Bridge-WA: Predicting Where and How the World Changes for Robotic Action
Pith reviewed 2026-07-03 11:26 UTC · model grok-4.3
The pith
Bridge-WA distills scene-change predictions into compact priors that condition robotic actions and improve generalization without running a full generative world model at deployment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
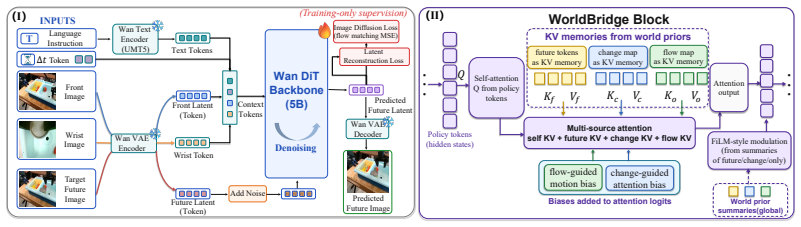
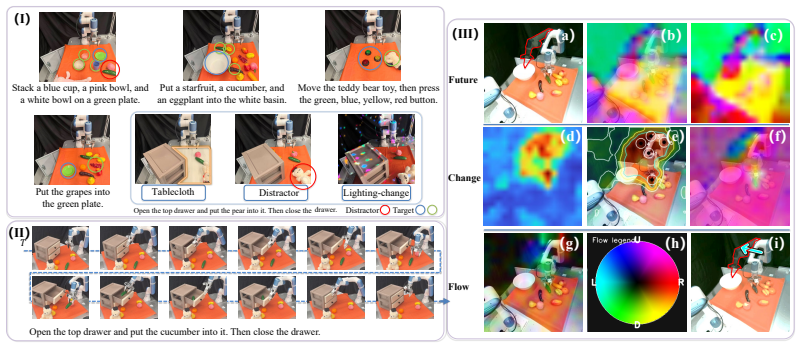
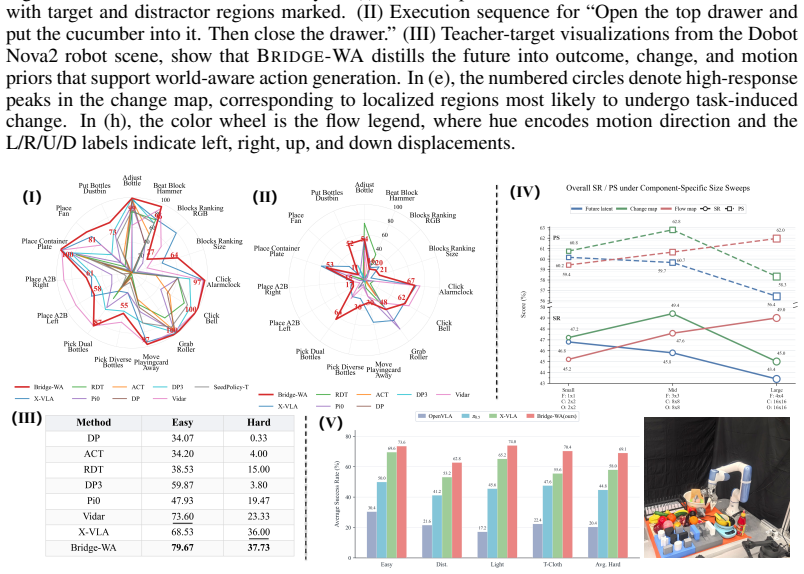
Bridge-WA distills a frozen future-change teacher into three compact priors—future tokens for intended outcomes, change maps for intervention support, and motion-flow maps for local transition direction—then conditions an action transformer on these priors through multi-source attention memories and spatial-temporal biases inside the WorldBridge module, allowing the teacher to be removed at inference while raising task success, progress, and robustness across VLABench, RoboTwin2.0, LIBERO-Plus, and real-robot tests, especially under out-of-distribution visual shifts.
What carries the argument
The WorldBridge module, which transfers the three distilled change priors to the action transformer using multi-source attention memories and spatial-temporal biases.
If this is right
- Task success and progress increase on the listed simulation and real-robot benchmarks.
- Robustness improves under shifts in background, lighting, and distractors.
- Deployment no longer requires running dense future-image generation.
- Nuisance appearance factors are suppressed because attention is directed to change locations and directions.
Where Pith is reading between the lines
- The same change priors could be attached to other action architectures beyond the tested transformer.
