Mitigating Object Hallucinations via Sentence-Level Early Intervention
Pith reviewed 2026-05-25 08:29 UTC · model grok-4.3
The pith
Sentence-level preference training from detector-validated pairs cuts object hallucinations in multimodal models by over 90 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
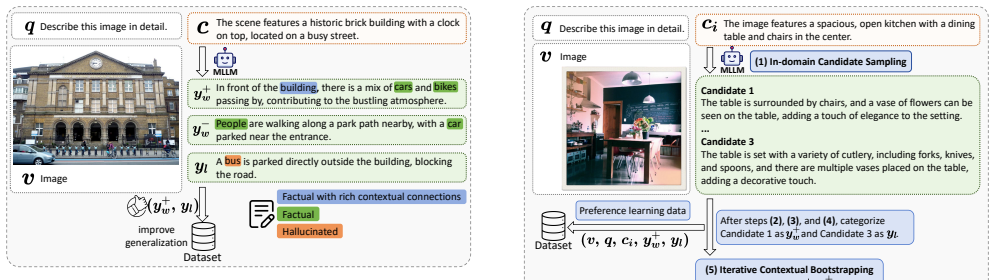
Hallucinations predominantly emerge at the early stages of text generation and propagate through subsequent outputs. By iteratively sampling model outputs, validating object existence through cross-checking with two open-vocabulary detectors, and classifying sentences into hallucinated or non-hallucinated categories, high-quality in-domain preference pairs can be bootstrapped without human annotations. Training with a context-aware preference loss (C-DPO) that emphasizes discriminative learning at the sentence level where hallucinations initially manifest then suppresses the fabrication of objects from the first sentence onward.
What carries the argument
SENTINEL framework that creates context-coherent positive and hallucinated negative sentence pairs via detector cross-validation and optimizes them with context-aware direct preference optimization (C-DPO) focused on early generation steps.
If this is right
- Models trained with SENTINEL reduce hallucinations by more than 90 percent relative to the base model while outperforming prior state-of-the-art methods on both hallucination and general capability benchmarks.
- No human-annotated preference data is required because the training pairs are generated automatically through detector validation.
- Focusing the preference loss at the sentence level prevents errors from propagating through later parts of the response.
- The iterative bootstrapping process produces progressively higher-quality preference data as the model improves.
Where Pith is reading between the lines
- The same early-sentence labeling and preference approach could be applied to other hallucination types such as incorrect attributes or spatial relations.
- If more accurate or specialized detectors become available, the quality of the automatically generated preference data would increase and further reduce residual hallucinations.
- The method's independence from human labels makes it practical to retrain models periodically as new vision backbones improve detector reliability.
Load-bearing premise
Cross-checking model outputs against two open-vocabulary detectors accurately classifies sentences as hallucinated or non-hallucinated without introducing new systematic errors or distribution shifts.
What would settle it
A collection of generated sentences where the two detectors label an object as present but a careful human review finds it absent (or the reverse) at a high rate would show the classification step is unreliable.
