Point Tracking Improves World Action Models
Pith reviewed 2026-05-25 03:49 UTC · model grok-4.3
The pith
A joint diffusion model that predicts both pixels and 2D point tracks captures long-horizon robot dynamics more reliably than pixel-only baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
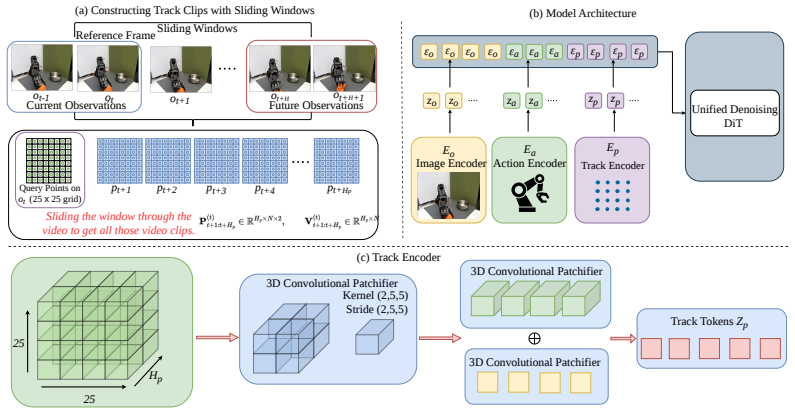
JOPAT predicts latent visual observations, 2D point tracks with visibility, and actions in a single denoising diffusion transformer; tracks supply an explicit motion representation that captures long-horizon dynamics and remains robust under occlusion or partial out-of-frame motion, delivering greater utility than pixel appearance modeling alone.
What carries the argument
JOPAT, the joint denoising diffusion transformer trained to output pixels, point tracks with visibility, and actions together.
If this is right
- Performance improves most on long-horizon tasks that include occlusion, object interaction, and off-screen motion.
- Explicit tracks supply a motion signal that disentangles dynamics from nuisance visual factors such as lighting and texture.
- The same training data and supervision budget suffice for both track prediction and pixel prediction.
- Robot policy learning benefits because world-action models become more stable under realistic visual variation.
Where Pith is reading between the lines
- The same joint objective could be applied to other diffusion-based world models to test whether tracks improve planning horizons beyond the tested benchmarks.
- Visibility prediction within the tracks may allow selective use of motion cues only when points remain reliable, potentially extending the method to highly dynamic scenes.
- If point tracks prove cheap to obtain at inference time, they could serve as an auxiliary input for downstream controllers without retraining the full model.
Load-bearing premise
The joint denoising objective can generate accurate point tracks without extra labeled track data or supervision beyond pixel baselines, and the motion signal outweighs any loss in pixel prediction accuracy.
What would settle it
Train the joint model and a pixel-only baseline on the same data; if the joint model produces inaccurate tracks on held-out sequences or shows no gain on long-horizon tasks with occlusion and off-screen motion, the central claim fails.
Figures




read the original abstract
Robot policy learning benefits from world-action models that capture environment dynamics, but pixel-level prediction entangles dynamics with nuisance factors such as lighting and texture, making learned representations vulnerable to task-irrelevant visual variation. We propose JOPAT, a JOint Pixel-And-Track World-Action Model that predicts latent visual observations, 2D point tracks with visibility, and actions in a single denoising diffusion transformer. The key insight is that tracks provide an explicit representation of motion that captures long-horizon dynamics and remains robust under occlusion or partial out-of-frame motion, offering greater utility than modeling pixel appearance alone. On LIBERO and real-world LeRobot tasks, JOPAT improves over pixel-based baselines, with the largest gains on long-horizon tasks involving occlusion, object interaction, and off-screen motion.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes JOPAT, a joint pixel-and-track world-action model using a single denoising diffusion transformer to predict latent visual observations, 2D point tracks with visibility, and actions. The central claim is that explicit point tracks provide a robust representation of long-horizon dynamics that is less entangled with appearance nuisances than pixel-only modeling, yielding performance gains over baselines on LIBERO and real-world LeRobot tasks, especially those involving occlusion, object interaction, and off-screen motion.