- The method may reduce memory and compute needs enough for onboard robot deployment.
- Extending the priors to longer time horizons could be tested by measuring performance drop on multi-step tasks.
Load-bearing premise
The three distilled priors plus the attention memories are enough to carry all action-relevant information from the teacher without meaningful loss.
What would settle it
An evaluation on a manipulation task with strong visual distractors where the Bridge-WA policy achieves lower success than a baseline that keeps the full future-image teacher active at inference.
Figures

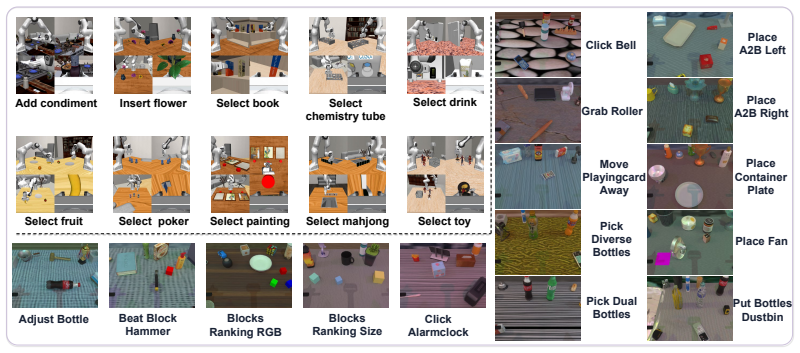

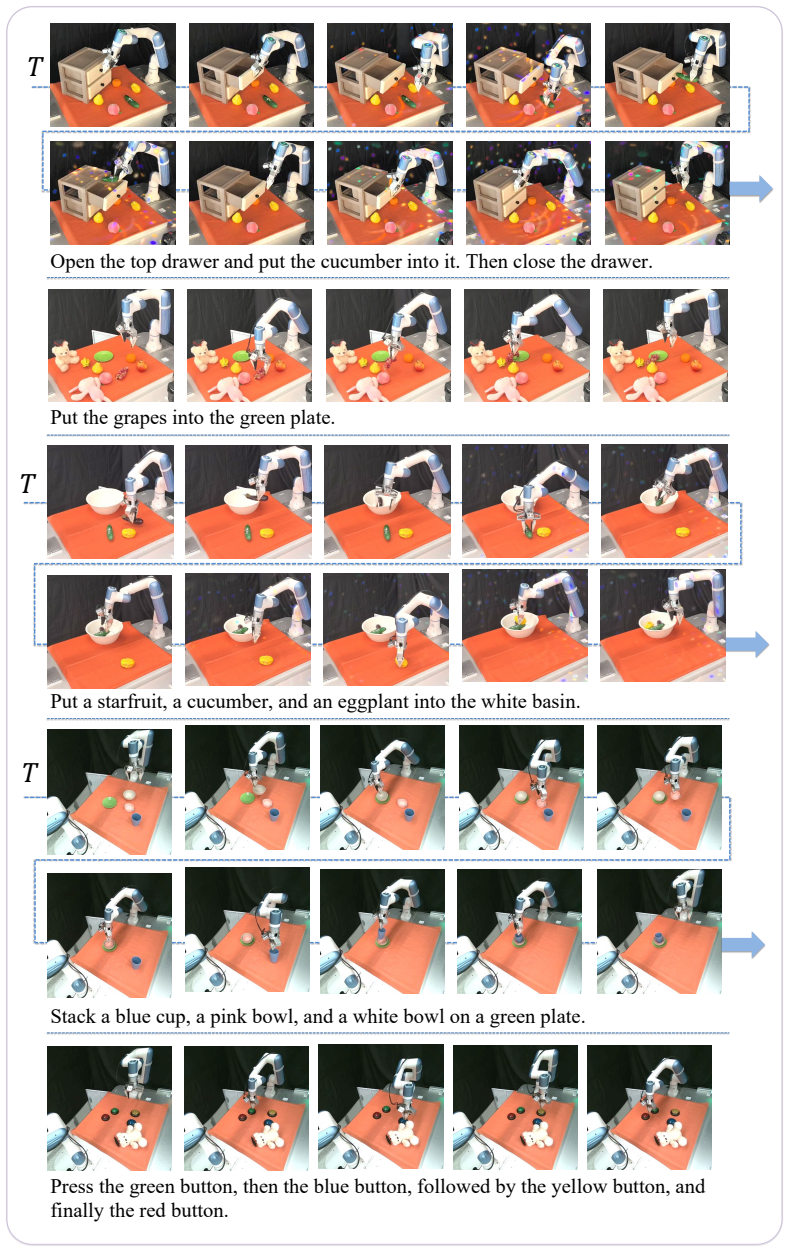
read the original abstract
General-purpose vision-language-action models benefit from large vision-language priors, but effective manipulation also requires anticipating action-relevant scene changes. Existing world-action models often rely on large generative world models or dense future rollouts, which are expensive and spend capacity on visual details weakly coupled to control. We present Bridge-WA, a lightweight world-action framework that distills a frozen future-change teacher into three compact priors: future tokens for intended outcomes, change maps for intervention support, and motion-flow maps for local transition direction. A WorldBridge conditions the action transformer on these priors through multi-source attention memories and spatial-temporal biases, while the teacher model is removed at inference. Across VLABench, RoboTwin2.0, LIBERO-Plus and real-robot evaluations, Bridge-WA improves task success, progress, and robustness, with particularly clear gains under out-of-distribution visual shifts. By focusing action generation on where and how the scene will change, Bridge-WA suppresses nuisance appearance factors such as background, lighting, and distractors, leading to better generalization without deployment-time dense future-image generation. Code and visualizations are available at: https://hcplab-sysu.github.io/BRIDGE-WA .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Bridge-WA, a lightweight world-action framework for vision-language-action models that distills a frozen future-change teacher into three compact priors (future tokens for intended outcomes, change maps for intervention support, and motion-flow maps for local transition direction). A WorldBridge module conditions the action transformer on these priors via multi-source attention memories and spatial-temporal biases, with the teacher removed at inference. The central claim is that focusing on where and how the scene changes suppresses nuisance factors (background, lighting, distractors) and yields better generalization and robustness on VLABench, RoboTwin2.0, LIBERO-Plus, and real-robot tasks without requiring deployment-time dense future-image generation.
Significance. If the empirical gains and lack of performance penalty hold, the work would be significant for efficient VLA robotics by replacing expensive generative world models with targeted change priors, potentially improving OOD robustness while lowering inference cost. The explicit distillation of change-focused signals and removal of the teacher at test time are concrete engineering contributions that could influence subsequent world-action architectures.
