Keep Policy Gradient in Charge: Sibling-Guided Credit Distillation for Long-Horizon Tool-Use Agents
Pith reviewed 2026-07-01 07:46 UTC · model grok-4.3
The pith
Sibling-Guided Credit Distillation reshapes GRPO advantages from LLM summaries of sibling rollouts to improve long-horizon tool-use performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
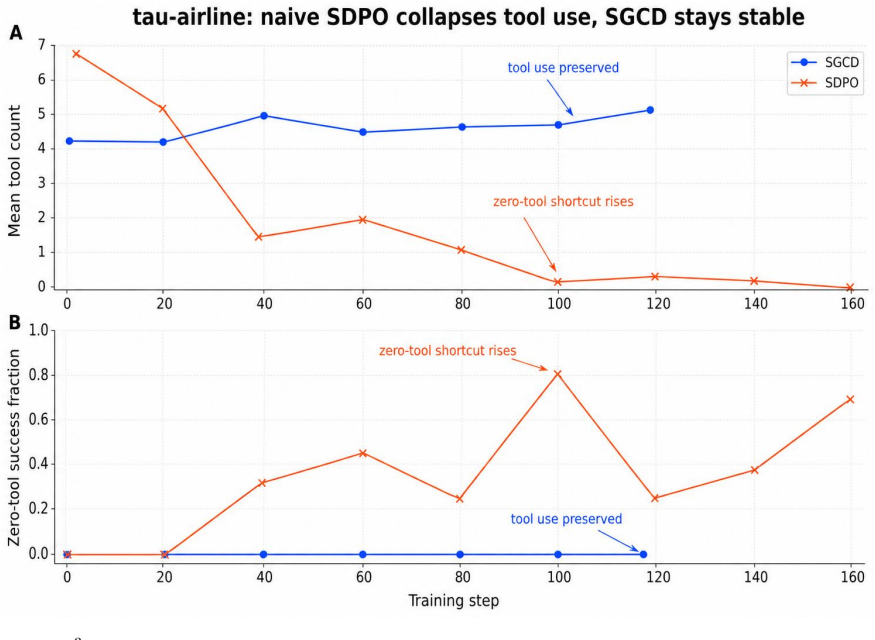
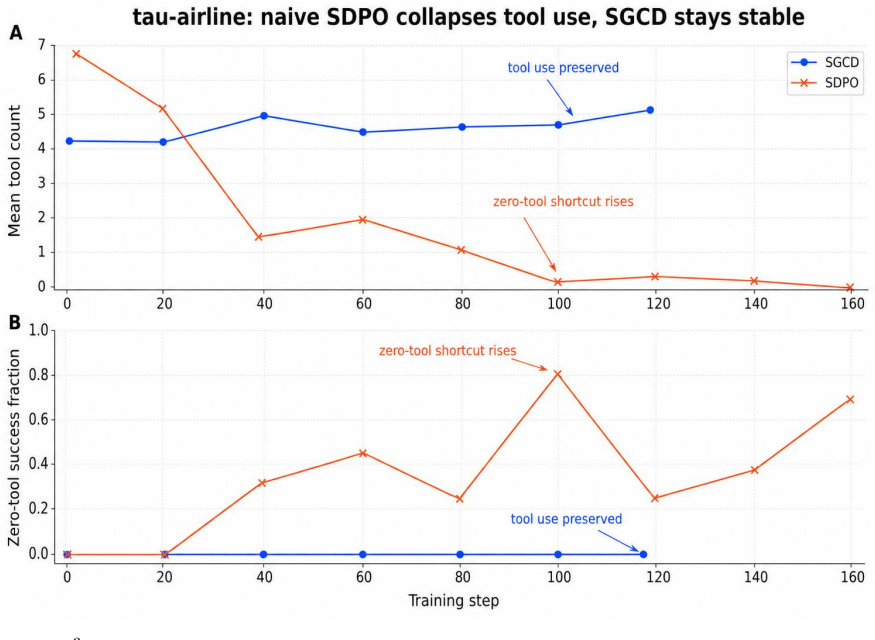
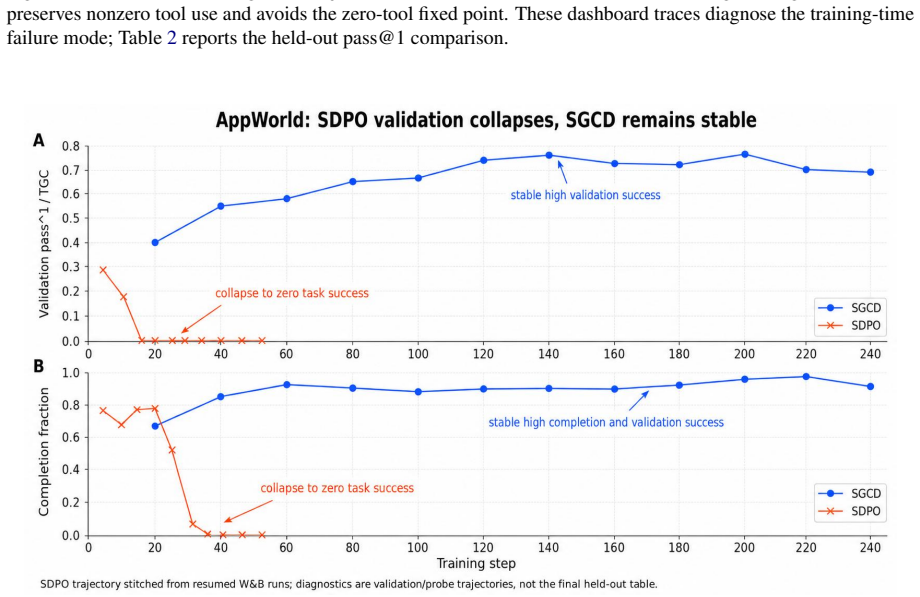
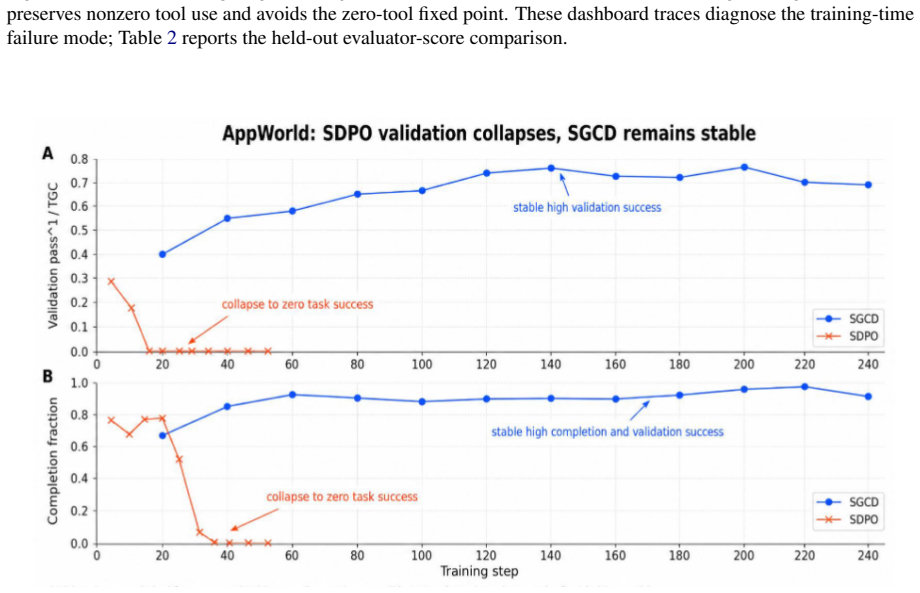
SGCD produces mixed successful and failed sibling rollouts, uses an external LLM to summarize their contrast into a training-only credit reference, and applies detached teacher/student divergence to reshape GRPO token advantages. The deployed student receives only the clean task prompt. Across AppWorld and tau^3-airline, SGCD reports higher held-out point estimates than GRPO-family comparators: AppWorld TGC improves from 42.9 to 45.6 on test_normal and from 24.7 to 27.0 on test_challenge, and tau^3-airline held-out evaluator score improves from 0.583 to 0.602.