Figures














read the original abstract
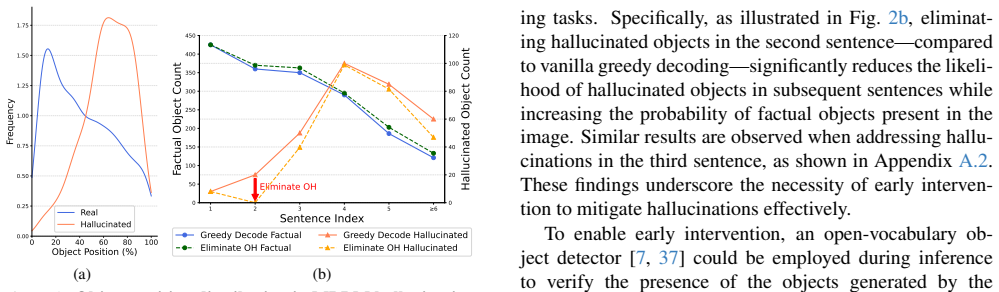
Multimodal large language models (MLLMs) have revolutionized cross-modal understanding but continue to struggle with hallucinations - fabricated content contradicting visual inputs. Existing hallucination mitigation methods either incur prohibitive computational costs or introduce distribution mismatches between training data and model outputs. We identify a critical insight: hallucinations predominantly emerge at the early stages of text generation and propagate through subsequent outputs. To address this, we propose SENTINEL (Sentence-level Early iNtervention Through IN-domain prEference Learning), a framework that eliminates dependency on human annotations. Specifically, we first bootstrap high-quality in-domain preference pairs by iteratively sampling model outputs, validating object existence through cross-checking with two open-vocabulary detectors, and classifying sentences into hallucinated/non-hallucinated categories. Subsequently, we use context-coherent positive samples and hallucinated negative samples to build context-aware preference data iteratively. Finally, we train models using a context-aware preference loss (C-DPO) that emphasizes discriminative learning at the sentence level where hallucinations initially manifest. Experimental results show that SENTINEL can reduce hallucinations by over 90% compared to the original model and outperforms the previous state-of-the-art method on both hallucination benchmarks and general capabilities benchmarks, demonstrating its superiority and generalization ability. The models, datasets, and code are available at https://github.com/pspdada/SENTINEL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SENTINEL, a framework to mitigate object hallucinations in MLLMs by intervening at the sentence level during early text generation. It bootstraps in-domain preference pairs without human annotations by iteratively sampling model outputs and classifying sentences as hallucinated or non-hallucinated via cross-checking against two open-vocabulary detectors; these pairs then train the model with a context-aware preference loss (C-DPO). The abstract claims this yields over 90% hallucination reduction versus the base model and outperforms prior SOTA on both hallucination and general capability benchmarks.
Significance. If the detector-based labeling accurately reflects true hallucinations, the method offers a scalable, annotation-free route to preference data that targets the early emergence of errors, with potential to improve MLLM reliability in grounded applications. The public release of models, datasets, and code at the cited GitHub repository is a clear strength for reproducibility and follow-on work.
major comments (2)
- [§3] §3 (bootstrapping procedure): The central pipeline classifies sentences using cross-checks against two open-vocabulary detectors, yet reports no inter-detector agreement statistics, human validation of labels, or ablation on detector choice. This is load-bearing for the >90% reduction claim, because systematic mislabeling (e.g., missing context-dependent fabrications or over-flagging valid descriptions) would cause C-DPO to optimize for detector agreement rather than visual grounding.
- [§4] Abstract and §4 (results): The reported 'over 90% reduction' and benchmark outperformance are presented without measurement-protocol details, statistical significance tests, variance across runs, or controls isolating detector-induced bias. Given that preference-pair quality directly determines the training signal, these omissions prevent assessment of whether the gains are robust or artifactual.
minor comments (2)
- The abstract refers to 'general capabilities benchmarks' without naming them; adding the specific datasets (e.g., VQAv2, GQA) would improve clarity.
- Notation for the C-DPO loss could be expanded with an explicit equation showing how sentence-level context is incorporated, to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will incorporate revisions to improve transparency and rigor.
read point-by-point responses
-
Referee: [§3] §3 (bootstrapping procedure): The central pipeline classifies sentences using cross-checks against two open-vocabulary detectors, yet reports no inter-detector agreement statistics, human validation of labels, or ablation on detector choice. This is load-bearing for the >90% reduction claim, because systematic mislabeling (e.g., missing context-dependent fabrications or over-flagging valid descriptions) would cause C-DPO to optimize for detector agreement rather than visual grounding.
Authors: We agree that inter-detector agreement statistics, human validation of labels, and ablations on detector choice are important for validating the bootstrapping pipeline. These elements were omitted from the original submission. In the revised manuscript we will add: (i) agreement metrics (e.g., percentage agreement and Cohen’s kappa) between the two detectors, (ii) human validation results on a random sample of 200 labeled sentences, and (iii) an ablation comparing SENTINEL performance when using each detector individually versus the cross-check. These additions will directly address concerns about potential systematic mislabeling. revision: yes
-
Referee: [§4] Abstract and §4 (results): The reported 'over 90% reduction' and benchmark outperformance are presented without measurement-protocol details, statistical significance tests, variance across runs, or controls isolating detector-induced bias. Given that preference-pair quality directly determines the training signal, these omissions prevent assessment of whether the gains are robust or artifactual.