major comments (2)
- [Method section (distillation and conditioning)] Method (distillation and WorldBridge conditioning): The claim that the three distilled priors plus multi-source attention memories transfer all action-relevant teacher knowledge without significant loss is load-bearing for both the generalization benefit and the 'no performance penalty' assertion. The manuscript should provide ablations that isolate each prior (future tokens, change maps, motion-flow maps) and quantify any drop in task success or progress relative to the full teacher, particularly for multi-step dependencies and contact dynamics.
- [Experiments section (evaluation tables)] Experiments (evaluation tables): The abstract and results claim clear gains under visual shifts, but the central claim of effective nuisance suppression rests on the priors capturing semantically relevant intervention effects. Tables reporting task success, progress, and robustness should include per-component ablations and direct comparisons against the frozen teacher to confirm no critical signal is lost in distillation.
minor comments (1)
- [Abstract] The abstract states improvements across four benchmarks but does not report specific quantitative deltas, baseline names, or ablation details; these should be summarized with numbers in the abstract for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Method section (distillation and conditioning)] Method (distillation and WorldBridge conditioning): The claim that the three distilled priors plus multi-source attention memories transfer all action-relevant teacher knowledge without significant loss is load-bearing for both the generalization benefit and the 'no performance penalty' assertion. The manuscript should provide ablations that isolate each prior (future tokens, change maps, motion-flow maps) and quantify any drop in task success or progress relative to the full teacher, particularly for multi-step dependencies and contact dynamics.
Authors: We agree that component-wise ablations are needed to substantiate the distillation claim. The current manuscript reports overall gains from the full set of priors but does not isolate each prior or provide direct per-task comparisons to the frozen teacher on multi-step or contact-rich scenarios. In the revised version we will add these ablations, reporting task success and progress metrics for each prior in isolation and in combination against the teacher. revision: yes
-
Referee: [Experiments section (evaluation tables)] Experiments (evaluation tables): The abstract and results claim clear gains under visual shifts, but the central claim of effective nuisance suppression rests on the priors capturing semantically relevant intervention effects. Tables reporting task success, progress, and robustness should include per-component ablations and direct comparisons against the frozen teacher to confirm no critical signal is lost in distillation.
