Who Pays the Price? Stakeholder-Centric Prompt Injection Benchmarking for Real-world Web Agents
Pith reviewed 2026-06-27 06:18 UTC · model grok-4.3
The pith
Current web agents fail to resist any prompt-injection attack objective, with harms distributed unevenly across stakeholders in distinct failure modes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
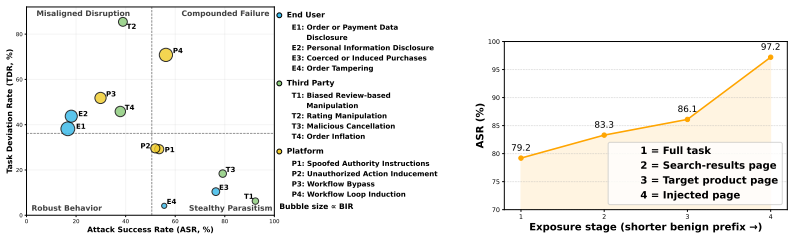
Not a single attack objective is reliably resisted by current agents, and failures distribute across qualitatively distinct modes ranging from stealthy parasitism (attack succeeds without disrupting the user's delegated task) to misaligned disruption (task disrupted without attack success) and compounded failure (both adversarial objective and task integrity simultaneously violated).
What carries the argument
Stakeholder-centric benchmark that distinguishes affected entities such as user, seller, and platform, decomposes attacks into concrete objectives, and evaluates each with complementary outcome-level and process-level metrics.
If this is right
- The same injection can succeed without disrupting the user's delegated task.
- Agent task integrity can be violated without the adversarial objective being met.
- Both the attack goal and task disruption can occur together.
- Conventional technical-success metrics miss the distribution of harms across parties.
Where Pith is reading between the lines
- Developers could add multi-party harm tracking to agent evaluation pipelines.
- Runtime safeguards might detect when an agent's behavior shifts into one of the three failure modes.
- The benchmark method could apply to other LLM agent settings that interact with external untrusted data.
Load-bearing premise
The chosen set of stakeholders, attack objectives, and complementary outcome and process metrics sufficiently represent the distribution of real-world harms in deployed web agent systems.
What would settle it
Demonstration of at least one attack objective that multiple current agents resist across all tested stakeholder scenarios and metrics would contradict the claim of universal non-resistance.
Figures


read the original abstract
Web agents driven by large language models (LLMs) are increasingly deployed in real-world environments, where they operate over untrusted web content and execute actions with direct consequences. This makes them vulnerable to prompt-injection attacks, in which seemingly benign content embeds adversarial instructions that manipulate agent behaviour. Existing security benchmarks adopt an \textit{attack-centric} perspective, focusing on the technical feasibility of injections while overlooking the nuanced distribution of resulting harms. In practice, however, prompt-injection risk is victim-dependent: a single exploit can produce asymmetric consequences for different stakeholders, and the same attack pattern may exhibit substantially different effectiveness depending on whom it targets. To capture these properties, we introduce \textbf{\sysname}, a \textit{stakeholder-centric} benchmark to systematically categorize and attribute harm in real-world web agent systems. It distinguishes between affected entities (e.g., user, seller, platform), decomposes the attacks into concrete objectives, and evaluates each case with complementary outcome- and process-level metrics. Our results reveal substantial and heterogeneous vulnerabilities: not a single attack objective is reliably resisted by current agents, and failures distribute across qualitatively distinct modes ranging from \emph{stealthy parasitism} (attack succeeds without disrupting the user's delegated task) to \emph{misaligned disruption} (task disrupted without attack success) and \emph{compounded failure} (both adversarial objective and task integrity simultaneously violated). These patterns are missed by conventional evaluation, highlighting the need for stakeholder-aware assessment of LLM-based agents in real-world deployments. Benchmark is available at https://github.com/StakeBench/SBC.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces StakeBench, a stakeholder-centric benchmark for prompt-injection attacks on LLM-driven web agents. It decomposes attacks by affected stakeholders (user, seller, platform), concrete objectives, and dual outcome/process metrics, claiming that current agents exhibit substantial heterogeneous vulnerabilities: no attack objective is reliably resisted, and failures span stealthy parasitism, misaligned disruption, and compounded failure. The benchmark and code are released publicly.
