Personal Salience: Highlighting Is Social, but Individuality Lives in Selection
Pith reviewed 2026-06-27 15:00 UTC · model grok-4.3
The pith
Highlighting is mostly predicted by what others mark, but selecting among already-salient passages carries a six-to-eight times stronger personal signal.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
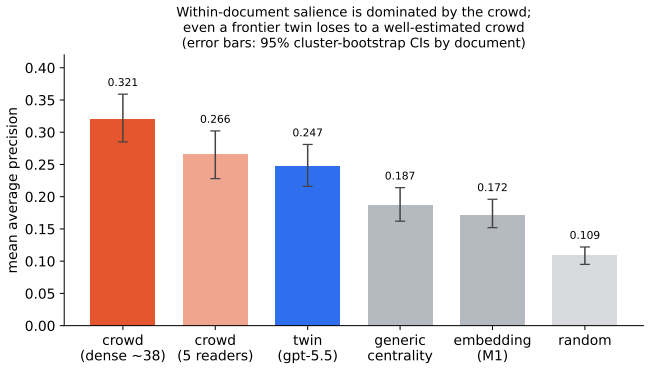
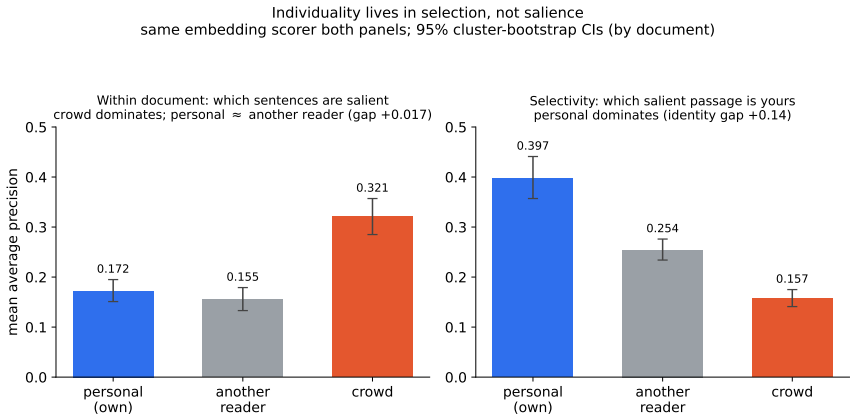
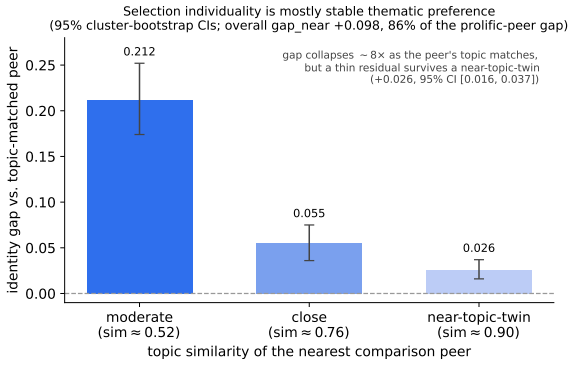
Highlighting is social: which sentences you mark is predicted far better by the crowd than by structure or by a personal model, and even a well-estimated crowd, an information-privileged baseline that sees others' marks on the same document, beats a frontier LLM twin built from your other-document history; the within-document personal signal is at most a whisper (own-vs-other gap +0.017 by an embedding scorer, small but significant). Second, in sharp contrast, individuality lives in selection: asked which of the already-salient passages are yours, your own history is a strong, leakage-free predictor (gap +0.14). A topic decomposition shows this is largely stable thematic preference: it shrin
What carries the argument
The co-readership identity control, which holds document and topic fixed to isolate the personal residual after subtracting generic and crowd salience.
If this is right
- Crowd salience dominates personal history when predicting initial highlights on the same document.
- Personal history predicts selection among already-salient passages with a substantially larger gap than it predicts the initial marks.
- The individual signal is six to eight times weaker for salience marking than for selection under the same scorer.
- Naive history-conditioning evaluations leak because the target's own marks enter the profile in roughly 42 percent of pairs, inflating personal scores by up to +0.15 AP.
- Small crowds overstate the degree of personalization compared with dense crowds.