Significance. If the gains are shown to arise from the motion representation rather than model capacity and if the tracks are verifiably accurate, the approach would offer a concrete way to improve world models for robotics by separating dynamics from lighting/texture variation. The joint diffusion formulation is a natural extension of existing pixel-based world models.
major comments (2)
- [Abstract] Abstract: The abstract states performance gains on named benchmarks but supplies no quantitative numbers, baseline details, statistical tests, or ablation results, so the data-to-claim link cannot be evaluated.
- [Method section] Method section: The joint denoising objective is presented without an explicit track loss term, weighting schedule, or auxiliary supervision signal (e.g., visibility classification or flow consistency) for the point tracks; this leaves open whether the high-dimensional pixel reconstruction term dominates and whether accurate tracks are produced without extra labeled track data.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below and will revise the manuscript to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract states performance gains on named benchmarks but supplies no quantitative numbers, baseline details, statistical tests, or ablation results, so the data-to-claim link cannot be evaluated.
Authors: We agree that the abstract would be strengthened by quantitative support. The full paper contains the requested details (success rates, baselines, and ablations on LIBERO and LeRobot). In revision we will condense key numbers, baseline names, and a brief reference to the point-track ablation into the abstract while respecting length constraints. revision: yes
-
Referee: [Method section] Method section: The joint denoising objective is presented without an explicit track loss term, weighting schedule, or auxiliary supervision signal (e.g., visibility classification or flow consistency) for the point tracks; this leaves open whether the high-dimensional pixel reconstruction term dominates and whether accurate tracks are produced without extra labeled track data.
Authors: The diffusion transformer is trained end-to-end on a joint denoising objective over the concatenated latent (pixels + tracks + visibility + actions). Point tracks and visibility are obtained from the same data sources used for pixel prediction (simulation ground truth or off-the-shelf trackers on real video), so no additional labeled track data is introduced. We will expand the method section with the precise combined loss formulation, per-component weighting schedule, and explicit statement that track supervision is provided by the input data rather than an auxiliary loss. revision: yes
Circularity Check
No significant circularity; empirical comparison is self-contained
full rationale
The paper introduces JOPAT as a joint denoising diffusion transformer predicting pixels, 2D point tracks with visibility, and actions. Its central claim rests on reported empirical gains versus pixel-only baselines on LIBERO and LeRobot tasks, with emphasis on long-horizon robustness. No equations, fitted parameters, or self-citations are shown that reduce any prediction or result to an input by construction. The work contains no load-bearing self-citation chains, uniqueness theorems, or ansatzes smuggled via prior work; the improvement is presented as an experimental outcome rather than a definitional equivalence.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
JOPAT jointly denoises action tokens, future visual-latent tokens, and track tokens in a shared sequence... Lp is applied only to 2D coordinates. Visibility is predicted by a separate head and supervised with binary cross entropy
