FORCE: Efficient VLA Reinforcement Fine-Tuning via Value-Calibrated Warm-up and Self-Distillation
Pith reviewed 2026-06-25 19:26 UTC · model grok-4.3
The pith
FORCE stabilizes reinforcement learning fine-tuning of vision-language-action models by calibrating the Q-function before online updates to avoid early unlearning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
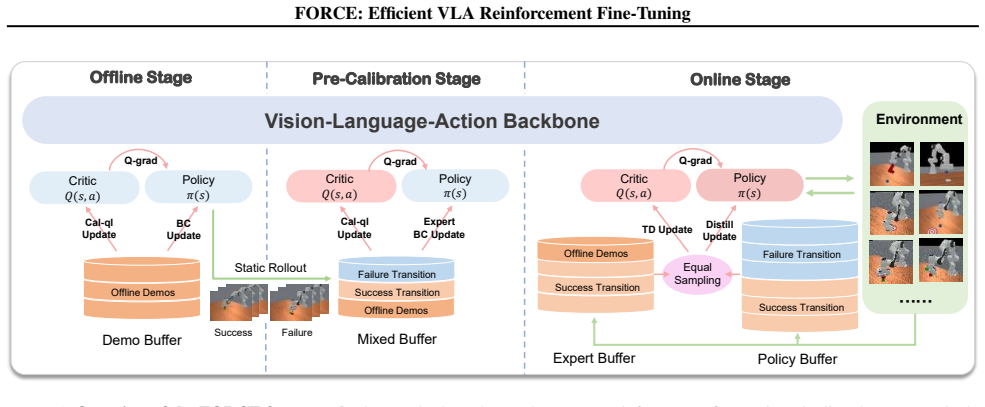
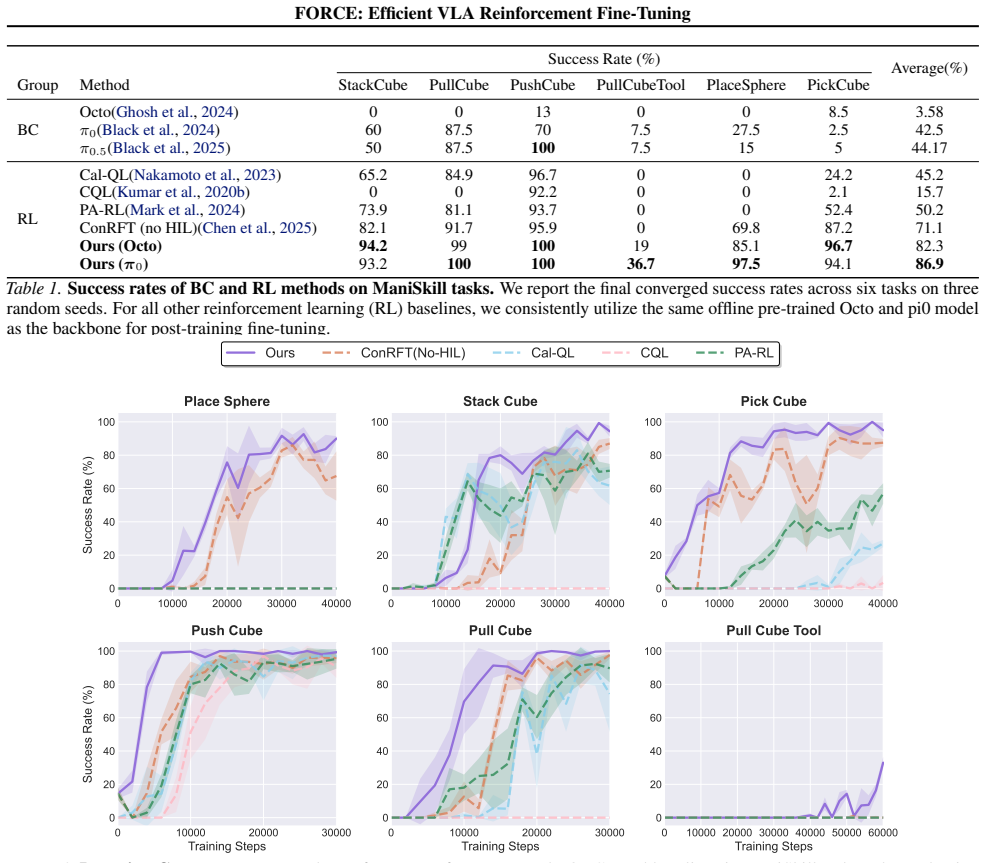
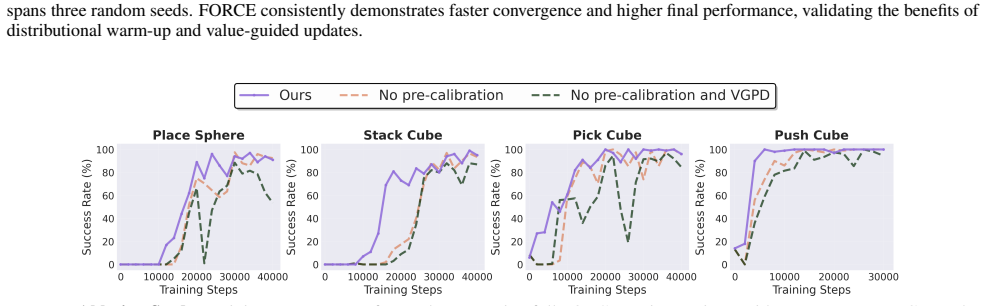
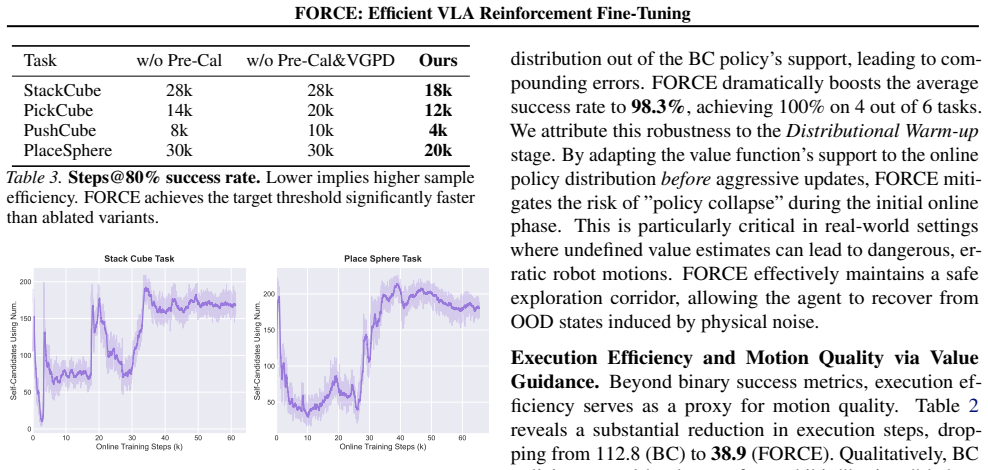
FORCE is a three-stage framework that first runs a Value-Calibrated Warm-Up with on-policy rollouts to reduce Q-function distributional shift, then uses the resulting Q-function as a filter on both policy-generated and expert actions during the online stage, thereby enabling stable RL fine-tuning of VLA models that delivers a 79 percent absolute success-rate improvement, outperforms prior RL methods by 10 percent, shortens training by 32.5 percent, and removes the need for human intervention.
What carries the argument
Value-Calibrated Warm-Up phase that uses on-policy rollouts to align the Q-function distribution so it can later filter high-value actions for policy updates.
Load-bearing premise
On-policy rollouts during the warm-up phase can sufficiently correct the Q-function distributional shift to stop catastrophic unlearning when RL fine-tuning of VLA models begins.
What would settle it
A controlled run that applies the online RL stage immediately after standard pre-training and still records a sharp early drop in success rate would show that the warm-up calibration step is not sufficient to stabilize the process.