Authors: We acknowledge the need for more complete reporting. The revised version will expand §4 to include: detailed measurement protocols for all benchmarks, statistical significance tests (paired t-tests with p-values) on the main results, standard deviations across at least three independent training runs, and a control experiment that trains on a human-labeled subset to quantify any detector-induced bias. These changes will allow readers to better evaluate the robustness of the reported gains. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper describes an empirical pipeline: iterative sampling of model outputs, labeling via two external open-vocabulary detectors to create preference pairs, and training with a context-aware C-DPO loss. No equations, self-citations, or uniqueness theorems are invoked that reduce the claimed >90% hallucination reduction or benchmark gains to fitted parameters or inputs by construction. Evaluation occurs on independent hallucination and capability benchmarks, keeping the central result externally falsifiable rather than tautological.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Hallucinations predominantly emerge at the early stages of text generation and propagate through subsequent outputs
Forward citations
Cited by 2 Pith papers
-
HypEHR: Hyperbolic Modeling of Electronic Health Records for Efficient Question Answering
HypEHR is a hyperbolic embedding model for EHR data that uses Lorentzian geometry and hierarchy-aware pretraining to answer clinical questions nearly as well as large language models but with much smaller size.
-
Mitigating Multimodal Hallucination via Phase-wise Self-reward
PSRD mitigates visual hallucinations in LVLMs via phase-wise self-reward decoding, cutting rates by 50% on LLaVA-1.5-7B and outperforming prior methods on five benchmarks.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ah- mad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774 ,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Qwen-vl: A versatile vision-language model for un- derstanding, localization
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A versatile vision-language model for un- derstanding, localization. Text Reading, and Beyond, 2023. 1, 9
work page 2023
-
[3]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923, 2025. 8, 9
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Hallucination of Multimodal Large Language Models: A Survey
Zechen Bai, Pichao Wang, Tianjun Xiao, Tong He, Zongbo Han, Zheng Zhang, and Mike Zheng Shou. Hallucination of multimodal large language models: A survey. arXiv preprint arXiv:2404.18930, 2024. 1, 2, 9
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Driving with llms: Fusing object-level vec- tor modality for explainable autonomous driving
Long Chen, Oleg Sinavski, Jan H ¨unermann, Alice Karnsund, Andrew James Willmott, Danny Birch, Daniel Maund, and Jamie Shotton. Driving with llms: Fusing object-level vec- tor modality for explainable autonomous driving. In 2024 IEEE International Conference on Robotics and Automation (ICRA), 2024. 1
work page 2024
-
[6]
Halc: Object hallucination re- duction via adaptive focal-contrast decoding
Zhaorun Chen, Zhuokai Zhao, Hongyin Luo, Huaxiu Yao, Bo Li, and Jiawei Zhou. Halc: Object hallucination re- duction via adaptive focal-contrast decoding. arXiv preprint arXiv:2403.00425, 2024. 2, 9
-
[7]
Yolo-world: Real-time open-vocabulary object detection
Tianheng Cheng, Lin Song, Yixiao Ge, Wenyu Liu, Xing- gang Wang, and Ying Shan. Yolo-world: Real-time open-vocabulary object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024. 3, 4
work page 2024
-
[8]
DoLa: Decoding by Contrasting Layers Improves Factuality in Large Language Models
Yung-Sung Chuang, Yujia Xie, Hongyin Luo, Yoon Kim, James Glass, and Pengcheng He. Dola: Decoding by con- trasting layers improves factuality in large language models. arXiv preprint arXiv:2309.03883, 2023. 1, 2, 6, 7, 9
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Instructblip: Towards general- purpose vision-language models with instruction tuning,
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, and Steven Hoi. Instructblip: Towards general- purpose vision-language models with instruction tuning,
-
[10]
Making the v in vqa matter: Elevating the role of image understanding in visual question answer- ing
Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Ba- tra, and Devi Parikh. Making the v in vqa matter: Elevating the role of image understanding in visual question answer- ing. In Proceedings of the IEEE conference on computer vision and pattern recognition, 2017. 2, 6, 5, 9
work page 2017
-
[11]
Mask-dpo: Generalizable fine-grained factuality alignment of llms
Yuzhe Gu, Wenwei Zhang, Chengqi Lyu, Dahua Lin, and Kai Chen. Mask-dpo: Generalizable fine-grained factuality alignment of llms. arXiv preprint arXiv:2503.02846, 2025. 4
-
[12]
Tianrui Guan, Fuxiao Liu, Xiyang Wu, Ruiqi Xian, Zongxia Li, Xiaoyu Liu, Xijun Wang, Lichang Chen, Furong Huang, Yaser Yacoob, et al. Hallusionbench: an advanced diagnos- tic suite for entangled language hallucination and visual il- lusion in large vision-language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition...
