Steering Where to Listen: Instruction-Based Activation Steering Redirects Temporal Attention in Large Audio-Language Models
Pith reviewed 2026-06-27 11:27 UTC · model grok-4.3
The pith
Instruction-based steering vectors let models reveal the timing of queried sounds by shifting their attention.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
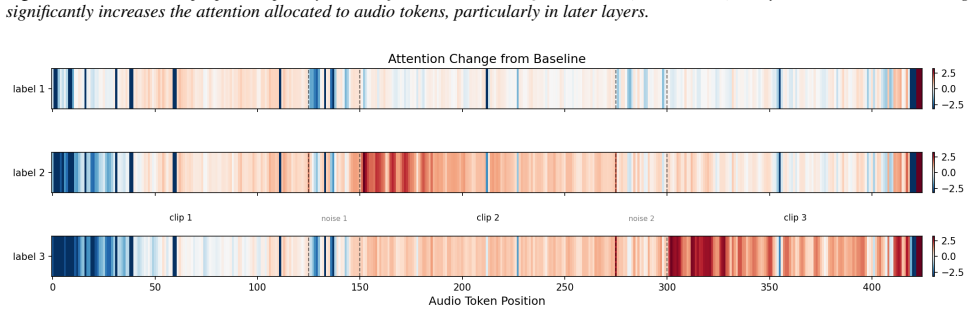
Instruction-based vector steering constructs a steering vector by contrasting activations from differently instructed prompts while keeping the audio fixed. This significantly redistributes temporal attention to acoustically relevant regions. Reading out the temporal position of maximal steering-induced attention change recovers the location of a queried sound event without any training, attaining 60.87% and 68.72% overlap with ground-truth intervals on Qwen2-Audio and Audio Flamingo 3, far above direct prompting (31.84%, 46.75%) and random baselines (27.74%).
What carries the argument
The instruction-based steering vector formed by subtracting activations under different prompts on the same audio, which redirects temporal attention allocation.
If this is right
- The steering intervention concentrates attention on relevant audio regions unlike standard prompting.
- Maximal attention change location recovers queried event positions at over 60% overlap.
- This provides a training-free method to probe latent temporal encoding in LALMs.
- Attention redistribution is behaviorally meaningful for sound event localization.
Where Pith is reading between the lines
- This method might allow interpreting attention in other multimodal models by similar contrastive instructions.
- Future work could test if the same steering works across different audio tasks like speech recognition or music analysis.
- The results suggest that instructions influence the model's internal attention mechanisms more directly than previously assumed.
Load-bearing premise
The steering vector obtained by subtracting activations from differently instructed prompts on fixed audio specifically isolates and redirects temporal attention rather than introducing unrelated prompt-induced changes or artifacts.
What would settle it
If the overlap between maximal attention change positions and ground-truth event intervals falls to random baseline levels (around 28%) when tested on new audio clips or models, the claim that steering redirects attention meaningfully would not hold.
Figures

read the original abstract
Large Audio-Language Models (LALMs) excel at audio understanding but expose little about where in an audio signal they attend. We introduce instruction-based vector steering, which constructs a steering vector by contrasting activations from differently instructed prompts while keeping the audio fixed. Through a systematic probe of LALM attention, we find that - unlike standard prompting or audio-based steering - this intervention significantly redistributes the temporal attention allocated to audio tokens, concentrating it on acoustically relevant regions. We then show that this attention shift is behaviorally meaningful: in a controlled three-event setting, reading out the temporal position of maximal steering-induced attention change recovers the location of a queried sound event without any training, attaining 60.87% and 68.72% overlap with ground-truth intervals on Qwen2-Audio and Audio Flamingo 3, far above direct prompting (31.84%, 46.75%) and random baselines (27.74%). Our results characterize a mechanistic property of instruction-based steering in LALMs and provide a training-free probe for the latent temporal structure these models encode.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces instruction-based activation steering for large audio-language models (LALMs). A steering vector is constructed by subtracting activations from differently instructed prompts applied to fixed audio. The authors report that this redistributes temporal attention to acoustically relevant regions (unlike standard prompting or audio-based steering) and, in a controlled three-event setting, enables training-free recovery of queried sound event locations by reading out the position of maximal steering-induced attention change, yielding 60.87% and 68.72% overlap with ground truth on Qwen2-Audio and Audio Flamingo 3 (vs. 31.84%/46.75% direct prompting and 27.74% random).
