LIME: Learning Intent-aware Camera Motion from Egocentric Video
Pith reviewed 2026-07-03 10:58 UTC · model grok-4.3
The pith
LIME learns to generate intent-driven camera poses from language and RGB by mining supervision in egocentric video.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
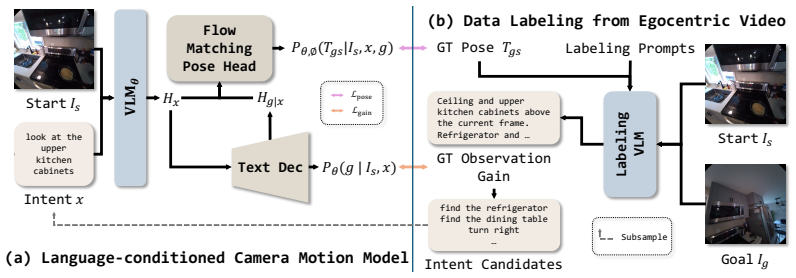
We formulate language-conditioned camera motion generation: given current RGB and a free-form natural-language intent, predict a relative target camera pose. Supervision is obtained by mining multi-intention camera-motion pairs from egocentric video. LIME combines an auto-regressive observation-gain output with a continuous flow-matching pose head, enabling joint prediction of semantic view gain and multi-hypothesis SE(3) targets. This design allows the model to learn active camera selection directly from passive recordings.
What carries the argument
LIME, a vision-language generator that pairs an auto-regressive observation-gain predictor with a continuous flow-matching pose head, trained on mined multi-intention camera-motion supervision from egocentric video.
If this is right
- Robots can select camera viewpoints that respond to free-form language at multiple semantic scales, from room entry to occluded detail.
- Passive egocentric videos become a scalable source of supervision for active perception without requiring active robot data collection.
- The flow-matching head enables the model to represent multiple plausible target poses consistent with the same intent and current view.
- Downstream robotic tasks that require intent-responsive view selection improve when camera motion is generated by LIME.
Where Pith is reading between the lines
- The same mining approach could be applied to generate longer sequences of camera motions rather than single-step targets.
- If human recording biases are present, performance may degrade when the robot's motion constraints differ from head-mounted camera trajectories.
- Integrating LIME-style camera control with existing vision-language navigation or manipulation policies could produce agents that jointly plan base motion, arm actions, and perception.
Load-bearing premise
Multi-intention camera-motion supervision mined from egocentric video supplies valid and sufficiently diverse training signal for language-conditioned pose prediction without systematic biases from human recording patterns.
What would settle it
A controlled robotic experiment in which LIME-selected poses produce no measurable gain over a language-agnostic baseline on an intent-driven inspection task would falsify the claim that the mined supervision is sufficient.
Figures











read the original abstract
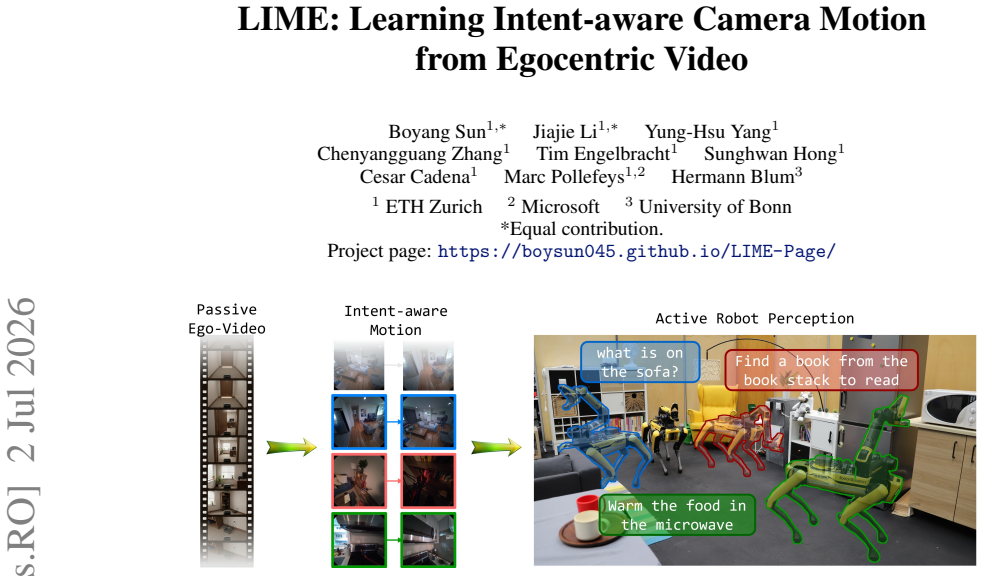
Autonomous robots often need to move their camera before they can act: to inspect an object, reveal an occluded region, or obtain a view that responds to a user's intent. While vision-language navigation translates instructions to base motion and vision-language-action policies map instructions to manipulation actions, language-conditioned camera motion remains comparatively underexplored as a first-class action. We formulate language-conditioned camera motion generation: given a current RGB observation and a free-form natural-language intent, predict a relative target camera pose for the next observation. This task is inherently non-trivial: viewpoint changes are driven by latent perceptual intentions, and a valid motion may operate at different semantic granularity, from entering a room to looking around a corner, inspecting a visible