KITE: Decoupling Kinematics and Interaction for Zero-Shot Cross-Embodiment Manipulation
Pith reviewed 2026-06-26 11:54 UTC · model grok-4.3
The pith
KITE decouples task reasoning from motor control via contact-based latent intents to enable zero-shot policy transfer across robot embodiments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
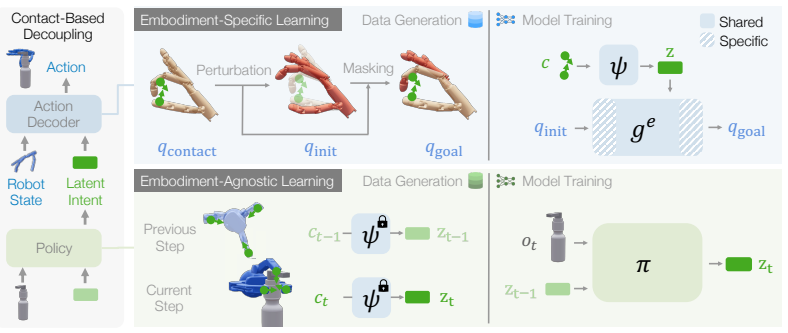
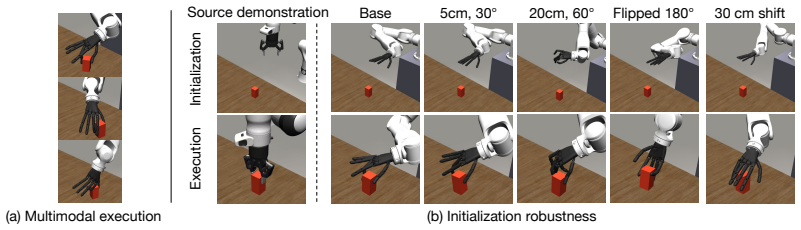
KITE decouples manipulation into an embodiment-agnostic task policy that predicts latent intents from source demonstrations and embodiment-specific action decoders conditioned on those intents and learned from kinematic models, allowing zero-shot transfer to structurally different target embodiments without additional demonstrations.
What carries the argument
The learned latent representation of interaction intent based on contact patterns, which bridges the shared task policy to each embodiment's action decoder.
If this is right
- A single task policy trained on source embodiments applies directly to new ones.
- Adapting to a new embodiment requires only its kinematic model, with no need for new task demonstrations.
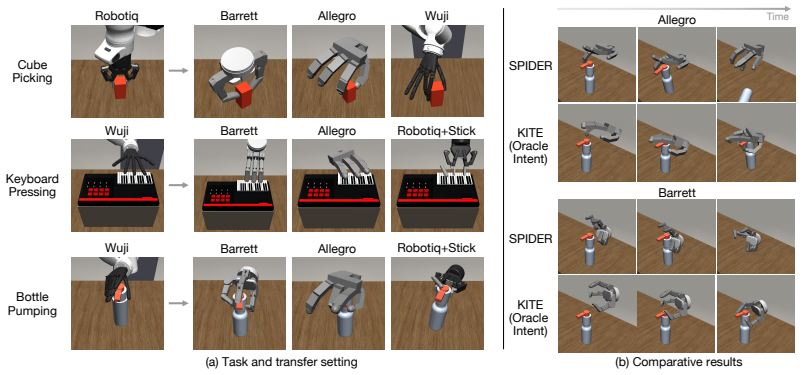
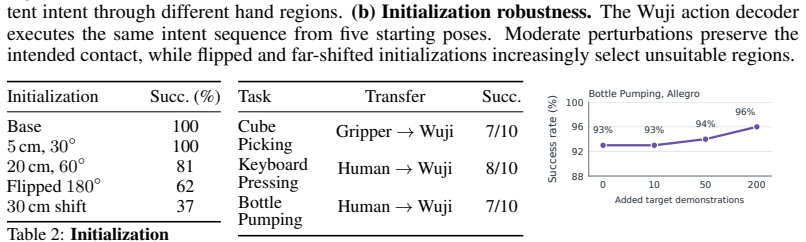
- Transfer succeeds across parallel grippers, dexterous hands, and composite embodiments where prior methods fail.
- The scope of reusable task policies expands without retraining the core reasoning component.
Where Pith is reading between the lines
- The same split could extend to domains with varying hardware, such as transferring locomotion policies between different legged robots.
- Aggregating demonstrations from multiple source embodiments might strengthen the latent intent predictor without extra target data.
- Limits could be tested by attempting transfer to embodiments with very different contact physics, such as soft or wheeled systems.
Load-bearing premise
That contact-pattern-based latent intents alone are enough to connect a task policy to any new embodiment's action decoder without target-embodiment demonstrations.
