Learning to Compose: Revisiting Proxy Task Design for Zero-Shot Composed Image Retrieval
Pith reviewed 2026-07-02 15:09 UTC · model grok-4.3
The pith
Zero-shot composed image retrieval improves when proxy tasks teach the model to learn composition in two stages instead of using fixed mechanisms.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
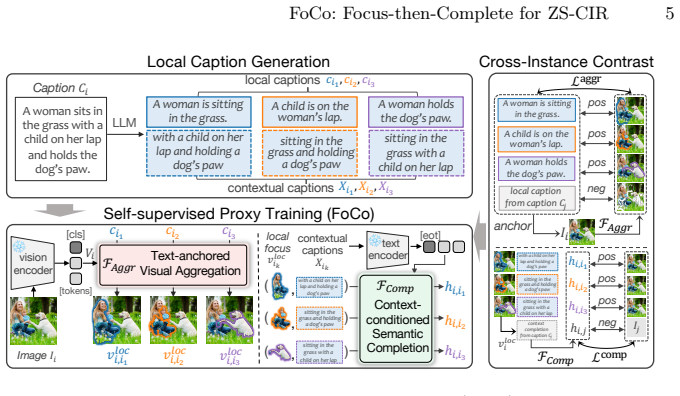
FoCo models composition as two coordinated stages: focusing on modification-relevant visual content, and then completing the target semantics. We realize these through two proxy tasks: text-anchored visual aggregation to selectively gather visual content guided by localized textual semantics, and context-conditioned semantic completion to transform these aggregated visuals with the remaining scene context into a coherent composed representation. The tasks are trained jointly with a cross-instance contrastive objective, encouraging semantic diversity and discouraging shortcut composition strategies.
What carries the argument
Two proxy tasks of text-anchored visual aggregation and context-conditioned semantic completion that coordinate to learn the composition function rather than relying on predefined mechanisms.
If this is right
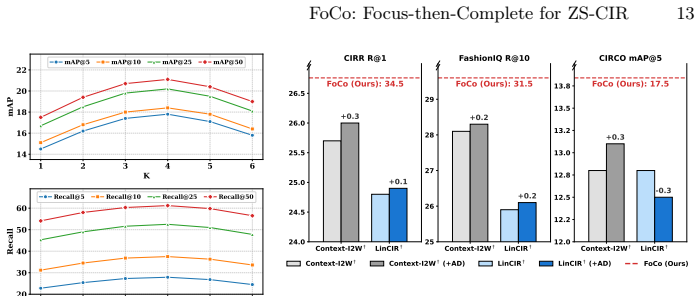
- State-of-the-art performance on four ZS-CIR benchmarks
- Better handling of diverse and fine-grained semantic modifications
- Learned composition function instead of accommodation to fixed mechanisms like pseudo-word injection or linear feature arithmetic
- Joint training with contrastive objective discourages shortcut strategies
- Improved generalization in zero-shot settings without triplet supervision
Where Pith is reading between the lines
- The two-stage separation could be tested in related tasks such as video or 3D object retrieval to see if explicit focus-then-complete stages help there too
- Integration with larger vision-language models might further boost zero-shot performance without needing new labeled data
- Examining failure cases on ambiguous real-world modifications could identify when the learned composition still falls short
- The contrastive objective's role in promoting diversity suggests similar losses might help other proxy-task designs avoid collapse
Load-bearing premise
The two proxy tasks trained jointly with the cross-instance contrastive objective will successfully learn diverse composition without shortcut strategies or overfitting.
What would settle it
Performance comparison on a test set of queries designed so that ignoring the reference image or copying text would produce wrong results, checking whether the model maintains accuracy while baselines that use shortcuts fail.
Figures


read the original abstract
Composed Image Retrieval (CIR) retrieves a target image from a reference image and a textual modification. While supervised CIR relies on costly triplets, Zero-Shot CIR (ZS-CIR) alleviates this reliance through proxy tasks trained on image-text pairs. However, existing proxy tasks primarily enhance visual and textual representations to accommodate a predefined composition mechanism such as pseudo-word injection into a frozen text encoder or linear feature arithmetic. As a result, the composition function itself remains unlearned, limiting the model's ability to express diverse and fine-grained semantic modifications. To address this, we propose FoCo, which models composition as two coordinated stages: focusing on modification-relevant visual content, and then completing the target semantics. We realize these through two proxy tasks: text-anchored visual aggregation to selectively gather visual content guided by localized textual semantics, and context-conditioned semantic completion to transform these aggregated visuals with the remaining scene context into a coherent composed representation. The tasks are trained jointly with a cross-instance contrastive objective, encouraging semantic diversity and discouraging shortcut composition strategies. Extensive experiments on four ZS-CIR benchmarks show FoCo's state-of-the-art performance and improved generalization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FoCo for zero-shot composed image retrieval, modeling composition as two coordinated stages (text-anchored visual aggregation followed by context-conditioned semantic completion) realized via proxy tasks on image-text pairs. These tasks are trained jointly under a cross-instance contrastive objective claimed to promote semantic diversity and block shortcuts, yielding state-of-the-art results on four ZS-CIR benchmarks while learning the composition function itself rather than relying on fixed mechanisms such as feature arithmetic or pseudo-word injection.