work page 2024
-
[13]
Detecting and preventing hallucinations in large vision language models
Anisha Gunjal, Jihan Yin, and Erhan Bas. Detecting and preventing hallucinations in large vision language models. In Proceedings of the AAAI Conference on Artificial Intelli- gence, 2024. 2, 7
work page 2024
-
[14]
Visual perturbation-aware collaborative learning for overcoming the language prior problem
Yudong Han, Liqiang Nie, Jianhua Yin, Jianlong Wu, and Yan Yan. Visual perturbation-aware collaborative learning for overcoming the language prior problem. arXiv preprint arXiv:2207.11850, 2022. 9
-
[15]
Skip \n: A sim- ple method to reduce hallucination in large vision-language models
Zongbo Han, Zechen Bai, Haiyang Mei, Qianli Xu, Changqing Zhang, and Mike Zheng Shou. Skip \n: A sim- ple method to reduce hallucination in large vision-language models. arXiv preprint arXiv:2402.01345, 2024. 5
-
[16]
A topic-level self-correctional ap- proach to mitigate hallucinations in mllms
Lehan He, Zeren Chen, Zhelun Shi, Tianyu Yu, Jing Shao, and Lu Sheng. A topic-level self-correctional ap- proach to mitigate hallucinations in mllms. arXiv preprint arXiv:2411.17265, 2024. 3, 6, 7
-
[17]
Lora: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models. ICLR,
-
[18]
Advancing medical imaging with language mod- els: A journey from n-grams to chatgpt
Mingzhe Hu, Shaoyan Pan, Yuheng Li, and Xiaofeng Yang. Advancing medical imaging with language mod- els: A journey from n-grams to chatgpt. arXiv preprint arXiv:2304.04920, 2023. 1
-
[19]
Qidong Huang, Xiaoyi Dong, Pan Zhang, Bin Wang, Con- ghui He, Jiaqi Wang, Dahua Lin, Weiming Zhang, and Nenghai Yu. Opera: Alleviating hallucination in multi- modal large language models via over-trust penalty and retrospection-allocation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition ,
-
[20]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perel- man, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Weli- hinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024. 7, 8
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Fgaif: Aligning large vision- language models with fine-grained ai feedback
Liqiang Jing and Xinya Du. Fgaif: Aligning large vision- language models with fine-grained ai feedback. arXiv preprint arXiv:2404.05046, 2024. 2, 7
-
[22]
Faith- score: Fine-grained evaluations of hallucinations in large vision-language models
Liqiang Jing, Ruosen Li, Yunmo Chen, and Xinya Du. Faith- score: Fine-grained evaluations of hallucinations in large vision-language models. arXiv preprint arXiv:2311.01477,
-
[23]
Visual genome: Connecting language and vision using crowdsourced dense image annotations
Ranjay Krishna, Yuke Zhu, Oliver Groth, Justin Johnson, Kenji Hata, Joshua Kravitz, Stephanie Chen, Yannis Kalan- tidis, Li-Jia Li, David A Shamma, et al. Visual genome: Connecting language and vision using crowdsourced dense image annotations. International journal of computer vision,
-
[24]
Lisa: Reasoning segmentation via large language model
Xin Lai, Zhuotao Tian, Yukang Chen, Yanwei Li, Yuhui Yuan, Shu Liu, and Jiaya Jia. Lisa: Reasoning segmentation via large language model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 9579–9589, 2024. 9
work page 2024
-
[25]
Step-DPO: Step-wise Preference Optimization for Long-chain Reasoning of LLMs
Xin Lai, Zhuotao Tian, Yukang Chen, Senqiao Yang, Xian- gru Peng, and Jiaya Jia. Step-dpo: Step-wise preference op- timization for long-chain reasoning of llms. arXiv preprint arXiv:2406.18629, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
V olcano: mitigating multimodal hallucina- tion through self-feedback guided revision
