HERMES: A Multi-Granularity Labeling Substrate for Pre-training Data Mixtures
Pith reviewed 2026-07-03 16:42 UTC · model grok-4.3
The pith
A data-derived hierarchy of labels allows testing mixing rules at different granularities, showing gains at one level that disappear at finer resolutions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
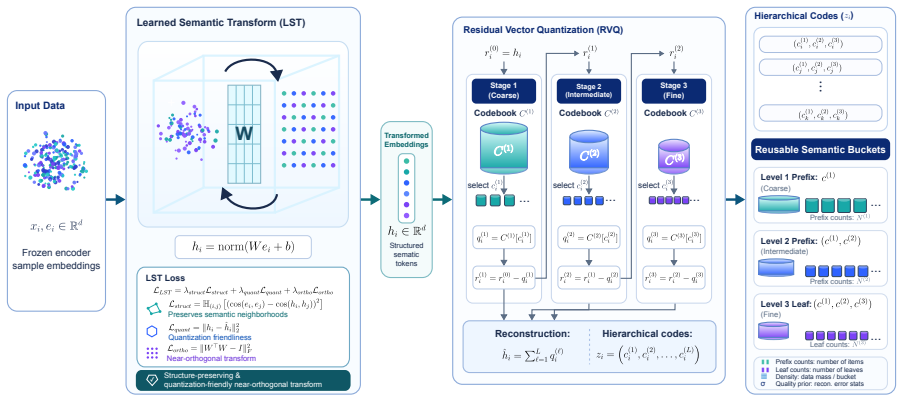
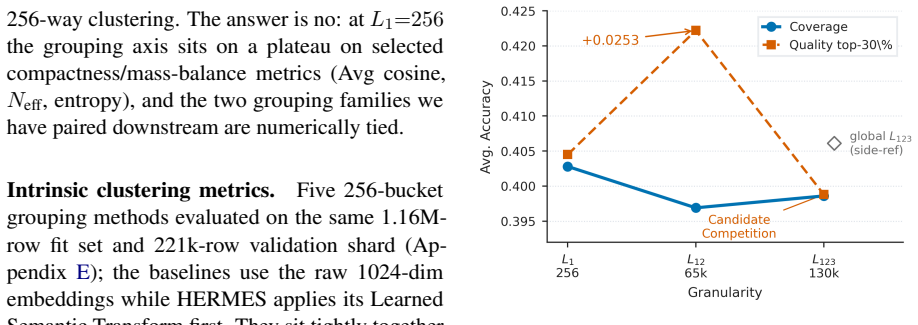
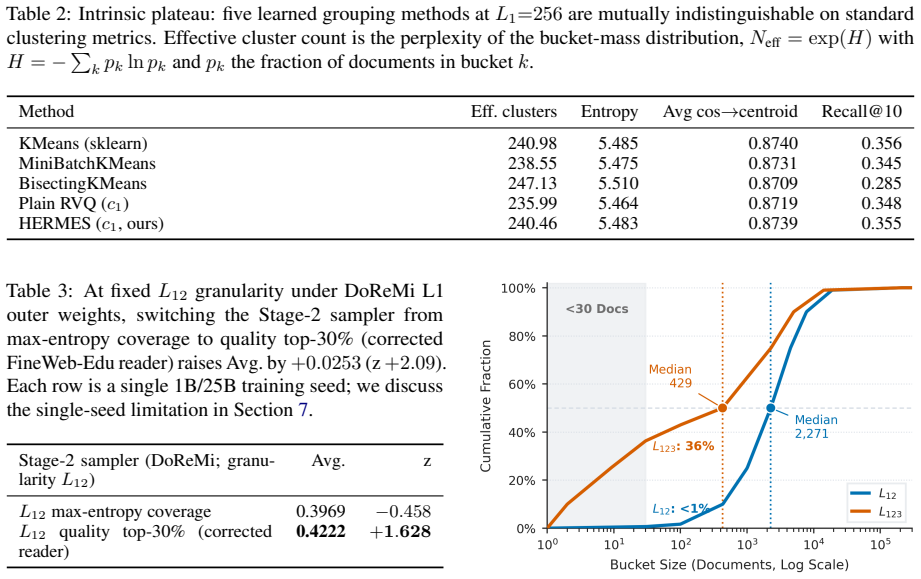
HERMES is a data-derived labeling substrate: a Learned Semantic Transform followed by 3-stage residual vector quantization annotates each document once into a coarse-to-fine code whose prefix length controls granularity up to approximately 130k cells. At one prefix length, a combined Stage-2 rule contrast of equal-subbucket coverage versus size-proportional within-bucket quality top-30% lifts a 16-task capability macro-average by +0.0253; at the next finer level, the same rule loses its measurable edge as candidate pools contract approximately 5x.