Figures




read the original abstract
Vision-Language-Action (VLA) models are often constrained by the imitation ceiling imposed by sub-optimal data. While Reinforcement Learning (RL) fine-tuning can surpass this limit, it is notoriously sample inefficient. This challenge arises from two core issues: (1) catastrophic initial unlearning due to an unstable Q-function and (2) inefficient policy updates caused by low-quality exploration data, often forcing a reliance on costly human interventions. We introduce FORCE, a 3-stage framework that stabilizes fine-tuning by tackling both issues. FORCE first incorporates a Value-Calibrated Warm-Up phase, utilizing on-policy rollouts to mitigate the distributional shift of the Q-function. Subsequently, during the online stage, this calibrated Q-function acts as a filter for both the policy's own action proposals and expert data, ensuring only high-value actions are used for the policy update. We evaluate FORCE on various simulation and real-world tasks, and the result shows that FORCE achieves a 79% absolute improvement in success rates and outperform prior RL methods by 10%, while accelerating training by 32.5%. Critically, it mitigates the common success rate drop and achieves this robust performance without human intervention, marking a significant step towards deploying capable and autonomous robotic agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces FORCE, a three-stage framework for RL fine-tuning of Vision-Language-Action (VLA) models. Stage 1 performs Value-Calibrated Warm-Up via on-policy rollouts to mitigate Q-function distributional shift and prevent catastrophic initial unlearning. Stage 2 uses the calibrated Q as a filter on both policy proposals and expert data to retain only high-value actions. Stage 3 applies self-distillation. The authors claim this yields a 79% absolute success-rate improvement, 10% gains over prior RL methods, 32.5% faster training, elimination of the typical success-rate drop, and fully autonomous operation without human intervention on simulation and real-world tasks.
Significance. If the reported gains are substantiated and the Value-Calibrated Warm-Up is shown to be the causal factor via isolated verification, the work would constitute a meaningful advance in sample-efficient RL for VLAs by reducing reliance on human interventions and addressing the imitation ceiling.
major comments (2)
- [Abstract and Method section] Abstract and Method section: The central claim that the on-policy Value-Calibrated Warm-Up mitigates Q-function distributional shift enough to avoid catastrophic unlearning is load-bearing for the 79% absolute improvement and 32.5% acceleration. No supporting quantitative evidence is supplied (Q-value variance plots, Wasserstein distance between pre- and post-warm-up Q distributions, or an ablation that removes only the calibration step while retaining filtering and self-distillation). Without such isolation it remains possible that gains arise from the Q-filter, self-distillation, or task selection rather than the claimed mechanism.
- [Experiments section] Experiments section: Performance numbers (79% absolute improvement, 10% outperformance, 32.5% acceleration) are stated without any description of baselines, number of runs, statistical significance tests, task specifications, or reward definitions. This absence prevents verification that the data support the mechanism claims.
minor comments (1)
- [Abstract] The abstract refers to 'various simulation and real-world tasks' without naming them or providing any equations that define the value calibration or filtering procedure.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing the need for isolated evidence on the Value-Calibrated Warm-Up mechanism and fuller experimental details. We address each major comment below and will revise the manuscript to strengthen these aspects.
read point-by-point responses
-
Referee: [Abstract and Method section] The central claim that the on-policy Value-Calibrated Warm-Up mitigates Q-function distributional shift enough to avoid catastrophic unlearning is load-bearing for the 79% absolute improvement and 32.5% acceleration. No supporting quantitative evidence is supplied (Q-value variance plots, Wasserstein distance between pre- and post-warm-up Q distributions, or an ablation that removes only the calibration step while retaining filtering and self-distillation). Without such isolation it remains possible that gains arise from the Q-filter, self-distillation, or task selection rather than the claimed mechanism.
Authors: We agree that the manuscript currently lacks quantitative isolation of the warm-up's causal contribution. In the revision we will add: (1) an ablation that disables only the Value-Calibrated Warm-Up while retaining the Q-filter and self-distillation stages, (2) Q-value variance plots before and after warm-up, and (3) distributional shift metrics (Wasserstein distance) between pre- and post-warm-up Q distributions. These additions will directly test whether the warm-up step is responsible for avoiding the initial success-rate drop. revision: yes
-
Referee: [Experiments section] Performance numbers (79% absolute improvement, 10% outperformance, 32.5% acceleration) are stated without any description of baselines, number of runs, statistical significance tests, task specifications, or reward definitions. This absence prevents verification that the data support the mechanism claims.
