Decodable Is Not Grounded: A Vision-Ablation Arbiter for VLM Spatial Reasoning
Pith reviewed 2026-07-01 06:20 UTC · model grok-4.3
The pith
A blank-image replacement shows that decodable spatial knowledge in VLMs is not necessarily grounded in vision.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
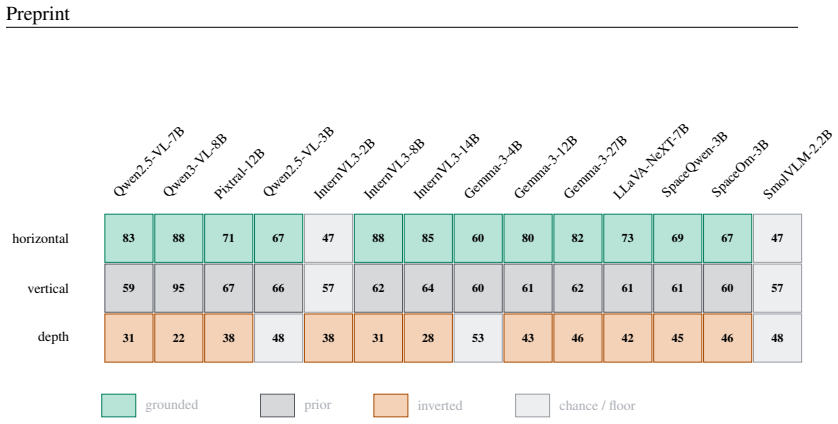
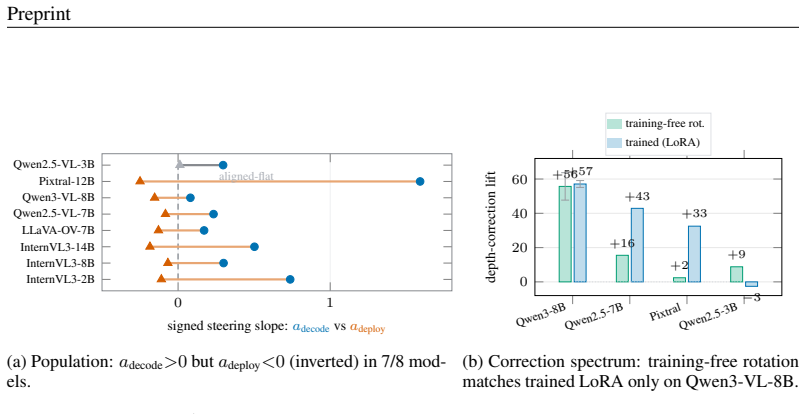
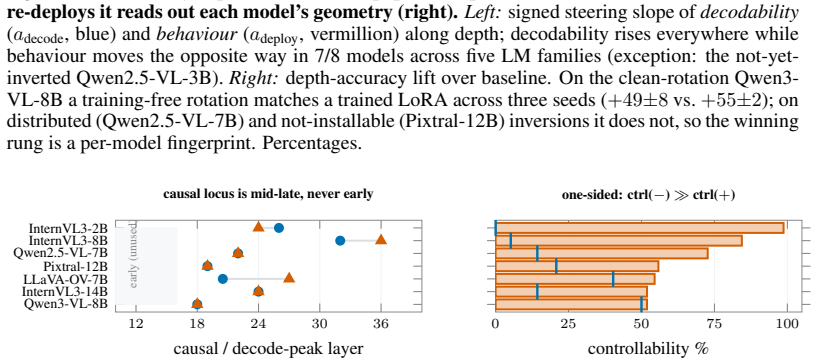
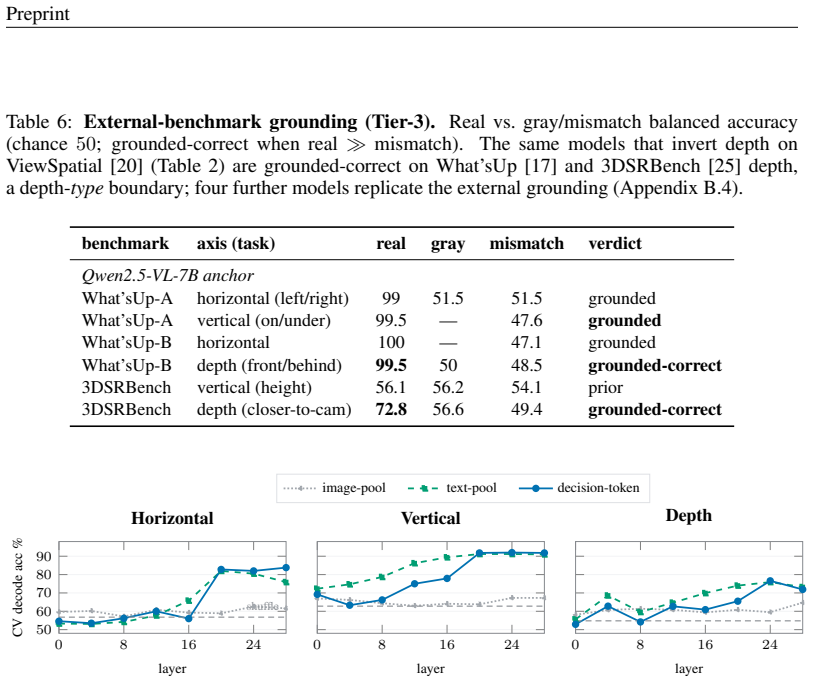
The central claim is that the standard combination of a linear probe and a training-free steering recovery can systematically overstate visual grounding in VLMs. The one-line causal control of replacing the image with a gray blank refutes apparent grounding on some axes and exposes an inversion regime where the model deploys the decoded direction with the wrong sign, scoring below chance. This taxonomy of grounded, prior, and inverted regimes holds across models from multiple families, with the inversion appearing at larger scales within families.
What carries the argument
The blank-image arbiter, a causal control that replaces the visual input with a uniform gray field to test dependence on actual image content.
If this is right
- Horizontal spatial axes are grounded in vision for the models tested.
- Vertical axes behave as image-independent priors.
- Depth axes are inverted, with decodable information deployed in the opposite direction.
- The complexity of correcting the inversion varies across models, from simple rotations to low-rank edits.
- The blank-image test cleanly separates the three regimes and should serve as a standard control.
Where Pith is reading between the lines
- Applying the same blank-image control to other reasoning tasks could reveal similar hidden priors or inversions.
- Training data biases may systematically produce inverted mappings on certain geometric dimensions.
- Future steering methods might need to include sign checks derived from ablation tests.
- The per-model spectrum of correction complexity suggests that some VLMs have more distributed representations of spatial inversions.
Load-bearing premise
Replacing the image with a gray blank cleanly isolates whether the model's spatial decisions depend on visual content rather than introducing new processing artifacts from uniform inputs.
What would settle it