Significance. If the empirical claims hold, the work is significant for ZS-CIR because it directly targets the unlearned composition function that limits prior proxy-task methods, potentially enabling finer-grained and more diverse modifications. The two-stage design with joint contrastive training offers a concrete alternative to representation-enhancement approaches and could generalize better across modification types.
major comments (2)
- [§3] §3 (Method, cross-instance contrastive objective): The central claim that joint training under this objective 'encourages semantic diversity and discourages shortcut composition strategies' is load-bearing, yet the manuscript supplies no mechanism details (negative-sample construction, instance pairing, or loss weighting) and no ablations isolating the objective's effect on preventing degenerate solutions such as global averaging or text-dominant retrieval. Without these, the coordination between the two proxy tasks is not demonstrated.
- [§4] §4 (Experiments): The SOTA performance on four benchmarks is asserted, but the absence of variants ablating the contrastive term or the two-stage structure means it is unclear whether gains derive from the proposed coordination or from other factors such as backbone choice or training scale; this directly affects whether the two-stage model learns non-trivial composition.
minor comments (2)
- [§3] Notation for the two proxy tasks (text-anchored aggregation and context-conditioned completion) is introduced without explicit equations linking the stages to the final composed representation; adding these would clarify the pipeline.
- The abstract and introduction repeat the limitation of prior work (unlearned composition) without citing the specific proxy-task papers being critiqued; adding 2-3 key references would strengthen the positioning.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below and will incorporate the suggested improvements in the revised manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Method, cross-instance contrastive objective): The central claim that joint training under this objective 'encourages semantic diversity and discourages shortcut composition strategies' is load-bearing, yet the manuscript supplies no mechanism details (negative-sample construction, instance pairing, or loss weighting) and no ablations isolating the objective's effect on preventing degenerate solutions such as global averaging or text-dominant retrieval. Without these, the coordination between the two proxy tasks is not demonstrated.
Authors: We agree that more details on the cross-instance contrastive objective are needed to fully support the claims. The revised manuscript will include explicit descriptions of negative-sample construction, instance pairing, and loss weighting. Additionally, we will add ablations to isolate the objective's effect on semantic diversity and to rule out degenerate solutions. revision: yes
-
Referee: [§4] §4 (Experiments): The SOTA performance on four benchmarks is asserted, but the absence of variants ablating the contrastive term or the two-stage structure means it is unclear whether gains derive from the proposed coordination or from other factors such as backbone choice or training scale; this directly affects whether the two-stage model learns non-trivial composition.
Authors: We acknowledge the lack of ablations for the contrastive term and two-stage structure. In the revision, we will conduct and report these ablations to demonstrate that the performance gains stem from the coordinated two-stage design and joint training rather than other factors. revision: yes
Circularity Check
No circularity; empirical proxy-task design with external benchmarks
full rationale
The paper introduces FoCo as two new proxy tasks (text-anchored visual aggregation and context-conditioned semantic completion) trained jointly under a cross-instance contrastive loss. No equations, uniqueness theorems, or self-citations are presented that reduce the claimed composition function to a fitted parameter or prior result by construction. Performance is asserted via SOTA numbers on four external ZS-CIR benchmarks, making the central claim falsifiable outside the training procedure itself. This is the normal non-circular case for an empirical architecture paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: The Twelfth Interna- tional Conference on Learning Representations (2024)
Bai, Y., Xu, X., Liu, Y., Khan, S., Khan, F., Zuo, W., Goh, R.S.M., Feng, C.M.: Sentence-level prompts benefit composed image retrieval. In: The Twelfth Interna- tional Conference on Learning Representations (2024)
2024
-