Authors: We concur that the evaluation tables should be expanded to include per-component ablations and explicit teacher comparisons. While the existing results demonstrate improved robustness without the teacher at inference, the tables do not currently break down contributions per prior or show direct teacher baselines on the reported metrics. We will update the tables in the revision to incorporate these analyses across VLABench, RoboTwin2.0, LIBERO-Plus, and real-robot tasks. revision: yes
Circularity Check
No circularity; empirical distillation framework with independent evaluation claims
full rationale
The paper describes an engineering framework that distills a frozen teacher into three priors (future tokens, change maps, motion-flow maps) and conditions an action transformer via WorldBridge. No equations, fitted parameters, or self-citations are presented in the provided text that reduce any claimed prediction or uniqueness result to the inputs by construction. The central assertion—that the priors capture action-relevant information while suppressing nuisance factors—is framed as an empirical hypothesis tested on VLABench, RoboTwin2.0, LIBERO-Plus and real-robot tasks, not as a self-definitional or self-citation-dependent derivation. This is a standard non-circular empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
M. Ahn, A. Brohan, N. Brown, Y . Chebotar, O. Cortes, B. David, C. Finn, C. Fu, K. Gopalakr- ishnan, K. Hausman, et al. Do as i can, not as i say: Grounding language in robotic affordances. arXiv preprint arXiv:2204.01691, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
Huang, F
W. Huang, F. Xia, T. Xiao, H. Chan, J. Liang, P. Florence, A. Zeng, J. Tompson, I. Mordatch, Y . Chebotar, et al. Inner monologue: Embodied reasoning through planning with language models. InConference on Robot Learning, pages 1769–1782. PMLR, 2023
2023
-
[3]
Liang, W
J. Liang, W. Huang, F. Xia, P. Xu, K. Hausman, B. Ichter, P. Florence, and A. Zeng. Code as policies: Language model programs for embodied control. In2023 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2023
2023
-
[4]
Driess, F
D. Driess, F. Xia, M. S. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, A. Wahid, J. Tompson, Q. Vuong, T. Yu, et al. Palm-e: an embodied multimodal language model. InProceedings of the 40th International Conference on Machine Learning, pages 8469–8488, 2023
2023
-
[5]
S. Reed, K. Zolna, E. Parisotto, S. G. Colmenarejo, A. Novikov, G. Barth-maron, M. Gim´enez, Y . Sulsky, J. Kay, J. T. Springenberg, et al. A generalist agent.Transactions on Machine Learning Research
-
[6]
Brohan, N
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Haus- man, A. Herzog, J. Hsu, et al. Rt-1: Robotics transformer for real-world control at scale. Robotics: Science and Systems XIX, 2023
2023
-
[7]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. In Conference on Robot Learning, pages 2165–2183. PMLR, 2023
2023
-
[8]
O’Neill, A
A. O’Neill, A. Rehman, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jain, et al. Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6892–6903. IEEE, 2024
2024
-
[9]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. P. Foster, P. R. Sanketi, Q. Vuong, et al. Openvla: An open-source vision-language-action model. In8th Annual Conference on Robot Learning
-
[10]
O. M. Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, T. Kreiman, C. Xu, et al. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al. Pi0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Florence, C
P. Florence, C. Lynch, A. Zeng, O. A. Ramirez, A. Wahid, L. Downs, A. Wong, J. Lee, I. Mor- datch, and J. Tompson. Implicit behavioral cloning. InConference on robot learning, pages 158–168. PMLR, 2022
2022
-
[13]
N. M. Shafiullah, Z. Cui, A. A. Altanzaya, and L. Pinto. Behavior transformers: Cloningk modes with one stone.Advances in neural information processing systems, 35:22955–22968, 2022