object, or revealing an occluded detail. To model this structure, we mine multi-intention camera-motion supervision from egocentric video, pairing plausible intents and observation-gain descriptions with relative SE(3) target poses. We propose LIME, a vision-language camera-motion generator that combines an auto-regressive observation-gain output with a continuous flow-matching pose head. This design lets the model jointly predict what the next view should reveal while representing multi-hypothesis target views. Across experiments and downstream robotic tasks, we show that LIME can learn to actively choose camera poses from passive human video, turning ordinary egocentric recordings into supervision for intent-aware active perception.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formulates language-conditioned camera motion generation as predicting a relative SE(3) target pose from current RGB and a free-form natural-language intent. It mines multi-intention supervision by automatically pairing plausible intents and observation-gain descriptions with relative poses extracted from egocentric video, then trains LIME, which combines an auto-regressive observation-gain predictor with a continuous flow-matching pose head. Experiments and downstream robotic tasks are reported to show that the resulting model can select camera poses from passive human video for intent-aware active perception.
Significance. If the central claim holds, the work would provide a scalable route to intent-aware active perception by converting abundant passive egocentric recordings into training targets, addressing the data scarcity that currently limits language-conditioned camera control relative to navigation or manipulation policies.
major comments (2)
- [Abstract / §3] Abstract and §3 (method): the load-bearing assumption that automatically mined (intent, observation-gain, relative SE(3) pose) tuples constitute unbiased and sufficiently diverse targets is not accompanied by any quantitative check (motion-histogram overlap, intent-coverage statistics, or cross-domain transfer gap) that would confirm the human-recording statistics do not systematically distort the learned flow-matching manifold.
- [Experiments] Experiments section: no ablation or analysis is described that isolates whether performance gains derive from the mined supervision versus the flow-matching architecture itself, leaving open whether the supervision source is the operative factor.
minor comments (2)
- [Method] Notation for the flow-matching head and the auto-regressive observation-gain module should be introduced with explicit equations rather than prose descriptions.
- [Figures] Figure captions and axis labels in the robotic-task results should explicitly state the evaluation metric and number of trials.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The two major comments highlight important aspects of validating the mined supervision and component contributions. We respond to each below and commit to revisions that directly address the concerns while preserving the core contributions of the work.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and §3 (method): the load-bearing assumption that automatically mined (intent, observation-gain, relative SE(3) pose) tuples constitute unbiased and sufficiently diverse targets is not accompanied by any quantitative check (motion-histogram overlap, intent-coverage statistics, or cross-domain transfer gap) that would confirm the human-recording statistics do not systematically distort the learned flow-matching manifold.