[2]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Baldrati, A., Agnolucci, L., Bertini, M., Del Bimbo, A.: Zero-shot composed image retrieval with textual inversion. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 15338–15347 (2023)
2023
-
[3]
In: 2025 IEEE International Conference on Multimedia and Expo (ICME)
Chen, J., Lai, H.: Pretrain like your inference: Masked tuning improves zero-shot composed image retrieval. In: 2025 IEEE International Conference on Multimedia and Expo (ICME). pp. 1–6. IEEE (2025)
2025
-
[4]
Artemis: Attention-based retrieval with text-explicit matching and implicit similar- ity,
Delmas, G., de Rezende, R.S., Csurka, G., Larlus, D.: Artemis: Attention- based retrieval with text-explicit matching and implicit similarity. arXiv preprint arXiv:2203.08101 (2022)
-
[5]
Modality- agnostic attention fusion for visual search with text feedback,
Dodds, E., Culpepper, J., Herdade, S., Zhang, Y., Boakye, K.: Modality- agnostic attention fusion for visual search with text feedback. arXiv preprint arXiv:2007.00145 (2020)
-
[6]
In: Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing
Fu,Z.,Li,Z.,Chen,Z.,Wang,C.,Song,X.,Hu,Y.,Nie,L.:Pair:Complementarity- guided disentanglement for composed image retrieval. In: Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing. pp. 1–5. IEEE (2025)
2025
-
[7]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Let- man, A., Mathur, A., Schelten, A., Vaughan, A., et al.: The llama 3 herd of models. arXiv preprint arXiv:2407.21783 (2024) 16 J. Zhang et al
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Gu, G., Chun, S., Kim, W., Kang, Y., Yun, S.: Language-only training of zero- shot composed image retrieval. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13225–13234 (2024)
2024
-
[9]
arXiv preprint arXiv:2410.09733 (2024) 8
Hua, H., Tang, Y., Zeng, Z., Cao, L., Yang, Z., He, H., Xu, C., Luo, J.: Mmcompo- sition: Revisiting the compositionality of pre-trained vision-language models. arXiv preprint arXiv:2410.09733 (2024)
-
[10]
Zenodo (Jul 2021), version 0.1
Ilharco, G., Wortsman, M., Wightman, R., Gordon, C., Carlini, N., Taori, R., Dave, A., Shankar, V., Namkoong, H., Miller, J., Hajishirzi, H., Farhadi, A., Schmidt, L.: Openclip. Zenodo (Jul 2021), version 0.1
2021
-
[11]
In: European Conference on Computer Vision
Jang, Y.K., Huynh, D., Shah, A., Chen, W.K., Lim, S.N.: Spherical linear inter- polation and text-anchoring for zero-shot composed image retrieval. In: European Conference on Computer Vision. pp. 239–254. Springer (2024)
2024
-
[12]
Advances in Neural Information Processing Systems (2024)
Jing, D., He, X., Luo, Y., Fei, N., Yang, G., Wei, W., Zhao, H., Lu, Z.: Fineclip: Self-distilled region-based clip for better fine-grained understanding. Advances in Neural Information Processing Systems (2024)
2024
-
[13]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Lee, S., Kim, D., Han, B.: Cosmo: Content-style modulation for image retrieval with text feedback. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 802–812 (2021)
2021
-
[14]
In: International confer- ence on machine learning
Li, J., Li, D., Xiong, C., Hoi, S.: Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In: International confer- ence on machine learning. pp. 12888–12900. PMLR (2022)
2022
-
[15]
arXiv preprint arXiv:2505.19406 (2025)
Li, T., Zhang, J., Rao, Y., Cheng, Y.: Unveiling the compositional ability gap in vision-language reasoning model. arXiv preprint arXiv:2505.19406 (2025)
-
[16]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Li, Z., Zhang, L., Fu, Z., Zhang, K., Mao, Z.: Hierarchy-aware pseudo word learning with text adaptation for zero-shot composed image retrieval. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 24319–24329 (2025)
2025
-
[17]
In: Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval
Li, Z., Zhang, L., Zhang, K., Chen, W., Zhang, Y., Mao, Z.: Rethinking pseudo word learning in zero-shot composed image retrieval: From an object-aware per- spective. In: Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. pp. 833–843 (2025)
2025
-
[18]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Li, Z., Chen, Z., Wen, H., Fu, Z., Hu, Y., Guan, W.: Encoder: Entity mining and modification relation binding for composed image retrieval. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 5101–5109 (2025)
2025
-
[19]
In: Proceedings of the IEEE/CVF international conference on computer vision
Liu, Z., Rodriguez-Opazo, C., Teney, D., Gould, S.: Image retrieval on real- life images with pre-trained vision-and-language models. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 2125–2134 (2021)
2021
-
[20]
Trends in cogni- tive sciences11(12), 520–527 (2007)
Oliva, A., Torralba, A.: The role of context in object recognition. Trends in cogni- tive sciences11(12), 520–527 (2007)