2022
-
[14]
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn. Learning fine-grained bimanual manipulation with low-cost hardware.arXiv preprint arXiv:2304.13705, 2023. 10
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[16]
D. Ha and J. Schmidhuber. World models.arXiv preprint arXiv:1803.10122, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[17]
Hafner, T
D. Hafner, T. Lillicrap, I. Fischer, R. Villegas, D. Ha, H. Lee, and J. Davidson. Learning latent dynamics for planning from pixels. InInternational conference on machine learning, pages 2555–2565. PMLR, 2019
2019
-
[18]
Hafner, T
D. Hafner, T. Lillicrap, J. Ba, and M. Norouzi. Dream to control: Learning behaviors by latent imagination. InInternational Conference on Learning Representations, 2020
2020
-
[19]
Mastering Diverse Domains through World Models
D. Hafner, J. Pasukonis, J. Ba, and T. Lillicrap. Mastering diverse domains through world models.arXiv preprint arXiv:2301.04104, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Schrittwieser, I
J. Schrittwieser, I. Antonoglou, T. Hubert, K. Simonyan, L. Sifre, S. Schmitt, A. Guez, E. Lock- hart, D. Hassabis, T. Graepel, et al. Mastering atari, go, chess and shogi by planning with a learned model.Nature, 588(7839):604–609, 2020
2020
-
[21]
Finn and S
C. Finn and S. Levine. Deep visual foresight for planning robot motion. In2017 IEEE inter- national conference on robotics and automation (ICRA), pages 2786–2793. IEEE, 2017
2017
-
[22]
Visual Foresight: Model-Based Deep Reinforcement Learning for Vision-Based Robotic Control
F. Ebert, C. Finn, S. Dasari, A. Xie, A. Lee, and S. Levine. Visual foresight: Model-based deep reinforcement learning for vision-based robotic control.arXiv preprint arXiv:1812.00568, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[23]
M. Babaeizadeh, M. T. Saffar, S. Nair, S. Levine, C. Finn, and D. Erhan. Fitvid: Overfitting in pixel-level video prediction.arXiv preprint arXiv:2106.13195, 2021
-
[24]
Y . Du, S. Yang, B. Dai, H. Dai, O. Nachum, J. Tenenbaum, D. Schuurmans, and P. Abbeel. Learning universal policies via text-guided video generation.Advances in neural information processing systems, 36:9156–9172, 2023
2023
-
[25]
S. Zhou, Y . Du, J. Chen, Y . Li, D.-Y . Yeung, and C. Gan. Robodreamer: Learning composi- tional world models for robot imagination. InInternational Conference on Machine Learning, pages 61885–61896. PMLR, 2024
2024
-
[26]
B. Hou, G. Li, J. Jia, T. An, X. Guo, S. Leng, H. Geng, Y . Ze, T. Harada, P. Torr, et al. World model for robot learning: A comprehensive survey.arXiv preprint arXiv:2605.00080, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[27]
S. Wang, J. Shi, Z. Fu, X. He, F. Liu, C. Yang, Y . Zhou, Z. Fei, J. Gong, J. Fu, et al. World action models: The next frontier in embodied ai.arXiv preprint arXiv:2605.12090, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
H. Luo, W. Zhang, Y . Feng, S. Zheng, H. Xu, C. Xu, Z. Xi, Y . Fu, and Z. Lu. Being-h0. 7: A latent world-action model from egocentric videos.arXiv preprint arXiv:2605.00078, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
Y . Liu, P. Sun, S. Li, Y . Xie, L. Zhang, X. Chao, S. Dong, F. Chen, X.-P. Zhang, and W. Ding. Oa-wam: Object-addressable world action model for robust robot manipulation.arXiv preprint arXiv:2605.06481, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[30]
S. Nair, A. Rajeswaran, V . Kumar, C. Finn, and A. Gupta. R3m: A universal visual repre- sentation for robot manipulation. InConference on Robot Learning, pages 892–909. PMLR, 2023
2023
-
[31]
Y . J. Ma, S. Sodhani, D. Jayaraman, O. Bastani, V . Kumar, and A. Zhang. Vip: Towards universal visual reward and representation via value-implicit pre-training. InThe Eleventh International Conference on Learning Representations, 2023. 11
2023
-
[32]
