Do Speech Emphasis Models Generalize across Languages and Emotions?
Pith reviewed 2026-06-29 04:50 UTC · model grok-4.3
The pith
Monolingual emphasis detection models show limited zero-shot transfer across typologically distant languages, while multilingual training substantially improves robustness and enables strong cross-emotion transfer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Monolingual models show limited zero-shot transfer, degrading across typologically distant languages, while multilingual training substantially improves robustness. Models transfer robustly between high- and low-arousal emotions; bidirectional transfer between synthetic and perceptual benchmarks suggests shared prosodic structure; and performance stays robust even at smaller training scales.
What carries the argument
The MMEE corpus of 10,000 professionally recorded utterances with three-level perceptual labels, used to benchmark cross-lingual and cross-emotion performance of emphasis detection models.
Load-bearing premise
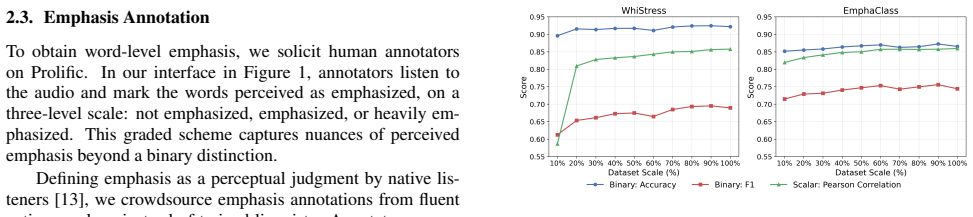
The three-level perceptual labels collected from ten annotators per sample accurately and consistently capture emphasis across the seven languages and thirty-four emotion categories.
What would settle it
Zero-shot testing of a multilingual model trained on MMEE data against emphasis labels in an eighth typologically distant language not included in the corpus.
Figures

read the original abstract
Prosodic emphasis varies across languages, emotions, and speaking styles, yet existing emphasis detection models are largely trained and evaluated on monolingual neutral read speech. We introduce MMEE (Multilingual Multi-Emotion Emphasis), a corpus of 10,000 professionally recorded expressive utterances (14.13 hours) across 7 languages and 34 emotion/style categories, with three-level perceptual labels (10 annotations per sample). We benchmark two state-of-the-art architectures under monolingual, cross-lingual, multilingual, cross-emotion, cross-dataset, and data-scale settings. Monolingual models show limited zero-shot transfer, degrading across typologically distant languages, while multilingual training substantially improves robustness. Models transfer robustly between high- and low-arousal emotions; bidirectional transfer between synthetic and perceptual benchmarks suggests shared prosodic structure; and performance stays robust even at smaller training scales.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the MMEE corpus (10,000 professionally recorded utterances, 14.13 hours, 7 languages, 34 emotion/style categories) with three-level perceptual emphasis labels (10 annotations per sample). It benchmarks two state-of-the-art architectures across monolingual, cross-lingual, multilingual, cross-emotion, cross-dataset, and data-scale settings. Key claims: monolingual models exhibit limited zero-shot transfer that degrades across typologically distant languages; multilingual training improves robustness; models transfer robustly between high- and low-arousal emotions; bidirectional transfer occurs between synthetic and perceptual benchmarks; and performance remains stable at smaller training scales.
Significance. If the perceptual labels are shown to be reliable and cross-lingually consistent, the work would provide a valuable new resource and empirical evidence on prosodic emphasis generalization, with implications for multilingual speech synthesis and emotion-aware systems. The multi-setting evaluation protocol and data-scale experiments are strengths that could support reproducible follow-up work.
major comments (2)
- [Corpus description paragraph] Corpus description paragraph: All reported transfer results (monolingual degradation, multilingual gains, emotion transfer, synthetic-perceptual transfer) rest on the assumption that the three-level perceptual labels accurately and comparably capture emphasis across 7 languages and 34 categories. The manuscript states only that 10 annotations per sample were collected; no inter-annotator agreement statistics, annotation guidelines, rater demographics, or cross-lingual consistency checks are provided. Systematic variation in agreement (e.g., by language or arousal level) would make observed performance differences potentially attributable to label noise rather than prosodic structure.
- [Abstract and experimental sections] Abstract and experimental sections: Benchmark outcomes are stated without accompanying model architecture details, training procedures, hyperparameter settings, statistical significance tests, error bars, or data exclusion criteria. These omissions prevent assessment of whether the reported transfer patterns are robust or sensitive to implementation choices.
minor comments (2)
- Clarify whether the MMEE corpus will be released publicly and under what license, as this directly affects the reproducibility of the cross-lingual and cross-emotion claims.