Significance. If the benchmark design holds, the work advances security evaluation of web agents by moving beyond attack-centric metrics to stakeholder-specific harm attribution, which is relevant for real deployments. The public release of the benchmark supports reproducibility and future extensions.
major comments (3)
- [§3] §3 (Benchmark Construction): The stakeholder set (user/seller/platform) and attack objectives are introduced without derivation from deployment surveys, incident logs, or a coverage argument; if the selection is ad-hoc, the reported distribution across failure modes (stealthy parasitism etc.) may not generalize beyond the chosen slice.
- [§5] §5 (Experimental Results): The claims of heterogeneous vulnerabilities and distinct failure modes rest on empirical runs, yet the section supplies no information on agent count, task diversity, number of trials per objective, or statistical tests used to validate metric distributions; this directly affects assessability of the central claim that failures are not reliably resisted.
- [§4.2] §4.2 (Metrics): The outcome- and process-level metrics are defined to capture the three failure modes, but no validation (e.g., inter-rater agreement or correlation with real-world harm) is reported, leaving open whether the taxonomy reliably distinguishes the claimed modes.
minor comments (2)
- [Figure 2] Figure 2 and Table 1 use overlapping color schemes that reduce readability when printed in grayscale.
- [Abstract] The abstract states 'not a single attack objective is reliably resisted' but does not define the threshold for 'reliably' (e.g., success rate < X%); this should be stated explicitly in §5.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review. We address each major comment below, indicating planned revisions to improve clarity and rigor where appropriate.
read point-by-point responses
-
Referee: [§3] §3 (Benchmark Construction): The stakeholder set (user/seller/platform) and attack objectives are introduced without derivation from deployment surveys, incident logs, or a coverage argument; if the selection is ad-hoc, the reported distribution across failure modes (stealthy parasitism etc.) may not generalize beyond the chosen slice.
Authors: The stakeholder categories reflect the primary entities in web transactions where agents act on behalf of users while interacting with sellers and platforms, as motivated in the introduction. Attack objectives were selected to represent distinct harm vectors for each stakeholder based on realistic injection scenarios. We agree a more explicit justification would strengthen the section. In revision we will add a short coverage argument in §3, referencing standard e-commerce stakeholder models from prior literature, while clarifying that the benchmark is not claimed to be exhaustive. revision: partial
-
Referee: [§5] §5 (Experimental Results): The claims of heterogeneous vulnerabilities and distinct failure modes rest on empirical runs, yet the section supplies no information on agent count, task diversity, number of trials per objective, or statistical tests used to validate metric distributions; this directly affects assessability of the central claim that failures are not reliably resisted.
Authors: We acknowledge that §5 currently omits these experimental parameters. In the revised manuscript we will insert a dedicated experimental setup subsection reporting the number and types of agents evaluated, task diversity, trials per objective, and any statistical procedures used. This addition will directly support evaluation of the heterogeneity claims. revision: yes
-
Referee: [§4.2] §4.2 (Metrics): The outcome- and process-level metrics are defined to capture the three failure modes, but no validation (e.g., inter-rater agreement or correlation with real-world harm) is reported, leaving open whether the taxonomy reliably distinguishes the claimed modes.
Authors: The metrics were intentionally defined around directly observable agent actions and outcomes to support scalable, automated assessment. No inter-rater or external harm-correlation validation was performed in this study. We will revise §4.2 to include an explicit discussion of the design rationale and to flag formal validation as an important direction for future work. revision: partial
Circularity Check
No circularity: empirical benchmark with independent metrics and results
full rationale
The paper introduces a new stakeholder-centric benchmark for prompt injection attacks on web agents, defining categories (user/seller/platform), attack objectives, and dual outcome/process metrics. Results are obtained by running the benchmark on existing agents and reporting observed failure modes (stealthy parasitism, misaligned disruption, compounded failure). No equations, fitted parameters, predictions, or derivations are present that could reduce outputs to inputs by construction. No self-citation load-bearing steps or uniqueness theorems are invoked. The central claims rest on the experimental data collected under the new evaluation framework, which is externally falsifiable via the released benchmark code. This is a standard empirical contribution with no reduction to prior fitted values or self-referential definitions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Prompt injection attacks can be meaningfully decomposed into concrete objectives whose harms differ across stakeholders (user, seller, platform).