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Sliding-window track construction uses the current frame as the reference image for grid query points... 25×25 grid, N=625
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Lucy Xiaoyang Shi, James Tanner, Quan Vuong, Anna Walling, Haohuan Wang, and Ury Zhilinsky. π0: A visi...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
RT-1: Robotics Transformer for Real-World Control at Scale
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, et al. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
Chilam Cheang, Sijin Chen, Zhongren Cui, Yingdong Hu, Liqun Huang, Tao Kong, Hang Li, Yifeng Li, Yuxiao Liu, Xiao Ma, et al. Gr-3 technical report.arXiv preprint arXiv:2507.15493, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Large VLM-based Vision-Language-Action Models for Robotic Manipulation: A Survey
Rui Shao, Wei Li, Lingsen Zhang, Renshan Zhang, Zhiyang Liu, Ran Chen, and Liqiang Nie. Large vlm-based vision-language-action models for robotic manipulation: A survey.arXiv preprint arXiv:2508.13073, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics
Mustafa Shukor, Dana Aubakirova, Francesco Capuano, Pepijn Kooijmans, Steven Palma, Adil Zouitine, Michel Aractingi, Caroline Pascal, Martino Russi, Andres Marafioti, et al. Smolvla: A vision-language-action model for affordable and efficient robotics.arXiv preprint arXiv:2506.01844, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Pure vision language action (vla) models: A comprehensive survey.arXiv preprint arXiv:2509.19012,
Dapeng Zhang, Jing Sun, Chenghui Hu, Xiaoyan Wu, Zhenlong Yuan, Rui Zhou, Fei Shen, and Qingguo Zhou. Pure vision language action (vla) models: A comprehensive survey.arXiv preprint arXiv:2509.19012, 2025. 10
-
[9]
Rt-2: Vision-language-action models transfer web knowledge to robotic control
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning, pages 2165–2183. PMLR, 2023
2023
-
[10]
Vlatest: Testing and evaluating vision-language-action models for robotic manipulation.Proceedings of the ACM on Software Engineering, 2(FSE):1615–1638, 2025
Zhijie Wang, Zhehua Zhou, Jiayang Song, Yuheng Huang, Zhan Shu, and Lei Ma. Vlatest: Testing and evaluating vision-language-action models for robotic manipulation.Proceedings of the ACM on Software Engineering, 2(FSE):1615–1638, 2025
2025
-
[11]
Borong Zhang, Jiahao Li, Jiachen Shen, Yishuai Cai, Yuhao Zhang, Yuanpei Chen, Juntao Dai, Jiaming Ji, and Yaodong Yang. Vla-arena: An open-source framework for benchmarking vision-language-action models.arXiv preprint arXiv:2512.22539, 2025
-
[12]
Aiden Swann, Lachlain McGranahan, Hugo Buurmeijer, Monroe Kennedy III, and Mac Schwa- ger. Sparse autoencoders reveal interpretable and steerable features in vla models.arXiv preprint arXiv:2603.19183, 2026
-
[13]
Shresth Grover, Akshay Gopalkrishnan, Bo Ai, Henrik I Christensen, Hao Su, and Xuan- lin Li. Enhancing generalization in vision-language-action models by preserving pretrained representations.arXiv preprint arXiv:2509.11417, 2025
-
[14]
What matters in building vision–language–action models for generalist robots.Nature Machine Intelligence, pages 1–15, 2026
Xinghang Li, Peiyan Li, Long Qian, Minghuan Liu, Dong Wang, Jirong Liu, Bingyi Kang, Xiao Ma, Xinlong Wang, Di Guo, et al. What matters in building vision–language–action models for generalist robots.Nature Machine Intelligence, pages 1–15, 2026
2026
-
[16]
Unified 4D World Action Modeling from Video Priors with Asynchronous Denoising
Jun Guo, Qiwei Li, Peiyan Li, Zilong Chen, Nan Sun, Yifei Su, Heyun Wang, Yuan Zhang, Xinghang Li, and Huaping Liu. Unified 4d world action modeling from video priors with asynchronous denoising.arXiv preprint arXiv:2604.26694, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