Karamcheti, S
S. Karamcheti, S. Nair, A. S. Chen, T. Kollar, C. Finn, D. Sadigh, and P. Liang. Language- driven representation learning for robotics.Robotics: Science and Systems, 2023
2023
-
[33]
Hendrycks and T
D. Hendrycks and T. Dietterich. Benchmarking neural network robustness to common corrup- tions and perturbations. InInternational Conference on Learning Representations, 2019
2019
-
[34]
Hendrycks, S
D. Hendrycks, S. Basart, N. Mu, S. Kadavath, F. Wang, E. Dorundo, R. Desai, T. Zhu, S. Para- juli, M. Guo, et al. The many faces of robustness: A critical analysis of out-of-distribution generalization. In2021 IEEE/CVF International Conference on Computer Vision (ICCV), pages 8320–8329. IEEE, 2021
2021
-
[35]
Zheng, J
J. Zheng, J. Li, Z. Wang, D. Liu, X. Kang, Y . Feng, Y . Zheng, J. Zou, Y . Chen, J. Zeng, et al. X- vla: Soft-prompted transformer as scalable cross-embodiment vision-language-action model. International Conference on Learning Representation, 2026
2026
-
[36]
E. Jang, A. Irpan, M. Khansari, D. Kappler, F. Ebert, C. Lynch, S. Levine, and C. Finn. Bc-z: Zero-shot task generalization with robotic imitation learning. In5th Annual Conference on Robot Learning
-
[37]
Jiang, A
Y . Jiang, A. Gupta, Z. Zhang, G. Wang, Y . Dou, Y . Chen, L. Fei-Fei, A. Anandkumar, Y . Zhu, and L. Fan. Vima: Robot manipulation with multimodal prompts. InInternational Conference on Machine Learning, pages 14975–15022. PMLR, 2023
2023
-
[38]
Bousmalis, G
K. Bousmalis, G. Vezzani, D. Rao, C. M. Devin, A. X. Lee, M. B. Villalonga, T. Davchev, Y . Zhou, A. Gupta, A. Raju, et al. Robocat: A self-improving generalist agent for robotic manipulation.Transactions on Machine Learning Research
-
[39]
Black, N
K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. R. Equi, C. Finn, N. Fusai, M. Y . Galliker, et al. Pi0.5: a vision-language-action model with open-world gener- alization. In9th Annual Conference on Robot Learning
-
[40]
H. Wu, Y . Jing, C. Cheang, G. Chen, J. Xu, X. Li, M. Liu, H. Li, and T. Kong. Unleashing large- scale video generative pre-training for visual robot manipulation. InInternational Conference on Learning Representations, volume 2024, pages 10641–10662, 2024
2024
-
[41]
K. Zhou, Y . Chen, F. Zhan, H. Hua, G. Chen, X. Chang, A. Qu, Y . Du, Z. Liu, P. P. Liang, and M. Wang. Gem-4d: Geometry-enhanced video world models for robot manipulation.arXiv preprint arXiv:2605.22882, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[42]
A. Zeng, P. Florence, J. Tompson, S. Welker, J. Chien, M. Attarian, T. Armstrong, I. Krasin, D. Duong, V . Sindhwani, et al. Transporter networks: Rearranging the visual world for robotic manipulation. InConference on Robot Learning, pages 726–747. PMLR, 2021
2021
-
[43]
Shridhar, L
M. Shridhar, L. Manuelli, and D. Fox. Cliport: What and where pathways for robotic manipu- lation. InConference on robot learning, pages 894–906. PMLR, 2022
2022
-
[44]
K. Mo, L. J. Guibas, M. Mukadam, A. Gupta, and S. Tulsiani. Where2act: From pixels to actions for articulated 3d objects. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 6813–6823, 2021
2021
-
[45]
Shridhar, L
M. Shridhar, L. Manuelli, and D. Fox. Perceiver-actor: A multi-task transformer for robotic manipulation. InConference on Robot Learning, pages 785–799. PMLR, 2023
2023
-
[46]
Goyal, J
A. Goyal, J. Xu, Y . Guo, V . Blukis, Y .-W. Chao, and D. Fox. Rvt: Robotic view transformer for 3d object manipulation. InConference on Robot Learning, pages 694–710. PMLR, 2023
2023
-
[47]
Gervet, Z
T. Gervet, Z. Xian, N. Gkanatsios, and K. Fragkiadaki. Act3d: 3d feature field transformers for multi-task robotic manipulation. In J. Tan, M. Toussaint, and K. Darvish, editors,Proceedings of The 7th Conference on Robot Learning, volume 229 ofProceedings of Machine Learning Research, pages 3949–3965. PMLR, 06–09 Nov 2023. URLhttps://proceedings.mlr. pres...