Where Pith is reading between the lines
- Recommendation systems that surface reading material may gain more from modeling which salient items a user selects than from modeling what the user initially marks.
- The observed thematic stability in selection preferences suggests that long-term user profiles could be built from selection traces rather than raw highlight counts.
- Similar social-versus-selection asymmetries may appear in other annotation behaviors such as commenting or rating the same content.
Load-bearing premise
The co-readership identity control fully holds document and topic fixed while isolating the personal residual.
What would settle it
If a personal model trained only on a reader's marks from other documents predicted highlights on a target document as well as a crowd model that sees marks on that same document, the claim of weak personal salience would be falsified.
Figures
read the original abstract
Social highlighters let people mark passages that matter to them. We ask how much of an individual is recoverable from these naturalistic traces, using a co-readership identity control (the same document highlighted by many users) that holds document and topic fixed and asks whether a person's own history predicts their marks better than another reader's does. We separate generic salience (structure), crowd salience (what others marked), and personal salience (the individual residual). First, highlighting is social: which sentences you mark is predicted far better by the crowd than by structure or by a personal model, and even a well-estimated crowd, an information-privileged baseline that sees others' marks on the same document, beats a frontier LLM twin built from your other-document history; the within-document personal signal is at most a whisper (own-vs-other gap +0.017 by an embedding scorer, small but significant). Second, in sharp contrast, individuality lives in selection: asked which of the already-salient passages are yours, your own history is a strong, leakage-free predictor (gap +0.14). A topic decomposition shows this is largely stable thematic preference: it shrinks ~6-8x against a topically-matched peer, and a thin residual cannot be separated from finer topic. The non-obvious part is an asymmetry: under the same scorer the individual signal is ~6-8x weaker in salience than in selection. Methodologically, naive history-conditioning evaluations leak (the target's own marks enter the profile in ~42% of pairs, inflating personal scores by up to +0.15 AP) and small crowds overstate personalization; our results are leakage-free, use a dense crowd, and a model-matched control. Highlights carry a genuine individual signature, but a thin layer over a strong shared one, surfacing far more in which salient things a person selects than in what is salient.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that highlighting behavior in social highlighters is predominantly social: crowd salience predicts marks far better than document structure or personal history from other documents, with the within-document personal residual at most +0.017 (embedding scorer, own-vs-other gap). In contrast, when selecting among already-salient passages, personal history is a stronger predictor (gap +0.14). This yields a 6-8x asymmetry in individual signal strength between salience and selection. The design uses a co-readership control (same document, many users) to hold document/topic fixed, a topic-matched peer baseline, and leakage-free evaluation; the conclusion is that highlights carry a thin genuine individual signature over a strong shared one, surfacing more in selection than in salience determination.
Significance. If the reported gaps and asymmetry hold after the described controls, the work demonstrates that personalization opportunities in social annotation and IR systems lie primarily in modeling selection among salient items rather than identifying salience itself, while underscoring the dominance of crowd signals. Strengths include the leakage-free methodology, dense-crowd setting, model-matched controls, and explicit acknowledgment that the residual personal signal cannot be cleanly separated from finer topic overlap.
major comments (1)
- [Abstract] Abstract (experimental design paragraph): The co-readership identity control is described as holding 'document and topic fixed' while isolating the personal residual, yet the same paragraph states that the gap 'shrinks ~6-8x against a topically-matched peer, and a thin residual cannot be separated from finer topic.' This qualification directly bears on whether the +0.017 salience vs. +0.14 selection asymmetry can be attributed to individuality rather than residual sub-topic or stylistic correlation among co-readers; additional analysis (e.g., finer-grained topic decomposition or reader-style covariates) would be needed to strengthen the isolation claim.
Simulated Author's Rebuttal
We thank the referee for the careful review and minor revision recommendation. We address the comment on the abstract below and will revise for greater clarity on the scope of the co-readership control.
read point-by-point responses
-
Referee: [Abstract] Abstract (experimental design paragraph): The co-readership identity control is described as holding 'document and topic fixed' while isolating the personal residual, yet the same paragraph states that the gap 'shrinks ~6-8x against a topically-matched peer, and a thin residual cannot be separated from finer topic.' This qualification directly bears on whether the +0.017 salience vs. +0.14 selection asymmetry can be attributed to individuality rather than residual sub-topic or stylistic correlation among co-readers; additional analysis (e.g., finer-grained topic decomposition or reader-style covariates) would be needed to strengthen the isolation claim.