Jiayi Chen, Wenxuan Song, Pengxiang Ding, Ziyang Zhou, Han Zhao, Feilong Tang, Donglin Wang, and Haoang Li. Unified diffusion vla: Vision-language-action model via joint discrete denoising diffusion process.arXiv preprint arXiv:2511.01718, 2025
-
[18]
HybridVLA: Collaborative Diffusion and Autoregression in a Unified Vision-Language-Action Model
Jiaming Liu, Hao Chen, Pengju An, Zhuoyang Liu, Renrui Zhang, Chenyang Gu, Xiaoqi Li, Ziyu Guo, Sixiang Chen, Mengzhen Liu, et al. Hybridvla: Collaborative diffusion and autoregression in a unified vision-language-action model.arXiv preprint arXiv:2503.10631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Diva: Discrete diffusion vision-language-action models for parallelized action generation
Xiufeng Song, Yiran Qin, Yan Tai, Li Kang, Heng Zhou, Siqi Luo, Jiwen Yu, Ling Yang, Philip Torr, LEI BAI, et al. Diva: Discrete diffusion vision-language-action models for parallelized action generation
-
[20]
John Won, Kyungmin Lee, Huiwon Jang, Dongyoung Kim, and Jinwoo Shin. Dual- stream diffusion for world-model augmented vision-language-action model.arXiv preprint arXiv:2510.27607, 2025
-
[21]
Unified vision-language-action model.arXiv preprint arXiv:2506.19850,
Yuqi Wang, Xinghang Li, Wenxuan Wang, Junbo Zhang, Yingyan Li, Yuntao Chen, Xin- long Wang, and Zhaoxiang Zhang. Unified vision-language-action model.arXiv preprint arXiv:2506.19850, 2025
-
[22]
Vipra: Video prediction for robot actions.arXiv preprint arXiv:2511.07732, 2025
Sandeep Routray, Hengkai Pan, Unnat Jain, Shikhar Bahl, and Deepak Pathak. Vipra: Video prediction for robot actions.arXiv preprint arXiv:2511.07732, 2025
-
[23]
Fangqi Zhu, Zhengyang Yan, Zicong Hong, Quanxin Shou, Xiao Ma, and Song Guo. Wmpo: World model-based policy optimization for vision-language-action models.arXiv preprint arXiv:2511.09515, 2025
-
[24]
Warpd: World model assisted reactive policy diffusion.arXiv preprint arXiv:2410.14040, 2024
Shashank Hegde, Satyajeet Das, Gautam Salhotra, and Gaurav S Sukhatme. Warpd: World model assisted reactive policy diffusion.arXiv preprint arXiv:2410.14040, 2024. 11
-
[25]
DreamVLA: A Vision-Language-Action Model Dreamed with Comprehensive World Knowledge
Wenyao Zhang, Hongsi Liu, Zekun Qi, Yunnan Wang, Xinqiang Yu, Jiazhao Zhang, Runpei Dong, Jiawei He, Fan Lu, He Wang, et al. Dreamvla: a vision-language-action model dreamed with comprehensive world knowledge.arXiv preprint arXiv:2507.04447, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
World Action Models are Zero-shot Policies
Seonghyeon Ye, Yunhao Ge, Kaiyuan Zheng, Shenyuan Gao, Sihyun Yu, George Kurian, Suneel Indupuru, You Liang Tan, Chuning Zhu, Jiannan Xiang, et al. World action models are zero-shot policies.arXiv preprint arXiv:2602.15922, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[27]
AIM: Intent-Aware Unified world action Modeling with Spatial Value Maps
Liaoyuan Fan, Zetian Xu, Chen Cao, Wenyao Zhang, Mingqi Yuan, and Jiayu Chen. Aim: Intent- aware unified world action modeling with spatial value maps.arXiv preprint arXiv:2604.11135, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
A step toward world models: A survey on robotic manipulation.arXiv preprint arXiv:2511.02097, 2025
Peng-Fei Zhang, Ying Cheng, Xiaofan Sun, Shijie Wang, Fengling Li, Lei Zhu, and Heng Tao Shen. A step toward world models: A survey on robotic manipulation.arXiv preprint arXiv:2511.02097, 2025
-
[29]
A comprehensive survey on world models for embodied ai.arXiv preprint arXiv:2510.16732, 2025
Xinqing Li, Xin He, Le Zhang, Min Wu, Xiaoli Li, and Yun Liu. A comprehensive survey on world models for embodied ai.arXiv preprint arXiv:2510.16732, 2025
-
[30]
Unleashing Large-Scale Video Generative Pre-training for Visual Robot Manipulation