What carries the argument
The coarse-to-fine code from 3-stage residual vector quantization after a learned semantic transform, where prefix length selects the granularity for applying mixing rules.
If this is right
- At one granularity level, equal-subbucket coverage mixing outperforms size-proportional selection of the top 30% quality documents within each bucket.
- The performance advantage of this rule contrast vanishes at the next finer granularity where candidate pools shrink by a factor of approximately 5.
- Data mixture design can be reframed as selecting and combining rules that operate across levels of a reusable hierarchy rather than choosing among fixed label sets.
- The substrate makes measurable an interaction between mixing rules and label resolution that any fixed-granularity pipeline cannot test.
Where Pith is reading between the lines
- If the granularity interaction generalizes, similar rule contrasts could be discovered for other model sizes or training token budgets.
- An adaptive mixer could select different rules depending on the current prefix length chosen from the hierarchy.
- The same hierarchical substrate might be applied to data curation tasks outside pre-training such as instruction tuning or evaluation set construction.
Load-bearing premise
The observed performance differences are caused by the choice of label granularity rather than uncontrolled variables in the 1B/25B pre-training runs or the specific mixing rules tested.
What would settle it
Re-running the 1B-parameter 25B-token pre-training experiments across multiple random seeds while holding all other factors fixed to check whether the +0.0253 gain at that specific prefix length remains consistent.
Figures


read the original abstract
Most data-mixing methods assume the corpus has already been partitioned into groups, and the choice of those groups determines what a mixer can express. Existing labels, including provenance, topic or format taxonomies, and flat embedding clusters, commit to one semantic axis at one granularity; changing the resolution rebuilds the labels. We argue the bottleneck is the label system, not the mixer, and provide a hierarchical one. HERMES is a data-derived labeling substrate: a Learned Semantic Transform followed by 3-stage residual vector quantization annotates each document once into a coarse-to-fine code whose prefix length controls granularity up to approximately 130k cells. At coarse granularity HERMES sits at a plateau with KMeans-family methods on standard clustering metrics, so the contribution is the substrate, not the clusterer. On 1B-parameter, 25B-token pre-training, the hierarchy exposes an interaction fixed-granularity pipelines cannot test: at one prefix length, a combined Stage-2 rule contrast, equal-subbucket coverage versus size-proportional within-bucket quality top-30%, lifts a 16-task capability macro-average by +0.0253; at the next finer level, the same rule loses its measurable edge as candidate pools contract approximately 5x. HERMES reframes data mixture design from choosing among fixed label sets to navigating a reusable, data-derived granularity hierarchy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HERMES, a hierarchical data labeling substrate consisting of a Learned Semantic Transform followed by 3-stage residual vector quantization. Each document receives a single coarse-to-fine code whose prefix length selects granularity (up to ~130k cells). At coarse levels the method matches KMeans-family baselines on standard metrics; the claimed contribution is the reusable substrate. On 1B-parameter models trained for 25B tokens, the hierarchy is used to test a Stage-2 mixing contrast (equal-subbucket coverage versus size-proportional top-30% quality) across prefix lengths. At one granularity the contrast produces a +0.0253 lift on a 16-task macro-average; at the next finer granularity the same contrast loses its measurable advantage as candidate pools contract by a factor of ~5. The paper concludes that data-mixture design should be reframed as navigation of a granularity hierarchy rather than selection among fixed label sets.
