Factions Within, Uncertain Across: Within-Document Reader Sub-Groups in Social Highlighting
Pith reviewed 2026-06-27 08:33 UTC · model grok-4.3
The pith
Readers form strong sub-groups when highlighting the same document, with pair agreement exceeding predictions from shared features.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
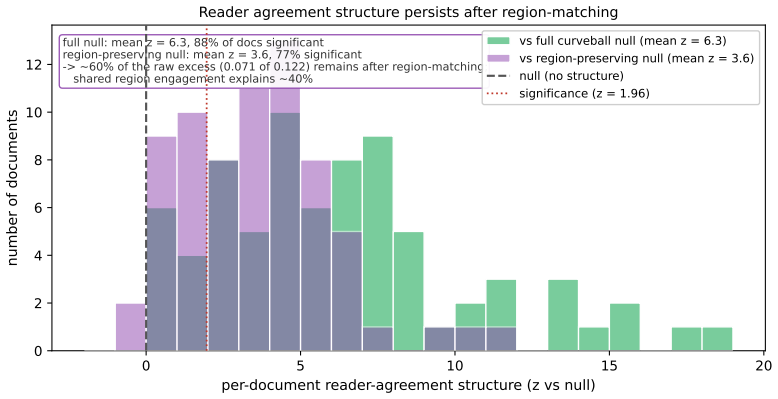
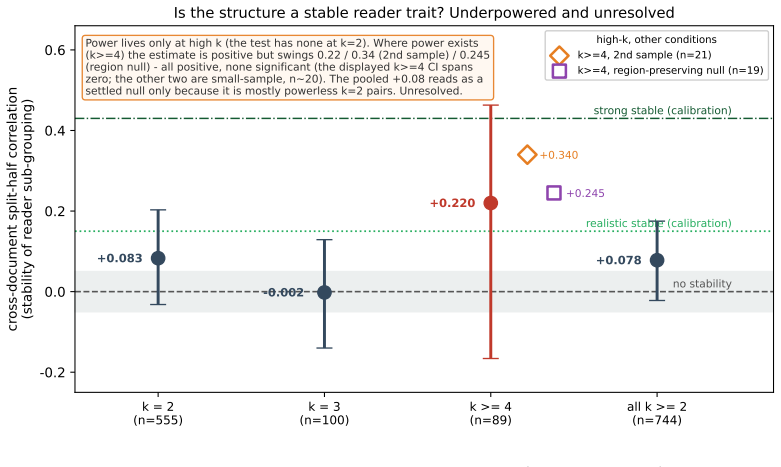
Within a document, readers form strong sub-groups: pairs agree far beyond what shared salience, mark density, and sentence popularity predict, with nearest-neighbour agreement z=+6.3 significant in 88 percent of documents. Under an eight-block region-preserving null, shared engagement with the same coarse regions accounts for about 40 percent of this excess; the majority survives as finer reader-specific agreement at z=+3.6, significant in 77 percent of documents. Cross-document split-half reproducibility of a pair's agreement is near zero, and power calibration shows the test is informative only for pairs that co-read many documents, leaving stability unresolved.
What carries the argument
Margin-preserving curveball null model paired with an eight-block region-preserving null, applied to isolate excess nearest-neighbour agreement attributable to reader sub-groups after removing effects of salience, density, popularity, and coarse region engagement.
If this is right
- The within-document crowd in social highlighting is factional rather than consensual.
- Coarse region engagement explains only part of the excess agreement between readers.
- Cross-document stability of reader pairs cannot be detected reliably with current levels of document overlap.
- The data remain consistent with either situational grouping or a weak stable reader trait.
Where Pith is reading between the lines
- Platforms that surface highlights could benefit from showing faction-specific rather than averaged marks within a single document.
- Larger datasets focused on readers who repeatedly co-read the same set of documents would be needed to resolve whether the factions are stable traits.
- The same null-model approach could be applied to other forms of social annotation such as comments or votes to test for analogous sub-group structure.
Load-bearing premise
The curveball null and eight-block region-preserving null together capture every non-subgroup source of agreement in the highlighting data.
What would settle it
A new collection of documents in which nearest-neighbour agreement drops to non-significant levels after the eight-block region-preserving null is applied would falsify the claim of persistent finer reader-specific sub-groups.