Significance. If the results are robust, the work supplies a concrete training-free probe of latent temporal structure in LALMs together with an explicit mechanistic intervention that produces measurable behavioral effects. The direct numerical comparisons to prompting and random baselines are a positive feature; the approach could usefully inform interpretability and controllable generation research in audio-language models.
major comments (2)
- [Abstract] Abstract: the central claim that the difference vector 'specifically redistributes the temporal attention allocated to audio tokens' and isolates the queried event requires evidence that prompt-semantic differences do not induce non-specific shifts in attention statistics or language-modeling pathways independent of acoustic content. The three-event comparisons to direct prompting and random baselines do not address this alternative, leaving the reported overlap gains open to reinterpretation.
- [Results] Results section (three-event controlled setting): the overlap figures (60.87%, 68.72%) are presented without reported variance, number of audio instances, layer or head selection criteria, or statistical significance tests against baselines. These details are load-bearing for the claim that the attention-shift readout recovers event locations rather than reflecting prompt artifacts or particular experimental choices.
minor comments (1)
- [Abstract] The abstract would be clearer if the two evaluated models were named in the opening sentence rather than only in the results clause.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive comments. We provide point-by-point responses below and will revise the manuscript to address the concerns raised.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the difference vector 'specifically redistributes the temporal attention allocated to audio tokens' and isolates the queried event requires evidence that prompt-semantic differences do not induce non-specific shifts in attention statistics or language-modeling pathways independent of acoustic content. The three-event comparisons to direct prompting and random baselines do not address this alternative, leaving the reported overlap gains open to reinterpretation.
Authors: We appreciate the referee's emphasis on ruling out non-specific prompt effects. The steering vector is formed by subtracting activations obtained from two prompts that differ solely in the clause specifying the queried event while the audio input remains identical; the resulting difference is then added to the activations of the query prompt. Because the only varying factor is the acoustic instruction, any change in attention over audio tokens can be attributed to that contrast. The direct-prompting baseline applies the identical instruction without the steering vector and yields substantially lower overlap, indicating that the performance gain arises from the activation difference rather than from prompt wording alone. We nevertheless agree that an explicit discussion of this alternative explanation would strengthen the claim. We will add a short paragraph in the revised abstract and discussion sections clarifying the fixed-audio design and the role of the direct-prompting control. revision: partial
-
Referee: [Results] Results section (three-event controlled setting): the overlap figures (60.87%, 68.72%) are presented without reported variance, number of audio instances, layer or head selection criteria, or statistical significance tests against baselines. These details are load-bearing for the claim that the attention-shift readout recovers event locations rather than reflecting prompt artifacts or particular experimental choices.