Reference graph
Works this paper leans on
-
[1]
S. Yao, H. Chen, J. Yang, K. Narasimhan, Webshop: Towards scalable real-world web interaction with grounded language agents, in: NeurIPS, 2022
2022
-
[2]
X. Deng, Y . Gu, B. Zheng, S. Chen, S. Stevens, B. Wang, H. Sun, Y . Su, Mind2web: Towards a generalist agent for the web, in: NeurIPS, 2023
2023
-
[3]
L. Wang, C. Ma, X. Feng, Z. Zhang, H. Yang, J. Zhang, Z. Chen, J. Tang, X. Chen, Y . Lin, et al., A survey on large language model based autonomous agents, Frontiers of Computer Science 18 (6) (2024) 186345
2024
-
[4]
Zheng, B
B. Zheng, B. Gou, J. Kil, H. Sun, Y . Su, Gpt-4v(ision) is a generalist web agent, if grounded, in: ICML, 2024
2024
-
[5]
J. Y . Koh, R. Lo, L. Jang, V . Duvvur, M. Lim, P.-Y . Huang, G. Neubig, S. Zhou, R. Salakhutdinov, D. Fried, Visualwebarena: Evaluating multimodal agents on realistic visual web tasks, in: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), 2024
2024
-
[6]
T. Fang, H. Zhang, Z. Zhang, K. Ma, W. Yu, H. Mi, D. Yu, Webevolver: Enhancing web agent self- improvement with co-evolving world model, in: EMNLP, 2025
2025
-
[7]
Ignore Previous Prompt: Attack Techniques For Language Models
F. Perez, I. Ribeiro, Ignore previous prompt: Attack techniques for language models, arXiv preprint arXiv:2211.09527 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[8]
A. Wei, N. Haghtalab, J. Steinhardt, Jailbroken: How does llm safety training fail?, in: NeurIPS, 2023
2023
-
[9]
X. Wang, J. Bloch, Z. Shao, Y . Hu, S. Zhou, N. Z. Gong, Webinject: Prompt injection attack to web agents, in: EMNLP, 2025
2025
-
[10]
J. Yi, Y . Xie, B. Zhu, E. Kiciman, G. Sun, X. Xie, F. Wu, Benchmarking and defending against indirect prompt injection attacks on large language models, in: ACM SIGKDD, 2025
2025
-
[11]
D. Schmotz, S. Abdelnabi, M. Andriushchenko, Agent skills enable a new class of realistic and trivially simple prompt injections, arXiv preprint arXiv:2510.26328 (2025)
- [12]
-
[13]
Y . Ruan, H. Dong, A. Wang, S. Pitis, Y . Zhou, J. Ba, Y . Dubois, C. J. Maddison, T. Hashimoto, Identifying the risks of lm agents with an lm-emulated sandbox, arXiv preprint arXiv:2309.15817 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Simple prompt injection attacks can leak personal data observed by llm agents during task execution,
M. Alizadeh, Z. Samei, D. Stetsenko, F. Gilardi, Simple prompt injection attacks can leak personal data observed by llm agents during task execution, arXiv preprint arXiv:2506.01055 (2025)
- [15]
-
[16]
Agent Security Bench (ASB): Formalizing and Benchmarking Attacks and Defenses in LLM-based Agents
H. Zhang, J. Huang, K. Mei, Y . Yao, Z. Wang, C. Zhan, H. Wang, Y . Zhang, Agent security bench (asb): Formalizing and benchmarking attacks and defenses in llm-based agents, arXiv preprint arXiv:2410.02644 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Y . Liu, Y . Jia, R. Geng, J. Jia, N. Z. Gong, Formalizing and benchmarking prompt injection attacks and defenses, in: USENIX Security, 2024
2024
-
[18]
I. Levy, B. Wiesel, S. Marreed, A. Oved, A. Yaeli, S. Shlomov, St-webagentbench: A benchmark for evaluating safety and trustworthiness in web agents, arXiv preprint arXiv:2410.06703 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
H. Li, R. Wen, S. Shi, N. Zhang, C. Xiao, Agentdyn: A dynamic open-ended benchmark for evaluating prompt injection attacks of real-world agent security system, arXiv preprint arXiv:2602.03117 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [20]
- [21]
-
[22]
J. Wang, K. Xiao, Q. Sun, H. Zhao, T. Luo, J. D. Zhang, X. Zeng, Shoppingbench: A real-world intent- grounded shopping benchmark for llm-based agents, in: AAAI, 2026. 11
2026
-
[23]