Authors: We agree that the manuscript would be strengthened by direct quantitative checks on the mined data distribution. The current validation relies primarily on downstream robotic task performance. In the revision we will add motion-histogram overlap statistics between the mined SE(3) poses and the source egocentric video, intent-coverage and diversity metrics across the mined tuples, and a brief cross-domain transfer experiment on a held-out video source. These additions will be placed in §3 and the experiments section. revision: yes
-
Referee: [Experiments] Experiments section: no ablation or analysis is described that isolates whether performance gains derive from the mined supervision versus the flow-matching architecture itself, leaving open whether the supervision source is the operative factor.
Authors: The flow-matching head was chosen specifically to accommodate the multi-hypothesis targets produced by multi-intent mining; the two elements are therefore coupled by design. Nevertheless, the referee's point is well taken. We will add an ablation in the revised experiments that trains an otherwise identical model on single-intent (or randomly paired) supervision while keeping the flow-matching head fixed, and a second ablation that replaces the flow-matching head with a deterministic regression head while retaining the multi-intent supervision. These results will clarify the relative contributions. revision: yes
Circularity Check
No circularity: supervision mined from external video; model trained on independent targets
full rationale
The paper formulates a language-conditioned pose prediction task and mines (intent, gain, SE(3)) tuples from passive egocentric recordings as training targets. No equations, fitted parameters, or self-citations are shown that would make the learned pose head equivalent to its own inputs by construction. The central claim rests on empirical performance on downstream robotic tasks using externally sourced video data, not on any definitional reduction or self-referential fit. This is the normal non-circular case for a data-driven robotics learning paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Egocentric video contains extractable pairs of natural-language intents and relative SE(3) camera motions that constitute valid supervision for intent-aware pose prediction.
Reference graph
Works this paper leans on
-
[1]
Siegwart, I
R. Siegwart, I. R. Nourbakhsh, and D. Scaramuzza.Introduction to autonomous mobile robots. MIT press, 2011
2011
-
[2]
Bajcsy, Y
R. Bajcsy, Y . Aloimonos, and J. K. Tsotsos. Revisiting active perception.Autonomous Robots, 42(2):177–196, 2018. 30
2018
-
[3]
M. F. Ahmed, K. Masood, V . Fremont, and I. Fantoni. Active slam: A review on last decade. Sensors, 23(19):8097, 2023
2023
-
[4]
J. A. Placed, J. Strader, H. Carrillo, N. Atanasov, V . Indelman, L. Carlone, and J. A. Castel- lanos. A survey on active simultaneous localization and mapping: State of the art and new frontiers.IEEE Transactions on Robotics, 39(3):1686–1705, 2023
2023
-
[5]
Lluvia, E
I. Lluvia, E. Lazkano, and A. Ansuategi. Active mapping and robot exploration: A survey. Sensors, 21(7):2445, 2021
2021
-
[6]
K. Li, M. Mantovani, R. J. Wood, L. Sabattini, and S. Gil. Motion-uncertainty-aware next- best-view planning for moving object reconstruction.arXiv preprint arXiv:2605.17593, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [7]
-
[8]
Zhang, K