What would settle it
Training an action decoder on a target embodiment's kinematics alone and finding that it cannot produce successful task actions even when supplied with accurate latent intents from the source policy.
Figures

read the original abstract
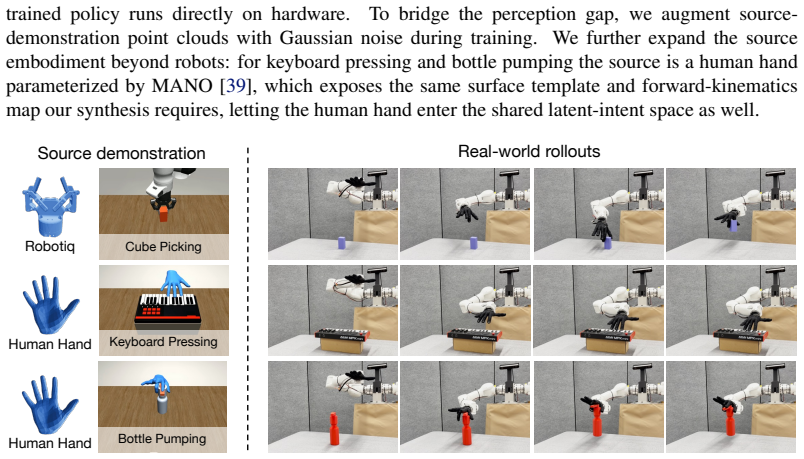
Generalizing manipulation policies across robot embodiments remains difficult because standard policies entangle task reasoning with embodiment-specific motor control. We study zero-shot cross-embodiment manipulation, where a policy trained on source embodiments must be deployed on a structurally different target embodiment without additional task demonstrations. We introduce Kinematic Interaction Transfer across Embodiments (KITE), which decouples manipulation into embodiment-agnostic task reasoning and embodiment-specific motor control, connected through a learned latent representation of interaction intent based on contact patterns. Task reasoning is performed by a shared policy that predicts latent intents from source demonstrations, while motor control is performed by an intent-conditioned action decoder learned from each embodiment's kinematic model. With KITE, adaptation to a new embodiment requires only training a new action decoder using its kinematic model, without recollecting demonstration data. We evaluate KITE on three manipulation tasks spanning transfer between parallel grippers, dexterous hands, and composite embodiments. KITE consistently achieves zero-shot transfer to structurally different target embodiments, outperforming state-of-the-art baselines in transfer success and task-embodiment scope.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces KITE, a method for zero-shot cross-embodiment manipulation that decouples embodiment-agnostic task reasoning from embodiment-specific motor control using a learned latent representation of interaction intent based on contact patterns. A shared policy predicts these intents from source demonstrations, and per-embodiment action decoders are trained using only the kinematic model of the target embodiment, allowing adaptation without recollecting demonstration data. The approach is evaluated on three manipulation tasks involving transfers between parallel grippers, dexterous hands, and composite embodiments, claiming consistent outperformance over state-of-the-art baselines in zero-shot transfer success.
Significance. If the central claims hold, KITE would represent a meaningful advance in robotics by enabling efficient transfer of manipulation policies across structurally different robot embodiments without additional task-specific data collection. This could broaden the practical deployment of learned policies in diverse hardware settings.
major comments (2)
- [Abstract] The central claim that the action decoder can be trained solely from the target embodiment's kinematic model (without task demonstrations) while correctly aligning to the latent intent space relies on the assumption that contact-pattern latents are sufficiently embodiment-invariant; however, the abstract provides no mechanism or evidence for how this invariance is achieved across differing contact geometries such as binary gripper contacts versus multi-fingered hand contacts.
- [Abstract] No equations, training procedure details, or quantitative results are supplied in the abstract, preventing assessment of whether the method avoids circularity in defining the latent space or decoder mapping.
minor comments (1)
- The abstract could benefit from a brief mention of the specific tasks or metrics used in evaluation to better contextualize the claims.
Simulated Author's Rebuttal
We thank the referee for their detailed review and constructive comments on the abstract of our manuscript. We address each point below.
read point-by-point responses
-
Referee: [Abstract] The central claim that the action decoder can be trained solely from the target embodiment's kinematic model (without task demonstrations) while correctly aligning to the latent intent space relies on the assumption that contact-pattern latents are sufficiently embodiment-invariant; however, the abstract provides no mechanism or evidence for how this invariance is achieved across differing contact geometries such as binary gripper contacts versus multi-fingered hand contacts.