Figures
read the original abstract
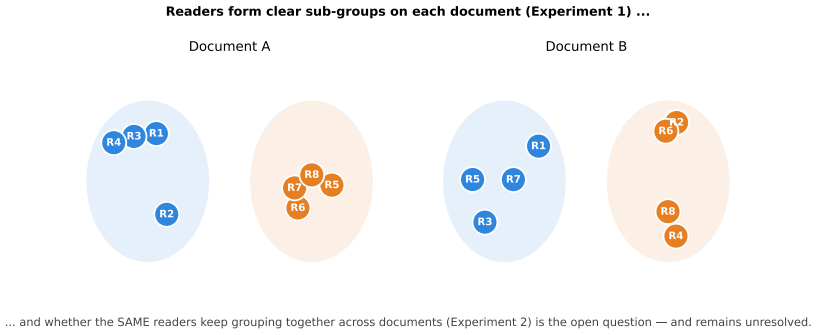
When many people highlight the same document, is the crowd a single consensus, or is it internally structured into reader sub-groups that mark different things -- and is that structure a stable property of a reader or of the document? Building on prior work showing an individual's within-document highlighting signal is a whisper while individuality lives in selection, we ask the group-level question on a co-readership platform using a margin-preserving curveball null. Experiment 1: within a document, readers form strong sub-groups -- pairs agree far beyond what shared salience, mark density, and sentence popularity predict (nearest-neighbour agreement z=+6.3, significant in 88% of documents). Under an eight-block region-preserving null, shared engagement with the same coarse regions of the document accounts for about 40% of this excess; the majority survives as finer reader-specific agreement (z=+3.6, 77% significant). So the within-document crowd is, in a descriptive sense, factional. Experiment 2: is that grouping a stable reader trait? Here we are honest about power. The cross-document split-half reproducibility of a pair's agreement is near zero pooled (+0.078 and 0.000 in two separately drawn samples), and a power calibration shows the test is informative only for pairs that co-read many documents. In the only informative high-overlap subset (k>=4), point estimates are positive but small-sample, imprecise across the separately drawn samples, never significant, and attenuate under the region-preserving null. We therefore leave cross-document stability unresolved: the data is consistent with anything from situational grouping to a weak-to-moderate stable reader trait. The crowd is factional within a document; whether its factions follow the reader across documents is, honestly, beyond our reach.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that within a single document, readers form sub-groups whose pairwise nearest-neighbour agreement substantially exceeds predictions from a margin-preserving curveball null (z=+6.3, significant in 88% of documents) and, after further conditioning on an eight-block region-preserving null, still shows residual excess (z=+3.6, significant in 77% of documents), which the authors attribute to finer reader-specific agreement. Cross-document stability of these groupings is left unresolved: split-half reproducibility is near zero overall, and even in the high-overlap (k>=4) subset the estimates are small, imprecise, and non-significant after the region null.
Significance. If the attribution of the residual excess to reader sub-groups is valid, the result supplies concrete evidence that social highlighting crowds are internally factional at the within-document level, with roughly 60% of the excess agreement surviving coarse region controls. The manuscript's strengths include the explicit use of two independent permutation nulls, reporting of z-scores and significance fractions, and an honest power calibration that correctly limits claims about cross-document stability. These features make the within-document finding falsifiable and the cross-document non-finding informative.
major comments (1)
- [Experiment 1] Experiment 1 (eight-block region-preserving null): the interpretation that the surviving z=+3.6 represents 'finer reader-specific agreement' requires that the eight-block null, together with the curveball, exhausts all non-subgroup sources of nearest-neighbour agreement. The manuscript does not demonstrate that medium-scale document structure (within-block topical clusters, sentence adjacency, or non-uniform salience inside blocks) is fully captured; any residual structure at those scales would directly undermine the attribution step without changing the raw excess over the curveball null.
minor comments (1)
- [Abstract and Experiment 1] The abstract and main text should explicitly state the number of documents and readers in each experiment so that the reported significance fractions (88%, 77%) can be evaluated against sample size.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. The single major comment identifies a substantive limitation in how we interpret the residual excess agreement after the eight-block null. We respond to it directly below and indicate the changes we will make.
read point-by-point responses
-
Referee: Experiment 1 (eight-block region-preserving null): the interpretation that the surviving z=+3.6 represents 'finer reader-specific agreement' requires that the eight-block null, together with the curveball, exhausts all non-subgroup sources of nearest-neighbour agreement. The manuscript does not demonstrate that medium-scale document structure (within-block topical clusters, sentence adjacency, or non-uniform salience inside blocks) is fully captured; any residual structure at those scales would directly undermine the attribution step without changing the raw excess over the curveball null.
