MemRefine: LLM-Guided Compression for Long-Term Agent Memory
Pith reviewed 2026-06-27 06:51 UTC · model grok-4.3
The pith
LLM-guided compression trims long-term agent memory stores to any fixed budget while keeping downstream performance intact.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
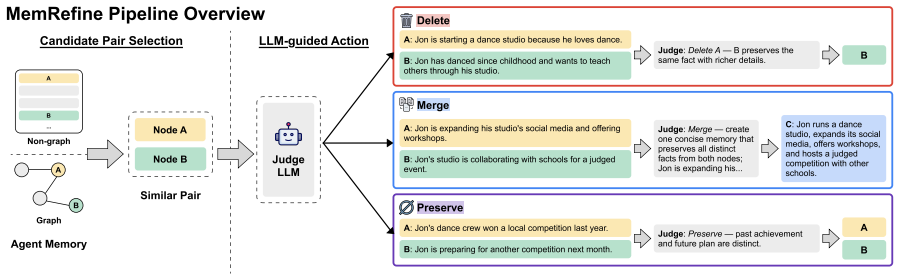
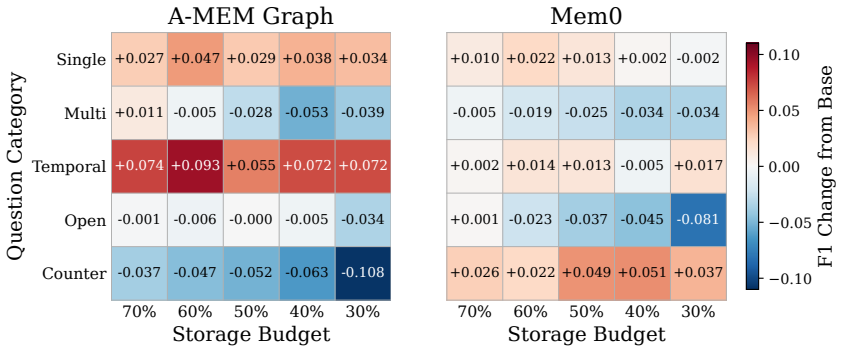
MemRefine is an LLM-guided framework for storage-budgeted memory management that, because surface similarity poorly reflects factual value, uses similarity only to propose candidate pairs and defers delete, merge, and preserve decisions to an LLM judge based on factual content, iterating until the budget is met. Across multiple memory frameworks and long-term conversation benchmarks, this approach consistently meets target budgets while preserving downstream performance and outperforming rule-based baselines under tight budgets.
What carries the argument
MemRefine, an iterative process that proposes candidate pairs by similarity then delegates factual delete/merge/preserve decisions to an LLM judge.
If this is right
- Agent memory stores can be kept inside hard resource limits without measurable loss on future tasks.
- The same compression method applies across different existing memory frameworks.
- Rule-based compression is outperformed when budgets are especially tight.
- Long-term agent operation becomes feasible on platforms with fixed memory ceilings.
Where Pith is reading between the lines
- If the LLM judge remains consistent across many iterations, the same candidate-plus-judge pattern could compress other expanding stores such as retrieval-augmented knowledge bases.
- Cloud deployments of agents could lower per-user memory costs by enforcing budgets without retraining the underlying models.
- A verification layer that re-checks merged facts after compression might reduce any accumulated judgment drift the paper does not test.
Load-bearing premise
LLM judgments of factual content and value are reliable enough to avoid introducing errors or biases that degrade downstream task performance.
What would settle it
On a standard long-term conversation benchmark, compare downstream task accuracy using MemRefine-compressed memory versus the original uncompressed memory at the same budget size; lower accuracy with MemRefine would falsify the preservation claim.
Figures




read the original abstract
Large language model (LLM) agents are increasingly expected to operate over long-term interactions, where information from past dialogues must be preserved and recalled to support future tasks. However, as interactions accumulate, the memory store grows without bound and fills with redundant entries that inflate storage cost and degrade retrieval by crowding out the most useful evidence. Furthermore, this is especially limiting on resource-constrained platforms with hard memory budgets, motivating us to formulate storage-budgeted memory management, the task of keeping an already constructed memory store within a fixed budget while preserving information useful for future interactions. To this end, we then propose MemRefine, an LLM-guided framework that, since surface similarity poorly reflects factual value, uses similarity only to propose candidate pairs and defers delete, merge, and preserve decisions to an LLM judge based on factual content, iterating until the budget is met. Across multiple memory frameworks and long-term conversation benchmarks, MemRefine consistently meets target budgets while preserving downstream performance and outperforming rule-based baselines under tight budgets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MemRefine, an LLM-guided compression framework for storage-budgeted memory management in long-term LLM agents. It uses surface similarity only to propose candidate pairs for compression and defers all delete/merge/preserve decisions to an LLM judge based on factual content and value, iterating until a target memory budget is met. The central claim is that this approach consistently meets budgets across multiple memory frameworks and long-term conversation benchmarks while preserving downstream task performance and outperforming rule-based baselines under tight budgets.
