PhyDrawGen: Physically Grounded Diagram Generation from Natural Language
Pith reviewed 2026-06-29 06:56 UTC · model grok-4.3
The pith
PhyDrawGen generates physics diagrams from text using an LLM scene graph followed by a deterministic solver that enforces physical laws as geometry.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
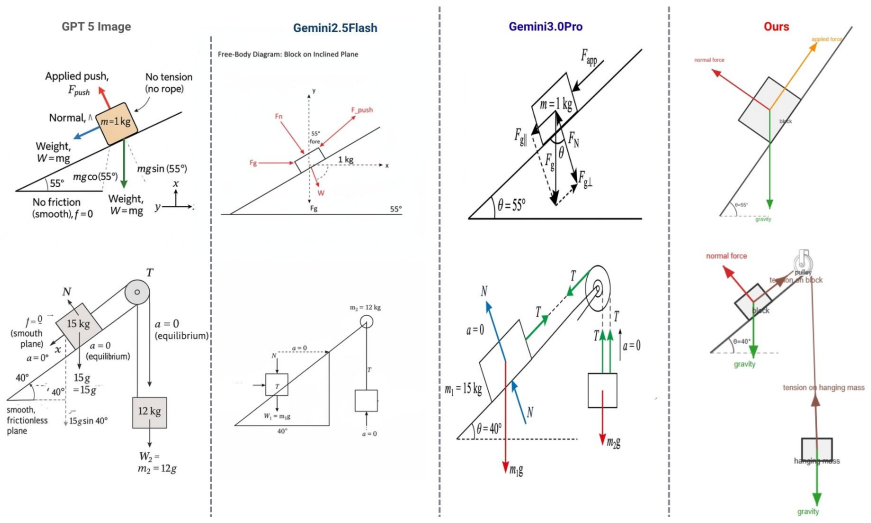
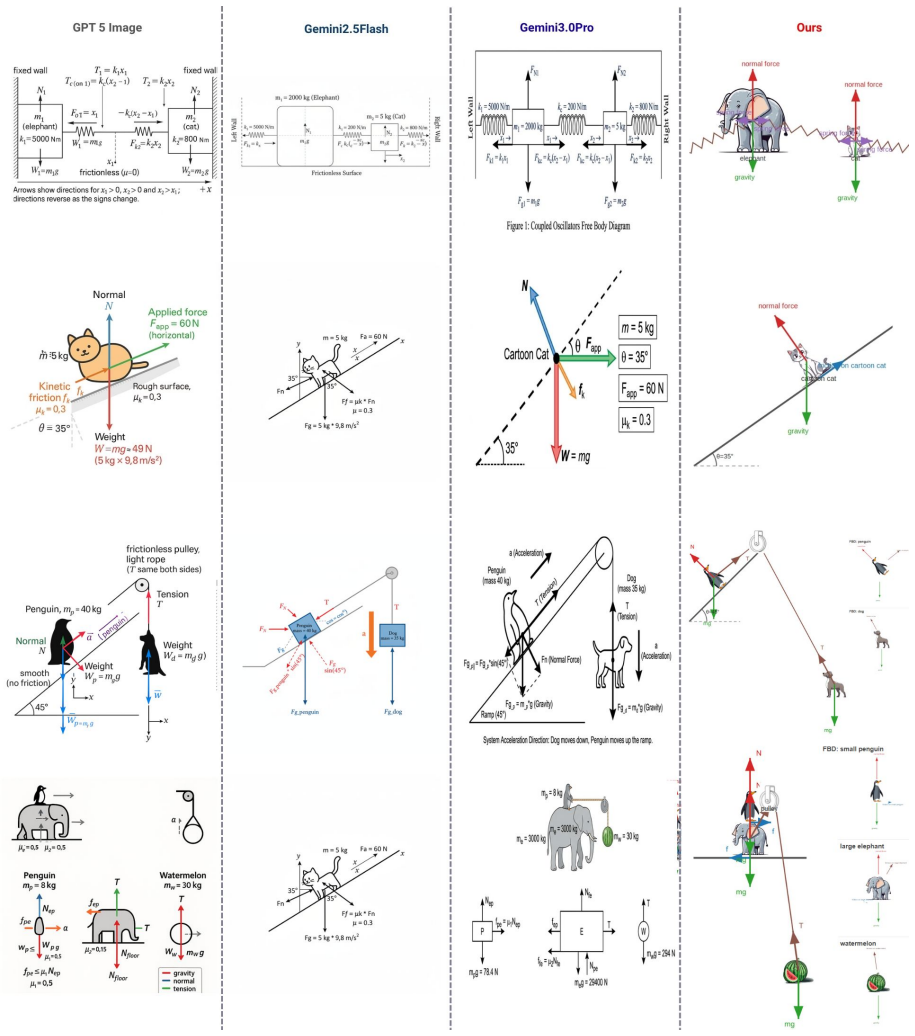
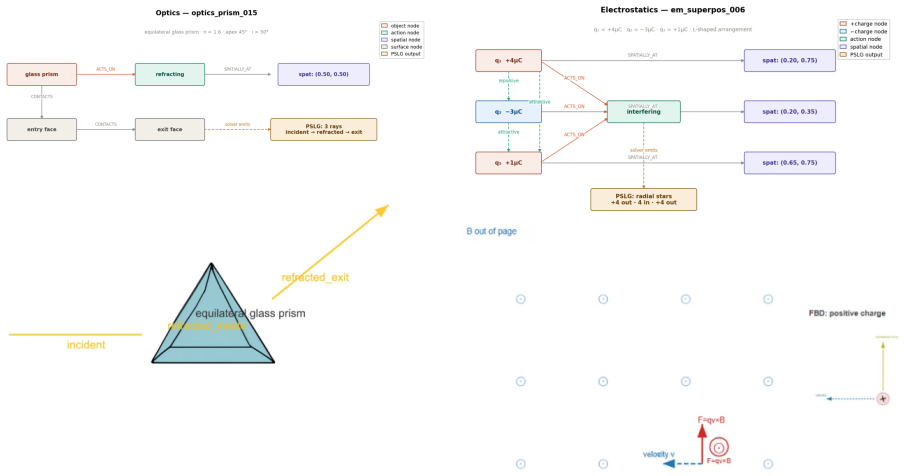
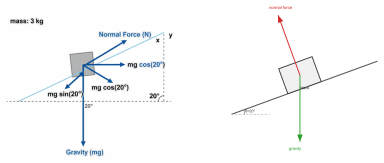
PhyDrawGen decouples semantic scene understanding from physical constraint satisfaction by extracting a typed scene graph with an LLM, converting that graph deterministically into a Planar Straight-Line Graph that encodes force balance, optical paths, and field topologies as exact geometric primitives, and applying a fine-tuned vision model in a propose-verify loop to correct residual violations, resulting in higher physical accuracy than GPT-5-image, Gemini 2.5 Flash, or Gemini 3 Pro across 1,449 mechanics, optics, and electromagnetism problems.
What carries the argument
The typed scene graph extracted from text and converted by the deterministic solver into a Planar Straight-Line Graph whose primitives encode physical constraints exactly.
If this is right
- Diagrams satisfy conservation laws and geometric constraints without requiring post-hoc fixes by the user.
- Accuracy holds for problems containing objects or configurations absent from training data.
- The same pipeline applies uniformly to mechanics, optics, and electromagnetism problems.
- Iterative visual correction reduces but does not eliminate errors that originate in the initial scene graph.
Where Pith is reading between the lines
- The same scene-graph-plus-solver structure could be tested on chemistry structure drawing or engineering schematic tasks that also mix language with strict rules.
- An explicit graph-verification step before the solver might reduce propagation of extraction errors.
- The method suggests that scientific diagram generation benefits from keeping symbolic constraint satisfaction separate from learned visual rendering.
Load-bearing premise
The LLM extracts a typed scene graph that accurately and completely records every physical constraint and relation present in the problem text.
What would settle it
A physics problem whose extracted scene graph omits a required force or path, after which the solver and correction loop still produce a diagram that violates that law.