Authors: We acknowledge the current Experiments section is insufficiently detailed for independent verification. The revised version will expand this section to include: explicit descriptions and citations for all baselines, the number of independent runs with random seeds, statistical significance tests (e.g., paired t-tests across seeds), complete task specifications (environments, success criteria, episode lengths), and the precise reward function definitions used in both simulation and real-world settings. revision: yes
Circularity Check
No circularity; empirical claims rest on experimental outcomes independent of self-referential definitions or fits.
full rationale
The manuscript describes a 3-stage pipeline (Value-Calibrated Warm-Up via on-policy rollouts, Q-filtering of actions, self-distillation) and reports measured success-rate gains, training acceleration, and absence of human intervention. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. Performance numbers are presented as external validation results on simulation and real-world tasks rather than quantities forced by the method's own definitions or prior author work. The load-bearing assumption about Q-function calibration is an empirical hypothesis, not a definitional reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Kim, Moo Jin and Pertsch, Karl and Karamcheti, Siddharth and Xiao, Ted and Balakrishna, Ashwin and Nair, Suraj and Rafailov, Rafael and Foster, Ethan and Lam, Grace and Sanketi, Pannag and Vuong, Quan and Kollar, Thomas and Burchfiel, Benjamin and Tedrake, Russ and Sadigh, Dorsa and Levine, Sergey and Liang, Percy and Finn, Chelsea , year = 2024, journal =
2024
-
[2]
Black, Kevin and Brown, Noah and Darpinian, James and Dhabalia, Karan and Driess, Danny and Esmail, Adnan and Equi, Michael and Finn, Chelsea and Fusai, Niccolo and Galliker, Manuel Y and Ghosh, Dibya and Groom, Lachy and Hausman, Karol and Ichter, Brian and Jakubczak, Szymon and Jones, Tim and Ke, Liyiming and LeBlanc, Devin and Levine, Sergey and
-
[3]
Black, Kevin and Brown, Noah and Driess, Danny and Esmail, Adnan and Equi, Michael and Finn, Chelsea and Fusai, Niccolo and Groom, Lachy and Hausman, Karol and Ichter, Brian and Jakubczak, Szymon and Jones, Tim and Ke, Liyiming and Levine, Sergey and
-
[4]
Policy agnostic rl: Offline rl and online rl fine-tuning of any class and backbone , author =
-
[5]
Precise and dexterous robotic manipulation via human-in-the-loop reinforcement learning , author =. Sci. Robotics , volume = 10, number = 105, doi =
-
[6]
RL-100: Performant Robotic Manipulation with Real-World Reinforcement Learning , author =
-
[7]
Steering your generalists: Improving robotic foundation models via value guidance , author =
-
[8]
Conrft: A reinforced fine-tuning method for vla models via consistency policy , author =
-
[9]
Tgrpo: Fine-tuning vision-language-action model via trajectory-wise group relative policy optimization , author =
-
[10]
Steering Your Diffusion Policy with Latent Space Reinforcement Learning
Steering Your Diffusion Policy with Latent Space Reinforcement Learning , author =. CoRR , volume =. doi:10.48550/ARXIV.2506.15799 , url =. 2506.15799 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.15799
-
[11]
RoboMonkey: Scaling test-time sampling and verification for vision- language-action models
RoboMonkey: Scaling Test-Time Sampling and Verification for Vision-Language-Action Models , author =. CoRR , volume =. doi:10.48550/ARXIV.2506.17811 , url =. 2506.17811 , timestamp =
-
[12]
Hume: Introducing System-2 Thinking in Visual-Language-Action Model , author =. CoRR , volume =. doi:10.48550/ARXIV.2505.21432 , url =. 2505.21432 , timestamp =
-
[13]
Reinforcement Learning with Action Chunking
Reinforcement Learning with Action Chunking , author =. CoRR , volume =. doi:10.48550/ARXIV.2507.07969 , url =. 2507.07969 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.07969
-
[14]
SimpleVLA-RL: Scaling VLA Training via Reinforcement Learning
Haozhan Li and Yuxin Zuo and Jiale Yu and Yuhao Zhang and Zhaohui Yang and Kaiyan Zhang and Xuekai Zhu and Yuchen Zhang and Tianxing Chen and Ganqu Cui and Dehui Wang and Dingxiang Luo and Yuchen Fan and Youbang Sun and Jia Zeng and Jiangmiao Pang and Shanghang Zhang and Yu Wang and Yao Mu and Bowen Zhou and Ning Ding , year = 2025, journal =. SimpleVLA-R...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2509.09674 2025
-
[15]
RLinf: Flexible and Efficient Large-scale Reinforcement Learning via Macro-to-Micro Flow Transformation , author =. CoRR , volume =. doi:10.48550/ARXIV.2509.15965 , url =. 2509.15965 , timestamp =
-
[16]
Lumos: Language-conditioned imitation learning with world models
Improving Vision-Language-Action Model with Online Reinforcement Learning , author =. doi:10.1109/ICRA55743.2025.11127299 , url =
-
[17]
Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics,
A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning , author =. Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics,
-
[18]
Proceedings of the Thirty-Second
Deep Q-learning From Demonstrations , author =. Proceedings of the Thirty-Second. doi:10.1609/AAAI.V32I1.11757 , url =
-
[19]
Tran and Radu Soricut and Anikait Singh and Jaspiar Singh and Pierre Sermanet and Pannag R
Brianna Zitkovich and Tianhe Yu and Sichun Xu and Peng Xu and Ted Xiao and Fei Xia and Jialin Wu and Paul Wohlhart and Stefan Welker and Ayzaan Wahid and Quan Vuong and Vincent Vanhoucke and Huong T. Tran and Radu Soricut and Anikait Singh and Jaspiar Singh and Pierre Sermanet and Pannag R. Sanketi and Grecia Salazar and Michael S. Ryoo and Krista Reymann...
