OopsieVerse: A Safety Benchmark with Damage-Aware Simulation for Robot Manipulation
Pith reviewed 2026-07-01 05:03 UTC · model grok-4.3
The pith
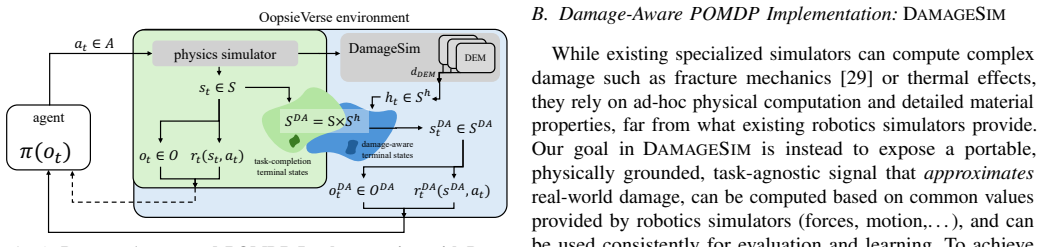
OOPSIEVERSE supplies damage as an explicit, physically-grounded signal in robot manipulation simulations by converting contact forces, temperature changes, and liquid interactions into mechanical, thermal, or fluid damage metrics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
OOPSIEVERSE provides damage as an explicit, physically-grounded, and task-agnostic signal by converting sources such as contact forces, temperature changes, and liquid interactions into corresponding mechanical, thermal or fluid damage. It comprises DAMAGESIM for detecting and quantifying damage during navigation and manipulation, plus tasks designed to evaluate common damage modes. The framework is instantiated in OmniGibson and RoboCasa, and supports use cases including safer demonstration collection, damage-conditioned policy learning, safety benchmarking of vision-language-action models, and improved sim-to-real transfer.
What carries the argument
DAMAGESIM, a simulator-agnostic framework that detects and quantifies damage from physical sources during robot navigation and manipulation.
If this is right
- Real-time damage feedback can guide collection of safer human demonstrations.
- Damage-conditioned imitation learning and reinforcement learning can produce safer manipulation policies.
- State-of-the-art vision-language-action policies can be benchmarked for safety in addition to task success.
- Sim-to-real transferred policies can achieve improved real-world safety.
Where Pith is reading between the lines
- The same damage-conversion approach could be applied to non-household domains such as industrial or outdoor robotics.
- Integrating DAMAGESIM outputs with real sensor streams might enable hybrid sim-real safety training loops.
- Standardized damage metrics from this framework could support regulatory or certification requirements for household robots.
Load-bearing premise
The conversion rules inside DAMAGESIM produce damage values that meaningfully correspond to real physical damage.
What would settle it
A direct comparison of damage values produced by DAMAGESIM against measured outcomes from equivalent real-world robot experiments using force sensors, temperature probes, and fluid volume tracking.
Figures







read the original abstract
While robotic manipulation capabilities have advanced rapidly, physical safety remains a major barrier to deploying household robots: task success is insufficient if the robot damages itself or its surroundings. Simulation offers a harm-free alternative to costly and dangerous real-world training and evaluation, yet existing simulators lack general mechanisms to detect, quantify, and represent damage. To address this gap, we introduce OOPSIEVERSE, a unified simulation framework and benchmark for damage-aware household manipulation. OOPSIEVERSE provides damage as an explicit, physically-grounded, and taskagnostic signal by converting sources such as contact forces, temperature changes, and liquid interactions into corresponding mechanical, thermal or fluid damage. OOPSIEVERSE comprises two core elements: (1) DAMAGESIM, a simulator-agnostic framework for detecting and quantifying damage during navigation and manipulation, and (2) a suite of household tasks designed to evaluate common damage modes and distinguish between task completion and safe execution. We demonstrate the generality of our framework by instantiating DAMAGESIM in two simulators with different physics backends, OmniGibson (Nvidia Omniverse) and RoboCasa (MuJoCo). We further showcase the utility of OOPSIEVERSE across multiple use cases, including (1) guiding safer demonstration collection via real-time damage feedback, (2) learning safer manipulation policies through damage-conditioned imitation learning and reinforcement learning, (3) benchmarking the safety of state-of-the-art Vision Language Action policies, and (4) improving real-world safety of sim-to-real transferred policies. Together, our results highlight the potential of OOPSIEVERSE as an open-source foundation for systematic, scalable research on safe robot manipulation. For code and more information, please refer to https://robin-lab.cs.utexas.edu/oopsieverse/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces OOPSIEVERSE, a unified simulation framework and benchmark for damage-aware household robot manipulation. It consists of DAMAGESIM, a simulator-agnostic layer that converts contact forces, temperature changes, and liquid interactions into mechanical, thermal, or fluid damage scores, instantiated in OmniGibson and RoboCasa; a suite of household tasks; and four use cases demonstrating safer demonstration collection, damage-conditioned policy learning, VLA benchmarking, and sim-to-real transfer.