Authors: We agree that the eight-block null does not explicitly control for within-block medium-scale structure such as topical clusters, sentence adjacency, or non-uniform salience. The null was chosen to capture coarse regional engagement (approximately 1/8 of the document per block), and the reduction from z=+6.3 to z=+3.6 shows that shared coarse-region preferences explain roughly 40% of the excess. However, we do not claim the two nulls together exhaust every alternative source; the surviving signal is therefore consistent with finer reader-specific agreement but could partly reflect unmodeled medium-scale document features. We will revise the manuscript to (a) state this limitation explicitly in the Experiment 1 results and discussion sections and (b) temper the attribution language from 'finer reader-specific agreement' to 'residual excess consistent with finer-scale agreement after coarse-region controls.' No new analyses are feasible with the current data, but the revision will make the interpretive step more cautious while preserving the reported z-scores and significance fractions. revision: partial
Circularity Check
No significant circularity
full rationale
The paper's derivation relies on z-scores computed as deviations of observed nearest-neighbour agreement from expectations generated by independently constructed margin-preserving curveball and eight-block region-preserving null models. These nulls preserve specified margins (reader/sentence margins and coarse-region engagement) without reference to the pairwise agreement values under test, and the residuals are interpreted via standard statistical attribution rather than any self-referential equation, fitted parameter renamed as prediction, or load-bearing self-citation. No step reduces the reported excess agreement (z=+6.3 or z=+3.6) to the input data by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math The curveball algorithm generates a uniform sample from the space of binary matrices with fixed row and column sums.
- domain assumption Highlighting decisions can be treated as a binary matrix without loss of the relevant structure for testing sub-group agreement.
Forward citations
Cited by 2 Pith papers
-
Trait, Not State: The Durability of Reading Identity in Social Highlighting
Readers' highlighting patterns on a social web platform remain stable over 24 months as a durable trait, with personal profiles from early documents predicting future selections at roughly 3x the average precision of ...
-
The Long Tail, Not the Front Page: Cold-Start Prediction of Crowd Highlight Salience
A supervised logistic ranker on embeddings and features beats the lead baseline by 0.044 average precision in retrospective cold-start prediction of crowd highlights.
Reference graph
Works this paper leans on
-
[1]
Personal Salience: Highlighting Is Social, but Individuality Lives in Selection
K. Nakayashiki and K. Watanabe. Personal Salience: Highlighting Is Social, but Individuality Lives in Selection. arXiv:2606.09024, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Selection, Not Salience: The Shape and Limits of Personalization in Social Highlighting
K. Nakayashiki and K. Watanabe. Selection, Not Salience: The Shape and Limits of Personal- ization in Social Highlighting. arXiv:2606.10398, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Winchell et al
A. Winchell et al. Highlights as an Early Predictor of Student Comprehension and Interests. Cognitive Science, 2020
2020
-
[4]
Aroyo and C
L. Aroyo and C. Welty. Truth Is a Lie: Crowd Truth and the Seven Myths of Human Annotation. AI Magazine, 2015
2015
- [5]
-
[6]
Surowiecki
J. Surowiecki. The Wisdom of Crowds. Doubleday, 2004
2004
-
[7]
Schoenegger et al
P. Schoenegger et al. Wisdom of the Silicon Crowd: LLM Ensemble Prediction Capabilities Rival Human Crowd Accuracy. Science Advances, 2024
2024
-
[8]
J. S. Park et al. Generative Agent Simulations of 1,000 People. arXiv:2411.10109, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Gygli and M
M. Gygli and M. Soleymani. PHD-GIFs: Personalized Highlight Detection for Automatic GIF Creation. ACM MM, 2018
2018
-
[10]
Salemi et al
A. Salemi et al. LaMP: When Large Language Models Meet Personalization. ACL, 2024. 11
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.