Figures




read the original abstract
Generating physics diagrams from text requires strict adherence to physical laws. While current generative models produce visually plausible outputs, they systematically hallucinate force vectors, ignore conservation laws, and violate geometric constraints. We present PhyDrawGen, a neuro-symbolic pipeline that decouples semantic scene understanding from physical constraint satisfaction. First, a large language model extracts a typed scene graph from the problem text. A deterministic solver then converts this graph into a Planar Straight-Line Graph (PSLG), encoding force balance, optical paths, and field topologies as exact geometric primitives. Finally, a fine-tuned Qwen-VL model implements a visually grounded propose-verify loop to iteratively correct any constraint violations. Evaluated on a benchmark of 1,449 problems spanning mechanics, optics, and electromagnetism, PhyDrawGen significantly outperforms GPT-5-image, Gemini 2.5 Flash, and Gemini 3 Pro, demonstrating robust physical accuracy even on unusual-object problems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents PhyDrawGen, a neuro-symbolic pipeline for generating physics diagrams from natural language. An LLM extracts a typed scene graph from the problem text, which a deterministic solver converts into a Planar Straight-Line Graph (PSLG) enforcing physical constraints such as force balance and optical paths. A fine-tuned Qwen-VL model then performs a propose-verify loop to correct violations. The paper claims that this approach significantly outperforms GPT-5-image, Gemini 2.5 Flash, and Gemini 3 Pro on a benchmark of 1,449 problems across mechanics, optics, and electromagnetism, with robust performance even on unusual-object problems.
Significance. If the quantitative claims hold with proper evaluation, the neuro-symbolic decoupling of semantic scene understanding from physical constraint satisfaction could advance reliable diagram generation for physics education and problem-solving applications.
major comments (2)
- [Abstract] Abstract: the claim of significant outperformance and robustness on the 1,449-problem benchmark is asserted without any quantitative metrics, error bars, benchmark construction details, or failure analysis, rendering the central claim impossible to evaluate.
- [Method] Pipeline (scene graph extraction step): the typed scene graph extracted by the LLM is assumed to accurately and completely encode all physical constraints and relations, but no quantitative evaluation or error analysis of extraction accuracy is provided. This assumption is load-bearing for the pipeline, as omissions (e.g., force balance or field topology) would cause the deterministic PSLG solver to fail with no recovery mechanism in the Qwen-VL loop, particularly on the cited unusual-object problems.
minor comments (1)
- [Abstract] Abstract: the benchmark is described only by total size (1,449) with no breakdown by subfield or details on problem selection and annotation.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback. We address each major comment below and commit to revisions that strengthen the manuscript's transparency and rigor.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of significant outperformance and robustness on the 1,449-problem benchmark is asserted without any quantitative metrics, error bars, benchmark construction details, or failure analysis, rendering the central claim impossible to evaluate.
Authors: We agree that the abstract should be self-contained with respect to the central claims. In the revision we will insert concise quantitative results (accuracy percentages with error bars across the three domains), a one-sentence description of benchmark construction, and a pointer to the full failure analysis in Section 5. These additions will allow readers to evaluate the performance claims directly from the abstract. revision: yes
-
Referee: [Method] Pipeline (scene graph extraction step): the typed scene graph extracted by the LLM is assumed to accurately and completely encode all physical constraints and relations, but no quantitative evaluation or error analysis of extraction accuracy is provided. This assumption is load-bearing for the pipeline, as omissions (e.g., force balance or field topology) would cause the deterministic PSLG solver to fail with no recovery mechanism in the Qwen-VL loop, particularly on the cited unusual-object problems.
Authors: The referee is correct that a quantitative assessment of scene-graph extraction accuracy is absent. We will add a dedicated subsection (new Section 4.2) that reports precision/recall for constraint extraction on a 200-problem held-out set, stratified by domain and by presence of unusual objects. We will also include an error-propagation analysis showing how extraction mistakes are (or are not) recovered by the subsequent Qwen-VL propose-verify loop. These results will be used to qualify the load-bearing assumption. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper describes a neuro-symbolic pipeline (LLM scene-graph extraction, deterministic PSLG solver, Qwen-VL propose-verify loop) with no equations, fitted parameters, or self-citations visible in the abstract or described method. No load-bearing step reduces a claimed result to its inputs by construction, and the central claims rest on the independence of the components rather than any self-referential fit or renaming.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption An LLM can extract a typed scene graph from natural language that fully captures the physical entities and constraints of the problem.