Significance. If the reported granularity-by-mixing interaction is reproducible, HERMES supplies a practical, data-derived hierarchy that decouples label construction from downstream mixing rules and enables systematic tests unavailable to single-granularity pipelines. The work correctly identifies the label system as the bottleneck and demonstrates a concrete empirical signature of that bottleneck. Strengths include the single-pass annotation design and the explicit linkage between prefix length and pool size; these are genuine engineering contributions even if the performance delta requires further validation.
major comments (3)
- [Abstract] Abstract (and the experimental results paragraph): the central claim that the hierarchy 'exposes an interaction fixed-granularity pipelines cannot test' rests on a +0.0253 macro-average lift that disappears at the next prefix length. No error bars, replicate counts, fixed-seed controls, or statistical tests are reported, so it is impossible to determine whether the observed difference exceeds run-to-run stochasticity on 1B/25B pre-training runs.
- [Abstract] Abstract (mixing-rule description): the Stage-2 contrast is defined only at the level of 'equal-subbucket coverage versus size-proportional within-bucket quality top-30%'. Without the precise bucket-construction equations or the exact quality metric used for the top-30% selection, it is unclear whether the reported interaction is driven by granularity or by an uncontrolled interaction between the specific heuristics and the RVQ code distribution.
- [Abstract] Abstract (pool-contraction claim): the disappearance of the edge is attributed to candidate pools contracting 'approximately 5x'. No table or figure quantifies the actual pool sizes at each prefix length, nor are the 16 tasks or the macro-average aggregation method specified, both of which are load-bearing for interpreting the granularity effect.
minor comments (2)
- [Abstract] The abstract states that HERMES 'sits at a plateau with KMeans-family methods on standard clustering metrics' but provides neither the metric values nor the exact KMeans baselines used for comparison.
- Notation for the three RVQ stages and the precise definition of 'prefix length' should be introduced with an equation or diagram in the methods section to make the granularity control reproducible.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and for recognizing the engineering value of the reusable hierarchical substrate. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract (and the experimental results paragraph): the central claim that the hierarchy 'exposes an interaction fixed-granularity pipelines cannot test' rests on a +0.0253 macro-average lift that disappears at the next prefix length. No error bars, replicate counts, fixed-seed controls, or statistical tests are reported, so it is impossible to determine whether the observed difference exceeds run-to-run stochasticity on 1B/25B pre-training runs.
Authors: We acknowledge that the reported lift lacks error bars, replicate counts, or statistical tests, which limits claims about exceeding stochasticity. Pre-training at this scale is computationally expensive, precluding additional replicates in the current work. In revision we will add an explicit limitations paragraph discussing run-to-run variability and will qualify the interaction as an empirical observation rather than a statistically validated effect. The 16-task suite and macro-average definition will also be stated explicitly. revision: partial
-
Referee: [Abstract] Abstract (mixing-rule description): the Stage-2 contrast is defined only at the level of 'equal-subbucket coverage versus size-proportional within-bucket quality top-30%'. Without the precise bucket-construction equations or the exact quality metric used for the top-30% selection, it is unclear whether the reported interaction is driven by granularity or by an uncontrolled interaction between the specific heuristics and the RVQ code distribution.
Authors: We agree the current description is high-level. The revised manuscript will include the exact bucket-construction equations and the definition of the quality metric used for top-30% selection, placed in the methods section with a reference from the abstract. revision: yes
-
Referee: [Abstract] Abstract (pool-contraction claim): the disappearance of the edge is attributed to candidate pools contracting 'approximately 5x'. No table or figure quantifies the actual pool sizes at each prefix length, nor are the 16 tasks or the macro-average aggregation method specified, both of which are load-bearing for interpreting the granularity effect.
Authors: We will add a table in the revision that reports candidate pool sizes at each prefix length. The 16 tasks and the precise macro-average aggregation procedure will be stated explicitly in both the abstract and the experimental section. revision: yes
- Absence of multiple independent pre-training replicates and formal statistical tests on the 1B/25B runs, as additional runs remain computationally prohibitive.