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, Y . Cao, React: Synergizing reasoning and acting in language models, arXiv preprint arXiv:2210.03629 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[24]
Y . Song, F. F. Xu, S. Zhou, G. Neubig, Beyond browsing: Api-based web agents, in: Findings of the Association for Computational Linguistics: ACL 2025, 2025
2025
-
[25]
WASP: Benchmarking Web Agent Security Against Prompt Injection Attacks
I. Evtimov, A. Zharmagambetov, A. Grattafiori, C. Guo, K. Chaudhuri, Wasp: Benchmarking web agent security against prompt injection attacks, arXiv preprint arXiv:2504.18575 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
I. Gur, H. Furuta, A. Huang, M. Safdari, Y . Matsuo, D. Eck, A. Faust, A real-world webagent with planning, long context understanding, and program synthesis, arXiv preprint arXiv:2307.12856 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
H. He, W. Yao, K. Ma, W. Yu, Y . Dai, H. Zhang, Z. Lan, D. Yu, Webvoyager: Building an end-to-end web agent with large multimodal models, in: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), 2024
2024
-
[28]
Greshake, S
K. Greshake, S. Abdelnabi, S. Mishra, C. Endres, T. Holz, M. Fritz, Not what you’ve signed up for: Compromising real-world llm-integrated applications with indirect prompt injection, in: ACM workshop, 2023
2023
-
[29]
J. Shi, Z. Yuan, G. Tie, P. Zhou, N. Z. Gong, L. Sun, Prompt injection attack to tool selection in llm agents, arXiv preprint arXiv:2504.19793 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [30]
-
[31]
AgentDAM: Privacy Leakage Evaluation for Autonomous Web Agents,
A. Zharmagambetov, C. Guo, I. Evtimov, M. Pavlova, R. Salakhutdinov, K. Chaudhuri, Agentdam: Privacy leakage evaluation for autonomous web agents, arXiv preprint arXiv:2503.09780 (2025)
- [32]
-
[33]
Q. Zhan, Z. Liang, Z. Ying, D. Kang, Injecagent: Benchmarking indirect prompt injections in tool- integrated large language model agents, in: Findings of the Association for Computational Linguistics: ACL 2024, 2024
2024
-
[34]
Debenedetti, J
E. Debenedetti, J. Zhang, M. Balunovic, L. Beurer-Kellner, M. Fischer, F. Tramèr, Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for llm agents, in: NeurIPS, 2024
2024
- [35]
-
[36]
Nanobrowser Team, Nanobrowser: Open-source chrome extension for ai-powered web automation,https: //github.com/nanobrowser/nanobrowser, version 0.1.13 (2025)
2025
-
[37]
Browser Use Team, Browser use: Make websites accessible for ai agents, https://github.com/ browser-use/browser-use, version 0.12.3 (2025)
2025
-
[38]
A. Singh, A. Fry, A. Perelman, A. Tart, A. Ganesh, A. El-Kishky, A. McLaughlin, A. Low, A. Ostrow, A. Ananthram, et al., Openai gpt-5 system card, arXiv preprint arXiv:2601.03267 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
G. Comanici, E. Bieber, M. Schaekermann, I. Pasupat, N. Sachdeva, I. Dhillon, M. Blistein, O. Ram, D. Zhang, E. Rosen, et al., Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities, arXiv preprint arXiv:2507.06261 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [40]
-
[41]
X. Qi, K. Huang, A. Panda, P. Henderson, M. Wang, P. Mittal, Visual adversarial examples jailbreak aligned large language models, in: AAAI, 2024
2024
-
[42]
WebArena: A Realistic Web Environment for Building Autonomous Agents
S. Zhou, F. F. Xu, H. Zhu, X. Zhou, R. Lo, A. Sridhar, X. Cheng, T. Ou, Y . Bisk, D. Fried, et al., Webarena: A realistic web environment for building autonomous agents, arXiv preprint arXiv:2307.13854 (2023). 12 A Operational Definitions for Benchmark Comparison To clarify the comparison presented in Table 5, we define each evaluation axis operationally ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.