Significance. If the damage conversion rules prove accurate, OOPSIEVERSE could fill a clear gap in existing simulators by supplying an explicit, task-agnostic safety signal, enabling more systematic research on safe manipulation. The open-source release, dual-simulator instantiation, and emphasis on reproducibility are concrete strengths that support adoption as a foundation for future work.
major comments (2)
- [Abstract / DAMAGESIM] Abstract and DAMAGESIM description: the central claim that damage is provided as a 'physically-grounded' signal rests on conversion rules whose outputs 'meaningfully correspond to real physical damage,' yet the manuscript supplies no calibration data, material-property thresholds, correlation coefficients, or post-interaction measurements (e.g., strain, fracture, or functional degradation) against real-world observations; this is load-bearing for the 'physically-grounded' property.
- [Use cases] Use-cases section: the four demonstrated applications (real-time feedback, imitation/RL, VLA benchmarking, sim-to-real) are described at a high level but contain no quantitative results, error bars, ablation studies, or statistical validation, so the claim that OOPSIEVERSE 'highlights the potential' as a foundation cannot be assessed from the presented evidence.
minor comments (1)
- [Abstract] Abstract: 'taskagnostic' is missing a hyphen and should read 'task-agnostic'.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and commit to revisions that strengthen the physical grounding and quantitative support in the manuscript.
read point-by-point responses
-
Referee: [Abstract / DAMAGESIM] Abstract and DAMAGESIM description: the central claim that damage is provided as a 'physically-grounded' signal rests on conversion rules whose outputs 'meaningfully correspond to real physical damage,' yet the manuscript supplies no calibration data, material-property thresholds, correlation coefficients, or post-interaction measurements (e.g., strain, fracture, or functional degradation) against real-world observations; this is load-bearing for the 'physically-grounded' property.
Authors: We agree this is a valid concern and that direct real-world calibration data would further support the claim. DAMAGESIM conversions are derived from established physical models and literature thresholds (e.g., contact force limits from material failure studies). In revision we will add a new subsection explicitly listing the physical basis, specific thresholds, and citations for each damage type. This directly addresses the load-bearing issue. revision: yes
-
Referee: [Use cases] Use-cases section: the four demonstrated applications (real-time feedback, imitation/RL, VLA benchmarking, sim-to-real) are described at a high level but contain no quantitative results, error bars, ablation studies, or statistical validation, so the claim that OOPSIEVERSE 'highlights the potential' as a foundation cannot be assessed from the presented evidence.