2023
-
[20]
Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, December 6-14, 2021, virtual , pages =
Decision Transformer: Reinforcement Learning via Sequence Modeling , author =. Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, December 6-14, 2021, virtual , pages =
2021
-
[21]
Proceedings of the 35th International Conference on Machine Learning (ICML) , publisher =
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor , author =. Proceedings of the 35th International Conference on Machine Learning (ICML) , publisher =
-
[22]
Proceedings of the 35th International Conference on Machine Learning (ICML) , publisher =
Addressing Function Approximation Error in Actor-Critic Methods , author =. Proceedings of the 35th International Conference on Machine Learning (ICML) , publisher =
-
[23]
AWAC: Accelerating Online Reinforcement Learning with Offline Datasets , author =
-
[24]
Robotics: Science and Systems XX, Delft, The Netherlands, July 15-19, 2024 , doi =
Octo: An Open-Source Generalist Robot Policy , author =. Robotics: Science and Systems XX, Delft, The Netherlands, July 15-19, 2024 , doi =
2024
-
[25]
Proceedings of the 35th International Conference on Machine Learning (ICML) , pages=
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor , author=. Proceedings of the 35th International Conference on Machine Learning (ICML) , pages=. 2018 , editor=
2018
-
[26]
Proceedings of the 35th International Conference on Machine Learning (ICML) , pages=
Addressing Function Approximation Error in Actor-Critic Methods , author=. Proceedings of the 35th International Conference on Machine Learning (ICML) , pages=. 2018 , editor=
2018
-
[27]
International Conference on Learning Representations (ICLR) , year=
AWAC: Accelerating Online Reinforcement Learning with Offline Datasets , author=. International Conference on Learning Representations (ICLR) , year=
-
[28]
arXiv preprint arXiv:1707.08817 , year=
Leveraging Demonstrations for Deep Reinforcement Learning on Robotics Problems with Sparse Rewards , author=. arXiv preprint arXiv:1707.08817 , year=
-
[29]
Kalashnikov, Dmitriy and Irpan, Alex and Pastor, Peter and Ibarz, Julian and Herzog, Alexander and Jang, Eric and Quillen, Deirdre and Holly, Ethan and Kalakrishnan, Mrinal and Vanhoucke, Vincent and others , journal=
-
[30]
2022 , volume=
Lu, Yao and Hausman, Karol and Chebotar, Yevgen and Yan, Mengyuan and Jang, Eric and Herzog, Alexander and Xiao, Ted and Irpan, Alex and Khansari, Mohi and Kalashnikov, Dmitry and Levine, Sergey , booktitle=. 2022 , volume=
2022
-
[31]
International Conference on Learning Representations (ICLR) , year=
Offline Reinforcement Learning with Implicit Q-Learning , author=. International Conference on Learning Representations (ICLR) , year=
-
[32]
Conservative
Kumar, Aviral and Zhou, Aurick and Tucker, George and Levine, Sergey , booktitle=. Conservative
-
[33]
The Tenth International Conference on Learning Representations,
Offline Reinforcement Learning with Implicit Q-Learning , author =. The Tenth International Conference on Learning Representations,
-
[34]
2025 IEEE International Conference on Robotics and Automation (ICRA) , pages=
Flare: Achieving masterful and adaptive robot policies with large-scale reinforcement learning fine-tuning , author=. 2025 IEEE International Conference on Robotics and Automation (ICRA) , pages=. 2025 , organization=
2025
-
[35]
2019 International Conference on Robotics and Automation (ICRA) , pages=
Hg-dagger: Interactive imitation learning with human experts , author=. 2019 International Conference on Robotics and Automation (ICRA) , pages=. 2019 , organization=
2019
-
[36]
arXiv preprint arXiv:2505.19789 , year=
What can rl bring to vla generalization? an empirical study , author=. arXiv preprint arXiv:2505.19789 , year=
-
[37]
arXiv preprint arXiv:2505.18719 , year=