If accuracy on real images for an axis does not drop when the image is replaced by a blank, while the claimed regime predicts a drop for grounded or a specific pattern for inverted, that would falsify the separation into three regimes.
Figures










read the original abstract
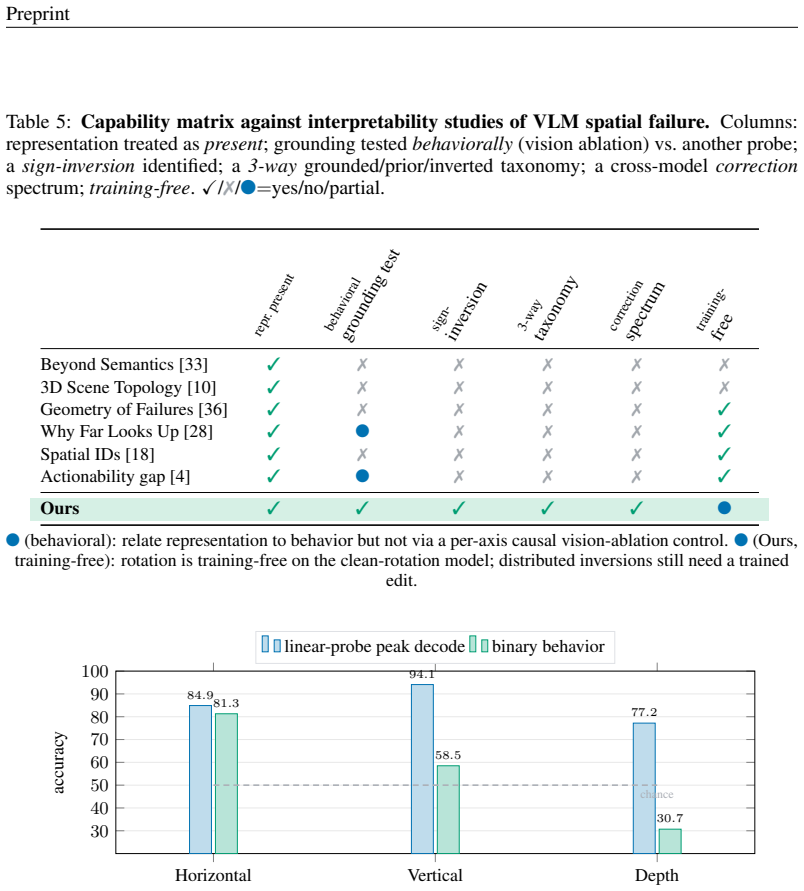
The standard way to read latent knowledge out of a model, a linear probe confirmed by a steering recovery, can systematically overstate what a vision-language model (VLM) actually grounds in the image. We show this on spatial reasoning, where the error is invisible to both probing and steering yet exposed by a one-line causal control: replacing the image with a gray blank. Probes decode the within-axis answer at 73--97% across axes, and a training-free projection lifts a near-chance axis from 59% to 79%, exactly the signature of unlocking latent knowledge. The blank-image arbiter refutes it, revealing three grounding regimes that probing conflates: an axis can be grounded (vision-dependent, correct), a prior (vision-independent, with its decode and its apparent recovery a directional default rather than perception), or, surprisingly, inverted: decodable, causally controllable, but deployed with the wrong sign, so the model scores below chance and the error requires looking. The taxonomy holds across the studied VLMs: in fourteen models spanning six language-model families and 2B--27B, horizontal is grounded, vertical is a prior, and depth is inverted, with the inversion emerging at scale within families. The decode-versus-deploy inversion replicates on seven of eight models across five families, and the minimal edit that re-deploys it varies with geometry: a training-free rotation matches a trained edit on the cleanest model, while distributed inversions need a trained low-rank edit, tracing a per-model correction-complexity spectrum. The cheap, self-calibrating arbiter cleanly separates grounded perception, inverted perception, and prior substitution; we argue it should be a default control for latent-knowledge and steering claims in VLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that standard linear probing and steering recovery in VLMs overstate visual grounding for spatial reasoning tasks. Using a blank-image (gray) ablation as a causal control, it identifies three regimes—grounded (vision-dependent and correct), prior (vision-independent directional