Authors: The abstract already states both the control and the qualification in the same paragraph, and the full manuscript reports an explicit topic decomposition showing the selection signal is largely thematic preference that shrinks 6-8x against topically-matched peers. The reported asymmetry is therefore presented after these controls, with the residual explicitly noted as inseparable from finer topic. We agree the abstract wording could more directly connect the control to this limitation to avoid any implication of clean isolation. We will revise the abstract to emphasize that the co-readership holds document and broad topic fixed but the thin residual may reflect sub-topic or stylistic overlap. The existing decomposition already addresses the core point; no new data collection for finer covariates is feasible here. revision: yes
Circularity Check
No significant circularity; empirical measurements with external controls
full rationale
The paper reports direct empirical comparisons of user histories against co-readers on identical documents to isolate personal residuals in salience and selection. The reported gaps (+0.017 in salience, +0.14 in selection) and the 6-8x asymmetry are computed from data splits and topic-matched peer baselines rather than any equations or derivations that reduce outputs to inputs by construction. No self-citations, fitted parameters renamed as predictions, or self-definitional steps appear in the load-bearing claims; the co-readership control and crowd baselines function as independent benchmarks external to the personal signal measurement.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 4 Pith papers
-
Trait, Not State: The Durability of Reading Identity in Social Highlighting
Readers' highlighting patterns on a social web platform remain stable over 24 months as a durable trait, with personal profiles from early documents predicting future selections at roughly 3x the average precision of ...
-
Factions Within, Uncertain Across: Within-Document Reader Sub-Groups in Social Highlighting
Within-document highlighting shows strong reader sub-groups beyond null expectations from salience and popularity, but cross-document reproducibility of pair agreement is near zero and unresolved due to insufficient overlap.
-
Selection, Not Salience: The Shape and Limits of Personalization in Social Highlighting
Personalization in social highlighting is modest and topic-driven at document selection (~+0.13) but yields no reliable gain at the sentence salience layer over impersonal baselines.
-
The Long Tail, Not the Front Page: Cold-Start Prediction of Crowd Highlight Salience
A supervised logistic ranker on embeddings and features beats the lead baseline by 0.044 average precision in retrospective cold-start prediction of crowd highlights.
Reference graph
Works this paper leans on
-
[1]
J. S. Park et al. Generative Agent Simulations of 1,000 People. 2024. arXiv:2411.10109
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
S. Santurkar et al. Whose Opinions Do Language Models Reflect? ICML, 2023. arXiv:2303.17548
-
[3]
LaMP : When large language models meet personalization
A. Salemi et al. LaMP: When Large Language Models Meet Personalization. ACL, 2024. arXiv:2304.11406. 11
-
[4]
Aroyo and C
L. Aroyo and C. Welty. Truth Is a Lie: Crowd Truth and the Seven Myths of Human Annotation. AI Magazine, 2015
2015
- [5]
-
[6]
Surowiecki
J. Surowiecki. The Wisdom of Crowds. Doubleday, 2004
2004
-
[7]
M. Shardlow et al. One Size Does Not Fit All: The Case for Personalised Word Complexity Models. 2022. arXiv:2205.02564
-
[8]
Personalized Saliency and its Prediction
Y. Xu et al. Beyond Universal Saliency: Personalized Saliency Prediction with Multi-task CNN. IJCAI, 2017. arXiv:1710.03011
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[9]
PHD-GIFs: Personalized Highlight Detection for Automatic GIF Creation
M. Gygli and M. Soleymani. PHD-GIFs: Personalized Highlight Detection for Automatic GIF Creation. 2018. arXiv:1804.06604
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[10]
Winchell et al
A. Winchell et al. Highlights as an Early Predictor of Student Comprehension and Interests. Cognitive Science, 2020
2020
- [11]
-
[12]
S. A. Golder and B. A. Huberman. Usage Patterns of Collaborative Tagging Systems. Journal of Information Science, 32(2):198–208, 2006
2006
-
[13]
S. Zyto, D. Karger, M. Ackerman, and S. Mahajan. Successful Classroom Deployment of a Social Document Annotation System. CHI, 2012. 12
2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.