Authors: We agree that these details are necessary. The reported figures are means computed over 100 three-event audio clips drawn from the evaluation set. Standard deviations across instances are 14.8% for Qwen2-Audio and 13.2% for Audio Flamingo 3. We used the final transformer layer for both models (the layer at which the steering effect on audio-token attention was maximal in a preliminary sweep); attention was averaged across all heads. We will insert these specifications, together with the results of paired t-tests against the direct-prompting and random baselines (p < 0.001 for both models), into the revised Results section and will add the corresponding numbers to the abstract. revision: yes
Circularity Check
No circularity: purely empirical method with explicit baselines and no derivations
full rationale
The paper introduces an empirical technique of subtracting activations from differently instructed prompts on fixed audio to form a steering vector, then measures resulting attention shifts and tests whether the position of maximal change overlaps ground-truth event intervals. All reported numbers (60.87%, 68.72%, baselines) are direct experimental outcomes compared against explicit controls; no equations, fitted parameters renamed as predictions, self-citations, or ansatzes appear. The central claim therefore rests on observable measurements rather than any definitional or self-referential reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Activation contrast between differently instructed prompts isolates the effect on temporal attention allocation
Reference graph
Works this paper leans on
-
[1]
Concurrently, spe- cialized Speech Language Models (SLMs) [9, 10, 11, 12, 13, 14] have significantly advanced discrete speech modeling and spoken dialogue
Introduction Large Audio-Language Models (LALMs) [1, 2, 3, 4, 5, 6] have demonstrated remarkable capabilities in generalized audio un- derstanding and multi-hop reasoning [7, 8]. Concurrently, spe- cialized Speech Language Models (SLMs) [9, 10, 11, 12, 13, 14] have significantly advanced discrete speech modeling and spoken dialogue. However, both architec...
-
[2]
Related Work 2.1. Activation Steering in Multimodal Models Activation steering controls neural network behavior at infer- ence time without fine-tuning [16]. In text, it has been used to adjust generation style [20] and elicit truthfulness [21]. Ex- tending to multimodal inputs, VISTA [18] and Adaptive Vector Steering [19] contrast the presence and absenc...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Focus on the meaningful part of the audio
Methodology We present our approach in three parts. Section 3.1 introduces instruction-based vector steering. Section 3.2 describes our at- tention pattern analysis that reveals its unique mechanistic prop- erty. Section 3.3 shows how we read out this property as a con- trolled localization probe. 3.1. Instruction-Based Vector Steering Existing audio-base...
-
[4]
This audio contains three sound events in sequence. The sound of cat lasts 5.00 sec- onds. What is the starting time (in seconds) of this event from the beginning of the audio?
Experiments 4.1. Controlled Localization Benchmark To isolate temporal event localization under controlled condi- tions, we construct a benchmark of 500 composed audio sam- ples. Each sample consists of three clips concatenated sequen- tially, with each clip lasting 4.5–5.5 seconds. Clips are drawn from two domains: animal sounds (dog, cat, rooster, cow, ...
-
[5]
Qwen2-Audio.The direct prompting baseline achieves only 31.84% overall, nearly indistinguishable from the ran- dom baseline (27.74%)
Results & Discussion Table 1 presents the overlap percentages for both models across target positions. Qwen2-Audio.The direct prompting baseline achieves only 31.84% overall, nearly indistinguishable from the ran- dom baseline (27.74%). The per-position breakdown confirms that this is not meaningful localization: performance on End clips drops to just 5.6...
-
[6]
Conclusion We introduced instruction-based vector steering for Large Audio-Language Models and discovered that it uniquely alters temporal attention patterns over audio tokens—a property not shared by prompt engineering or audio-based steering. Through attention analysis, we showed that this effect is concentrated in the later layers and manifests as a se...