Vla-rl: Towards masterful and general robotic manipulation with scalable reinforcement learning , author=. arXiv preprint arXiv:2505.18719 , year=
-
[38]
arXiv preprint arXiv:2505.17016 , year=
Interactive Post-Training for Vision-Language-Action Models , author=. arXiv preprint arXiv:2505.17016 , year=
-
[39]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Adaptive policy learning for offline-to-online reinforcement learning , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[40]
arXiv preprint arXiv:2210.06718 , year=
Hybrid rl: Using both offline and online data can make rl efficient , author=. arXiv preprint arXiv:2210.06718 , year=
-
[41]
International Conference on Machine Learning , pages=
Actor-critic alignment for offline-to-online reinforcement learning , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[42]
Advances in neural information processing systems , volume=
Conservative q-learning for offline reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[43]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Toward the Fundamental Limits of Imitation Learning , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[44]
Conference on Robot Learning (CoRL) , year=
Instruction-driven history-aware policies for robotic manipulations , author=. Conference on Robot Learning (CoRL) , year=
-
[45]
OpenVLA: An Open-Source VLA and Fine-Tuning Recipe (OFT) , author=
-
[46]
Nakamoto, Mitsuhiko and Zhai, Yuexiang and Singh, Anikait and Mark, Max Sobol and Ma, Yi and Finn, Chelsea and Kumar, Aviral and Levine, Sergey , booktitle=
-
[47]
arXiv preprint arXiv:1707.06347 , year=
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
-
[48]
arXiv preprint arXiv:2507.07969 , year=
Reinforcement learning with action chunking , author=. arXiv preprint arXiv:2507.07969 , year=
-
[49]
arXiv preprint arXiv:2410.07864 , year=
Rdt-1b: a diffusion foundation model for bimanual manipulation , author=. arXiv preprint arXiv:2410.07864 , year=
-
[50]
Robotics: Science and Systems , year=
ManiSkill3: GPU Parallelized Robotics Simulation and Rendering for Generalizable Embodied AI , author=. Robotics: Science and Systems , year=
-
[51]
Journal of mathematics and mechanics , pages=
A Markovian decision process , author=. Journal of mathematics and mechanics , pages=. 1957 , publisher=
1957
-
[52]
Journal of Cognitive Neuroscience , volume=
Reinforcement learning , author=. Journal of Cognitive Neuroscience , volume=
-
[53]
arXiv preprint arXiv:2402.10329 , year=
Universal manipulation interface: In-the-wild robot teaching without in-the-wild robots , author=. arXiv preprint arXiv:2402.10329 , year=
-
[54]
Advantage-Weighted Regression: Simple and Scalable Off-Policy Reinforcement Learning
Peng, Xue Bin and Kumar, Aviral and Zhang, Grace and Levine, Sergey , year = 2019, month = oct, number =. Advantage-. doi:10.48550/arXiv.1910.00177 , urldate =. arXiv , keywords =:1910.00177 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1910.00177 2019
-
[55]
arXiv preprint arXiv:2212.06817 , year=
Rt-1: Robotics transformer for real-world control at scale , author=. arXiv preprint arXiv:2212.06817 , year=
-
[56]
Conference on Robot Learning , pages=
Rt-2: Vision-language-action models transfer web knowledge to robotic control , author=. Conference on Robot Learning , pages=. 2023 , organization=
2023
-
[57]
arXiv preprint arXiv:1910.00177 , year=
Advantage-weighted regression: Simple and scalable off-policy reinforcement learning , author=. arXiv preprint arXiv:1910.00177 , year=
Pith/arXiv arXiv 1910
-
[58]
Advances in neural information processing systems , volume=
A minimalist approach to offline reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[59]
arXiv preprint arXiv:2110.06169 , year=
Offline reinforcement learning with implicit q-learning , author=. arXiv preprint arXiv:2110.06169 , year=
-
[60]
arXiv preprint arXiv:2402.03300 , year=
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.