Significance. If the LLM judge decisions prove reliable, the work addresses a practical bottleneck in scaling LLM agents to extended interactions by providing a method to control memory growth without uniform degradation. The use of LLM reasoning over factual value rather than heuristics is a plausible direction, though its impact depends on empirical validation of judge accuracy.
major comments (2)
- [Abstract] Abstract: The central performance-preservation claim depends on the reliability of LLM judgments for factual delete/merge/preserve decisions, yet the provided text contains no mention of human ground-truth validation, inter-annotator agreement, or error analysis on those judgments. This is load-bearing because systematic over-merging or deletion of useful facts could leave downstream metrics unchanged only if the chosen benchmarks are insensitive to the introduced noise.
- [Abstract] Abstract: No error bars, dataset sizes, ablation results, or statistical significance tests are reported for the claimed consistent outperformance and budget adherence. Without these, it is impossible to assess whether the gains over rule-based baselines are robust or sensitive to particular memory frameworks and benchmarks.
minor comments (1)
- [Abstract] Abstract: The phrasing 'since surface similarity poorly reflects factual value' is presented as a premise without supporting citation or preliminary evidence in the visible text; a brief justification or reference would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our work. We address each major comment below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central performance-preservation claim depends on the reliability of LLM judgments for factual delete/merge/preserve decisions, yet the provided text contains no mention of human ground-truth validation, inter-annotator agreement, or error analysis on those judgments. This is load-bearing because systematic over-merging or deletion of useful facts could leave downstream metrics unchanged only if the chosen benchmarks are insensitive to the introduced noise.
Authors: We agree that direct validation of the LLM judge is important for substantiating the central claim. The current manuscript relies on downstream task performance as an indirect indicator of judgment quality across multiple benchmarks and memory frameworks, but does not include human ground-truth evaluation or error analysis of the individual delete/merge/preserve decisions. In the revised version we will add a human evaluation study on a representative sample of LLM judgments (including inter-annotator agreement and categorization of error types) to directly assess judge reliability. revision: yes
-
Referee: [Abstract] Abstract: No error bars, dataset sizes, ablation results, or statistical significance tests are reported for the claimed consistent outperformance and budget adherence. Without these, it is impossible to assess whether the gains over rule-based baselines are robust or sensitive to particular memory frameworks and benchmarks.
Authors: We acknowledge that the current presentation lacks explicit error bars, dataset sizes, additional ablations, and statistical significance tests. The manuscript already evaluates across multiple memory frameworks and long-term conversation benchmarks, but we will revise the experimental section and abstract to report dataset sizes, include error bars on all performance figures, add further ablation studies on key design choices, and apply appropriate statistical tests to support the robustness claims. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper describes an LLM-guided memory compression method that proposes candidate pairs via similarity and defers all delete/merge/preserve decisions to external LLM judgments, iterating until a budget is met. No equations, fitted parameters, self-definitional constructs, or load-bearing self-citations appear in the provided text. The central procedure relies on independent external LLM calls rather than any reduction to the paper's own inputs by construction, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
Retrieval-Augmented Generation for Knowledge-Intensive
Patrick Lewis and Ethan Perez and Aleksandra Piktus and Fabio Petroni and Vladimir Karpukhin and Naman Goyal and Heinrich K. Retrieval-Augmented Generation for Knowledge-Intensive. Advances in Neural Information Processing Systems 33 , year =
-
[9]
Transactions of the Association for Computational Linguistics , volume =
Lost in the Middle: How Language Models Use Long Contexts , author =. Transactions of the Association for Computational Linguistics , volume =. 2024 , publisher =
2024
-
[10]
Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =
Beyond Goldfish Memory: Long-Term Open-Domain Conversation , author =. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =. 2022 , address =