Authors: The use-cases section includes quantitative metrics (damage reduction, success rates) via figures, but we acknowledge the absence of error bars, ablations, and statistical tests limits assessment. We will expand the section with repeated-trial statistics, error bars, and ablation studies on damage conditioning to provide the requested rigor. revision: yes
Circularity Check
No circularity: new definitional framework with no equations or self-referential reductions
full rationale
The paper introduces OOPSIEVERSE and DAMAGESIM as a new simulation framework and benchmark that defines damage conversion rules from contact forces, temperature, and liquids. No equations, fitted parameters, predictions, or self-citations are present in the provided text that would cause any claimed result to reduce to its own inputs by construction. The contribution is the creation of this tooling and task suite rather than a derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Damage can be quantified from contact forces, temperature changes, and liquid interactions in simulation
invented entities (1)
-
DAMAGE SIM
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Chengshu Li, Ruohan Zhang, Josiah Wong, Cem Gokmen, Sanjana Srivastava, Roberto Mart ´ın-Mart´ın, Chen Wang, Gabrael Levine, Wensi Ai, Benjamin Martinez, Hang Yin, Michael Lingelbach, Minjune Hwang, Ayano Hiranaka, Sujay Garlanka, Arman Aydin, Sharon Lee, Jiankai Sun, Mona Anvari, Manasi Sharma, Dhruva Bansal, Samuel Hunter, Kyu-Young Kim, Alan Lou, Caleb...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Nvidia omniverse developer overview
NVIDIA. Nvidia omniverse developer overview. https://docs.omniverse.nvidia.com/dev-overview/latest/ index.html. Accessed 2026-01-31
2026
-
[3]
RoboCasa: Large-Scale Simulation of Everyday Tasks for Generalist Robots
Soroush Nasiriany, Abhiram Maddukuri, Lance Zhang, Adeet Parikh, Aaron Lo, Abhishek Joshi, Ajay Mandlekar, and Yuke Zhu. Robocasa: Large-scale simulation of everyday tasks for generalist robots.arXiv preprint arXiv:2406.02523, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
robosuite: A modular simulation framework and benchmark for robot learning,
Yuke Zhu, Josiah Wong, Ajay Mandlekar, Roberto Mart´ın- Mart´ın, Abhishek Joshi, Kevin Lin, Abhiram Maddukuri, Soroush Nasiriany, and Yifeng Zhu. robosuite: A modular simulation framework and benchmark for robot learning,
-
[5]
URL https://arxiv.org/abs/2009.12293
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[6]
Mujoco: A physics engine for model-based control
Emanuel Todorov, Tom Erez, and Yuval Tassa. Mujoco: A physics engine for model-based control. In2012 IEEE/RSJ international conference on intelligent robots and systems, pages 5026–5033. IEEE, 2012
2012
-
[7]
A time-dependent hamilton-jacobi formulation of reachable sets for continuous dynamic games.IEEE Transactions on automatic control, 50(7):947–957, 2005
Ian M Mitchell, Alexandre M Bayen, and Claire J Tomlin. A time-dependent hamilton-jacobi formulation of reachable sets for continuous dynamic games.IEEE Transactions on automatic control, 50(7):947–957, 2005
2005
-
[8]
Conflict resolution for air traffic management: A study in multiagent hybrid systems.IEEE Transactions on automatic control, 43(4):509–521, 2002
Claire Tomlin, George J Pappas, and Shankar Sastry. Conflict resolution for air traffic management: A study in multiagent hybrid systems.IEEE Transactions on automatic control, 43(4):509–521, 2002
2002
-
[9]
Control barrier function based quadratic programs for safety critical systems.IEEE Transactions on Automatic Control, 62(8):3861–3876, 2016
Aaron D Ames, Xiangru Xu, Jessy W Grizzle, and Paulo Tabuada. Control barrier function based quadratic programs for safety critical systems.IEEE Transactions on Automatic Control, 62(8):3861–3876, 2016
2016
-