J. Zhang, K. Wang, S. Wang, M. Li, H. Liu, S. Wei, Z. Wang, Z. Zhang, and H. Wang. Uni- navid: A video-based vision-language-action model for unifying embodied navigation tasks, 2024
2024
-
[9]
Y . Hong, Q. Wu, Y . Qi, C. Rodriguez-Opazo, and S. Gould. A recurrent vision-and-language bert for navigation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1643–1653, June 2021
2021
-
[10]
M. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. In Conference on Robot Learning, pages 2165–2183. PMLR, 2023
2023
-
[12]
Yamauchi
B. Yamauchi. A frontier-based approach for autonomous exploration. InProceedings 1997 IEEE International Symposium on Computational Intelligence in Robotics and Automation CIRA’97. ’Towards New Computational Principles for Robotics and Automation’, pages 146–
1997
-
[13]
D. S. Chaplot, M. Dalal, S. Gupta, J. Malik, and R. R. Salakhutdinov. Seal: Self-supervised embodied active learning using exploration and 3d consistency.Advances in neural informa- tion processing systems, 34:13086–13098, 2021
2021
- [14]
-
[15]
Schmid, M
L. Schmid, M. Pantic, R. Khanna, L. Ott, R. Siegwart, and J. Nieto. An efficient sampling- based method for online informative path planning in unknown environments.IEEE Robotics and Automation Letters, 5(2):1500–1507, 2020
2020
-
[16]
B. Sun, H. Chen, S. Leutenegger, C. Cadena, M. Pollefeys, and H. Blum. Frontiernet: Learning visual cues to explore.IEEE Robotics and Automation Letters, 10(7):6576–6583, 2025. doi: 10.1109/LRA.2025.3569122
- [17]
-
[18]
Y . Kompis, L. Bartolomei, R. Mascaro, L. Teixeira, and M. Chli. Informed Sampling Explo- ration Path Planner for 3D Reconstruction of Large Scenes.IEEE Robotics and Automation Letters, 6(4):7894–7901, 10 2021. ISSN 23773766. doi:10.1109/LRA.2021.3101856
-
[19]
J. Li, B. Sun, L. D. Giammarino, H. Blum, and M. Pollefeys. Actloc: Learning to lo- calize on the move via active viewpoint selection. In J. Lim, S. Song, and H.-W. Park, editors,Proceedings of The 9th Conference on Robot Learning, volume 305 ofProceed- ings of Machine Learning Research, pages 1225–1245. PMLR, 27–30 Sep 2025. URL https://proceedings.mlr.p...
2025
-
[20]
Zhang and D
Z. Zhang and D. Scaramuzza. Beyond point clouds: Fisher information field for active visual localization. pages 5986–5992. IEEE, 2019
2019
-
[21]
Chang, T
M. Chang, T. Gervet, M. Khanna, S. Yenamandra, D. Shah, S. Y . Min, K. Shah, C. Paxton, S. Gupta, D. Batra, et al. Goat: Go to any thing. 2024
2024
-
[22]
Zhang, L
J. Zhang, L. Dai, F. Meng, Q. Fan, X. Chen, K. Xu, and H. Wang. 3d-aware object goal navigation via simultaneous exploration and identification. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6672–6682, 2023
2023
-
[23]
Z. Zhou, Y . Hu, L. Zhang, Z. Li, and S. Chen. Beliefmapnav: 3d voxel-based belief map for zero-shot object navigation, 2025
2025
-
[24]
W. Xie, H. Jiang, Y . Zhu, J. Qian, and J. Xie. Naviformer: A spatio-temporal context-aware transformer for object navigation. InProceedings of the AAAI Conference on Artificial Intelli- gence, volume 39, pages 14708–14716, 2025
2025
-
[25]
J. Gu, E. Stefani, Q. Wu, J. Thomason, and X. Wang. Vision-and-language navigation: A survey of tasks, methods, and future directions. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7606–7623, 2022
2022
- [26]
-
[27]
Kawaharazuka, J
K. Kawaharazuka, J. Oh, J. Yamada, I. Posner, and Y . Zhu. Vision-language-action models for robotics: A review towards real-world applications.IEEE Access, 2025
2025
- [28]
- [29]
- [30]
-
[31]
Cheng, Y