default), and inverted (decodable and steerable but with wrong sign, yielding below-chance performance)—that probing conflates. Horizontal axes are grounded, vertical are priors, and depth is inverted (emerging at scale); the pattern replicates across 14 models in 6 families (2B–27B). A training-free rotation or low-rank edit can correct inversions, with complexity varying by model. The blank-image arbiter is proposed as a default control for grounding claims.
Significance. If the blank-image control validly isolates vision dependence, the result supplies a cheap, self-calibrating diagnostic that separates true perceptual grounding from language priors and sign inversions, directly challenging reliance on probe accuracy or steering recovery alone. The broad evaluation across model families and scales, plus the geometry-specific correction spectrum, strengthens the practical takeaway. The work credits the external control for exposing patterns invisible to internal methods and offers falsifiable per-axis predictions.
major comments (2)
- [Methods (blank-image control)] Methods / blank-image arbiter description: The central taxonomy (grounded vs. prior vs. inverted) is defined solely by comparing real-image vs. gray-blank performance. No validation is reported that uniform gray inputs do not themselves trigger model-specific attention shifts, logit biases, or out-of-distribution defaults; if they do, the 'prior' and 'inverted' labels become artifacts of the control rather than evidence about grounding on actual images. This directly undermines the claim that the arbiter cleanly separates the three regimes.
- [Results (depth inversion)] Results (cross-model patterns, e.g., depth inversion at scale): The inversion claim for depth (and its emergence within families) rests on the gray-blank baseline being neutral. Without auxiliary controls (e.g., Gaussian noise, black images, or scrambled patches) to confirm the gray field does not systematically invert or default the depth axis, the scale-dependent pattern cannot be attributed to grounding failure rather than control artifact.
minor comments (2)
- [Abstract / Results] Abstract and §4: The reported accuracy ranges (73–97%, 59% to 79%) would benefit from per-model, per-axis tables with confidence intervals or statistical tests to support the 'exactly the signature' claim for steering recovery.