[10]
Control barrier functions: Theory and applications
Aaron D Ames, Samuel Coogan, Magnus Egerstedt, Gennaro Notomista, Koushil Sreenath, and Paulo Tabuada. Control barrier functions: Theory and applications. In 2019 18th European control conference (ECC), pages 3420–3431. Ieee, 2019
2019
-
[11]
Set invariance in control.Automatica, 35(11):1747–1767, 1999
Franco Blanchini. Set invariance in control.Automatica, 35(11):1747–1767, 1999
1999
-
[12]
Safe model-based reinforcement learning with stability guarantees.Advances in neural information processing systems, 30, 2017
Felix Berkenkamp, Matteo Turchetta, Angela Schoellig, and Andreas Krause. Safe model-based reinforcement learning with stability guarantees.Advances in neural information processing systems, 30, 2017
2017
-
[13]
Safe exploration in continuous action spaces
Gal Dalal, Daniel Gilboa, Shie Mannor, and Andreas Schumann. Safe exploration in continuous action spaces. InInternational Conference on Machine Learning (ICML), 2018
2018
-
[14]
Recovery rl: Safe reinforcement learning with learned recovery zones.Robotics: Science and Systems (RSS), 2021
Brijen Thananjeyan, Ashwin Balakrishna, Suraj Nair, et al. Recovery rl: Safe reinforcement learning with learned recovery zones.Robotics: Science and Systems (RSS), 2021
2021
- [15]
-
[16]
Don’t let your robot be harmful: Responsible robotic manipulation via safety-as-policy, 2025
Minheng Ni, Lei Zhang, Zihan Chen, Kaixin Bai, Zhaopeng Chen, Jianwei Zhang, Lei Zhang, and Wang- meng Zuo. Don’t let your robot be harmful: Responsible robotic manipulation via safety-as-policy, 2025. URL https://arxiv.org/abs/2411.18289
-
[17]
Safemimic: Towards safe and autonomous human-to-robot imitation for mobile manip- ulation, 2025
Arpit Bahety, Arnav Balaji, Ben Abbatematteo, and Roberto Mart ´ın-Mart´ın. Safemimic: Towards safe and autonomous human-to-robot imitation for mobile manip- ulation, 2025. URL https://arxiv.org/abs/2506.15847
-
[18]
Generalizing safety beyond collision-avoidance via latent- space reachability analysis
Kensuke Nakamura, Lasse Peters, and Andrea Bajcsy. Generalizing safety beyond collision-avoidance via latent- space reachability analysis. InRobotics: Science and Systems XXI, RSS2025. Robotics: Science and Systems Foundation, 2025. doi: 10.15607/rss.2025.xxi.113. URL http://dx.doi.org/10.15607/RSS.2025.XXI.113
-
[19]
A comprehensive survey on safe reinforcement learning.Journal of Machine Learning Research, 16:1437–1480, 2015
Javier Garcia and Fernando Fern ´andez. A comprehensive survey on safe reinforcement learning.Journal of Machine Learning Research, 16:1437–1480, 2015
2015
-
[20]
Benchmarking Batch Deep Reinforcement Learning Algorithms
Alex Ray, Joshua Achiam, and Dario Amodei. Bench- marking safe exploration in deep reinforcement learning. arXiv preprint arXiv:1910.01708, 7(1):2, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[21]
Safety gymnasium: A unified safe reinforcement learning benchmark.Advances in Neural Information Processing Systems, 36:18964– 18993, 2023
Jiaming Ji, Borong Zhang, Jiayi Zhou, Xuehai Pan, Weidong Huang, Ruiyang Sun, Yiran Geng, Yifan Zhong, Josef Dai, and Yaodong Yang. Safety gymnasium: A unified safe reinforcement learning benchmark.Advances in Neural Information Processing Systems, 36:18964– 18993, 2023
2023
-
[22]
Safe-control-gym: A unified benchmark suite for safe learning-based control and reinforcement learning in robotics.IEEE Robotics and Automation Letters, 7(4): 11142–11149, 2022
Zhaocong Yuan, Adam W Hall, Siqi Zhou, Lukas Brunke, Melissa Greeff, Jacopo Panerati, and Angela P Schoellig. Safe-control-gym: A unified benchmark suite for safe learning-based control and reinforcement learning in robotics.IEEE Robotics and Automation Letters, 7(4): 11142–11149, 2022
2022
-
[23]