- The abstract mentions 'two state-of-the-art architectures' without naming them or citing the original papers; add explicit references and brief architectural descriptions in the methods section.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important areas for improving the clarity and reproducibility of our work on the MMEE corpus. We address each major comment below.
read point-by-point responses
-
Referee: [Corpus description paragraph] Corpus description paragraph: All reported transfer results (monolingual degradation, multilingual gains, emotion transfer, synthetic-perceptual transfer) rest on the assumption that the three-level perceptual labels accurately and comparably capture emphasis across 7 languages and 34 categories. The manuscript states only that 10 annotations per sample were collected; no inter-annotator agreement statistics, annotation guidelines, rater demographics, or cross-lingual consistency checks are provided. Systematic variation in agreement (e.g., by language or arousal level) would make observed performance differences potentially attributable to label noise rather than prosodic structure.
Authors: We agree that the current manuscript provides insufficient detail on the annotation process to fully support the cross-lingual and cross-emotion claims. In the revised version we will expand the corpus description to report inter-annotator agreement (e.g., Fleiss’ kappa overall and broken down by language and arousal level), the full annotation guidelines, rater demographics, and a brief analysis of label consistency across languages. These additions will allow readers to evaluate whether performance differences are attributable to prosodic structure rather than label noise. revision: yes
-
Referee: [Abstract and experimental sections] Abstract and experimental sections: Benchmark outcomes are stated without accompanying model architecture details, training procedures, hyperparameter settings, statistical significance tests, error bars, or data exclusion criteria. These omissions prevent assessment of whether the reported transfer patterns are robust or sensitive to implementation choices.
Authors: We acknowledge that the submitted manuscript omits several implementation details required for reproducibility. In the revision we will add complete model architecture specifications, training procedures, hyperparameter values, statistical significance tests with p-values, error bars on all metrics, and explicit data exclusion criteria to the experimental sections. The abstract will be updated where space allows to reference these methodological aspects. revision: yes
Circularity Check
No circularity: empirical benchmarking on newly collected corpus
full rationale
The paper introduces the MMEE corpus and reports direct empirical results from monolingual, multilingual, cross-lingual, and cross-emotion benchmarks. No equations, fitted parameters renamed as predictions, or derivation chains appear in the provided text. Central claims rest on held-out evaluation rather than self-referential definitions or self-citation load-bearing. This matches the default case of a self-contained empirical study with no reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The three-level perceptual labels from 10 annotations per utterance accurately reflect emphasis across languages and emotions.
Reference graph
Works this paper leans on
-
[1]
You can’t sithere
Introduction Prosodic emphasis plays a key role in spoken communication, signaling contrast, focus, speaker intent, and affect. For exam- ple, the same words can convey different meanings depending on emphasis: “You can’t sithere” can reject a location, while “You can’tsithere” can reject the action itself. Accurate mod- eling of emphasis is essential for...
-
[2]
However, existing approaches share several limitations: Figure 1:Speech emphasis annotation interface on Prolific
encode structural stress patterns via narrow rhythm unit (NRU) notation. However, existing approaches share several limitations: Figure 1:Speech emphasis annotation interface on Prolific. Participants click on words in the transcript they perceive as emphasized after listening to the audio. they are predominantly English-only, often rely on synthetic or p...
-
[3]
Do Speech Emphasis Models Generalize across Languages and Emotions?
Dataset 2.1. Speech Corpus We leverage a proprietary multilingual expressive speech cor- pus we collected internally as the foundation for annotating emphasis and conducting analyses. The dataset spans 34 cate- 1Website:https://multilingual-speech-emphasis. github.io arXiv:2606.27717v1 [cs.CL] 26 Jun 2026 Table 1:Comparison of emphasis datasets. Label sou...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
not emphasized
Methods We benchmark two state-of-the-art models, EmphaClass [10] and WhiStress [15], on MMEE, using a fixed 80/10/10 train/validation/test split, shared across models. All experi- ments are conducted on 8 NVIDIA 80 GB A100s. EmphaClass [10] finetunes a 1B-parameter multilingual SSL model (XLS-R) [24] built on Wav2Vec 2.0 [25] for frame- level binary clas...