Seongyun Lee, Sue Hyun Park, Yongrae Jo, and Min- joon Seo. V olcano: mitigating multimodal hallucina- tion through self-feedback guided revision. arXiv preprint arXiv:2311.07362, 2023. 6
-
[27]
Sicong Leng, Hang Zhang, Guanzheng Chen, Xin Li, Shijian Lu, Chunyan Miao, and Lidong Bing. Mitigating object hal- lucinations in large vision-language models through visual contrastive decoding. In Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, 2024. 1, 2, 6, 7, 9
work page 2024
-
[28]
Silkie: Preference distillation for large visual lan- guage models
Lei Li, Zhihui Xie, Mukai Li, Shunian Chen, Peiyi Wang, Liang Chen, Yazheng Yang, Benyou Wang, and Lingpeng Kong. Silkie: Preference distillation for large visual lan- guage models. arXiv preprint arXiv:2312.10665, 2023. 2
-
[29]
Mini-Gemini: Mining the Potential of Multi-modality Vision Language Models
Yanwei Li, Yuechen Zhang, Chengyao Wang, Zhisheng Zhong, Yixin Chen, Ruihang Chu, Shaoteng Liu, and Jiaya Jia. Mini-gemini: Mining the potential of multi-modality vision language models. arXiv:2403.18814, 2023. 9
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
Factual: A benchmark for faithful and consistent tex- tual scene graph parsing
Zhuang Li, Yuyang Chai, Terry Yue Zhuo, Lizhen Qu, Gholamreza Haffari, Fei Li, Donghong Ji, and Quan Hung Tran. Factual: A benchmark for faithful and consistent tex- tual scene graph parsing. arXiv preprint arXiv:2305.17497,
-
[31]
Flame: Factuality- aware alignment for large language models
Sheng-Chieh Lin, Luyu Gao, Barlas Oguz, Wenhan Xiong, Jimmy Lin, Scott Yih, and Xilun Chen. Flame: Factuality- aware alignment for large language models. Advances in Neural Information Processing Systems, 2024. 2
work page 2024
-
[32]
Mitigating Hallucination in Large Multi-Modal Models via Robust Instruction Tuning
Fuxiao Liu, Kevin Lin, Linjie Li, Jianfeng Wang, Yaser Ya- coob, and Lijuan Wang. Mitigating hallucination in large multi-modal models via robust instruction tuning. arXiv preprint arXiv:2306.14565, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. Advances in neural information processing systems, 2023. 1, 9
work page 2023
-
[34]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. In Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024. 6, 1, 7
work page 2024
-
[35]
Llavanext: Improved reasoning, ocr, and world knowledge, 2024
Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. Llavanext: Improved reasoning, ocr, and world knowledge, 2024. 1, 8, 9
work page 2024
-
[36]
A Survey on Hallucination in Large Vision-Language Models
Hanchao Liu, Wenyuan Xue, Yifei Chen, Dapeng Chen, Xiu- tian Zhao, Ke Wang, Liping Hou, Rongjun Li, and Wei Peng. A survey on hallucination in large vision-language models. arXiv preprint arXiv:2402.00253, 2024. 1, 9
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. In Eu- ropean Conference on Computer Vision, 2024. 3, 4, 1
work page 2024
-
[38]
Typicalness- aware learning for failure detection
Yijun Liu, Jiequan Cui, Zhuotao Tian, Senqiao Yang, Qing- dong He, Xiaoling Wang, and Jingyong Su. Typicalness- aware learning for failure detection. arXiv preprint arXiv:2411.01981, 2024. 9
-
[39]
NLTK: The Natural Language Toolkit
Edward Loper and Steven Bird. Nltk: The natural language toolkit. arXiv preprint cs/0205028, 2002. 2
work page internal anchor Pith review Pith/arXiv arXiv 2002
-
[40]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101, 2017. 6, 3
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[41]
Learn to explain: Multimodal reasoning via thought chains for science question answering