- domain assumption A deterministic solver can always convert the extracted scene graph into a PSLG that satisfies force balance, optical paths, and field topologies without additional human intervention.
Reference graph
Works this paper leans on
-
[1]
URL: " 'urlintro :=
ENTRY address author booktitle chapter edition editor howpublished institution journal key month note number organization pages publisher school series title type volume year eprint doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRINGS urlintro eprinturl eprintpr...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. 2023. https://arxiv.org/abs/2308.12966 Qwen-VL : A versatile vision-language model for understanding, localization, text reading, and beyond . arXiv preprint arXiv:2308.12966
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [4]
-
[5]
Marshall Bern and Barry Hayes. 1996. The complexity of flat origami. In Proceedings of the Seventh Annual ACM-SIAM Symposium on Discrete Algorithms, SODA '96, page 175–183, USA. Society for Industrial and Applied Mathematics
1996
-
[6]
Erik D Demaine and Joseph O'Rourke. 2007. https://doi.org/10.1017/CBO9780511735172 Geometric Folding Algorithms: Linkages, Origami, Polyhedra . Cambridge University Press, Cambridge, UK
- [7]
-
[8]
David J Griffiths. 2013. Introduction to electrodynamics. Pearson
2013
-
[9]
Chaoqun He, Renjie Luo, Yuzhuo Wang, Jiannan Wang, Wei Chu, et al. 2024. https://arxiv.org/abs/2402.14008 OlympiadBench : A challenging benchmark for promoting AGI with olympiad-level bilingual multimodal scientific problems . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Eugene Hecht. 2002. Optics, 4th intern edition. Addison Wesley
2002
-
[11]
David Hestenes, Malcolm Wells, and Gregg Swackhamer. 1992. https://doi.org/10.1119/1.2343497 Force concept inventory . The Physics Teacher, 30(3):141--158
-
[12]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. https://arxiv.org/abs/2006.11239 Denoising diffusion probabilistic models . In Advances in Neural Information Processing Systems, volume 33, pages 6840--6851
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[13]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021. http://arxiv.org/abs/2106.09685 Lora: Low-rank adaptation of large language models
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[14]
Yanjia Huang, Yunuo Chen, Ying Jiang, Jinru Han, Zhengzhong Tu, Yin Yang, and Chenfanfu Jiang. 2026. http://arxiv.org/abs/2603.29585 Learn2fold: Structured origami generation with world model planning
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
Thomas C Hull. 2002. The combinatorics of flat folds: A survey. In Origami ^3 : Third International Meeting of Origami Science, Mathematics, and Education, pages 29--38. A K Peters
2002
-
[16]
Justin Johnson, Agrim Gupta, and Li Fei-Fei. 2018. https://arxiv.org/abs/1804.01622 Image generation from scene graphs . In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1219--1228
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[17]
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. 2022. https://arxiv.org/abs/2205.11916 Large language models are zero-shot reasoners . In Advances in Neural Information Processing Systems, volume 35, pages 22199--22213
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[18]
Harold W. Kuhn. 1955. https://doi.org/10.1002/nav.3800020109 The Hungarian Method for the Assignment Problem . Naval Research Logistics Quarterly, 2(1--2):83--97
-
[19]
Ka Ho Lai, Hei Tung Tsang, Gary P. T. Choi, and Lok Ming Lui. 2026. http://arxiv.org/abs/2604.20137 Optimization of constrained quasiconformal mapping for origami design
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
Yuheng Li, Haotian Liu, Qingyang Wu, Fangzhou Mu, Jianwei Yang, Jianfeng Gao, Chunyuan Li, and Yong Jae Lee. 2023. https://arxiv.org/abs/2301.07093 GLIGEN : Open-set grounded text-to-image generation . In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22511--22521
-
[21]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. https://arxiv.org/abs/2304.08485 Visual instruction tuning . In Advances in Neural Information Processing Systems, volume 36
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Pan Lu, Bansal Hritik, Tony Xia, Jiacheng Liu, Chunyuan Li, Hajishirzi Hannaneh, Cheng Hao, Chang Kai-Wei, Galley Michel, and Gao Jianfeng. 2024. https://arxiv.org/abs/2310.02255 MathVista : Evaluating mathematical reasoning of foundation models in visual contexts . In International Conference on Learning Representations