-
[5]
Monolingual, Cross-Lingual, and Multilingual Monolingual experiments are run on all language dialects and classes, across 13 configurations
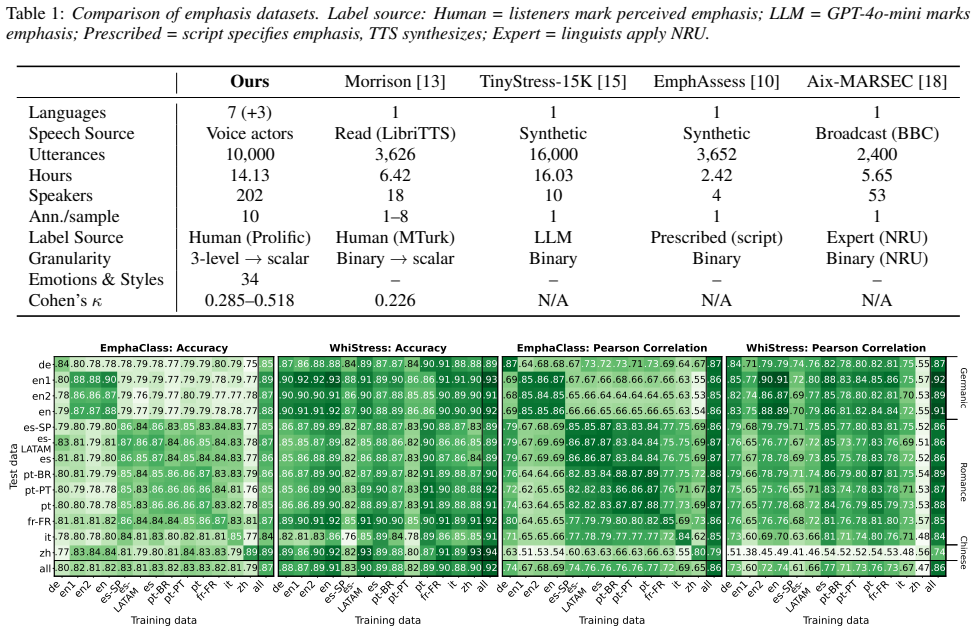
Results and Discussion 4.1. Monolingual, Cross-Lingual, and Multilingual Monolingual experiments are run on all language dialects and classes, across 13 configurations. Cross-lingual experiments involve training on one language and testing on each of the other languages. Multilingual (all) trains on the full dataset (8,000 training samples) and tests on i...
-
[6]
Emphasis representa- tions are partially universal, but fracture at typologically dis- tant languages
Conclusion We investigate whether pretrained speech models learn uni- versal representations of prosodic emphasis through a large- scale multilingual study using MMEE. Emphasis representa- tions are partially universal, but fracture at typologically dis- tant languages. Cross-lingual transfer follows language fam- ily structure and drops most strongly for...
-
[7]
The authors thoroughly reviewed and validated all outputs throughout the implementation and experimentation process
Generative AI Use Disclosure Cursor and Claude Code were used to assist experiment im- plementation. The authors thoroughly reviewed and validated all outputs throughout the implementation and experimentation process. Claude was used for minor editing of the draft (e.g. reducing word count, formatting tables); the original draft and all research contribut...