Pan Lu, Swaroop Mishra, Tanglin Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. Learn to explain: Multimodal reasoning via thought chains for science question answering. Advances in Neural Information Processing Systems, 2022. 2, 6, 5, 9
work page 2022
-
[42]
Simpo: Simple preference optimization with a reference-free reward
Yu Meng, Mengzhou Xia, and Danqi Chen. Simpo: Simple preference optimization with a reference-free reward. Ad- vances in Neural Information Processing Systems, 2024. 9
work page 2024
-
[43]
Counterfactual vqa: A cause- effect look at language bias
Yulei Niu, Kaihua Tang, Hanwang Zhang, Zhiwu Lu, Xian- Sheng Hua, and Ji-Rong Wen. Counterfactual vqa: A cause- effect look at language bias. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition ,
- [44]
-
[45]
Clip-dpo: Vision-language models as a source of preference for fixing hallucinations in lvlms
Yassine Ouali, Adrian Bulat, Brais Martinez, and Georgios Tzimiropoulos. Clip-dpo: Vision-language models as a source of preference for fixing hallucinations in lvlms. In European Conference on Computer Vision, 2024. 6
work page 2024
-
[46]
Smaug: Fixing Failure Modes of Preference Optimisation with DPO-Positive
Arka Pal, Deep Karkhanis, Samuel Dooley, Manley Roberts, Siddartha Naidu, and Colin White. Smaug: Fixing failure modes of preference optimisation with dpo-positive. arXiv preprint arXiv:2402.13228, 2024. 9
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[47]
Omni-dpo: A dual- perspective paradigm for dynamic preference learning of llms
Shangpin Peng, Weinong Wang, Zhuotao Tian, Senqiao Yang, Xing Wu, Haotian Xu, Chengquan Zhang, Takashi Isobe, Baotian Hu, and Min Zhang. Omni-dpo: A dual- perspective paradigm for dynamic preference learning of llms. arXiv preprint arXiv:2506.10054, 2025. 9
-
[48]
Tianyuan Qu, Longxiang Tang, Bohao Peng, Senqiao Yang, Bei Yu, and Jiaya Jia. Does your vision-language model get lost in the long video sampling dilemma? arXiv preprint arXiv:2503.12496, 2025. 9
-
[49]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. In International conference on machine learning, 2021. 3
work page 2021
-
[50]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. In International conference on machine learning, pages 8748–8763. PmLR, 2021. 9
work page 2021
-
[51]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christo- pher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. Advances in Neural Information Processing Systems, 2023. 2, 4, 9 10
work page 2023
-
[52]
Zero: Memory optimizations toward training trillion parameter models
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. Zero: Memory optimizations toward training trillion parameter models. In SC20: International Confer- ence for High Performance Computing, Networking, Storage and Analysis, 2020. 3
work page 2020
-
[53]
A Survey of Hallucination in Large Foundation Models
Vipula Rawte, Amit Sheth, and Amitava Das. A survey of hallucination in large foundation models. arXiv preprint arXiv:2309.05922, 2023. 1, 2, 9
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[55]
Object Hallucination in Image Captioning
Anna Rohrbach, Lisa Anne Hendricks, Kaylee Burns, Trevor Darrell, and Kate Saenko. Object hallucination in image cap- tioning. arXiv preprint arXiv:1809.02156, 2018. 2, 6, 8, 4, 5, 7, 9
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[56]
Data-augmented phrase-level alignment for mitigating object hallucination
Pritam Sarkar, Sayna Ebrahimi, Ali Etemad, Ahmad Beirami, Sercan ¨O Arık, and Tomas Pfister. Data-augmented phrase-level alignment for mitigating object hallucination. arXiv preprint arXiv:2405.18654, 2024. 6, 7
-