A.-C. Cheng, Y . Ji, Z. Yang, X. Zou, J. Kautz, E. Biyik, H. Yin, S. Liu, and X. Wang. Navila: Legged robot vision-language-action model for navigation. InRSS, 2025
2025
- [32]
- [33]
-
[34]
OpenFrontier: General Navigation with Visual-Language Grounded Frontiers
E. Padilla, B. Sun, M. Pollefeys, and H. Blum. Openfrontier: General navigation with visual- language grounded frontiers.arXiv preprint arXiv:2603.05377, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [35]
-
[36]
D. Goetting, H. G. Singh, and A. Loquercio. End-to-end navigation with vision lan- guage models: Transforming spatial reasoning into question-answering.arXiv preprint arXiv:2411.05755, 2024
-
[37]
M. Habibpour and F. Afghah. History-augmented vision-language models for frontier-based zero-shot object navigation.arXiv preprint arXiv:2506.16623, 2025
-
[38]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al.π 0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [39]
- [40]
-
[41]
Y . Zou, C. Shi, W. Yu, H. Xue, J. Lv, Y . Pan, C. Wen, and C. Lu. Activeglasses: Learn- ing manipulation with active vision from ego-centric human demonstration.arXiv preprint arXiv:2604.08534, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [42]
- [43]
- [44]
- [45]
- [46]
-
[47]
N. Yokoyama, R. Ramrakhya, A. Das, D. Batra, and S. Ha. HM3D-OVON: A dataset and benchmark for open-vocabulary object goal navigation.arXiv preprint arXiv:2409.14296, 2024
-
[48]
A. Das, S. Datta, G. Gkioxari, S. Lee, D. Parikh, and D. Batra. Embodied question answering,
-
[49]
URLhttps://arxiv.org/abs/1711.11543
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
Majumdar, A
A. Majumdar, A. Ajay, X. Zhang, P. Putta, S. Yenamandra, M. Henaff, S. Silwal, P. Mcvay, O. Maksymets, S. Arnaud, K. Yadav, Q. Li, B. Newman, M. Sharma, V . Berges, S. Zhang, P. Agrawal, Y . Bisk, D. Batra, M. Kalakrishnan, F. Meier, C. Paxton, S. Sax, and A. Ra- jeswaran. Openeqa: Embodied question answering in the era of foundation models. InCon- ferenc...
2024
-
[51]
A. Z. Ren, J. Clark, A. Dixit, M. Itkina, A. Majumdar, and D. Sadigh. Explore until confident: Efficient exploration for embodied question answering. InRobotics: Science and Systems, 2024
2024
-
[52]
Jiang, Y
K. Jiang, Y . Liu, W. Chen, J. Luo, Z. Chen, L. Pan, G. Li, and L. Lin. Beyond the destina- tion: A novel benchmark for exploration-aware embodied question answering. InIEEE/CVF International Conference on Computer Vision (ICCV), 2025
2025
-
[53]
J. Koo, D. Choi, S. Youn, P. Y . Lee, and M. Sung. Toward ambulatory vision: Learn- ing visually-grounded active view selection, 2025. URLhttps://arxiv.org/abs/2512. 13250
2025
-
[54]
E3VS-Bench: A Benchmark for Viewpoint-Dependent Active Perception in 3D Gaussian Splatting Scenes
K. Sakamoto, T. Miyanishi, D. Azuma, S. Kurita, S. Morikuni, N. Chiba, M. Kawanabe, Y . Iwasawa, and Y . Matsuo. E3vs-bench: A benchmark for viewpoint-dependent active per- ception in 3d gaussian splatting scenes, 2026. URLhttps://arxiv.org/abs/2604.17969
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[55]
S. Bai, Y . Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Ge, W. Ge, Z. Guo, Q. Huang, J. Huang, F. Huang, B. Hui, S. Jiang, Z. Li, M. Li, M. Li, K. Li, Z. Lin, J. Lin, X. Liu, J. Liu, C. Liu, Y . Liu, D. Liu, S. Liu, D. Lu, R. Luo, C. Lv, R. Men, L. Meng, X. Ren, X. Ren, S. Song, Y . Sun, J. Tang, J. Tu, J. Wan, P. Wang, P. Wang,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