- [Figures] Figure captions: Clarify whether the gray blank is a constant RGB value or sampled; this affects reproducibility of the control.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying the need for stronger validation of the blank-image control. We agree that additional auxiliary controls would increase confidence in the taxonomy and will incorporate them in the revision.
read point-by-point responses
-
Referee: Methods / blank-image arbiter description: The central taxonomy (grounded vs. prior vs. inverted) is defined solely by comparing real-image vs. gray-blank performance. No validation is reported that uniform gray inputs do not themselves trigger model-specific attention shifts, logit biases, or out-of-distribution defaults; if they do, the 'prior' and 'inverted' labels become artifacts of the control rather than evidence about grounding on actual images. This directly undermines the claim that the arbiter cleanly separates the three regimes.
Authors: We acknowledge that the manuscript reports no explicit comparison of the gray blank against other neutral inputs. In the revised manuscript we will add experiments replacing the image with Gaussian noise and with solid black fields, reporting probe accuracies and steering recovery under each. If the grounded/prior/inverted classification remains stable across these controls, this will confirm that the taxonomy reflects model behavior on real images rather than a gray-specific artifact. revision: yes
-
Referee: Results (cross-model patterns, e.g., depth inversion at scale): The inversion claim for depth (and its emergence within families) rests on the gray-blank baseline being neutral. Without auxiliary controls (e.g., Gaussian noise, black images, or scrambled patches) to confirm the gray field does not systematically invert or default the depth axis, the scale-dependent pattern cannot be attributed to grounding failure rather than control artifact.
Authors: We agree that the depth-inversion result would be more robust with the suggested auxiliary controls. The revision will include per-axis probe and steering results under Gaussian noise and black-image baselines, with particular attention to whether the below-chance depth performance and its scale dependence persist. This will allow us to attribute the inversion to the models rather than to the choice of gray field. revision: yes
Circularity Check
No circularity; empirical control defines taxonomy independently
full rationale
The paper's central result is an empirical taxonomy (grounded / prior / inverted) obtained by direct performance comparison between real images and gray-blank ablations across 14 models. This is an external causal intervention, not a quantity fitted to data and then renamed as a prediction, nor any self-definitional mapping, nor a load-bearing self-citation. No equations, ansatzes, or uniqueness theorems are invoked; the three regimes are observed outcomes of the control experiment itself. The derivation chain therefore contains no reduction to its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Don’t just assume; look and answer: Overcoming priors for visual question answering
Aishwarya Agrawal, Dhruv Batra, Devi Parikh, and Aniruddha Kembhavi. Don’t just assume; look and answer: Overcoming priors for visual question answering. InCVPR, 2018
2018
-
[2]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jian- qiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report....
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [4]
-
[5]
Probing classifiers: Promises, shortcomings, and advances.Computational Linguistics, 48(1):207–219, 2022
Yonatan Belinkov. Probing classifiers: Promises, shortcomings, and advances.Computational Linguistics, 48(1):207–219, 2022
2022
-
[6]
Spatialbot: Precise spatial understanding with vision language models
Wenxiao Cai et al. Spatialbot: Precise spatial understanding with vision language models. arXiv preprint arXiv:2406.13642, 2024
-
[7]
Spatialvlm: Endowing vision-language models with spatial reasoning capabilities
Boyuan Chen et al. Spatialvlm: Endowing vision-language models with spatial reasoning capabilities. InCVPR, 2024
2024
-
[8]
Mm-spatial: Exploring 3d spatial understanding in multimodal llms
Erik Daxberger et al. Mm-spatial: Exploring 3d spatial understanding in multimodal llms. In ICCV, 2025. arXiv:2503.13111
-
[9]
Mengfei Du et al. Embspatial-bench: Benchmarking spatial understanding for embodied tasks with large vision-language models.arXiv preprint arXiv:2406.05756, 2024