What carries the argument
Sibling-Guided Credit Distillation (SGCD), which bounds credit weighting via LLM-summarized contrasts from sibling rollouts and detached divergence to reshape advantages without competing as an actor loss.
Load-bearing premise
The external LLM produces accurate, unbiased summaries of the contrast between successful and failed sibling rollouts that can be safely converted into token-level credit references without introducing systematic errors that distort the GRPO advantages.
What would settle it
Replacing the LLM-generated contrast summary with random credit signals of matching format and checking whether the held-out performance gains over GRPO baselines disappear on the same AppWorld and tau^3-airline splits.
Figures

read the original abstract
Long-horizon tool-use reinforcement learning learns from outcome verification, but trajectory-level advantages are broadcast over reasoning, API, and answer tokens. Direct self-distillation can supply a denser signal, but in our experiments it can also destroy tool use by rehearsing teacher behavior without identifying which actions the verifier rewards. We introduce Sibling-Guided Credit Distillation (SGCD), which uses distillation for bounded credit weighting rather than as a competing actor loss. Dynamic sampling produces mixed successful and failed sibling rollouts; an external LLM summarizes their contrast into a training-only credit reference; and detached teacher/student divergence reshapes GRPO token advantages. The deployed student receives only the clean task prompt. Across AppWorld and tau^3-airline, SGCD reports higher held-out point estimates than GRPO-family comparators: AppWorld TGC improves from 42.9 to 45.6 on test_normal and from 24.7 to 27.0 on test_challenge, and tau^3-airline held-out evaluator score improves from 0.583 to 0.602. These results support a narrow design rule for long-horizon tool-use agents: use distillation to guide credit assignment while keeping policy gradient in charge of the actor update.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Sibling-Guided Credit Distillation (SGCD) for long-horizon tool-use RL. Dynamic sampling generates mixed successful/failed sibling rollouts; an external LLM summarizes their contrast into a training-only credit reference; detached divergence then reshapes GRPO token advantages while the policy-gradient actor update remains unchanged. The deployed student sees only the clean task prompt. On AppWorld, SGCD raises TGC from 42.9 to 45.6 (test_normal) and 24.7 to 27.0 (test_challenge); on tau^3-airline the held-out evaluator score rises from 0.583 to 0.602. These point estimates are presented as support for the design rule that distillation should guide credit assignment but not replace the policy-gradient update.
Significance. If the reported gains prove statistically reliable, the work supplies a concrete, narrow design principle for credit assignment in long-horizon tool-use agents: keep the actor update under policy gradient while using bounded, training-only distillation to densify token-level credit. The approach is empirically motivated and avoids the risk of teacher rehearsal destroying tool-use behavior.
major comments (2)
- [Results / abstract] Results (held-out numbers in abstract and §4): the central claim that SGCD produces reliably higher scores rests on three isolated point estimates (AppWorld test_normal 42.9→45.6, test_challenge 24.7→27.0; tau^3-airline 0.583→0.602). No standard deviations across seeds, confidence intervals, or hypothesis tests are supplied. In long-horizon tool-use RL, trajectory variance is high; without these statistics it is impossible to determine whether the deltas exceed noise or whether the credit-distillation mechanism is responsible.
- [§3.2–3.3] Method (§3.2–3.3): the external LLM is assumed to produce accurate, unbiased summaries of successful vs. failed sibling contrasts that can be converted into token-level credit references without systematic distortion. No ablation or sensitivity analysis of this summarizer (prompt, model choice, or error rate) is reported, yet the assumption is load-bearing for the credit signal that reshapes GRPO advantages.
minor comments (2)
- [§3.3] Notation for the detached divergence loss and the exact form of the reshaped advantage (Eq. in §3.3) should be written out explicitly rather than described only in prose.