Hongtao Wu, Ya Jing, Chilam Cheang, Guangzeng Chen, Jiafeng Xu, Xinghang Li, Minghuan Liu, Hang Li, and Tao Kong. Unleashing large-scale video generative pre-training for visual robot manipulation.arXiv preprint arXiv:2312.13139, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
Cosmos World Foundation Model Platform for Physical AI
Niket Agarwal, Arslan Ali, Maciej Bala, Yogesh Balaji, Erik Barker, Tiffany Cai, Prithvijit Chattopadhyay, Yongxin Chen, Yin Cui, Yifan Ding, et al. Cosmos world foundation model platform for physical ai.arXiv preprint arXiv:2501.03575, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
GR-2: A Generative Video-Language-Action Model with Web-Scale Knowledge for Robot Manipulation
Chi-Lam Cheang, Guangzeng Chen, Ya Jing, Tao Kong, Hang Li, Yifeng Li, Yuxiao Liu, Hongtao Wu, Jiafeng Xu, Yichu Yang, et al. Gr-2: A generative video-language-action model with web-scale knowledge for robot manipulation.arXiv preprint arXiv:2410.06158, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
R3M: A Universal Visual Representation for Robot Manipulation
Suraj Nair, Aravind Rajeswaran, Vikash Kumar, Chelsea Finn, and Abhinav Gupta. R3m: A universal visual representation for robot manipulation.arXiv preprint arXiv:2203.12601, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[34]
Robot learning with sensorimotor pre-training
Ilija Radosavovic, Baifeng Shi, Letian Fu, Ken Goldberg, Trevor Darrell, and Jitendra Malik. Robot learning with sensorimotor pre-training. InConference on Robot Learning, pages 683–693. PMLR, 2023
2023
-
[35]
The unsur- prising effectiveness of pre-trained vision models for control
Simone Parisi, Aravind Rajeswaran, Senthil Purushwalkam, and Abhinav Gupta. The unsur- prising effectiveness of pre-trained vision models for control. Ininternational conference on machine learning, pages 17359–17371. PMLR, 2022
2022
-
[36]
Teleportation, simulation, or human video? data utilization law for robot manipulation
Chenhao Shi, Yichen Zhu, Junjie Wen, Yefei Chen, Ziang Liu, Faming Fang, and Yi Xu. Teleportation, simulation, or human video? data utilization law for robot manipulation
-
[37]
Causal video models are data-efficient robot policy learners.Rhoda AI Blog, 2026
Rhoda AI Team. Causal video models are data-efficient robot policy learners.Rhoda AI Blog, 2026
2026
-
[38]
Learning an actionable discrete diffusion policy via large-scale actionless video pre-training.Advances in Neural Information Processing Systems, 37:31124–31153, 2024
Haoran He, Chenjia Bai, Ling Pan, Weinan Zhang, Bin Zhao, and Xuelong Li. Learning an actionable discrete diffusion policy via large-scale actionless video pre-training.Advances in Neural Information Processing Systems, 37:31124–31153, 2024
2024
-
[39]
Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
2023
-
[40]
Unsupervised learning for physical in- teraction through video prediction.Advances in neural information processing systems, 29, 2016
Chelsea Finn, Ian Goodfellow, and Sergey Levine. Unsupervised learning for physical in- teraction through video prediction.Advances in neural information processing systems, 29, 2016
2016
-
[41]
Stochastic Variational Video Prediction
Mohammad Babaeizadeh, Chelsea Finn, Dumitru Erhan, Roy H Campbell, and Sergey Levine. Stochastic variational video prediction.arXiv preprint arXiv:1710.11252, 2017. 12
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[42]
Genie: Generative interactive environments
Jake Bruce, Michael D Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, et al. Genie: Generative interactive environments. InForty-first International Conference on Machine Learning, 2024
2024
-
[43]
Pixel motion diffusion is what we need for robot control.arXiv preprint arXiv:2509.22652, 2025
E-Ro Nguyen, Yichi Zhang, Kanchana Ranasinghe, Xiang Li, and Michael S Ryoo. Pixel motion diffusion is what we need for robot control.arXiv preprint arXiv:2509.22652, 2025