-
[10]
Uncovering and Shaping the Latent Representation of 3D Scene Topology in Vision-Language Models
Wei Gao et al. Uncovering and shaping the latent representation of 3d scene topology in vision-language models.arXiv preprint arXiv:2605.07148, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, et al. Gemma 3 technical report.arXiv preprint arXiv:2503.19786, 2025. 10 Preprint
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Making the V in VQA matter: Elevating the role of image understanding in visual question answering
Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Making the V in VQA matter: Elevating the role of image understanding in visual question answering. In CVPR, 2017
2017
-
[13]
Language models represent space and time
Wes Gurnee and Max Tegmark. Language models represent space and time. InICLR, 2024
2024
-
[14]
Designing and interpreting probes with control tasks
John Hewitt and Percy Liang. Designing and interpreting probes with control tasks. InEMNLP, 2019
2019
-
[15]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. InInter- national Conference on Learning Representations (ICLR), 2022. arXiv:2106.09685
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[16]
Omnispatial: Towards comprehensive spatial reasoning benchmark for vision language models,
Mengdi Jia, Zekun Qi, Shaochen Zhang, Wenyao Zhang, Xinqiang Yu, Jiawei He, He Wang, and Li Yi. Omnispatial: Towards comprehensive spatial reasoning benchmark for vision lan- guage models. InICLR, 2026. arXiv:2506.03135
-
[17]
Amita Kamath, Jack Hessel, and Kai-Wei Chang. What’s “up” with vision-language mod- els? investigating their struggle with spatial reasoning. InEMNLP, 2023. arXiv:2310.19785; benchmark commonly cited as “What’sUp”
-
[18]
Raphi Kang, Hongqiao Chen, Georgia Gkioxari, and Pietro Perona. Linear mechanisms for spatiotemporal reasoning in vision language models.arXiv preprint arXiv:2601.12626, 2026
-
[19]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Yan- wei Li, Ziwei Liu, and Chunyuan Li. Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
ViewSpatial-Bench: Evaluating multi-perspective spatial localization in vision-language models,
Dingming Li, Hongxing Li, Zixuan Wang, Yuchen Yan, Hang Zhang, Siqi Chen, Guiyang Hou, Shengpei Jiang, Wenqi Zhang, Yongliang Shen, Weiming Lu, and Yueting Zhuang. Viewspatial-bench: Evaluating multi-perspective spatial localization in vision-language mod- els.arXiv preprint arXiv:2505.21500, 2025
-
[21]
Inference-Time Intervention: Eliciting Truthful Answers from a Language Model
Kenneth Li, Oam Patel, Fernanda Vi´egas, Hanspeter Pfister, and Martin Wattenberg. Inference- time intervention: Eliciting truthful answers from a language model. InAdvances in Neural Information Processing Systems (NeurIPS), 2023. arXiv:2306.03341
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Visual spatial reasoning.TACL, 2023
Fangyu Liu, Guy Emerson, and Nigel Collier. Visual spatial reasoning.TACL, 2023
2023
-
[23]
Yuhong Liu, Beichen Zhang, Yuhang Zang, Yuhang Cao, Long Xing, Xiaoyi Dong, Haodong Duan, Dahua Lin, and Jiaqi Wang. Spatial-ssrl: Enhancing spatial understanding via self- supervised reinforcement learning.arXiv preprint arXiv:2510.27606, 2025. CVPR 2026 ac- cepted
-
[24]
Zhining Liu, Ziyi Chen, Hui Liu, Chen Luo, Xianfeng Tang, Suhang Wang, Joy Zeng, Zhenwei Dai, Zhan Shi, Tianxin Wei, Benoit Dumoulin, and Hanghang Tong. Seeing but not believing: Probing the disconnect between visual attention and answer correctness in vlms.arXiv preprint arXiv:2510.17771, 2025
-
[25]
de Melo, Alan Yuille, and Jieneng Chen
Wufei Ma, Haoyu Chen, Guofeng Zhang, Celso M. de Melo, Alan Yuille, and Jieneng Chen. 3DSRBench: A comprehensive 3D spatial reasoning benchmark. InarXiv preprint arXiv:2412.07825, 2024
-
[26]
SmolVLM: Redefining small and efficient multimodal models
Andr ´es Marafioti et al. Smolvlm: Redefining small and efficient multimodal models.arXiv preprint arXiv:2504.05299, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Locating and editing factual associations in gpt
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and editing factual associations in gpt. InNeurIPS, 2022
2022
-
[28]
Why Far Looks Up: Probing Spatial Representation in Vision-Language Models
Cheolhong Min, Jaeyun Jung, Daeun Lee, Hyeonseong Jeon, Yu Su, Jonathan Tremblay, Chan Hee Song, and Jaesik Park. Why far looks up: Probing spatial representation in vision- language models.arXiv preprint arXiv:2605.30161, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