-
[8]
Emphasis control for parallel neural TTS,
S. Seshadri, T. Raitio, D. Castellani, and J. Li, “Emphasis control for parallel neural TTS,” inProc. Interspeech, 2022
2022
-
[9]
Prosodic promi- nence and boundaries in sequence-to-sequence speech synthesis,
A. Suni, S. Kakouros, M. Vainio, and J. ˇSimko, “Prosodic promi- nence and boundaries in sequence-to-sequence speech synthesis,” inSpeech Prosody 2020, 2020
2020
-
[10]
A model for vary- ing speaking style in tts systems,
S. Roekhaut, J.-P. Goldman, and A. C. Simon, “A model for vary- ing speaking style in tts systems,” inSpeech Prosody 2010, 2010
2010
-
[11]
Con- trollable emphasis with zero data for text-to-speech,
A. Joly, M. Nicolis, E. Peterova, A. Lombardi, A. Abbas, A. van Korlaar, A. Hussain, P. Sharma, A. Moinet, M. Lajszczak, P. Karanasou, A. Bonafonte, T. Drugman, and E. Sokolova, “Con- trollable emphasis with zero data for text-to-speech,” in12th ISCA Speech Synthesis Workshop (SSW2023), 2023
2023
-
[12]
R. Liu, Z. Jia, J. Yang, Y . Hu, and H. Li, “Emphasis rendering for conversational text-to-speech with multi-modal multi-scale con- text modeling,”arXiv preprint arXiv:2410.09524, 2024
-
[13]
Learning fine-grained controllability on speech generation via ef- ficient fine-tuning,
C.-M. Chien, A. Tjandra, A. Vyas, M. Le, B. Shi, and W.-N. Hsu, “Learning fine-grained controllability on speech generation via ef- ficient fine-tuning,” inProc. Interspeech, 2024
2024
-
[14]
Diffprosody: Diffusion- based latent prosody generation for expressive speech synthesis with prosody conditional adversarial training,
H.-S. Oh, S.-H. Lee, and S.-W. Lee, “Diffprosody: Diffusion- based latent prosody generation for expressive speech synthesis with prosody conditional adversarial training,”IEEE/ACM Trans. Audio, Speech, Lang. Process., 2024
2024
-
[15]
EME-TTS: Unlocking the Empha- sis and Emotion Link in Speech Synthesis,
H. Li, L. Qu, J. Hu, and T. Li, “EME-TTS: Unlocking the Empha- sis and Emotion Link in Speech Synthesis,” inProc. Interspeech, 2025
2025
-
[16]
Explicit empha- sis control in text-to-speech synthesis,
J. Bauer, F. Zalkow, M. M ¨uller, and C. Dittmar, “Explicit empha- sis control in text-to-speech synthesis,” inProceedings of the 13th ISCA Speech Synthesis Workshop, 2025
2025
-
[17]
Em- phAssess : a Prosodic Benchmark on Assessing Emphasis Trans- fer in Speech-to-Speech Models,
M. de Seyssel, A. D’Avirro, A. Williams, and E. Dupoux, “Em- phAssess : a Prosodic Benchmark on Assessing Emphasis Trans- fer in Speech-to-Speech Models,” inProc. EMNLP, 2024
2024
-
[18]
StressTest: Can YOUR Speech LM Handle the Stress?
I. Yosha, G. Maimon, and Y . Adi, “StressTest: Can YOUR Speech LM Handle the Stress?”arXiv preprint arXiv:2505.22765, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Deep Learning For Prominence Detection In Children’s Read Speech,
M. Vaidya, K. Sabu, and P. Rao, “Deep Learning For Prominence Detection In Children’s Read Speech,” inProc. ICASSP, 2022
2022
-
[20]
Crowd- sourced and Automatic Speech Prominence Estimation,
M. Morrison, P. Pawar, N. Pruyne, J. Cole, and B. Pardo, “Crowd- sourced and Automatic Speech Prominence Estimation,” inProc. ICASSP, 2024
2024
-
[21]
ProsAudit, a prosodic benchmark for self-supervised speech models,
M. de Seyssel, M. Lavechin, H. Titeux, A. Thomas, G. Vir- let, A. S. Revilla, G. Wisniewski, B. Ludusan, and E. Dupoux, “ProsAudit, a prosodic benchmark for self-supervised speech models,” inProc. Interspeech, 2023
2023
-
[22]
WhiStress: Enriching Tran- scriptions with Sentence Stress Detection,
I. Yosha, D. Shteyman, and Y . Adi, “WhiStress: Enriching Tran- scriptions with Sentence Stress Detection,” inProc. Interspeech, 2025
2025
-
[23]
Exploring sentence stress detection using whisper-based speech models,
T.-A. Hung, Y .-H. Hsieh, T.-H. Lo, Y .-C. Hsu, and B. Chen, “Exploring sentence stress detection using whisper-based speech models,” inProc. ROCLING, 2025, pp. 314–319
2025
-
[24]
LibriTTS: A corpus derived from LibriSpeech for text-to-speech,
H. Zen, R. Clark, R. J. Weiss, V . Dang, Y . Jia, Y . Wu, Y . Zhang, and Z. Chen, “LibriTTS: A corpus derived from LibriSpeech for text-to-speech,” inProc. Interspeech, 2019
2019
-
[25]