Y . Zhou, C. Barnes, J. Lu, J. Yang, and H. Li. On the continuity of rotation representations in neural networks. In2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5738–5746, 2019. doi:10.1109/CVPR.2019.00589
-
[57]
Back to Basics: Let Denoising Generative Models Denoise
T. Li and K. He. Back to basics: Let denoising generative models denoise.arXiv preprint arXiv:2511.13720, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[58]
Grauman, A
K. Grauman, A. Westbury, L. Torresani, K. Kitani, J. Malik, T. Afouras, K. Ashutosh, V . Baiyya, S. Bansal, B. Boote, et al. Ego-exo4d: Understanding skilled human activity from first-and third-person perspectives. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19383–19400, 2024
2024
-
[59]
L. Ma, Y . Ye, F. Hong, V . Guzov, Y . Jiang, R. Postyeni, L. Pesqueira, A. Gamino, V . Baiyya, H. J. Kim, et al. Nymeria: A massive collection of multimodal egocentric daily motion in the wild. InEuropean Conference on Computer Vision, pages 445–465. Springer, 2024
2024
-
[60]
Damen, H
D. Damen, H. Doughty, G. M. Farinella, S. Fidler, A. Furnari, E. Kazakos, D. Moltisanti, J. Munro, T. Perrett, W. Price, et al. The epic-kitchens dataset: Collection, challenges and baselines.IEEE Transactions on Pattern Analysis and Machine Intelligence, 43(11):4125– 4141, 2020
2020
-
[61]
Egoscale: Scaling dexterous manipulation with diverse egocentric human data,
R. Zheng, D. Niu, Y . Xie, J. Wang, M. Xu, Y . Jiang, F. Casta˜neda, F. Hu, Y . L. Tan, L. Fu, et al. Egoscale: Scaling dexterous manipulation with diverse egocentric human data.arXiv preprint arXiv:2602.16710, 2026
-
[62]
Kareer, D
S. Kareer, D. Patel, R. Punamiya, P. Mathur, S. Cheng, C. Wang, J. Hoffman, and D. Xu. Egomimic: Scaling imitation learning via egocentric video. In2025 IEEE International Con- ference on Robotics and Automation (ICRA), pages 13226–13233. IEEE, 2025
2025
-
[63]
H. Lin, S. Chen, J. H. Liew, D. Y . Chen, Z. Li, G. Shi, J. Feng, and B. Kang. Depth anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[64]
M. Han, L. Ma, K. Zhumakhanova, E. Radionova, J. Zhang, X. Chang, X. Liang, and I. Laptev. Roomtour3d: Geometry-aware video-instruction tuning for embodied navigation. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 27586– 27596, 2025. 34
2025
-
[65]
M. T. I. SpatialVerse Research Team. Interiorgs: A 3d gaussian splatting dataset of se- mantically labeled indoor scenes.https://huggingface.co/datasets/spatialverse/ InteriorGS, 2025
2025
-
[66]
Yeshwanth, Y .-C
C. Yeshwanth, Y .-C. Liu, M. Nießner, and A. Dai. Scannet++: A high-fidelity dataset of 3d indoor scenes. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 12–22, 2023
2023
-
[67]
H. Chen, B. Sun, A. Zhang, M. Pollefeys, and S. Leutenegger. VidBot: Learning generalizable 3d actions from in-the-wild 2d human videos for zero-shot robotic manipulation. 2025
2025
-
[68]
R. Wang, S. Xu, Y . Dong, Y . Deng, J. Xiang, Z. Lv, G. Sun, X. Tong, and J. Yang. Moge- 2: Accurate monocular geometry with metric scale and sharp details.Advances in Neural Information Processing Systems, 38:35928–35959, 2026
2026
-
[69]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning, 2023. URLhttps://arxiv.org/abs/2306. 03310
2023
-
[70]
Black, N
Physical Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner...
2025
-
[71]
J. Wang, M. Chen, S. Zhang, N. Karaev, J. Sch¨onberger, P. Labatut, P. Bojanowski, D. Novotny, A. Vedaldi, and C. Rupprecht. VGGT-Ω. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026. 35
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.