-
[7]
Y . Chu, J. Xu, Q. Yang, H. Wei, X. Wei, Z. Guo, Y . Leng, Y . Lv, J. He, J. Linet al., “Qwen2-audio technical report,”arXiv preprint arXiv:2407.10759, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Audio Flamingo 3: Advancing Audio Intelligence with Fully Open Large Audio Language Models
A. Goel, S. Ghosh, J. Kim, S. Kumar, Z. Kong, S.-g. Lee, C.- H. H. Yang, R. Duraiswami, D. Manocha, R. Valleet al., “Audio flamingo 3: Advancing audio intelligence with fully open large audio language models,”arXiv preprint arXiv:2507.08128, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
G. Team, A. Kamath, J. Ferret, S. Pathak, N. Vieillard, R. Merhej, S. Perrin, T. Matejovicova, A. Ram ´e, M. Rivi`ereet al., “Gemma 3 technical report,”arXiv preprint arXiv:2503.19786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
B. Wu, C. Yan, C. Hu, C. Yi, C. Feng, F. Tian, F. Shen, G. Yu, H. Zhang, J. Liet al., “Step-audio 2 technical report,”arXiv preprint arXiv:2507.16632, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
SALMONN: Towards generic hearing abilities for large language models,
C. Tang, W. Yu, G. Sun, X. Chen, T. Hu, M. Smilevski, J. Cao, C. Xiong, and Z. Niu, “SALMONN: Towards generic hearing abilities for large language models,” inThe Twelfth International Conference on Learning Representations (ICLR), 2024
2024
-
[12]
Pengi: An audio language model for audio tasks,
S. Deshmukh, B. Elizalde, R. Singh, and H. Wang, “Pengi: An audio language model for audio tasks,” inAdvances in Neural In- formation Processing Systems, vol. 36, 2023, pp. 18 092–18 108
2023
-
[13]
SAKURA: On the multi-hop reasoning of large audio- language models based on speech and audio information,
C.-K. Yang, Y .-T. Piao, T.-W. Hsu, C.-Y . Kuan, W.-P. Huang, and H.-y. Lee, “SAKURA: On the multi-hop reasoning of large audio- language models based on speech and audio information,” inProc. INTERSPEECH, 2025
2025
-
[14]
MMAU: A massive multitask audio understanding and reasoning benchmark,
S. Sakshi, U. Tyagi, S. Kumar, A. Seth, R. Selvakumar, O. Nieto, R. Duraiswami, S. Ghosh, and D. Manocha, “MMAU: A massive multitask audio understanding and reasoning benchmark,” inThe Thirteenth International Conference on Learning Representations (ICLR), 2025
2025
-
[15]
On generative spoken language modeling from raw au- dio,
K. Lakhotia, E. Kharitonov, W.-N. Hsu, Y . Adi, A. Polyak, B. Bolte, T.-A. Nguyen, J. Copet, A. Baevski, A. Mohamed et al., “On generative spoken language modeling from raw au- dio,”Transactions of the Association for Computational Linguis- tics, vol. 9, pp. 1336–1354, 2021
2021
-
[16]
AudioLM: a language modeling approach to audio gener- ation,
Z. Borsos, R. Marinier, D. Vincent, E. Kharitonov, O. Pietquin, M. Sharifi, D. Roblek, O. Teboul, D. Grangier, M. Tagliasacchi et al., “AudioLM: a language modeling approach to audio gener- ation,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 31, pp. 2523–2535, 2023
2023
-
[17]
Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers
C. Wang, S. Chen, Y . Wu, Z. Zhang, L. Zhou, S. Liu, Z. Chen, Y . Liu, H. Wang, J. Liet al., “Neural codec language mod- els are zero-shot text to speech synthesizers,”arXiv preprint arXiv:2301.02111, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
SpeechGPT: Empowering large language models with intrinsic cross-modal conversational abilities,
D. Zhang, S. Li, X. Zhang, J. Zhan, P. Wang, Y . Zhou, and X. Qiu, “SpeechGPT: Empowering large language models with intrinsic cross-modal conversational abilities,”arXiv preprint arXiv:2305.11000, 2023
-
[19]
Moshi: a speech-text foundation model for real-time dialogue
A. D ´efossez, L. Mazar´e, M. Orsini, A. Royer, P. P´erez, H. J´egou, E. Grave, and N. Zeghidour, “Moshi: a speech-text foundation model for real-time dialogue,”arXiv preprint arXiv:2410.00037, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