The aix-marsec project: an evolutive database of spoken british english,
C. Auran, C. Bouzon, and D. J. Hirst, “The aix-marsec project: an evolutive database of spoken british english,” inSpeech Prosody 2004, 2004
2004
-
[26]
X. Shi, X. Wang, Z. Guo, Y . Wang, P. Zhang, X. Zhang, Z. Guo, H. Hao, Y . Xi, B. Yang, J. Xu, J. Zhou, and J. Lin, “Qwen3-asr technical report,”arXiv preprint arXiv:2601.21337, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[27]
Silero V AD: pre-trained enterprise-grade V oice Activ- ity Detector (V AD), Number Detector and Language Classifier,
S. Team, “Silero V AD: pre-trained enterprise-grade V oice Activ- ity Detector (V AD), Number Detector and Language Classifier,” 2024, gitHub repository
2024
-
[28]
Judging llm-as-a-judge with mt-bench and chatbot arena,
L. Zheng, W.-L. Chiang, Y . Sheng, S. Zhuang, Z. Wu, Y . Zhuang, Z. Lin, Z. Li, D. Li, E. P. Xing, H. Zhang, J. E. Gonzalez, and I. Stoica, “Judging llm-as-a-judge with mt-bench and chatbot arena,” inNeurIPS 2023 Datasets and Benchmarks Track, 2023
2023
-
[29]
Deduplicating training data makes lan- guage models better,
K. Lee, D. Ippolito, A. Nystrom, C. Zhang, D. Eck, C. Callison- Burch, and N. Carlini, “Deduplicating training data makes lan- guage models better,” inProc. ACL, 2022
2022
-
[30]
Automatic sentence stress feedback for non-native english learners,
G. G. Lee, H.-Y . Lee, J. Song, B. Kim, S. Kang, J. Lee, and H. Hwang, “Automatic sentence stress feedback for non-native english learners,”Computer Speech & Language, vol. 41, pp. 29– 42, 2017
2017
-
[31]
XLS-R: Self-supervised Cross-lingual Speech Rep- resentation Learning at Scale,
A. Babu, C. Wang, A. Tjandra, K. Lakhotia, Q. Xu, N. Goyal, K. Singh, P. von Platen, Y . Saraf, J. Pino, A. Baevski, A. Conneau, and M. Auli, “XLS-R: Self-supervised Cross-lingual Speech Rep- resentation Learning at Scale,” inInterspeech 2022, 2022, pp. 2278–2282
2022
-
[32]
wav2vec 2.0: A framework for self-supervised learning of speech representa- tions,
A. Baevski, Y . Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representa- tions,” inAdvances in Neural Information Processing Systems, vol. 33, 2020, pp. 12 449–12 460
2020
-
[33]
Robust speech recognition via large-scale weak su- pervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak su- pervision,” inProceedings of the 40th International Conference on Machine Learning, vol. 202. PMLR, 2023, pp. 28 492– 28 518
2023
-
[34]
Effects of tone and focus on the formation and alignment of f0 contours,
Y . Xu, “Effects of tone and focus on the formation and alignment of f0 contours,”Journal of Phonetics, vol. 27, no. 1, pp. 55–105, 1999
1999
-
[35]
A circumplex model of affect,
J. A. Russell, “A circumplex model of affect,”Journal of Person- ality and Social Psychology, vol. 39, no. 6, pp. 1161–1178, 1980
1980
-
[36]
V ocal communication of emotion: A review of research paradigms,
K. R. Scherer, “V ocal communication of emotion: A review of research paradigms,”Speech Communication, vol. 40, no. 1, pp. 227–256, 2003
2003
-
[37]
F0-contours in emotional speech,
A. Paeschke, M. Kienast, and W. F. Sendlmeier, “F0-contours in emotional speech,” inProceedings of the 14th International Congress of Phonetic Sciences (ICPhS 1999), San Francisco, CA, 1999, pp. 929–932
1999
-
[38]
Analysis of emotionally salient aspects of fundamental frequency for emotion detection,
C. Busso, S. Lee, and S. Narayanan, “Analysis of emotionally salient aspects of fundamental frequency for emotion detection,” IEEE Transactions on Audio, Speech, and Language Processing, vol. 17, no. 4, pp. 582–596, 2009
2009
-
[39]
Communicating emotion: The role of prosodic fea- tures,
R. Frick, “Communicating emotion: The role of prosodic fea- tures,”Psychological Bulletin, vol. 97, pp. 412–429, 05 1985
1985
-
[40]
Toward the simulation of emo- tion in synthetic speech: A review of the literature on human vo- cal emotion,
I. R. Murray and J. L. Arnott, “Toward the simulation of emo- tion in synthetic speech: A review of the literature on human vo- cal emotion,”The Journal of the Acoustical Society of America, vol. 93, no. 2, pp. 1097–1108, Feb. 1993
1993
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.