[57]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Rad- ford, and Oleg Klimov. Proximal policy optimization algo- rithms. arXiv preprint arXiv:1707.06347, 2017. 2
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[58]
Ex- plore the potential of clip for training-free open vocabulary semantic segmentation
Tong Shao, Zhuotao Tian, Hang Zhao, and Jingyong Su. Ex- plore the potential of clip for training-free open vocabulary semantic segmentation. In European Conference on Com- puter Vision, pages 139–156. Springer, 2024. 9
work page 2024
-
[59]
Towards vqa models that can read
Amanpreet Singh, Vivek Natarajan, Meet Shah, Yu Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, and Marcus Rohrbach. Towards vqa models that can read. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019. 2, 6, 8, 4, 5, 9
work page 2019
-
[60]
Fine-tuning language models for factuality
Katherine Tian, Eric Mitchell, Huaxiu Yao, Christopher D Manning, and Chelsea Finn. Fine-tuning language models for factuality. In The Twelfth International Conference on Learning Representations, 2023. 2
work page 2023
-
[61]
Learning shape-aware embedding for scene text detection
Zhuotao Tian, Michelle Shu, Pengyuan Lyu, Ruiyu Li, Chao Zhou, Xiaoyong Shen, and Jiaya Jia. Learning shape-aware embedding for scene text detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4234–4243, 2019. 9
work page 2019
-
[62]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[63]
AMBER: An LLM-free Multi-dimensional Benchmark for MLLMs Hallucination Evaluation
Junyang Wang, Yuhang Wang, Guohai Xu, Jing Zhang, Yukai Gu, Haitao Jia, Jiaqi Wang, Haiyang Xu, Ming Yan, Ji Zhang, et al. Amber: An llm-free multi-dimensional bench- mark for mllms hallucination evaluation. arXiv preprint arXiv:2311.07397, 2023. 2, 6, 7, 8, 5
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[64]
Declip: Decoupled learning for open- vocabulary dense perception
Junjie Wang, Bin Chen, Yulin Li, Bin Kang, Yichi Chen, and Zhuotao Tian. Declip: Decoupled learning for open- vocabulary dense perception. In Proceedings of the Com- puter Vision and Pattern Recognition Conference , pages 14824–14834, 2025. 9
work page 2025
-
[65]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution. arXiv preprint arXiv:2409.12191, 2024. 1, 9
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[66]
Noiseboost: Alleviating hallucination with noise perturbation for multimodal large language models
Kai Wu, Boyuan Jiang, Zhengkai Jiang, Qingdong He, Donghao Luo, Shengzhi Wang, Qingwen Liu, and Chengjie Wang. Noiseboost: Alleviating hallucination with noise perturbation for multimodal large language models. arXiv preprint arXiv:2405.20081, 2024. 6
-
[67]
Yike Wu, Yu Zhao, Shiwan Zhao, Ying Zhang, Xiaojie Yuan, Guoqing Zhao, and Ning Jiang. Overcoming language priors in visual question answering via distinguishing superficially similar instances. In Proceedings of the 29th International Conference on Computational Linguistics, 2022. 9
work page 2022
-
[68]
Embodied task planning with large language models
Zhenyu Wu, Ziwei Wang, Xiuwei Xu, Jiwen Lu, and Haibin Yan. Embodied task planning with large language models. arXiv preprint arXiv:2307.01848, 2023. 1
-
[69]
Detecting and mitigating hallucination in large vision language models via fine-grained ai feedback
Wenyi Xiao, Ziwei Huang, Leilei Gan, Wanggui He, Haoyuan Li, Zhelun Yu, Fangxun Shu, Hao Jiang, and Lin- chao Zhu. Detecting and mitigating hallucination in large vision language models via fine-grained ai feedback. arXiv preprint arXiv:2404.14233, 2024. 2, 3, 6, 7, 9
-
[70]