- [§4 / Appendix] The paper should state the number of random seeds, total training steps, and exact hyper-parameter settings used for all GRPO-family baselines so that the comparison can be reproduced.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below, indicating the revisions we will make.
read point-by-point responses
-
Referee: [Results / abstract] Results (held-out numbers in abstract and §4): the central claim that SGCD produces reliably higher scores rests on three isolated point estimates (AppWorld test_normal 42.9→45.6, test_challenge 24.7→27.0; tau^3-airline 0.583→0.602). No standard deviations across seeds, confidence intervals, or hypothesis tests are supplied. In long-horizon tool-use RL, trajectory variance is high; without these statistics it is impossible to determine whether the deltas exceed noise or whether the credit-distillation mechanism is responsible.
Authors: We agree that the lack of variability statistics weakens the ability to assess whether the reported gains exceed noise. In the revised manuscript we will report standard deviations across multiple random seeds for the held-out metrics on both AppWorld and tau^3-airline, add confidence intervals, and include hypothesis tests where appropriate. revision: yes
-
Referee: [§3.2–3.3] Method (§3.2–3.3): the external LLM is assumed to produce accurate, unbiased summaries of successful vs. failed sibling contrasts that can be converted into token-level credit references without systematic distortion. No ablation or sensitivity analysis of this summarizer (prompt, model choice, or error rate) is reported, yet the assumption is load-bearing for the credit signal that reshapes GRPO advantages.
Authors: The LLM summarizer operates only at training time to produce detached credit references; the deployed policy never sees it. We did not include ablations on prompt, model, or error rate in the original submission. We will add an explicit limitations paragraph in §3 discussing possible summarizer biases and their implications for the credit signal. revision: partial
Circularity Check
No circularity: empirical procedure with held-out evaluation
full rationale
The paper describes an empirical RL training procedure (SGCD) that augments GRPO with external-LLM-derived credit references from sibling rollouts. Reported gains are point estimates on held-out test sets (AppWorld TGC, tau^3-airline evaluator score). No equation, derivation, or prediction reduces to a fitted parameter, self-citation, or input by construction; the central claim rests on external benchmark measurements rather than internal redefinition. This is the normal case for an applied training-method paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption An external LLM can produce accurate and unbiased summaries of the difference between successful and failed sibling rollouts that translate directly into useful token credit references.
Reference graph
Works this paper leans on
-
[1]
2015 , eprint =
Distilling the Knowledge in a Neural Network , author =. 2015 , eprint =
2015
-
[2]
2024 , eprint =
On-Policy Distillation of Language Models: Learning from Self-Generated Mistakes , author =. 2024 , eprint =
2024
-
[3]
Journal of Machine Learning Research , volume =
Learning Using Privileged Information: Similarity Control and Knowledge Transfer , author =. Journal of Machine Learning Research , volume =
-
[4]
Divergence Measures Based on the
Lin, Jianhua , journal =. Divergence Measures Based on the. 1991 , doi =
1991
-
[5]
2026 , eprint =
Reinforcement Learning via Self-Distillation , author =. 2026 , eprint =
2026
-
[6]
2026 , eprint =
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models , author =. 2026 , eprint =
2026
-
[8]
2026 , eprint =
Self-Distilled Agentic Reinforcement Learning , author =. 2026 , eprint =
2026
-
[9]
Machine Learning , volume =
Simple Statistical Gradient-Following Algorithms for Connectionist Reinforcement Learning , author =. Machine Learning , volume =. 1992 , doi =