2007
-
[21]
arXiv preprint arXiv:2401.11337 (2024)
Ossowski, T., Jiang, M., Hu, J.: Prompting large vision-language models for com- positional reasoning. arXiv preprint arXiv:2401.11337 (2024)
-
[22]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021)
2021
-
[23]
In: ProceedingsoftheIEEE/CVFConferenceonComputerVisionandPatternRecog- nition
Saito, K., Sohn, K., Zhang, X., Li, C.L., Lee, C.Y., Saenko, K., Pfister, T.: Pic2word: Mapping pictures to words for zero-shot composed image retrieval. In: ProceedingsoftheIEEE/CVFConferenceonComputerVisionandPatternRecog- nition. pp. 19305–19314 (2023)
2023
-
[24]
In: Proceed- FoCo: Focus-then-Complete for ZS-CIR 17 ings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Sharma, P., Ding, N., Goodman, S., Soricut, R.: Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. In: Proceed- FoCo: Focus-then-Complete for ZS-CIR 17 ings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 2556–2565 (2018)
2018
-
[25]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Sun, Z., Jing, D., Yang, G., Fei, N., Lu, Z.: Leveraging large vision-language model as user intent-aware encoder for composed image retrieval. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 7149–7157 (2025)
2025
-
[26]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Tang, Y., Yu, J., Gai, K., Zhuang, J., Xiong, G., Gou, G., Wu, Q.: Missing target- relevant information prediction with world model for accurate zero-shot composed image retrieval. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 24785–24795 (2025)
2025
-
[27]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Tang, Y., Yu, J., Gai, K., Zhuang, J., Xiong, G., Hu, Y., Wu, Q.: Context-i2w: Mapping images to context-dependent words for accurate zero-shot composed im- age retrieval. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 38, pp. 5180–5188 (2024)
2024
-
[28]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Tian, L., Zhao, J., Hu, Z., Yang, Z., Li, H., Jin, L., Wang, Z., Li, X.: Ccin: Com- positional conflict identification and neutralization for composed image retrieval. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 3974–3983 (2025)
2025
-
[29]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Vaze, S., Carion, N., Misra, I.: Genecis: A benchmark for general conditional image similarity. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 6862–6872 (2023)
2023
-
[30]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Vo, N., Jiang, L., Sun, C., Murphy, K., Li, L.J., Fei-Fei, L., Hays, J.: Composing text and image for image retrieval-an empirical odyssey. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 6439–6448 (2019)
2019
-
[31]
arXiv preprint arXiv:2504.10995 (2025)
Wang, C., Zhang, Z., Teng, L., Li, Z., Kan, S.: Tmcir: Token merge benefits com- posed image retrieval. arXiv preprint arXiv:2504.10995 (2025)
-
[32]
Wen, H., Zhang, X., Song, X., Wei, Y., Nie, L.: Target-guided composed image retrieval.In:Proceedingsofthe31stACMInternationalConferenceonMultimedia. pp. 915–923 (2023)
2023
-
[33]
In: Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition
Wu, H., Gao, Y., Guo, X., Al-Halah, Z., Rennie, S., Grauman, K., Feris, R.: Fash- ion iq: A new dataset towards retrieving images by natural language feedback. In: Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition. pp. 11307–11317 (2021)
2021
-
[34]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Yang, X., Liu, D., Zhang, H., Luo, Y., Wang, C., Zhang, J.: Decomposing semantic shifts for composed image retrieval. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 38, pp. 6576–6584 (2024)
2024
-
[35]
arXiv preprint arXiv:2505.17796 (2025)
Yang, Y., Zhou, Y., Chen, Y., Zhang, Z., Ma, Z., Yuan, C., Li, B., Song, L., Gao, J., Li, P., et al.: Detailfusion: A dual-branch framework with detail enhancement for composed image retrieval. arXiv preprint arXiv:2505.17796 (2025)
-
[36]
In: Proceedings of the IEEE/CVF international conference on computer vision
Zhai, X., Mustafa, B., Kolesnikov, A., Beyer, L.: Sigmoid loss for language im- age pre-training. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 11975–11986 (2023)
2023
-
[37]
In: 2024 IEEE International Conference on Image Processing (ICIP)
Zhang, H., Yanagi, R., Togo, R., Ogawa, T., Haseyama, M.: Zero-shot composed image retrieval considering query-target relationship leveraging masked image-text pairs. In: 2024 IEEE International Conference on Image Processing (ICIP). pp. 2431–2437. IEEE (2024)
2024
-
[38]
In: ECCV (2024)
Zheng, K., Zhang, Y., Wu, W., Lu, F., Ma, S., Jin, X., Chen, W., Shen, Y.: Dream- lip: Language-image pre-training with long captions. In: ECCV (2024)
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.