Circularity Check
No significant circularity; results are empirical observations
full rationale
The paper introduces HERMES as a data-derived hierarchical labeling substrate via Learned Semantic Transform plus 3-stage residual vector quantization, then reports direct empirical outcomes from 1B/25B pre-training runs: a Stage-2 mixing rule contrast yields +0.0253 macro-average lift at one prefix length but loses the edge at the next finer granularity where pools contract ~5x. These observations are presented as measured performance differences across granularity levels, not as predictions or derivations obtained by fitting parameters to the target quantities or by self-citation chains. No equations, uniqueness theorems, or ansatzes are invoked that reduce the reported interaction to the inputs by construction. The central claim therefore remains an independent empirical finding.
Axiom & Free-Parameter Ledger
free parameters (2)
- number of RVQ stages =
3
- quality selection threshold =
top-30%
invented entities (1)
-
HERMES hierarchical code
no independent evidence
Reference graph
Works this paper leans on
-
[1]
and Ma, Tengyu and Yu, Adams Wei , booktitle=
Xie, Sang Michael and Pham, Hieu and Dong, Xuanyi and Du, Nan and Liu, Hanxiao and Lu, Yifeng and Liang, Percy and Le, Quoc V. and Ma, Tengyu and Yu, Adams Wei , booktitle=. 2023 , url=. 2305.10429 , archivePrefix=
-
[2]
International Conference on Learning Representations , year=
Data Mixing Laws: Optimizing Data Mixtures by Predicting Language Modeling Performance , author=. International Conference on Learning Representations , year=. 2403.16952 , archivePrefix=
-
[3]
Liu, Qian and Zheng, Xiaosen and Muennighoff, Niklas and Zeng, Guangtao and Dou, Longxu and Pang, Tianyu and Jiang, Jing and Lin, Min , booktitle=. 2025 , url=. 2407.01492 , archivePrefix=
-
[4]
Diao, Shizhe and Yang, Yu and Fu, Yonggan and Dong, Xin and Su, Dan and Kliegl, Markus and Chen, Zijia and Belcak, Peter and Suhara, Yoshi and Yin, Hongxu and Patwary, Mostofa and Lin, Yingyan Celine and Kautz, Jan and Molchanov, Pavlo , booktitle=. 2025 , url=. 2504.13161 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
International Conference on Machine Learning , year=
Chameleon: A Flexible Data-mixing Framework for Language Model Pretraining and Finetuning , author=. International Conference on Machine Learning , year=. 2505.24844 , archivePrefix=
-
[6]
Proceedings of the 42nd International Conference on Machine Learning , pages=
Organize the Web: Constructing Domains Enhances Pre-Training Data Curation , author=. Proceedings of the 42nd International Conference on Machine Learning , pages=. 2025 , volume=. 2502.10341 , archivePrefix=
-
[7]
Topic Over Source: The Key to Effective Data Mixing for Language Models Pre-training , author=. 2025 , howpublished=. 2502.16802 , archivePrefix=
-
[8]
DataComp-LM: In search of the next generation of training sets for language models
Li, Jeffrey and Fang, Alex and Smyrnis, Georgios and Ivgi, Maor and Jordan, Matt and Gadre, Samir and Bansal, Hritik and Guha, Etash and Keh, Sedrick and Arora, Kushal and Garg, Saurabh and Xin, Rui and Muennighoff, Niklas and Heckel, Reinhard and Mercat, Jean and Chen, Mayee and Gururangan, Suchin and Wortsman, Mitchell and Albalak, Alon and Bitton, Yona...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Advances in Neural Information Processing Systems , year=
Data Selection for Language Models via Importance Resampling , author=. Advances in Neural Information Processing Systems , year=. 2302.03169 , archivePrefix=
-
[10]
Wettig, Alexander and Gupta, Aatmik and Malik, Saumya and Chen, Danqi , booktitle=. 2024 , url=. 2402.09739 , archivePrefix=
-
[11]
Companion of the 2024 International Conference on Management of Data , year=
Data-Juicer: A One-Stop Data Processing System for Large Language Models , author=. Companion of the 2024 International Conference on Management of Data , year=. doi:10.1145/3626246.3653385 , url=. 2309.02033 , archivePrefix=