Guard: A safe reinforcement learning benchmark.Transactions on Machine Learning Research, 2023
Weiye Zhao, Yifan Sun, Feihan Li, Rui Chen, Ruixuan Liu, Tianhao Wei, and Changliu Liu. Guard: A safe reinforcement learning benchmark.Transactions on Machine Learning Research, 2023
2023
-
[24]
Jan Leike, Miljan Martic, Victoria Krakovna, Pedro A. Ortega, Tom Everitt, Andrew Lefrancq, Laurent Orseau, and Shane Legg. Ai safety gridworlds, 2017. URL https://arxiv.org/abs/1711.09883
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[25]
Datasets and benchmarks for offline safe reinforcement learning, 2023
Zuxin Liu, Zijian Guo, Haohong Lin, Yihang Yao, Jiacheng Zhu, Zhepeng Cen, Hanjiang Hu, Wenhao Yu, Tingnan Zhang, Jie Tan, and Ding Zhao. Datasets and benchmarks for offline safe reinforcement learning, 2023. URL https://arxiv.org/abs/2306.09303
-
[26]
Geng Yiran, Jiaming Ji, Yuanpei Chen, Geng Haoran, Fangwei Zhong, and Yaodong Yang. Redman: reli- able dexterous manipulation with safe reinforcement learning.Machine Learning, 114, 07 2025. doi: 10.1007/s10994-025-06825-x
-
[27]
Hasard: A benchmark for vision-based safe reinforce- ment learning in embodied agents
Tristan Tomilin, Meng Fang, and Mykola Pechenizkiy. Hasard: A benchmark for vision-based safe reinforce- ment learning in embodied agents. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[28]
Littman, and An- thony R
Leslie Pack Kaelbling, Michael L. Littman, and An- thony R. Cassandra. Planning and acting in partially observable stochastic domains.Artif. Intell., 101:99– 134, 1998. URL https://api.semanticscholar.org/CorpusID: 5613003
1998
-
[29]
Value alignment or misalignment-what will keep systems accountable? InAAAI Workshops, pages 81–88, 2017
Thomas Arnold, Daniel Kasenberg, and Matthias Scheutz. Value alignment or misalignment-what will keep systems accountable? InAAAI Workshops, pages 81–88, 2017
2017
-
[30]
T. L. Anderson.Fracture Mechanics: Fundamentals and Applications. CRC Press, Boca Raton, FL, 4 edition, 2017. ISBN 978-1-4987-2813-3. doi: 10.1201/9781315370293
-
[31]
Cam- bridge university press, 1987
Kenneth Langstreth Johnson.Contact mechanics. Cam- bridge university press, 1987
1987
-
[32]
John wiley & sons, 2020
William D Callister Jr and David G Rethwisch.Materials science and engineering: an introduction. John wiley & sons, 2020
2020
-
[33]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maxi- milian Nickel, and Matt Le. Flow matching for generative modeling, 2023. URL https://arxiv.org/abs/2210.02747
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
Steering your diffusion policy with latent space reinforcement learning,
Andrew Wagenmaker, Mitsuhiko Nakamoto, Yunchu Zhang, Seohong Park, Waleed Yagoub, Anusha Naga- bandi, Abhishek Gupta, and Sergey Levine. Steering your diffusion policy with latent space reinforcement learning,
-
[35]
URL https://arxiv.org/abs/2506.15799
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
GR00T N1: An open foundation model for generalist humanoid robots
NVIDIA, Nikita Cherniadev Johan Bjorck andFernando Casta˜neda, Xingye Da, Runyu Ding, Linxi ”Jim” Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, Joel Jang, Zhenyu Jiang, Jan Kautz, Kaushil Kundalia, Lawrence Lao, Zhiqi Li, Zongyu Lin, Kevin Lin, Guilin Liu, Edith Llontop, Loic Magne, Ajay Mandlekar, Avnish Narayan, Soroush Nasiriany, Scott Reed, Yo...
2025
-
[39]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. π0: A vision-language- action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms, 2017. URL https://arxiv.org/abs/1707.06347. APPENDIX A. CONSTRAINEDMDP FORMULATION In the main text, we formulate DAMAGESIMas a Damage- Aware POMDP to provide maximum flexibility in how health and damage signals are utilized, whether as ...
work page internal anchor Pith review Pith/arXiv arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.