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Pan Lu, Swaroop Mishra, Tanglin Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. 2022. https://arxiv.org/abs/2209.09513 Learn to explain: Multimodal reasoning via thought chains for science question answering . In Advances in Neural Information Processing Systems, volume 35, pages 2507--2521
-
[24]
J. Matas, C. Galambos, and J. Kittler. 2000. https://doi.org/https://doi.org/10.1006/cviu.1999.0831 Robust detection of lines using the progressive probabilistic hough transform . Computer Vision and Image Understanding, 78(1):119--137
-
[25]
Chong Mou, Xintao Wang, Liangbin Xie, Jian Zhang, Zhongang Qi, Ying Shan, and Xiaohu Qie. 2024. https://arxiv.org/abs/2302.08453 T2I-Adapter : Learning adapters to dig out more controllable ability for text-to-image diffusion models . In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 4296--4304
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
OpenAI . 2023. https://arxiv.org/abs/2303.08774 GPT-4 technical report . arXiv preprint arXiv:2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. 2022. https://arxiv.org/abs/2204.06125 Hierarchical text-conditional image generation with CLIP latents . arXiv preprint arXiv:2204.06125
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[28]
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj \"o rn Ommer. 2022. https://arxiv.org/abs/2112.10752 High-resolution image synthesis with latent diffusion models . In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10684--10695
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[29]
Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily Denton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, S. Sara Mahdavi, Rapha Gontijo Lopes, Tim Salimans, Jonathan Ho, David J Fleet, and Mohammad Norouzi. 2022. http://arxiv.org/abs/2205.11487 Photorealistic text-to-image diffusion models with deep language understanding
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[30]
Jiaming Song, Chenlin Meng, and Stefano Ermon. 2021. https://arxiv.org/abs/2010.02502 Denoising diffusion implicit models . In International Conference on Learning Representations
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[31]
Michael Vignal and Bethany R. Wilcox. 2022. https://doi.org/10.1103/physrevphyseducres.18.010104 Investigating unprompted and prompted diagrams generated by physics majors during problem solving . Physical Review Physics Education Research, 18(1)
- [32]
-
[33]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, and Denny Zhou. 2022. https://arxiv.org/abs/2201.11903 Chain-of-thought prompting elicits reasoning in large language models . In Advances in Neural Information Processing Systems, volume 35, pages 24824--24837
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[34]
Kun Xiang, Heng Li, Terry Jingchen Zhang, Yinya Huang, Zirong Liu, Peixin Qu, Jixi He, Jiaqi Chen, Yu-Jie Yuan, Jianhua Han, Hang Xu, Hanhui Li, Mrinmaya Sachan, and Xiaodan Liang. 2025. http://arxiv.org/abs/2505.19099 Seephys: Does seeing help thinking? -- benchmarking vision-based physics reasoning
-
[35]
Ximing Xing, Chuang Wang, Haitao Zhou, Jing Zhang, Qian Yu, and Dong Xu. 2026. http://arxiv.org/abs/2306.14685 Diffsketcher: Text guided vector sketch synthesis through latent diffusion models
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[36]
Danfei Xu, Yuke Zhu, Christopher B Choy, and Li Fei-Fei. 2017. https://arxiv.org/abs/1701.02426 Scene graph generation by iterative message passing . In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5410--5419
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[37]
Hu Ye, Jun Zhang, Sibo Liu, Xiao Han, and Wei Yang. 2023. https://arxiv.org/abs/2308.06721 IP-Adapter : Text compatible image prompt adapter for text-to-image diffusion models . arXiv preprint arXiv:2308.06721
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[38]
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, Cong Wei, Botao Yu, Ruibin Yuan, Renliang Sun, Ming Yin, Boyuan Zheng, Zhenzhu Yang, Yibo Liu, Wenhao Huang, Huan Sun, Yu Su, and Wenhu Chen. 2024. http://arxiv.org/abs/2311.16502 Mmmu: A massive multi-discipline multimodal underst...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. 2023. https://arxiv.org/abs/2302.05543 Adding conditional control to text-to-image diffusion models . In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 3836--3847
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.