-
[44]
Pixel motion as universal representation for robot control.arXiv preprint arXiv:2505.07817, 2025
Kanchana Ranasinghe, Xiang Li, E-Ro Nguyen, Cristina Mata, Jongwoo Park, and Michael S Ryoo. Pixel motion as universal representation for robot control.arXiv preprint arXiv:2505.07817, 2025
-
[45]
Translating flow to policy via hindsight online imitation.arXiv preprint arXiv:2512.19269, 2025
Yitian Zheng, Zhangchen Ye, Weijun Dong, Shengjie Wang, Yuyang Liu, Chongjie Zhang, Chuan Wen, and Yang Gao. Translating flow to policy via hindsight online imitation.arXiv preprint arXiv:2512.19269, 2025
-
[46]
Track2act: Predicting point tracks from internet videos enables generalizable robot manipulation
Homanga Bharadhwaj, Roozbeh Mottaghi, Abhinav Gupta, and Shubham Tulsiani. Track2act: Predicting point tracks from internet videos enables generalizable robot manipulation. In European Conference on Computer Vision, pages 306–324. Springer, 2024
2024
-
[47]
Any-point Trajectory Modeling for Policy Learning
Chuan Wen, Xingyu Lin, John So, Kai Chen, Qi Dou, Yang Gao, and Pieter Abbeel. Any-point trajectory modeling for policy learning.arXiv preprint arXiv:2401.00025, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[48]
Adam Hung, Bardienus Pieter Duisterhof, and Jeffrey Ichnowski. 3pointr: 3d point tracks for robot manipulation pretraining from casual videos.arXiv preprint arXiv:2603.08485, 2026
-
[49]
arXiv preprint arXiv:2601.03782 (2026)
Wenlong Huang, Yu-Wei Chao, Arsalan Mousavian, Ming-Yu Liu, Dieter Fox, Kaichun Mo, and Li Fei-Fei. Pointworld: Scaling 3d world models for in-the-wild robotic manipulation. arXiv preprint arXiv:2601.03782, 2026
-
[50]
Karthik Dharmarajan, Wenlong Huang, Jiajun Wu, Li Fei-Fei, and Ruohan Zhang. Dream2flow: Bridging video generation and open-world manipulation with 3d object flow.arXiv preprint arXiv:2512.24766, 2025
-
[51]
Gen2Act: Human Video Generation in Novel Scenarios enables Generalizable Robot Manipulation
Homanga Bharadhwaj, Debidatta Dwibedi, Abhinav Gupta, Shubham Tulsiani, Carl Doer- sch, Ted Xiao, Dhruv Shah, Fei Xia, Dorsa Sadigh, and Sean Kirmani. Gen2act: Human video generation in novel scenarios enables generalizable robot manipulation.arXiv preprint arXiv:2409.16283, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[52]
ReKep: Spatio-Temporal Reasoning of Relational Keypoint Constraints for Robotic Manipulation
Wenlong Huang, Chen Wang, Yunzhu Li, Ruohan Zhang, and Li Fei-Fei. Rekep: Spatio- temporal reasoning of relational keypoint constraints for robotic manipulation.arXiv preprint arXiv:2409.01652, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[53]
VoxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models
W Huang, C Wang, R Zhang, Y Li, J Wu, and L V oxposer Fei-Fei. Composable 3d value maps for robotic manipulation with language models. arxiv 2023.arXiv preprint arXiv:2307.05973
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[54]
Fangchen Liu, Kuan Fang, Pieter Abbeel, and Sergey Levine. Moka: Open-world robotic manipulation through mark-based visual prompting.arXiv preprint arXiv:2403.03174, 2024
-
[55]
Jianshu Hu, Lidi Wang, Shujia Li, Yunpeng Jiang, Xiao Li, Paul Weng, and Yutong Ban. Generalizable coarse-to-fine robot manipulation via language-aligned 3d keypoints.arXiv preprint arXiv:2509.23575, 2025
-
[56]
Tap-vid: A benchmark for tracking any point in a video, 2023
Carl Doersch, Ankush Gupta, Larisa Markeeva, Adrià Recasens, Lucas Smaira, Yusuf Aytar, João Carreira, Andrew Zisserman, and Yi Yang. Tap-vid: A benchmark for tracking any point in a video, 2023. URLhttps://arxiv.org/abs/2211.03726
-
[57]
Cotracker3: Simpler and better point tracking by pseudo-labelling real videos