-
[12]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
Optimized Product Quantization for Approximate Nearest Neighbor Search , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=. 2013 , doi=
2013
-
[13]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
Product Quantization for Nearest Neighbor Search , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=. 2011 , doi=
2011
-
[14]
Improved Residual Vector Quantization for High-dimensional Approximate Nearest Neighbor Search
Improved Residual Vector Quantization for High-dimensional Approximate Nearest Neighbor Search , author=. arXiv preprint arXiv:1509.05195 , year=. 1509.05195 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
International Conference on Machine Learning , year=
Residual Quantization with Implicit Neural Codebooks , author=. International Conference on Machine Learning , year=. 2401.14732 , archivePrefix=
-
[16]
International Conference on Learning Representations , year=
Vallaeys, Th. International Conference on Learning Representations , year=. 2501.03078 , archivePrefix=
-
[17]
Neural Discrete Representation Learning
Neural Discrete Representation Learning , author=. Advances in Neural Information Processing Systems , year=. 1711.00937 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Zeghidour, Neil and Luebs, Alejandro and Omran, Ahmed and Skoglund, Jan and Tagliasacchi, Marco , journal=. 2022 , doi=. 2107.03312 , archivePrefix=
-
[19]
High Fidelity Neural Audio Compression
High Fidelity Neural Audio Compression , author=. Transactions on Machine Learning Research , year=. 2210.13438 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Autoregressive Image Generation using Residual Quantization , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=. 2022 , doi=. 2203.01941 , archivePrefix=
-
[21]
, journal=
Lloyd, Stuart P. , journal=. Least Squares Quantization in. 1982 , doi=
1982
-
[22]
Proceedings of the 19th International Conference on World Wide Web , pages=
Web-Scale K-Means Clustering , author=. Proceedings of the 19th International Conference on World Wide Web , pages=. 2010 , doi=
2010
-
[23]
KDD Workshop on Text Mining , year=
A Comparison of Document Clustering Techniques , author=. KDD Workshop on Text Mining , year=
-
[24]
Billion-scale similarity search with GPUs
Johnson, Jeff and Douze, Matthijs and J. Billion-scale Similarity Search with. IEEE Transactions on Big Data , volume=. 2021 , doi=. 1702.08734 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[25]
LLaMA: Open and Efficient Foundation Language Models
Touvron, Hugo and Lavril, Thibaut and Izacard, Gautier and Martinet, Xavier and Lachaux, Marie-Anne and Lacroix, Timoth. arXiv preprint arXiv:2302.13971 , year=. 2302.13971 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Touvron, Hugo and Martin, Louis and Stone, Kevin and others , journal=. 2023 , url=. 2307.09288 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
2019 , doi=
Zellers, Rowan and Holtzman, Ari and Bisk, Yonatan and Farhadi, Ali and Choi, Yejin , booktitle=. 2019 , doi=
2019
-
[28]
2021 , howpublished=
A Framework for Few-shot Language Model Evaluation , author=. 2021 , howpublished=
2021
-
[29]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Clark, Peter and Cowhey, Isaac and Etzioni, Oren and Khot, Tushar and Sabharwal, Ashish and Schoenick, Carissa and Tafjord, Oyvind , journal=. Think You Have Solved Question Answering? Try. 2018 , url=. 1803.05457 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[30]
2019 , doi=
Talmor, Alon and Herzig, Jonathan and Lourie, Nicholas and Berant, Jonathan , booktitle=. 2019 , doi=
2019
-
[31]
PIQA: Reasoning about Physical Commonsense in Natural Language
Bisk, Yonatan and Zellers, Rowan and Gao, Jianfeng and Choi, Yejin , booktitle=. 2020 , doi=. 1911.11641 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[32]
2019 , doi=