Shangyu Xing, Fei Zhao, Zhen Wu, Tuo An, Weihao Chen, Chunhui Li, Jianbing Zhang, and Xinyu Dai. Efuf: Efficient fine-grained unlearning framework for mitigating hallucina- tions in multimodal large language models. arXiv preprint arXiv:2402.09801, 2024. 6, 7, 9
-
[71]
Lidar-llm: Exploring the potential of large language models for 3d lidar understanding
Senqiao Yang, Jiaming Liu, Ray Zhang, Mingjie Pan, Zoey Guo, Xiaoqi Li, Zehui Chen, Peng Gao, Yandong Guo, and Shanghang Zhang. Lidar-llm: Exploring the potential of large language models for 3d lidar understanding. arXiv preprint arXiv:2312.14074, 2023. 9
-
[72]
An improved baseline for reasoning segmentation with large language model
Senqiao Yang, Tianyuan Qu, Xin Lai, Zhuotao Tian, Bohao Peng, Shu Liu, and Jiaya Jia. An improved baseline for reasoning segmentation with large language model. arXiv preprint arXiv:2312.17240, 2023
-
[73]
Visionzip: Longer is better but not necessary in vision language models
Senqiao Yang, Yukang Chen, Zhuotao Tian, Chengyao Wang, Jingyao Li, Bei Yu, and Jiaya Jia. Visionzip: Longer is better but not necessary in vision language models. arXiv preprint arXiv:2412.04467, 2024. 9
-
[74]
Unified language-driven zero-shot domain adaptation
Senqiao Yang, Zhuotao Tian, Li Jiang, and Jiaya Jia. Unified language-driven zero-shot domain adaptation. In Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 23407–23415, 2024. 9
work page 2024
-
[75]
Woodpecker: Hallucination correction for multimodal large language models
Shukang Yin, Chaoyou Fu, Sirui Zhao, Tong Xu, Hao Wang, Dianbo Sui, Yunhang Shen, Ke Li, Xing Sun, and Enhong Chen. Woodpecker: Hallucination correction for multimodal large language models. Science China Information Sciences,
-
[76]
Tianyu Yu, Yuan Yao, Haoye Zhang, Taiwen He, Yifeng Han, Ganqu Cui, Jinyi Hu, Zhiyuan Liu, Hai-Tao Zheng, Maosong Sun, et al. Rlhf-v: Towards trustworthy mllms via behavior alignment from fine-grained correctional human feedback. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024. 2, 6, 7
work page 2024
-
[77]
Rlaif-v: Aligning mllms through open-source 11 ai feedback for super gpt-4v trustworthiness
Tianyu Yu, Haoye Zhang, Yuan Yao, Yunkai Dang, Da Chen, Xiaoman Lu, Ganqu Cui, Taiwen He, Zhiyuan Liu, Tat-Seng Chua, et al. Rlaif-v: Aligning mllms through open-source 11 ai feedback for super gpt-4v trustworthiness. arXiv preprint arXiv:2405.17220, 2024. 3, 6, 5, 7, 9
-
[78]
MM-Vet: Evaluating Large Multimodal Models for Integrated Capabilities
Weihao Yu, Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Zicheng Liu, Xinchao Wang, and Lijuan Wang. Mm-vet: Evaluating large multimodal models for integrated capabilities. arXiv preprint arXiv:2308.02490, 2023. 2, 6, 8, 4, 9
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[79]
Less is more: Mitigat- ing multimodal hallucination from an eos decision perspec- tive
Zihao Yue, Liang Zhang, and Qin Jin. Less is more: Mitigat- ing multimodal hallucination from an eos decision perspec- tive. arXiv preprint arXiv:2402.14545, 2024. 6, 1
-
[80]
Automated multi-level prefer- ence for mllms
Mengxi Zhang, Wenhao Wu, Yu Lu, Yuxin Song, Kang Rong, Huanjin Yao, Jianbo Zhao, Fanglong Liu, Haocheng Feng, Jingdong Wang, et al. Automated multi-level prefer- ence for mllms. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. 2, 7
work page 2024
-
[81]
Omdet: Large-scale vision-language multi-dataset pre-training with multimodal detection network
Tiancheng Zhao, Peng Liu, and Kyusong Lee. Omdet: Large-scale vision-language multi-dataset pre-training with multimodal detection network. IET Computer Vision, 2024. 3
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.