1992
-
[10]
Advances in Neural Information Processing Systems , volume =
Policy Gradient Methods for Reinforcement Learning with Function Approximation , author =. Advances in Neural Information Processing Systems , volume =. 1999 , url =
1999
-
[11]
2017 , eprint =
Proximal Policy Optimization Algorithms , author =. 2017 , eprint =
2017
-
[13]
Understanding R1-Zero-Like Training: A Critical Perspective
Liu, Zichen and Chen, Changyu and Li, Wenjun and Qi, Penghui and Pang, Tianyu and Du, Chao and Lee, Wee Sun and Lin, Min , year =. Understanding. 2503.20783 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Rethinking the Trust Region in LLM Reinforcement Learning
Qi, Penghui and Zhou, Xiangxin and Liu, Zichen and Pang, Tianyu and Du, Chao and Lin, Min and Lee, Wee Sun , year =. Rethinking the Trust Region in. 2602.04879 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
- [16]
-
[17]
Chu, Xiangxiang and Huang, Hailang and Zhang, Xiao and Wei, Fei and Wang, Yong , year =. 2504.02546 , archivePrefix =
-
[18]
2025 , eprint =
Group Sequence Policy Optimization , author =. 2025 , eprint =
2025
-
[19]
2025 , eprint =
The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models , author =. 2025 , eprint =
2025
-
[26]
2026 , eprint =
The Many Faces of On-Policy Distillation: Pitfalls, Mechanisms, and Fixes , author =. 2026 , eprint =
2026
-
[27]
2026 , eprint =
Revisiting On-Policy Distillation: Empirical Failure Modes and Simple Fixes , author =. 2026 , eprint =
2026
-
[28]
2026 , eprint =
Rethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe , author =. 2026 , eprint =
2026
-
[29]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
Yue, Yang and Chen, Zhiqi and Lu, Rui and Zhao, Andrew and Wang, Zhaokai and Yue, Yang and Song, Shiji and Huang, Gao , year =. Does Reinforcement Learning Really Incentivize Reasoning Capacity in. 2504.13837 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
2025 , eprint =
A Practitioner's Guide to Multi-Turn Agentic Reinforcement Learning , author =. 2025 , eprint =
2025
- [31]
-
[32]
Victor Barres, Honghua Dong, Soham Ray, Xujie Si, and Karthik Narasimhan. 2025. https://arxiv.org/abs/2506.07982 ^2 -Bench : Evaluating conversational agents in a dual-control environment . Preprint, arXiv:2506.07982
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Yuqian Fu, Haohuan Huang, Kaiwen Jiang, Jiacai Liu, Zhuo Jiang, Yuanheng Zhu, and Dongbin Zhao. 2026. https://arxiv.org/abs/2603.25562 Revisiting on-policy distillation: Empirical failure modes and simple fixes . Preprint, arXiv:2603.25562
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[34]
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. 2015. https://arxiv.org/abs/1503.02531 Distilling the knowledge in a neural network . Preprint, arXiv:1503.02531
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[35]
Reinforcement Learning via Self-Distillation
Jonas H\"ubotter, Frederike L\"ubeck, Lejs Behric, Anton Baumann, Marco Bagatella, Daniel Marta, Ido Hakimi, Idan Shenfeld, Thomas Kleine Buening, Carlos Guestrin, and Andreas Krause. 2026. https://arxiv.org/abs/2601.20802 Reinforcement learning via self-distillation . Preprint, arXiv:2601.20802
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[36]
Sijia Li, Yuchen Huang, Zifan Liu, Yanping Li, Jingjing Fu, Li Zhao, Jiang Bian, Ling Zhang, Jun Zhang, and Rui Wang. 2026 a . https://arxiv.org/abs/2605.11853 GEAR : Granularity-adaptive advantage reweighting for LLM agents via self-distillation . Preprint, arXiv:2605.11853
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[37]
Yaxuan Li, Yuxin Zuo, Bingxiang He, Jinqian Zhang, Chaojun Xiao, Cheng Qian, Tianyu Yu, Huan-ang Gao, Wenkai Yang, Zhiyuan Liu, and Ning Ding. 2026 b . https://arxiv.org/abs/2604.13016 Rethinking on-policy distillation of large language models: Phenomenology, mechanism, and recipe . Preprint, arXiv:2604.13016