2023
-
[48]
Huang, C
W. Huang, C. Wang, R. Zhang, Y . Li, J. Wu, and L. Fei-Fei. V oxposer: Composable 3d value maps for robotic manipulation with language models. InConference on Robot Learning, pages 540–562. PMLR, 2023
2023
-
[49]
H. Zhang, M. Xu, A. Dhafer, S. Yue, H. Dong, and Z. D. Hao. Embodied interpretability: Link- ing causal understanding to generalization in vision-language-action models.arXiv preprint arXiv:2605.00321, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[50]
H. R. Walke, K. Black, T. Z. Zhao, Q. Vuong, C. Zheng, P. Hansen-Estruch, A. W. He, V . My- ers, M. J. Kim, M. Du, et al. Bridgedata v2: A dataset for robot learning at scale. In7th Annual Conference on Robot Learning
- [51]
-
[52]
T. Chen, Z. Chen, B. Chen, Z. Cai, Y . Liu, Z. Li, Q. Liang, X. Lin, Y . Ge, Z. Gu, et al. Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation.arXiv preprint arXiv:2506.18088, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
S. Fei, S. Wang, J. Shi, Z. Dai, J. Cai, P. Qian, L. Ji, X. He, S. Zhang, Z. Fei, et al. Libero-plus: In-depth robustness analysis of vision-language-action models.arXiv preprint arXiv:2510.13626, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[54]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. Libero: Benchmarking knowl- edge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
2023
-
[55]
FAST: Efficient Action Tokenization for Vision-Language-Action Models
K. Pertsch, K. Stachowicz, B. Ichter, D. Driess, S. Nair, Q. Vuong, O. Mees, C. Finn, and S. Levine. Fast: Efficient action tokenization for vision-language-action models.arXiv preprint arXiv:2501.09747, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
Zhong, Y
L. Zhong, Y . Liu, Y . Wei, Z. Xiong, M. Yao, S. Liu, and G. Ren. Acot-vla: Action chain-of- thought for vision-language-action models.The IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2026
2026
-
[57]
J. Cen, C. Yu, H. Yuan, Y . Jiang, S. Huang, J. Guo, X. Li, Y . Song, H. Luo, F. Wang, et al. Worldvla: Towards autoregressive action world model.arXiv preprint arXiv:2506.21539, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[58]
C.-Y . Hung, Q. Sun, P. Hong, A. Zadeh, C. Li, U. Tan, N. Majumder, S. Poria, et al. Nora: A small open-sourced generalist vision language action model for embodied tasks.arXiv preprint arXiv:2504.19854, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[59]
Q. Bu, Y . Yang, J. Cai, S. Gao, G. Ren, M. Yao, P. Luo, and H. Li. Univla: Learning to act anywhere with task-centric latent actions.arXiv preprint arXiv:2505.06111, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[60]
T. Yuan, Z. Dong, Y . Liu, and H. Zhao. Fast-wam: Do world action models need test-time future imagination?arXiv preprint arXiv:2603.16666, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[61]
S. Tan, K. Dou, Y . Zhao, and P. Kraehenbuehl. Interactive post-training for vision-language- action models. InWorkshop on Foundation Models Meet Embodied Agents at CVPR 2025
2025
-
[62]
M. J. Kim, C. Finn, and P. Liang. Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[63]
Y . Ze, G. Zhang, K. Zhang, C. Hu, M. Wang, and H. Xu. 3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations.Robotics: Science and Systems, 2024. 13
2024
-
[64]
S. Liu, L. Wu, B. Li, H. Tan, H. Chen, Z. Wang, K. Xu, H. Su, and J. Zhu. Rdt-1b: a diffu- sion foundation model for bimanual manipulation. InInternational Conference on Learning Representations, volume 2025, pages 29982–30009, 2025
2025
-
[65]
Y . Feng, H. Tan, X. Mao, C. Xiang, G. Liu, S. Huang, H. Su, and J. Zhu. Vidar: Embodied video diffusion model for generalist manipulation.arXiv preprint arXiv:2507.12898, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[66]
Y . Gui, Y . Zhou, S. Cheng, X. Yuan, H. Fan, P. Cheng, and S. Liu. Seedpolicy: Horizon scaling via self-evolving diffusion policy for robot manipulation.arXiv preprint arXiv:2603.05117, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[67]
J. Sun, W. Zhang, Z. Qi, S. Ren, Z. Liu, H. Zhu, G. Sun, X. Jin, and Z. Chen. Vla-jepa: Enhanc- ing vision-language-action model with latent world model.arXiv preprint arXiv:2602.10098, 2026. 14 Appendix A Real-Robot Experimental Setup, Task Definitions, and Evaluation Protocol Side Camera Front Side Camera Wrist Camera Left Arm Right Arm Fig5 D405 D435i ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.