Authors: We agree that the abstract, as a concise summary, does not detail the mechanism for embodiment invariance. The full manuscript (Section 3) explains that the latent space is learned from contact patterns in source demonstrations to capture task-level interaction intents (e.g., relative contact configurations with objects) rather than embodiment-specific geometries. This enables the intent-conditioned decoder to be trained independently using only the target's kinematic model. Experimental evidence of successful zero-shot transfers (e.g., gripper to dexterous hand) is in Section 5. We will revise the abstract to briefly note that invariance arises from contact-pattern-based latents. revision: yes
-
Referee: [Abstract] No equations, training procedure details, or quantitative results are supplied in the abstract, preventing assessment of whether the method avoids circularity in defining the latent space or decoder mapping.
Authors: Abstracts are subject to strict length constraints and standardly omit equations, detailed procedures, and quantitative results to focus on contributions. The manuscript avoids circularity by training the shared intent predictor on source demonstrations (Section 3.2) and per-embodiment decoders separately on kinematic models (Section 3.3), with full details and results in Sections 3-5. This follows conventional paper structure and requires no change. revision: no
Circularity Check
No significant circularity; derivation self-contained with no visible reductions
full rationale
The provided abstract and description outline a decoupling approach using a shared policy for latent intents from source data and per-embodiment decoders from kinematics, but contain no equations, training procedures, or derivation steps. No self-definitional mappings, fitted inputs renamed as predictions, or self-citation chains are present or quotable. The method's validity rests on empirical transfer results rather than any closed mathematical loop, making it self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Open X-Embodiment Collaboration. Open X-embodiment: Robotic learning datasets and RT- X models.arXiv preprint arXiv:2310.08864, 2023. URLhttps://arxiv.org/abs/2310. 08864
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Ghosh, H
Octo Model Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, T. Kreiman, C. Xu, J. Luo, Y . L. Tan, L. Y . Chen, P. Sanketi, Q. Vuong, T. Xiao, D. Sadigh, C. Finn, and S. Levine. Octo: An open-source generalist robot policy. InProceedings of Robotics: Science and Systems, 2024
2024
- [3]
-
[4]
S. Liu, L. Wu, B. Li, H. Tan, H. Chen, Z. Wang, K. Xu, H. Su, and J. Zhu. RDT-1B: A diffusion foundation model for bimanual manipulation.arXiv preprint arXiv:2410.07864, 2024. URL https://arxiv.org/abs/2410.07864
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Devin, A
C. Devin, A. Gupta, T. Darrell, P. Abbeel, and S. Levine. Learning modular neural network policies for multi-task and multi-robot transfer. In2017 IEEE International Conference on Robotics and Automation (ICRA), pages 2169–2176. IEEE, 2017
2017
-
[6]
Huang, I
W. Huang, I. Mordatch, and D. Pathak. One policy to control them all: Shared modular policies for agent-agnostic control. InProceedings of the 37th International Conference on Machine Learning, volume 119 ofProceedings of Machine Learning Research, pages 4455–
-
[7]
Sferrazza, D.-M
C. Sferrazza, D.-M. Huang, F. Liu, J. Lee, and P. Abbeel. Body transformer: Leveraging robot embodiment for policy learning. InProceedings of the 8th Conference on Robot Learning, volume 270 ofProceedings of Machine Learning Research, pages 3407–3424. PMLR, 2025
2025
-
[8]
Patel and S
A. Patel and S. Song. GET-Zero: Graph embodiment transformer for zero-shot embodiment generalization. In2025 IEEE International Conference on Robotics and Automation (ICRA), 2025
2025
-
[9]
RT-1: Robotics Transformer for Real-World Control at Scale
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Haus- man, A. Herzog, J. Hsu, et al. RT-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022. URLhttps://arxiv.org/abs/2212.06817
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[10]
Brohan, N
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, X. Chen, K. Choromanski, T. Ding, D. Driess, A. Dubey, C. Finn, et al. RT-2: Vision-language-action models transfer web knowledge to robotic control. InProceedings of the 7th Conference on Robot Learning, 2023
2023
-
[11]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Fos- ter, G. Lam, P. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn. OpenVLA: An open-source vision-language-action model. InProceed- ings of the 8th Conference on Robot Learning (CoRL), 2024. URLhttps://arxiv.org/ a...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