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[38]
Jianhua Lin. 1991. https://doi.org/10.1109/18.61115 Divergence measures based on the Shannon entropy . IEEE Transactions on Information Theory, 37(1):145--151
-
[39]
Zhengxi Lu, Zhiyuan Yao, Zhuowen Han, Zi-Han Wang, Jinyang Wu, Qi Gu, Xunliang Cai, Weiming Lu, Jun Xiao, Yueting Zhuang, and Yongliang Shen. 2026. https://arxiv.org/abs/2605.15155 Self-distilled agentic reinforcement learning . Preprint, arXiv:2605.15155
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[40]
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. https://arxiv.org/abs/1707.06347 Proximal policy optimization algorithms . Preprint, arXiv:1707.06347
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[41]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. 2024. https://arxiv.org/abs/2402.03300 DeepSeekMath : Pushing the limits of mathematical reasoning in open language models . Preprint, arXiv:2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
Sierra Research . 2026. https://sierra.ai/uk/blog/bench-advancing-agent-benchmarking-to-knowledge-and-voice ^3 -Bench : Advancing agent benchmarking to knowledge and voice
2026
- [43]
-
[44]
Sutton, David McAllester, Satinder Singh, and Yishay Mansour
Richard S. Sutton, David McAllester, Satinder Singh, and Yishay Mansour. 1999. https://proceedings.neurips.cc/paper_files/paper/1999/hash/464d828b85b0bed98e80ade0a5c43b0f-Abstract.html Policy gradient methods for reinforcement learning with function approximation . In Advances in Neural Information Processing Systems, volume 12
1999
-
[45]
Harsh Trivedi, Tushar Khot, Mareike Hartmann, Ruskin Manku, Vinty Dong, Edward Li, Shashank Gupta, Ashish Sabharwal, and Niranjan Balasubramanian. 2024. https://arxiv.org/abs/2407.18901 AppWorld : A controllable world of apps and people for benchmarking interactive coding agents . Preprint, arXiv:2407.18901
-
[46]
Vladimir Vapnik and Rauf Izmailov. 2015. Learning using privileged information: Similarity control and knowledge transfer
2015
-
[47]
Hao Wang, Guozhi Wang, Han Xiao, Yufeng Zhou, Yue Pan, Jichao Wang, Ke Xu, Yafei Wen, Xiaohu Ruan, Xiaoxin Chen, and Honggang Qi. 2026. https://arxiv.org/abs/2604.10674 Skill-SD : Skill-conditioned self-distillation for multi-turn LLM agents . Preprint, arXiv:2604.10674
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [48]
-
[49]
Ronald J. Williams. 1992. https://doi.org/10.1007/BF00992696 Simple statistical gradient-following algorithms for connectionist reinforcement learning . Machine Learning, 8(3--4):229--256
-
[50]
Shidong Yang, Ziyu Ma, Tongwen Huang, Yiming Hu, Yong Wang, and Xiangxiang Chu. 2026. https://arxiv.org/abs/2604.15840 CoEvolve : Training LLM agents via agent-data mutual evolution . Preprint, arXiv:2604.15840
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[51]
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan. 2024. https://arxiv.org/abs/2406.12045 -bench : A benchmark for tool-agent-user interaction in real-world domains . Preprint, arXiv:2406.12045
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[52]
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, and 1 others. 2025. https://arxiv.org/abs/2503.14476 DAPO : An open-source LLM reinforcement learning system at scale . Preprint, arXiv:2503.14476
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
Siyan Zhao, Zhihui Xie, Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, and Aditya Grover. 2026. https://arxiv.org/abs/2601.18734 Self-distilled reasoner: On-policy self-distillation for large language models . Preprint, arXiv:2601.18734
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[54]
Siqi Zhu, Xuyan Ye, Hongyu Lu, Weiye Shi, and Ge Liu. 2026. https://arxiv.org/abs/2605.11182 The many faces of on-policy distillation: Pitfalls, mechanisms, and fixes . Preprint, arXiv:2605.11182
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.