2022
-
[11]
Findings of the Association for Computational Linguistics: EMNLP 2022 , pages =
Keep Me Updated! Memory Management in Long-term Conversations , author =. Findings of the Association for Computational Linguistics: EMNLP 2022 , pages =. 2022 , address =
2022
-
[12]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages =
Conversation Chronicles: Towards Diverse Temporal and Relational Dynamics in Multi-Session Conversations , author =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages =. 2023 , address =
2023
-
[13]
Proceedings of the Thirty-Eighth AAAI Conference on Artificial Intelligence , pages =
Wanjun Zhong and Lianghong Guo and Qiqi Gao and He Ye and Yanlin Wang , title =. Proceedings of the Thirty-Eighth AAAI Conference on Artificial Intelligence , pages =. 2024 , url =
2024
-
[14]
arXiv preprint arXiv:2305.14322 , year =
Ali Modarressi and Ayyoob Imani and Mohsen Fayyaz and Hinrich Sch. arXiv preprint arXiv:2305.14322 , year =. doi:10.48550/ARXIV.2305.14322 , eprinttype =
-
[15]
MemGPT: Towards LLMs as Operating Systems
Charles Packer and Vivian Fang and Shishir G. Patil and Kevin Lin and Sarah Wooders and Joseph E. Gonzalez , title =. arXiv preprint arXiv:2310.08560 , year =. doi:10.48550/ARXIV.2310.08560 , eprinttype =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.08560
-
[16]
Advances in Neural Information Processing Systems 38 , year =
Wujiang Xu and Zujie Liang and Kai Mei and Hang Gao and Juntao Tan and Yongfeng Zhang , title =. Advances in Neural Information Processing Systems 38 , year =
-
[17]
Neurocomputing , volume =
Qingyue Wang and Yanhe Fu and Yanan Cao and Shuai Wang and Zhiliang Tian and Liang Ding , title =. Neurocomputing , volume =. 2025 , url =
2025
-
[18]
Proceedings of the 31st International Conference on Computational Linguistics , pages =
Compress to Impress: Unleashing the Potential of Compressive Memory in Real-World Long-Term Conversations , author =. Proceedings of the 31st International Conference on Computational Linguistics , pages =. 2025 , address =
2025
-
[19]
SimpleMem: Efficient Lifelong Memory for LLM Agents
Jiaqi Liu and Yaofeng Su and Peng Xia and Siwei Han and Zeyu Zheng and Cihang Xie and Mingyu Ding and Huaxiu Yao , title =. arXiv preprint arXiv:2601.02553 , year =. doi:10.48550/ARXIV.2601.02553 , eprinttype =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2601.02553
-
[20]
LightMem: Lightweight and Efficient Memory-Augmented Generation
Jizhan Fang and Xinle Deng and Haoming Xu and Ziyan Jiang and Yuqi Tang and Ziwen Xu and Shumin Deng and Yunzhi Yao and Mengru Wang and Shuofei Qiao and Huajun Chen and Ningyu Zhang , title =. arXiv preprint arXiv:2510.18866 , year =. doi:10.48550/ARXIV.2510.18866 , eprinttype =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2510.18866
-
[21]
The Twelfth International Conference on Learning Representations , year =
Fangyuan Xu and Weijia Shi and Eunsol Choi , title =. The Twelfth International Conference on Learning Representations , year =
-
[22]
2023 , address =
Jiang, Huiqiang and Wu, Qianhui and Lin, Chin-Yew and Yang, Yuqing and Qiu, Lili , booktitle =. 2023 , address =
2023
-
[23]
2024 , address =
Jiang, Huiqiang and Wu, Qianhui and Luo, Xufang and Li, Dongsheng and Lin, Chin-Yew and Yang, Yuqing and Qiu, Lili , booktitle =. 2024 , address =
2024
-
[24]
StreamMeCo: Long-Term Agent Memory Compression for Efficient Streaming Video Understanding
Junxi Wang and Te Sun and Jiayi Zhu and Junxian Li and Haowen Xu and Zichen Wen and Xuming Hu and Zhiyu Li and Linfeng Zhang , title =. arXiv preprint arXiv:2604.09000 , year =. doi:10.48550/ARXIV.2604.09000 , eprinttype =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.09000
-
[25]
Computer Networks and ISDN Systems , volume =
Sergey Brin and Lawrence Page , title =. Computer Networks and ISDN Systems , volume =. 1998 , url =
1998
-
[26]
Evaluating Very Long-Term Conversational Memory of
Maharana, Adyasha and Lee, Dong-Ho and Tulyakov, Sergey and Bansal, Mohit and Barbieri, Francesco and Fang, Yuwei , booktitle =. Evaluating Very Long-Term Conversational Memory of. 2024 , address =
2024
-
[27]
The Thirteenth International Conference on Learning Representations , publisher =
Di Wu and Hongwei Wang and Wenhao Yu and Yuwei Zhang and Kai-Wei Chang and Dong Yu , title =. The Thirteenth International Conference on Learning Representations , publisher =. 2025 , url =
2025
-
[28]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Prateek Chhikara and Dev Khant and Saket Aryan and Taranjeet Singh and Deshraj Yadav , title =. arXiv preprint arXiv:2504.19413 , year =. doi:10.48550/ARXIV.2504.19413 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2504.19413
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.