URLhttps://arxiv.org/abs/2410.24164
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
J. Wen, Y . Zhu, J. Li, Z. Tang, C. Shen, and F. Feng. DexVLA: Vision-language model with plug-in diffusion expert for general robot control. InProceedings of the 9th Conference on Robot Learning (CoRL), 2025. URLhttps://arxiv.org/abs/2502.05855
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Z. Wei, Y . Yao, and M. Ding. One hand to rule them all: Canonical representations for unified dexterous manipulation.arXiv preprint arXiv:2602.16712, 2026. URLhttps://arxiv. org/abs/2602.16712
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [16]
- [17]
- [18]
-
[19]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10–11):1684–1704, 2025. doi:10.1177/02783649241273668
-
[20]
Y . Ze, G. Zhang, K. Zhang, C. Hu, M. Wang, and H. Xu. 3D diffusion policy: Generalizable visuomotor policy learning via simple 3D representations. InProceedings of Robotics: Science and Systems (RSS), 2024. URLhttps://arxiv.org/abs/2403.03954
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Y . Ze, Z. Chen, W. Wang, T. Chen, X. He, Y . Yuan, X. B. Peng, and J. Wu. Generalizable hu- manoid manipulation with 3d diffusion policies. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 2873–2880. IEEE, 2025
2025
-
[22]
P. Li, T. Liu, Y . Li, Y . Geng, Y . Zhu, Y . Yang, and S. Huang. GenDexGrasp: Generalizable dex- terous grasping. In2023 IEEE International Conference on Robotics and Automation (ICRA), pages 8068–8074. IEEE, 2023
2023
-
[23]
S. Liu, Y . Zhou, J. Yang, S. Gupta, and S. Wang. Contactgen: Generative contact modeling for grasp generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 20609–20620, 2023
2023
- [24]
- [25]
- [26]
-
[27]
L. Shao, F. Ferreira, M. Jorda, V . Nambiar, J. Luo, E. Solowjow, J. A. Ojea, O. Khatib, and J. Bohg. UniGrasp: Learning a unified model to grasp with multifingered robotic hands.IEEE Robotics and Automation Letters, 5(2):2286–2293, 2020
2020
-
[28]
Attarian, M
M. Attarian, M. A. Asif, J. Liu, R. Hari, A. Garg, I. Gilitschenski, and J. Tompson. Ge- ometry matching for multi-embodiment grasping. InProceedings of the 7th Conference on Robot Learning, volume 229 ofProceedings of Machine Learning Research, pages 1242–
-
[29]
Z. Xu, C. Gao, Z. Liu, G. Yang, C. Tie, H. Zheng, H. Zhou, W. Peng, D. Wang, T. Hu, et al. Manifoundation model for general-purpose robotic manipulation of contact synthesis with arbitrary objects and robots. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 10905–10912. IEEE, 2024
2024
-
[30]
Y . Xu, W. Wan, J. Zhang, H. Liu, Z. Shan, H. Shen, R. Wang, H. Geng, Y . Weng, J. Chen, T. Liu, L. Yi, and H. Wang. UniDexGrasp: Universal robotic dexterous grasping via learning diverse proposal generation and goal-conditioned policy. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 4737–4746, 2023
2023
- [31]
-
[32]
A. Handa, K. Van Wyk, W. Yang, J. Liang, Y .-W. Chao, Q. Wan, S. Birchfield, N. D. Ratliff, and D. Fox. DexPilot: Vision-based teleoperation of dexterous robotic hand-arm system. In 2020 IEEE International Conference on Robotics and Automation (ICRA), pages 9164–9170. IEEE, 2020. doi:10.1109/ICRA40945.2020.9197124
-
[33]
Y . Qin, W. Yang, B. Huang, K. Van Wyk, H. Su, X. Wang, Y .-W. Chao, and D. Fox. AnyTeleop: A general vision-based dexterous robot arm-hand teleoperation system. InProceedings of Robotics: Science and Systems, Daegu, Republic of Korea, July 2023. doi:10.15607/RSS. 2023.XIX.015
- [34]
-
[35]
C. Chi, Z. Xu, C. Pan, E. Cousineau, B. Burchfiel, S. Feng, R. Tedrake, and S. Song. Universal manipulation interface: In-the-wild robot teaching without in-the-wild robots. InProceedings of Robotics: Science and Systems (RSS), 2024
2024
- [36]
-
[37]
Bharadhwaj, R
H. Bharadhwaj, R. Mottaghi, A. Gupta, and S. Tulsiani. Track2act: Predicting point tracks from internet videos enables generalizable robot manipulation. InEuropean Conference on Computer Vision, pages 306–324. Springer, 2024
2024
- [38]
-
[39]
S. Haldar and L. Pinto. Point policy: Unifying observations and actions with key points for robot manipulation.arXiv preprint arXiv:2502.20391, 2025. URLhttps://arxiv.org/ abs/2502.20391
-
[40]
Romero, D
J. Romero, D. Tzionas, and M. J. Black. Embodied hands: Modeling and capturing hands and bodies together.ACM Transactions on Graphics, (Proc. SIGGRAPH Asia), 36(6), Nov. 2017. 12
2017
-
[41]
Bloom, J
S. Bloom, J. Brumberg, I. Fisk, R. Harrison, R. Hull, M. Ramasubramanian, K. Van Vliet, and J. Wing. Empire ai: A new model for provisioning ai and hpc for academic research in the public good. InPractice and Experience in Advanced Research Computing 2025: The Power of Collaboration, pages 1–4. 2025. 13 Appendix In the appendix, we begin with the full arc...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.