Mistral AI. Pixtral 12b.arXiv preprint arXiv:2410.07073, 2024. 11 Preprint
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Sparse autoencoders learn monosemantic features in vision-language models
Mateusz Pach, Shyamgopal Karthik, Quentin Bouniot, Serge Belongie, and Zeynep Akata. Sparse autoencoders learn monosemantic features in vision-language models. InCVPR, 2025. arXiv:2504.02821
-
[31]
Steering Llama 2 via Contrastive Activation Addition
Nina Panickssery, Nick Gabrieli, Julian Schulz, Meg Tong, Evan Hubinger, and Alexan- der Matt Turner. Steering Llama 2 via contrastive activation addition. InACL, 2024. arXiv:2312.06681
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Steering llama 2 via contrastive activation addition
Nina Panickssery, Nick Gabrieli, Julian Schulz, Meg Tong, Evan Hubinger, and Alexan- der Matt Turner. Steering llama 2 via contrastive activation addition. InACL, 2024. Alias for panickssery2024; preserved for citations
2024
-
[33]
Jianing Qi, Jiawei Liu, Hao Tang, and Zhigang Zhu. Beyond semantics: Rediscovering spatial awareness in vision-language models.arXiv preprint arXiv:2503.17349, 2025
-
[34]
Yifu Qiu, Zheng Zhao, Yftah Ziser, Anna Korhonen, Edoardo M. Ponti, and Shay B. Cohen. Spectral editing of activations for large language model alignment. InAdvances in Neural Information Processing Systems (NeurIPS), 2024. arXiv:2405.09719
-
[35]
SpaceQwen2.5-VL and SpaceOm: Spatial-reasoning fine-tunes of Qwen2.5-VL
RemyxAI. SpaceQwen2.5-VL and SpaceOm: Spatial-reasoning fine-tunes of Qwen2.5-VL. Hugging Face model cards,https://huggingface.co/remyxai, 2025. VQASynth- distilled spatial-reasoning VLMs, building on SpatialVLM [7]
2025
-
[36]
The Geometry of Representational Failures in Vision Language Models
Daniele Savietto, Declan Campbell, Andr ´e Panisson, Marco Nurisso, Giovanni Petri, Jonathan D. Cohen, and Alan Perotti. The geometry of representational failures in vision language models.arXiv preprint arXiv:2602.07025, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[37]
Linear spatial world models emerge in large language models.arXiv preprint arXiv:2506.02996, 2025
Matthieu Tehenan, Christian Bolivar Moya, Tenghai Long, and Guang Lin. Linear spatial world models emerge in large language models.arXiv preprint arXiv:2506.02996, 2025
-
[38]
Angular steering: Behavior control via rotation in activation space
Vu and Nguyen. Angular steering: Behavior control via rotation in activation space. InAd- vances in Neural Information Processing Systems (NeurIPS), 2025. arXiv:2510.26243
-
[39]
Interpretability in the wild: a circuit for indirect object identification in gpt-2 small
Kevin Wang et al. Interpretability in the wild: a circuit for indirect object identification in gpt-2 small. InICLR, 2023
2023
-
[40]
Semantics-adaptive activation intervention for LLMs via dynamic steering vectors
Weixuan Wang, Jingyuan Yang, and Wei Peng. Semantics-adaptive activation intervention for LLMs via dynamic steering vectors. InInternational Conference on Learning Representations (ICLR), 2025. arXiv:2410.12299
-
[41]
Manning, and Christopher Potts
Zhengxuan Wu, Aryaman Arora, Zheng Wang, Atticus Geiger, Dan Jurafsky, Christopher D. Manning, and Christopher Potts. ReFT: Representation finetuning for language models. In NeurIPS, 2024
2024
-
[42]
Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie
Jihan Yang, Shusheng Yang, Anjali W. Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie. Think- ing in space: How multimodal large language models see, remember and recall spaces. In CVPR, 2025. VSI-Bench
2025
-
[43]
MMSI-Bench: A Benchmark for Multi-Image Spatial Intelligence
Sihan Yang, Runsen Xu, Yiman Xie, Sizhe Yang, Mo Li, Jingli Lin, Chenming Zhu, Xiaochen Chen, Haodong Duan, Xiangyu Yue, Dahua Lin, Tai Wang, and Jiangmiao Pang. Mmsi-bench: A benchmark for multi-image spatial intelligence. InICLR, 2026. arXiv:2505.23764
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[44]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Yuchen Duan, Hao Tian, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
knowledge present, not deployed
Andy Zou et al. Representation engineering: A top-down approach to ai transparency.arXiv preprint, 2023. 12 Preprint A IMPLEMENTATIONDETAILS Model and decoding.Qwen2.5-VL-7B-Instruct [3], loaded in 4-bit nf4 on a single RTX 4090,attn implementation="sdpa"(flash-attention not installed), greedy decoding, max new tokens=8. The language tower has 28 decoder ...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.