Clark, Christopher and Lee, Kenton and Chang, Ming-Wei and Kwiatkowski, Tom and Collins, Michael and Toutanova, Kristina , booktitle=. 2019 , doi=
2019
-
[33]
Penedo, Guilherme and Kydl. The. Advances in Neural Information Processing Systems , year=. 2406.17557 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Training Compute-Optimal Large Language Models
Training Compute-Optimal Large Language Models , author=. arXiv preprint arXiv:2203.15556 , year=. 2203.15556 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Penedo, Guilherme and Malartic, Quentin and Hesslow, Daniel and Cojocaru, Ruxandra and Cappelli, Alessandro and Alobeidli, Hamza and Pannier, Baptiste and Almazrouei, Ebtesam and Launay, Julien , booktitle=. The. 2023 , url=. 2306.01116 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
Scaling Laws for Neural Language Models
Scaling Laws for Neural Language Models , author=. arXiv preprint arXiv:2001.08361 , year=. 2001.08361 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[37]
arXiv preprint arXiv:2402.16827 , year=
A Survey on Data Selection for Language Models , author=. arXiv preprint arXiv:2402.16827 , year=. 2402.16827 , archivePrefix=
-
[38]
Distributionally Robust Neural Networks for Group Shifts: On the Importance of Regularization for Worst-Case Generalization , author=. International Conference on Learning Representations , year=. 1911.08731 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[39]
Gu, Yuling and Tafjord, Oyvind and Kuehl, Bailey and Haddad, Dany and Dodge, Jesse and Hajishirzi, Hannaneh , booktitle=. 2025 , url=. 2406.08446 , archivePrefix=
-
[40]
Proceedings of the 3rd Workshop on Noisy User-generated Text , pages=
Crowdsourcing Multiple Choice Science Questions , author=. Proceedings of the 3rd Workshop on Noisy User-generated Text , pages=. 2017 , doi=
2017
-
[41]
LAB-Bench: Measuring Capabilities of Language Models for Biology Research
Laurent, Jon M. and Janizek, Joseph D. and Ruzo, Michael and Hinks, Michaela M. and Hammerling, Michael J. and Narayanan, Siddharth and Ponnapati, Manvitha and White, Andrew D. and Rodriques, Samuel G. , journal=. 2024 , url=. 2407.10362 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
Transactions of the Association for Computational Linguistics , volume=
Natural Questions: A Benchmark for Question Answering Research , author=. Transactions of the Association for Computational Linguistics , volume=. 2019 , doi=
2019
-
[43]
2019 , doi=
Sap, Maarten and Rashkin, Hannah and Chen, Derek and LeBras, Ronan and Choi, Yejin , booktitle=. 2019 , doi=
2019
-
[44]
Scikit-learn: Machine Learning in
Pedregosa, Fabian and Varoquaux, Ga. Scikit-learn: Machine Learning in. Journal of Machine Learning Research , volume=. 2011 , url=
2011
-
[45]
2021 , howpublished=
vector-quantize-pytorch , author=. 2021 , howpublished=
2021
-
[46]
Yu, Zichun and Das, Spandan and Xiong, Chenyan , booktitle=. 2024 , url=. 2406.06046 , archivePrefix=
-
[47]
Xia, Mengzhou and Malladi, Sadhika and Gururangan, Suchin and Arora, Sanjeev and Chen, Danqi , booktitle=. 2024 , url=. 2402.04333 , archivePrefix=
-
[48]
Kwon, Yongchan and Wu, Eric and Wu, Kevin and Zou, James , booktitle=. 2024 , url=. 2310.00902 , archivePrefix=
-
[49]
Xi, Xiangyu and Kong, Deyang and Yang, Jian and Yang, Jiawei and Chen, Zhengyu and Wang, Wei and Wang, Jingang and Cai, Xunliang and Zhang, Shikun and Ye, Wei , journal=. 2025 , url=. 2503.01506 , archivePrefix=
-
[50]
Liu, Fengze and Zhou, Weidong and Liu, Binbin and Yu, Zhimiao and Zhang, Yifan and Lin, Haobin and Yu, Yifeng and Zhang, Bingni and Zhou, Xiaohuan and Wang, Taifeng and Cao, Yong , journal=. 2025 , url=. 2504.16511 , archivePrefix=
-
[51]
Data Mixing for Large Language Models Pretraining: A Survey and Outlook
Data Mixing for Large Language Models Pretraining: A Survey and Outlook , author=. arXiv preprint arXiv:2604.16380 , year=. 2604.16380 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.