Nikita Karaev, Iurii Makarov, Jianyuan Wang, Natalia Neverova, Andrea Vedaldi, and Christian Rupprecht. Cotracker3: Simpler and better point tracking by pseudo-labelling real videos, 2024. URLhttps://arxiv.org/abs/2410.11831
-
[58]
The un- surprising effectiveness of pre-trained vision models for control
Simone Parisi, Aravind Rajeswaran, Senthil Purushwalkam, and Abhinav Gupta. The un- surprising effectiveness of pre-trained vision models for control. InProceedings of the 39th International Conference on Machine Learning, pages 17359–17371. PMLR, 2022. 13
2022
-
[59]
R3m: A universal visual representation for robot manipulation
Suraj Nair, Aravind Rajeswaran, Vikash Kumar, Chelsea Finn, and Abhinav Gupta. R3m: A universal visual representation for robot manipulation. InConference on Robot Learning, pages 892–909. PMLR, 2023
2023
-
[60]
Masked visual pre-training for motor control.arXiv preprint arXiv:2203.06173, 2022
Tete Xiao, Ilija Radosavovic, Trevor Darrell, and Jitendra Malik. Masked visual pre-training for motor control.arXiv preprint arXiv:2203.06173, 2022
-
[61]
Reinforcement learning with action-free pre-training from videos
Younggyo Seo, Kimin Lee, Stephen L James, and Pieter Abbeel. Reinforcement learning with action-free pre-training from videos. InInternational Conference on Machine Learning, pages 19561–19579. PMLR, 2022
2022
-
[62]
Unleashing large-scale video generative pre-training for visual robot manipulation
Hongtao Wu, Ya Jing, Chilam Cheang, Guangzeng Chen, Jiafeng Xu, Xinghang Li, Minghuan Liu, Hang Li, and Tao Kong. Unleashing large-scale video generative pre-training for visual robot manipulation. InThe Twelfth International Conference on Learning Representations,
-
[63]
URLhttps://openreview.net/forum?id=NxoFmGgWC9
-
[64]
villa-X: Enhancing Latent Action Modeling in Vision-Language-Action Models
Xiaoyu Chen, Hangxing Wei, Pushi Zhang, Chuheng Zhang, Kaixin Wang, Yanjiang Guo, Rushuai Yang, Yucen Wang, Xinquan Xiao, Li Zhao, et al. Villa-x: enhancing latent action modeling in vision-language-action models.arXiv preprint arXiv:2507.23682, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[65]
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Alexander Khazatsky, Karl Pertsch, Suraj Nair, Ashwin Balakrishna, Sudeep Dasari, Siddharth Karamcheti, et al. Droid: A large-scale in-the-wild robot manipulation dataset.arXiv preprint arXiv:2403.12945, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[66]
Openvid-1m: A large-scale high-quality dataset for text-to-video generation
Kepan Nan, Rui Xie, Penghao Zhou, Tiehan Fan, Zhenheng Yang, Zhijie Chen, Xiang Li, Jian Yang, and Ying Tai. Openvid-1m: A large-scale high-quality dataset for text-to-video generation. InInternational Conference on Learning Representations, 2025
2025
-
[67]
Diffusion policy: Visuomotor policy learning via action diffusion,
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion,
-
[68]
URLhttps://arxiv.org/abs/2303.04137
work page internal anchor Pith review Pith/arXiv arXiv
-
[69]
Octo: An Open-Source Generalist Robot Policy
Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, Jianlan Luo, You Liang Tan, Lawrence Yunliang Chen, Pannag Sanketi, Quan Vuong, Ted Xiao, Dorsa Sadigh, Chelsea Finn, and Sergey Levine. Octo: An open-source generalist robot policy, 2024. URL https://arxiv.org/abs/2405.12213
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[70]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn. Openvla: An open-source vision-language-action model, 2024. URL https://arxiv. org/abs/...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[71]
FAST: Efficient Action Tokenization for Vision-Language-Action Models
Karl Pertsch, Kyle Stachowicz, Brian Ichter, Danny Driess, Suraj Nair, Quan Vuong, Oier Mees, Chelsea Finn, and Sergey Levine. Fast: Efficient action tokenization for vision-language-action models, 2025. URLhttps://arxiv.org/abs/2501.09747