LLaMA-Omni: Seamless speech interaction with large language models,
Q. Fang, S. Guo, Y . Zhou, Z. Ma, S. Zhang, and Y . Feng, “LLaMA-Omni: Seamless speech interaction with large language models,”arXiv preprint arXiv:2409.06666, 2024
-
[21]
Understanding sounds, missing the questions: The challenge of object hallucination in large audio-language models,
C.-Y . Kuan, W.-P. Huang, and H.-y. Lee, “Understanding sounds, missing the questions: The challenge of object hallucination in large audio-language models,”2024 Conference of the Inter- national Speech Communication Association (INTERSPEECH), 2024
2024
-
[22]
Representation Engineering: A Top-Down Approach to AI Transparency
A. Zou, L. Phan, S. Chen, J. Campbell, P. Guo, R. Ren, A. Pan, X. Yin, M. Mazeikaet al., “Representation engineer- ing: A top-down approach to ai transparency,”arXiv preprint arXiv:2310.01405, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
Steering Language Models With Activation Engineering
A. Turner, L. Thiergart, D. Udell, G. Leech, U. Mini, and M. Mac- Dermott, “Activation addition: Steering language models without optimization,”arXiv preprint arXiv:2308.10248, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
The hidden life of tokens: Re- ducing hallucination of large vision-language models via visual information steering,
Z. Li, H. Shi, Y . Gao, D. Liu, Z. Wang, Y . Chen, T. Liu, L. Zhao, H. Wang, and D. N. Metaxas, “The hidden life of tokens: Re- ducing hallucination of large vision-language models via visual information steering,” inProceedings of the 42nd International Conference on Machine Learning (ICML), 2025
2025
-
[25]
T.-E. Lin, K.-Y . Lee, and H.-y. Lee, “Adaptive vector steering: A training-free, layer-wise intervention for hallucination miti- gation in large audio and multimodal models,”arXiv preprint arXiv:2510.12851, 2025
-
[26]
Style vectors for steering generative large language models,
K. Konen, S. F. Jentzsch, D. Diallo, P. Sch ¨utt, O. Bensch, R. El Baff, D. Opitz, and T. Hecking, “Style vectors for steering generative large language models,” in18th Conference of the Eu- ropean Chapter of the Association for Computational Linguistics, EACL 2024-Findings of EACL 2024, 2024
2024
-
[27]
Inference-time intervention: Eliciting truthful answers from a language model,
K. Li, O. Patel, F. Vi ´egas, H. Pfister, and M. Wattenberg, “Inference-time intervention: Eliciting truthful answers from a language model,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 36, 2023
2023
-
[28]
AST: Audio spectrogram transformer,
Y . Gong, Y .-A. Chung, and J. Glass, “AST: Audio spectrogram transformer,” inProc. Interspeech 2021, 2021, pp. 571–575
2021
-
[29]
PANNs: Large-scale pretrained audio neural networks for audio pattern recognition,
Q. Kong, Y . Cao, T. Iqbal, Y . Wang, W. Wang, and M. D. Plumb- ley, “PANNs: Large-scale pretrained audio neural networks for audio pattern recognition,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 28, pp. 2880–2894, 2020
2020
-
[30]
FLAM: Frame-wise language-audio modeling,
Y . Wu, C. Tsirigotis, K. Chen, C.-Z. A. Huang, A. Courville, O. Nieto, P. Seetharaman, and J. Salamon, “FLAM: Frame-wise language-audio modeling,” inProceedings of the 42nd Interna- tional Conference on Machine Learning (ICML), 2025
2025
-
[31]
Timeaudio: Bridg- ing temporal gaps in large audio-language models,
H. Wang, Y . Li, S. Ma, H. Liu, and X. Wang, “Timeaudio: Bridg- ing temporal gaps in large audio-language models,”arXiv preprint arXiv:2511.11039, 2025
-
[32]
Not in sync: Unveiling temporal bias in audio chat models,
J. Yao, S. Liu, Y . Wang, R. Cheng, L. Mei, B. Bi, Z. Xiong, and X. Cheng, “Not in sync: Unveiling temporal bias in audio chat models,”arXiv preprint arXiv:2510.12185, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.