswamy, K.-H. Lee, K. Liu, D. McConachie, I. McMa- hon, H. Nishimura, C. Phillips-Grafflin, C. Richter, P. Shah, K. Srinivasan, B. Wulfe, C. Xu, M. Zhang, et al. A careful examination of large behavior models for multitask dexterous...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.05331 2025
-
[47]
M. J. Kim, C. Finn, and P. Liang. Fine-tuning vision-language-action models: Optimizing speed and success. InRobotics: Science and Systems (RSS), 2025. doi:10.15607/RSS.2025. XXI.017
-
[48]
C.-Y . Wang, A. Bochkovskiy, and H.-Y . M. Liao. Yolov7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 7464–7475, 2023. doi:10.1109/CVPR52729.2023. 00721
-
[49]
M. Sundermeyer, Z.-C. Marton, M. Durner, M. Brucker, and R. Triebel. Implicit 3d orientation learning for 6d object detection from rgb images. InEuropean Conference on Computer Vision (ECCV), 2018. doi:10.1007/978-3-030-01231-1 43. 12
-
[50]
B. Calli, A. Singh, J. Bruce, A. Walsman, K. Konolige, S. Srinivasa, P. Abbeel, and A. M. Dollar. Yale-cmu-berkeley dataset for robotic manipulation research.International Journal of Robotics Research (IJRR), 36(3):261–268, 2017. doi:10.1177/0278364917700714
-
[51]
K. H. Strobl and G. Hirzinger. More accurate camera and hand-eye calibrations with un- known grid pattern dimensions. InIEEE International Conference on Robotics and Automation (ICRA), pages 1398–1405, 2008. doi:10.1109/ROBOT.2008.4543398
-
[52]
P. J. Besl and N. D. McKay. A method for registration of 3-D shapes.IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 14(2):239–256, 1992. doi:10.1109/34. 121791. 13 A Supplementary Material This appendix provides supplementary material. Section A.1 provides the extended gap-in-literature discussion. Section A.2 provides additional r...
work page doi:10.1109/34 1992
-
[53]
skill name
acquires and composes learned visuo-motor policies through dialogue-based interaction. These approaches compose skillssymbolically, selecting and sequencing discrete primitives rather than operating at the continuous trajectory level. Trajectory-level fusion via products of Gaussians is an established mechanism in probabilistic and kernelized movement pri...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.