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[72]
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Manuel Y . Galliker, Dibya Ghosh, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Devin LeBlanc, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsc...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[73]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Moo Jin Kim, Chelsea Finn, and Percy Liang. Fine-tuning vision-language-action models: Optimizing speed and success, 2025. URLhttps://arxiv.org/abs/2502.19645
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[74]
SpatialVLA: Exploring Spatial Representations for Visual-Language-Action Model
Delin Qu, Haoming Song, Qizhi Chen, Yuanqi Yao, Xinyi Ye, Yan Ding, Zhigang Wang, JiaYuan Gu, Bin Zhao, Dong Wang, and Xuelong Li. Spatialvla: Exploring spatial representations for visual-language-action model, 2025. URLhttps://arxiv.org/abs/2501.15830. 14
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[75]
Wenxuan Song, Jiayi Chen, Pengxiang Ding, Han Zhao, Wei Zhao, Zhide Zhong, Zongyuan Ge, Jun Ma, and Haoang Li. Accelerating vision-language-action model integrated with action chunking via parallel decoding, 2025. URLhttps://arxiv.org/abs/2503.02310
-
[76]
STAR: Learning Diverse Robot Skill Abstractions through Rotation-Augmented Vector Quantization
Hao Li, Qi Lv, Rui Shao, Xiang Deng, Yinchuan Li, Jianye Hao, and Liqiang Nie. Star: Learning diverse robot skill abstractions through rotation-augmented vector quantization, 2025. URLhttps://arxiv.org/abs/2506.03863
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[77]
Dita: Scaling diffusion transformer for generalist vision-language-action policy, 2025
Zhi Hou, Tianyi Zhang, Yuwen Xiong, Haonan Duan, Hengjun Pu, Ronglei Tong, Chengyang Zhao, Xizhou Zhu, Yu Qiao, Jifeng Dai, and Yuntao Chen. Dita: Scaling diffusion transformer for generalist vision-language-action policy, 2025. URL https://arxiv.org/abs/2503. 19757
2025
-
[78]
CoT-VLA: Visual Chain-of-Thought Reasoning for Vision-Language-Action Models
Qingqing Zhao, Yao Lu, Moo Jin Kim, Zipeng Fu, Zhuoyang Zhang, Yecheng Wu, Zhaoshuo Li, Qianli Ma, Song Han, Chelsea Finn, Ankur Handa, Ming-Yu Liu, Donglai Xiang, Gordon Wetzstein, and Tsung-Yi Lin. Cot-vla: Visual chain-of-thought reasoning for vision-language- action models, 2025. URLhttps://arxiv.org/abs/2503.22020
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[79]
Wei Li, Renshan Zhang, Rui Shao, Jie He, and Liqiang Nie. CogVLA: Cognition-aligned vision-language-action model via instruction-driven routing & sparsification.arXiv preprint, arxiv:2508.21046, 2025
-
[80]
Unified World Models: Coupling Video and Action Diffusion for Pretraining on Large Robotic Datasets
Chuning Zhu, Raymond Yu, Siyuan Feng, Benjamin Burchfiel, Paarth Shah, and Abhishek Gupta. Unified world models: Coupling video and action diffusion for pretraining on large robotic datasets, 2025. URLhttps://arxiv.org/abs/2504.02792
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[81]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
Tony Z. Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. Learning fine-grained bimanual manipulation with low-cost hardware, 2023. URLhttps://arxiv.org/abs/2304.13705
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[82]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis, 2023. URLhttps://arxiv.org/abs/2307.01952
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[83]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models, 2022. URLhttps://arxiv.org/abs/2010.02502
work page internal anchor Pith review Pith/arXiv arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.